
Effect-ts 预备课:理解 opencode 的编程基石
叙事角色:首席架构师 | 情绪曲线:好奇 → 原来如此 → 还能这样? 首席架构师 — 带读者站在作者视角,理解每个模块的设计意图与权衡 本文是 series-opencode-deconstruction 系列的第 3 篇
如果你打开 opencode 的源码,随便挑一个文件看,大概率会看到这行导入:
import { Effect, Layer, Context, Schema } from "effect"
effect 不是 Node.js 原生库,它是一个独立的 TypeScript 函数式编程框架——Effect-ts。在 opencode 项目中,911 个 TypeScript 文件导入了 effect,占了整个代码库的绝大部分。Effect-ts 不是 opencode 的一个"模块"或"工具库",它是整座大厦的钢筋混凝土。
但 Effect-ts 的学习曲线出了名的陡峭。它的概念栈从 Effect<A, E, R> 三元组到 Layer 依赖注入,再到 Scope / ScopedCache / ManagedRuntime,层层嵌套。如果你是第一次接触,看源码时可能连 yield* 是什么意思都要想半天。
本文不会教你 Effect-ts 的全部 API——那需要一本书。但读完这篇,你再看 opencode 的源码,至少能认出四个核心模式,知道它们各自解决什么问题。
【问题】没有 Effect-ts 会怎样
我们先看一个很常见的场景:查询用户信息,然后返回给调用方。
Promise 的三大短板
如果没有 Effect-ts,你会这样写:
async function findUser(id: string): Promise<User> {
const db = await getDatabase()
const rows = await db.query("SELECT * FROM users WHERE id = ?", [id])
return rows[0]
}
简洁易懂。但加几个需求后,Promise 的三块短板就会暴露:
短板一:错误类型丢失。 db.query() 可能抛"连接超时"或"语法错误",但在 Promise 的世界里,catch 到的永远是 unknown。你只能用 instanceof 运行时检查——编译器不会帮你检查是否遗漏了某种错误类型。
短板二:取消不安全和资源泄漏。 用户按 Ctrl+C 时,Promise 不会自动释放数据库连接。你需要手动介入 AbortController,而 AbortController 是一个传染性极强的机制——所有中间函数都得透传 signal 参数。
短板三:依赖不可追踪。 findUser 依赖 getDatabase(),但这个依赖在函数签名中完全不可见。测试时必须 mock 全局模块或构造函数注入——没有任何编译期保障说你提供的 mock 是否正确。
下图左侧展示了 Promise 世界的这三个问题,右侧是 Effect-ts 的解决方案:
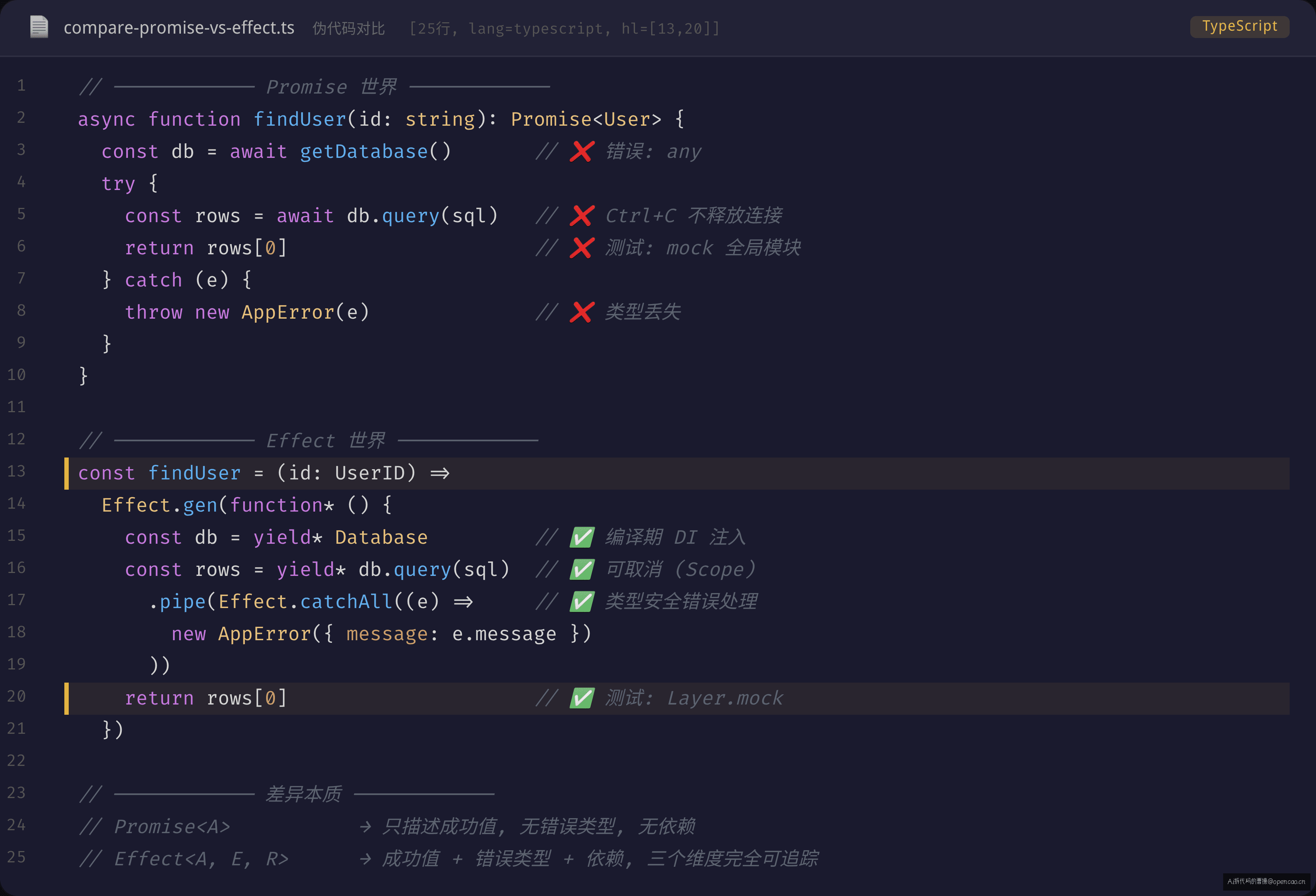
Effect 的三元组方案
Effect-ts 用一个类型同时表达了前文提到的三个维度:
Effect<User, DatabaseError | QueryError, Database>
这个三元组不是一个结构体——它是一个类型级别的契约。每个类型参数解决一块 Promise 的短板:
User(第一参数):成功时拿到的值——等价于Promise<User>里的UserDatabaseError | QueryError(第二参数):可能失败的所有类型——编译器保证你覆盖了每一种错误路径Database(第三参数):这个 Effect 依赖哪些 Service——Effect 运行时按这个签名去容器里找实现
你可以把它理解成"Promise + instanceof + 构造函数参数"三合一的版本,区别是这三者在类型层面绑定成了一个整体。改动任何一个维度,编译器都会告知你所有受影响的代码路径。
下图用流程图对比了同一个"查询用户"任务在两个世界中的完整路径:
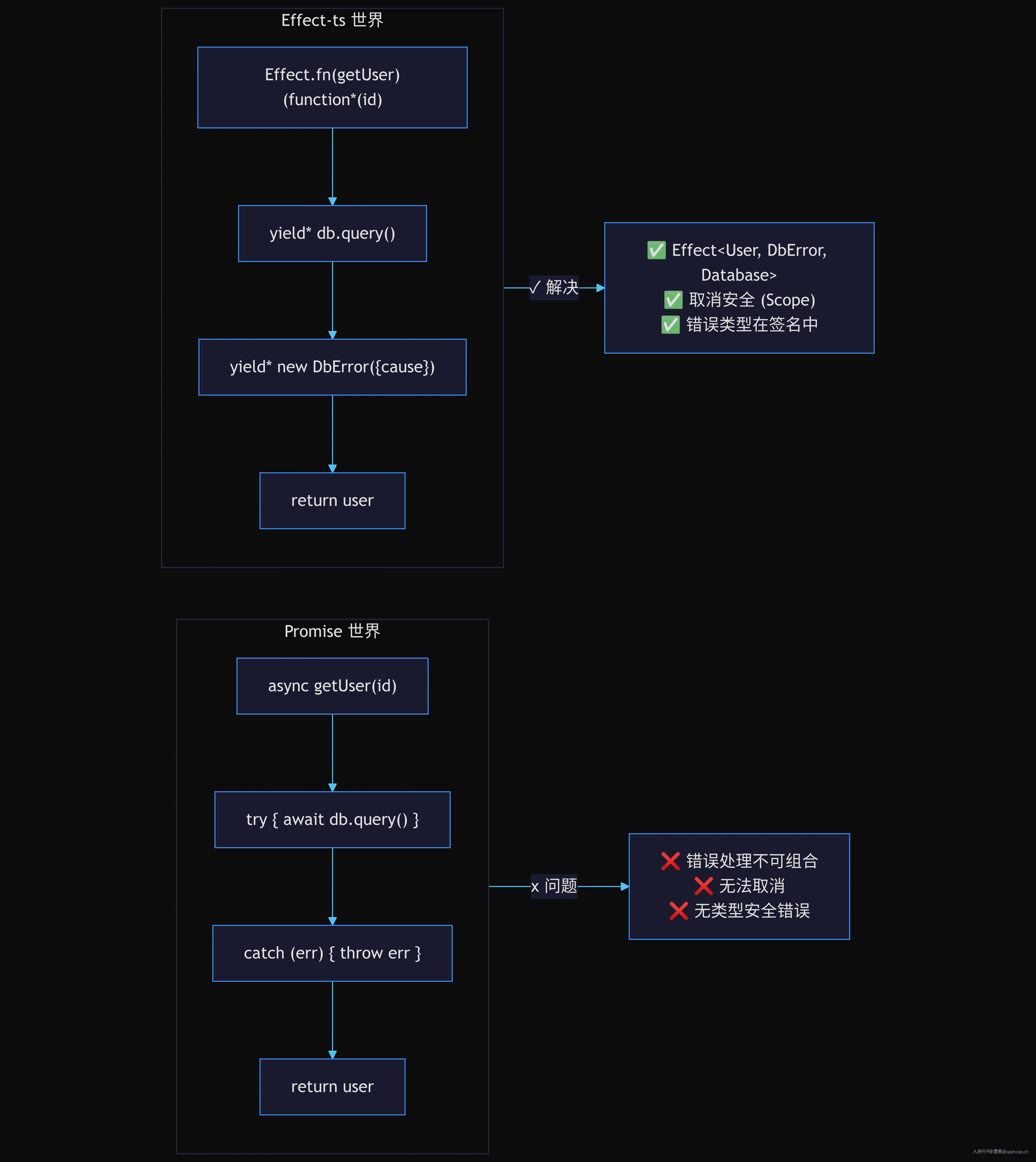
yield* 是 Effect-ts 版的 await,但存在一个本质差异。
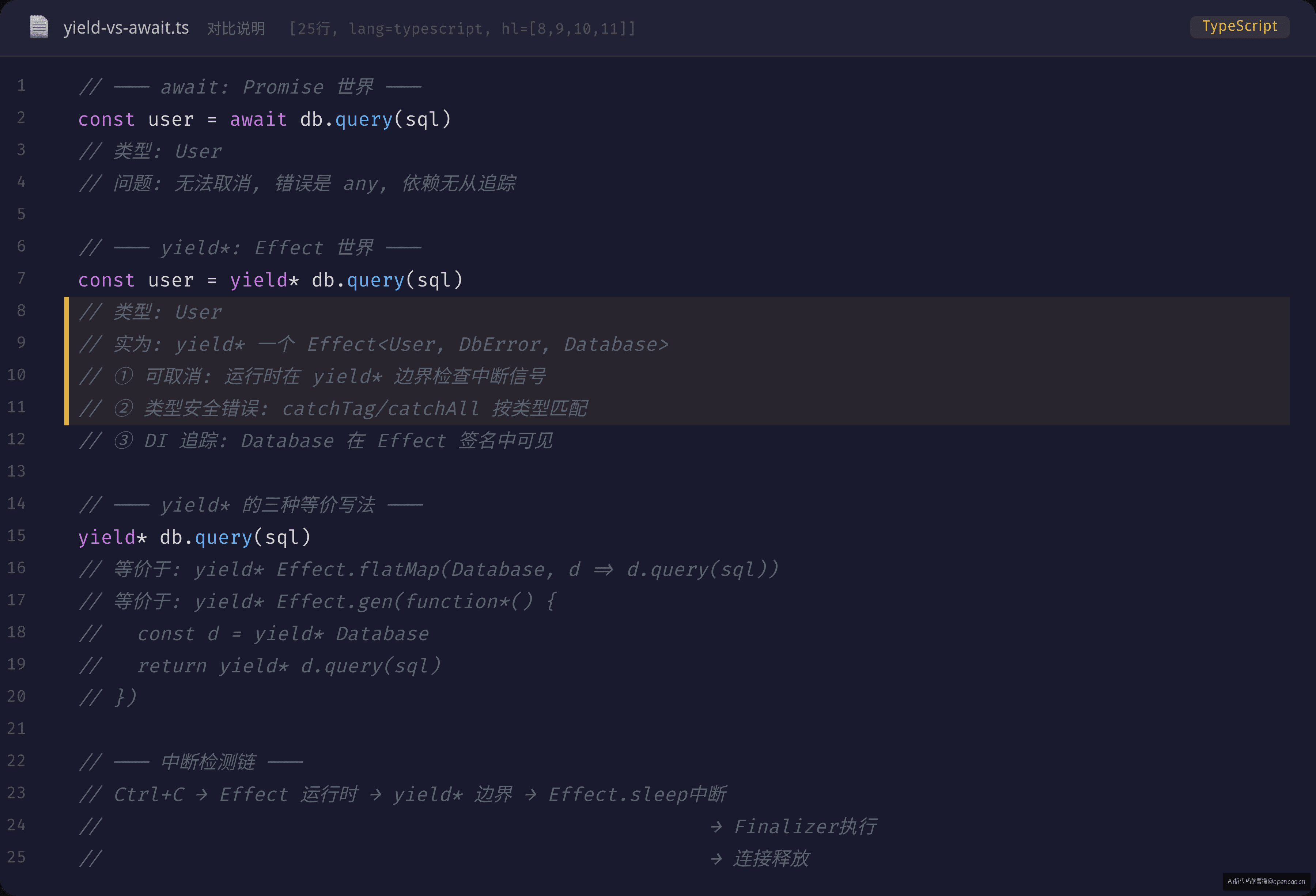
yield* 与 await 的本质差异
从视觉上看,yield* 和 await 非常像:
// await: 暂停直到 Promise 完成
const user = await fetchUser(id)
// yield*: 暂停直到 Effect 完成
const user = yield* fetchUser(id)
但 yield* 比 await 多做了一件关键的事:每次 yield* 都是一个 Effect 运行时调度点。
当用户按 Ctrl+C 时,Effect 运行时会在这个调度点检查中断信号。如果检测到中断,运行时会自动跳过后续的 Effect 并执行所有注册的 Finalizer(释放连接、关闭文件等)。这个机制不需要你在业务代码中传递任何 signal 参数——它内嵌在运行时中。
更深一层的区别是 yield* 的语义精确性。在 Promise 中:
await db.query(sql)
这个 await 拿到的是 User 类型。但 db.query() 可能失败——不成功的路径被掩盖在 Promise 的类型系统之外了。而在 Effect 中:
const user = yield* db.query(sql)
这个 yield* 不是简单地从 Promise 中取值——它是从 Effect<User, DbError, Database> 中解构出 User,同时把错误路径和依赖路径暴露在类型签名中。
【设计】三个核心抽象
Effect-ts 的概念多,但在 opencode 中真正高频使用的只有三个。掌握了它们,就能看懂 90% 的业务逻辑。
Schema.Class — 数据验证 + 品牌类型
Schema 的双重身份:编译时 + 运行时
opencode 中几乎所有面向外部的数据结构都用 Schema.Class 定义:
// packages/stats/core/src/config.ts
export class AppConfigValue extends Schema.Class<AppConfigValue>("AppConfigValue")({
stage: Schema.NonEmptyString,
publicUrl: Schema.NonEmptyString,
}) {}
这一行同时定义了两个东西:
<AppConfigValue>(尖括号):TypeScript 类型参数,自引用——extends Schema.Class<AppConfigValue>意味着这个类的实例类型就是AppConfigValue本身。编译器用这个类型做检查。("AppConfigValue")(括号里的字符串):运行时的标识符。Schema 在验证失败时会在错误消息中用这个名字指明是哪个数据出错。
为什么要两个名字?因为 TypeScript 类型在编译后不存在了。运行时需要一个字符串来标识"验证出错的是哪个结构"。不常写 Schema 的人容易卡在这个 <T>("T") 双写模式上。
Schema.NonEmptyString 不是普通的 string——它在 Schema.String 的基础上加了一个品牌标记(Brand)。这个标记同时影响编译时和运行时:编译时阻止你把普通字符串赋值给这个字段,运行时在校验时额外检查 .trim().length > 0。
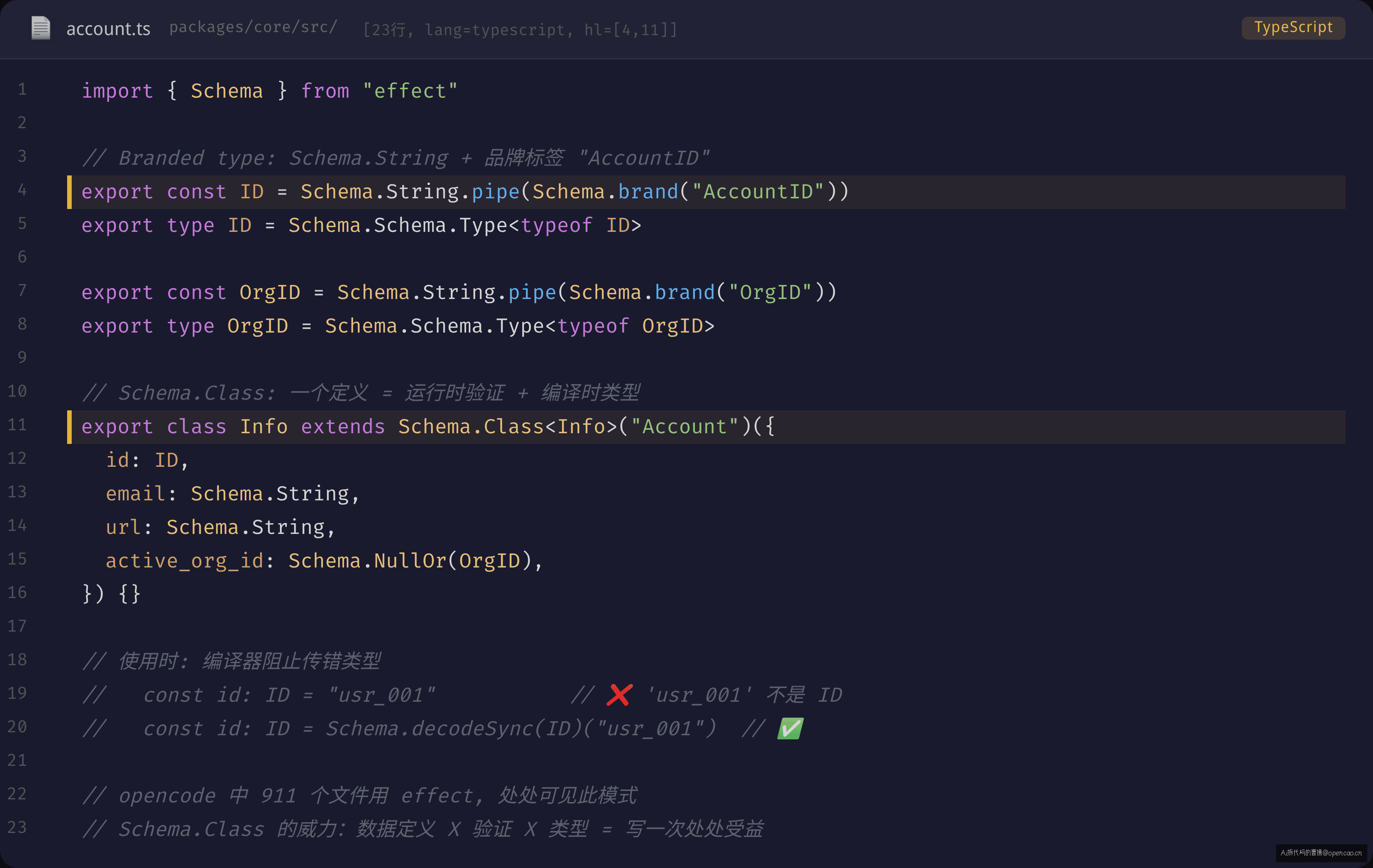
品牌类型:编译器的栅栏
// packages/core/src/account.ts
export const ID = Schema.String.pipe(Schema.brand("AccountID"))
export type ID = Schema.Schema.Type<typeof ID>
export class Info extends Schema.Class<Info>("Account")({
id: ID, // 编译器阻止传普通 string
email: Schema.String,
url: Schema.String,
}) {}
Schema.String.pipe(Schema.brand("AccountID")) 创建了一个品牌类型。如果你试图这样写:
function createInfo(id: string) {
return new Info({ id, email: "a@b.com", url: "" })
// ^^ ❌ Type 'string' is not assignable to type 'Brand<AccountID>'
}
编译器会报错,因为 string 不能赋给 Brand<"AccountID">。必须显式通过转换函数:
const safeID = Schema.decodeSync(ID)("usr_001") // ✅ 返回 ID 类型
new Info({ id: safeID, email: "a@b.com", url: "" }) // ✅
Schema.decodeSync 在运行时验证输入确实是有效的非空字符串,加上品牌标记后返回。如果传入 "",它会抛出一个 ParseError。
验证失败时
当数据来源不可靠(环境变量、API 请求体、数据库记录)时,使用 Schema.decodeUnknownSync:
// 假设环境变量: STAGE="", PUBLIC_URL="invalid-url"
const config = Schema.decodeUnknownSync(AppConfigValue)({
stage: "", // ❌ Schema.NonEmptyString: 验证失败
publicUrl: "not-a-url", // ❌ Schema.NonEmptyString: 验证失败
})
// ↳ 抛 ParseError: "AppConfigValue > stage: Expected a non-empty string"
抛出的 ParseError 是 Effect-ts 的内置错误类型,包含完整的错误路径链。在 opencode 中,这个错误通常通过 Effect.orDie 或者 catchTag 处理——前者表示"配置错误直接终止"(因为配置错了程序不该继续运行),后者表示"可以优雅降级"。
Schema + Config:从环境变量到类型的完整链路
把 Schema 和 Effect-ts 的 Config 模块组合起来,就得到 opencode 中最常见的配置读取模式:
// packages/stats/core/src/config.ts
const config = Config.all({
stage: Config.succeed(Resource.App.stage),
publicUrl: Config.string("PUBLIC_URL").pipe(
Config.withDefault("http://localhost:3000")
),
}).pipe(Config.map(decodeAppConfigValue))
// 此时 config 的类型: Config<AppConfigValue>
每一步的类型变化:
Config.string("PUBLIC_URL")→Config<string>(声明从环境变量PUBLIC_URL读字符串).pipe(Config.withDefault(...))→Config<string>(如果环境变量不存在,用默认值)Config.all({ ... })→Config<{ stage: string; publicUrl: string }>(合并两个配置).pipe(Config.map(decodeAppConfigValue))→Config<AppConfigValue>(把普通对象映射为 Schema 实例)
第 4 步的 Config.map(decodeAppConfigValue) 就是运行时验证的触发点。decodeAppConfigValue 会调用 Schema.decodeUnknownSync(AppConfigValue) 来校验最终值。
Context.Service — 标签即身份
传统方案的问题:反射
传统的 DI 框架(NestJS、Spring)用装饰器标注依赖关系:
@Injectable()
class UserService {
constructor(@Inject("DB") private db: Database) {}
}
这段代码在运行时依赖 reflect-metadata:Node.js 启动时 import "reflect-metadata" 会在全局 Reflect 对象上挂载 defineMetadata / getMetadata 方法。框架启动时扫描所有类,读取装饰器元数据,构建依赖图。这个过程涉及两次反射调用——一次读构造函数的参数类型元数据,一次根据 token 字符串查找对应的 provider。
副作用是:reflect-metadata 是一个全局副作用——一旦 import,它修改了 Reflect,所有模块共享这个被修改后的全局对象。而且只有等你运行到这行代码时,token 不匹配才会报错。
Effect-ts 的方案:标签
Effect-ts 不用装饰器,不用反射,用标签(Tag):
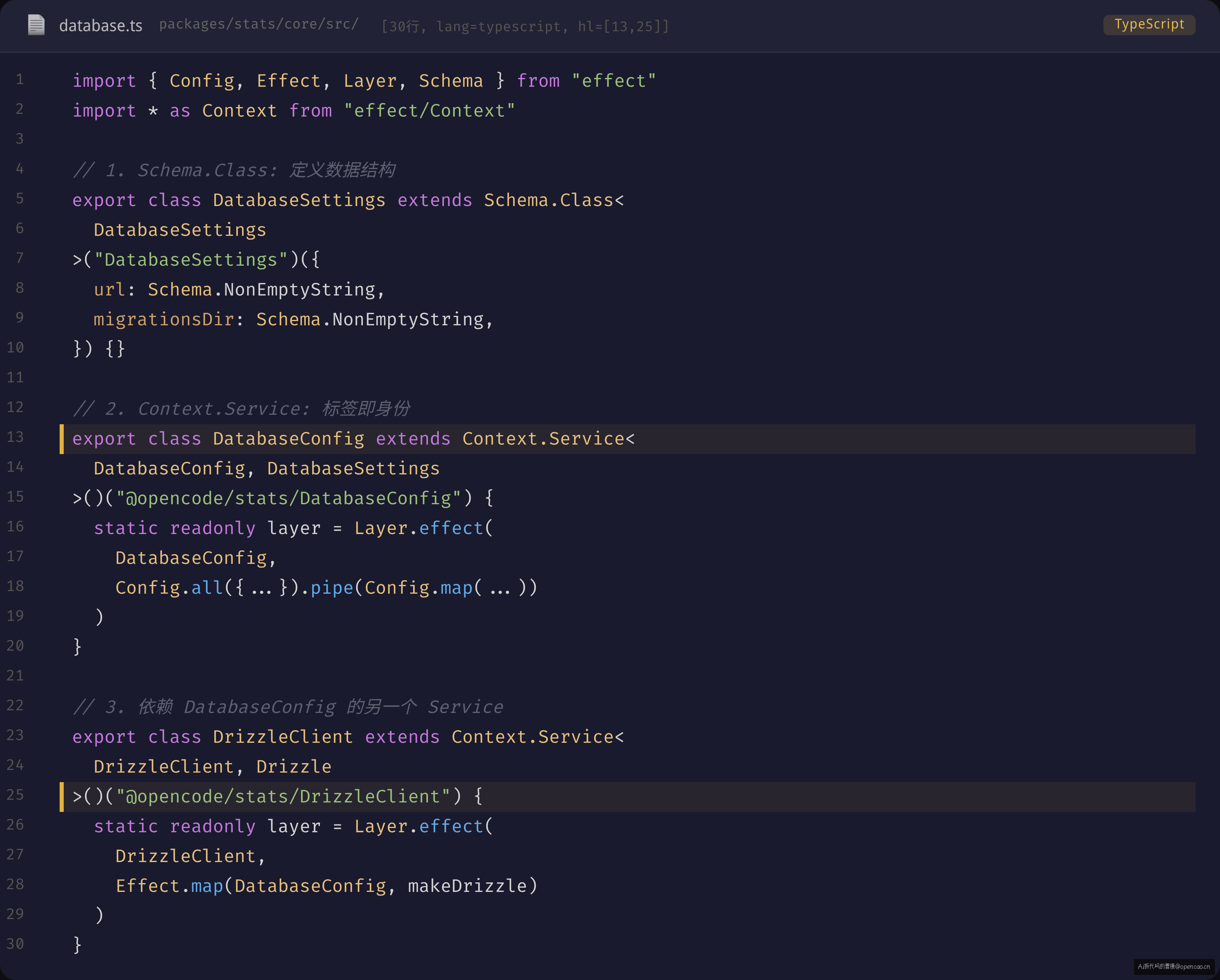
// packages/stats/core/src/database.ts
export class DatabaseConfig extends Context.Service<
DatabaseConfig, DatabaseSettings
>()("@opencode/stats/DatabaseConfig") {
static readonly layer = Layer.effect(DatabaseConfig, /* ... */)
}
export class DrizzleClient extends Context.Service<
DrizzleClient, Drizzle
>()("@opencode/stats/DrizzleClient") {
static readonly layer = Layer.effect(
DrizzleClient,
Effect.map(DatabaseConfig, makeDrizzle),
)
}
三个参数拆解:<Self, Value>()(tagString)
这一行是三重重载的调用链,很多人第一次看到会懵。从左到右拆:
| 部分 | 含义 | 什么时候用到 |
|---|---|---|
Context.Service<Self, Value>() |
泛型参数。Self = 这个类自己的类型。Value = 运行时实际拿到的值的类型 |
编译时:yield* 返回值类型推导 |
(tagString) |
带 () 的 IIFE——上一行返回一个函数,立刻调用。"@opencode/stats/DatabaseConfig" 是运行时查找的唯一键 |
运行时:容器中存的 key-value 对 |
具体到 DatabaseConfig 的例子:
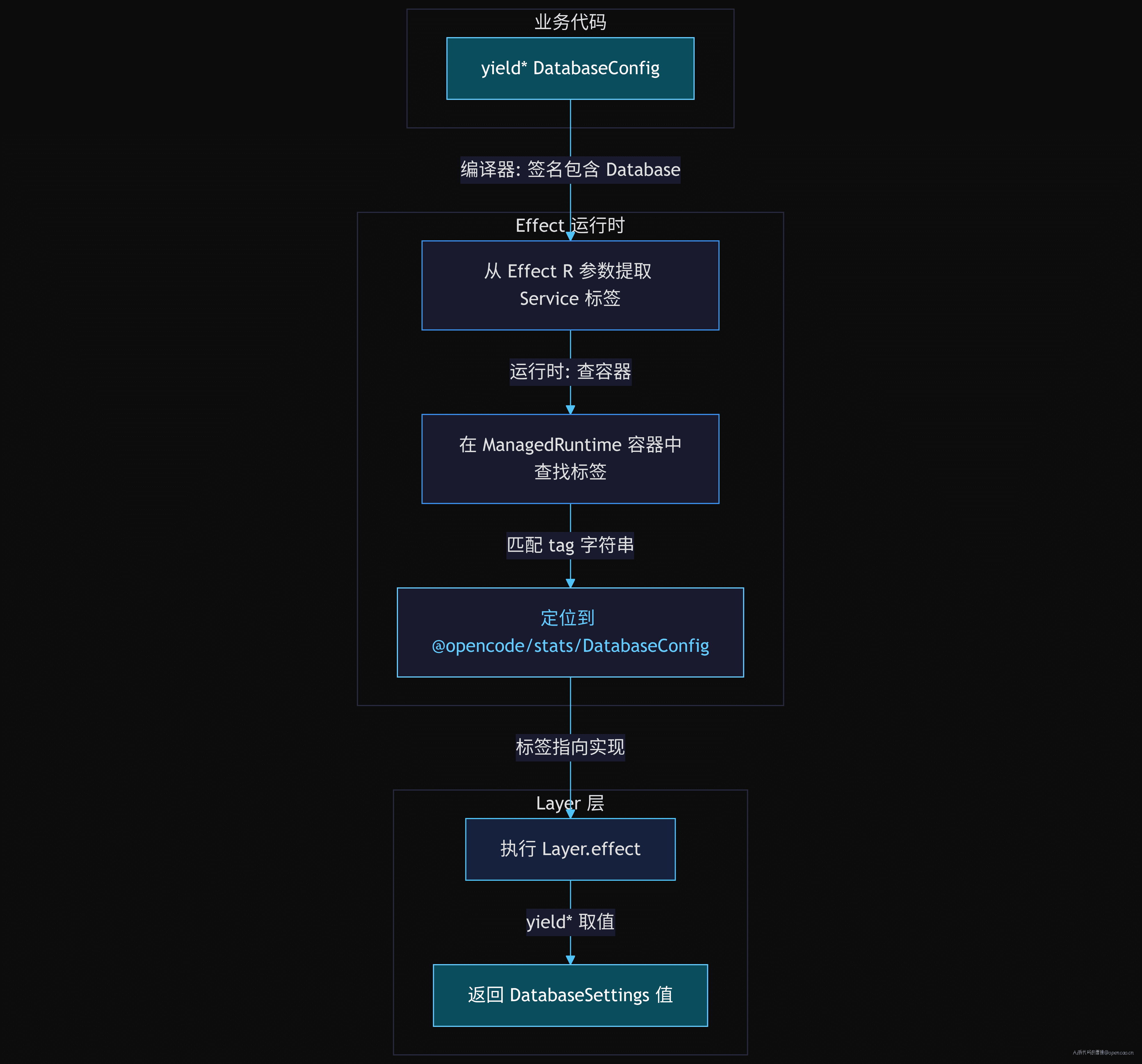
Self=DatabaseConfig:yield* DatabaseConfig返回的类型就是这个类的实例。因为类本身也充当了标签。Value=DatabaseSettings:运行时容器中实际存储的是一个DatabaseSettings值。yield* DatabaseConfig拿到的运行时的值就是这个。tagString="@opencode/stats/DatabaseConfig":容器是一个Map<string, any>结构。yield*实际上做的是container.get("@opencode/stats/DatabaseConfig")。
所以当你在业务代码中写 const config = yield* DatabaseConfig 时,编译器推导 config: DatabaseSettings,运行时从容器中根据 "@opencode/stats/DatabaseConfig" 字符串查找并返回之前通过 Layer.effect 绑定的值。
Context.Service vs Context.Tag
Effect-ts 实际上提供两个级别的标签 API:
Context.Tag<Value>()(tagString):低阶 API。只包装值类型,不提供layer等便捷方法。在 opencode 中仍然出现(尤其 stats 包中),但较少。Context.Service<Self, Value>()(tagString):高阶 API。继承Context.Tag并额外提供了Service.of()工厂方法和与Layer.effect的便捷配合。opencode 统一用这个。
本质上,Context.Service<Self, Value> 可以理解为一个「带自引用类型的 Context.Tag」。开头的双名 <AppConfigValue>("AppConfigValue") 模式同理。
没有反射的实际收益
Effect-ts 不依赖 reflect-metadata 带来的不是"优雅",而是三个具体的工程收益:
- 加载顺序无关:装饰器方案中 provider 的声明顺序影响依赖图构建。Effect-ts 的 Layer 组合是纯函数,顺序不影响正确性。
- 没有全局副作用:
reflect-metadata的import "reflect-metadata"是一个全局修改。Effect-ts 的 Context 是纯数据结构,不修改任何全局状态。 - Tree-shaking 可行:装饰器的
@Injectable()在编译时产生不可静态分析的元数据写入调用。Effect-ts 的Context.Service只是一个类继承——没有被引用的 Layer 会被 tsc 标记为 unused。
下图展示了 yield* DatabaseConfig 这句代码在 Effect 运行时中的完整查找流程——从标签到实现,再到值:
Layer — 可组合的 DI
Layer 本身的泛型:也是一个三元组
Layer 自己也有三个类型参数,和 Effect<A, E, R> 结构一致:
Layer.Layer<A, E, R>
A = 产出的服务类型(这个 Layer 提供了什么)
E = 初始化过程中可能发生的错误
R = 这个 Layer 依赖哪些其他 Service
举例:
// 这个 Layer 产出 DrizzleClient,不依赖其他服务(never)
Layer.Layer<DrizzleClient, never, never>
// 这个 Layer 产出 DatabaseConfig,可能失败,不依赖其他服务
Layer.Layer<DatabaseConfig, never, never>
// 这个 Layer 产出 DrizzleClient,依赖 DatabaseConfig 先就绪
Layer.Layer<DrizzleClient, never, DatabaseConfig>
第三个类型参数 R 是 Layer 组合的核心机制——当 R 不为 never 时,这个 Layer 在被创建之前,Effect 运行时必须先解析 R 中列出的所有依赖。这个解析过程是递归的、编译期可见的。
三种创建方式的选型
| 方式 | 签名 | 适用场景 | 执行时机 | opencode 案例 |
|---|---|---|---|---|
Layer.succeed(Tag, value) |
同步纯值 | 没有初始化逻辑,直接给一个值 | ManagedRuntime.make 时立即执行 |
很少——因为即使"纯值"也可能来自配置 |
Layer.sync(Tag, factory) |
同步工厂 () => V |
有轻量初始化,不涉及 Effect | 被使用时延迟执行 | Logger 等没有 I/O 的服务 |
Layer.effect(Tag, effect) |
Effect 工厂 Effect<V, E, R> |
需要异步/可能有依赖的初始化 | 被使用时执行,R 中的依赖先于它就绪 | DatabaseConfig、DrizzleClient、Athena |
opencode 中绝大多数 Layer 用 Layer.effect,因为初始化通常涉及读取配置或建立连接。Layer.sync 用于纯计算型服务。Layer.succeed 很少单独出现——它被 Layer.mergeAll 等组合器内部使用。
依赖链可视化:provide 的数据流
Layer 有三个类型参数:Layer.Layer<产出(A), 错误(E), 依赖(R)>。Layer.provide 的作用是:用一个 Layer 的产出,去填另一个 Layer 的依赖,填完之后被填的那个 Layer 就不再需要这个依赖了。
用 DrizzleClient 的例子拆开看:
// DatabaseConfig.layer 的签名
Layer.Layer<DatabaseSettings, never, never>
// ↑ 产出 DatabaseSettings ↑ 不需要任何依赖
// DrizzleClient.layer 的签名
Layer.Layer<DrizzleClient, never, DatabaseConfig>
// ↑ 产出 DrizzleClient ↑ 依赖 DatabaseConfig
DrizzleClient.layer 的依赖 R = DatabaseConfig——它需要一个 DatabaseConfig 类型的 Service 在它之前初始化。DatabaseConfig.layer 的产出 A = DatabaseSettings——它的产出正好匹配 DrizzleClient 需要的依赖。
把它们连起来:
const fullLayer = DrizzleClient.layer.pipe(
Layer.provide(DatabaseConfig.layer)
)
// fullLayer 的签名:
// Layer.Layer<DrizzleClient, never, never>
// ↑ 产出不变 ↑ 依赖变 never —— DatabaseConfig 已被满足
Layer.provide 的效果是:被 provide 的 Layer 从依赖(R)中移除,它的产出(A)成为供给。 如果 DrizzleClient.layer 除了 DatabaseConfig 还依赖其他 Service(比如 Logger),provide(DatabaseConfig.layer) 只会移除 DatabaseConfig,Logger 仍留在 R 中。
当最终的 Layer 的 R = never 时,ManagedRuntime.make 才能安全地执行它——因为所有依赖都已注册完毕。
下图展示了 provide 前后的类型变化:

mergeAll vs provideMerge
这两个是 opencode 最常用的组合方式,写法非常像,语义不同:
Layer.mergeAll(A, B, C)——A、B、C 是三个并列的、互不依赖的 Service。合并成一个同时产出 A+B+C 的大 Layer。
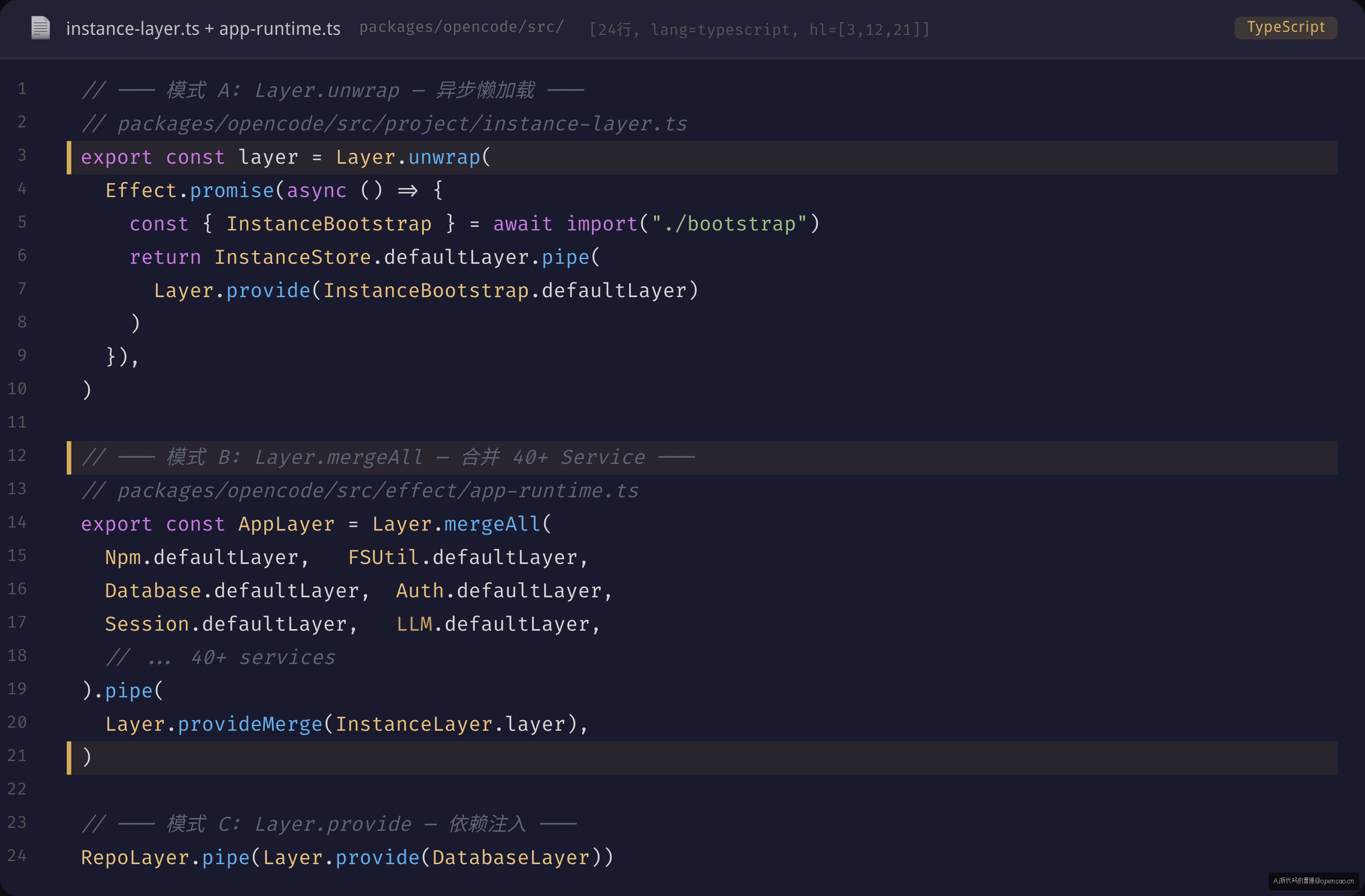
export const AppLayer = Layer.mergeAll(
Npm.defaultLayer, // 产出 Npm
FSUtil.defaultLayer, // 产出 FSUtil
Database.defaultLayer, // 产出 Database
Auth.defaultLayer, // 产出 Auth
// ... 40+ services
).pipe(
Layer.provideMerge(InstanceLayer.layer), // 追加 InstanceLayer 到产出集合
Layer.provideMerge(Ripgrep.defaultLayer),
)
Layer.provideMerge(B)——B 的产出被注入到 A 的 R(依赖)中,同时 B 也成为合并后 Layer 的产出之一。
AppLayer 的构建过程是:先用 mergeAll 把 40+ 并列 Service 合并,再用 provideMerge 把那些依赖了其他 Service 的 Layer 接入。InstanceLayer.layer 依赖 InstanceBootstrap,所以不能直接 mergeAll——必须先确保 InstanceBootstrap 就绪再 provide。
下图展示了这三种组合模式在 opencode 中的具体写法:
三个抽象的协作关系
把前面三节串起来,工作流程是这样的:
Schema.Class 定义数据格式
↓ Context.Service 为数据贴上服务标签
↓ Layer 把标签绑定到具体实现
↓ ManagedRuntime 把 Layer 跑起来
底层的数据(Schema.Class)通过标签(Context.Service)被暴露给上层;Layer 将标签映射到实现;最后 ManagedRuntime.make(AppLayer) 将所有 Layer 组合成一个可执行的运行时。从外部看,你只需要 yield* ServiceTag,剩下的全部由运行时自动完成。
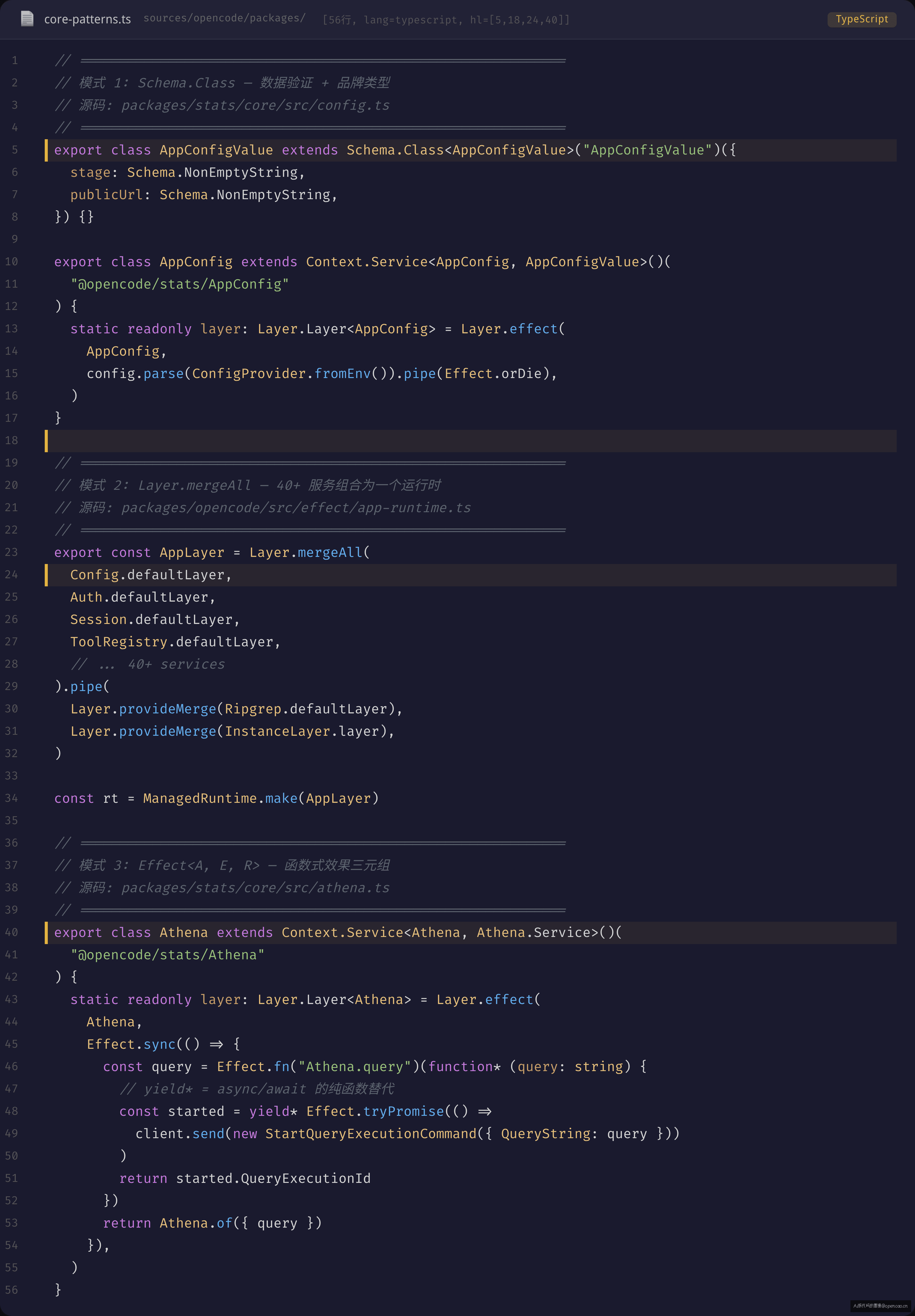
【源码】Effect.fn 命名生成器模式
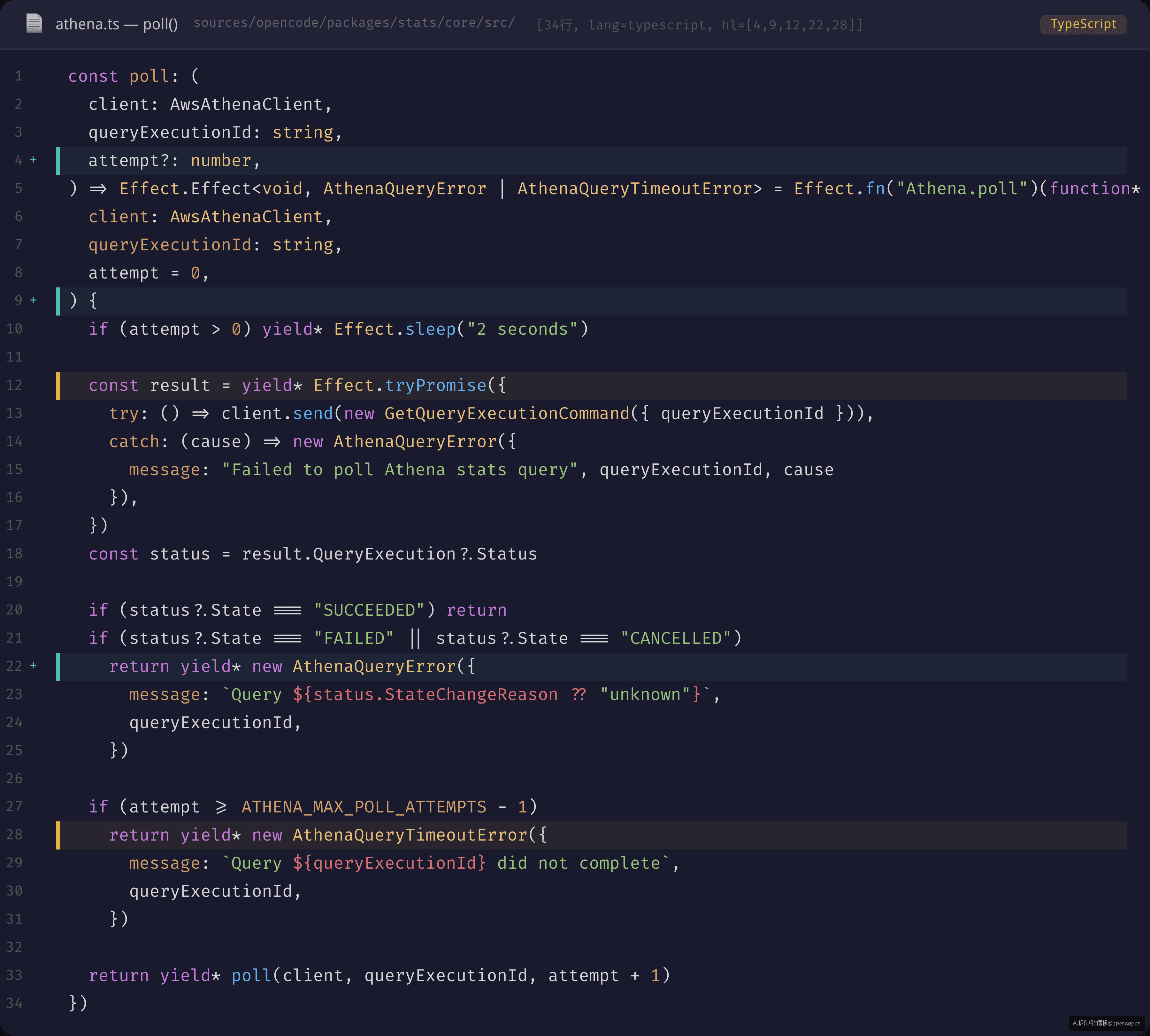
来看一段在 opencode 中出现了 1,137 次的模式——Effect.fn 命名生成器。
命名追踪:Effect.fn
// packages/stats/core/src/athena.ts
const poll = Effect.fn("Athena.poll")(function* (
client: AwsAthenaClient,
queryExecutionId: string,
attempt = 0,
) {
if (attempt > 0) yield* Effect.sleep("2 seconds")
const result = yield* Effect.tryPromise({
try: () => client.send(new GetQueryExecutionCommand({ queryExecutionId })),
catch: (cause) => new AthenaQueryError({ message: "Failed to poll", queryExecutionId, cause }),
})
if (result.QueryExecution?.Status?.State === "SUCCEEDED") return
if (result.QueryExecution?.Status?.State === "FAILED") {
return yield* new AthenaQueryError({ message: `Query failed: ...`, queryExecutionId })
}
if (attempt >= 60) {
return yield* new AthenaQueryTimeoutError({ message: `Query did not complete`, queryExecutionId })
}
return yield* poll(client, queryExecutionId, attempt + 1)
})
Effect.fn("Athena.poll") 给这个 Effect 一个可读名称。在追踪和日志中,你可以看到 Athena.poll 出现在调用链中——这在调试 40+ Service 的复杂交互时非常有用。
yield* Effect.sleep("2 seconds") 和 await setTimeout() 的区别前文已经讨论过——关键点在于可取消。如果用户在轮询过程中按 Ctrl+C,这个 sleep 不会"泄漏"到超时触发。
yield* Effect.tryPromise(...) 把第三方 Promise 桥接到 Effect 世界。catch 返回 typed error(AthenaQueryError),失联路径被类型系统捕获。
yield* new AthenaQueryError(...):在 Effect 中,throw 被 yield* new ErrorType(...) 取代。这不是 throw——这是 Effect.fail 的语法糖。调用方可以在 Effect<Data, Error> 的第二个类型参数里看到所有可能的错误。
递归:yield* poll(client, queryExecutionId, attempt + 1) 是递归 Effect。每次递归调用都经过 Effect 运行时的调度,运行时可以在递归边界做中断检测。
【权衡】为什么是 Effect-ts
任何技术选型都有代价。下面是五个维度的系统性对比:
五维对比
| 对比维度 | Effect-ts | NestJS | 裸 async/await |
|---|---|---|---|
| 运行时依赖 | 0 反射,纯静态分析 | 反射 + 装饰器元数据 | 无依赖,手动管理 |
| 错误处理 | Effect |
ExceptionFilter 运行时捕获 | throw/try-catch 无类型约束 |
| 取消安全 | Scope + Finalizer 编译期保障 | 手动 + 中间件易遗漏 | AbortController 传染性 |
| DI 组合 | Layer.mergeAll 一行合并 40+ Service | @Module 装饰器声明 | 手动传参无容器 |
| 学习曲线 | 陡峭,函数式思维 | 中等,装饰器熟悉 | 低,标准语法 |
选 Effect-ts 的核心原因不是"函数式编程更优雅"——而是 0 运行时反射 + 编译期 DI 约束。
NestJS 的装饰器方案在运行时依赖 reflect-metadata——通过反射读取装饰器元数据来构建依赖图。这意味着:
- 反射调用在运行时发生——如果你写错了
@Inject()的 token,只有运行到那行才知道 reflect-metadata是一个全局副作用——一旦 import,它修改了全局的Reflect对象- Tree-shaking 困难——装饰器在编译时不可静态分析,打包工具无法确定哪些依赖没被使用
Effect-ts 的类型层面方案把这些问题消灭在编译期:类型错误编译时不通过,不产生运行时元数据开销,没被引用的 Layer 会被 tsc 标记为 unused import。
下图从五个维度展示了三个方案的具体差异:
不过,Effect-ts 的陡峭学习曲线是一个真实的成本。以下场景中这个成本可能超过收益:脚本或一次性任务、页面渲染为主的纯前端应用、团队无人熟悉函数式编程(新人需要 2-4 周才能产出高效代码)。opencode 的情况刚好相反——40+ 个 Service 互相依赖、需要取消安全、需要类型安全的错误处理——Effect-ts 的优势完全发挥。
【锚点】下次你写"需要注入一个 Service"时
与其记 API,不如记决策框架。
四步框架 + 三个自问题
当你需要一个 Service 时:
1. Schema.Class — 定义数据格式
→ 编译时类型 + 运行时验证。写一次,两处受益。
2. Context.Service — 声明标签
→ 标签即身份,无 @Inject,无 reflect-metadata。
3. Layer.effect / Layer.succeed — 绑定实现
→ 一个 Layer 完成 Tag → Value 的映射。
4. Layer.mergeAll + ManagedRuntime.make — 组合运行
→ 几十个 Service 一行合并,零反射。
每次设计 DI 方案时,再用三个问题检验:
- "数据和行为能拆开吗?" → Schema.Class 定义数据,Context.Service 定义行为接口
- "依赖需要在编译期保证吗?" → Effect-ts 的答案是"是的"——
yield*编译不过是忘提供 Service 的信号 - "Scope 谁管理?" → 资源型 Service 用
Layer.effect+Effect.addFinalizer或ScopedCache托管

学会了这四个模式和三个问题,你再回头看 opencode 的源码——不管是 instance-state.ts 里的 ScopedCache,还是 athena.ts 里的 Effect.fn,还是 app-runtime.ts 里那个 48 个 Service 的 Layer.mergeAll——应该都不会觉得陌生了。
📖 全文带完整截图和源码引用 🔗 个人博客:https://opencao.cn 📺 公众号:Ai拆代码的曹操 🌟 知识星球:Ai拆代码的曹操


