
bootstrap 做了什么:环境检测与运行时初始化
拆解 opencode 源码 · 第二章 CLI 入口与启动流程 · 第二篇
如果你要设计一个 CLI 工具的启动流程——用户敲了 opencode run,到 AI Agent 真正开始处理问题之前——你觉得中间需要做多少准备工作?
一个直观的想法是:读一下配置文件,加载必要的插件,然后启动 Agent Loop。
问题是:谁负责加载配置?加载到哪一层可以访问?插件加载失败了怎么办?配置改动了 Agent 的参数,但 Agent 启动在插件加载之后,顺序怎么保证?更微妙的是——多项目的场景下,用户在目录 A 和目录 B 启动 opencode,配置和项目上下文完全不同,这些上下文是怎么隔离的?
02-01 我们看了 CLI 入口层的 yargs + effectCmd 架构。effectCmd 自动做了三件事:InstanceStore.load({ directory }) → provide(InstanceRef, ctx) → dispose(ctx)。但 load 里面到底做了什么?这就是本文要拆的内容。
实际上,bootstrap 不是一件事,而是三层职责的叠加:实例上下文创建(把目录变成 InstanceContext)→ 运行时就绪(配置文件 + 插件 + 6 个后台服务)→ 上下文传播(让所有下游代码都能拿到当前目录的上下文)。这三层任何一层出问题,Agent 都无法正常工作。
涉及的源码文件和调用关系整理如下:
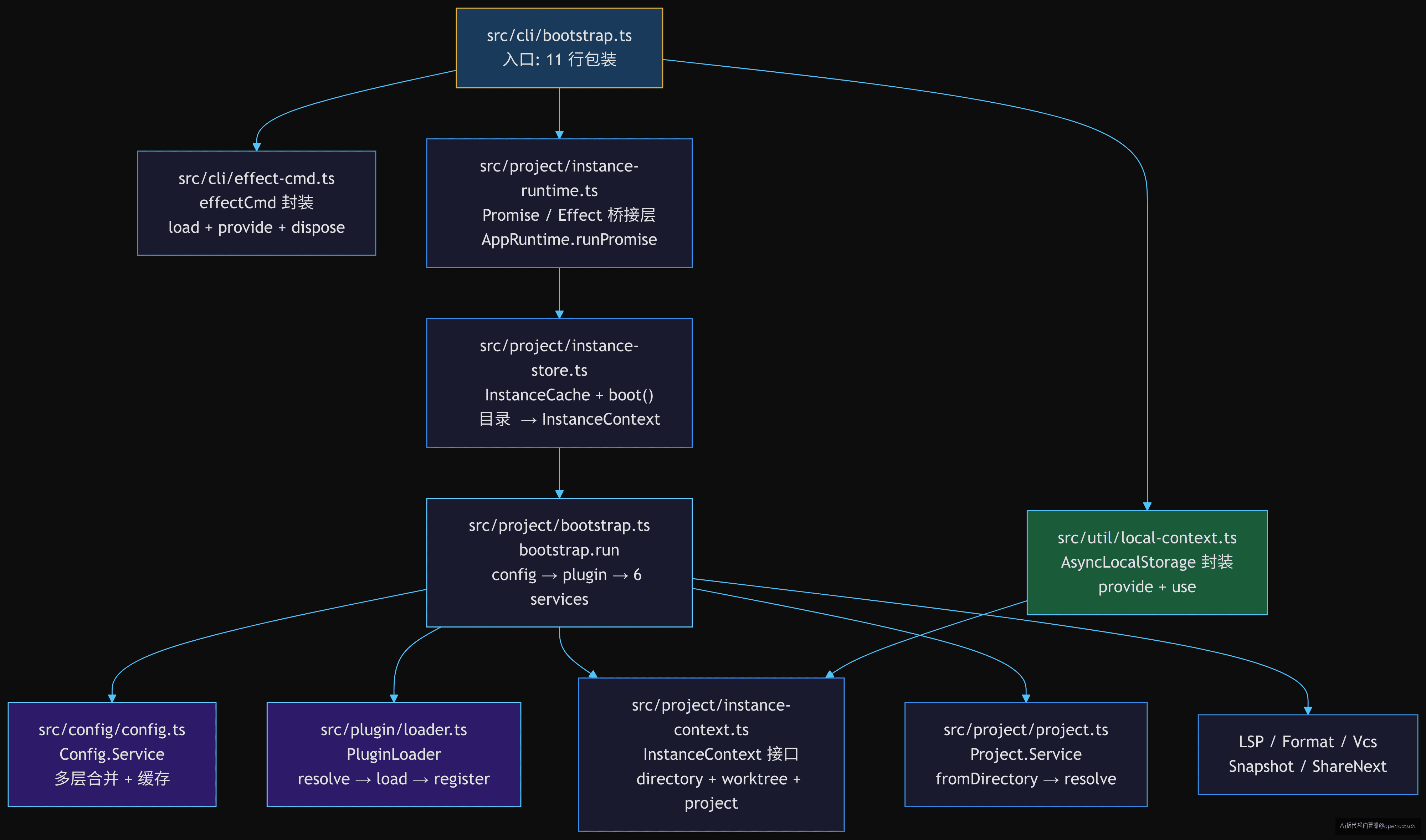
从这棵树可以看到,bootstrap 的代码分散在 8 个文件中,但核心逻辑只有三条线:bootstrap.ts 入口 → instance-runtime.ts 桥接层 → instance-store.ts 缓存 + boot,然后 instance-store.ts 分支到 bootstrap.ts(project/)的 run 方法,run 方法再调度 config、plugin、6 services。每条线的文件都不超过 50 行,但组合起来完成了从「用户敲命令」到「Agent 可工作」的全部初始化。
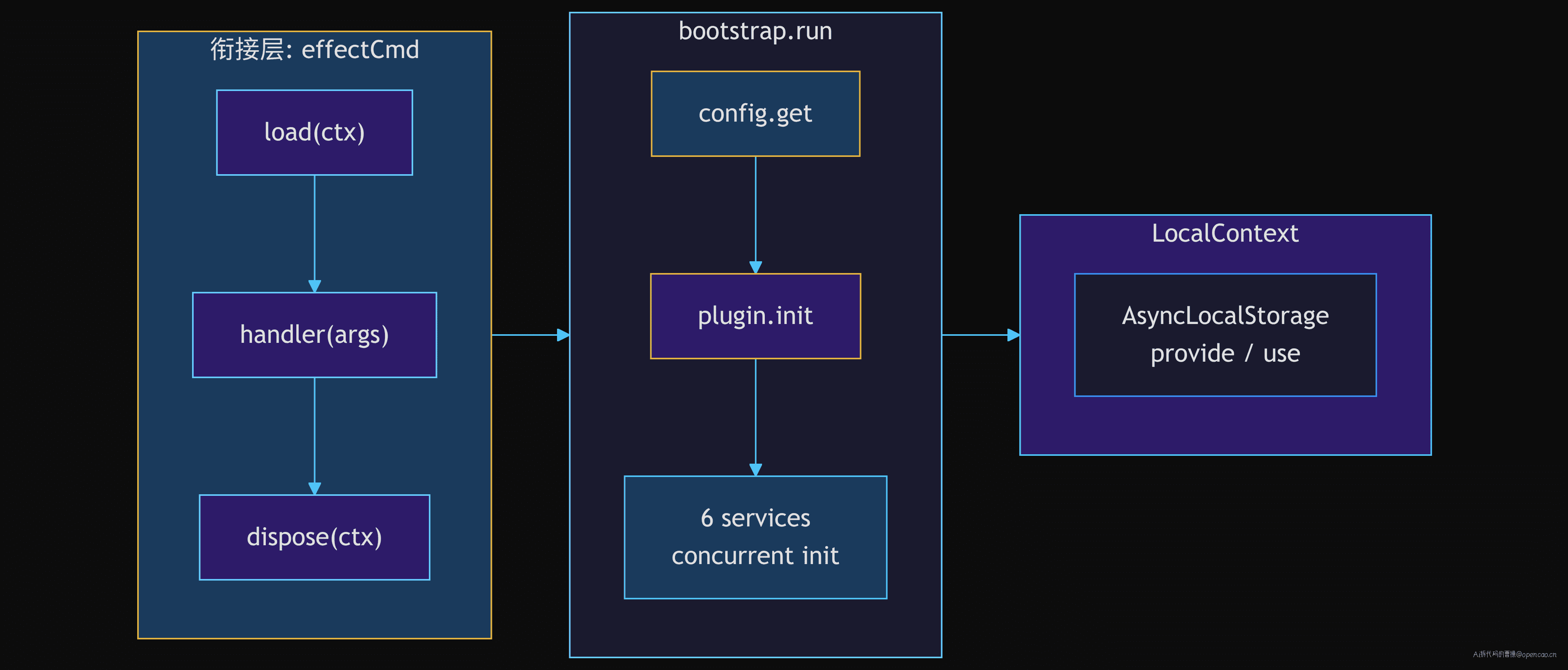
【衔接】从 effectCmd 到 Bootstrap
effectCmd 的 load→handler→dispose
先看 effectCmd 的入口。每一条需要项目上下文的命令(instance: true 或 instance: (args) => boolean),effectCmd 都自动包裹了一个三层生命周期:
// 简化自 packages/opencode/src/cli/effect-cmd.ts:87-94
const { store, ctx } = await AppRuntime.runPromise(
InstanceStore.Service.use((store) => store.load({ directory })
.pipe(Effect.map((ctx) => ({ store, ctx })))),
)
try {
await AppRuntime.runPromise(
opts.handler(args).pipe(Effect.provideService(InstanceRef, ctx))
)
} finally {
await AppRuntime.runPromise(store.dispose(ctx))
}

这段代码的意义在于:你把 handler 写成一个纯 Effect,不需要知道 Instance 什么时候加载、什么时候释放。框架替你 cover 了三种退出路径——正常 return、抛出异常、Effect 中断——全部命中 finally。
为什么这件事值得单独提?因为如果每条命令自己管理 init/dispose,两条命令之间就可能出现"前一条泄漏了监听器,后一条工作不正常"的鬼畜问题。opencode 的作者在 effectCmd 里用 30 行代码把这个隐患从 20+ 条命令中一次性清除了。
这层封装的代价是:你必须理解 AppRuntime.runPromise 是一个必要的桥接——Promise 世界和 Effect 世界之间的通道。InstanceStore.Service.use() 拿到 store,store.load() 跑出 ctx,Effect.provideService 把 ctx 注入到 handler 的 Effect 环境中。每一层都是精确设计的取舍。
衔接下一节:store.load 内部调用了 boot()——这是 InstanceContext 的真正构建入口。
InstanceRuntime.load:桥接层的设计取舍
opencode 内部有两种调用风格:一种是在 Effect 运行时内(Layer.effect、Effect.gen),可以直接 yield* 获取服务;另一种是传统 async/await 代码(如 CLI handler、测试文件),它们无法 yield Effect。
InstanceRuntime 就是为后者准备的桥接层:
// packages/opencode/src/project/instance-runtime.ts:9-11
export const load = (input: LoadInput) =>
AppRuntime.runPromise(InstanceStore.Service.use((store) => store.load(input)))
export const disposeInstance = (ctx: InstanceContext) =>
AppRuntime.runPromise(InstanceStore.Service.use((store) => store.dispose(ctx)))
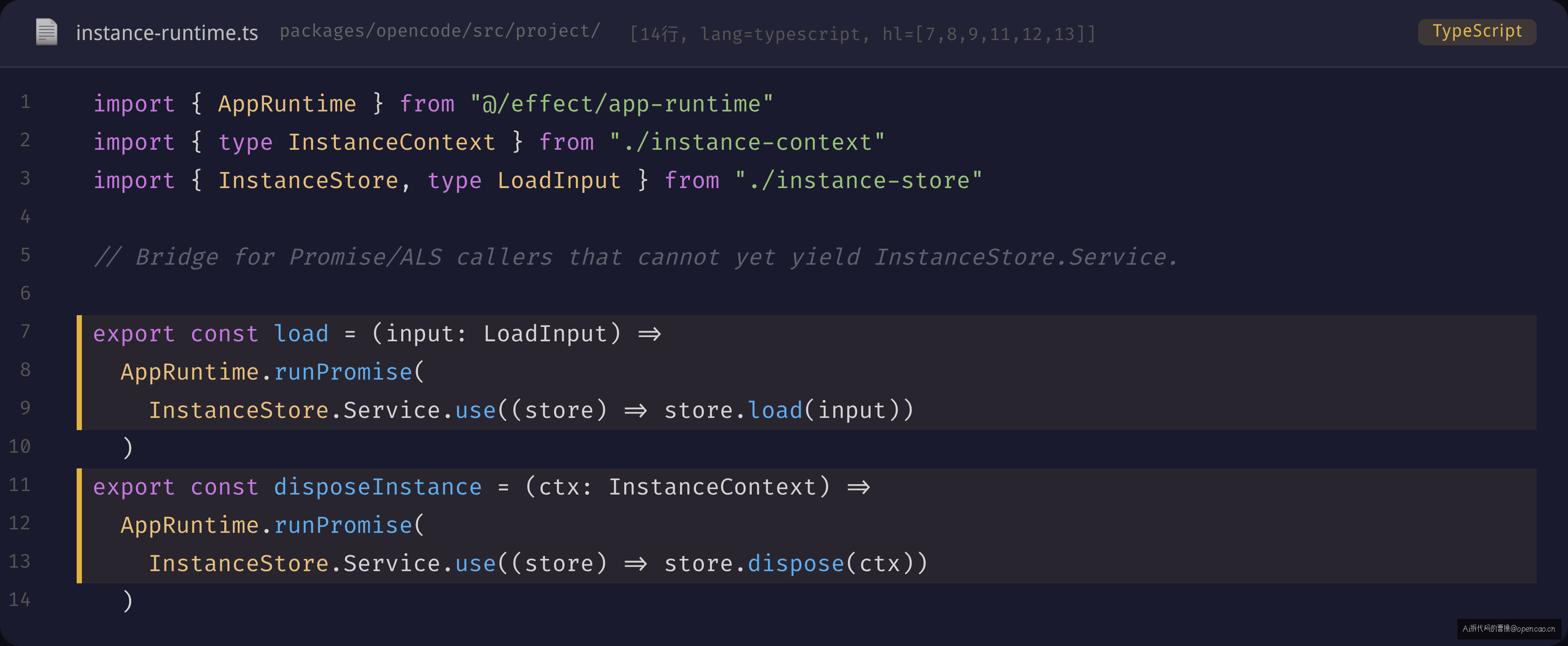
这里的模式是「借 Effect 的能力,还 Promise 的接口」。AppRuntime.runPromise 是全局 Effect 运行时的唯一入口——它创建了一个 Effect.Runner,把 Effect 跑完再转成 Promise。
naive 方案可能直接把 Effect 的能力爆露给调用方(yield* store.load()),但这意味着调用方也必须运行在 Effect 上下文中。bootstrap.ts 的调用方是 CLI handler,而 CLI handler 的入口来自 yargs——yargs 是纯 async/await 的。所以必须在 CLI 边界做一次转换。
bootstrap.ts 的原始版本是更直白的 11 行函数(已在本文开头给出),而 InstanceRuntime 方案就是把这个 11 行模式固化为一个可复用的模块。两者做同一件事,但 InstanceRuntime 多了桥接层的概念,方便其它 Promise 边界(如测试、HTTP handler)复用。
衔接下一节:boot() 内部做的事情——把目录变成 InstanceContext。
【第一层】config.get() — 配置就绪
配置发现:从目录到配置文件
InstanceStore.boot() 的第一步是 project.fromDirectory(directory):
// packages/opencode/src/project/instance-store.ts:45-63
const boot = (input: LoadInput & { directory: string }) =>
Effect.gen(function* () {
const ctx: InstanceContext =
input.project && input.worktree
? { directory: input.directory, worktree: input.worktree, project: input.project }
: yield* project.fromDirectory(input.directory).pipe(
Effect.map((result) => ({
directory: input.directory,
worktree: result.sandbox,
project: result.project,
})),
)
yield* bootstrap.run.pipe(Effect.provideService(InstanceRef, ctx))
return ctx
})
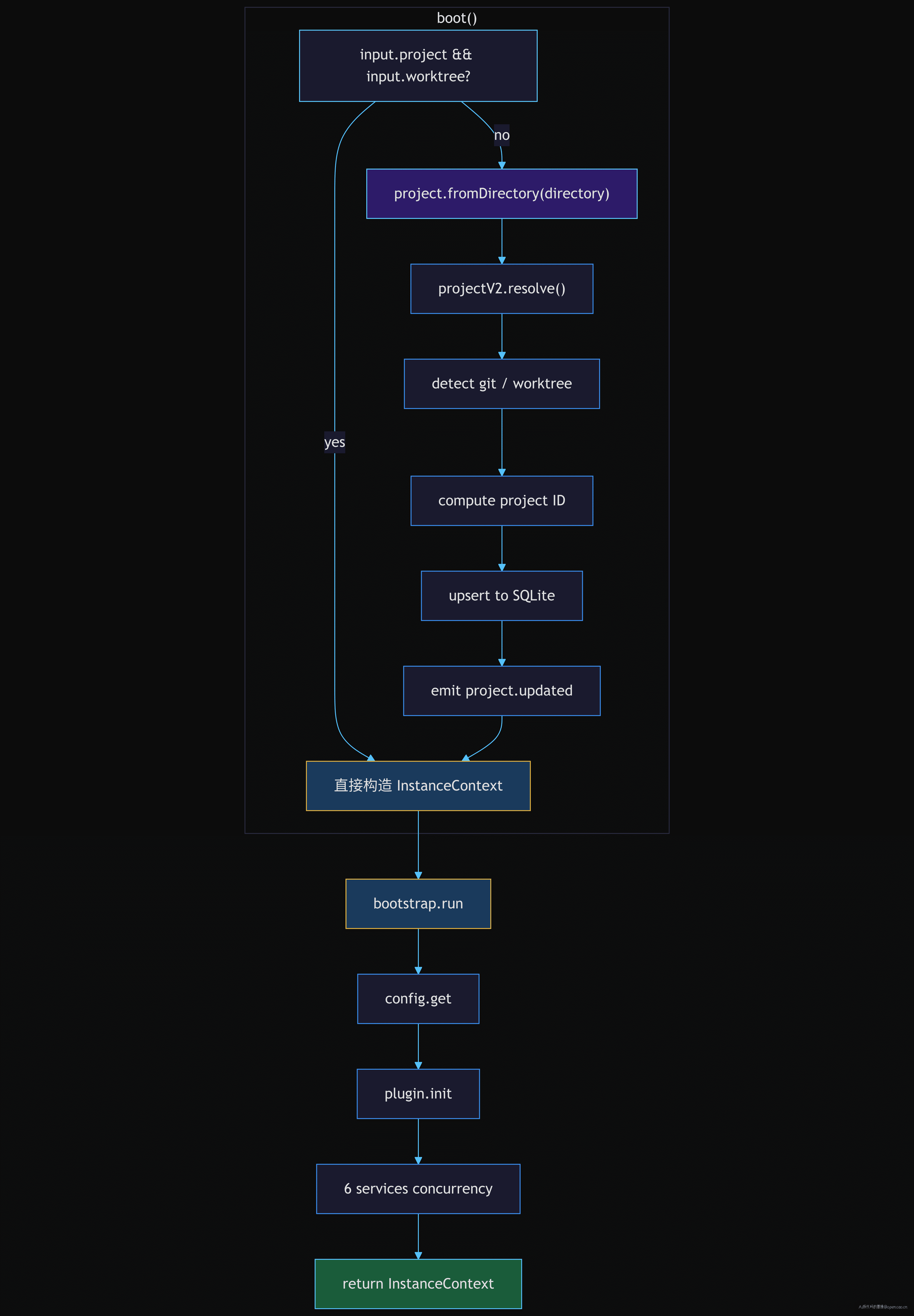
构建 InstanceContext 有两种路径:
- 热路径(input 已含 project + worktree):跳过 fromDirectory,直接构造
- 冷路径(大部分情况):调用 project.fromDirectory(directory) 发现项目
fromDirectory 内部做了什么?它调用了 projectV2.resolve() 去解析目录:检测是否在 git 仓库内、获取 worktree 路径、计算出 project ID。然后 upsert 到 SQLite 数据库,更新 sandboxes 列表,最后发射 project.updated 事件。
这个过程之所以存在,是因为 opencode 需要知道"当前目录对应哪个项目"——同一个 git 仓库的不同子目录启动,project ID 必须一致;不同仓库之间,project ID 必须不同。没有 fromDirectory,每个目录就是一个独立的项目,多个子目录之间的 session、权限、配置就无法共享。
config.get:全部配置的第一道关卡
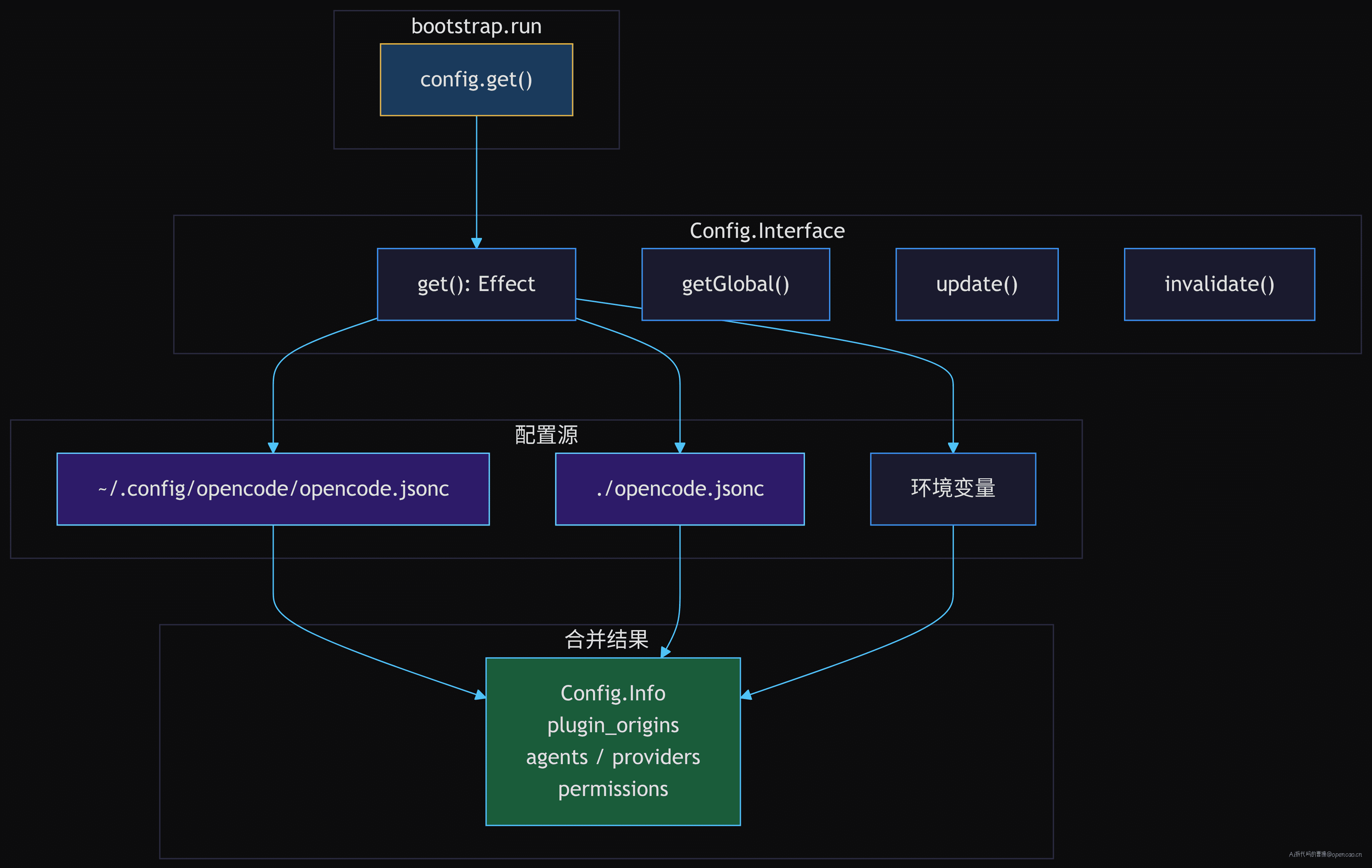
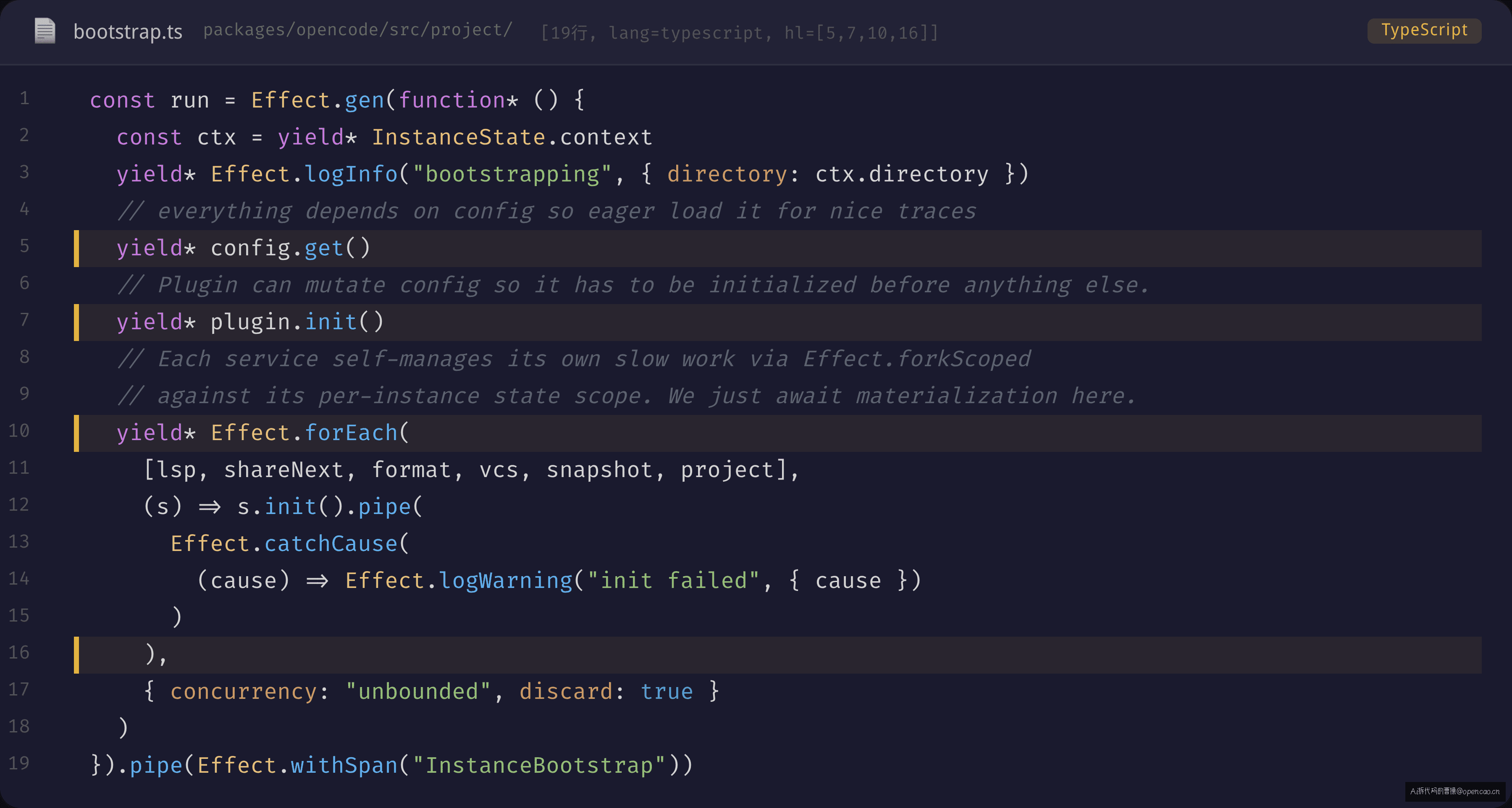
InstanceContext 构建完成后,bootstrap.run 调用 config.get():
// packages/opencode/src/project/bootstrap.ts:32-36
const run = Effect.gen(function* () {
const ctx = yield* InstanceState.context
yield* Effect.logInfo("bootstrapping", { directory: ctx.directory })
yield* config.get() // 第一步:配置加载
yield* plugin.init() // 第二步:插件初始化(可改配置)
// ... 6 个服务并发
})
config.get() 返回的是 Effect.Effect<Info>,这意味着它不会在 get 时重新读文件——配置的解析和合并已经在 Service 初始化时完成了。这个设计有一个重要的隐藏含义:配置加载是 eager 的,但不会随着每次 get 重复。
naive 方案可能每次 get 都重新读文件,确保配置最新——但 opencode 选择了"一旦就绪就不变"的契约。原因在于:配置影响了太多下游状态(Agent 列表、provider 凭证、权限规则),如果配置在运行中突然变化,Agent 的行为会变得不可预测。opencode 的配置热更新是通过专门的控制通道实现的,不是自动重读。
Config.Interface 定义了 6 个方法:
- get() — 获取当前项目配置
- getGlobal() — 获取全局配置(跨项目共享)
- update() / updateGlobal() — 写入配置
- invalidate() — 显式让缓存失效
- directories() — 配置源目录列表
配置合并是多层叠加:全局 ~/.config/opencode/opencode.jsonc → 项目级 ./opencode.jsonc → 环境变量覆盖。mergeConfigConcatArrays 确保数组字段(如 instructions)是拼接而非替换。
衔接下一节:配置就绪后,plugin.init() 被调用——但注意,它在 config.get 之后,这是有原因的。
【第二层】plugin.init() — 插件发现
插件必须先于其他服务的理由
回头看 bootstrap.run 的顺序:
yield* config.get()
// Plugin can mutate config so it has to be initialized before anything else.
yield* plugin.init()
yield* Effect.forEach(
[lsp, shareNext, format, vcs, snapshot, project],
(s) => s.init(),
{ concurrency: "unbounded", discard: true },
)
插件必须在其他服务之前初始化,原因只有一个:插件可以修改配置。
opencode 的插件系统里有一类特殊的「ConfigPlugin」。这类插件的初始化动作可能包括:从远程拉取配置模板、注入自定义的 Agent 定义、修改权限规则。如果先初始化了 LSP 或 VCS 服务(它们依赖于完整的配置),插件修改配置后这些服务可能工作在不一致的配置上——出现"LSP 用了旧的 provider 配置,但 Agent 用了新配置"的问题。
naive 方案可能会说:那把配置做成响应式的,服务监听配置变更不就行了?但问题是:配置变更不是增量事件驱动的——插件 init 是一个同步操作,在它完成之前,配置是不完整的。你在"配置一半"的状态下启动其他服务,这就跟汽车还没装好轮子就点火一样——也许走得动,但出问题的概率很高。
另一个方案是"所有服务都支持热重载,配置变了就重新 init"。opencode 没有走这条路,原因有二: 1. 复杂性代价:每个服务都需要实现配置变更监听、状态迁移、rollback,6 个服务 × 3 个状态约 18 个复杂度单元 2. 实际需求:配置在 bootstrap 阶段之后极少变更,为极低频场景增加永久复杂度不划算
所以作者选了最简单直接的方案——先 config、再 plugin、最后其他服务。一条直线,没有状态跃迁。
插件的发现与加载
plugin.init() 内部做三件事:
- 从配置中读取 plugin 字段(plugin spec 列表)
- 对每个 spec,做 resolve → 按 kind(server/tui)识别 entrypoint → 动态 import
- 加载成功后在 registry 中注册
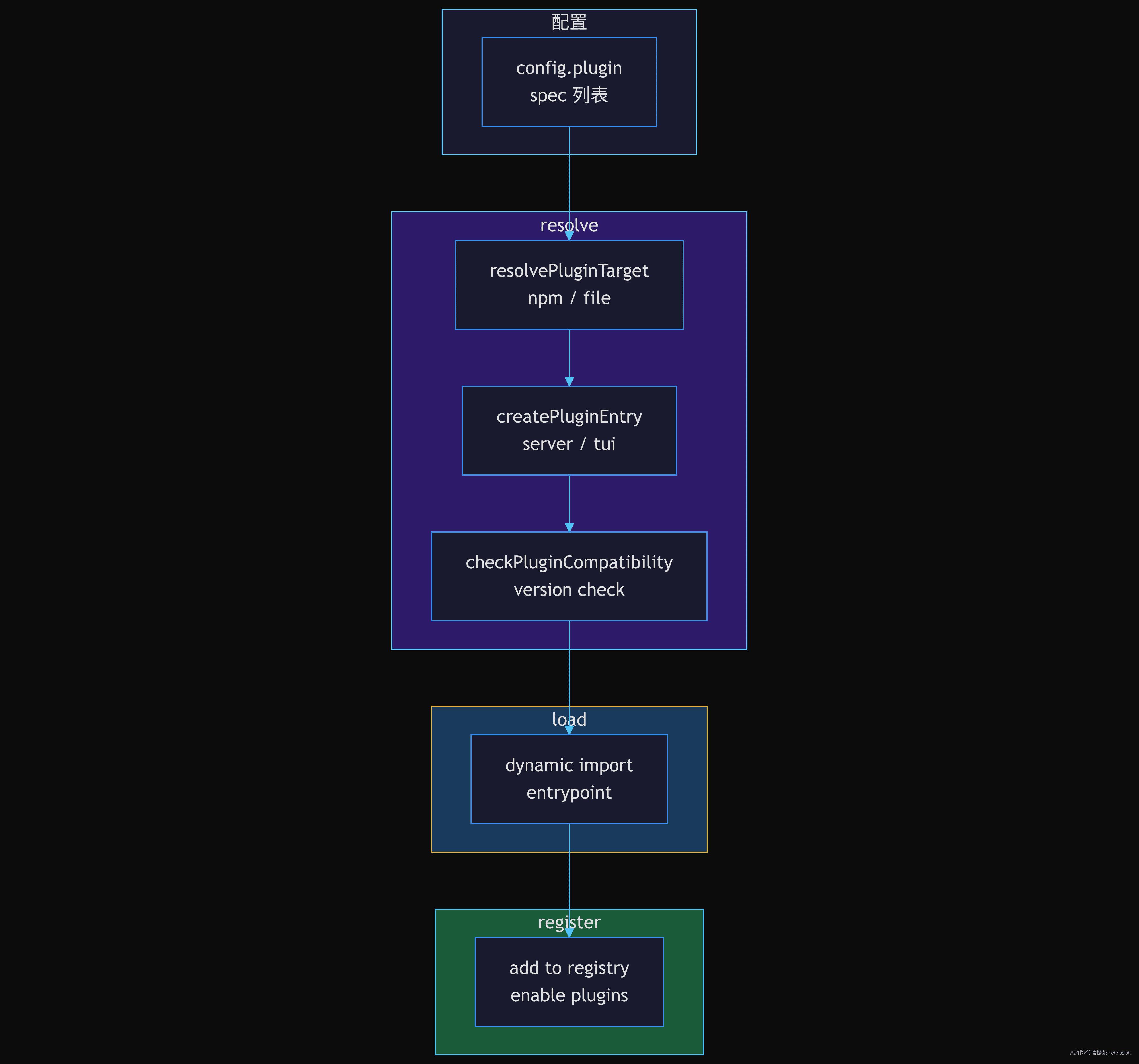
它的复杂度不在加载本身,而在降级策略:某个插件 resolve 失败时,是跳过、重试、还是终止整个 bootstrap?
opencode 的插件加载器在 packages/opencode/src/plugin/loader.ts 中定义了完整的三阶段管线:resolve(定位 target + 检测 entrypoint + 兼容性检查)→ load(动态 import)→ finish(注册到运行时)。如果 resolve 失败(比如 npm 包未安装——属于 "install" 阶段错误且是 file-plugin 时),会在 wait() 之后重试一次;其他阶段的失败永久跳过。
opencode 的选择是:"跳过,但记录"。plugin.init() 不会因为某个插件加载失败就阻止 Agent 启动——但如果插件是 config plugin(可以在 load 过程中修改配置),跳过它的后果可能已经影响到配置完整性。所以 config plugin 的加载其实是惰性且安全的:它们的影响通过 Effect 的 forkIn(scope) 隔离在自己的 Effect 沙箱中。
衔接下一节:插件初始化完成后,6 个服务并发启动。
【第三层】6 个服务并发 init
并发 init 的意图:谁需要快?
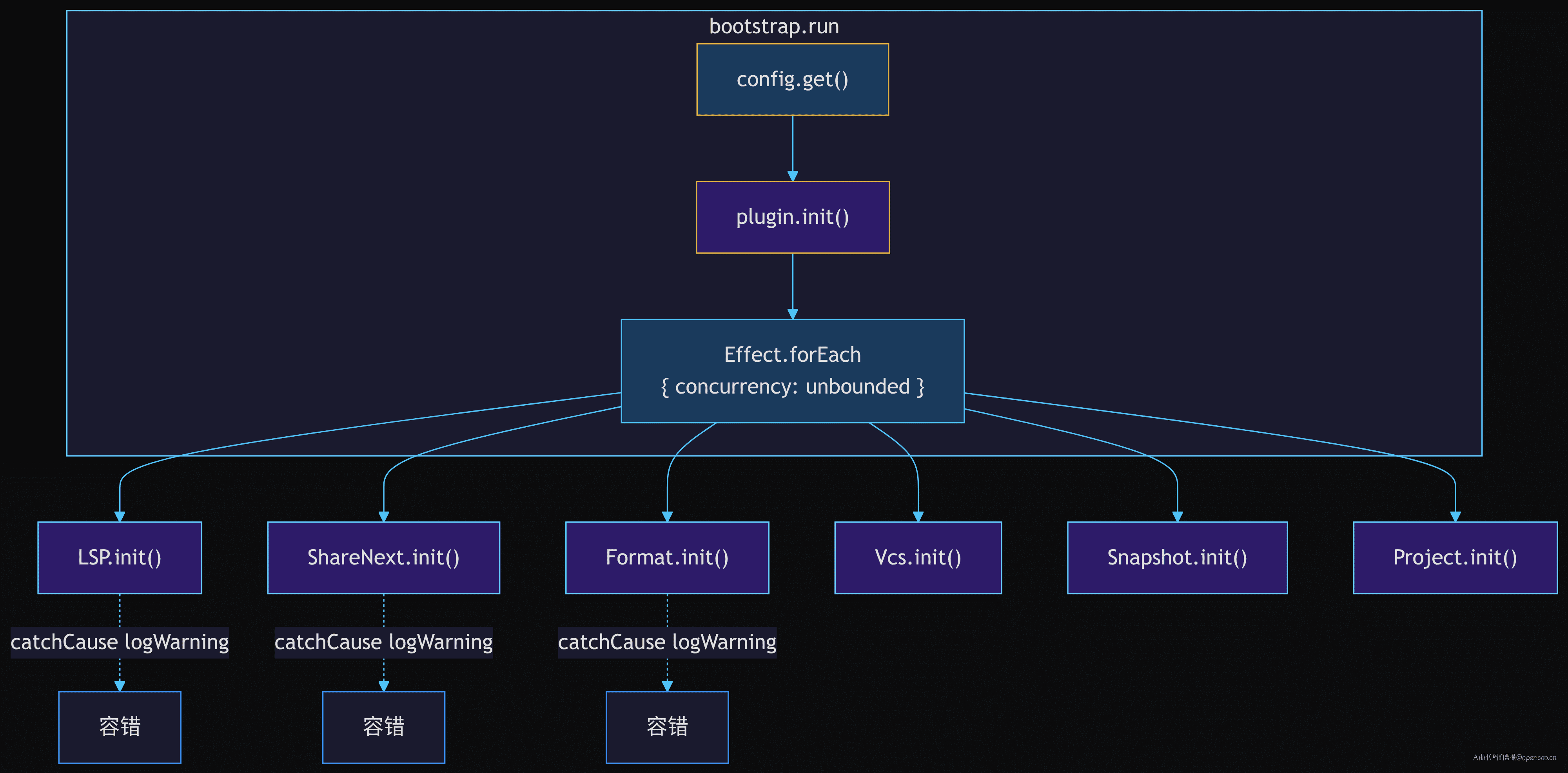
yield* Effect.forEach(
[lsp, shareNext, format, vcs, snapshot, project],
(s) => s.init().pipe(Effect.catchCause((cause) => Effect.logWarning("init failed", { cause }))),
{ concurrency: "unbounded", discard: true },
)
六个服务分别是:
- LSP — 语言服务器协议客户端,提供代码补全/诊断能力
- ShareNext — 分享与协作功能
- Format — 代码格式化
- Vcs — 版本控制(git)集成
- Snapshot — 快照管理,用于安全回退
- Project — 项目元数据管理(订阅 /init 命令)
这些服务有一个共同点:它们都对 Agent 不是立即可用的。用户输入问题后的第一反应(LLM 调用、工具执行)不需要它们。因此它们被设计为后台惰性初始化——即使某个服务 init 失败(走 catchCause → logWarning),Agent 仍然可以工作。
naive 方案可能把所有服务串行 init——保证顺序确定,好调试。但代价是:用户在 opencode run 之后要等 LSP 启动 → VCS 扫描 → Format 加载 → Project 注册……全跑完才看到提示符。opencode 选择了"容错并发"——每个服务自己管理生命周期(通过 Effect.forkScoped 在 per-instance scope 内启动),bootstrap.run 只负责 await 它们第一次具体化。
"容错"的心态
注意 catchCause 而不是 catchTag——它捕获所有类型的失败,不管是可以恢复的配置缺失,还是不可恢复的数据库错误。这看起来有点粗放,但意图明确:bootstrap 的目标是让 InstanceContext 可工作,不是完美。LSP 挂了?你仍然可以写代码提问。Snapshot 挂了?顶多是无法回退到上一个安全检查点。
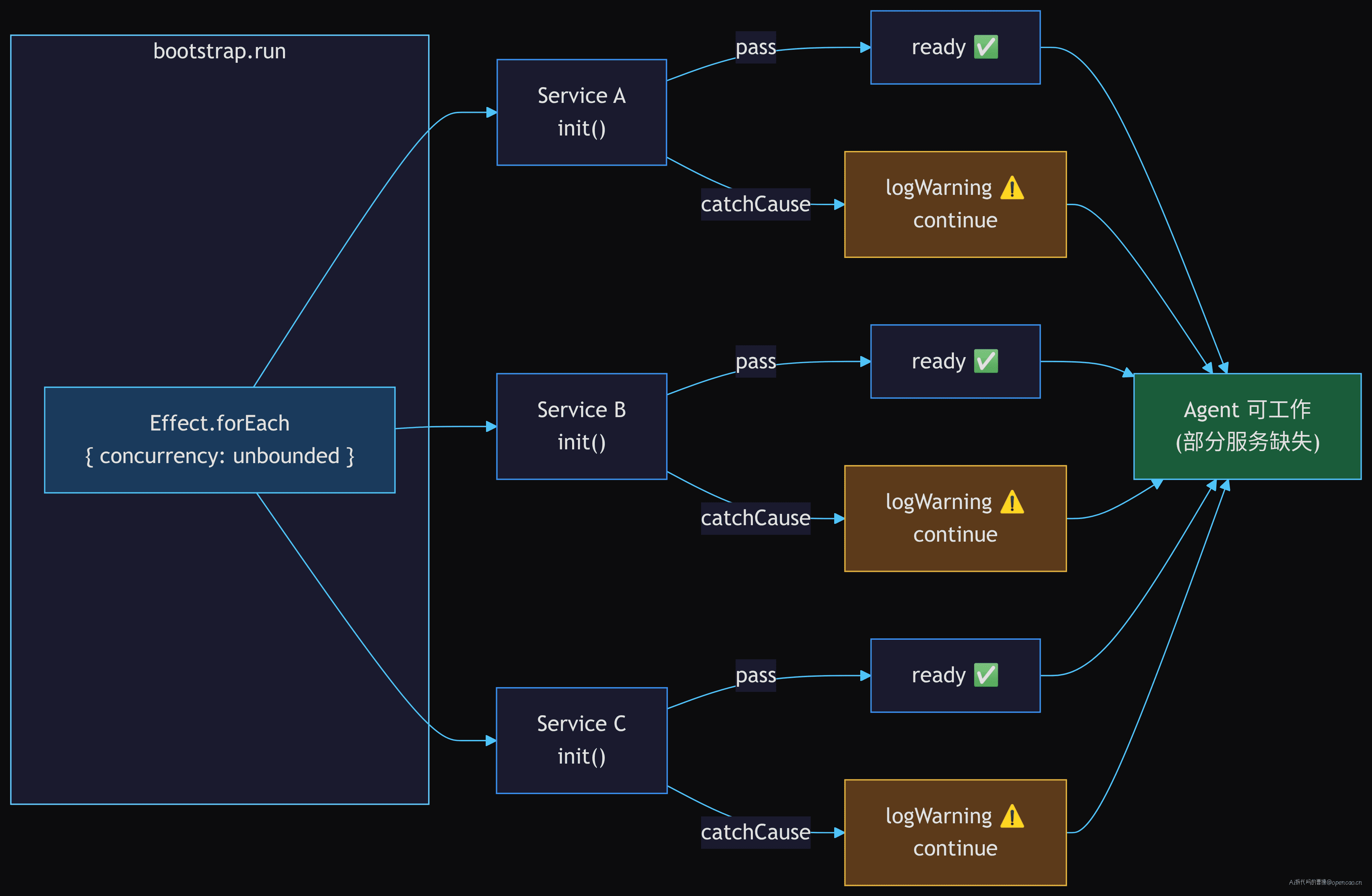
这张图展示了关键设计:6 个服务中任意一个失败(走 catchCause → logWarning),不影响其他服务的 init 结果。三个服务的 init 路径汇总到同一个 DONE 状态——Agent 可以带着"部分服务缺失"继续工作。naive 方案可能会让任何一个服务的失败阻断整个 bootstrap(比如抛出异常终止),但 opencode 选择了"能用比完美更重要"的哲学。
每个服务的 init() 内部也遵循类似的容错策略。比如 Project.init() 只是通过 InstanceState.get(initState) 等待范围订阅就绪:
// packages/opencode/src/project/project.ts:427-429
const init = Effect.fn("Project.init")(function* () {
yield* InstanceState.get(initState)
})
它只是 await 了一个缓存的 Effect——实际的订阅创建在 InstanceStore.boot() 之前的 InstanceState.make() 中就已经完成了。这意味着 init 不会失败,因为它只是"等一个已经启动的协程"。
衔接下一节:三层初始化的顺序为什么是 config → plugin → 6 services?有替代方案吗?
【权衡】bootstrap 顺序为什么是这个顺序?
三种可能的初始化排序
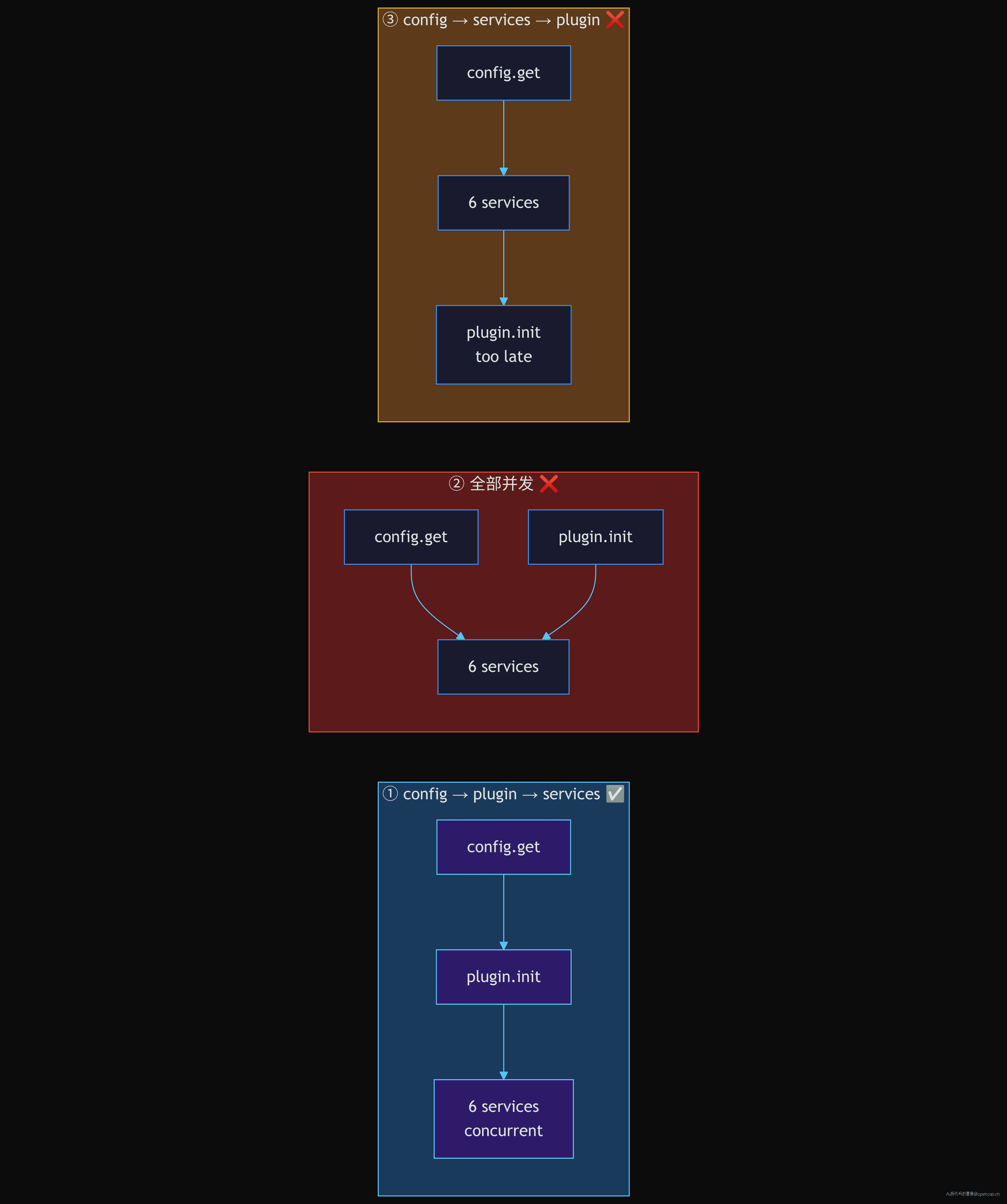
用一个表对比三种可能的顺序:
| 顺序 | 方案 | 问题 |
|---|---|---|
| ① | config → plugin → 6 services | ✅ opencode 的选择。plugin 可改 config,6 services 不需要等待 plugin 完成 |
| ② | 全部并发 | plugin 可能在 config 完成之前执行——如果 plugin 依赖 config,出现问题 |
| ③ | config → 6 services → plugin | 6 services 在配置完整的状态下启动,但 plugin 对 config 的修改无法被 6 services 感知 |
为什么不是 ②「全部并发」?因为 config plugin 需要在配置就绪后才能执行——它的本质是"修改已经加载的配置"。全部并发意味着你不知道 config plugin 读到的配置是不是最终版。opencode 的 config plugin 场景虽然不多,但一旦出现(比如远程配置注入),顺序错误的影响是致命性的——Agent 可能用错误的 provider 配置跑完全程。
为什么不是 ③「config → 6 services → plugin」?因为 6 services 中的某些服务(如 Format、VCS)的初始化路径可能依赖 plugin 注册的扩展点。如果 plugin 在服务之后加载,这些服务就看不到 plugin 添加的能力——虽然目前 opencode 的 6 个服务没有深层依赖 plugin,但这个顺序为未来留下了灵活性。
所以 ① 是唯一正确的顺序:config 最先(不可动摇)→ plugin 其次(因为它能改 config)→ 6 services 最后(容错并发)。
这段顺序代码的更深层意义
回头看 bootstrap.run 的完整源码:

5 条 statement,定义了 config + plugin + 6 services 三层的执行顺序。但更重要的是注释:
// Each service self-manages its own slow work via Effect.forkScoped against
// its per-instance state scope. We just await materialization here.
这句注释揭示了 bootstrap.run 的本质:它不是一个"init 控制者",而是一个"init 等待者"。6 个服务的实际初始化是在 InstanceState.make() 时通过 registerDisposer 注册的——它们早就启动在后台了。bootstrap.run 只是等待它们第一次准备就绪。
这跟 naive 方案"bootstrap 执行完所有初始化动作"的预期完全不同。opencode 的作者把 bootstrap 设计成了一个"就绪信号的收集器",而不是"初始化动作的执行器"。
【锚点】Bootstrap = 运行时就绪协议
总结三层职责
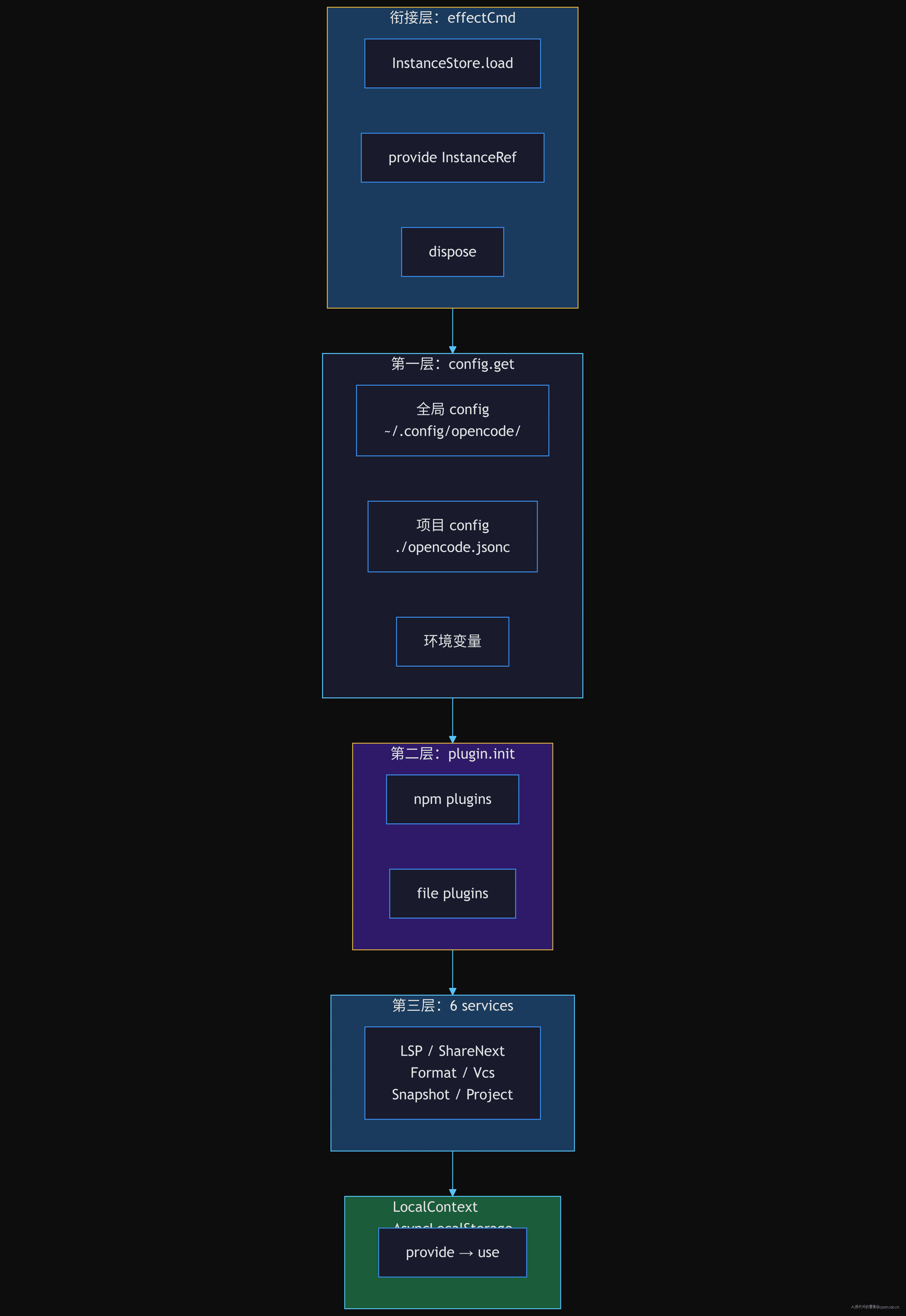
整个 bootstrap 链条可以浓缩为三层:
- 衔接层:effectCmd 捕获三条命令生命周期(load→handler→dispose),
InstanceRuntime桥接 Effect ↔ Promise 边界 - 第一层——config.get:多层配置合并,一次性加载后冻结,不被自动重读干扰
- 第二层——plugin.init:config plugin 必须先于其他服务,因为它的本质是"修改已加载的配置"
- 第三层——6 services:容错并发,每个服务自管理生命周期,bootstrap.run 只收集就绪信号
三层不是三个串行步骤——config → plugin 是串行(plugin 依赖 config),但 6 services 是并发的、有错容忍的。这个排序规则的精确原因是:config 不可动摇,plugin 能改 config,6 services 不需要等待 plugin 完成。
naive 方案假设 bootstrap 是一个线性的初始化过程——做完 A 做 B,做到 Z 就完事了。但 opencode 的 bootstrap 更像是一个"准备就绪"协议:config.get 确保配置能读、plugin.init 确保插件能加载、6 services 的 init 确保它们都 fork 到后台了。至于它们什么时候真正初始化完成——这不阻塞 bootstrap 的退出。
核心模式
Bootstrap 不做事——它等人。
不是 init 执行器,是 ready 信号收集器。
这个模式在分布式系统中很常见(如 Kubernetes 的 readiness probe),但在 CLI 工具的启动流程中并不多见。opencode 把它用在一个单进程 CLI 应用的启动中——因为它的启动链不是"按顺序做完 A→B→C",而是"确保 A、B、C 各就各位,然后发令枪响"。
InstanceContext 的生命周期不仅限于 CLI。在 opencode 的 Server 模式和 HTTP API 中,InstanceStore 提供了 provide 方法来允许 Effect 运行在指定上下文下——同一个服务进程可以为多个目录的请求提供服务,每个请求独立 bootstrap 和 dispose。
这一切的根基是一个 17 行的 AsyncLocalStorage 封装:
// packages/opencode/src/util/local-context.ts:9-23
export function create<T>(name: string) {
const storage = new AsyncLocalStorage<T>()
return {
use() { ... },
provide<R>(value: T, fn: () => R) { ... },
}
}
被 InstanceContext、WorkspaceContext、SessionContext 三个模块依赖。Node.js 的 AsyncLocalStorage 保证了即使在异步链(Promise / setTimeout / Effect 调度)中,use() 也能拿到正确的上下文。没有这个机制,bootstrap 的三层职责就无法传播到下游代码——每一层都要手动传参,而手动传参往往是泄漏和 Bug 的温床。
衔接 02-03
下一篇文章(02-03)我们来看 run 命令全流程:当 bootstrap 完成、InstanceContext 就绪、所有后台服务各就各位之后——opencode run 如何启动 Agent Loop、处理用户输入、跨度漫长的工具调用链。如果说本文是"发令枪响之前",下一篇就是"发令枪响之后"的全部。


