
斜杠命令系统:/review /commit /diff 背后的引擎
如果你要设计一个 AI Agent 的斜杠命令系统 —— 用户在对话框输入 /review,Agent 就自动审查代码变更 —— 你会怎么实现?
一个直观的想法是 if (input.startsWith('/review')) { reviewHandler() } —— 每加一条命令改一次 if-else 链。
opencode 的选择完全不同:可插拔的命令注册表 + 模板注入管道。/review 的本质不是调用一个函数,而是加载一个 101 行的 LLM 提示词模板,替换参数,扔给模型执行。这套系统支持 2 个内置命令 + 任意数量的用户配置命令、MCP 服务暴露的 prompts、技能包自动注册 —— 三个来源并行注入,互不干扰。
开篇:命令系统的全景图
斜杠命令的两种形态
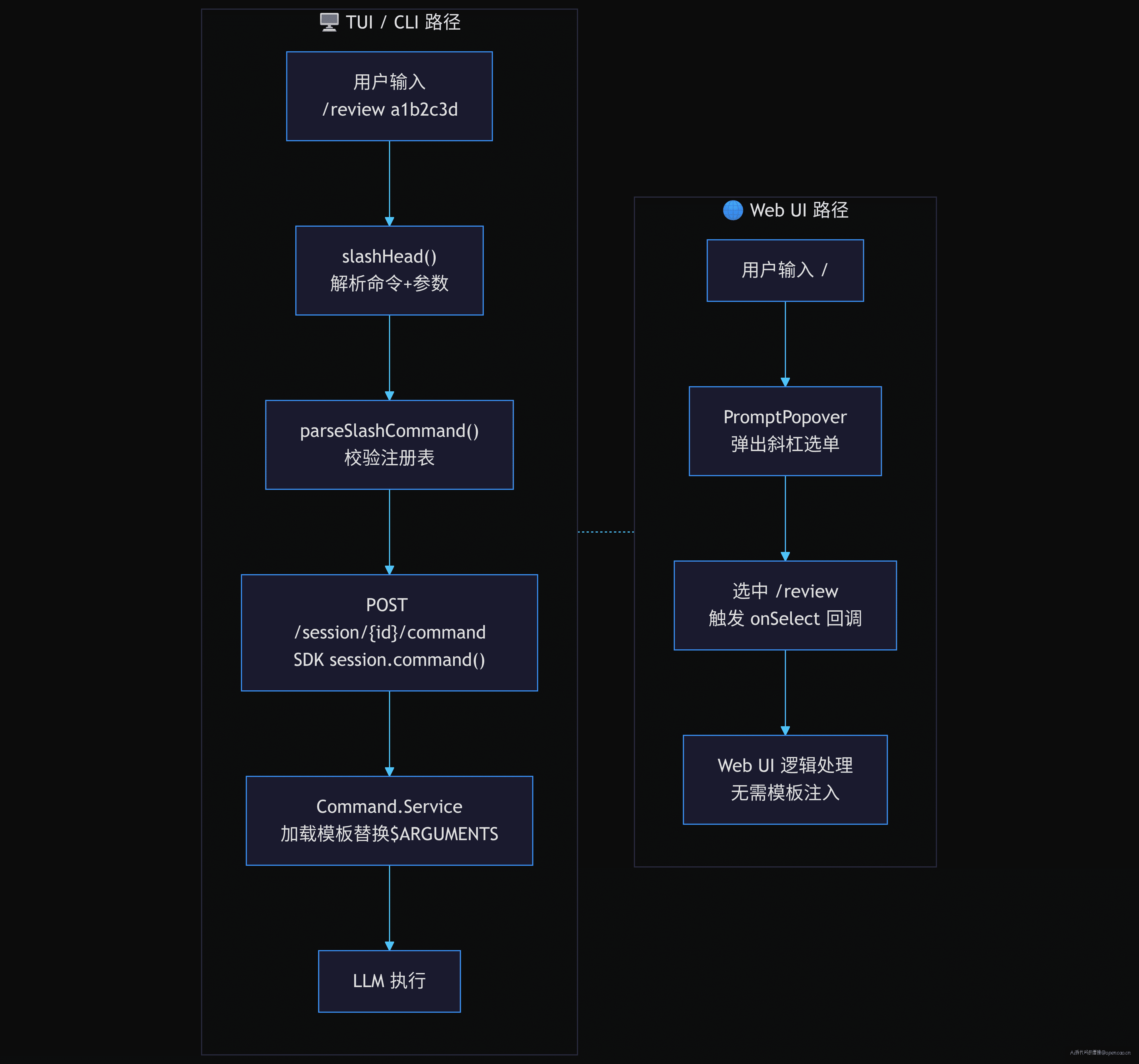
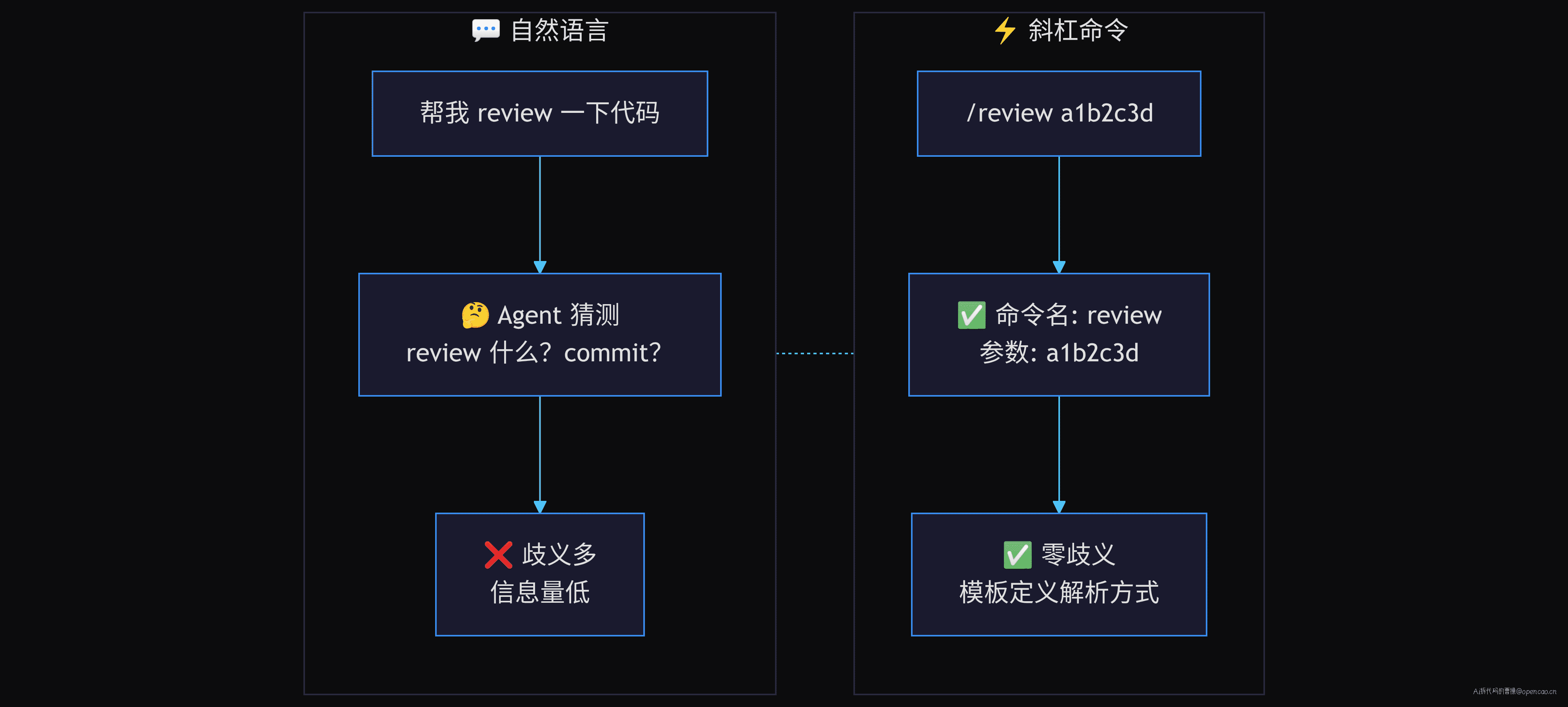
opencode 有两套并存的斜杠命令系统。等一下,两套? 对——不是一套系统在终端和 UI 之间复用,而是两套独立的实现,各自解决不同的问题。
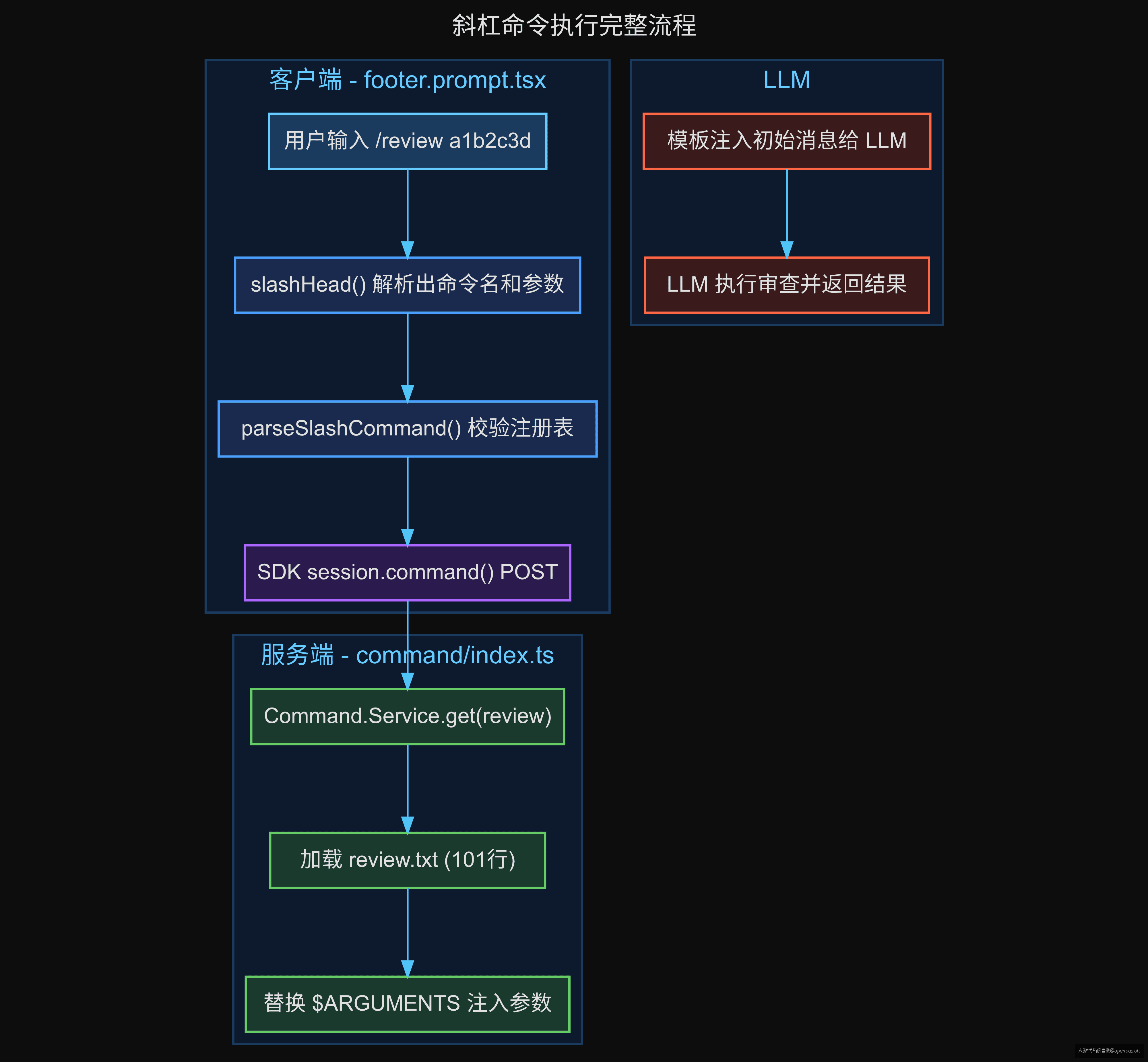
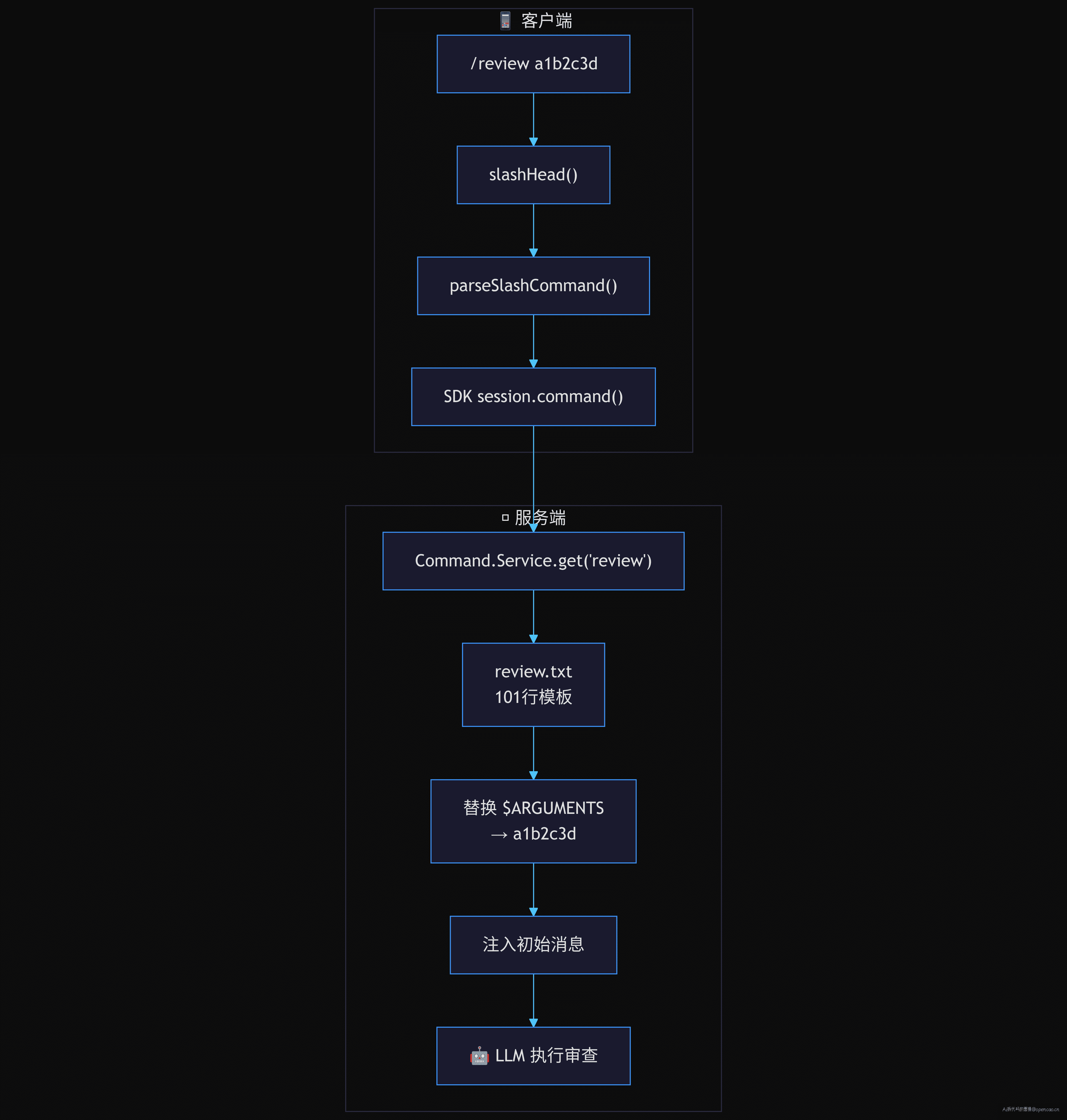
第一套是 TUI 模式(终端交互)。用户在底部 prompt 输入 /review a1b2c3d,经过 slashHead() 解析为 { name: "review", arguments: "a1b2c3d" },由 parseSlashCommand() 校验命令是否在服务端注册表中。如果命中了,prompt 通过 POST /session/{id}/command 发送,服务端加载对应的模板文件,替换 $ARGUMENTS,注入到 LLM 的初始消息中。这一套的核心是模板注入——命令不执行函数,只加载模板。
第二套是 Web UI 模式(桌面端浏览器界面)。命令通过 command.register() 注册为 CommandOption,带 slash: "review" 属性。用户在输入框输入 / 时弹出 PromptPopover 选单,选择后触发 onSelect 回调。总共有 12 个斜杠命令:/new、/undo、/redo、/compact、/fork、/share、/unshare、/open、/terminal、/model、/mcp、/agent。这一套的核心是回调路由——命令直接触发 UI 逻辑。
这两个系统面向的场景不同,但解决的是同一个问题:如何让用户以结构化方式表达意图? 一个用模板驱动 LLM,一个用回调驱动 UI,各司其职。
跨项目对比
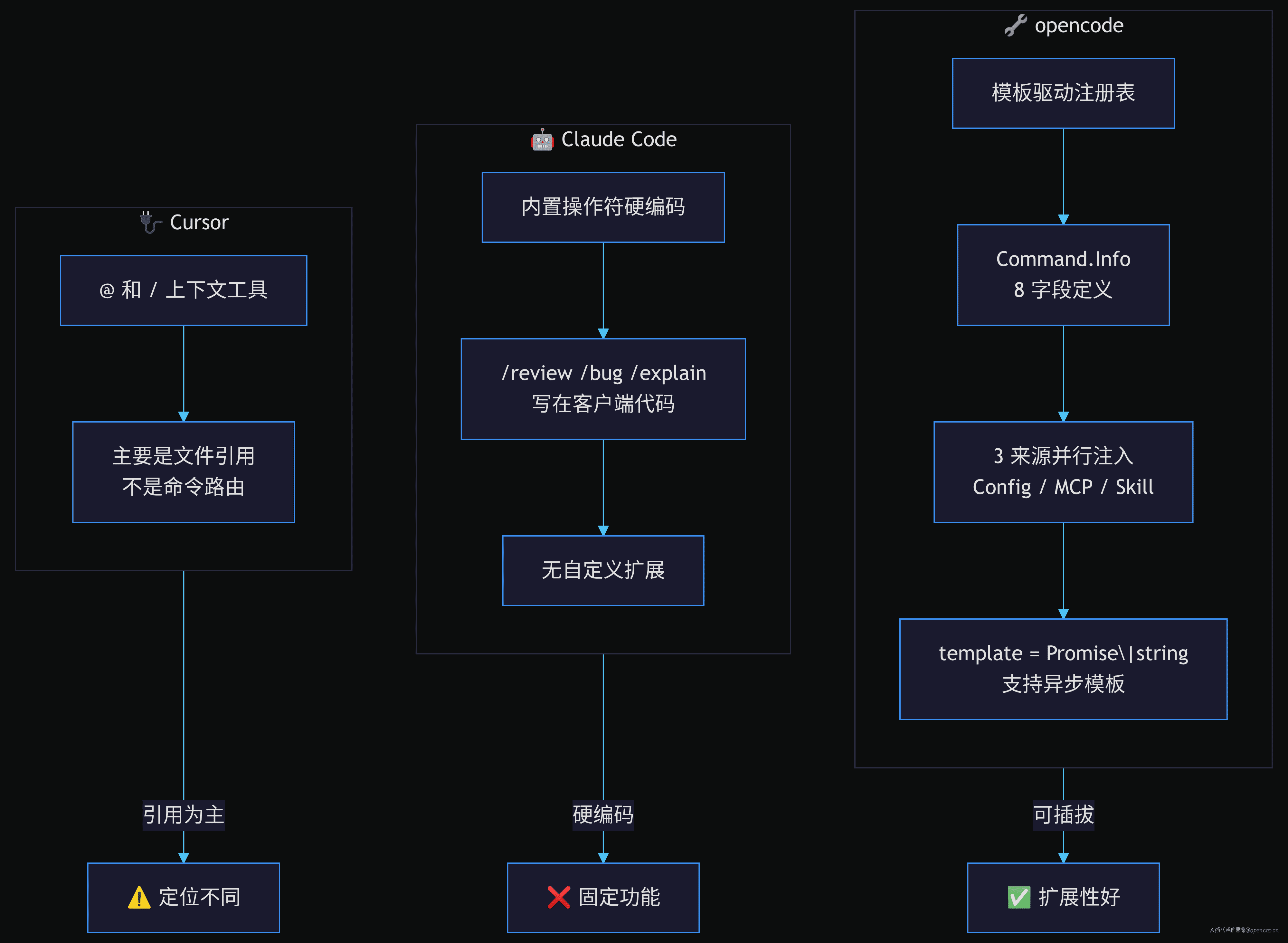
Claude Code 的斜杠命令是内置操作符硬编码 —— /review、/bug、/explain 是写死在客户端代码里的。Cursor 的 @ 和 / 主要是上下文工具引用,不是命令路由。
opencode 的选择:模板驱动注册表。新增一条命令不需要改客户端代码,只需要写一个 .txt 提示词模板,然后在配置/技能/MCP 中注册。从零新建一条命令的流程:写模板 → 配置声明 → 重启 session。这个模式让命令系统变成一个扩展点,而不是功能清单。
章节路线图
本篇拆解斜杠命令系统最核心的机制:
- 为什么需要斜杠命令——从自然语言到结构化指令的进化
- 核心抽象——Command.Info 8 个字段定义一切命令
- 主流程——从 /review 到 LLM 的完整管道
- 是否该用 switch-case——注册表方案的取舍
下一篇拆解 /config 命令:配置管理的命令行入口。
为什么需要斜杠命令?
当自然语言不够精确
如果你对 Agent 说:"帮我 review 一下代码",Agent 需要猜测:review 什么?是工作区所有变更?特定 commit?还是某个 PR?
斜杠命令让这变得精确:/review a1b2c3d 明确告诉 Agent:命令是 review,参数是 commit hash a1b2c3d。零歧义。
这种结构化的价值在 /review 模板中体现得很清楚:
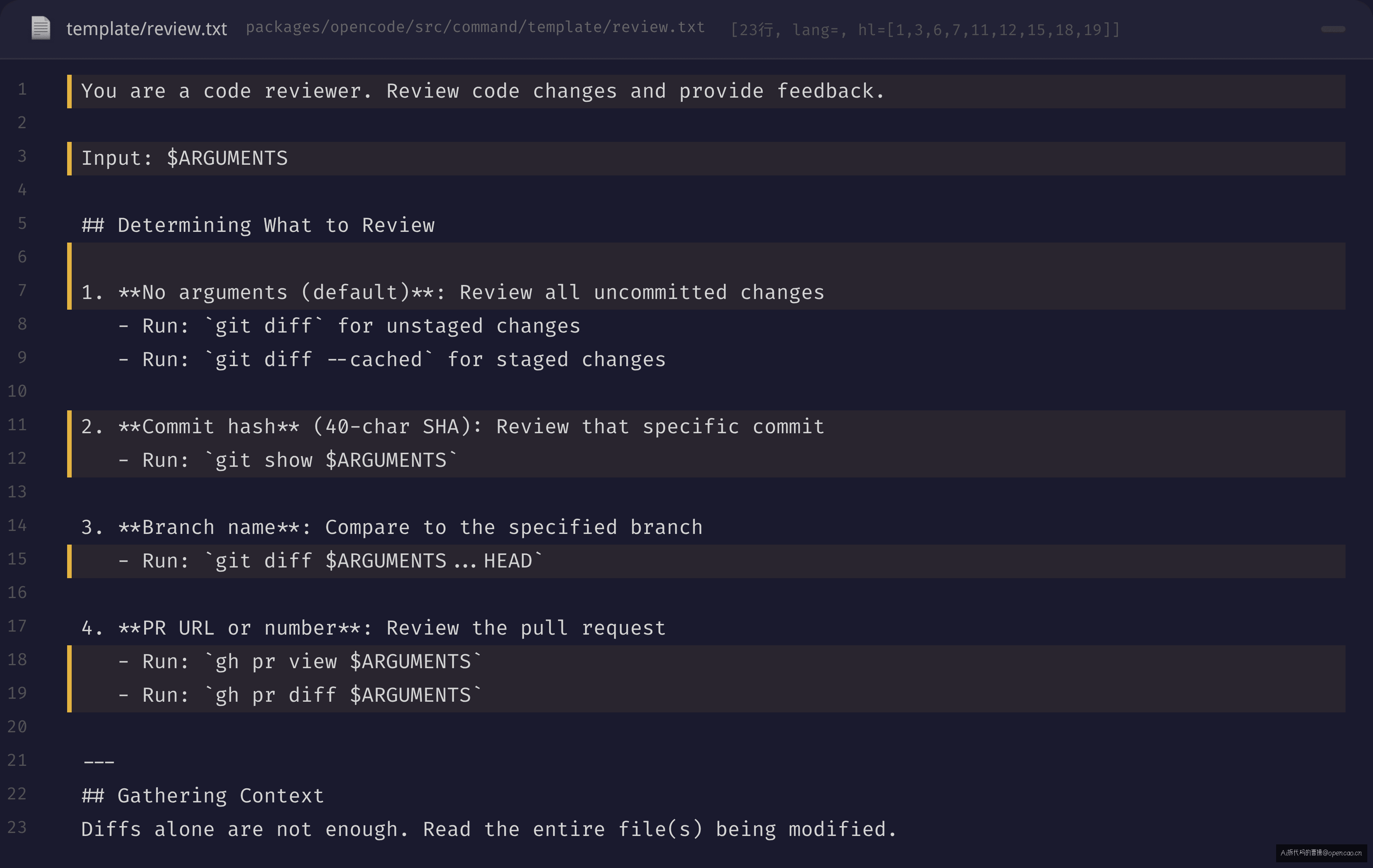
模板定义了 4 种输入场景:无参数走 git diff,40 位 SHA 走 git show,分支名走 git diff branch...HEAD,GitHub URL 走 gh pr diff。解析逻辑全部在模板里,不在代码里。
这就是斜杠命令的核心价值:把"意图解析"从客户端代码移到服务端模板。客户端只负责把 { command: "review", arguments: "a1b2c3d" } 发出去,具体怎么解释 a1b2c3d 是模板的事情。
naive 方案在这就撑不住了
如果采用 if-else 硬编码,每个命令的模板、参数解析、校验逻辑都写在客户端。opencode 有 2 个内置命令,加上用户自定义配置命令、MCP 服务暴露的 prompt、技能包自动注册,总命令数量在运行时不可预测。这显然不是 if 语句能解决的规模。
核心抽象:一个 Info 定义走天下
Command.Info 的 8 个字段
整个命令系统的核心是一个 Schema 定义:
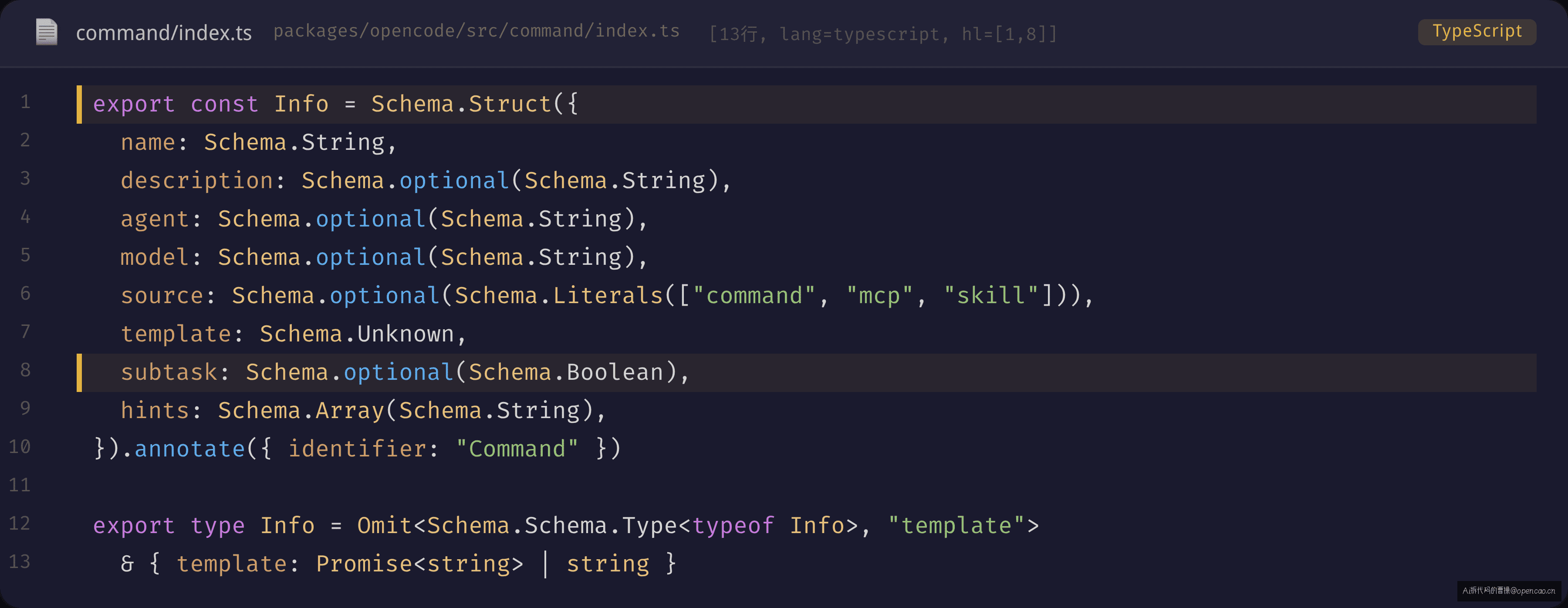
8 个字段定义一条命令的一切。最关键的字段是 template —— 它的类型是 Schema.Unknown,注释写得很清楚:有些命令模板是 MCP 远程解析的懒加载 Promise,不是静态字符串。
你可能会想:为什么不用 string 而是用 Unknown?这不就丢了类型安全吗?
作者的选择恰恰相反:Unknown 不是放弃类型,而是拥抱两种加载模式。 静态模板在初始化时就拿到字符串,MCP 模板在首次访问时才触发 RPC。如果设计成 string,所有命令初始化时都要 await,MCP 不可用时 session 启动就会阻塞。一个 Unknown 字段同时承载了同步和异步两种状态——这是 Effect-ts 生态里常见的"类型驱动设计"模式:用类型系统的能力表达运行时的灵活性,而不是被类型系统束缚。
hints 字段由 hints() 函数从模板文本中提取:扫描 $1、$2 这类编号占位符和 $ARGUMENTS 关键字。提取结果用于给 SDK 客户端做参数校验提示。
三层架构
命令系统分三层:
Info(数据描述)→ Service(查询接口)→ InstanceState(会话级状态)
第一层 Info 定义命令的数据结构。第二层 Service 提供 get(name) 和 list() 两个方法接口:
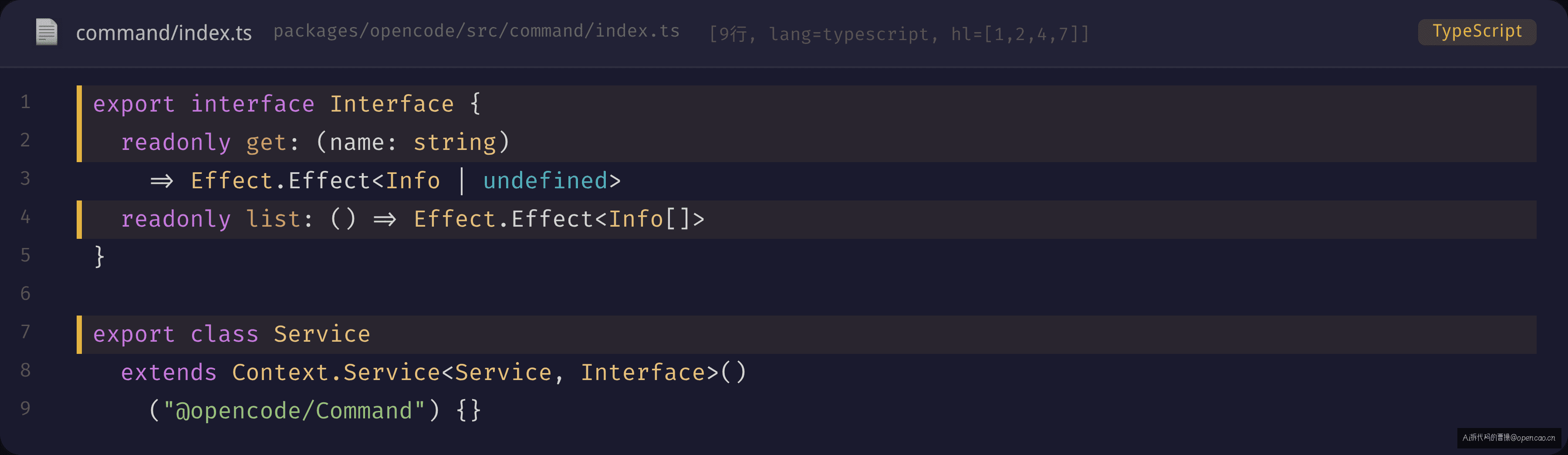
第三层 InstanceState(InstanceState —— Effect-ts 的状态管理模式,相当于 React 的 useState 但支持 Effect 的依赖注入)保证每个会话(session)都有自己的命令注册表快照。当用户修改 opencode.json、添加 MCP 服务、安装技能包时,命令注册表在当前会话中热更新,不影响其他会话。
三个来源并行注入
命令注册在 init 函数中完成,三个来源依次灌入同一个 commands 字典:

Config 命令:从用户 opencode.json 的 command 配置读取。这是用户自定义入口,通常用于添加团队专用模板,比如 /deploy、/code-review、/api-doc。每个配置命令可以指定 agent、model,让不同命令使用不同的 Agent 和模型。
MCP 命令:从 MCP 服务暴露的 prompts 中读取。这是命令系统的异步来源 —— MCP 的 getPrompt() 需要做 RPC 调用。template 字段是一个 bridge.promise() 封装的懒加载值,首次访问时才触发远程解析。这个设计保证 session 初始化不会因为 MCP 服务不可用而阻塞。
Skill 命令:从已安装的技能包自动注册。技能包的内容本身就是模板。命名冲突时 Config 命令优先覆盖 Skill 命令(因为循环顺序:Config 先注册,Skill 跳过已存在的 name)。
这就是命令系统的核心架构模式:扁平注册表 + 优先序覆盖。 不是分层路由,不是级联查找——就是一个字典,写在前面的赢。简单到让你怀疑:就这?对,就这。因为这三个来源的唯一消费者是 list() 和 get() 两个方法,它们需要的唯一能力就是"查询"。一个 Map 足够了。
你可能会想:为什么不让三个来源各自维护一个注册表,而是合并到同一个字典?
作者的选择是:查询路径只有一条。不论命令来自哪里,消费方(客户端、SDK、LLM)看到的都是一个扁平的 name → Info 映射。如果分层存储,Service.list() 就需要做三层归并,引入不必要的复杂度。合并产生的命名冲突成本由注册顺序约定解决,比运行时归并更简单。
主流程:从 /review 到 LLM 的完整管道
第一步:slashHead——斜杠解析器
当用户在 TUI 底部 prompt 输入 /review a1b2c3d 时,首先触发的是 slashHead() 函数:

这个函数的逻辑极其简单:从头扫描到第一个空白字符,斜杠后面、空格前面的文本是命令名,之后的是参数。从架构角度看,这里的 simplicity 是刻意的 —— 解析逻辑越简单,客户端和服务端的契约就越清晰。
第二步:parseSlashCommand——命令校验
解析出 { name: "review", arguments: "a1b2c3d" } 后,parseSlashCommand() 查询服务端命令注册表验证这个命令是否存在:
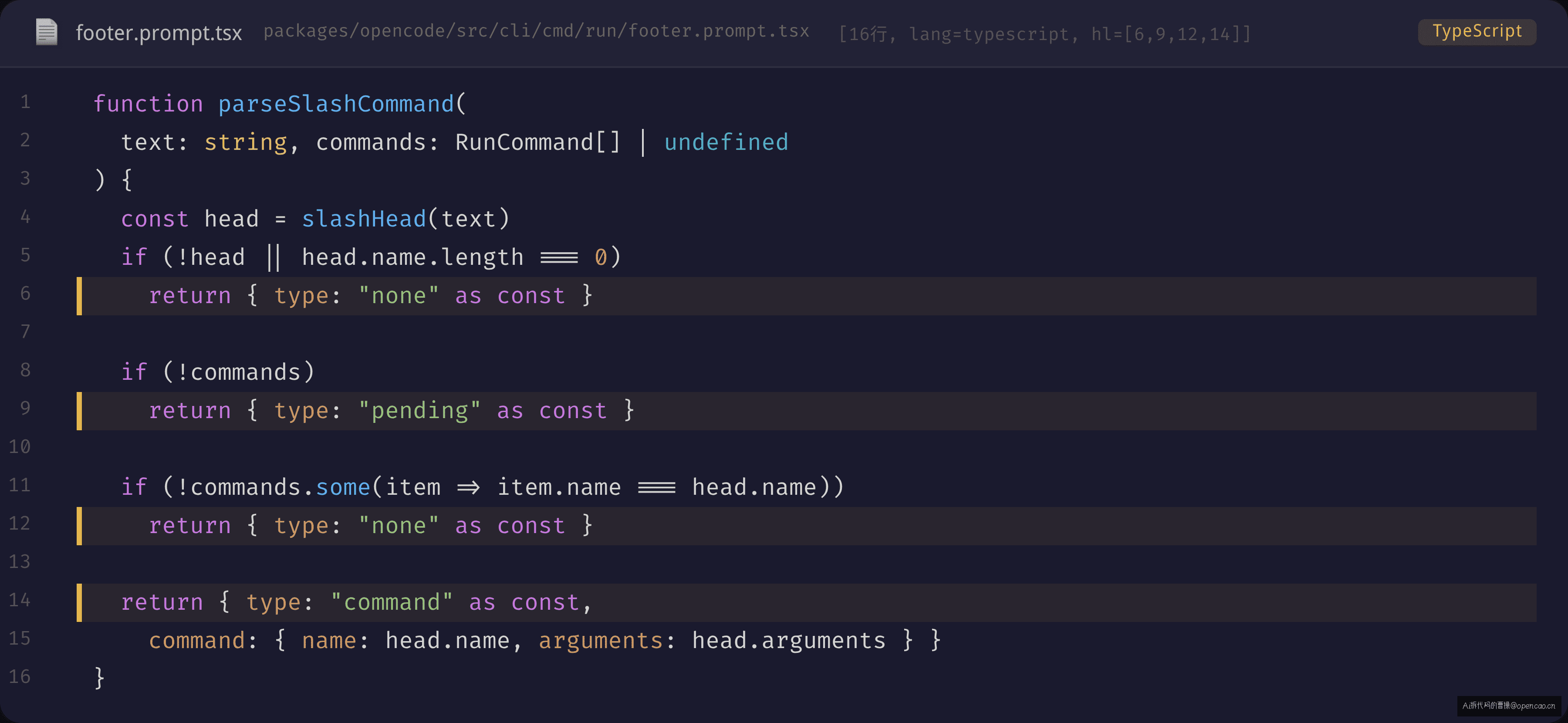
注意 pending 状态:当命令列表尚未从服务端加载完成时,parseSlashCommand 返回 pending,提示用户"loading commands"。这个小小的状态处理解决了初始化时序问题 —— 服务端注册表可能还没传过来,用户已经开始敲斜杠了。
第三步:SDK 发送命令
校验通过后,prompt 被标记为 command 模式,不再走普通 prompt 路径。在 stream.transport.ts 中,当 next.prompt.command 存在时,调用 SDK 的 session.command() 而非 session.promptAsync():
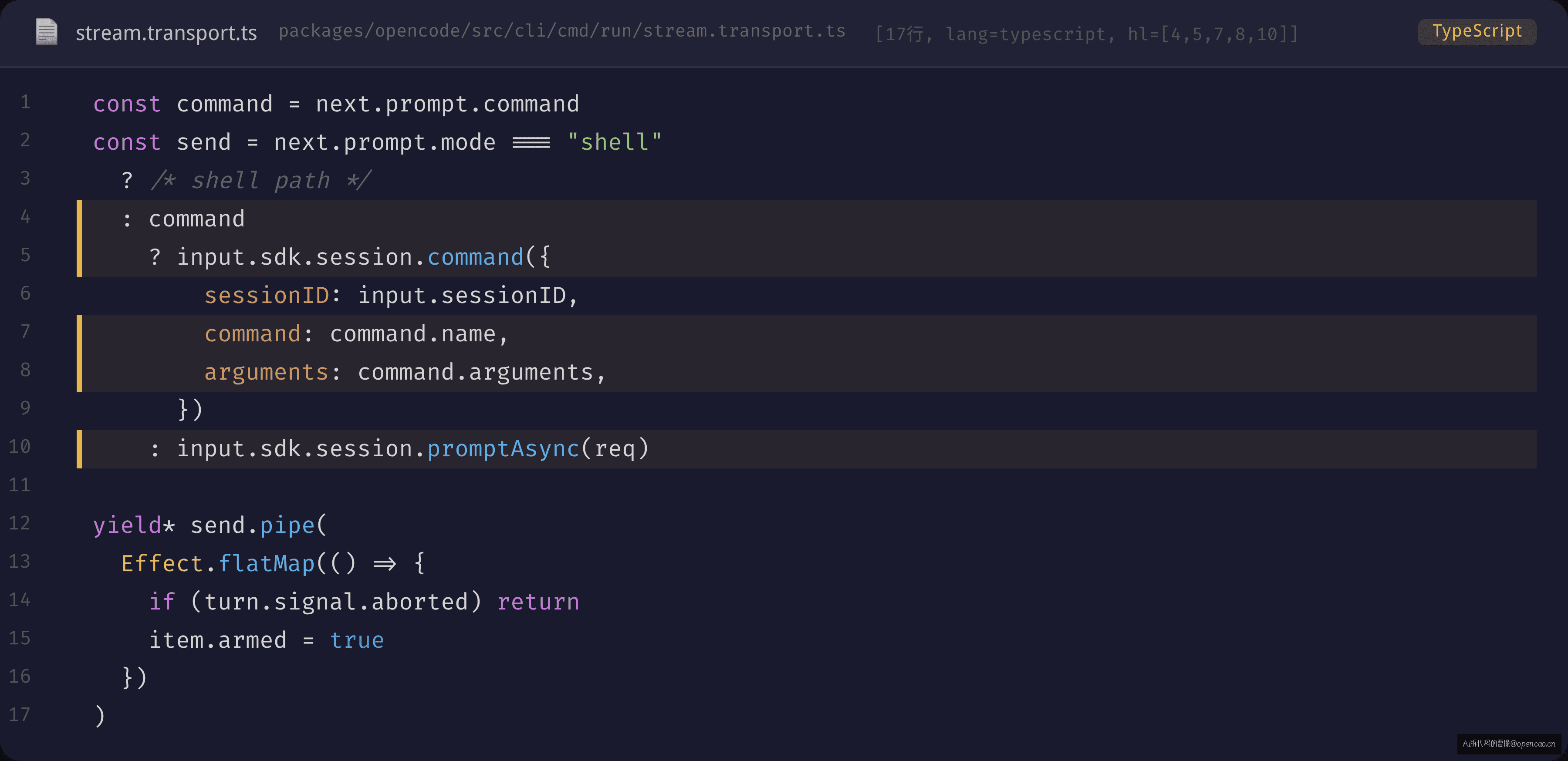
第四步:服务端加载模板
服务端收到 command 请求后,通过 Command.Service.get("review") 获取命令的 Info,拿到 template 字段(参考文首完整流程图中"服务端"部分)。对于内置命令,template 是一个 getter,加载对应的模板文本文件并替换 ${path}。
review.txt 模板 101 行,initialize.txt 模板 66 行。模板内容以对话视角覆盖了完整的审查场景。
模板中的 $ARGUMENTS 占位符由服务端替换为用户实际输入。模板还定义了参数校验规则:无参数 → git diff,40位SHA → git show,分支名 → git diff...HEAD,GitHub URL → gh pr diff。
第五步:模板注入初始消息
替换完成的模板作为初始消息注入 LLM 对话。LLM 看到的第一个消息就是这个模板,相当于"你现在是一名代码审查者,用户提供的参数是 xxx"。这就是 /review 的真正本质:不是执行一个函数,而是加载一段提示词模板替换参数后注入 LLM。
你可能会想:那 /commit 和 /diff 呢?它们和 /review 共享同一套机制。/commit 对应一个不同的模板,核心逻辑是生成符合 Conventional Commits 规范的提交信息。/diff 也是同理,模板指导 LLM 如何理解 diff 输出并总结变更。
三个命令本质上共享同一个架构模式:斜杠 → 命令名 → 模板加载 → 参数注入 → LLM 执行。不同的只是模板文件的内容。
为什么不是 switch-case?
naive 方案的缺陷清单
如果当初选择 if-else 或 switch-case,在 opencode 的场景下会暴露三个致命问题。分析这些问题的过程揭示了一个普遍规律:当扩展点的来源从"一个开发团队"变成"多个第三方"时,注册表就从"可选的"变成"必需的"。
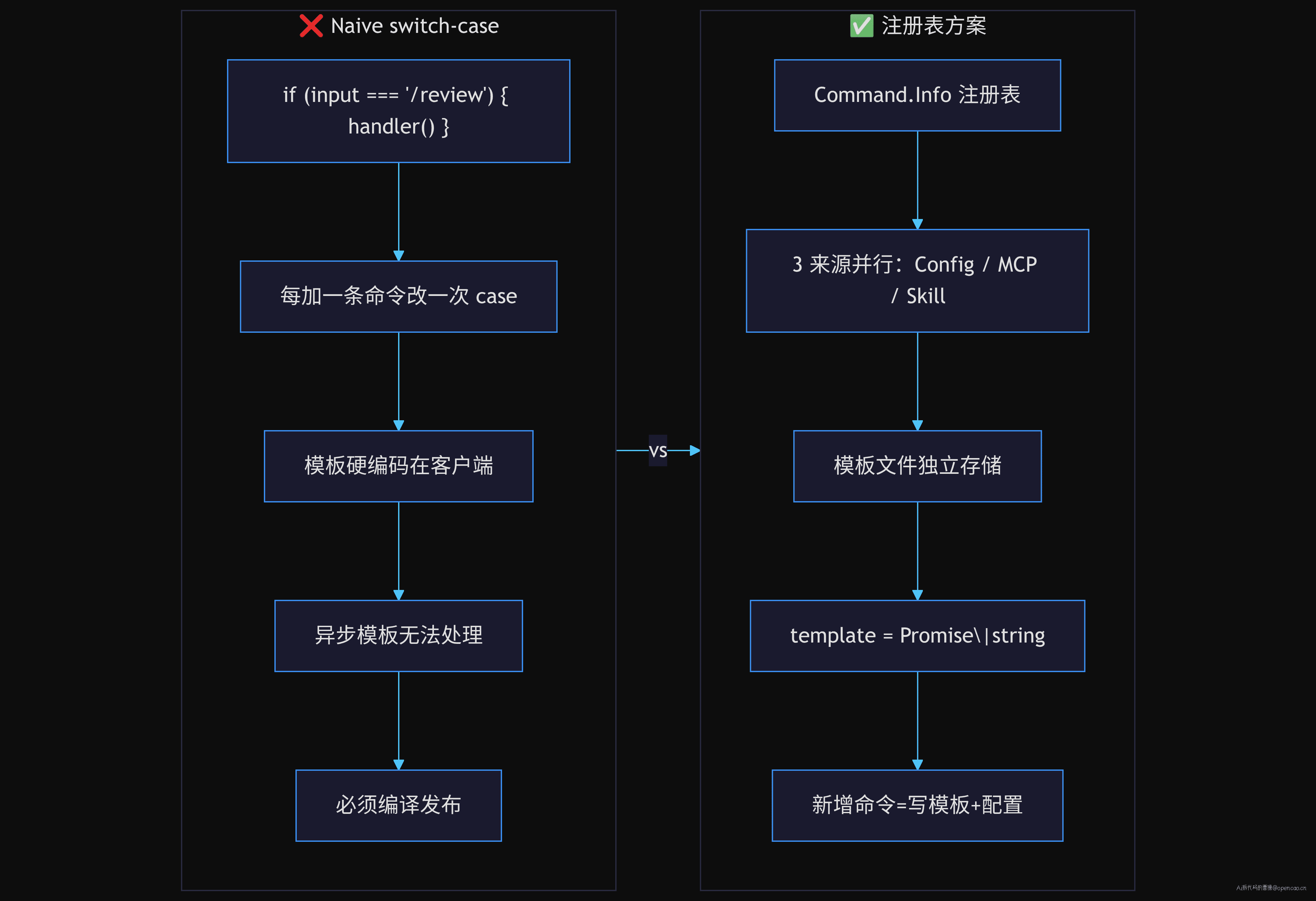
第一个问题:维护成本线性增长。 每新增一条命令,必须改客户端代码、重新编译、重新发布。对于 2 个内置命令来说这没问题,但当 Config/MCP/Skill 三个来源都能注册命令时,客户端根本不知道总共有多少命令。
第二个问题:模板和逻辑耦合。 在 switch-case 方案下,每个命令的模板字符串要么硬编码在代码里(无法热更新),要么存储在某个配置文件里(需要额外的加载机制)。opencode 的方案直接让 Command.Info.template 承载模板,hints() 自动从模板提取参数占位符,零配置。
第三个问题:异步模板无能为力。 MCP 命令的模板是经过 RPC 远程解析的 Promise<string>。switch-case 模式无法优雅处理一个需要 await 才能拿到内容的命令路由。opencode 在 Info 定义中声明 template: Schema.Unknown,并用 bridge.promise() 封装异步值,让查询方无感知。
选型的代价
没有任何设计是免费的。注册表方案有两个代价:
第一,调试路径变长。在 switch-case 方案下,"用户输入 X → 执行 Y"的映射关系是一目了然的。在注册表方案下,你需要依次追踪:用户输入 → slashHead() 解析 → parseSlashCommand() 校验 → SDK session.command() → 服务端 Command.Service.get() → 模板加载 → 注入。每一步都是一层间接。
第二,MCP 命令的异步模板渲染增加故障面。如果 MCP 服务不可用,session.command() 可能因为模板加载失败而报错。这在 switch-case 方案中不会发生,因为所有模板都是同步加载的。
opencode 选择这个代价,换取的是扩展性。当命令系统需要支持任意数量的来源、异步模板、热更新注册表时,间接层不是 overhead,而是架构必需品。
模式提炼
"注册表模式"在软件工程中并不新鲜。Spring 的 Bean 注册、Express 的路由注册、VSCode 的 Command 注册都遵循同样的思路:用一个中央注册表替代硬编码分发。
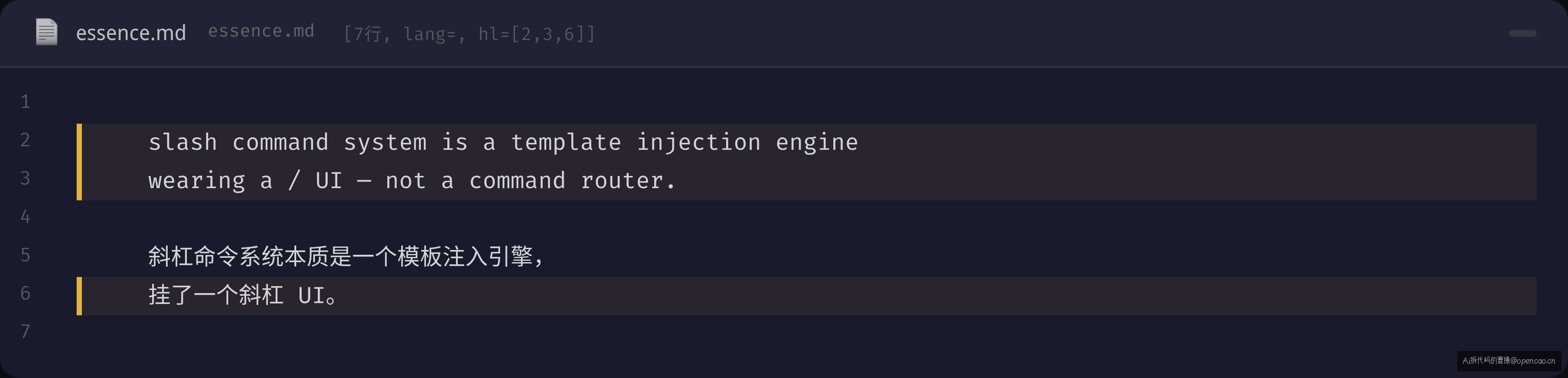
opencode 给这个经典模式加了一个 twist:模板注入。注册表里的每个命令带着一个 LLM 提示词模板,执行命令的本质是加载模板替换参数后注入 LLM。这个模式让"新增命令"变成"写配置文件声明模板"或"安装一个技能包"——不需要改任何代码。这种注册表+模板注入的模式我在公众号每周拆解的源码项目里反复出现——从 VSCode 的 command 注册到 Spring 的 Bean 注入,同一个模式改名换面而已。
如果你下次要设计一个 AI Agent 的扩展点,当考虑如何让三方开发者不修改核心代码就能添加功能时,开一个注册表,而不是加一个 case。
结语
斜杠命令系统的设计展现了一个微妙但重要的权衡:用户看到的是精简的 /review,背后是 184 行的命令引擎 + 101 行的提示词模板 + 三层架构 + 三个来源并行注入。naive 方案从 5 行的 if 语句开始,到 20 条命令时膨胀成 100 行的 case 链。opencode 从 184 行的引擎开始,新增命令 = 0 行客户端代码改动。
表面简单,是复杂系统的最高评价。
下一次你需要在项目里设计一个扩展点——不管是命令、插件还是中间件——做完功能后问自己一句:用户看到的是 if-else 还是注册表?前者 5 行写出,200 行崩溃。后者 200 行搭好,永远只加配置文件。
下一篇我们拆解 /config 命令:配置管理的命令行入口。opencode 如何通过两条路径(CLI 的 opencode config 和交互式的 /config)覆盖配置的读取和修改。如果你觉得这种架构拆解有用,转发给你的同事——他们会感谢你的。
🔗 个人博客:https://opencao.cn 📺 公众号:Ai拆代码的曹操 🌟 知识星球:Ai拆代码的曹操


