
/config:配置管理的命令行入口
如果你要设计一个 AI Agent 的配置系统——用户用 JSON 配置 provider、Agent、权限规则、MCP 服务——你会怎么组织?
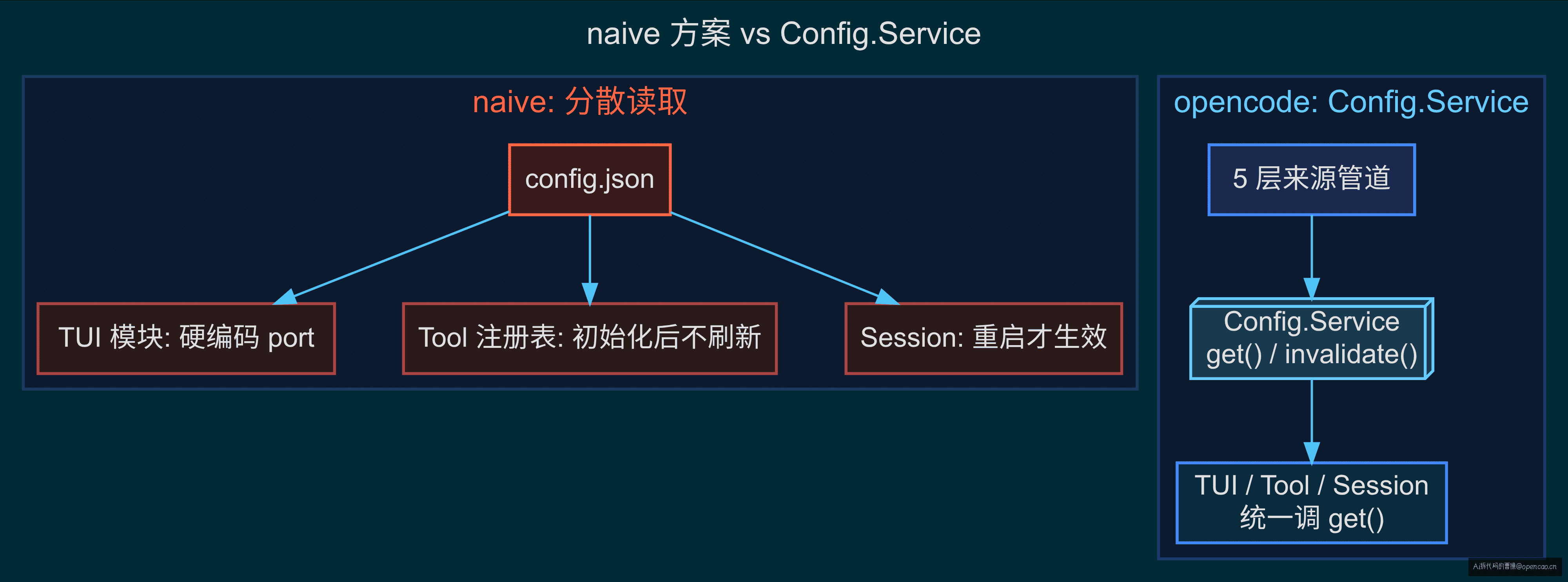
一个直观的想法是:全局一个 config.json,每个模块 import 自己需要的字段,各管各的。但这样 server.port 改了,session 的 WebSocket URL 不知道。disabled_providers 配了,tool 注册表不自动刷新。配置的本质是 cross-cutting concern——不是模块私有字段,是跨模块的状态契约。
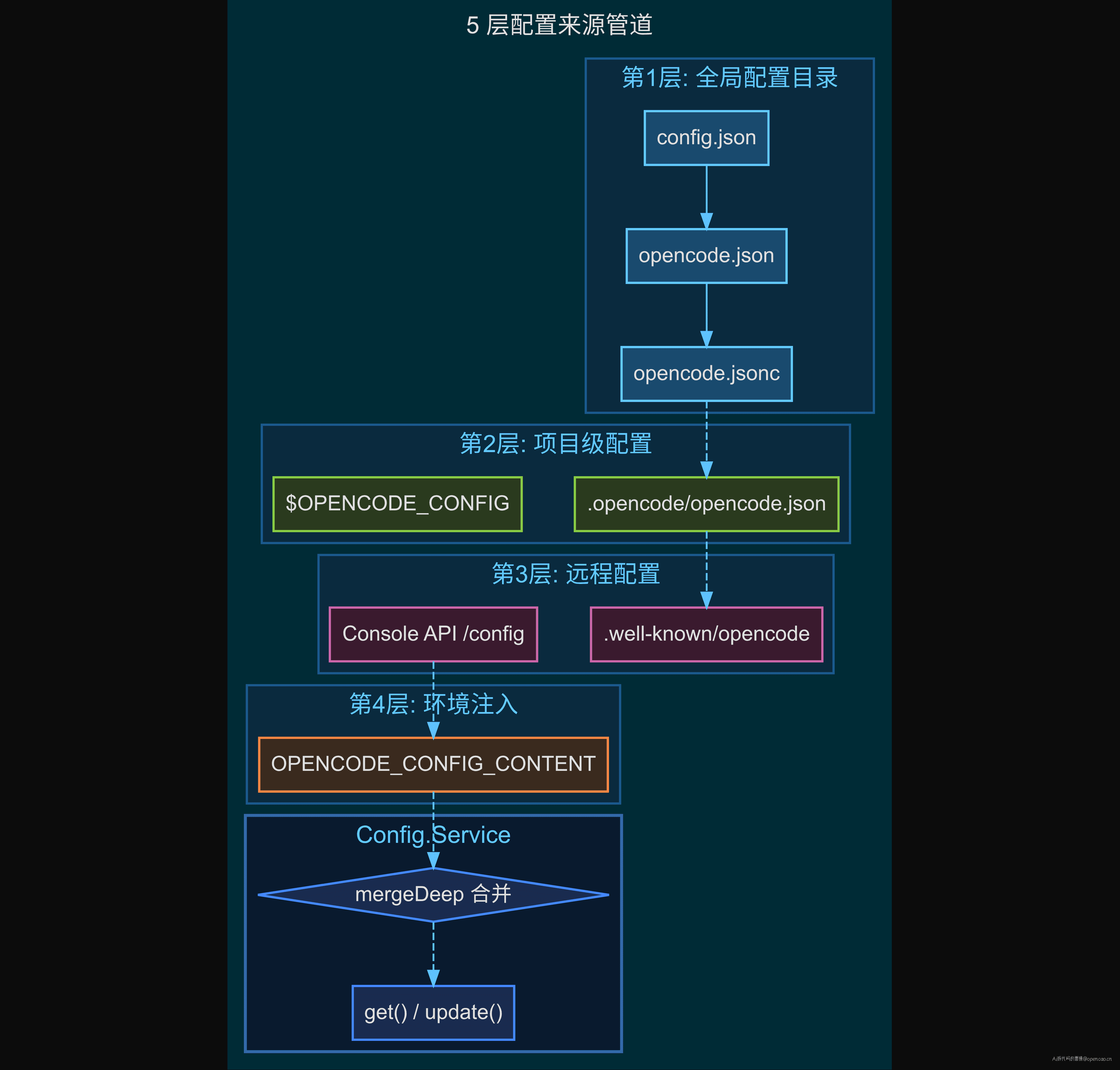
等一下——opencode 在同一个目录下同时支持 config.json、opencode.json、opencode.jsonc 三个文件名。不是随便选的,是有意为之的 优先级策略:后读取的覆盖前者,谁先有值谁赢。
opencode 的配置系统整体的选择:5 层来源管道。全局目录三文件 → 项目 .opencode/ → 远程 well-known URL → 环境变量。5 层来源最终合并为一个 Config.Service。两条入口共享这一个 Service:CLI 的 opencode debug config 和 SDK 的 sdk.config.get()。
【问题】改了 opencode.json,Agent 就是不生效?
naive 方案:分散读取的两个致命问题
如果每个模块自己读配置,会出两个实际问题。理解这两个问题,就理解了为什么 opencode 选择用 686 行的 Service 来管理配置。
第一个问题:跨模块联动断裂。server.port 改了,TUI 的 WebSocket URL 不会自动感知——因为 TUI 模块在初始化时已经硬编码了自己的端口。disabled_providers 改了,tool 注册表不会自动刷新——因为注册表初始化时已经读完了 provider 列表。跨模块的配置变更要等进程重启才生效,这在 Agent 长时间运行的场景下非常痛苦——一个 session 可能跑几小时,期间远程配置变了,你不能让用户重启。opencode 通过 Config.Service 提供统一的 get() 和 invalidate() 接口,让所有模块从同一个源读取配置,远程配置变更时自动重新加载。这不是过度设计——v1 版本确实没有这个机制,每个模块各自读配置,结果就是改一个字段要重启整个进程。
第二个问题:来源优先级混乱。全局配置、项目级配置、环境变量、远程组织配置——当这四个来源对同一个字段都赋值时,谁的优先级最高?naive 方案下没有明确答案。每个模块的读取策略不同,同一个字段在不同模块眼中可能值不同。opencode 用 mergeDeep(深度合并,后覆盖前)实现了确定的 5 层优先级列表:
config.json → opencode.json → opencode.jsonc ← 三级全局文件级联
↓
$OPENCODE_CONFIG / .opencode/opencode.json ← 项目级覆盖
↓
远程 well-known URL / Console API config ← 组织级远程配置
↓
OPENCODE_CONFIG_CONTENT 环境变量 ← 运行时注入
每一层通过 mergeDeep 合并——只有当前层有值的字段会覆盖上一层的同名字段,空值不覆盖。这个策略保证了"配了就用,不配就继承上级"。你可能会想:为什么要搞这么多层?让用户只在一个地方配不行吗?因为 opencode 的使用场景决定了配置必然来自多个源头。个人开发者在自己电脑上配 provider.apiKey,团队通过远程配置下发 disabled_providers,CI 环境通过 OPENCODE_CONFIG_CONTENT 注入运行参数——三个来源在同一个 session 中共存,谁都不该覆盖谁的合理范围。配置合并管道不是过度设计,是多场景共存的必然产物。
【设计】5 层来源,一个查询入口
Config.Info:63 字段的统一空间
如果采用 naive 方案的"每个模块自己读配置",每个模块就需要各自知道配置的结构——TUI 模块要知道它的端口从哪里读,tool 注册表要知道 provider 列表在哪个文件。这意味着配置 Schema 被隐式分散到 N 个模块的 import 语句里,改一个字段名要改 N 处。
opencode 的方式是一个统一 Schema——ConfigV1.Info,定义在 packages/core/src/v1/config/config.ts(189 行):
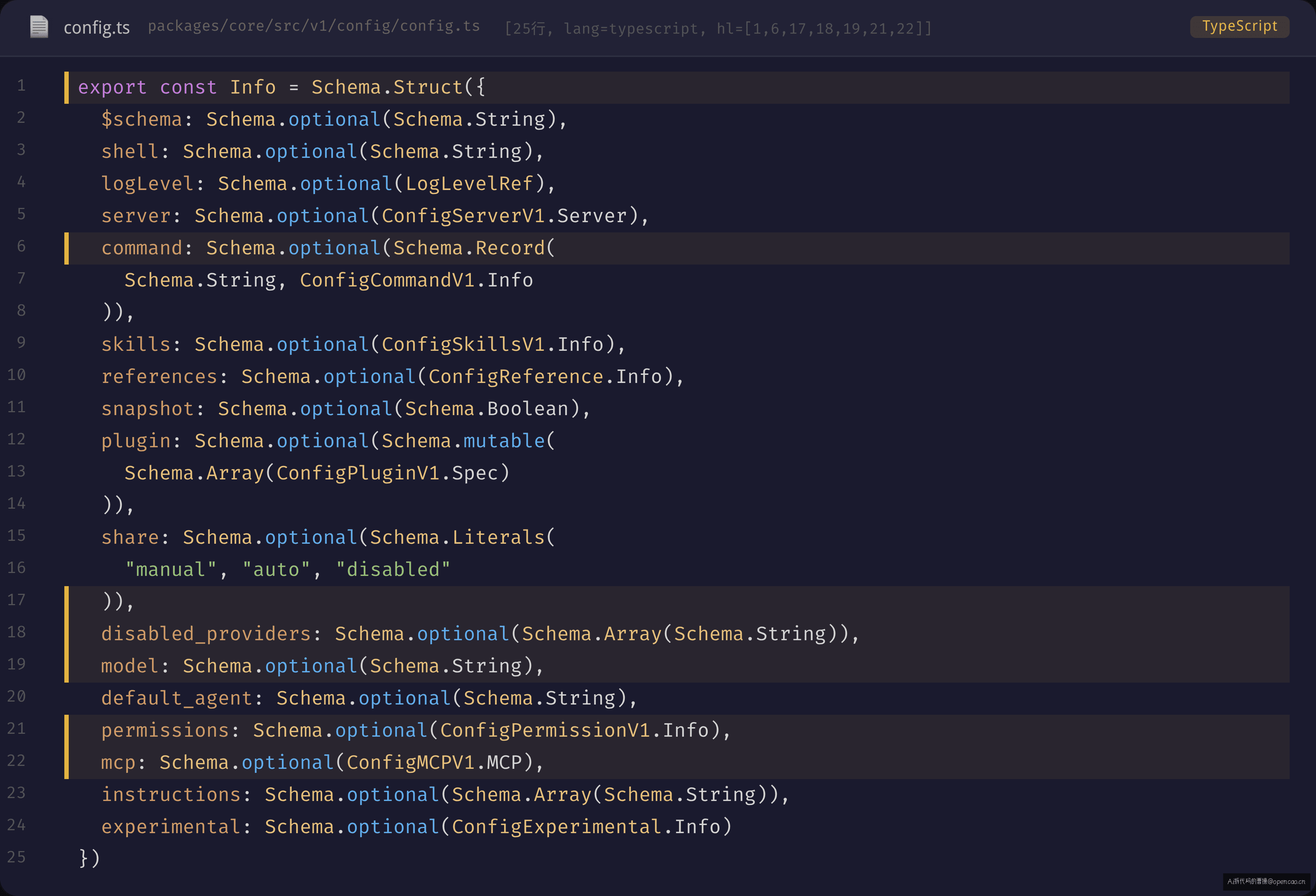
63 个顶级字段覆盖了 opencode 的方方面面:provider(LLM 供应商配置)、model(默认模型)、permissions(权限规则)、command(自定义斜杠命令)、mcp(MCP 服务连接)、server(服务端参数)、skills(技能路径)、plugin(插件来源)。每个字段都是 optional(可选的),因为大部分字段都有默认值或自动发现机制。比如 model 不配,opencode 会自动选择供应商列表中最优的可用模型。permissions 不配,使用默认的"ask"模式——每次工具调用都询问用户。
这个 Schema 就是整个配置系统的"命名空间"——所有来源的配置最终都会合并到这个 63 字段的结构里。naive 方案做不到这点,因为每个模块只知道自己的那一小块字段,全局的字段地图不存在。你无法在分散读取的模式下问"我有哪些配置字段可以用"——答案分散在 N 个模块的 import 链里。一份 Schema 定义同时担纲了验证器、类型定义和运行时注册的契约。更有意思的是,command 字段的类型是 Schema.Record(Schema.String, ConfigCommandV1.Info)——你可以在 opencode.json 里配自定义斜杠命令,比如 /deploy,配置后命令注册表自动识别,不需要改一行代码。naive 方案下,每条命令的配置格式散落在各自的模块里,统一管理只是一种奢望。第六章拆 tool 的 Zod Schema 时我们会看到同样的设计哲学——Schema 不仅约束数据,还驱动 LLM 的工具定义。
Config.Service:686 行的薄层 + 两条入口
Config Service 是配置系统的运行时核心,定义在 packages/opencode/src/config/config.ts(686 行):
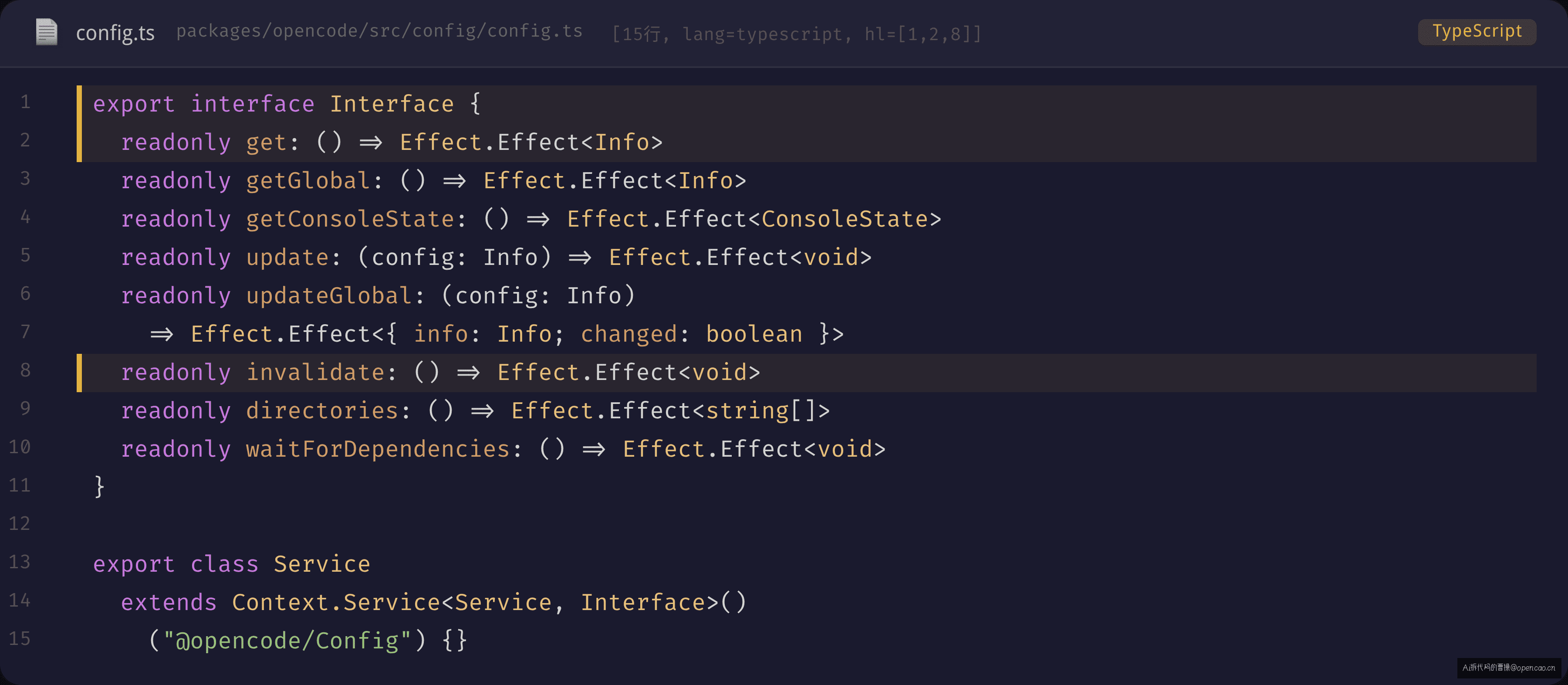
7 个方法覆盖了配置的完整生命周期。get() 和 getGlobal() 是查询入口——前者返回当前 session 的完整合并配置(5 层来源合并后的结果),后者只返回全局文件层。update() 和 updateGlobal() 是写入入口——它们通过 patchJsonc 原地修改 JSONC 文件,不是全量重写。invalidate() 触发远程配置重新加载,directories() 列出所有配置扫描目录。
最关键的实现细节在 loadInstanceState() 方法(config.ts:313)。它从前文说的 5 层来源依次合并,每一步都是 Effect 驱动的异步管道——远程配置通过 fetchRemoteJson 拉取(失败不中断,只打日志),项目级 command 和 agent 配置通过 ConfigCommand.load(dir) 和 ConfigAgent.load(dir) 异步读取。整个合并过程有完整的错误处理链:文件不存在就跳过,JSON 解析失败就打日志,远程拉取超时就等下次 invalidate()。这不是 try-catch 的滥用,是 Effect 的 Option/Either 模式让每步失败都可恢复。
这个 Service 有两条消费入口。CLI 入口 packages/opencode/src/cli/cmd/debug/config.ts 只有 10 行:
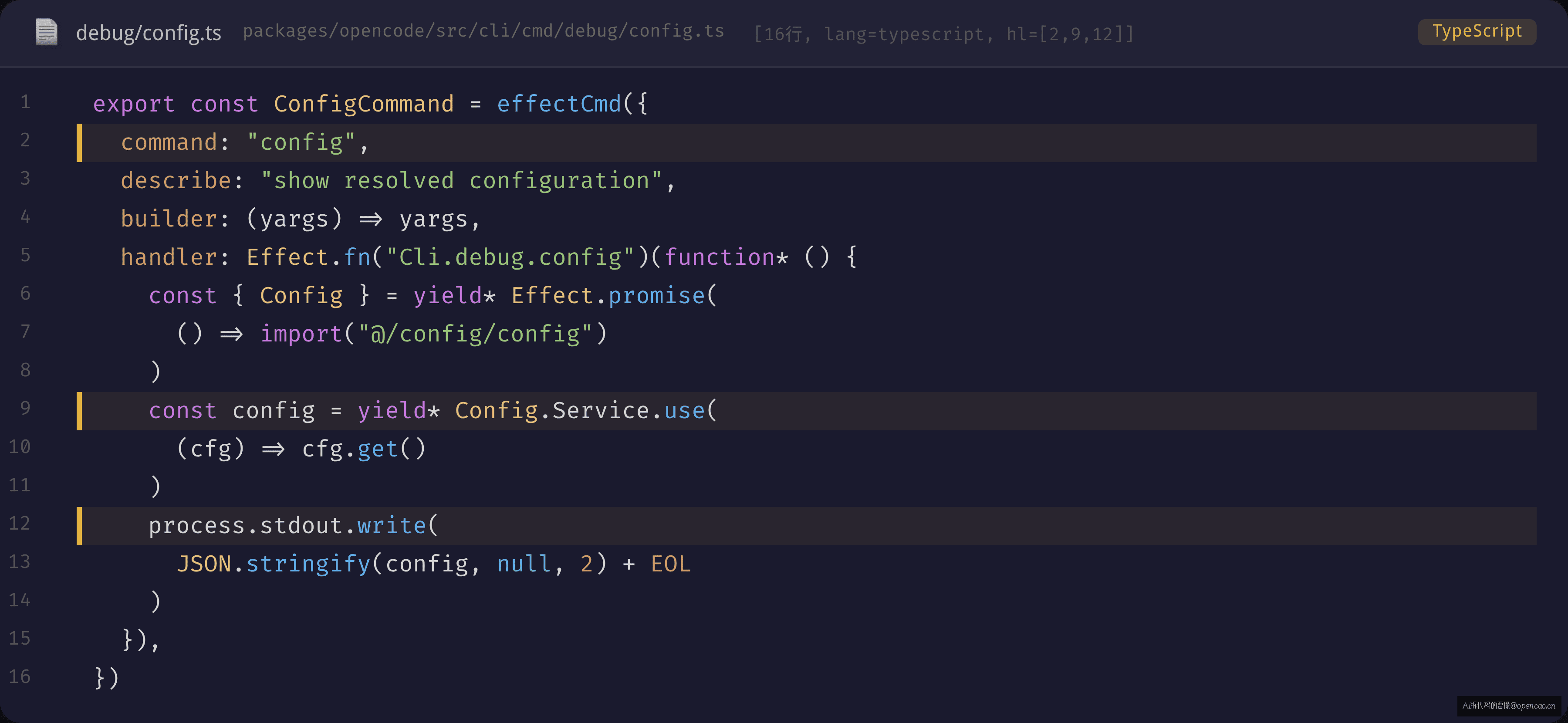
3 行核心逻辑:动态 import Config → Config.Service.use(cfg => cfg.get()) → JSON.stringify。这就是"薄层"的威力——CLI handler 不需要知道配置合并的细节,只需要调一句 get()。Effect.promise(() => import(...)) 动态导入保证 Config 模块只在执行 opencode debug config 时才加载,不污染 CLI 启动路径。
SDK 入口同样简单。服务端暴露 GET /config HTTP API,经过实例路由和权限校验后,返回同一个 Service 的 get() 结果。CLI 读到实例级别的完整配置,SDK 走 HTTP——殊途同归:查询路径只有一条,消费方看到的都是一个扁平的 Info 结构,它们不需要知道背后是 1 层还是 5 层来源。
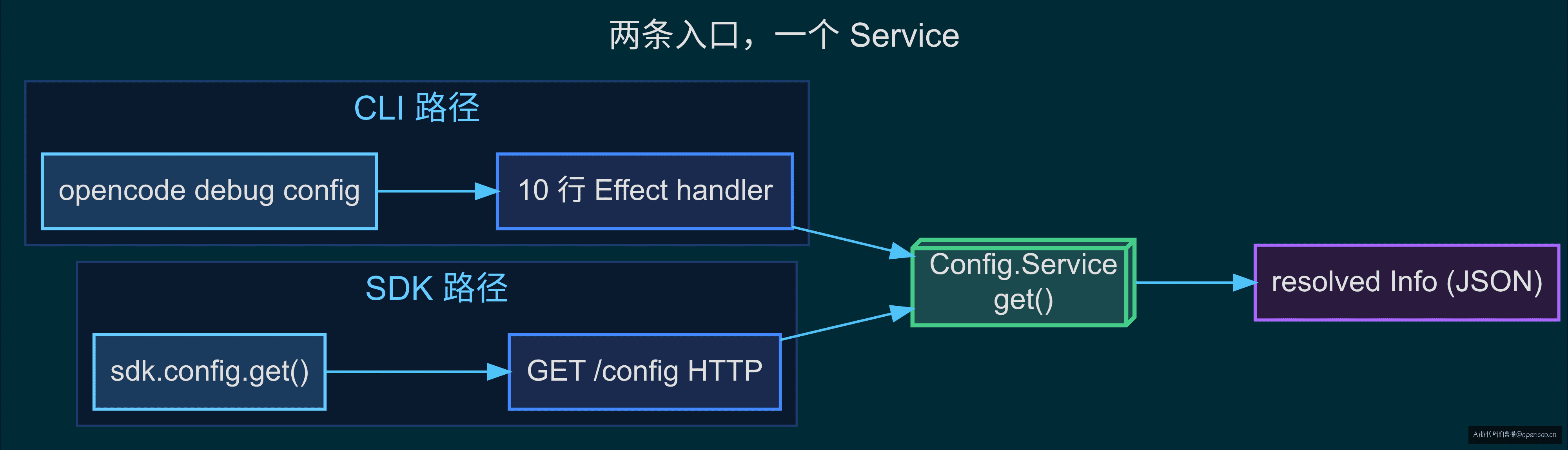
【源码】从 debug config 命令到 resolved JSON
loadGlobal 的三文件优先级链
naive 方案下想查"最终生效的 disabled_providers 是什么"要翻三四个文件。你打开 config.json 看到配了,但某个模块读的是 .opencode/opencode.json,另一个模块走的是环境变量——你要的不是精准值,你要的是最终值。opencode 的 loadInstanceState 把所有来源集中到一个管道里,第一层就是全局配置加载 loadGlobal:
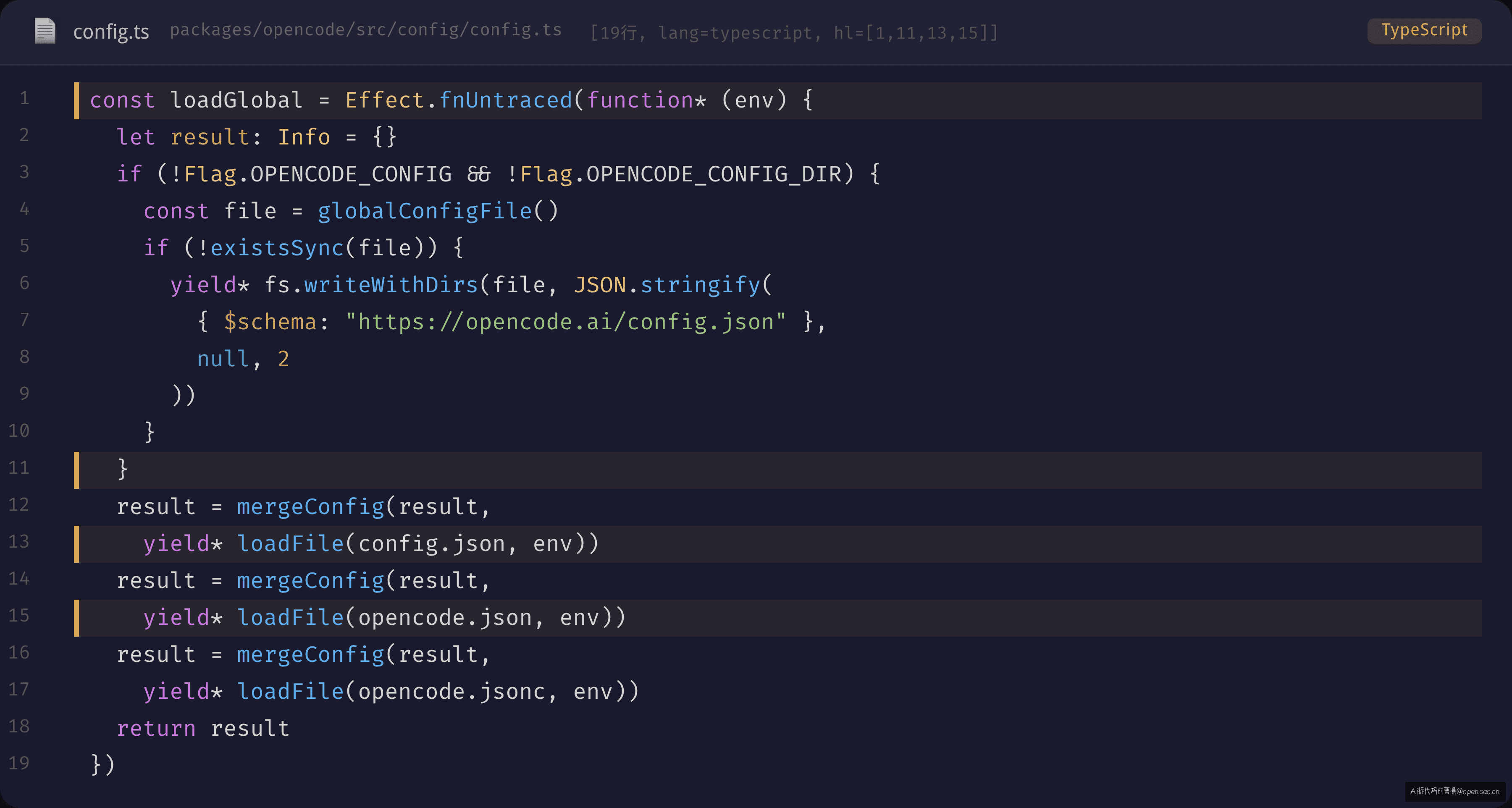
三文件级联加载的顺序是 config.json → opencode.json → opencode.jsonc。后加载的通过 mergeConfig 覆盖前一个的重复字段。如果你在 config.json 里配了 model: "anthropic/claude-sonnet-4",但在 opencode.jsonc 里配了同一个字段,后者胜出。这背后是 mergeDeep 的语义——它不是覆盖整个对象,是按叶子节点逐字段覆盖。所以 config.json 的 server.port 如果没在 opencode.jsonc 中出现,它不会被抹掉。
等一下——为什么不只支持一个文件名?这是渐进式迁移策略。config.json 是旧版格式的产物,opencode.json 是标准配置名,opencode.jsonc 是带注释和尾随逗号的升级体验版。三文件共存保证了旧版本升级用户的配置自动生效,新建用户默认获得 opencode.jsonc 的更好编辑体验。奇妙之处在于,这是 0 行代码实现的向前兼容——后读取的文件自然覆盖前一个,迁移路径是读取顺序决定的,不是代码分支决定的。
那用户同时有这三个文件,配置到底生效了哪个?按字段独立决定。model 来自 opencode.jsonc 覆盖了 config.json,但 disabled_providers 如果只在 config.json 里配了,就自动继承到合并结果里。三文件融合成一个 Info 结构,逻辑上等价于在一份文件里配了所有字段。
项目级 + 远程 + 环境变量的四层叠加
loadGlobal 执行完后,项目级配置开始逐级注入。naive 方案在每个层级都要重复实现"读文件→解析→合并"的逻辑,而 opencode 用一个统一的 merge 函数贯穿所有层级:
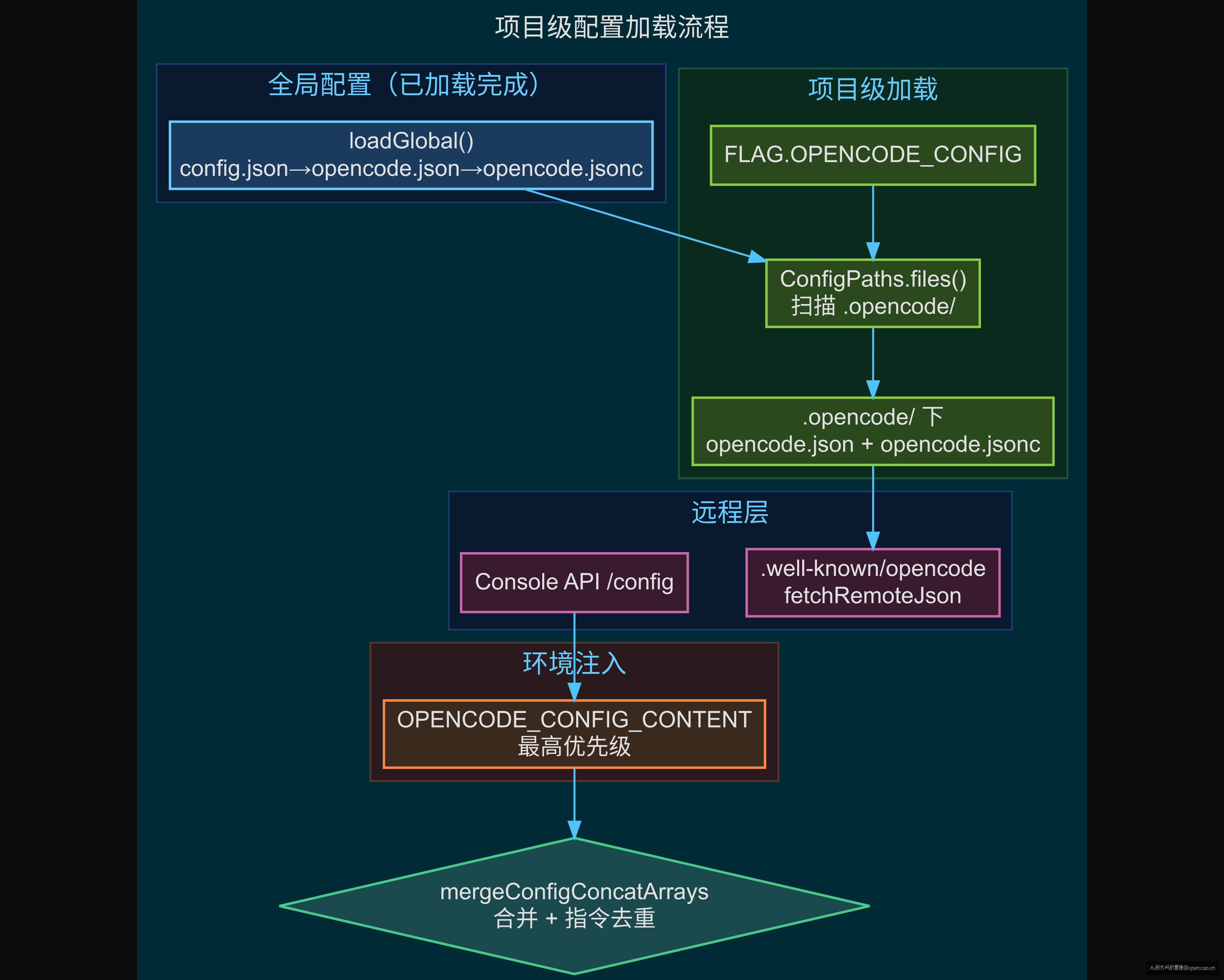
第一层是 $OPENCODE_CONFIG 标志。如果用户通过 --config 或 OPENCODE_CONFIG 环境变量指定了配置文件路径,它最先被合并。这为 CI 和容器化场景提供了精确的配置入口。
第二层是项目级扫描。ConfigPaths.files() 遍历当前目录和工作树根目录下的 .opencode/ 文件夹,加载其中的 opencode.json 和 opencode.jsonc。这里的关键设计是"两个锚点"——当前目录和工作树根目录。这意味着 monorepo 的子项目可以有自己的 .opencode/opencode.json,同时继承根目录的团队配置。naive 方案下每个子项目要各自处理配置加载,合并后统一扫描省去了 N 份重复代码。
第三层是远程配置。通过 Auth.Service 拿到的 well-known URL(如 https://example.com/.well-known/opencode),用 fetchRemoteJson 拉取 JSON 并合并。注意这里的失败不中断语义——网络超时、HTTP 500、JSON 解析失败都只打日志,不影响本地配置。这是 Effect 的 Option/Either 错误处理模式:失败不是异常,是带 fallback 的值。
第四层是环境变量注入。OPENCODE_CONFIG_CONTENT 可以在 GitHub Actions 中设置为一段 JSON,它的优先级最高,覆盖其他所有来源。这在 CI 场景中非常实用——你可以在 pipeline 中动态生成配置段,注入到 Agent 的运行环境中。
5 层来源的完整优先级链:
loadGlobal(三文件) → 第1层
↓
FLAG.OPENCODE_CONFIG → 第2层
↓
ConfigPaths.files() 项目扫描 → 第3层
↓
remote well-known + Console API → 第4层
↓
OPENCODE_CONFIG_CONTENT env → 第5层(最高优先级)
每一层通过 mergeConfigConcatArrays 合并——不仅做 mergeDeep,还对 instructions 数组做去重拼接。全局配了 3 条指令,团队配了 2 条,最终用户收到 5 条不重复的指令。这个数组特化处理是 mergeDeep 默认行为(替换)无法满足的,所以在 mergeConfigConcatArrays 中单独处理。
【权衡】为什么弃了 TOML?
jsonc-parser 的原地编辑优势 + 两个代价
naive 方案下你不会为 JSON vs TOML 纠结——每个模块自己读配置,格式自定。但一旦做出"统一 Service"的架构决策,就必须选一个所有模块都能消费的格式。opencode 为此多写了 100 行代码。
opencode 曾经支持 TOML。代码库中至今残留着迁移路径——读取 TOML 文件,自动转写成 config.json,然后删除 TOML 源文件。作者弃 TOML 的根本原因在于 patchJsonc:
function patchJsonc(input, patch, path) {
if (!isRecord(patch)) {
const edits = modify(input, path, patch, { ... })
return applyEdits(input, edits)
}
return Object.entries(patch).reduce((result, [key, value]) =>
patchJsonc(result, value, [...path, key]), input
)
}
jsonc-parser 的 modify() 可以在保留原格式、注释、空行的前提下,精确修改 JSONC 文件的某个字段。Config.Service.update() 借此原地修改一个字段而不丢失其他内容——用户在桌面端 UI 改了 model,patchJsonc 只改那一行,其余原封不动。TOML 生态没有等价工具——修改一个字段需要全量解析、修改 AST、重新序列化,丢失原格式和注释。
选 JSONC 不是因为流行,而是因为 运行时修改单字段而不重写整个文件 是刚需。
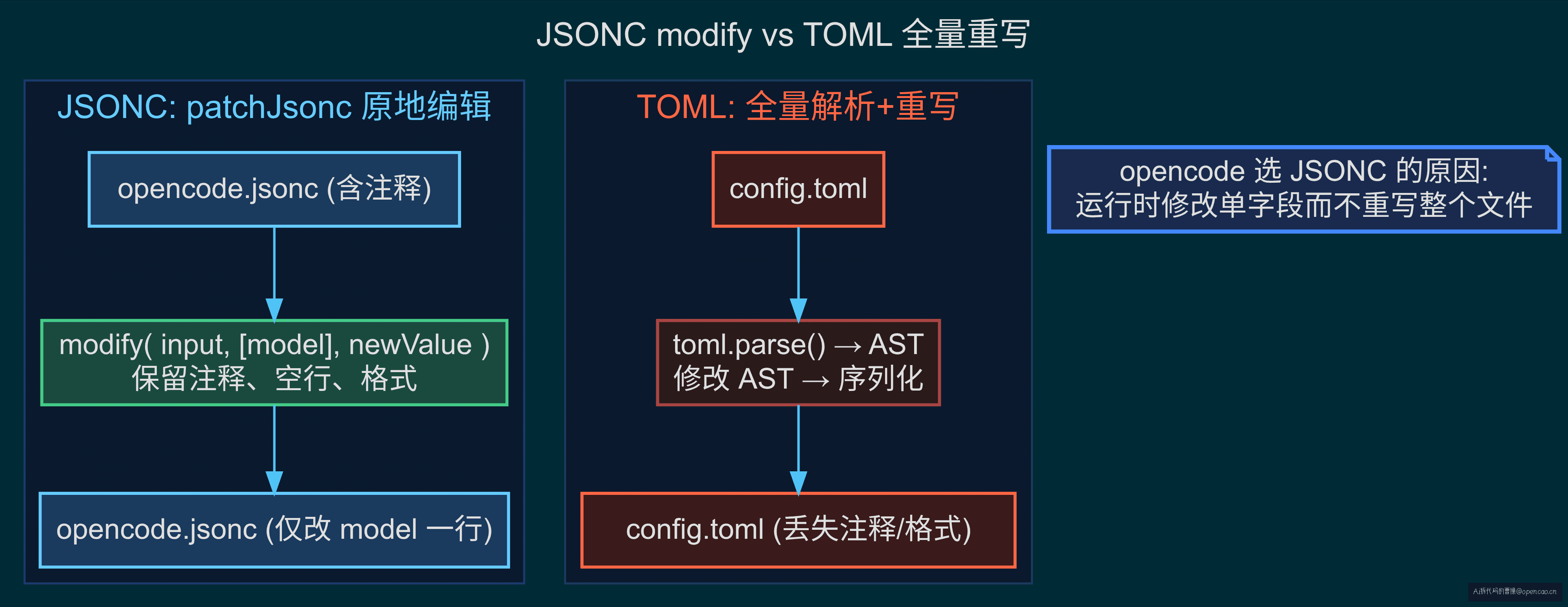
代价有两个。第一:Schema 校验不依赖 JSON Schema 工具链,Effect Schema 的校验能力无法在 VSCode 的 $schema 中体现——错误的字段值要运行时才能发现。第二:63 个字段全是 optional,Schema 宽容到漏配关键字段也不会警告——团队远程配置需要自己在应用层做必填校验。
opencode 接受这些代价,因为配置的跨模块特性决定了大部分字段本来就是可选的。model 不配就自动发现最优模型,provider 不配就用内置供应商列表,disabled_providers 不配就不禁用任何 provider。opencode 的 686 行 config.ts 有接近 100 行花在 patchJsonc 和 TOML 迁移上——格式抉择不是边缘功能,是花了功夫的架构决策。
【锚点】配置合并管道
一句话金句
多来源合并、单一查询入口。
opencode 用一个 Config.Service 承载了 5 层来源、63 个字段、2 条入口的配置系统。你从 CLI 输入 opencode debug config 看到的 JSON,背后是全局文件级联、项目级覆盖、远程拉取、环境注入的完整管道。这个模式的核心洞察是:配置的消费者不应该知道配置的来源。CLI handler 只调 cfg.get(),SDK 只调 sdk.config.get(),它们都不知道管道里有多少层。
这个模式的泛化版本在软件工程中反复出现。Spring 的 application-{profile}.yml 层级合并——开发环境配 application-dev.yml,生产环境配 application-prod.yml,按 profile 顺序叠加。Rails 的 credentials 分层解密——credentials.yml.enc 用不同 key 解密出不同环境的值。Kubernetes ConfigMap 的多层覆盖——namespace 级、deployment 级、container 级依次覆盖。它们的共同模式是:开一个 Service,接一个合并管道,让消费者永远只说一句 get()。
那 opencode 的方案有什么特殊之处?它把来源管道的运行时动态性做到了极致。Spring 的 profile 文件在启动时确定,不会在运行中切换。opencode 的远程配置在 session 运行时可以重新加载——登录工作账号,配置自动更新;断开 VPN,配置回退到本地层级。这种运行时动态性由 Effect 的 cachedInvalidateWithTTL(缓存失效模式,TTL 过期后自动重新计算并更新)和异步 fetch 驱动,不是静态文件扫描能实现的。
如果你下次设计一个需要多级配置的系统,设计原则应该是:查询路径只有一条,合并规则是确定的。消费者的 get() 接口不变,来源管道可以加层、减层、重排序,消费者不需要改一行代码。具体怎么做?记住 opencode 的思路:mergeDeep 决定合并语义,后合并的覆盖前面的同名字段。你的场景没有数组拼接需求的话,10 行 merge 函数就能跑通整个管道。你不需要 686 行——你需要的是清晰的优先级定义和一个薄层封装。
结语
opencode 的配置系统 686 行——比起 naive 方案每个模块自己读配置,是多写了 600 行。但换来的是 5 层来源的自由组合、63 字段的集中管理、两条入口统一查询、运行时 patchJsonc 原地编辑。
200 行搭好管道,永远只加来源不改查询。
上一篇我们看到了"注册表模式"的力量。这一篇是"合并管道模式"——不是横向扩展(加命令),而是纵向叠加(加来源)。下一篇拆 Git 集成,看第三个模式:Session 内嵌的状态管理。
如果你觉得这种源码拆解有用,转发给你的同事——他们会感谢你的。
🔗 个人博客:https://opencao.cn 📺 公众号:Ai拆代码的曹操 🌟 知识星球:Ai拆代码的曹操


