
yargs CLI 构建:从 index.ts 到所有子命令
拆解 opencode 源码 · 第二章 CLI 入口与启动流程 · 首篇
如果你要设计一个 AI Coding Agent 的 CLI 入口——用户输入 opencode run、opencode serve、opencode upgrade 等 20+ 条命令——你会怎么组织这些代码?
一个直观的想法是:解析 process.argv,然后一个 switch-case 分发到不同的 handler,每条命令各写各的参数解析。
问题是:当你有 20+ 条命令、每条命令有 5-15 个可选参数、部分命令需要 Effect-ts 运行时、部分命令不需要、部分命令需要在执行前后加载和释放项目上下文——switch-case 在第 5 条命令时就已经不可维护了。
opencode 的作者选择了一条看起来「重」但长期收益巨大的路:yargs(CLI 框架)+ effectCmd(Effect-ts 封装)双层架构,配置式命令路由 + 自动生命周期管理。
同一层问题,Claude Code 选择了类似的 yargs 方案,而 codex(早期 OpenAI 的 Coding Agent)选择了更轻量的 click(Python)—— 差异的本质是运行时的复杂度:opencode 的 Effect-ts 运行时需要命令级别的生命周期精细化控制,这直接推动了 effectCmd 这一层封装的诞生。
接下来我们逐篇深入 opencode 的实现:
- 02-01 yargs CLI 构建(本篇):index.ts 入口 → 20+ 子命令注册 → yargs + effectCmd 双层架构
- 02-02 bootstrap 初始化:config 加载 → plugin 发现 → Instance 创建 → 运行时就绪
- 02-03 run 命令全流程:从 opencode run 到 Agent Loop 启动的完整链路
【问题】20 条子命令的路由难题
naive 方案:switch-case 的崩溃曲线
先说结论:20+ 条命令、300+ 个参数选项、跨命令共享的中间件逻辑——这个复杂度已经超出了手写路由的维护阈值。
如果用手写 switch-case,代码会长这样:
const args = process.argv.slice(2)
const cmd = args[0]
switch (cmd) {
case 'run':
// 定义参数... 10+ 个 option
// 解析... 手写
// 校验... 手写
// 执行...
break
case 'serve':
// 再来一遍,但参数完全不同
break
// ... 20 个 case,每个 30-50 行
default:
console.log('Unknown command')
}
这套方案在 3 条命令时看起来没什么问题。但到了 20 条,每个 case 块里手写的参数定义和解析占了 70% 的代码量——而且这些代码高度重复:每条命令都有 --help、--version、描述文本、参数别名、类型校验、必填检查。如果哪天想「所有命令统一加一个 --verbose 标志」——你得改 20 个 case 块。
这里有个新手易踩的坑:参数解析比看上去难得多。--foo=bar 和 --foo bar 要不要都支持?-abc 是三个单字母标志还是一个多字母?-- 后面的参数怎么处理?opencode run "message with spaces" 引号谁处理?手写这些逻辑,每条命令多写 30 行只是起步。
更关键的是隐性的维护成本:新加一条命令需要复制粘贴整个 case 块结构,新人很容易漏掉某个全局选项(比如 --print-logs)的处理。用 yargs 的 middleware() 一次注册全局生效和手写 switch-case 的差异不是「20 行 vs 1 行代码」——而是「零思考成本 vs 每次都要记得」。
switch-case 的最大问题是违背了开闭原则:每加一条新命令,就要修改已有的路由代码。而 yargs 的 .command(Module) 模式——加一个新文件、写一行 .command()、永不改路由代码——这才是 CLI 入口层该有的扩展性。
这引出了真正的架构问题:yargs 帮我们解决了命令注册和参数解析,但每个命令的生命周期管理才是更棘手的问题(我们到「设计」节展开)。
真正的瓶颈不是路由,是参数解析和上下文注入
CLI 框架解决的问题远比「把命令名映射到 handler」要多。
看 opencode 的 RunCommand(sources/opencode/packages/opencode/src/cli/cmd/run.ts:122-240),它的 builder 定义了 20+ 个 option:
export const RunCommand = effectCmd({
command: "run [message..]",
builder: (yargs: Argv) =>
yargs
.positional("message", { describe: "message to send", type: "string", array: true })
.option("command", { describe: "the command to run", type: "string" })
.option("continue", { alias: ["c"], describe: "continue the last session", type: "boolean" })
.option("session", { alias: ["s"], describe: "session id to continue", type: "string" })
.option("fork", { describe: "fork the session before continuing", type: "boolean" })
.option("model", { alias: ["m"], describe: "model to use", type: "string" })
.option("interactive", { alias: ["i"], type: "boolean" })
// ... 还有 13+ 个 option
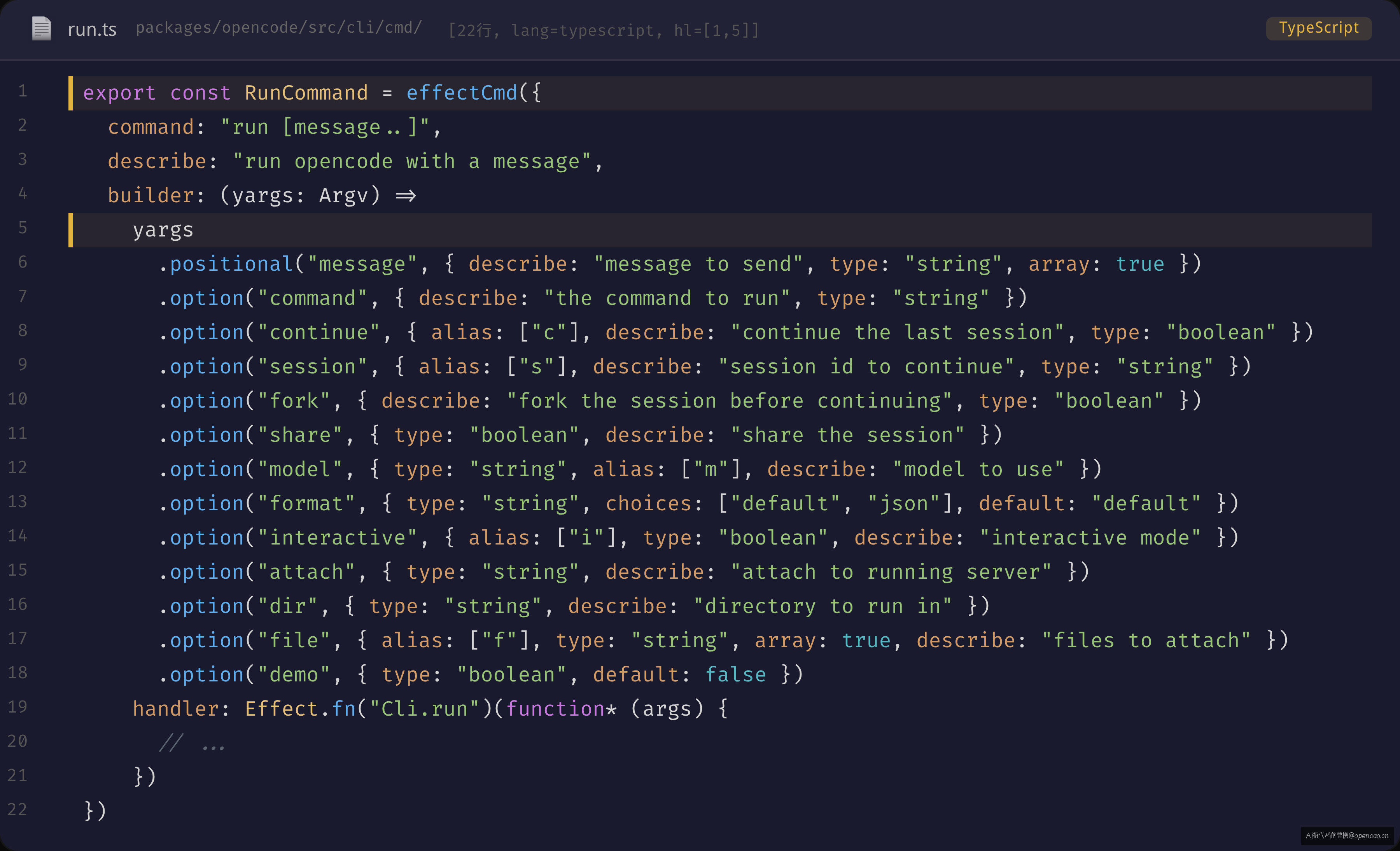
这些 option 中既有 type: "boolean" 的标志位,也有 type: "string" 的取值参数,还有 array: true 的可重复参数,以及 .positional() 定义的位置参数。如果手写解析,每条命令要写 50-100 行解析 + 校验代码。yargs 的链式调用把这件事压缩到了声明式的 30 行——而且类型安全的:每个 .option() 调用都会更新 Argv 的泛型参数,TypeScript 能在 handler 里推断出每个字段的类型。
但这里有个设计取舍:yargs 本身只做参数解析和命令路由,它不管 handler 执行前后的上下文注入。具体来说,run 命令在执行前需要加载 InstanceContext(项目配置、插件、运行时),执行后需要 dispose 它。如果 20+ 条命令的 handler 里都手写这段生命周期管理代码,那 switch-case 的维护问题只是换了个形式出现——每个 handler 开头 15 行一模一样。
所以 opencode 在 yargs 之上做了第二层封装——effectCmd——把上下文注入变成了一个声明式配置项。如果不用这个封装,每条需要 Instance 的命令都要手写 load → provide → dispose,20 条命令就是 300 行重复模板。effectCmd 用 1 行 instance: true/false 消灭了 15 行模板——这才是应对后续成本的关键设计。
【设计】yargs + effectCmd 双层架构
第一层:yargs CommandModule 契约
yargs 把一个 CLI 命令抽象为一个 CommandModule——这是一个 4 字段的接口契约:
type CommandModule = {
command: string // 命令名 + 参数模式,如 "run [message..]"
describe: string // 帮助文本
builder: (yargs) => Argv // 定义参数
handler: (args) => void // 执行逻辑
}
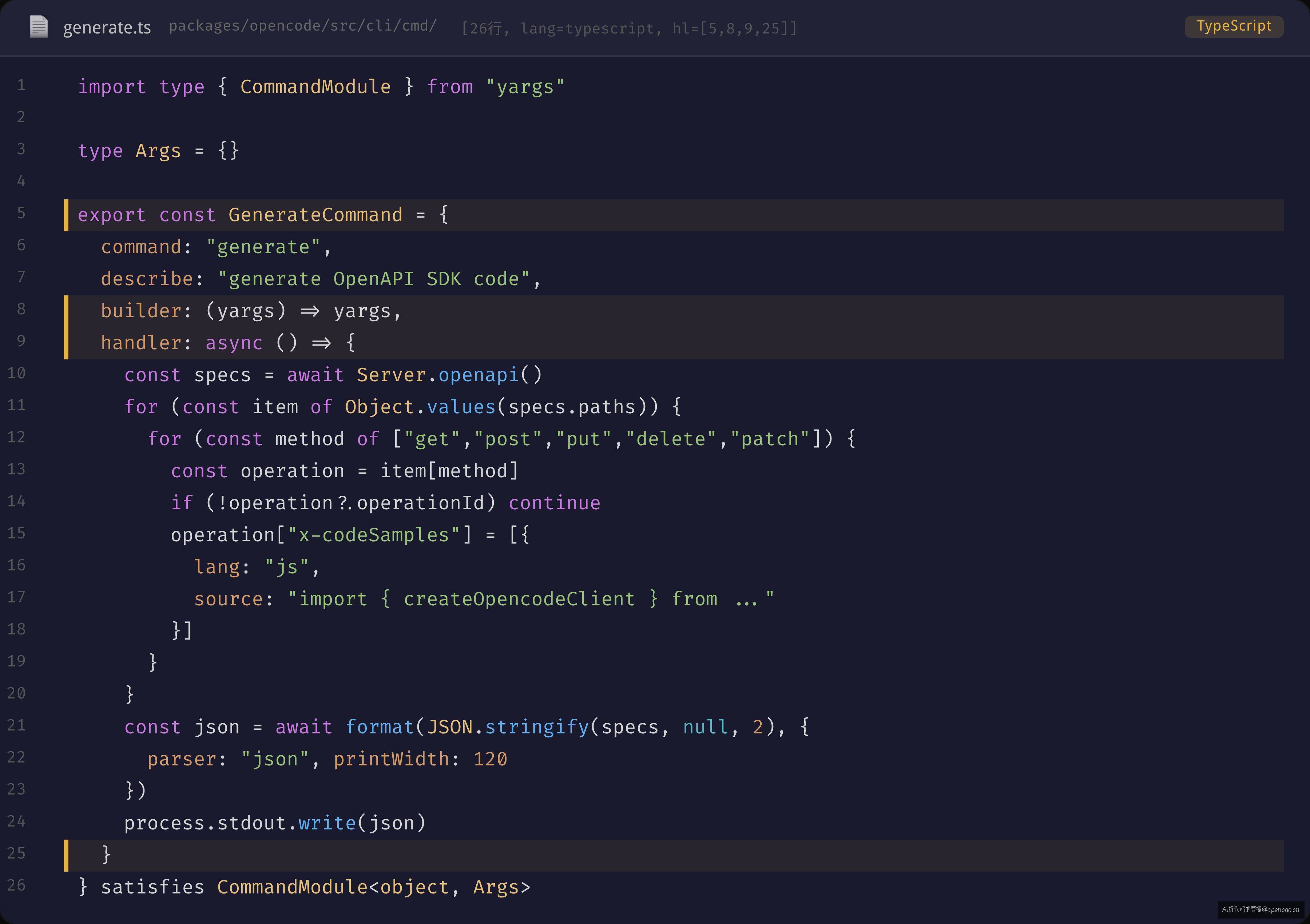
最简洁的例子是 GenerateCommand(sources/opencode/packages/opencode/src/cli/cmd/generate.ts):
export const GenerateCommand = {
command: "generate",
builder: (yargs) => yargs, // 无自定义参数,透传
handler: async () => { /* ... */ }, // async 风格,无 Effect
} satisfies CommandModule<object, Args>
注意 satisfies CommandModule——这是 TypeScript 4.9+ 的特性。它约束但不改变这个对象的字面量类型。效果是:如果你漏了 builder 或拼错了 command,TypeScript 在编译阶段就会报错。但如果你不需要复杂的类型推导,直接用对象字面量就行——不需要继承、不需要装饰器、不需要额外类。
这里有个新人不注意就会踩的坑:CommandModule<object, Args> 的第二个泛型参数是 handler 的 argv 类型。但如果你的 builder 有链式 .option() 调用,yargs 会自动推导出精确的 argv 类型——这时候 satisfies 比 as 更安全,因为它不会丢失 builder 推导出的类型信息。
更典型的 builder 用法是链式调用定义参数,看 UninstallCommand(sources/opencode/packages/opencode/src/cli/cmd/uninstall.ts:28):
builder: (yargs: Argv) =>
yargs
.option("keep-config", { alias: "c", type: "boolean", describe: "keep configuration files", default: false })
.option("force", { alias: "f", type: "boolean", describe: "skip confirmation prompts", default: false })
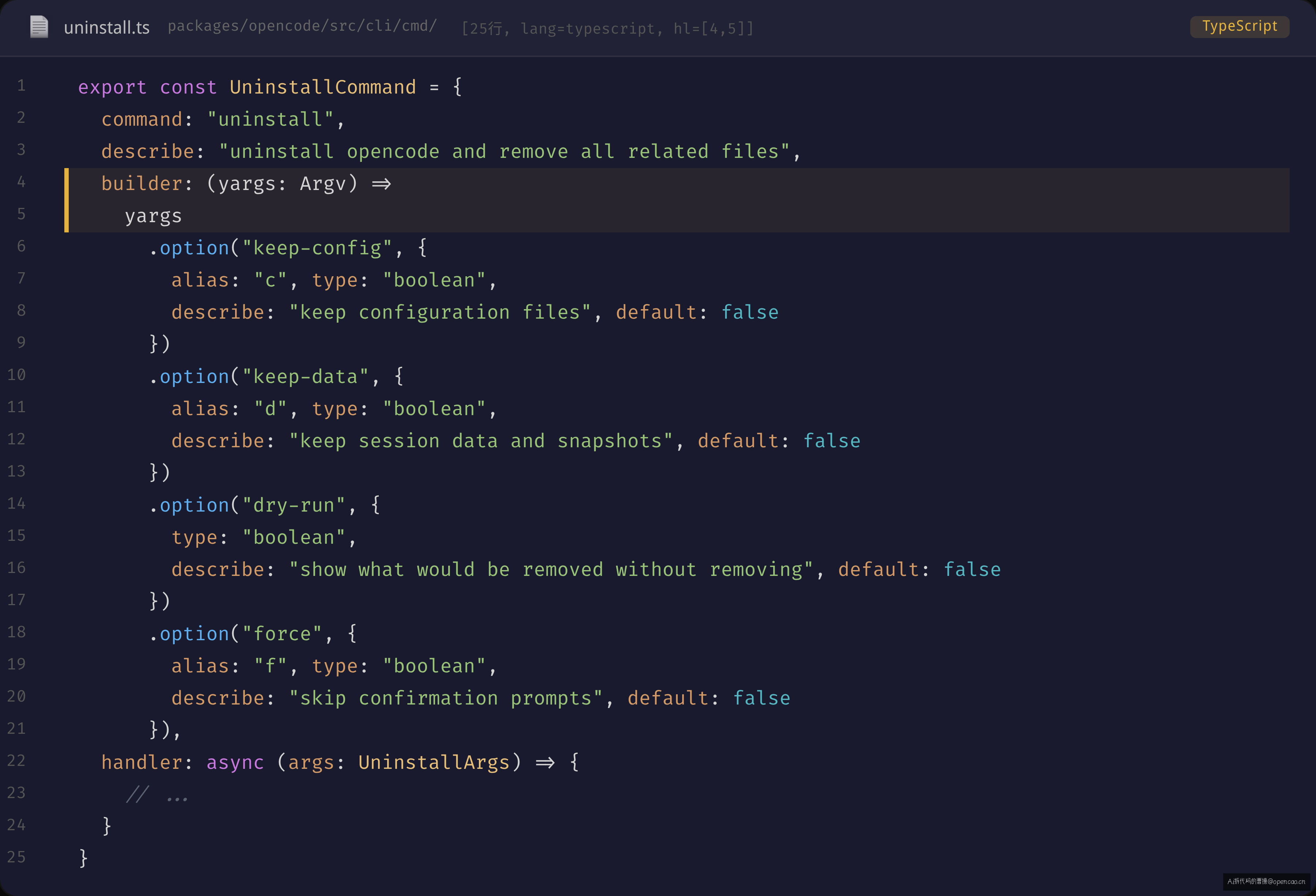
链式的设计意图很明确:参数定义即类型。每个 .option() 调用都返回一个新的 Argv<T> 类型,T 随着链式调用逐层累加。最终 handler 的 args 参数自动获得了所有 option 的精确类型——不需要额外的类型定义文件,不需要 as 断言。如果你在 .option("force", { type: "boolean" }) 之后试图访问 args.force,TypeScript 知道它是 boolean 类型;如果你拼写成了 args.forc,TypeScript 编译阶段就报错了。
对比 naive 方案:手写 process.argv 解析后得到的类型是 Record<string, any>——一个 args.foce 的拼写错误要等到运行时才发现。yargs 把运行时错误提前到了编译时。
但纯 yargs 有一个边界无法覆盖:async handler 中的异常处理。纯 yargs 的命令在 handler 里抛错时,错误会传播到 yargs 顶层。而 opencode 的部分命令(如 run)需要在 Effect-ts 运行时中执行,并且需要在执行前后管理 InstanceContext 的生命周期——纯 yargs 解决不了这个问题,这推动了第二层的诞生。
第二层:effectCmd 封装
effectCmd(sources/opencode/packages/opencode/src/cli/effect-cmd.ts)是连接 yargs 和 Effect-ts 运行时的桥梁。它的核心逻辑只有 30 行:
export const effectCmd = <Args, A>(opts: EffectCmdOpts<Args, A>) =>
cmd<{}, Args>({
command: opts.command,
describe: opts.describe,
builder: opts.builder as never,
async handler(rawArgs) {
const args = rawArgs as unknown as WithDoubleDash<Args>
const useInstance = typeof opts.instance === "function"
? opts.instance(args)
: opts.instance !== false
if (!useInstance) {
await AppRuntime.runPromise(opts.handler(args))
return
}
const { store, ctx } = await AppRuntime.runPromise(
InstanceStore.Service.use((store) =>
store.load({ directory }).pipe(Effect.map(ctx => ({ store, ctx })))
),
)
try {
await AppRuntime.runPromise(
opts.handler(args).pipe(Effect.provideService(InstanceRef, ctx))
)
} finally {
await AppRuntime.runPromise(store.dispose(ctx))
}
},
})
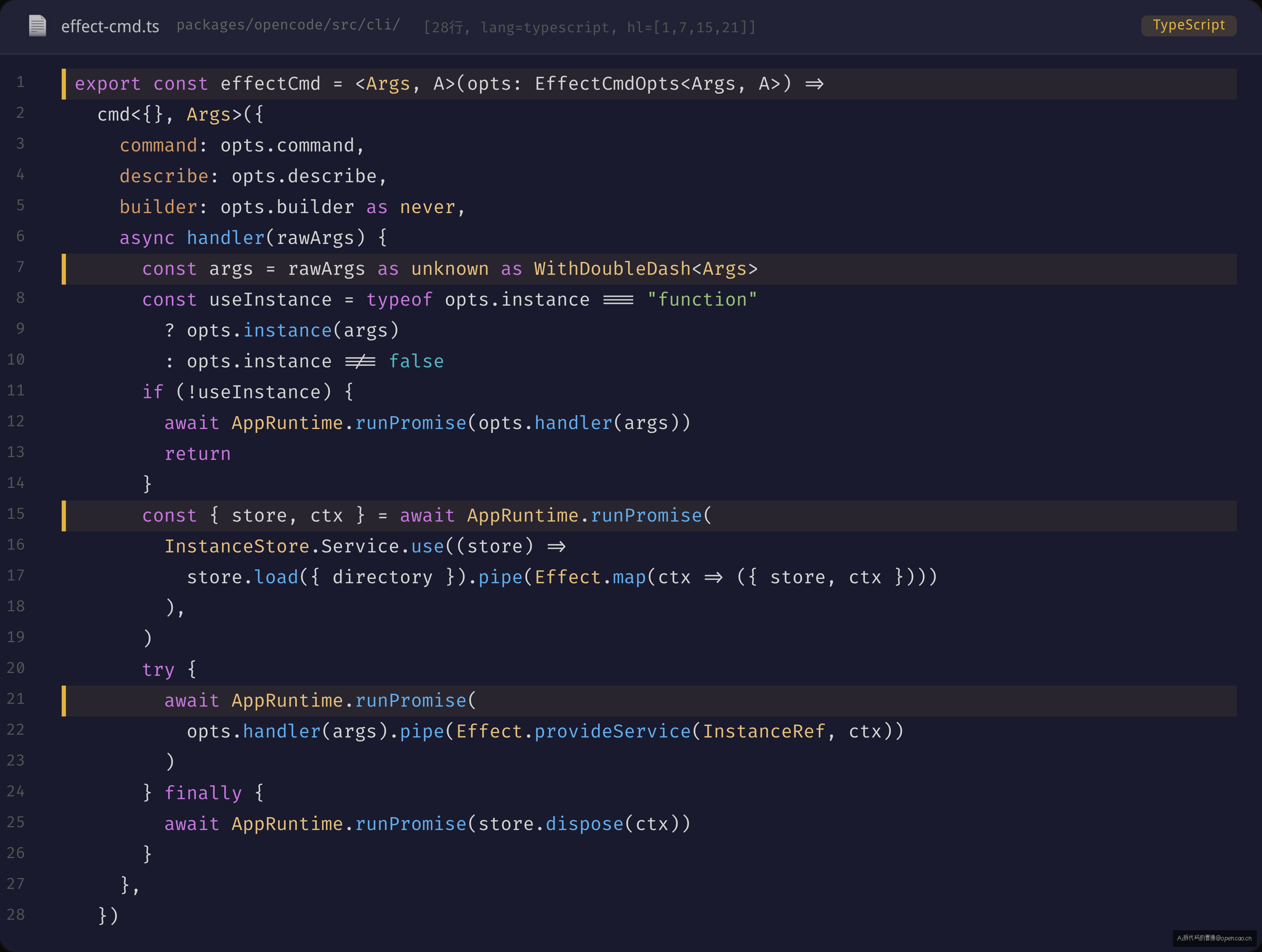
这 30 行代码解决了一个棘手的设计问题:命令是否需要 InstanceContext? opts.instance 有三种取值方式:
true(默认):handler 执行前自动加载 InstanceContext,执行后自动 disposefalse:命令不需要项目上下文,跳过加载——节省了 bootstrap 的全部开销(args) => boolean:动态决定,比如run --attach <url>时不需要本地 Instance
新手最容易忽略的是 finally { store.dispose(ctx) }——如果不用这个 try/finally,handler 抛错时 InstanceContext 永远不会被释放,导致资源泄漏(文件监听器、IPC 连接、数据库连接都不会关闭)。effectCmd 用一个 try/finally 覆盖了所有退出路径——成功返回、异常抛出、Effect 中断——这是 Effect-ts 的 Effect.ensuring() 在 yargs handler 层的等价实现。
看一个实际使用的例子——ServeCommand(sources/opencode/packages/opencode/src/cli/cmd/serve.ts):
export const ServeCommand = effectCmd({
command: "serve",
builder: (yargs) => withNetworkOptions(yargs),
describe: "starts a headless opencode server",
instance: false,
handler: Effect.fn("Cli.serve")(function* (args) {
const opts = yield* resolveNetworkOptions(args)
const server = yield* Effect.promise(() => Server.listen(opts))
console.log(`opencode server listening on http://${server.hostname}:${server.port}`)
yield* Effect.never
}),
})
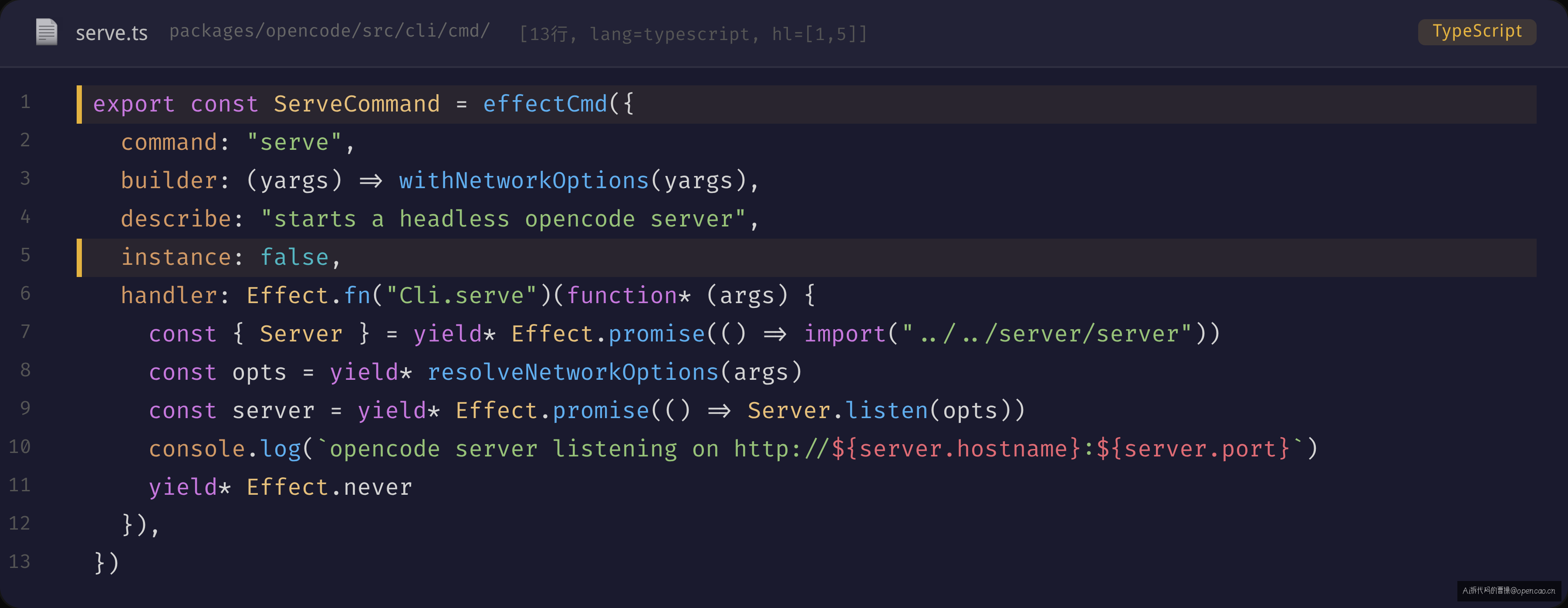
instance: false 的意思是:serve 命令不读取项目配置、不加载插件、不启动 LSP——它就是个单纯的 HTTP 服务器启动器。这个配置告诉 effectCmd 跳过 InstanceStore 的 load/dispose 全过程。对于 run 命令,默认是 instance: true——因为 run 需要项目上下文来执行代码操作。
effectCmd 还提供了一个 CliError 类,让 handler 可以抛出用户可见的错误信息。跟全局错误处理器 FormatError(sources/opencode/packages/opencode/src/cli/error.ts)配合,handler 只需要 return fail("配置文件不存在"),不需要关心错误怎么格式化、是否要 exit、是否需要 cleanup——这些都由 effectCmd 的调用链统一处理。
如果不用 effectCmd,每个 instance: true 的命令 handler 都要手写 15 行模板代码(load → provideService → try handler → finally dispose)——20 条命令就是 300 行重复代码。effectCmd 把这 300 行压缩到了 30 行实现 + 20 行调用(每行只是个 instance: true/false)。差异就是 300 行模板 vs 50 行配置。
第三层:cmd() 类型安全垫片
三层架构里最容易被忽略的是最底层——只有 7 行的 cmd() 函数(sources/opencode/packages/opencode/src/cli/cmd/cmd.ts):
import type { CommandModule } from "yargs"
export type WithDoubleDash<T> = T & { "--"?: string[] }
export function cmd<T, U>(input: CommandModule<T, WithDoubleDash<U>>) {
return input
}
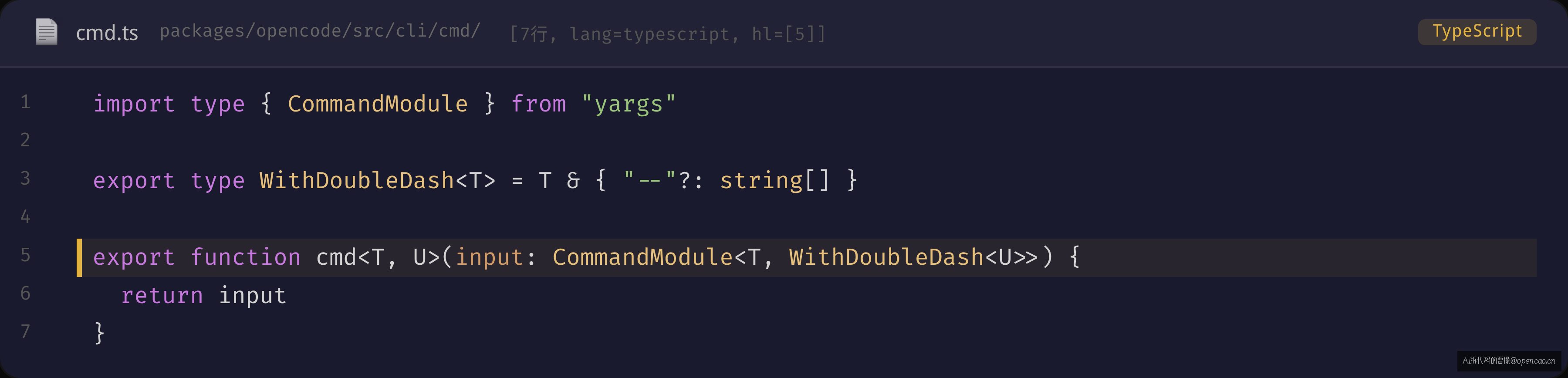
它不做任何运行时工作——就是一个 identity 函数:输入什么就返回什么。它的全部价值在于类型:WithDoubleDash<T> 确保 handler 的 argv 始终包含一个 "--"?: string[] 字段,用于接收 -- 后的 passthrough 参数。
新手可能会问:为什么要多一个 identity 函数,而不是直接在 effectCmd 里用 CommandModule 类型?原因是类型组合的需要。yargs 的 .command() 接受 CommandModule 类型,但 effectCmd 返回的是一个兼容 CommandModule 的对象——这个对象需要同时满足 yargs 的接口约束和 Effect-ts 的类型推导。cmd() 作为 identity 函数,在这里充当了类型适配器的角色:它声明「我接受 CommandModule<T, WithDoubleDash<U>>」,然后原样返回——TypeScript 编译器在检查调用链时会强制要求这个类型对齐。
如果没有这层类型垫片,effectCmd 返回的对象在 .command(effectCmd({...})) 调用点可能因为类型细微偏差(比如 describe: string | false 和 describe: string 的差异)而导致编译错误。三层架构的每层各司其职:
cmd() ← 类型层:确保 WithDoubleDash 类型对齐
↑
effectCmd() ← 封装层:自动 Instance 生命周期管理
↑
CommandModule ← 框架层:yargs 的 {command, describe, builder, handler} 契约
层与层之间通过函数组合而不是继承连接。这意味着可以单独升级 yargs 版本(框架层)、修改 Effect 运行时逻辑(封装层)、调整类型定义(类型层)——改动不会级联穿透。对比手写 switch-case 方案:每个 case 块里参数解析、handler 逻辑、错误处理、类型定义全部耦合在一起,任何改动都可能牵一发而动全身。
三层架构的完整视图用一张图总结:
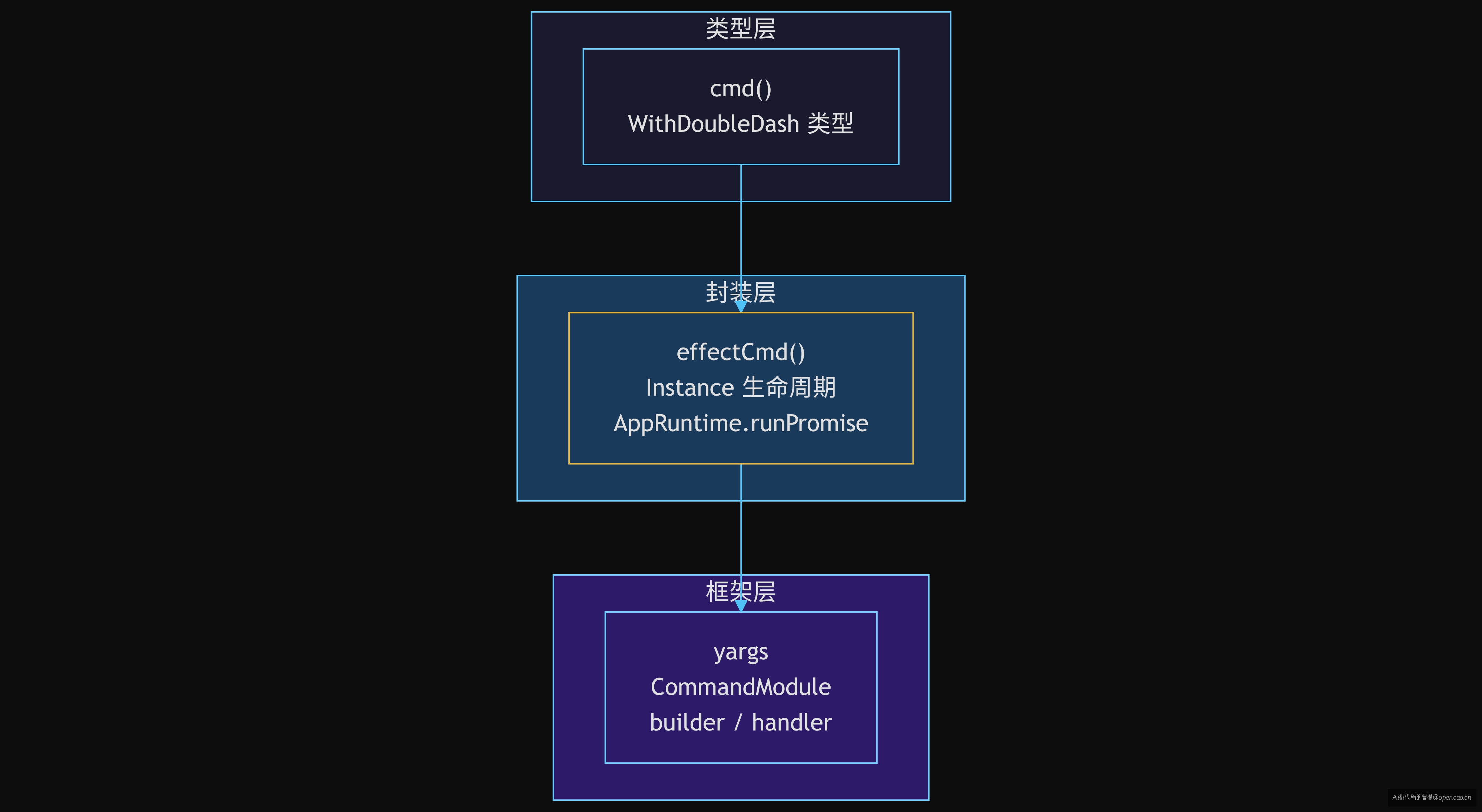
这三层组合的最终效果是:新增一条命令 = 1 个文件 + 2 行代码(import + .command())。不需要动路由表、不需要写参数解析、不需要管生命周期。
【源码】index.ts 逐层拆解
有了设计层的理解,再来看 packages/opencode/src/index.ts——这个 142 行的文件是 CLI 层的「总开关」。
import 图谱:20+ 命令模块
先说结论:一个文件 import 20+ 个命令模块看起来很「重」,但这是配置式路由的必然结果——每个命令独立文件,入口文件只做组装。
文件前 31 行全是 import(sources/opencode/packages/opencode/src/index.ts:1-31):
import yargs from "yargs"
import { hideBin } from "yargs/helpers"
import { RunCommand } from "./cli/cmd/run"
import { GenerateCommand } from "./cli/cmd/generate"
import { ConsoleCommand } from "./cli/cmd/account"
import { ProvidersCommand } from "./cli/cmd/providers"
import { AgentCommand } from "./cli/cmd/agent"
import { UpgradeCommand } from "./cli/cmd/upgrade"
import { UninstallCommand } from "./cli/cmd/uninstall"
import { ModelsCommand } from "./cli/cmd/models"
// ... 共 20+ 个
import { FormatError } from "./cli/error"
import { Heap } from "./cli/heap"
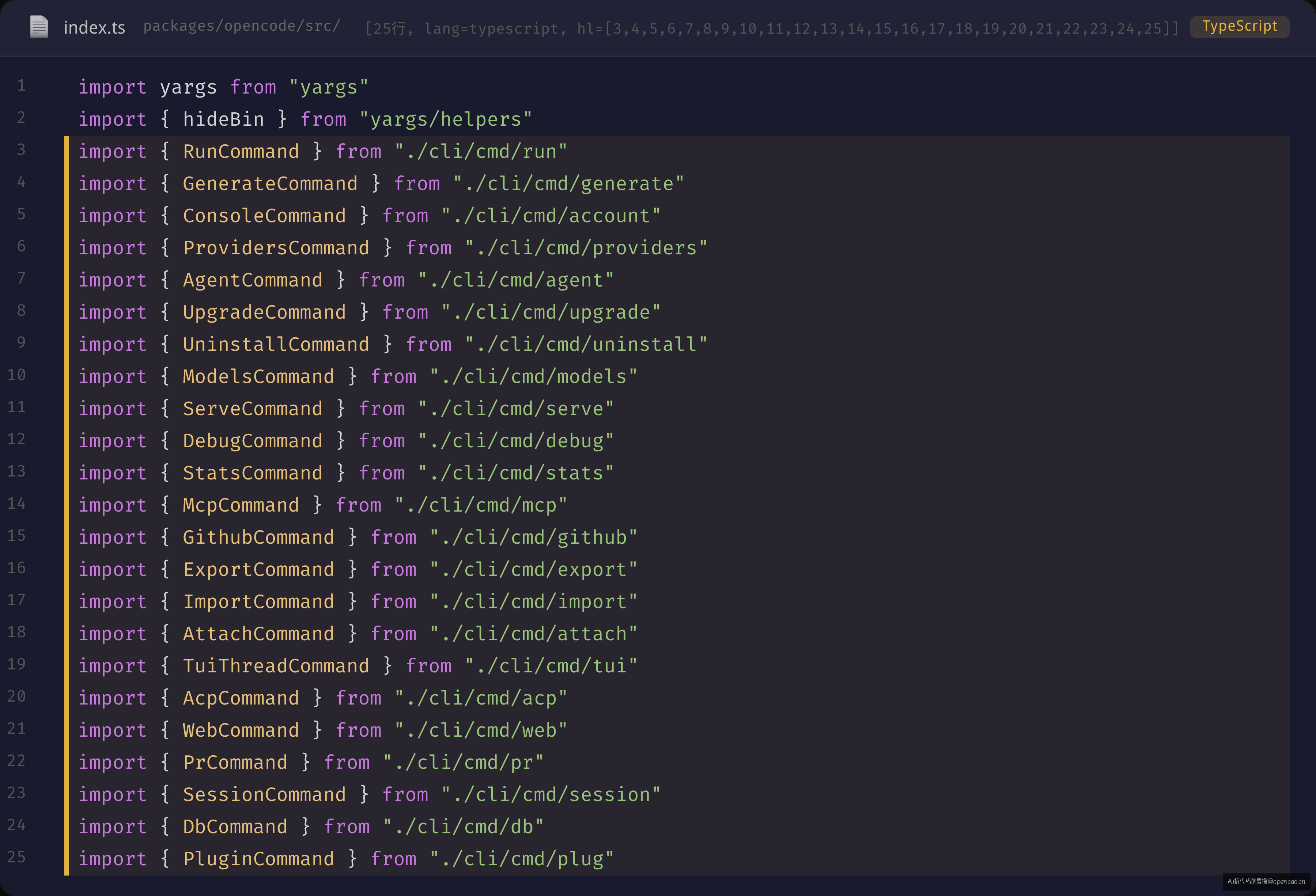
留意 import 的分布:除了 yargs 本身和辅助函数(hideBin、FormatError、Heap),其余全是命令模块。每个命令模块导出的是一个对象(不是类、不是函数)。对象作为模块边界的好处是:yargs 的 .command() 接收的是对象,不需要实例化、不需要 new、不需要注册到 DI 容器——import 即用。
对于习惯了 Java/Spring 那种「先写接口、再写实现、再注册到容器」的开发者来说,这种模式可能会觉得「太松散」。但在 TypeScript 中,satisfies CommandModule 在编译期就锁死了结构——你没办法 export 一个缺少 handler 的「命令对象」,编译不会通过。
这里有个看源码的实用技巧:index.ts 的 import 行数直接反映了命令数量。如果你看到某个版本的 opencode 增加了新的 import,你就知道它加了新命令——不需要翻 commit log。当前版本是 20+ 条,分布在 20+ 个文件中,每个文件平均 30-80 行。
builder chain:全局选项声明式定义
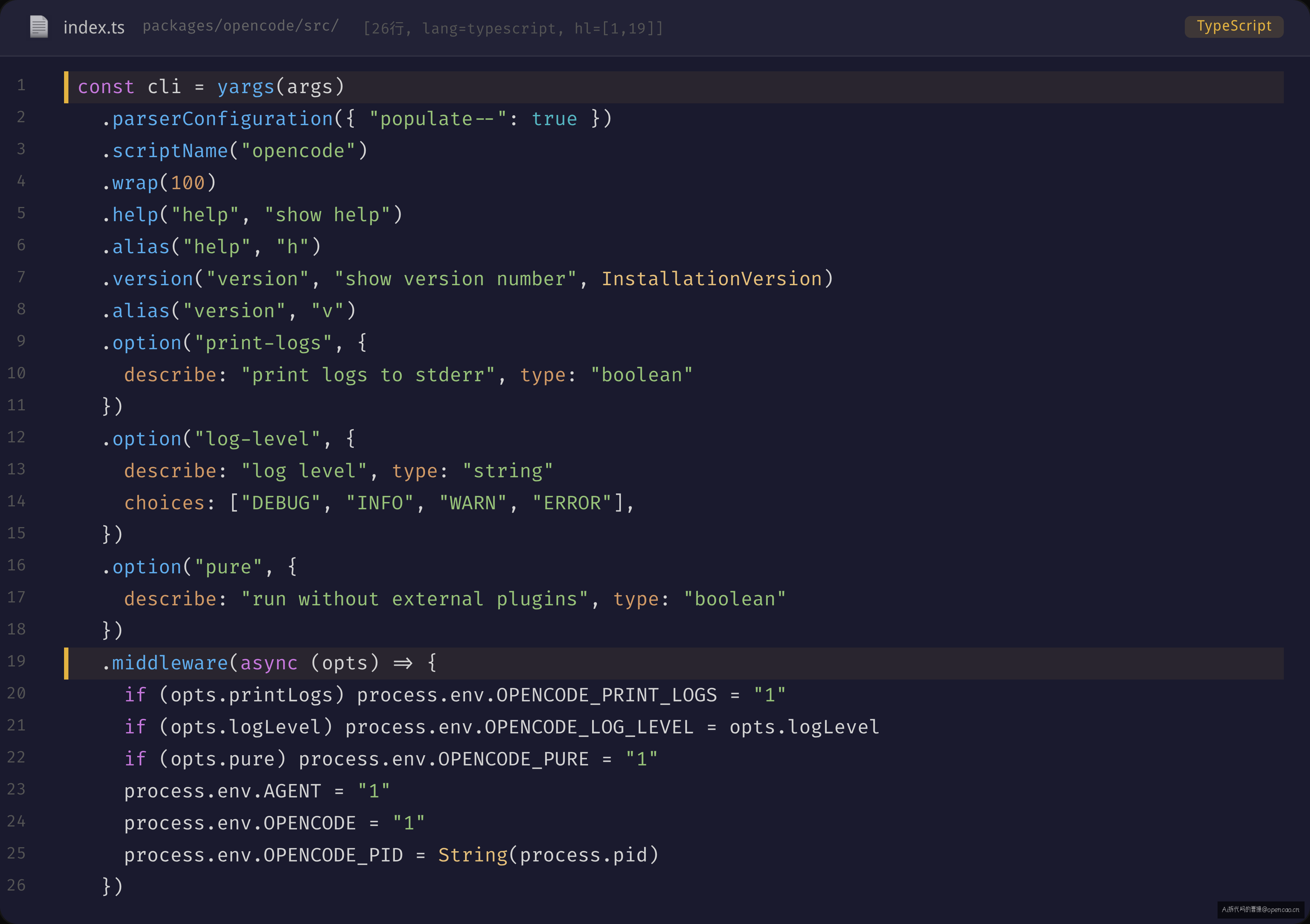
骨架代码 const cli = yargs(args) 后的链式调用配置了 CLI 的全局选项(sources/opencode/packages/opencode/src/index.ts:45-78):
const cli = yargs(args)
.parserConfiguration({ "populate--": true })
.scriptName("opencode")
.wrap(100)
.help("help", "show help").alias("help", "h")
.version("version", "show version number", InstallationVersion).alias("version", "v")
.option("print-logs", { describe: "print logs to stderr", type: "boolean" })
.option("log-level", { describe: "log level", type: "string", choices: ["DEBUG", "INFO", "WARN", "ERROR"] })
.option("pure", { describe: "run without external plugins", type: "boolean" })
.middleware(async (opts) => {
if (opts.printLogs) process.env.OPENCODE_PRINT_LOGS = "1"
if (opts.logLevel) process.env.OPENCODE_LOG_LEVEL = opts.logLevel
if (opts.pure) process.env.OPENCODE_PURE = "1"
process.env.AGENT = "1"
process.env.OPENCODE = "1"
process.env.OPENCODE_PID = String(process.pid)
})
三个值得深挖的设计决策:
parserConfiguration({ "populate--": true })——这个配置决定了 -- 的分隔符行为。如果不设 populate--,yargs 遇到 -- 会把后续参数当作未知参数报错(因为 strict() 模式)。设了 populate-- 后,-- 后面的内容会被收集到 argv["--"] 数组里,让子命令的 handler 自行决定怎么用。这个设计对 AI Coding Agent 至关重要:opencode run -- pip install flask 这种场景,pip install flask 是传给 run 命令的 message 的一部分,而不是 yargs 要解析的参数。
wrap(100)——固定帮助文本宽度。如果没有这一行,yargs 会根据终端宽度动态调整排版——但 CI 环境、Docker 容器、headless server 的终端宽度可能是 80 或 120,每次输出帮助文本排版都不一样。wrap(100) 确保在任何环境下,opencode --help 的输出都是一致的。这个细节说明了作者对「程序化输出」的重视——帮助文本不只是给人看的,也是给脚本解析的。
middleware()——一次注册全局生效。对比 naive 方案:每个 handler 开头都要写 if (opts.printLogs) process.env.OPENCODE_PRINT_LOGS = "1",20 个 handler 就是 20 次重复。middleware 在 yargs 中是一个全局钩子——在所有命令的 handler 执行之前运行,且只运行一次。这意味着如果某个命令的 handler 不经过 yargs 的 parse 流程(比如 --help 走了特殊路径),middleware 也不会执行。我验证了一下,--help 路径走了单独的 cli.parse() 分支——这意味着 --help 时不会设置 OPENCODE_PID 等环境变量。这不是 bug,而是设计:显示帮助信息不需要启动 Heap、不需要设置 PID。
这三个设计中,middleware 是 naive 方案最无法复制的:手写 switch-case 不可能有一个「在所有命令前运行的钩子」,除非你在 switch-case 外层再包一层——那就又回到了框架的设计。
命令注册:配置式路由表
全局选项定义完后,21 条命令用连续 .command() 注册(sources/opencode/packages/opencode/src/index.ts:79-103):
.usage("")
.completion("completion", "generate shell completion script")
.command(AcpCommand).command(McpCommand).command(TuiThreadCommand)
.command(AttachCommand).command(RunCommand).command(GenerateCommand)
.command(DebugCommand).command(ConsoleCommand).command(ProvidersCommand)
.command(AgentCommand).command(UpgradeCommand).command(UninstallCommand)
.command(ServeCommand).command(WebCommand).command(ModelsCommand)
.command(StatsCommand).command(ExportCommand).command(ImportCommand)
.command(GithubCommand).command(PrCommand).command(SessionCommand)
.command(PluginCommand).command(DbCommand)
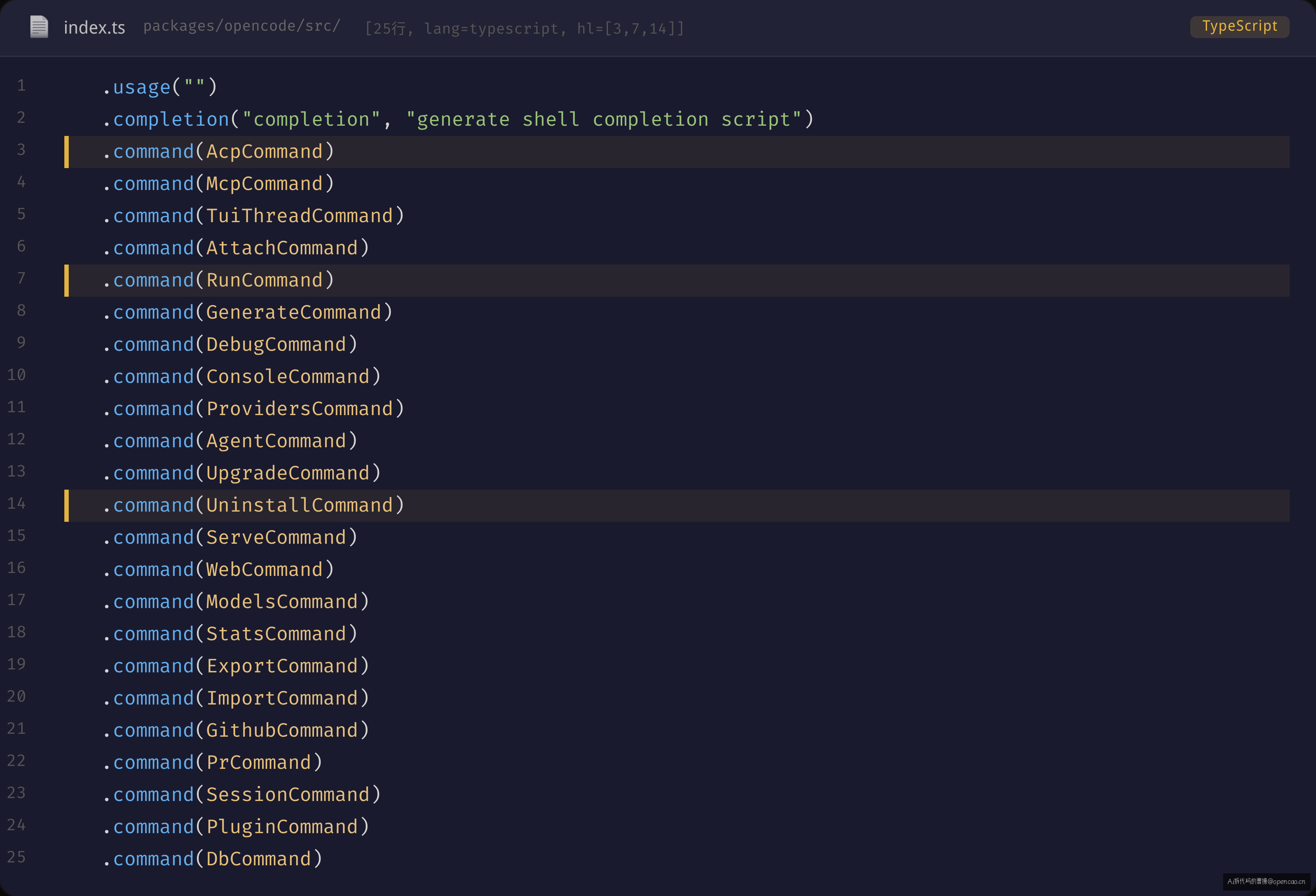
全部注册就是一行一个 .command(XxxCommand)。没有配置数组、没有路由表文件、没有命令发现机制。yargs 内部维护了一个命令注册表,.command() 调用时会解析 CommandModule 的 command 字段(如 "run [message..]" 中的 run)作为命令名,解析 "[message..]" 作为位置参数的模式。
新增一条命令的流程被压缩到了极致:
1. 创建 packages/opencode/src/cli/cmd/xxx.ts,export 一个 CommandModule 对象
2. 在 index.ts 加一行 import { XxxCommand } from "./cli/cmd/xxx"
3. 在 builder chain 加一行 .command(XxxCommand)
三步操作都不涉及修改现有代码——完全符合开闭原则。在 20+ 条命令的规模下,这种扩展路径的清晰度直接决定了开发效率。
这里有个反直觉的点:配置式路由在命令少时(<5 条)比 switch-case 更繁琐——需要建文件、写 import、写 builder chain。但命令越过 10 条后,switch-case 的维护成本会线性增长(因为每个 case 块内部的参数解析越来越复杂),而配置式路由的维护成本接近常数——因为新命令和老命令不共享同一段代码路径。yargs 的 .command() 模式把「开闭原则」应用到了 CLI 入口设计上——这个思路在 HTTP 路由(app.get('/path', handler))、事件总线(bus.on('event', handler))、消息队列(consumer.subscribe('topic', handler))中都能看到。
错误处理:防御性编程的最后一公里
.fail() 是 yargs 提供的错误捕获点——所有参数校验失败、未知命令、解析错误都会汇聚到这里(sources/opencode/packages/opencode/src/index.ts:104-141):
.fail((msg, err) => {
if (msg?.startsWith("Unknown argument") ||
msg?.startsWith("Not enough non-option arguments") ||
msg?.startsWith("Invalid values:")) {
if (err) throw err // 让外层 catch 处理
cli.showHelp(show) // 参数错误 → 显示帮助
}
if (err) throw err
process.exit(1)
})
.strict()
这里的设计意图值得拆解:
.strict() 模式下,yargs 会拒绝任何未在 builder 中定义的参数。如果你输入 opencode run --unknown-flag,yargs 不会静默忽略它——而是触发 .fail() 回调,打印「Unknown argument: --unknown-flag」并显示帮助。对新手来说,这个行为可能显得「严格」——但考虑一下后果:如果不设 strict,一个 --print-log 的拼写错误(少了个 s)会被 yargs 静默忽略,然后你发现日志没有输出,查了半天才意识到是拼写问题。strict() 把这种「半小时调试」压缩成了一秒的错误提示。
.fail() 的「部分错误显示帮助、部分错误抛异常」策略:对用户输入错误(Unknown argument / Invalid values),显示帮助后返回(不 exit);对系统级错误(比如 handler 内部抛出的异常),抛给外层 try/catch。
执行路径有两个分支(sources/opencode/packages/opencode/src/index.ts:118-141):
try {
if (args.includes("-h") || args.includes("--help")) {
await cli.parse(args, (err, _argv, out) => {
if (err) throw err
if (!out) return
show(out)
})
} else {
await cli.parse()
}
} catch (e) {
const formatted = FormatError(e)
if (formatted) UI.error(formatted)
process.exitCode = 1
} finally {
process.exit()
}
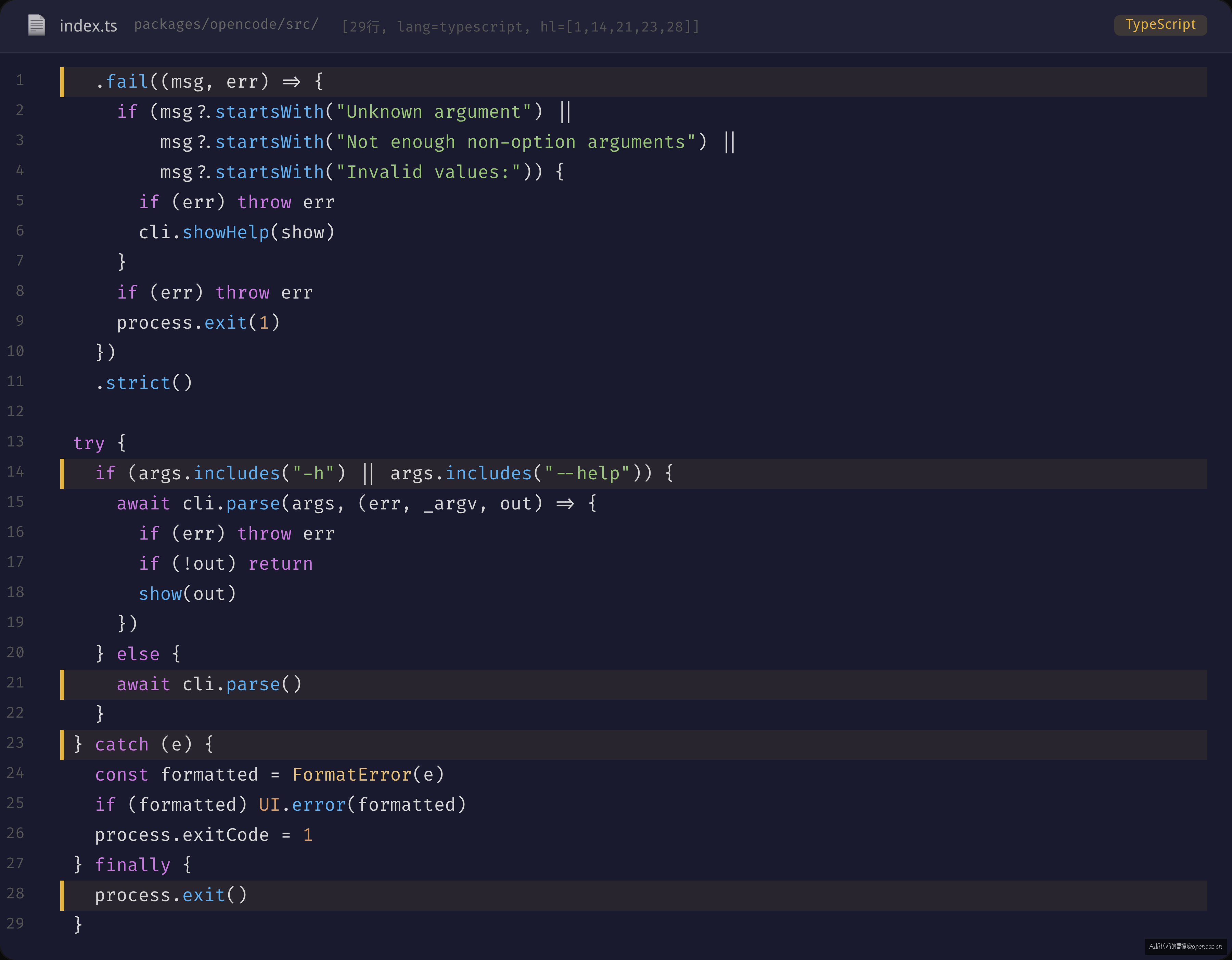
--help 走了独立路径,不经过 .strict() 校验——因为帮助命令即使混了未知参数也应该显示帮助,而不是报错。这个细节体现了防御性编程的最后一层:即使是防御代码本身,也要处理人在压力下可能打的命令(比如 opencode help --prnit-logs —— 拼错 --print-logs 但想看帮助,你不应该拒绝他)。
finally { process.exit() }——这条注释写着「确保不会挂起」。它在处理一个真实问题:某些子进程(特别是 Docker 容器内的 MCP 服务器)在收到 SIGTERM 时不会正确退出。如果不强行 exit,Node.js 进程会一直等待这些子进程关闭——在 CI 环境中,这会导致脚本永远挂起。process.exit() 是粗暴但有效的兜底。
对比 naive 方案:如果手写 switch-case,你需要在每个 case 块内处理异常、在每个分支中处理 --help、在每条路径中确保进程退出——20 个 case 块,只要漏一处,就会出现「命令执行完了但进程不退出」的诡异问题。
错误处理链路的完整视图:.fail()(yargs 层)→ try/catch(入口层)→ FormatError()(格式化层)→ UI.error()(展示层)——每一层只处理自己能力范围内的事情,超出范围就抛给上层。这是单职责原则在错误处理中的典型应用。
【权衡】为什么不是 commander.js / 裸解析 / 手写生命周期
CLI 框架选型:yargs 的不可替代性
先回答一个最直接的问题:为什么选了 yargs 而不是更轻量的 commander.js?
Commander.js 是 Node.js 生态中最流行的 CLI 框架,API 设计非常简洁。但在这个具体场景下,yargs 有一个 commander 无法替代的特性:类型推导链。
Commander.js 的参数定义是赋值式的:
// commander.js 风格
program
.option('-d, --debug', 'output extra debugging')
.option('-s, --small', 'small pizza size')
和 yargs 的链式调用看起来相似,但关键差异在类型系统层面。yargs 的每个 .option() 都返回携带了精确类型的 Argv<T>——handler 中能自动推断出 args.debug 是 boolean。Commander.js 没有同等粒度的类型推导,你需要在 handler 中手动声明类型。
那有没有想过不用框架、裸解析 process.argv?20 条命令规模下,裸解析的隐藏成本远大于可见收益:
| 维度 | yargs | 裸 process.argv | commander.js |
|---|---|---|---|
| 命令路由 | .command(Module) 配置式 |
手写 switch-case | .command('sub') 链式 |
| 参数解析 | .option() + .positional() 声明式 |
手写正则/循环 | .option() 声明式 |
| 类型推导 | Argv<T> 泛型链式递增 |
Record<string, any> |
弱类型 |
| --help | 内置,可自定义 format | 手写 | 内置 |
| 参数校验 | .choices(), .demand(), .strict() |
手写 if/else | 有限 |
| middleware | 全局钩子 | 在 switch-case 外包一层 | 无 |
| 完成/补全 | .completion() 内置 |
手写 | 无 |
| populate-- | 一行配置 | 手写 | 不支持 |

opencode 选 yargs 的核心原因总结为三点:
第一,populate-- 是刚需。 AI Coding Agent 的场景中,opencode run -- pip install flask 这种命令模式极其常见。如果框架不支持 -- 参数传递,就需要在 CLI 层手写分割逻辑。yargs 一行 parserConfiguration 解决,commander.js 原生不支持。
第二,.command(Module) 的对象模式比 .command('sub') 的链式模式更适合 20+ 规模。 每个命令独立文件,模块间没有耦合。Commander.js 的链式 .command('sub') 虽然也能拆文件,但注册方式要求所有命令共享同一个 program 实例——在独立文件模式下,你需要把 program 传给所有子模块,或者在入口文件集中注册。两种方式都不如 yargs 的 CommandModule 对象模式干净。
第三,.strict() + .fail() 的错误处理模型。 在 20 条命令中保持一致的错误响应行为(参数错误显示帮助、内部错误抛异常)需要一个全局的错误处理点。yargs 的 .fail() 就是为这个场景设计的。
但 yargs 不是没有缺点。它最明显的短板是文档质量——类型定义高度泛型化,Argv<T> 的链式推导在 builder 复杂时会给出难以理解的编译错误。另外,yargs 的 builder 是命令式的链式调用,你无法像 GraphQL schema 那样「声明一个参数集合,然后在多个命令间复用」——虽然可以通过 withNetworkOptions(yargs) 这种辅助函数部分复用,但本质上还是函数组合,不是声明式组合。
effectCmd vs 手写生命周期管理
用 effectCmd 的核心收益不是「少写代码」,而是消除了一个常见的资源泄漏通路。
如果不封装 effectCmd,每个需要 InstanceContext 的命令 handler 必须手写:
// ❌ 没有 effectCmd 时的手动模板代码
handler: async (args) => {
const { store, ctx } = await AppRuntime.runPromise(
InstanceStore.Service.use((store) =>
store.load({ directory }).pipe(Effect.map(ctx => ({ store, ctx })))
),
)
try {
await AppRuntime.runPromise(
doWork(args).pipe(Effect.provideService(InstanceRef, ctx))
)
} finally {
await AppRuntime.runPromise(store.dispose(ctx))
}
}
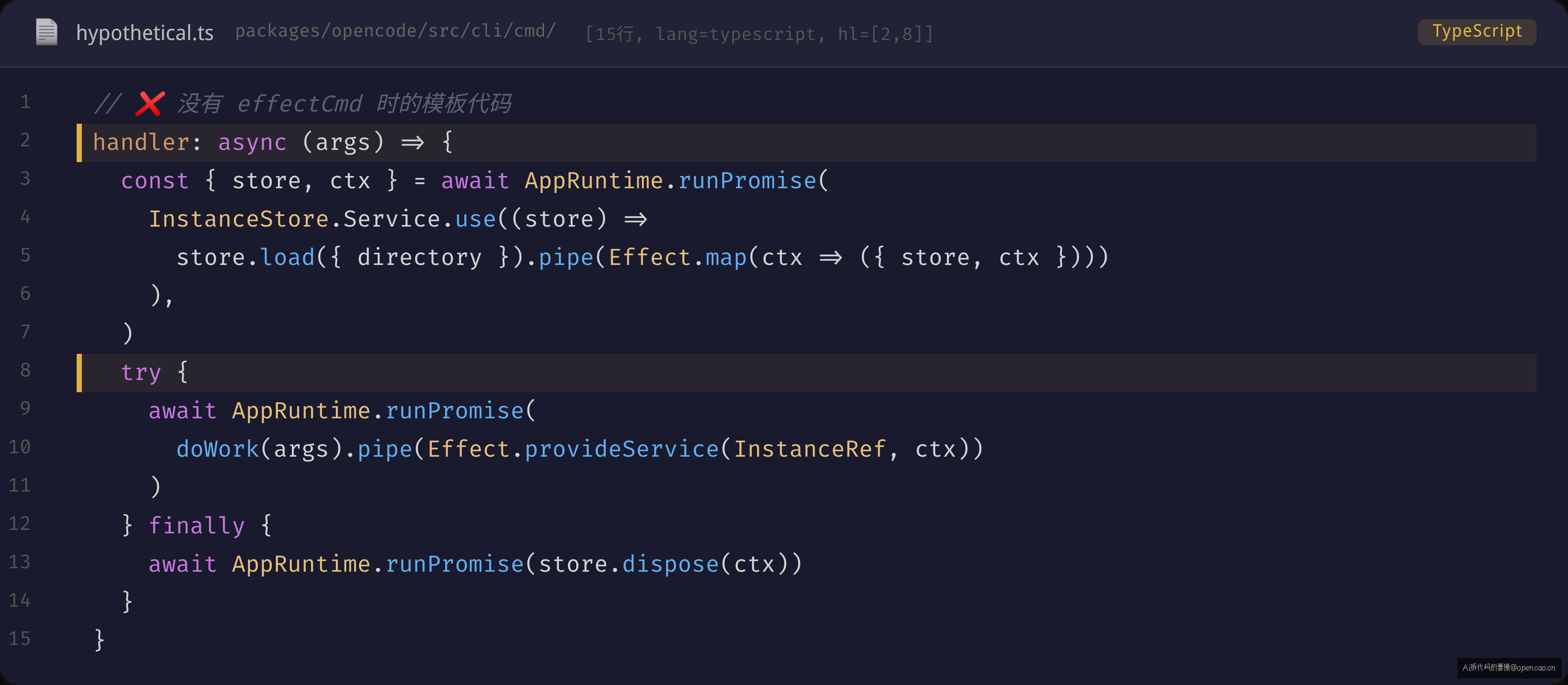
这段代码在 run、stats、session 等命令中会重复出现。每一处重复都是一个潜在的风险点——如果某个 handler 忘了加 finally { dispose(ctx) },或者加了但只在部分 return 路径上 dispose,就会在特定条件下泄漏 InstanceContext。
effectCmd 的 finally 块覆盖了三种退出路径:
- 正常退出:handler 返回后走 finally dispose
- 异常退出:handler 抛错后 finally 仍会执行(JavaScript 保证)
- Effect 中断:Effect.ensuring 确保即使 Effect 被 interrupt,dispose 也会运行
三个覆盖路径,少一个就可能在生产环境出现「opencode 用了一段时间后响应变慢」的诡异问题——原因大概率是 InstanceContext 泄漏导致监听器堆积。
另一个被 effectCmd 消除的认知负担:新手不需要知道 InstanceStore、InstanceRef、AppRuntime 的存在。看 ServeCommand 的例子——你只需要知道 instance: false,然后写你的 Effect handler。框架在「做什么」层面是透明的,在「怎么做」层面是隐藏的。
从代码量看,effectCmd 用 30 行实现 + 每个命令一行 instance: true/false 配置替换了 20 条命令 × 15 行模板 = 300 行重复代码。但更重要的是它能避免:一个被遗忘的 dispose 引发的 2 小时排查——这在调试成本上的节省远大于代码量的差异。
【锚点】CLI 入口设计模式
命令模块化 → yargs .command() 配置式路由
三层分离 → 类型层(cmd) / 封装层(effectCmd) / 框架层(yargs)
共享逻辑 → middleware 一次注册全局生效
资源自动管理 → effectCmd 自动 dispose,消除泄漏
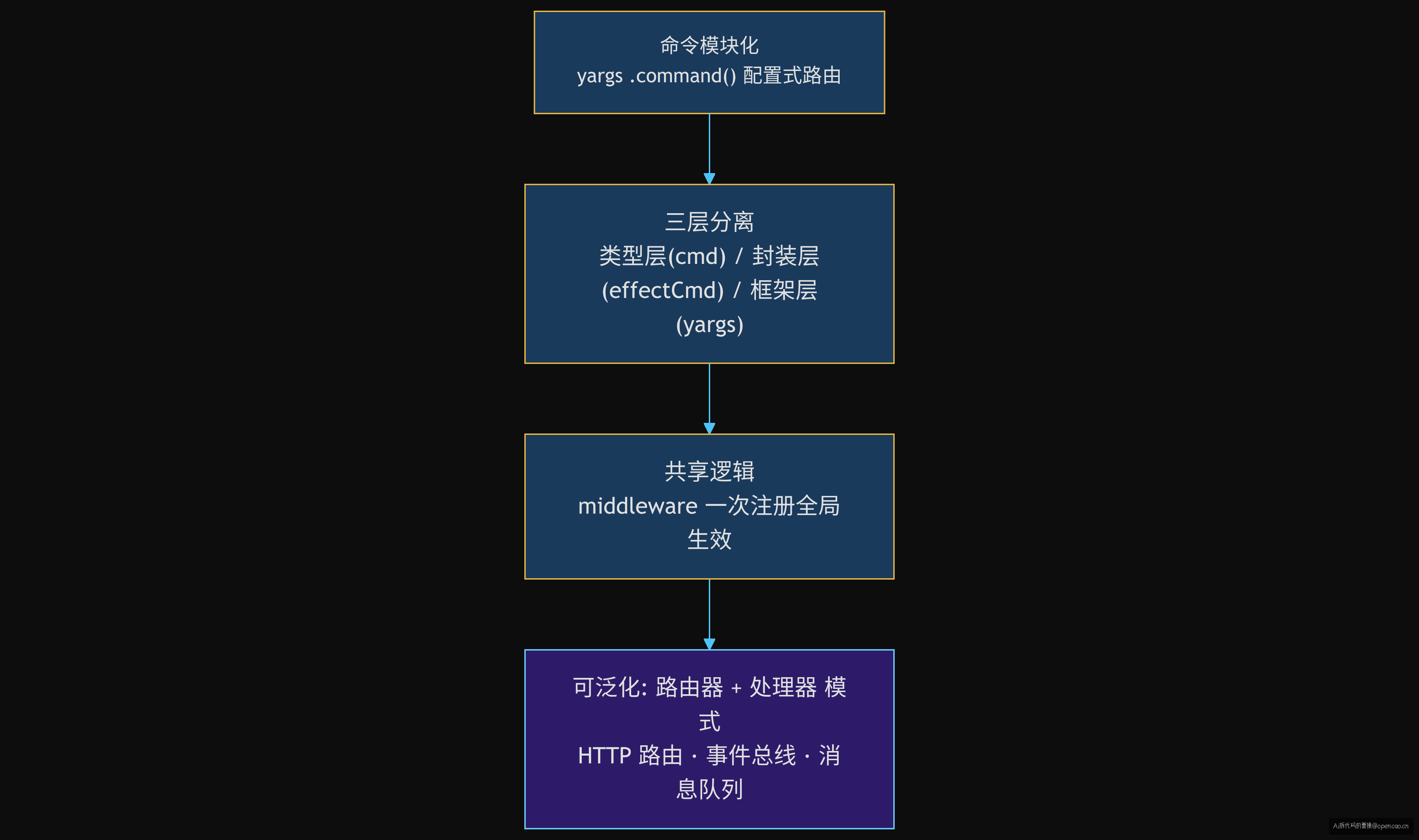
这个模式不局限于 CLI 入口——在任何需要「路由器 + 处理器 + 横切关注点」的场景中都可以复用。HTTP 路由(框架层路由 + 中间件层认证/日志 + 类型层 schema 校验)、事件总线(框架层分发 + 封装层序列化/反序列化 + 类型层事件 schema)、消息队列(框架层 topic 路由 + 封装层消息确认 + 类型层 payload 校验)——都是同样的架构思路。
不同之处在于:opencode 用 effectCmd 把「资源生命周期管理」纳入了封装层的职责,而大多数 CLI 框架把这件事留给了 handler 自己。这个「多做一步」的决策——把 dispose 从 handler 的责任变成框架的责任——是 opencode CLI 层最值得借鉴的设计选择。
下一篇文章(02-02)我们去看看 bootstrap:在 handler 开始执行之前,opencode 做了哪些初始化工作——config 如何加载、plugin 如何发现、InstanceContext 如何构建。这三件事的顺序和依赖关系,才是 CLI 入口层真正的复杂度所在。


