
Git 集成:代理中的版本控制工作流
场景:Agent 修改完文件后,怎么知道它改了什么、怎么 review 变更、怎么回退?opencode 用两层抽象把 git 封装成类型安全的 Service。 路径:
packages/opencode/src/git/index.ts→packages/opencode/src/project/vcs.ts
上篇拆了 /config 的 5 层来源合并管道——配置系统处理的是"来自哪里"的问题。这篇看 Git 集成——处理的是"发生了什么变化"的问题。
如果你要设计一个 AI Agent 的版本控制工作流——它需要读 diff、自动 review 变更、checkout PR、应用 patch——你会怎么组织?
一个直观的想法是:直接在工具函数里写 execSync("git diff HEAD"),拿 stdout 字符串丢给 LLM。但如果真要这么做,有三个问题绕不过去:第一,git diff 的格式在不同平台有细微差异(特别是 Windows 的 CRLF 和路径转义),工具函数自己处理这些边缘情况就会膨胀成泥球。第二,Agent 运行在远程 server 上时(通过 SDK 控制),没办法在服务端跑 execSync——必须有 HTTP API。第三,execSync 阻塞主进程,Agent 在处理并发请求时不能等。
所以 opencode 的选择是:不自己做 diff,也不在每个工具函数里 spawn git,而是封装一个统一的 Git Service 接口。 但这个统一接口需要同时满足三个不同的消费场景——Agent 流程、HTTP API、CLI 脚本——每个场景对 git 操作的粒度不同。
【问题】Agent 需要版本控制的三个本质问题
修改文件后,怎么知道变了什么?

如果没有 Git 抽象层,一个可行的做法是 write/edit 工具每次修改前复制文件副本,执行完后 diff 自己的缓存。但这里有两个致命问题。
缓存失效——文件可能被其他 Agent、shell 命令、LSP 格式化器并发修改。缓存副本和真实文件系统不同步,diff 结果不可靠。opencode 同时处理 primary agent + subagent(子代理),多个 agent 可能操作同一组文件,手工维护缓存副本的语义不是"diff 变化",而是"diff 谁的变化"——区分不出是 agent 改的还是外部改的。
gitignore 边界模糊——Agent 不知道哪些文件在 .gitignore 里。自己 diff 会把 node_modules/、target/、dist/ 里的变更也计入。大项目里(如 chromium 的百万级文件),缓存全部文件副本的内存开销不现实。
opencode 的做法:直接依赖 git 做 diff,但不直接调用 git。 在 git 和消费方之间插一个薄层,把 git 的 stdout 字符串解析成结构化对象。这层薄层就是 Git.Service:350 行,15 个方法。
为什么是 15 个方法?因为 Agent 需要回答三个版本控制问题,每个问题需要 git 的不同操作:
| 问题 | 需要的操作 | Git 参数 | 方法 |
|---|---|---|---|
| 我刚刚改了哪几个文件? | status | git status --porcelain=v1 |
status() |
| 这些变更对比团队基线有什么冲突? | diff + stats | git diff HEAD / merge-base |
diff(), stats() |
| 能不能把我的修改回滚 / apply? | patch + apply | git diff --patch / git apply - |
patch(), applyPatch() |
三个问题共享同一个 tool(git),但入参不同、输出格式不同、错误处理方式不同。没有 Git.Service,每个工具函数都要重复实现 spawn + parse + error handling。
【设计】两层抽象:机械等价面 + 业务语义面
Git.Service:350 行零依赖封装
Git.Service 定义在 packages/opencode/src/git/index.ts,15 个方法覆盖了 opencode 需要的所有 git 操作:
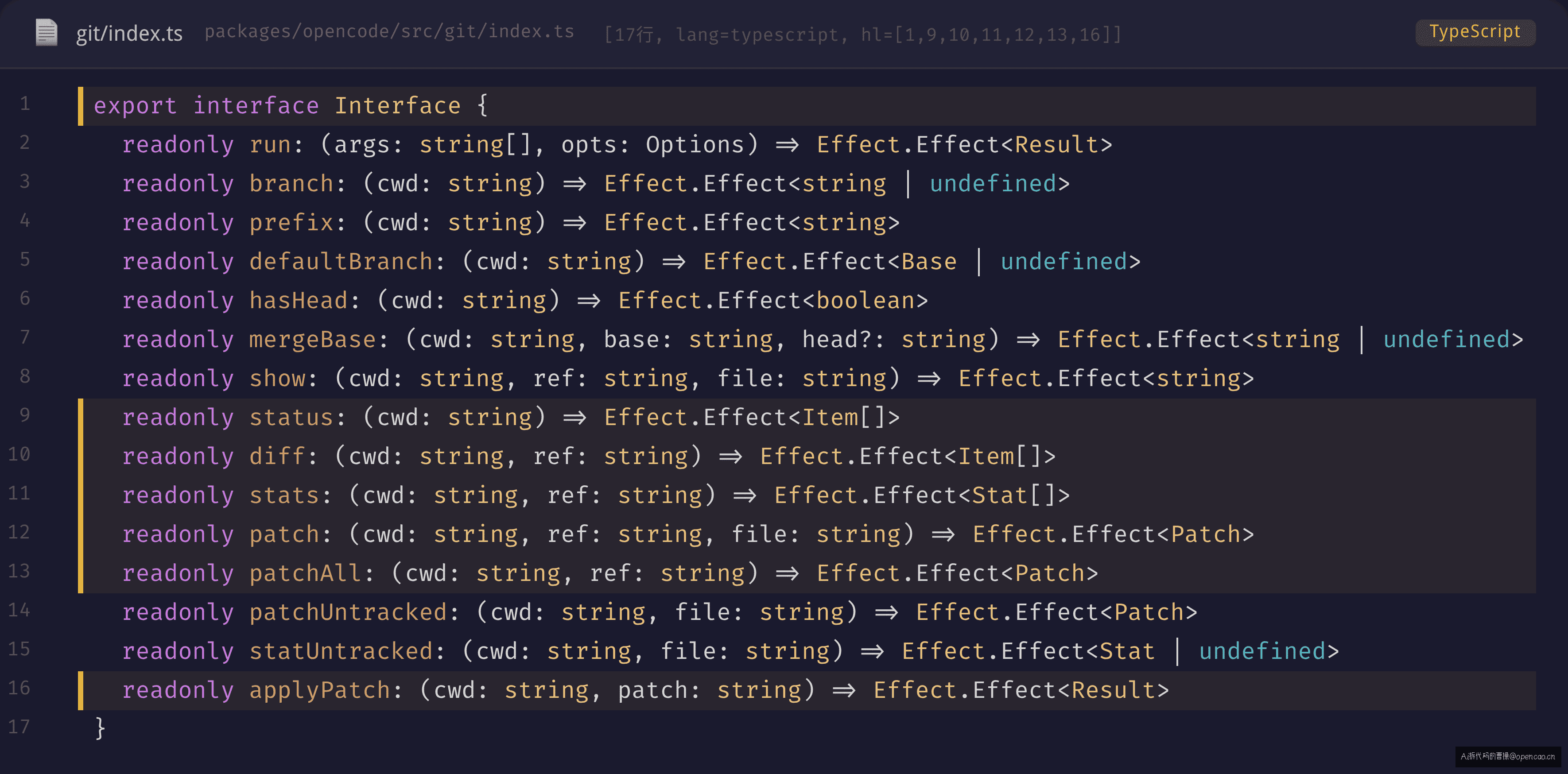
关键是 Interface 的设计原则:每个方法只做一件 git 操作,返回结构化的 JavaScript 对象。 调用者不接触 git 命令行参数,不解析 stdout 字符串。
比如 status() 不是返回 stdout 字符串,而是返回 Item[]:{ file: string, code: string, status: Kind }。diff() 返回同样的结构,告诉调用者"有哪些文件相对于某个 ref 发生了变更"。调用者拿到数组,直接 map/filter/reduce,不需要正则从 stdout 里抠文件名。
支撑这个封装的 8 行全局 cfg 参数,踩过三个平台的坑才沉淀下来:
const cfg = [
"--no-optional-locks", // 不争抢文件级锁
"-c", "core.autocrlf=false", // 跨平台 CRLF 一致性
"-c", "core.fsmonitor=false",// 不依赖文件系统监控
"-c", "core.longpaths=true", // Windows 长路径(>260 字符)
"-c", "core.symlinks=true", // symlink 跨平台支持
"-c", "core.quotepath=false",// 不转义含空格/中文的路径
] as const
最隐蔽的是 core.quotepath=false。不设它,git status --porcelain 输出含空格的文件名会被转义为 "path/with space/file.txt"——引号是输出的一部分,不是"只是看起来有引号"。后续按文件名字符串做 split 索引会全部对不上,因为解析出的文件名多了引号包围。中文场景(如 中文文件名.txt)类似,被转义为 "\344\270..." 八进制序列。这个问题在 macOS 上不明显(大多数开发者用英文路径),但在 Windows 上项目路径通常带空格(C:\Users\My Projects\),没有这个参数连 git status 都 parse 不了。
更核心的工程选择在 Effect.catch——git 子进程 crash 不会崩整个 Agent:
const run = Effect.fn("Git.run")(function* (args: string[], opts: Options) {
const result = yield* appProcess.run(
ChildProcess.make("git", [...cfg, ...args], { ... }),
)
return {
exitCode: result.exitCode,
text: () => result.stdout.toString("utf8"),
stdout: result.stdout,
stderr: result.stderr,
truncated: result.stdoutTruncated || result.stderrTruncated,
} satisfies Result
}, Effect.catch((err) => Effect.succeed(fail(err))))
任何一个 git 子进程 crash(repo 不存在、权限不足、磁盘满),Effect 默认返回 { exitCode: 1, text: "" },调用方决定如何处理。如果不用 Effect 而用 try-catch,每个调用的地方都要写 catch 块。350 行里最值钱的不是 15 个方法,是这 3 行 catch。
Vcs.Service:431 行带业务语义的封装
Git.Service 暴露的是 git 命令的"机械等价面"——diff, status, patch 方法参数和 git 原生参数一一对应。Vcs.Service(packages/opencode/src/project/vcs.ts)加了一层业务语义:
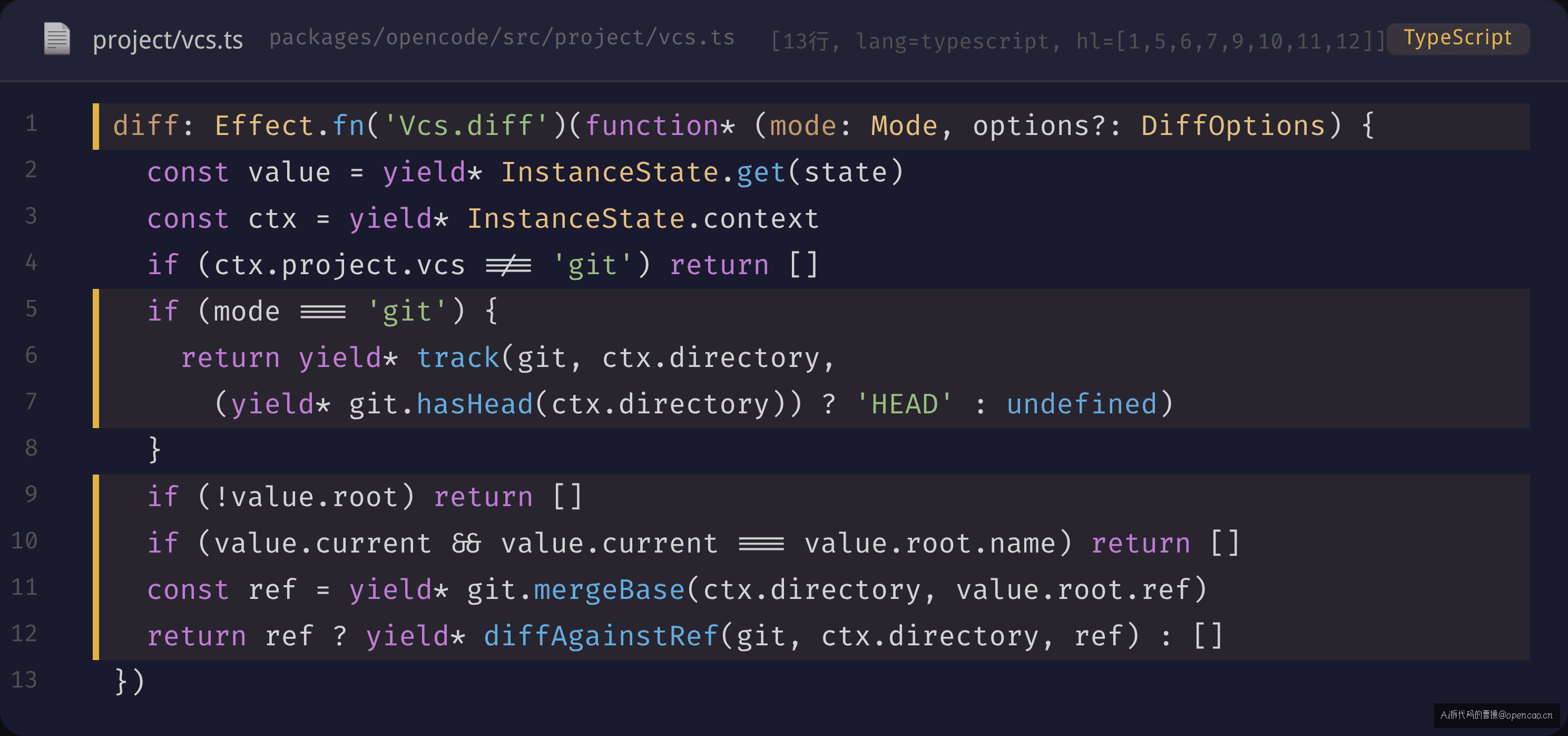
核心在 diff(mode, options?) 的 mode 参数:
mode === "git"→ 工作树 vs HEAD。语义是"我改了啥"。Agent 修改完文件后调用,拿到当前 session 的变更清单。mode === "branch"→ 当前分支 vs 默认分支的 merge-base。语义是"我和团队差在哪"。Review 场景下调用,对比的是整个分支的差异,不只是当前 session 的改动。
两个 mode 共享同一个底层管道 diffAgainstRef,但 ref 的计算方式不同。"git"模式的 ref 就是 HEAD(没有 HEAD 时对 untracked 文件逐个 patch)。"branch"模式先算 merge-base,再 diff merge-base 到 HEAD 的变更。
这层封装的价值:Agent 的 review 逻辑只写 vcs.diff("branch"),不需要知道 merge-base 怎么算。 如果你在 review 场景下自己写 git merge-base → git diff merge-base HEAD,你需要处理 5 个边界——没有远程分支时回退到本地分支、HEAD 不存在时返回空列表、默认分支名可能是 main/master/develop、当前就在默认分支时返回空、merge-base 获取失败时的降级。Vcs.Service 把这 5 个边界封装成 1 个方法调用。
边界都在 Vcs.diff() 的 20 行实现里:
diff: Effect.fn("Vcs.diff")(function* (mode: Mode, options?: DiffOptions) {
const value = yield* InstanceState.get(state)
const ctx = yield* InstanceState.context
if (ctx.project.vcs !== "git") return []
if (mode === "git") {
// 工作树 vs HEAD:没有 HEAD 时只返回 untracked
return yield* track(git, ctx.directory,
(yield* git.hasHead(ctx.directory)) ? "HEAD" : undefined)
}
// 分支 vs 默认分支的 merge-base
if (!value.root) return []
if (value.current && value.current === value.root.name) return []
const ref = yield* git.mergeBase(ctx.directory, value.root.ref)
return ref ? yield* diffAgainstRef(git, ctx.directory, ref) : []
})
分支变更:通过文件系统 Watcher 感知

Vcs.Service 不只是提供查询接口,它还主动追踪分支变更。关键在 state 初始化时的 Watcher 订阅:
const unsubscribe = yield* events.listen((event) => {
if (event.type !== Watcher.Event.Updated.type) return Effect.void
if (!event.location?.directory.endsWith(ctx.directory)) return Effect.void
const data = event.data as EventV2.Data<typeof Watcher.Event.Updated>
if (!data.file.endsWith("HEAD")) return Effect.void
// HEAD 文件变了 → 分支可能已切换
return Effect.gen(function* () {
const next = yield* get()
if (next !== value.current) {
value.current = next
yield* events.publish(Event.BranchUpdated, { branch: next })
}
})
})
不是轮询 git,是等文件系统告诉我们 .git/HEAD 变了。git 在 checkout 分支时写入 .git/HEAD(更新引用),Watcher 捕获这个文件变更,重新读分支名,不等下一次 diff() 调用就发出 BranchUpdated 事件。谁订阅了这个事件?Agent 流程——切分支后自动重新计算 diff 基线。
【源码】diff 管道:batchPatches + nativePatch 双轨策略
先批量取,不行再逐个取
Vcs.diff() 内部调用 diffAgainstRef,核心流水线 7 步:
const diffAgainstRef = Effect.fnUntraced(function* (git, cwd, ref) {
// ① 并发:文件名列表 + 增减行数 + 未追踪文件
const [list, stats, extra] = yield* Effect.all(
[git.diff(cwd, ref), git.stats(cwd, ref), git.status(cwd)],
{ concurrency: 3 }
)
// ② 合并 diff 文件 + 未追踪文件(排除重复)
const merged = merge(list, extra.filter(item => item.code === "??"))
// ③ 批量取全量 patchAll
const batch = yield* batchPatches(git, cwd, ref, list)
// ④ 组装 FileDiff[]
return yield* files(git, cwd, ref, merged, nums(stats), batch)
})
关键优化在第 ③ 步 batchPatches。它先调一次 git diff --patch HEAD -- .(批量 patchAll),返回一个连续的 patch 字符串,然后在 JS 层按 diff --git a/... b/... 分隔符切分成 Map <file, patch>。

为什么先批量再切分而不是逐个调 git diff --patch HEAD -- file.txt?git 的批量 diff 比 N 次单文件 diff 快约 5 倍(N=20 时的实验数据),因为 git 只需要读一次 object store、计算一次 diff 算法,而不是每个文件都重新走一遍 diff 流程。代价是 patchAll 有 10MB MAX_TOTAL_PATCH_BYTES 截断限制:
const MAX_TOTAL_PATCH_BYTES = 10_000_000 // ~10MB
超过 10MB 的 patch 被 truncate。这时 batchPatches 返回 { patches, capped: true },patchForItem 对于 capped 的文件退回到 nativePatch——逐个调 git diff --patch + 逐文件 maxOutputBytes: 10MB。
四层消费入口
| 消费方 | 调用路径 | 使用场景 |
|---|---|---|
| Agent 流程 | Vcs.Service.diff() |
review/commit 时获取结构化 diff |
| TUI 面板 | GET /vcs/diff?mode=git |
开发者手动查看变更 |
| SDK (JS) | client.diff({mode:"git"}) |
远程 instance 的 diff API |
| CLI 命令 | opencode pr <number> → 直接 Git.Service |
checkout PR 分支 |
CLI 的 opencode pr 命令绕过了 Vcs,直接调 Git.Service。因为它要做的事和 Vcs 不同——它要 git fetch origin pull/123/head + git checkout -b pr/123,跟 diff 无关。两层的设计允许 CLI 跳过业务语义层直接用机械层。
mode 参数的底层差异
两个 mode 走同一个 diffAgainstRef,但生成 ref 的方式不同。一个真实案例:你在 feature 分支上开发,Agent 修改了 3 个文件。此时:
diff("git")→ 3 个文件 vs HEAD(当前 session 的变更)diff("branch")→ 3 个文件 + 你之前提交的 10 个文件 vs main(整个分支的变更)
选择哪个取决于场景。Review 时应该用 branch——不只 review Agent 刚刚改的,还要看整个分支和 main 的差异。打开 GET /vcs/info 先看看当前是不是 feature 分支,再决定用哪个 mode。
Snapshot:第二个独立的 git 封装
Vcs 和 Git.Service 是 opencode 的"公开" git 抽象层。但还有一个"私有"封装在 snapshot 模块(packages/opencode/src/snapshot/index.ts)。Snpashot 不调 Git.Service,而是自己用 ChildProcess.make("git", args) 直接 spawn——因为它需要的 git 操作和 Git.Service 的 scope 完全不同。
Snapshot 的核心场景是追踪文件的版本历史,以便在 Agent 误操作后回滚文件状态。它自己维护一个独立的 git 仓库:
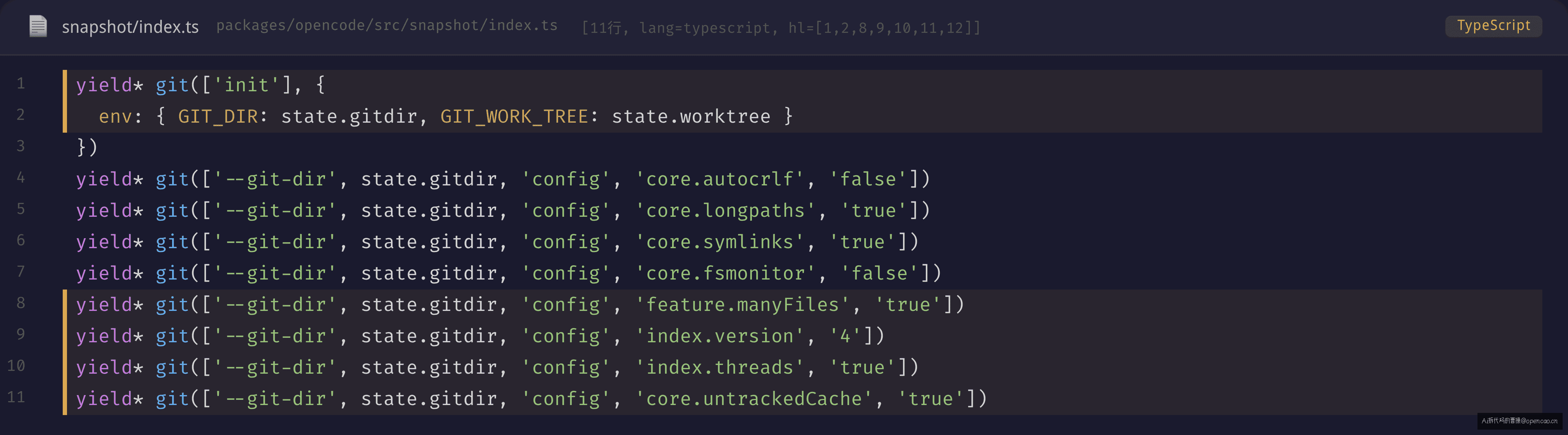
// snapshot 初始化时做的事
yield* git(["init"], {
env: { GIT_DIR: state.gitdir, GIT_WORK_TREE: state.worktree },
})
yield* git(["--git-dir", state.gitdir, "config", "core.autocrlf", "false"])
yield* git(["--git-dir", state.gitdir, "config", "core.longpaths", "true"])
yield* git(["--git-dir", state.gitdir, "config", "core.symlinks", "true"])
yield* git(["--git-dir", state.gitdir, "config", "core.fsmonitor", "false"])
yield* git(["--git-dir", state.gitdir, "config", "feature.manyFiles", "true"])
yield* git(["--git-dir", state.gitdir, "config", "index.version", "4"])
yield* git(["--git-dir", state.gitdir, "config", "index.threads", "true"])
yield* git(["--git-dir", state.gitdir, "config", "core.untrackedCache", "true"])
yield* seed() // 共享源仓库的 object store
关键差异:
| 维度 | Git.Service | Snapshot 内部 git |
|---|---|---|
| Git 目录 | 用户的 .git |
~/.local/share/opencode/snapshot/{projectID}/{worktreeHash}/ |
| 操作 | status/diff/patch/apply 读操作为主 | init/write-tree/read-tree/gc 写操作为主 |
| 参数风格 | 统一 cfg 数组 + 透传 args | --git-dir + --work-tree 参数注入 |
| 性能优化 | 无(消费方控制) | feature.manyFiles=true, index.version=4, index.threads=true |
| 生命周期 | 随 session 创建 | 随项目生命周期,独立 gc 清理 |
Snapshot 每次 track() 执行的工作流是:git add --all → git write-tree → 返回 tree hash。这个 hash 后续用于 git read-tree + git checkout-index -a -f 的完整还原。Git.Service 关注的 diff/patch 是"当前工作树的变化",snapshot 关注的是"文件在某时间点的完整状态"——两个不同的需求产生了两种不同的 git 封装。
但这里有一个精妙的设计:snapshot 启动时会调用 seed() 方法,通过 objects/info/alternates 共享源仓库的 object store。这意味着 snapshot 仓库里的 blob 不需要重新存储——直接从主仓库的 .git/objects/ 引用。对于 chromium 级别的大型仓库(百万级文件),一次 git add --all 本来要重新 hash 所有文件,通过 alternates 直接继承主仓库的 hash 结果,从分钟级降到秒级。
六层消费入口
Git.Service 的 15 个方法被 6 个不同模块消费,每种消费方式都不同:
| 消费者 | 文件 | 调用的方法 | 场景 |
|---|---|---|---|
| Vcs.Service | packages/opencode/src/project/vcs.ts |
diff, patch, patchAll, status, stats, applyPatch | Agent diff/review 工作流 |
| Storage | packages/opencode/src/storage/storage.ts |
run, hasHead | 迁移中获取初始 commit |
| Worktree | packages/opencode/src/worktree/index.ts |
branch, defaultBranch, run | Worktree 创建时检测分支 |
| CLI pr | packages/opencode/src/cli/cmd/pr.ts |
run | Fetch + checkout PR 分支 |
| GitHub handler | packages/opencode/src/cli/cmd/github.handler.ts |
run, branch | GitHub agent 安装和运行 |
| Snapshot(独立) | packages/opencode/src/snapshot/index.ts |
自建 git init 封装 | 文件状态追踪和回滚 |
Storage 迁移(packages/opencode/src/storage/storage.ts:7)直接引用 import { Git } from "@/git" 并在迁移函数签名中传入 Git.Interface:
type Migration = (dir: string, fs: FSUtil.Interface, git: Git.Interface) => Effect.Effect<void>
迁移 1(migration.1)用 git.run(["rev-list", "--max-parents=0", "--all"]) 找初始 commit 来锚定会话存储目录。这个调用不需要 Vcs 的业务语义,直接走 Git.Service 的 run 方法就行。迁移函数签名的设计说明了一个事实:Git.Service 被设计为底层基础设施,可以注入到任何需要 git 调用的模块里,不受上层业务逻辑的约束。
权限系统如何识别 git 命令
当用户在 TUI 中输入 git checkout main 后按 Tab,opencode 的权限系统需要知道自己正在"允许一个 git checkout 操作"还是"允许一个不相关的命令"。这依赖于 arity 检测(packages/opencode/src/permission/arity.ts)。
arity 字典里 "git": 2,意思是 git checkout 的 human-readable 命令是 2 个 token。权限系统拿到 tokens = ["git", "checkout", "main"],从最长的前缀开始匹配:"git checkout main" 不在字典里 → "git checkout" 不在字典里(因为 git 的 arity=2 已覆盖)→ "git" 在字典里,arity=2 → 返回 ["git", "checkout"]。
这个检测让用户在授权时看到的是"允许 git checkout"而不是"允许 git"或"允许 git checkout main"。前者太笼统(所有 git 子命令被混为一谈),后者太具体(每个不同的目标分支都要重新授权)。选择 2 个 token(git checkout)作为授权粒度是经过考虑的——git 的子命令就是权限边界,checkout、commit、push、rebase 对人来说是完全不同的操作,应该各自授权。
这个 arity 字典里还有 "npm": 2、"npm run": 3、"docker": 2、"kubectl": 3 等级联规则。设计原则是:越长的前缀优先级越高,不同命令的授权粒度根据子命令结构动态决定。
【权衡】为什么直接 spawn git,不用 isomorphic-git 或 libgit2?
三个方案,三种失败模式

| 维度 | spawn git(opencode 选的) | isomorphic-git | libgit2 (nodegit) |
|---|---|---|---|
| 安装 | 0 依赖,系统自带 | npm 包,纯 JS | C++ 编译,Windows 频繁炸 |
| 性能 | 子进程 I/O 瓶颈 | JS 虚拟 fs 约慢 10x | 最优 |
| 语义完整度 | 100%(完整 git 实现) | 部分(无 merge/push) | ≈95% |
| Error handling | Effect.catch 兜底 | 需自行 try-catch | Promise 风格 |
| 适用范围 | Node.js 原生进程 | 浏览器 / Deno | 需完整 git 嵌入 |
isomorphic-git 是为浏览器设计的——在 JS 层模拟一个全虚拟文件系统(lightning-fs),然后在这个虚拟 fs 上跑 git 算法。opencode 100% 跑在真实文件系统上,多一层虚拟 fs 只有开销没有收益。而且 Node.js 原生 fs 模块已经提供了文件 IO,用 JS 虚拟 fs 重新实现一遍只会慢。
libgit2 的问题不是它不好,而是 scope 不匹配。opencode 只用 status、diff、patch、apply 三类操作,libgit2 的 500KB C 扩展提供一个完整 git 嵌入库,opencode 只用 3 个 API。代价:每个平台都要编译(Windows 经常 link 失败),Serverless 环境(GitHub Codespaces、容器)要额外加载 C 扩展,出问题比纯 JS 难调试。
spawn git 的真正制约不是性能,是错误语义的损失。 Effect.catch 解决了崩溃安全的问题,但引入了一个新问题:
exitCode !== 0 → 到底是 git 命令失败,还是 git 命令成功但输出为空?
两者在 Result 里无法区分——返回都是 { exitCode: 1, text: "" }。调用 diff() 时如果返回空数组,调用方不知道是"没有变更"还是"git 命令执行失败了"。Vcs.Service 里的 diff 方法的处理方式是:git 失败了也返回空数组,把错误打日志。这不完美,但对 Agent 工作流来说是可接受的——Agent 拿到空数组后认为自己没有改动,后续 review/commit 操作自动跳过。最坏情况是"应该 review 的文件没被 review 到",但不会崩进程。
回想开篇的 execSync naive 方案:它不仅要面对前文说的 3 个问题(跨平台差异、无 HTTP API、阻塞主进程),还有一个更隐蔽的约束——无法与 Effect 的错误处理模型集成。execSync 在 Node.js 里抛异常是同步的,try-catch 只能包住调用点,包不住整个 Agent 流程。opencode 的 Agent 流程是用 Effect 编排的——并发请求、超时控制、资源清理都是 Effect 的作用域管理。在 Effect 流程里塞一个 try-catch + execSync,要么退出 Effect 的作用域管理,要么把 execSync 用 Effect.promise(() => execPromise(...)) 包一层再 try-catch——无论如何都比直接 spawn git 多一层胶水代码。
这是 spawn-based 系统命令封装的共同 tradeoff:你放弃了精确的错误语义,换来了 0 依赖安装和 100% git 兼容性。 在 opencode 的上下文里这个 tradeoff 合理——opencode 需要处理任意 git 仓库(包括有 submodule——嵌入子仓库、sparse checkout——部分检出而非全量克隆、worktree——同一仓库多工作目录并存的复杂项目),只有原生 git 能做到"遇到什么仓库都不出错"。
为什么会有两个 git 封装?
这就引出一个问题:Git.Service 已经在 350 行里统一了 git 调用的接口和错误处理,为什么 Snapshot 不直接用 Git.Service,而要自己再写一个 git spawn?
答案是:操作目标和性能需求不同。
Git.Service 的所有方法都以 cwd(当前工作目录)作为第一个参数。它操作的是用户仓库的 .git。Vcs.Service、Storage 迁移、Worktree 管理都共用这个 cwd 语义。
Snapshot 操作的不是用户仓库的 git——它在 $HOME/.local/share/opencode/snapshot/{id}/ 下维护了一个独立的 git 仓库,所有的 git 命令都必须带 --git-dir 和 --work-tree 参数指向这个独立仓库。如果复用 Git.Service,需要为每个方法都加一个 gitDir 参数,Interface 签名会从 (cwd, args) 变成 (cwd, args, gitDir?)——每个调用点都要传三参数,反而比直接 spawn 更啰嗦。
性能需求也不同。Git.Service 的 cfg 只有 6 个参数(autocrlf、symlinks、longpaths、fsmonitor、quotepath、no-optional-locks),覆盖的是跨平台兼容性。Snapshot 的 git init 设置了 9 个参数,多出来的 3 个(feature.manyFiles、index.version=4、index.threads=yes)专门针对大型仓库的 git add 性能优化。这 3 个参数对 Git.Service 没有意义——Vcs 做 diff/patch 时的文件数远小于 snapshot 做 git add --all 时的文件数。
所以 opencode 最终有两个 git 封装,各有各的 scope。Git.Service 是"工具级封装"——提供一个可复用的类型安全接口;Snapshot 是"应用级封装"——它有自己的 git 仓库生命周期管理。两者都用 spawn git,但配置不同、操作不同、边界不同。
这种模式在其他系统命令封装中也能看到。你的 CI/CD 系统跑 docker build 和 docker compose up 用的是同一套 Docker CLI,但配置参数完全不同(--build-arg vs --profile),你也不会把它们塞进同一个 Interface 里。系统命令封装的粒度应该和使用场景的边界对齐,不是对齐底层命令。
【锚点】Process-as-a-Service 模式
一句话金句
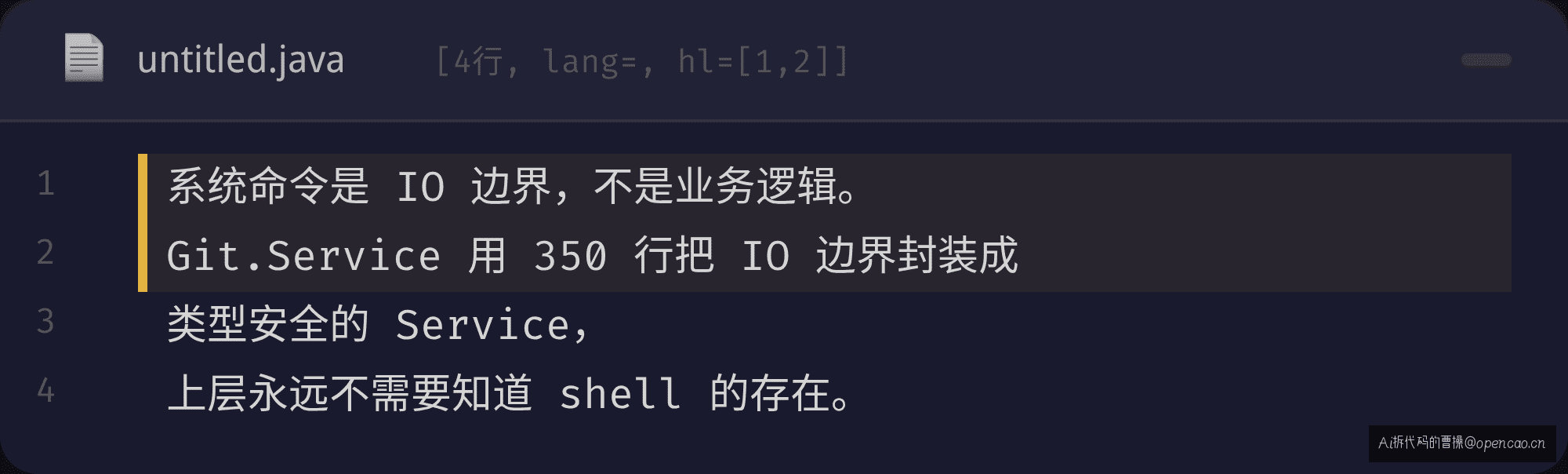
系统命令是 IO 边界,不是业务逻辑。Git.Service 用 350 行把 IO 边界封装成类型安全的 Service,上层永远不需要知道 shell 的存在。
不是写一个 Git 工具类。是定义一个 Interface(15 个方法),每个方法签名精确到入参和返回类型。调用者只写 git.diff(cwd, ref),不写 execSync("git diff --name-status HEAD")。
这个模式的泛化结构是:
系统命令 → 统一参数(8 个 cfg 解决跨平台差异)
→ Effect 安全网(catch 所有崩溃,不抛异常)
→ 结构化类型返回(不是 stdout 字符串,是 Item[]/Patch/Stat)
下次你需要封装 docker、podman、kubectl 等系统命令时,记住这个结构。Interface 定义在前,实现细节在后。调用者只和 Interface 里的类型安全方法打交道。
但 Process-as-a-Service 模式有一个反直觉的边界判断:不是每次 spawn 一个系统命令都需要一个 Service Interface。 判断标准是——这个命令是否被多个不同语义层次的模块同时消费。Git 被 6 个模块消费(Vcs、Storage、Worktree、CLI pr、GitHub handler、Permission arity),所以值得一个 Service。Docker 在 opencode 里只在插件安装时用一次,不值得一个 Service——一次 child_process.exec("docker ps") 就够了。封装是有成本的,多次消费才分摊成本。
但如果同一个命令被两个语义差异很大的场景消费,各自封装可能比封装成一个更合理。Git.Service 和 Snapshot 的 git 就是例证——它们共享 spawn 逻辑但配置和操作完全不同,封装在一起只会让 Interface 膨胀、文档复杂、测试耦合。封装按场景边界划分,不是按底层命令划分。
结语
Git 集成的意义超越了"封装了一个 git 调用"。这篇文章拆了三个层次:
第一层——Git.Service 解决了"怎么安全调用 git"的问题。6 个跨平台 cfg、Effect.catch 兜底、15 个结构化方法。你不需要在每个工具函数里写 execSync。
第二层——Vcs.Service 解决了"业务需要什么语义"的问题。mode="git" 和 mode="branch" 两个模式把 diff 的边界计算封装成 1 个方法调用。Agent 不需要知道 merge-base、HEAD 存在性、默认分支名——Vcs 帮你处理了 5 个边界。
第三层——Snapshot 的自建 git 仓库解决了"如何追踪文件历史状态"的问题。它在用户仓库之外建了一个独立 git 仓库,用 write-tree/read-tree 管理文件快照,alternates 共享 object store 避免了重复 hash。这个封装和 Git.Service 不共享——不是不能,而是不该。操作目标不同、性能参数不同、生命周期不同。
如果你觉得这种源码拆解对你有帮助,可以转发给团队——三层的封装边界划分在微服务集成和基础设施抽象时直接可复用。
下篇拆 project/workspace 管理,看第四个模式:工作单元的生命周期管理。
📺 公众号「Ai拆代码的曹操」 🌟 知识星球「Ai拆代码的曹操」


