
project/workspace 管理:工作单元的组织方式
场景:Agent 打开一个目录就开始工作了——但 opencode 怎么知道这是个什么项目、是不是 git 仓库、之前有没有 session? 路径:
packages/opencode/src/project/→instance-context.ts/project.ts/instance-store.ts
上篇拆了 Git 集成——opencode 用两层抽象把 git 封装成类型安全的 Service。这篇来看 project/workspace 管理——工作单元怎么被组织和追踪的。
如果你要设计一个 AI Agent 的工作单元——它需要知道当前在哪个目录工作、项目有没有 git、该目录之前有没有 session——你会怎么抽象?
一个直观的想法是:直接用 process.cwd() 当 session 的唯一标识,current working directory 是哪就是哪。但如果你在同一个 monorepo 的不同子目录里分别启动 Agent——packages/opencode/ 和 packages/core/——它们在同一个 git 仓库里,共享同一个 .git 目录。process.cwd() 给两个不同的路径,但逻辑上它们属于"同一个项目"。反过来,如果你用 git worktree 同时打开同一个仓库的不同分支——/project/main 和 /project/feature——两个目录有各自的 .git,是独立的项目。cwd 既不能唯一标识项目,也不能唯一标识工作单元。
所以 opencode 的选择是:用一个三元组(directory, worktree, project)来定义工作单元,用 InstanceContext 绑定这三个字段。 整个 project/workspace 管理模块 700 行,核心就是三件事——项目从目录自动发现、InstanceContext 生命周期管理、sandboxes(一个项目关联的多个工作目录,如 monorepo 中不同子目录)多目录支持。
【问题】"这个文件属于哪个项目"的三个变形
directory ≠ project:反直觉的第三个字段
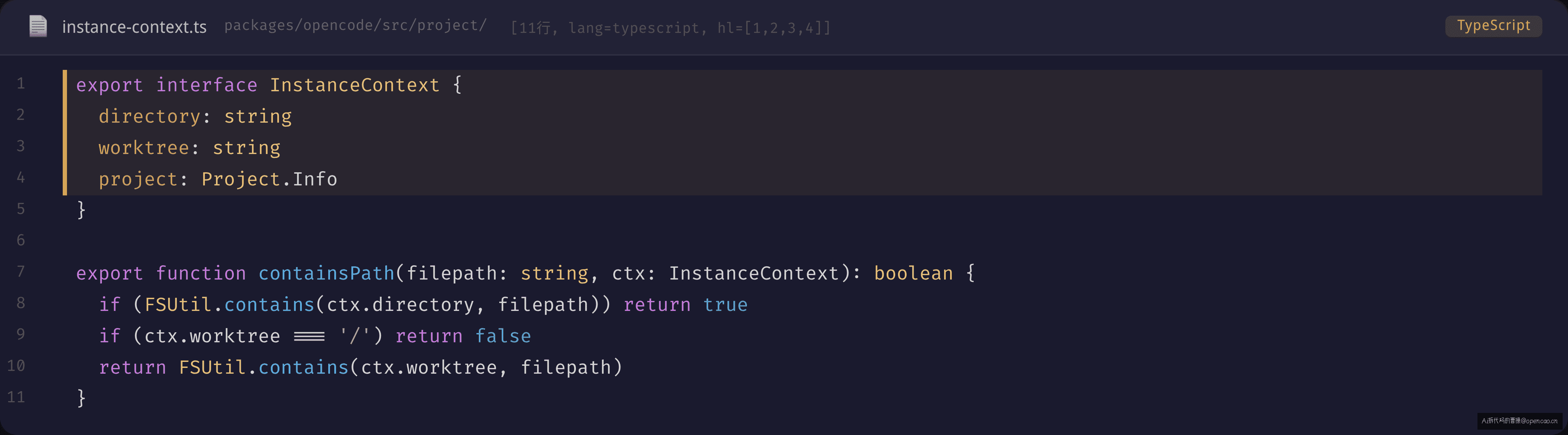
InstanceContext 定义在 packages/opencode/src/project/instance-context.ts:5-9,只有 3 个字段:directory、worktree、project。但为什么需要三个?两个(directory + project)不够吗?
如果 opencode 只用 directory(当前工作目录)做唯一标识,那在同一个 git 仓库的不同子目录启动 session 就会被视为"不同项目"——但它们的 git 仓库是同一个,sandboxes 应该合并而不是新建。反过来,如果只用 worktree(git 仓库根目录),那用 git worktree 切换分支时,两个 worktree 路径不同但共享没写完的 session 数据应该隔离。
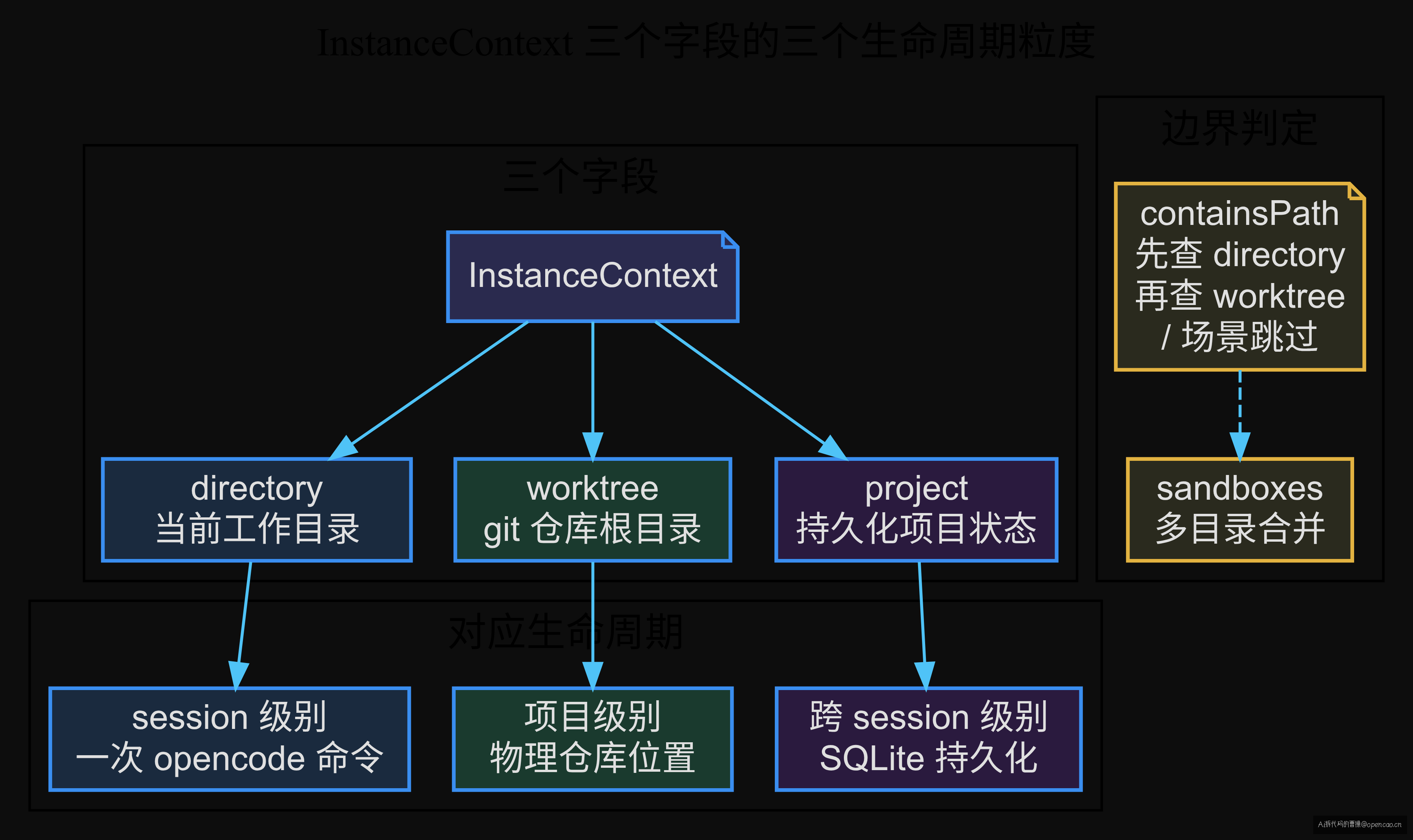
所以三个字段对应三个不同的生命周期:directory 是 session 粒度的(一次 opencode 命令的上下文),worktree 是项目粒度的(git 仓库物理位置),project 是跨 session 粒度的(DB 里持久化的项目状态)。三个粒度,三种消费场景。
实际生效的边界判定在 containsPath(instance-context.ts:18-23):
export function containsPath(filepath: string, ctx: InstanceContext): boolean {
if (FSUtil.contains(ctx.directory, filepath)) return true
if (ctx.worktree === "/") return false
return FSUtil.contains(ctx.worktree, filepath)
}
先 check directory——如果文件在 session 的启动目录内,直接通过。再 check worktree——非 git 项目设 worktree 为 "/",会匹配所有绝对路径,所以 / 场景跳过 worktree 检查。这个 / 值的处理不是边界 hack,而是设计选择:全局模式的 worktree 就是 /,此时文件访问只受 directory 约束。如果你在 /tmp 下面跑 Agent,且 /tmp 不是 git repo,那 /tmp 就是你全部的可见空间——既不该问 /etc 属不属于你(不在 directory 内,也不在 worktree 内),也不该误以为 / 内的东西都归你管(worktree 被跳过)。
为什么不是 git 目录就不是项目
opencode 的项目发现机制有一个隐藏的设计规则:没有 git 的项目不是"项目",只是一个目录。 非 git 项目的 worktree 被硬编码为 /,sandboxes 为空数组,project.id 设为 global。这不是歧视非 git 项目——而是因为 opencode 的大部分功能(diff/review/checkout/commit/apply patch)强依赖 git。没有 git,Agent 的写操作没有回退能力,review 没有基准线,branch 切换没有感知。如果一个目录确实没有 git,opencode 也允许你工作——只是限制在"只读 consult(咨询式对话)"模式,不能做写操作。
这个设计选择背后的工程理由是:git 是 opencode 的底层存储抽象,不是可有可无的工具。 第三章之前拆的 Git.Service 的 350 行、Vcs 的 431 行、Snapshot 的自建 git 仓库——它们都假设 git 存在。在非 git 项目上,这些模块不会抛错(Effect.catch 处理了),但实际上不会执行任何有用操作。所以 fromDirectory 在发现没有 git 时,设置 vcs: undefined,后续所有 git 依赖的功能自动降级。
【设计】三层抽象:directory → project → instance
InstanceContext:三个字段定边界
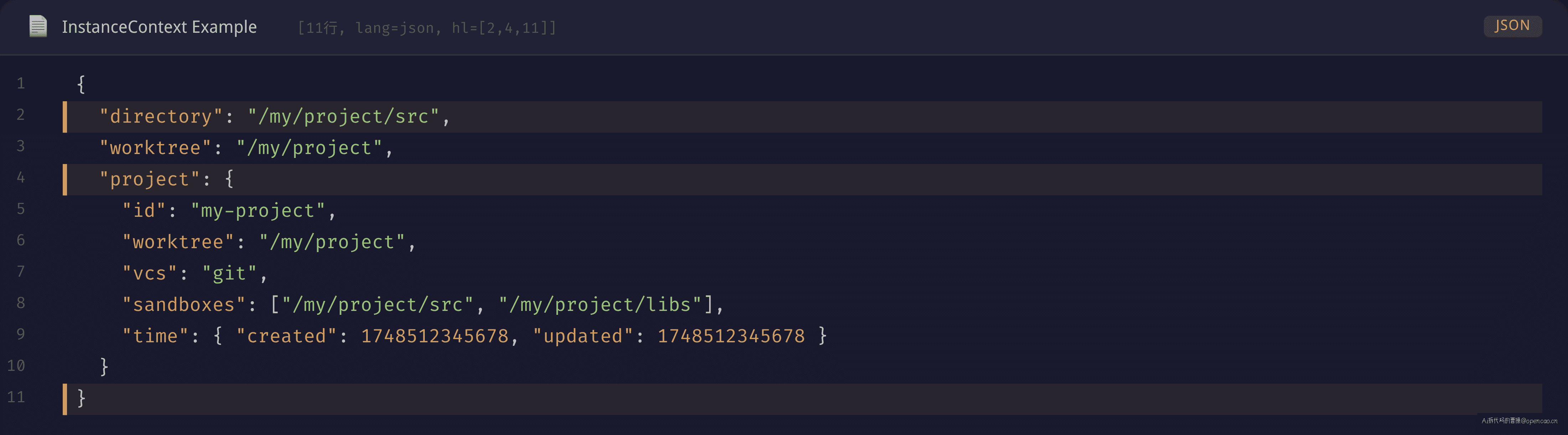
整个工作单元模型的入口是 InstanceContext。如果你用 InstanceStore.load("/my/project") 拿到的是:
{
directory: "/my/project/src", // session 启动目录
worktree: "/my/project", // git 仓库根目录
project: {
id: "my-project", // 项目唯一标识
worktree: "/my/project",
vcs: "git",
sandboxes: ["/my/project/src", "/my/project/libs"],
time: { created: 1748512345678, updated: 1748512345678 }
}
}
三个字段的关系是:directory ⊆ worktree(session 目录一定在 git 仓库内),worktree 是 project.worktree 的值(一个 project 只有一个物理 worktree),sandboxes 可以用来记录额外的 session 启动目录。所以 containsPath 需要先查 directory 再查 worktree——sandboxes 里记录的目录可能不在 worktree 下面(比如 Cargo workspace 的独立 crate 目录)。
这里的关键设计决策:InstanceContext 是一个贫接口,不是一个富 Service。 它不做任何事,只是把三个字段绑在一起。实际的操作(项目发现、生命周期管理、session 关联)都委托给其他 Service。InstanceContext 只是"结果的快照",不是"过程的控制器"。这意味着你可以安全地跨模块传递 InstanceContext,不需要担心它持有锁或引用。
fromDirectory:5 步自动发现管道
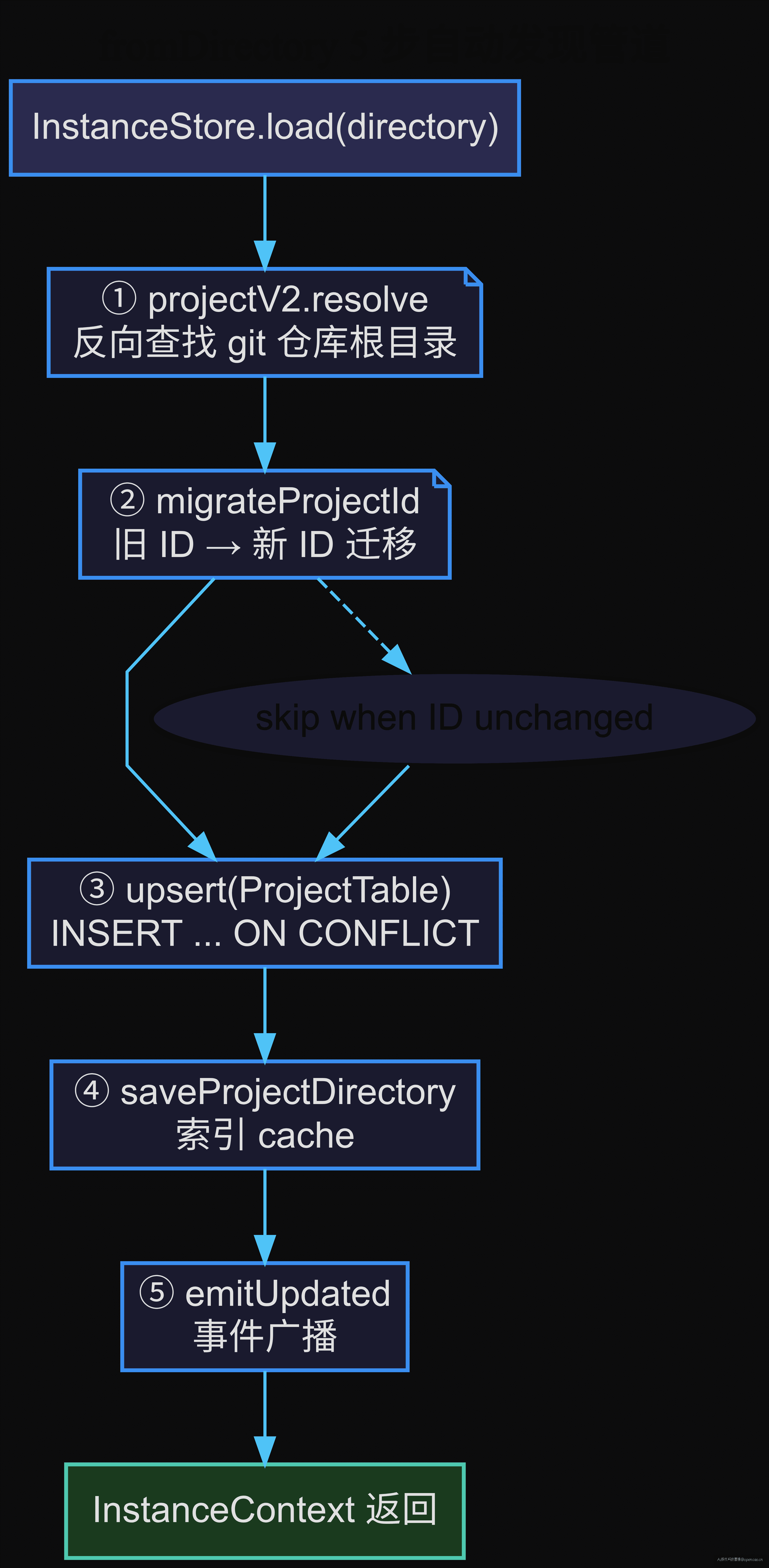
Project.fromDirectory(project.ts:242-339)是项目发现的入口,5 步走完从路径到完整 project 的映射:
① projectV2.resolve(AbsolutePath.make(directory)) — 核心库调用。从给定路径反向查找最近的 git 仓库根目录(找 .git 目录链),返回 { id, directory, vcs }。这一步决定了"我在哪个项目里"。
② migrateProjectId(previous, projectID) — 项目 ID 迁移。如果 resolve 发现旧 ID 和新 ID 不同(比如项目被重命名或 .git 配置变了),迁移 DB 中的 session、workspace 记录到新的 ID。这是 git worktree 切换后的关键保障——切换分支后 .git 的 worktree 配置变了,resolve 可能返回不同 ID,迁移确保 session 不丢失。
③ upsert(ProjectTable) — DB 行写入。INSERT ... ON CONFLICT DO UPDATE,把 resolved 的 project 信息持久化到 SQLite。核心行只有 60 行,但覆盖了 worktree、vcs、name、icon、sandboxes、commands、time_initialized 共 7 个字段的 upsert。
④ saveProjectDirectory — 辅助索引。在 ProjectDirectoryTable 中记录 directory → projectID 映射。这个表只做一件事——后面 InstanceStore.load 不用管 project 发现逻辑,直接从这个表查当前目录属于哪个 project。
⑤ emitUpdated — 事件通知。发出 project.updated 事件,GlobalBus 把新状态广播给所有订阅者(TUI、SDK event stream、工作区面板)。
5 步中,第 ① 步是最频繁的执行路径——每次 InstanceStore.load 都会调一次 fromDirectory。如果项目已经在 DB 里了,第 ② 步会跳过(迁移只在 ID 不同时才跑),第 ③ 步是 upsert(有则更新无则插入),第 ④ 步是插入。整体成本≈一次 resolve + 一次 upsert + 一次 insert + 一次事件广播≈3ms(本地 SQLite)。
Project Schema:9 个字段定义项目状态

export const Info = Schema.Struct({
id: ProjectV2.ID,
worktree: Schema.String,
vcs: optionalOmitUndefined(ProjectVcs),
name: optionalOmitUndefined(Schema.String),
icon: optionalOmitUndefined(ProjectIcon),
commands: optionalOmitUndefined(ProjectCommands),
time: ProjectTime,
sandboxes: Schema.Array(Schema.String),
}).annotate({ identifier: "Project" })
9 个字段(project.ts:45-54)分为三组:
标识组(id, name, icon)——你是谁。id 是自动生成的(由 git repo 的 path hash 决定),name 和 icon 由用户设置或自动发现(discover() 方法在 worktree 里扫 favicon.*)。
边界组(worktree, vcs, sandboxes)——你在哪。worktree 是物理根目录,vcs 是版本控制类型(目前只有 "git"),sandboxes 是额外的工作目录列表。sandboxes 的存在让一个 project 可以关联多个路径——比如你同时打开 libs/core/ 和 apps/web/ 两个目录,它们共享同一个 git 仓库(同一个 id),open system 会把两个目录都加入 sandboxes,后续的 fromDirectory 不会重复创建 project。
生命周期组(time.created, time.updated, time.initialized)——什么时候开始的。initialized 是一个特殊的时间戳——它在用户第一次执行 /init 命令时设置。这个字段的存在说明了一个设计意图:项目创建和项目初始化是两个独立的事件。 前者在 fromDirectory 中自动发生(第一次打开目录就注册了),后者需要用户显式触发(执行 /init 设置项目配置)。用户可能只是临时打开一个目录查资料,还没决定要不要在这个项目里做实质性工作——opencode 不会因为没有初始化就报错或阻塞。
特别的:time.initialized 的设置不通过 Project Service 本身,而是通过订阅 Command.Event.Executed 事件(project.ts:416-425)。这种做法符合 opencode 的一贯风格:核心 Service 不耦合具体命令逻辑。
【源码】InstanceStore:工作单元生命周期
Deferred 异步加载:同一个目录的请求合并

InstanceStore(instance-store.ts:108-124)是整个 project/workspace 管理的运行时核心。它的 load 方法不是直接调 boot,而是用了一个精妙的模式:
const load = (input: LoadInput): Effect.Effect<InstanceContext> => {
const directory = FSUtil.resolve(input.directory)
return Effect.uninterruptibleMask((restore) =>
Effect.gen(function* () {
const existing = cache.get(directory)
if (existing) return yield* restore(Deferred.await(existing.deferred))
const entry: Entry = { deferred: Deferred.makeUnsafe<InstanceContext>() }
cache.set(directory, entry)
yield* Effect.forkIn(scope, { startImmediately: true })(
Effect.gen(function* () {
yield* completeLoad(directory, input, entry)
}),
)
return yield* restore(Deferred.await(entry.deferred))
}),
)
}
三步走:① cache hit → 等已有的 Deferred(Effect 中代表异步结果的容器,可被 await 一次或多次)完成。② cache miss → 创建 Deferred,forkIn 后台跑 boot。③ 调用方挂起等结果。
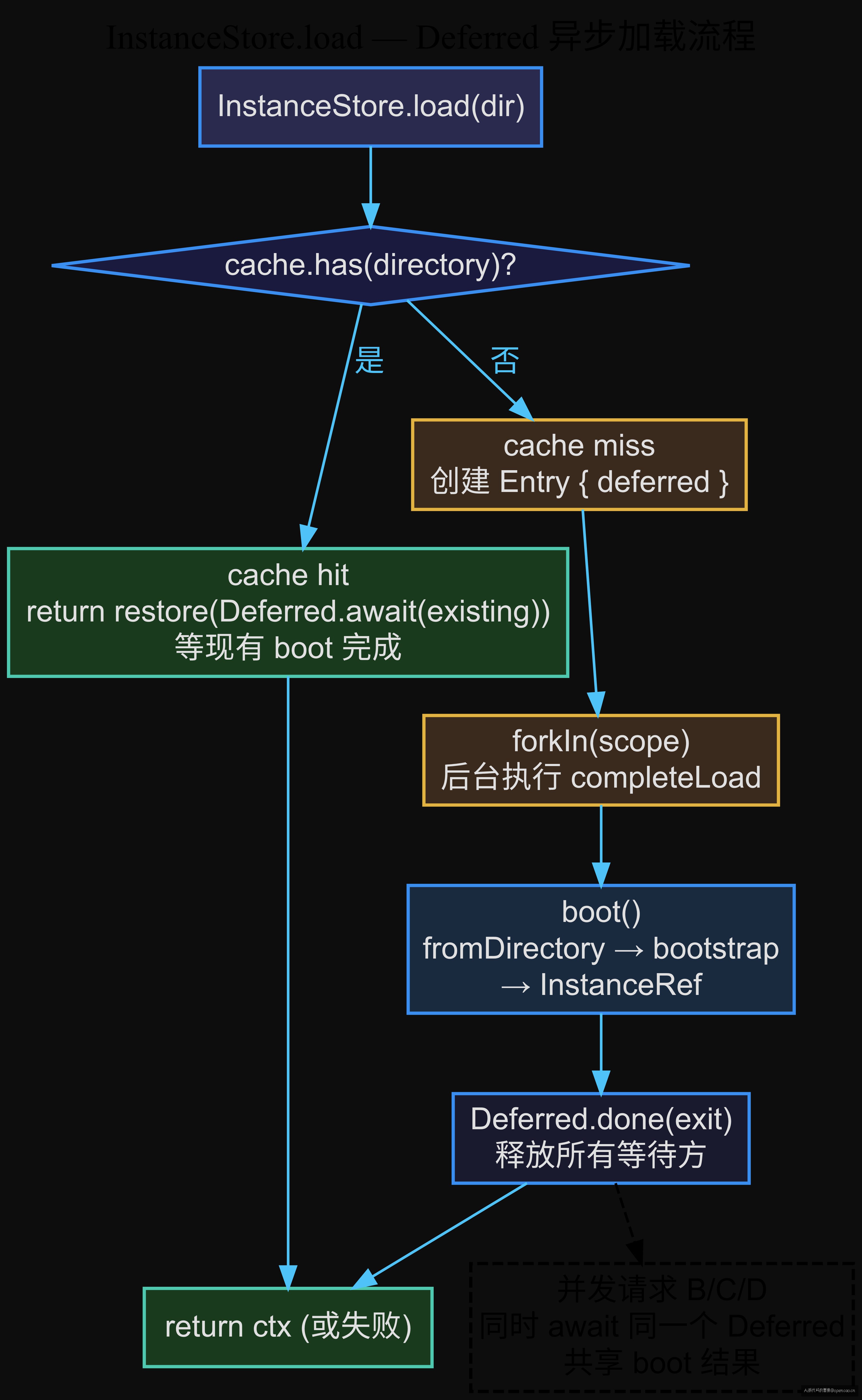
这里的关键是 forkIn(scope, { startImmediately: true })——boot 过程不阻塞当前 Effect 流程。load 立刻返回 Deferred.await,让调用方感知到的只是"我拿到了一个 ctx"。如果 boot 失败,Deferred.done(exit) 会释放所有等待的调用方,它们同时拿到失败结果,不会多个调用方各自重试。
为什么不用简单的 Promise.all 模式?因为同一个 session 多次调 load(如 config-service 和 project 同时需要 InstanceContext),如果 Promise.all 会触发两次 boot。Deferred 模式跟 Map 绑定,确保同一个 directory 只有一个 boot 在执行。opencode 用这个模式在多个场景中处理"同源并发"——capture-screenshots.js 的 HTTP server 初始化、Config.Service 的远程配置加载、Watcher 的文件系统监听初始化——都是先 check cache,没有才创建,保证只有一个执行者。
boot:fromDirectory → bootstrap → InstanceRef
boot 函数是 load 的实现细节(instance-store.ts:45-63):
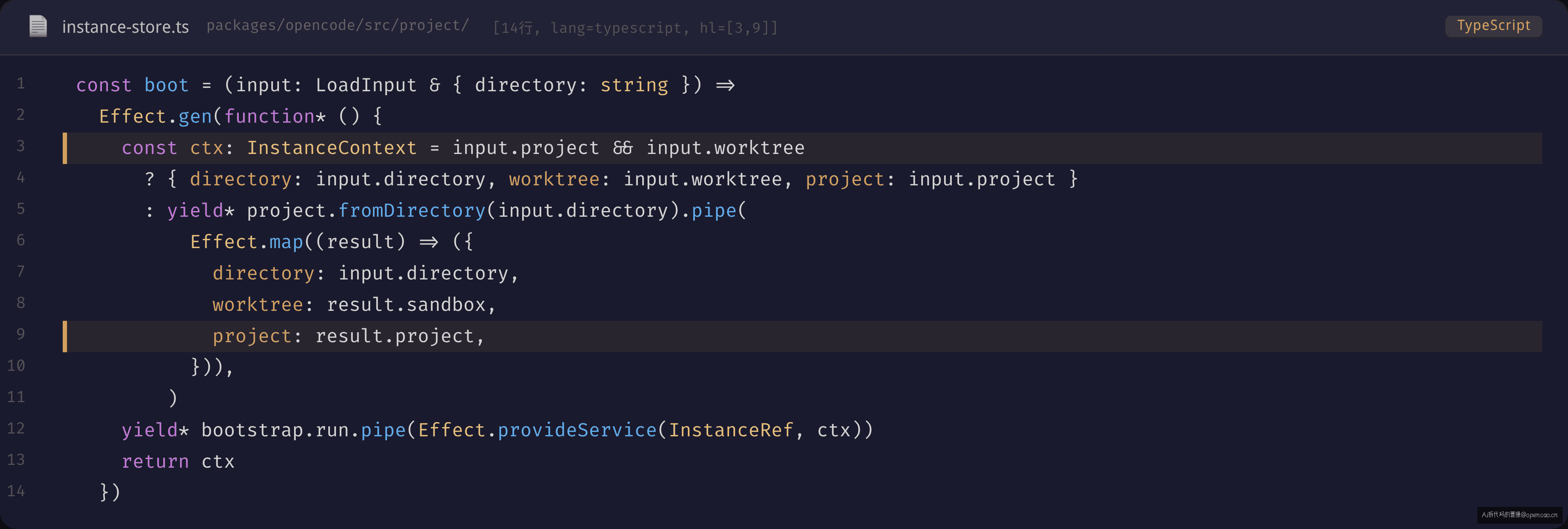
const boot = (input: LoadInput & { directory: string }) =>
Effect.gen(function* () {
const ctx: InstanceContext = input.project && input.worktree
? { directory: input.directory, worktree: input.worktree, project: input.project }
: yield* project.fromDirectory(input.directory).pipe(
Effect.map((result) => ({
directory: input.directory,
worktree: result.sandbox,
project: result.project,
})),
)
yield* bootstrap.run.pipe(Effect.provideService(InstanceRef, ctx))
return ctx
})
两段逻辑:如果调用方直接传了 project + worktree(比如 reload 场景),跳过 fromDirectory,直接构造 InstanceContext。否则走 fromDirectory 的自动发现管道。
拿到 ctx 后,立即执行 bootstrap.run。InstanceBootstrap 的定义在 bootstrap-service.ts——它只是一个 Effect.Effect<void> 的 Interface。具体实现由 bootstrap.ts 提供,内容包括:Watcher(文件系统监听器)初始化、EventV2 会话建立、Permission 上下文绑定。所有这些初始化操作都通过 Effect.provideService(InstanceRef, ctx) 注入 ctx——bootstrap 实现方通过 InstanceRef 拿到当前 instance 的 InstanceContext,不需要知道调用方是谁。
这里的设计模式值得注意:InstanceRef 是一个 Context Service,不是全局变量。 provideService 把 ctx 注入到 Effect 的作用域里,bootstrap 实现方 yield* InstanceRef 获取。不依赖全局变量、不污染函数签名。Effect 的 Layer 系统保证了这个注入是类型安全的——如果你在 bootstrap 里尝试获取一个没有注入的 Service,TypeScript 编译期就报错。
dispose:三路清理 + EventBus 事件

整个 instance 的生命周期从 load → boot → use → dispose:
Instance 的销毁配置了三路清理:
路径 A:dispose(ctx) — 从外部传入 ctx,cache 中查找对应 entry,验证匹配后清理。这是 TUI 关闭面板、SDK 客户端断开、用户手工 /exit 时的清理路径。
路径 B:disposeDirectory(directory) — 只通过目录名清理。不知道 ctx 的情况下(如清理脚本、后台 GC 任务)也能精确清理特定目录。
路径 C:disposeAll() — 销毁所有 instance。进程退出时执行,用 cachedWithTTL(Duration.zero) 确保只执行一次。Scope.addFinalizer 在 layer 初始化时注册了这个清理函数——layer 的 scope 就是一个 instance 的"全局生命周期"。
三层 dispose 共享同一个 disposeContext 函数(instance-store.ts:94-98):
const disposeContext = Effect.fn("InstanceStore.disposeContext")(function* (ctx: InstanceContext) {
yield* Effect.promise(() => runDisposers(ctx.directory))
yield* emitDisposed({ directory: ctx.directory, project: ctx.project.id })
})
runDisposers 是注册在 instance-registry.ts 中的同步函数集合(通过 disposeInstance 注册)。每个模块在初始化时通过 disposeInstance 注册自己的清理函数——Watcher 关闭文件监听、Session 保存未完成的 session 数据、Permission 释放权限缓存。这种"注册式清理"的好处是:InstanceStore 不需要知道有哪些模块需要清理,只要遍历 registry 逐个调就行。
最后 emitDisposed 发出 server.instance.disposed 事件。这个事件被 GlobalBus 广播给所有连接——TUI 面板关闭标签页、SDK client 收到 instance 断开通知、HTTP API 的 workspace routing 清理路由表。
【权衡】为什么不用全局单例?
三个方案,一个选择

naive 方案是全局单例——系统里只有一个 InstanceContext,谁需要谁 import。opencode 的作者实际也考虑过,而且代码库里有遗迹——GlobalBus 本身就是一个全局单例,但 InstanceStore 没有走这条路。
| 维度 | 全局单例 | 目录映射(opencode 选的) | 懒加载 Proxy |
|---|---|---|---|
| API 简洁度 | Instance.current() |
InstanceStore.load(dir) |
instance(directory).project |
| 多目录并发 | ❌ 不支持 | ✅ 每个目录独立 ctx | ✅ 原型支持 |
| 清理粒度 | ❌ 全局一起清 | ✅ 按目录精确清理 | ⚠️ GC 难度 |
| 类型安全 | 好(有状态) | 好(每个 load 返回新值) | 差(Proxy 返回的类型不确定) |
| 实现复杂度 | 50 行 | ≈200 行 | 约 400 行 |
全局单例被否决的原因不是多目录并发(Agent 一次只跑一个 session 的场景居多),而是清理粒度。sandboxes 的存在意味着一个 project 可能关联多个目录。如果全局单例,A 目录的 instance 清理会干掉 B 目录的 boot 结果。opencode 的 disposeDirectory(dir) 可以精确清理,因为 cache 的 key 是 directory。
那极端的场景是:同一个目录被两个不同的 session 同时使用(如两个 WebSocket 客户端同时连接到同一个 instance)。这是否会导致 cache 被覆盖?看 load 的实现——cache.set(directory, entry) 会覆盖,但第二个请求不会销毁第一个的 ctx(通过 restore(Deferred.await(entry.deferred)) 返回同一个 ctx)。两个 session 拿到的 InstanceContext 引用相同,谁调 dispose 也不会影响到另一个(dispose 验证了 Entry 的匹配才清理)。但如果第一个 session 调了 disposeDirectory,第二个 session 的调用会拿到 disposed 后的 ctx。opencode 对这个场景的态度是:同一个目录不应该同时被两个独立 session 管理——如果有,后面的 session 应该先启动 admin 操作(决定是接管还是等待)。InstanceStore 的 reload 方法就是为接管设计的——它先 dispose 旧的,再 boot 新的。
那为什么非要一个 map
这个问题问到 Effect 的作用域边界了。load 返回的 ctx 是 Effect 值,不是 Service——它不会被 Layer 自动管理。如果把 ctx 放到 Scope 里(像 Watcher 的文件监听那样),那每个调 load 的调用方都要自己管理 scope 生命周期,一个 scope 过期 ctx 就丢了。InstanceStore 选择用 Map + Deferred 是自己管理生命周期——不依赖调用方的 scope 管理。代价是多了 dispose 的手动清理步骤,但换来的是 ctx 的生命周期不绑定在某个 Effect 流程上——即使用户断开 WebSocket(Effect scope 被清理),ctx 还在 cache 里,下次同一个目录重连不重建。
【锚点】Context-as-a-Service 模式
三个字段定义了一个工作单元的一生
InstanceContext 的三个字段(directory / worktree / project)不是数据的组合,是三种粒度的生命周期。session 级别的 directory、项目级别的 worktree、持久化的 project——读懂了三个粒度,就读懂了 opencode 的工作单元管理。
从这篇文章你可以带走三个心智模型:
第一——项目的"身份"由 git 决定,不是由用户决定。opencode 的 fromDirectory 用 projectV2.resolve 反向查找 git 仓库,然后 upsert 到 SQLite。没有 git 的目录仍然是可工作的,但它的 project.id 是 global,vcs 是 undefined,sandboxes 是空数组——所有 git 依赖的功能自动降级。这个设计的力量在于:你不需要告诉 opencode"我在做什么项目"——它自己查。
第二——InstanceContext 的"贫接口"是故意的。它只有三个字段,不做任何操作。InstanceStore 提供 load/reload/dispose 生命周期,Project.Service 提供 fromDirectory/list/update 查询管道——但 InstanceContext 不引用它们任何一个。这意味着它可以在任何 Effect 作用域里安全传递,不会因为携带了 Service 引用导致循环依赖。
第三——Deferred + Map 是 Effect 世界里的"懒加载单例"模式。不在启动时创建所有 instance(不知用户要开哪个目录),也不在每次调用时重新创建(成本高)。第一次被请求时创建并缓存,后续请求复用——用 forkIn 把初始化过程沉到后台,调用方只看到 Deferred.await。这个模式在 opencode 里出现了至少 4 次(InstanceStore、Config 远程加载、Watcher 初始化、capture-screenshots HTTP server),是 Effect 生态的惯用做法。
下次设计工作单元时
当你的系统需要管理多个"上下文"——每个上下文有自己的目录、配置、状态——按 opencode 的模式分三步:定义 InstanceContext(贫接口,只绑定数据)、定义 InstanceStore(提供生命周期和并发控制)、定义消费方接入点(通过 provideService 注入 InstanceRef)。三步走完,工作单元的生命周期管理就成型了。
但这个模式有一个反直觉的适用边界:不是每个需要目录的地方都需要 InstanceContext。 判断标准是——这个上下文是否需要跨模块共享、是否需要在 dispose 时触发清理。Opencode 的 Watcher 只在自己模块里用了一个 Map<string, WatchHandle>,没有走 InstanceStore,因为 Watcher 不需要跨模块共享——它在 bootstrap.run 里初始化,在 disposeInstance 里注册清理,生命周期完全自包含。上下文的共享范围决定了是否需要中心化的生命周期管理。 如果只有一个模块消费,用模块自己的 Map 就够了。如果被多个服务消费(Config、Permission、Project、Vcs 都读 InstanceContext),才需要 InstanceStore。
这个判断标准在你自己的架构设计中也适用。微服务的"请求上下文"(request-scoped context)只在网关和 handler 之间传递时,一个 Map<string, Context> 就够了——不需要中心化的生命周期管理器。但如果你有多个中间件、多个数据源、多个下游服务都需要同一份上下文,那就值得建一个中心化的 ContextStore。否则你会在 N 个模块里重复实现"创建上下文"和"销毁上下文"的逻辑——而上下文销毁时的资源释放是最容易被遗忘的。
结语
InstanceStore + InstanceContext 的组合是 opencode 工作单元管理的核心。700 行代码做了三件事:从目录自动发现项目、用 InstanceContext 绑定三粒度数据、用 Deferred 控制并发生命周期的 load/dispose。从实例启动到文件访问边界判定,整个 Agent 运行时都依赖这三个字段。
如果你觉得这种源码拆解对你有帮助,可以转发给团队——上下文生命周期管理在微服务架构和基础设施抽象时直接可复用。
下篇拆错误处理体系——从 error.ts 到用户提示的完整链路,看 opencode 的 Effect 错误模型如何贯穿整个系统的异常处理。
📺 公众号「Ai拆代码的曹操」 🌟 知识星球「Ai拆代码的曹操」


