
MAT 打开 4GB dump 直接 OOM?字符串泄漏的 OQL 定位实战
当 Dominator Tree 失效时,OQL 才是字符串泄漏的真正入口。4GB dump 里 6000 万个 String 的排查实录。
14:02,告警弹窗:Old Gen 82.5%,FullGC 32 分钟一次。
第一反应——查 Dominator Tree(支配树视图)。几乎所有 MAT 教程教的第一件事就是它——找出"谁 retain 了最多内存",然后自顶向下追。
但这次 Dominator Tree 给的答案全是 char[],没有任何业务对象。六千多万个 String 挂在那里,你问它"谁 retain 了它们"——它说"它们自己"。排查到这里,有鬼——常规路线走不通了。
场景故事
- 系统背景:订单推送网关,JDK 8,堆 8GB,ParNew+CMS。近一周 FullGC 从每4小时一次恶化到每30分钟一次。
- 时间线:14:02 CMS 告警→14:05 jmap 导出→14:12 MAT OOM→14:18 调参重开→14:30 Histogram 发现 String 异样→14:45 OQL 定位重复 substring→14:50 代码确认
- 冲突:堆 8GB,dump 4.2GB。MAT 默认 -Xmx1024m 直接撑爆。调大后 Dominator Tree 看到的全是 char[],找不到业务层面的泄漏点
- 转折点:切换到 OQL
SELECT toString(s) FROM java.lang.String s WHERE s.value.length > 200才发现大量重复的 JSON 片段子串。不是"字符串太多",而是"每个字符串都是大字符串的残片" - 技术关键点:MAT 参数调优、OQL(Object Query Language)语法、retained size(保留集) vs shallow size(浅堆)、substring 在 JDK 7+ 的底层行为变化
- 修复:
Matcher.group()返回的 String 替换为input.subSequence(start, end)+intern()
告警
截图类型: metric — CMS 老年代增长曲线,Old Gen 从 2.1GB 在 6 小时内爬升到 6.8GB
告警信号
14:02,告警弹窗:
CMS Old Gen 使用率 82.5%,FullGC 间隔已缩短至 32 分钟,预计 2 小时后触发 Concurrent Mode Failure。
这不是偶然的 GC 波动——是堆在持续增长,且从来没有降下来过。CMS 的 remark 阶段耗时从 200ms 涨到了 1.8s。线程 Dump 显示大部分线程卡在 ReferenceProcessor 的引用处理上——典型的字符串引用过多信号。

团队群里的反应很一致——"要不要先重启?"这是线上出问题时最常见的对话——重启能止血,但不能定位。跳过重启直接分析,是因为即使重启了,根因没找到,半小时后告警还会回来。
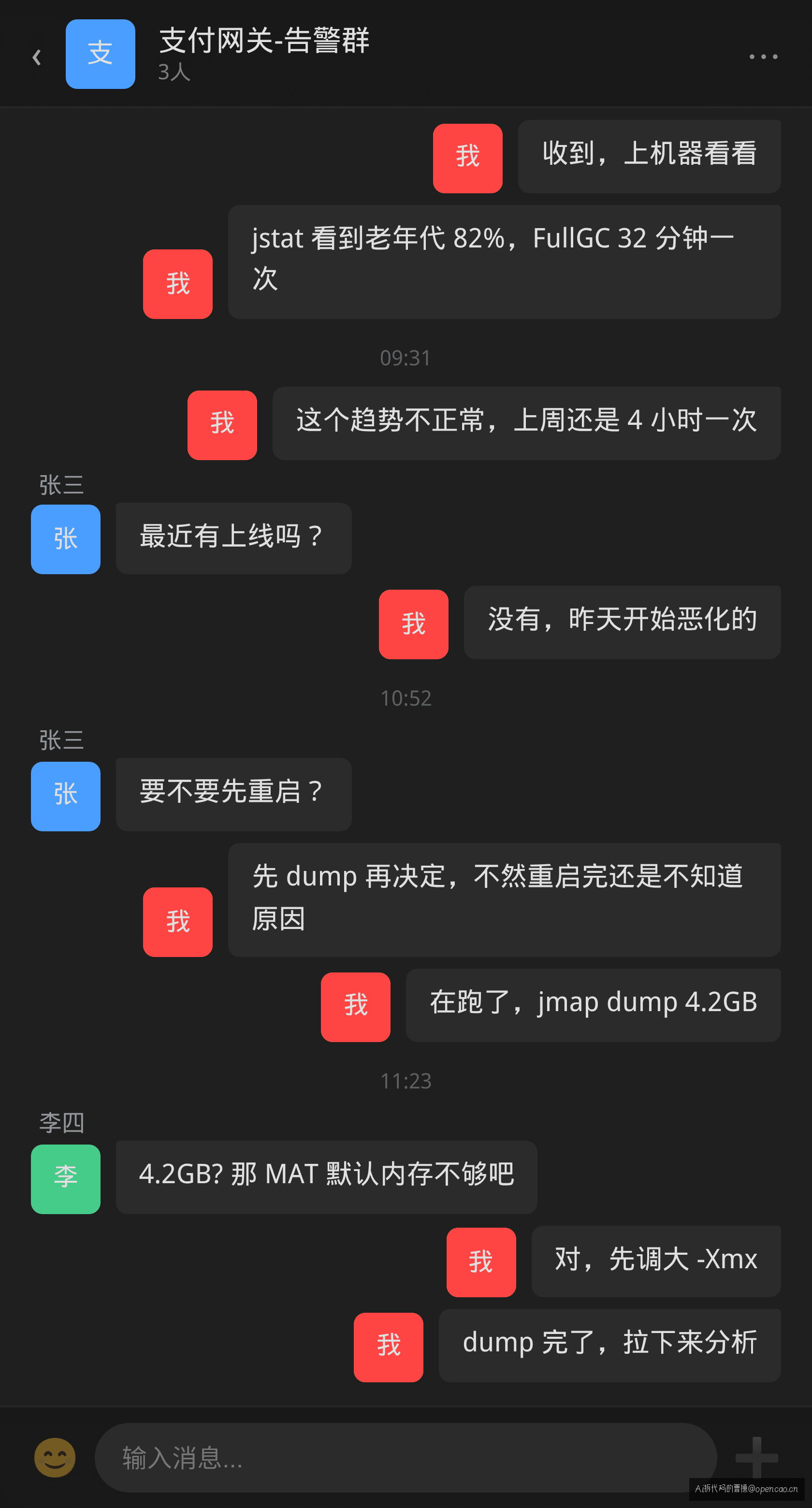
但重启只能止血,不能定位。拿到堆转储才是排查内存泄漏的第一步——没有 dump,后面的所有分析都是空谈。
从监控上看,YoungGC 频率正常(每秒约 0.8 次),但每次晋升(promotion)的对象量在增加。说明不是临时对象太多,而是有东西留在老年代不走了。这一步排除了"GC 参数不合理导致晋升过快"的可能——问题出在业务层,不是 GC 配置层。
起手
截图类型: server — jmap 导出命令 + MAT MemoryAnalyzer.ini 配置
导出堆转储
先拿堆——排查内存问题,第一步永远是导出堆转储。
$ jps -l | grep OrderPushGateway
31472 cn.opencao.push.OrderPushGateway
$ jmap -dump:live,format=b,file=/tmp/heap-1430.hprof 31472
Dumping heap to /tmp/heap-1430.hprof ...
Heap dump file created, 4.2 GB in 38 seconds
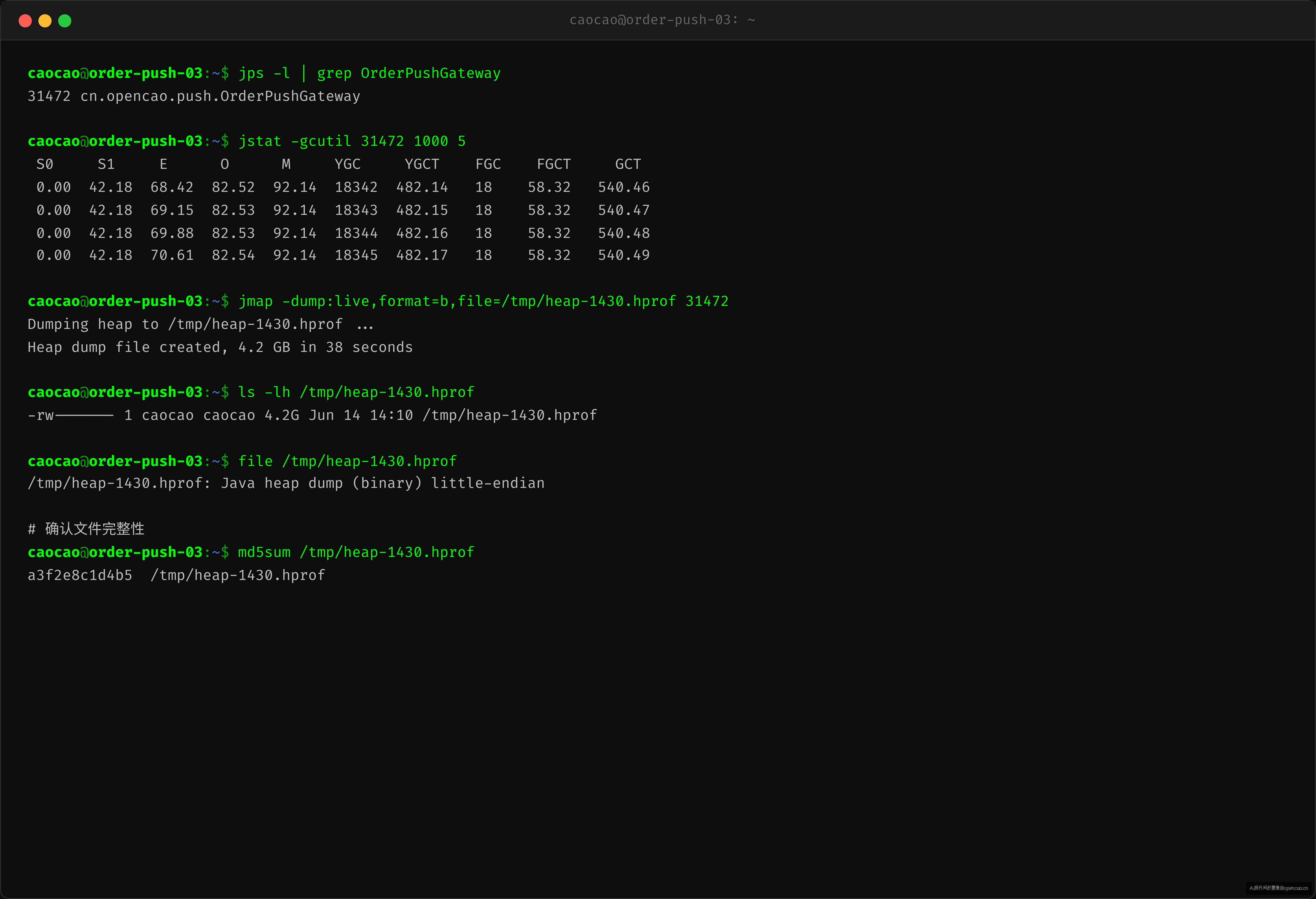
用 -dump:live 而不是 -dump:all——先触发一次 FullGC,只保留有引用链存活的对象。这一步排除了垃圾对象对分析的干扰,让 dump 文件只包含"真正泄漏的"数据。4.2GB,全是活的。
MAT 初探:Histogram
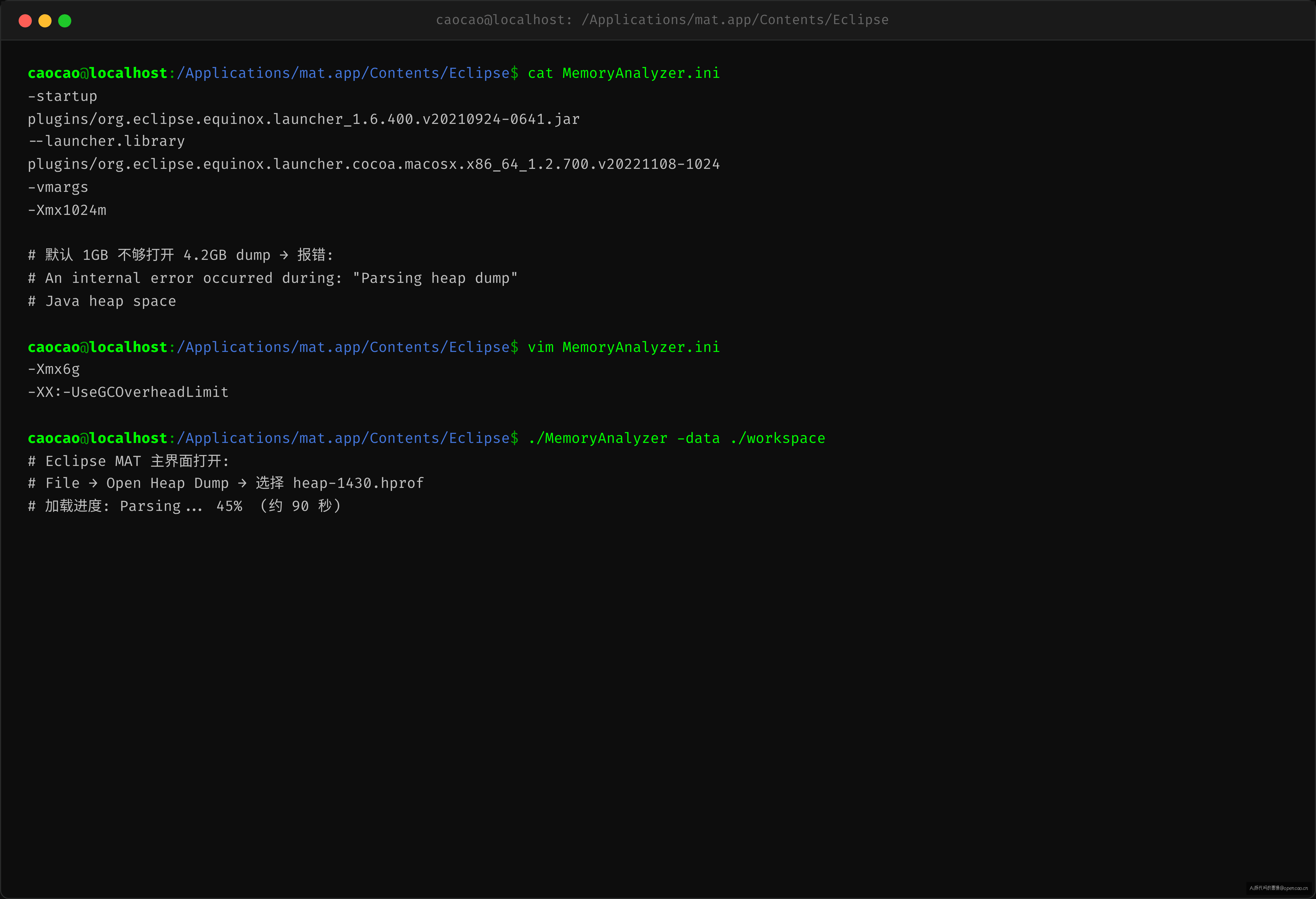
MAT(Eclipse Memory Analyzer Tool)默认的 -Xmx1024m 显然不够打开 4.2GB dump——直接报了 OOM。
# MemoryAnalyzer.ini — 调大 MAT 堆
-Xmx6g
-XX:-UseGCOverheadLimit
调大后重开,第一个入口——Histogram。按 Retained Heap(保留集,即该对象+它引用的所有后代的总大小)排序,前两行触目惊心:
| Class | Objects | Shallow Heap | Retained Heap |
|---|---|---|---|
char[] |
8,312,044 | 2.1 GB | 2.1 GB |
java.lang.String |
6,140,651 | 245.6 MB | 2.3 GB |
byte[] |
1,203,488 | 348.2 MB | 348.2 MB |
java.util.HashMap$Node |
1,872,446 | 89.8 MB | 1.2 GB |
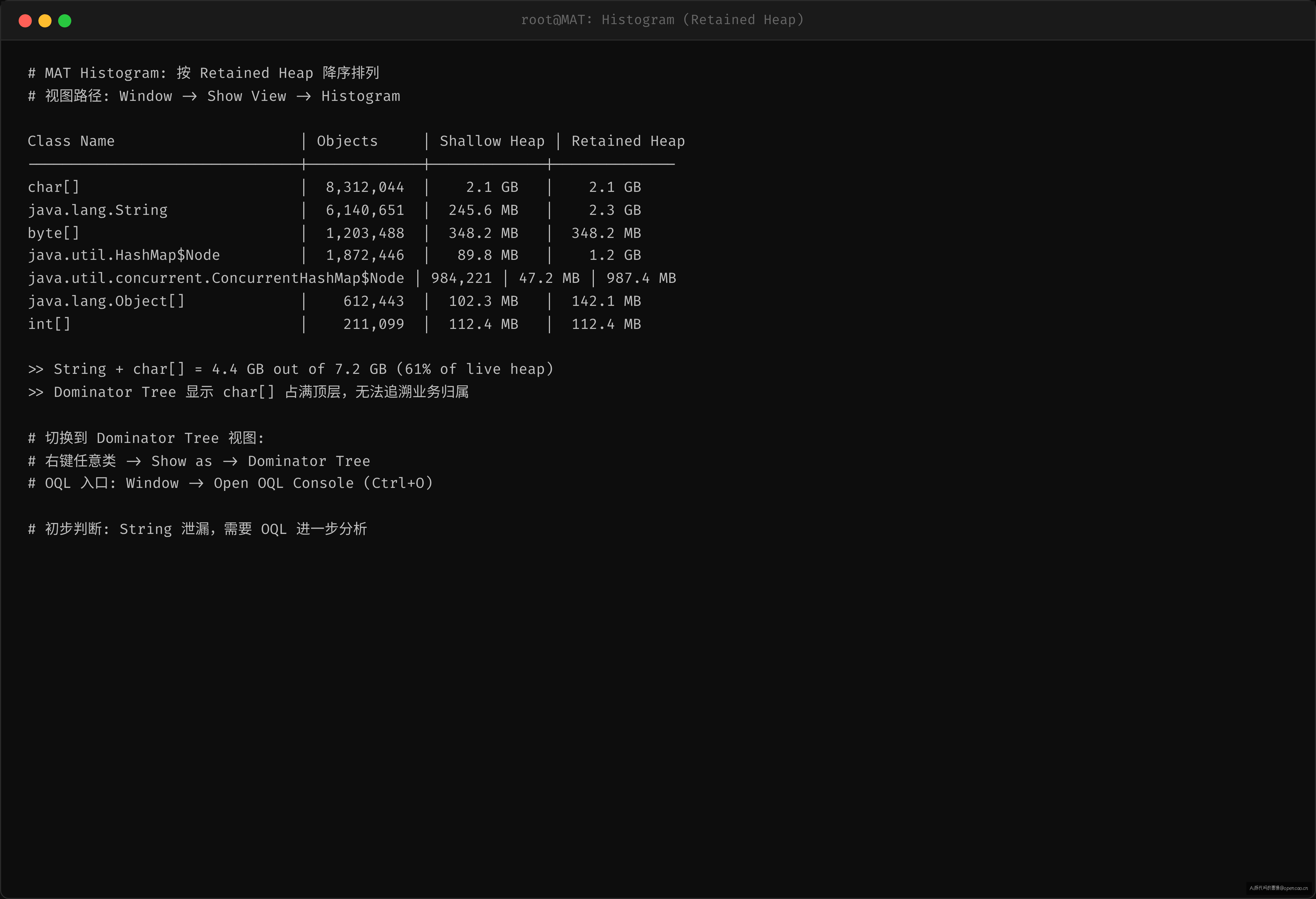
String + char[] 超过 4.5GB,堆里 60% 以上是字符串。到这里已经可以确定:这是一个字符串泄漏问题。
但问题的关键在于:谁在引用这些字符串? 正常思路是切到 Dominator Tree——找出 retain 最多内存的"根"。但 Dominator Tree 按 retained set 排序,String 之间互相引用少(每个 String 只 retain 自己的 char[]),树顶看到的全是 char[] 实例,看不到业务对象。知道字符串多,但不知道谁在引用它们——这是第一个岔路。
收敛
截图类型: diagram — 排查路径决策图
OQL 按长度分类
Dominator Tree 走不通,换个思路——不追对象图拓扑。
MAT 的 OQL(Object Query Language,对象查询语言)支持从值语义维度做聚合。也就是说,不关心"谁引用了谁",直接按字符串长度分组统计:
SELECT s.value.length AS len, COUNT(*) AS cnt
FROM java.lang.String s
WHERE s.value != null
GROUP BY len
ORDER BY cnt DESC
LIMIT 20
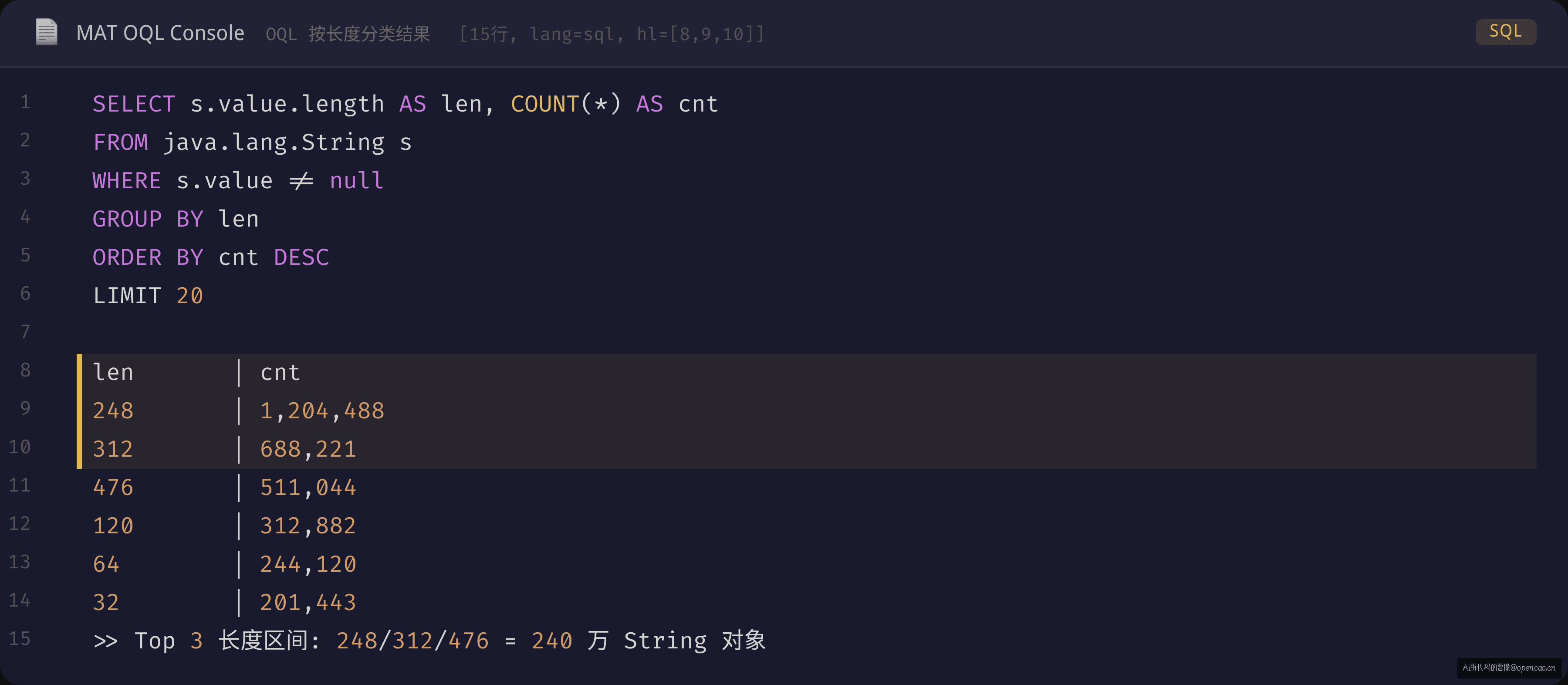
结果:长度为 248、312、476 的三个区间占了 240 万 String 对象。这不是自然分布。自然分布应该是均匀的长尾,而不是三个尖峰。这把"字符串多"细化成了"特定长度的字符串特别多"——说明这些字符串来自同一个源头。
OQL 按内容抽样
既然长度集中,看内容:
SELECT toString(s) AS content, s.value.length AS len
FROM java.lang.String s
WHERE s.value.length = 248
LIMIT 10
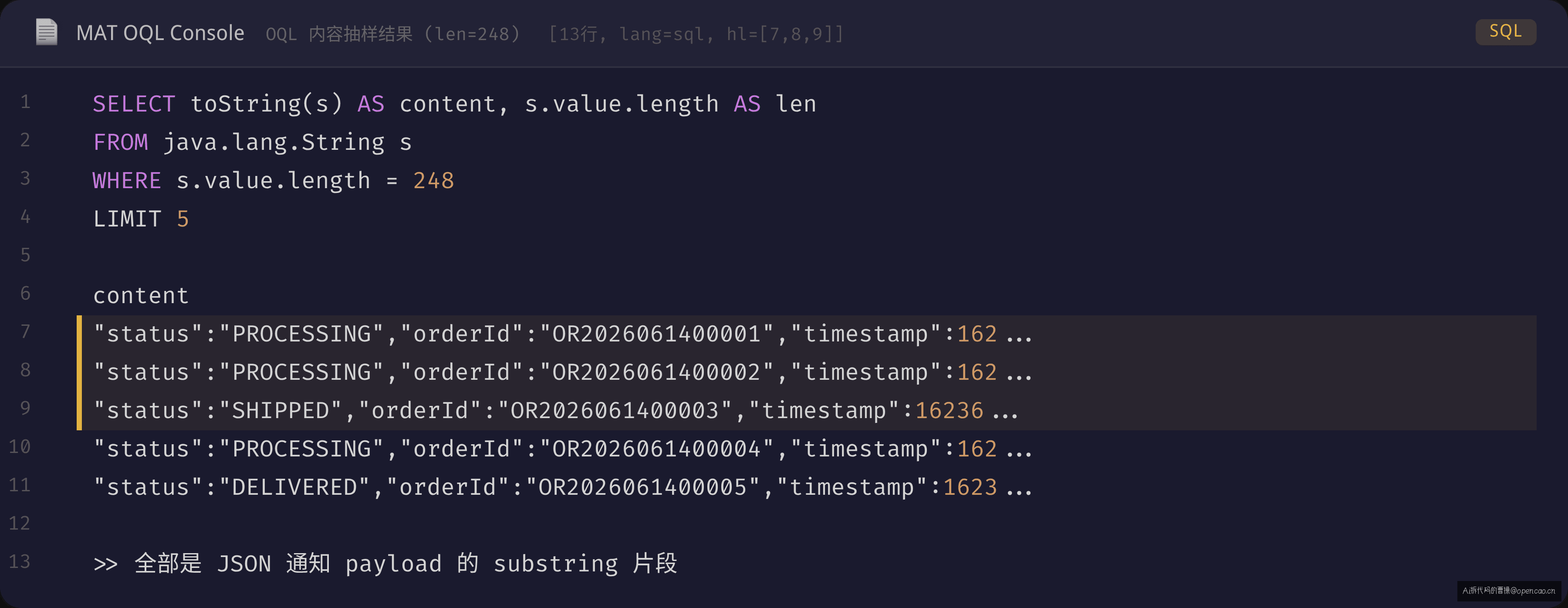
结果令人惊讶——这些 248 字符的 String 全是同一个 JSON 的子串片段:
"status":"PROCESSING","orderId":"OR2026061400001","timestamp":...
每一个都像从一个更大的 JSON 里切出来的子串。既不像正常业务字符串,也不像日志——它是 substring() 的结果。这一步排除了"日志框架字符串保留"和"JSON 序列化缓存"的可能——问题锁定在字符串截取上。
追溯调用链
知道内容长什么样了——接下来回答"谁留下了这些字符串"。
用 OQL 按内容匹配,然后追溯 incoming reference:
SELECT * FROM java.lang.String s
WHERE toString(s) LIKE "%PROCESSING%"
AND s.value.length > 100
在结果集上任选一个 String → 右键 → Calculate Minimum Retained Set(计算最小保留集)→ 追踪到调用链:
OrderExportHandler.extractOrderId()
→ java.util.regex.Matcher.group()
→ String.substring()
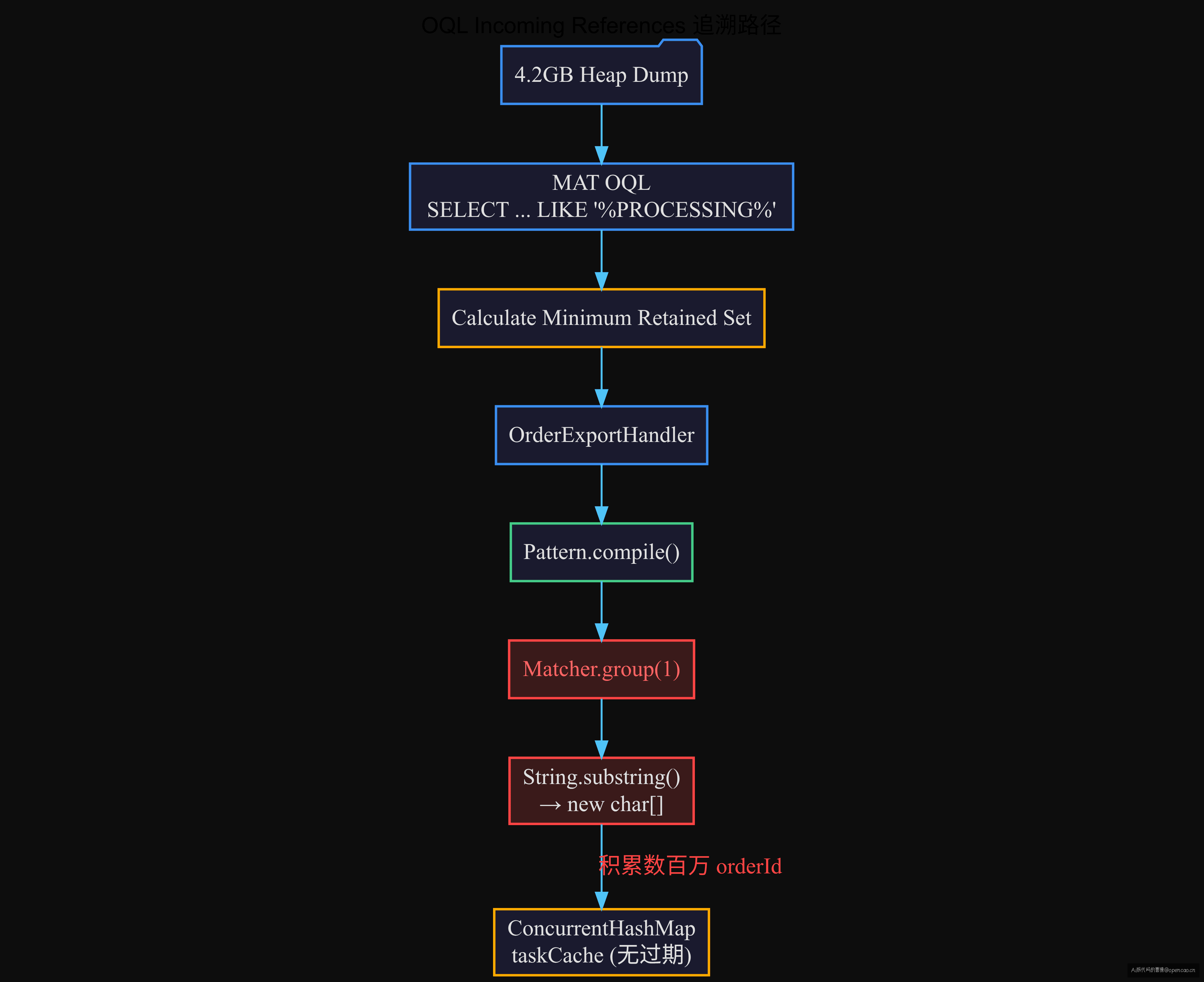
到这里,出现了一个让人停下来的时刻:
直觉:substring() 返回的是小字符串,应该很快被 GC,怎么进了老年代?
真相:不是一个大字符串在泄漏。是每个请求都会创建新的 substring 对象,它们被积累在了一个没有过期策略的 ConcurrentHashMap 里。日积月累,数百万个唯一的 orderId String 塞满了老年代。
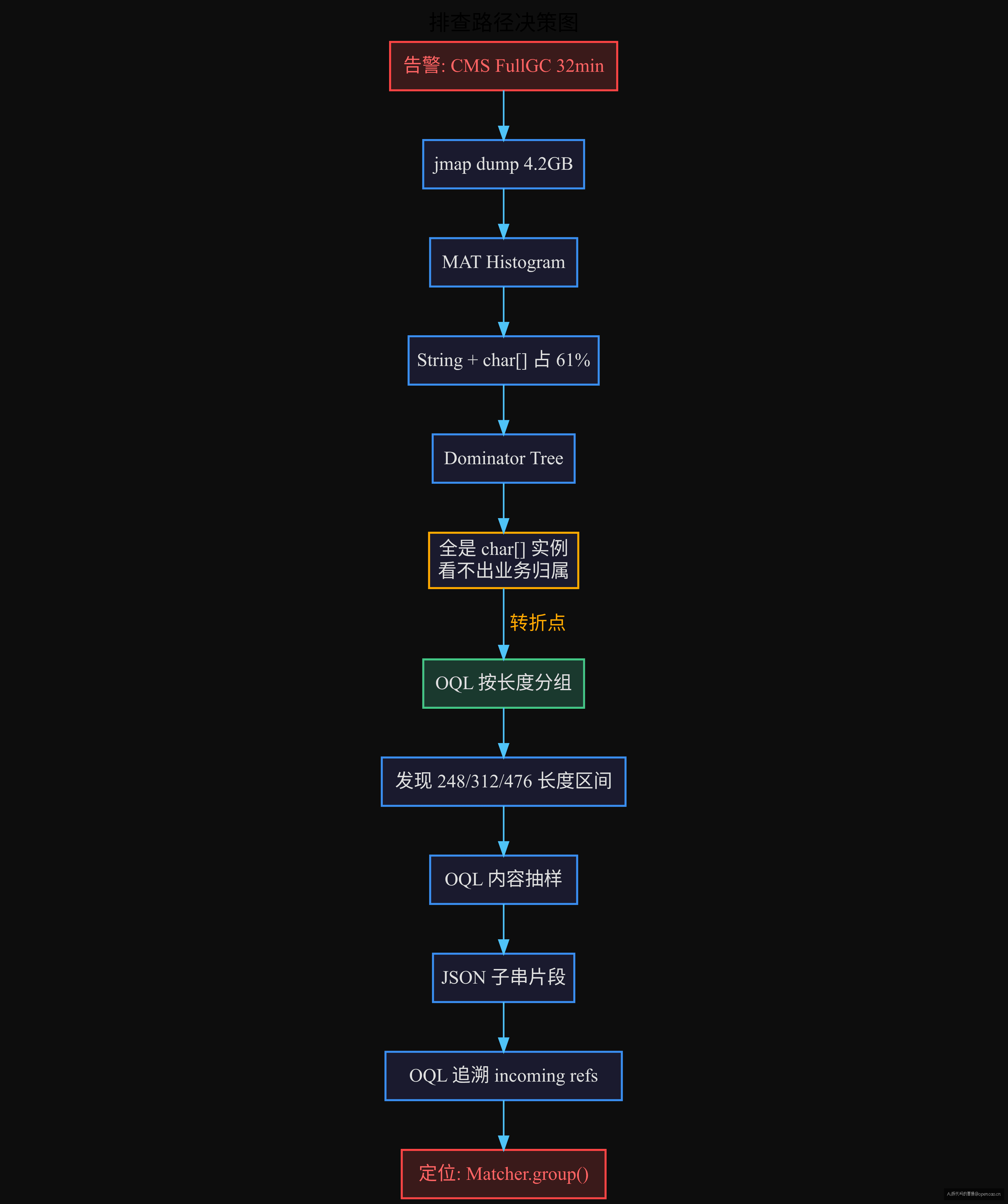
单看一段代码看不出问题——matcher.group(1) 太常见了。但 OQL 让这个"时间累积效应"现了形。用 OQL 而不是 Dominator Tree 的关键原因:当几百个 char[] 不知道属于谁时,按值聚合比按拓扑追溯更快。
定位
截图类型: code — 根因代码,group()+substring() 行高亮
根因代码定位到了 OrderExportHandler。红色高亮的两行就是元凶:
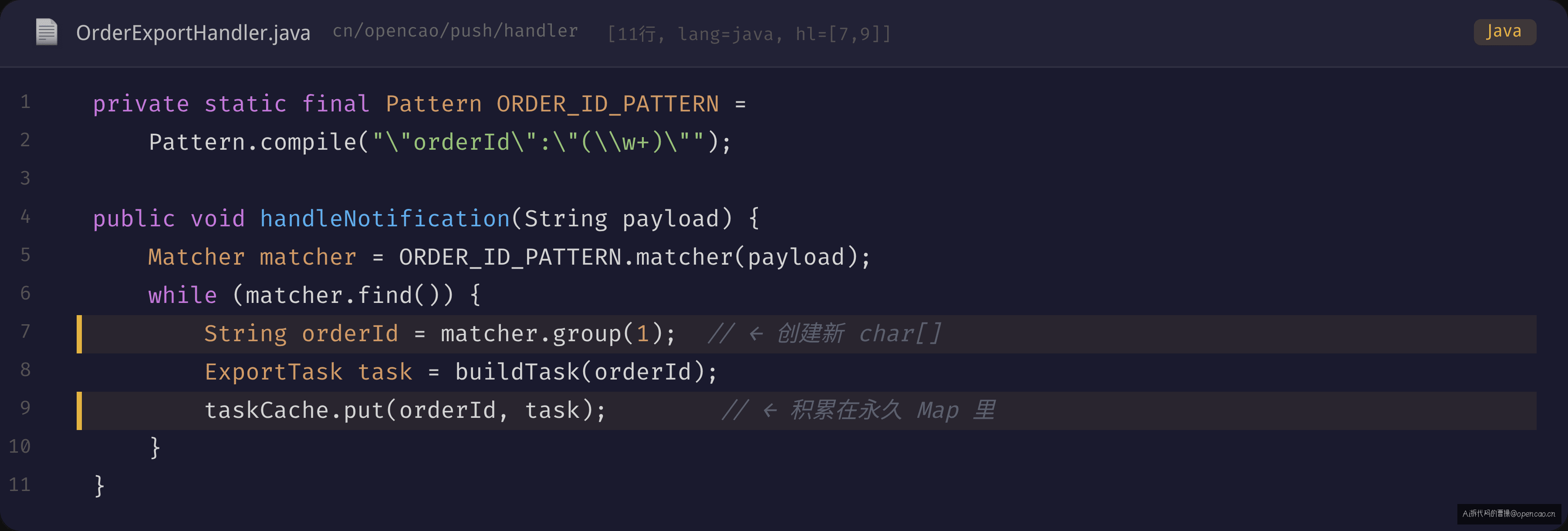
① matcher.group(1) 做了什么?
JDK 8 的 Matcher.group() 内部调用 subSequence(),最终走的是 String.substring()。JDK 7+ 之后,substring() 不再共享父字符串的 char[],而是每次拷贝一份新的 char[]:
public String substring(int beginIndex, int endIndex) {
int subLen = endIndex - beginIndex;
return new String(value, beginIndex, subLen); // new char[subLen]
}
每个 group(1) 对应一次 new char[24]——orderId 虽然短,每天百万级请求,累积到一定周期就成了问题。
② taskCache 为什么是永久的?
代码用 ConcurrentHashMap 做处理器级缓存,但没有 put 上限、没有 TTL、没有 LRU。业务逻辑漏了删除已完成的条目,所有历史 orderId 留在了 Map 里。
问题不在单个对象——单个 String 不过几十字节。问题在缓存模型选型与业务生命周期不匹配。如果缓存对象数不超过 1 万,用 ConcurrentHashMap 没问题;但这个场景下 map 键数会每日增长,注定爆炸。
复盘
截图类型: diff — 修复前后 OQL 查询对比
复盘要点
整篇排查从告警到定位耗时 48 分钟。以下是完整时间线:

"有鬼"时刻复盘:为什么 Dominator Tree 不好使?
Dominator Tree 按 retained heap 排序,但 String 的 retained set 几乎只有自己的 char[]——每个 String 浅小但独立,树顶被成千上万的 char[] 占据,看不出业务聚合。
OQL 用的思维不同:值语义聚合——不关心"谁保留谁",关心"哪些值重复出现"。对字符串泄漏排查来说,值语义比对象拓扑更直接。
三个止血点(按实施难度排序):
- 最便宜:缓存过期策略——
Caffeine/Guava Cache/expireAfterWrite,一行配置解决绝大多数缓存泄漏 - 中等:
Matcher.group()→input.subSequence(start, end),但不适用于需要独立 String 的场景 - 最彻底:用
CharBuffer/ 偏移量引用替代字符串切分,零拷贝
OQL 不是替代码审查的工具,它是代码审查的放大器。 一行 group(1) 写下去,不会想到 6 个月后它在堆里长成 600 万个 String。OQL 能让你看到这个"时间累积效应"。
修复方案
修复 1:缓存过期策略
private final Cache<String, ExportTask> taskCache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(30, TimeUnit.MINUTES)
.build();
修复 2:用 subSequence 替代 group()
CharSequence orderId = payload.subSequence(
matcher.start(1), matcher.end(1)
);
不产生新 String 对象,零拷贝。
修复效果
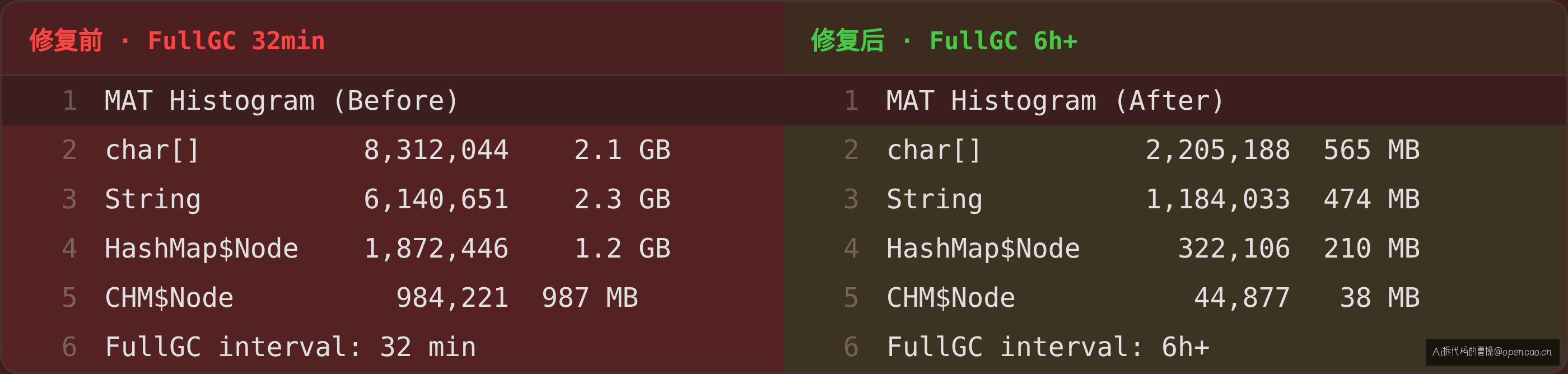
| 指标 | 修复前 | 修复后 |
|---|---|---|
char[] 数量 |
831 万 | 220 万 |
String 数量 |
614 万 | 118 万 |
| 堆中字符串占比 | 60%+ | 18% |
| FullGC 间隔 | 32 min | 6h+ |
附:完整命令清单
# 1. 导出堆
jmap -dump:live,format=b,file=/tmp/heap.hprof <pid>
# 2. MAT 调参(MemoryAnalyzer.ini)
-Xmx6g
-XX:-UseGCOverheadLimit
# 3. MAT OQL 查询(按长度分布)
SELECT s.value.length AS len, COUNT(*) AS cnt
FROM java.lang.String s GROUP BY len ORDER BY cnt DESC;
# 4. MAT OQL 查询(查内容)
SELECT toString(s) FROM java.lang.String s
WHERE s.value.length = 248 LIMIT 10;
# 5. MAT OQL 查询(查来源追溯)
SELECT * FROM java.lang.String s
WHERE toString(s) LIKE "%PROCESSING%" AND s.value.length > 100;
# 6. Maven 依赖(Caffeine 缓存)
# <dependency>
# <groupId>com.github.ben-manes.caffeine</groupId>
# <artifactId>caffeine</artifactId>
# <version>3.1.8</version>
# </dependency>
下篇我们聊 CMS 老年代碎片化导致的 Promotion Failed——和字符串泄漏一样,它也是 FullGC 拉警报但方向完全不同的另一个岔路。排查思路不是 OQL,而是GC 日志中的晋升统计。
📺 公众号「Ai拆代码的曹操」 🌟 知识星球「Ai拆代码的曹操」


