
ConcurrentHashMap 面试八股 vs 生产环境踩坑实录
叙事框架:
面试题 → 标准答案验证 → 三个翻车现场 → 边界分析 → 升级版答案
上篇讲了线程池参数面试和生产场景的落差,这篇我们来看另一道高频面试题——ConcurrentHashMap。线程安全?标准答案背得滚瓜烂熟,但组合操作照样翻车。
面试题:ConcurrentHashMap 为什么线程安全?
Q:ConcurrentHashMap 和 HashMap 有什么区别?为什么 ConcurrentHashMap 线程安全?
这道题几乎每次 Java 面试都会出现,标准答案也高度统一:
JDK 7:分段锁(Segment 数组继承 ReentrantLock),默认 16 个 Segment,锁粒度粗 JDK 8+:CAS + synchronized 锁单个 bin(链表/红黑树头节点),锁粒度降到数组元素级
面试官听到 JDK 7 vs JDK 8 的差异,一般就满意了。这道题从《Java 并发编程实战》到各大公司的面试题库,答案几乎一字不差。
标准答案的隐含假设
但如果你把标准答案拆开看,它隐含了三个假设:
- 你只用单操作——只 put 一个 key、只 get 一个 key、只 remove 一个 key
- 你来决定 JDK 版本——JDK 8+ 默认,JDK 7 是历史
- 你只关心容器本身——不关心调用方怎么编排这些操作
三个假设在面试中都被认为是"理所当然"的。直到生产环境把它们一个个击穿。
生产事故:线程安全容器也翻车
事故一:"卖了 5 件,只扣了 3 件"
陈姐维护的库存服务,核心逻辑只有两行:
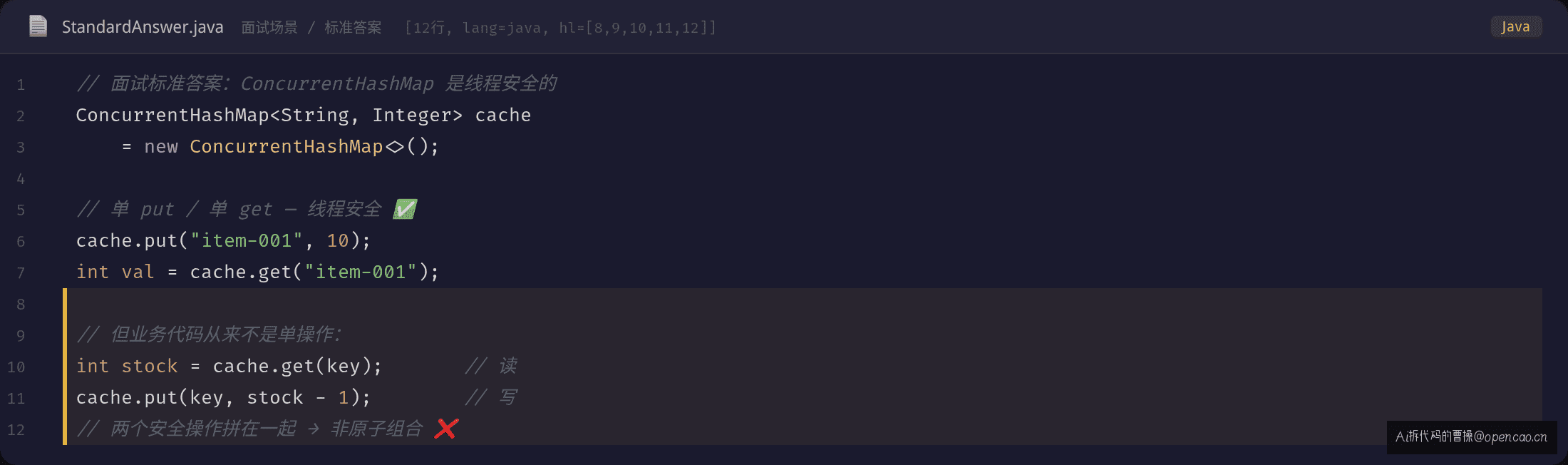
int stock = cache.get(key);
cache.put(key, stock - 1);
100 个线程同时扣库存。上线第一周正常——并发量低。第二周大促流量进来,库存对不上了:账面显示还有 3 件,实际卖了 5 件。
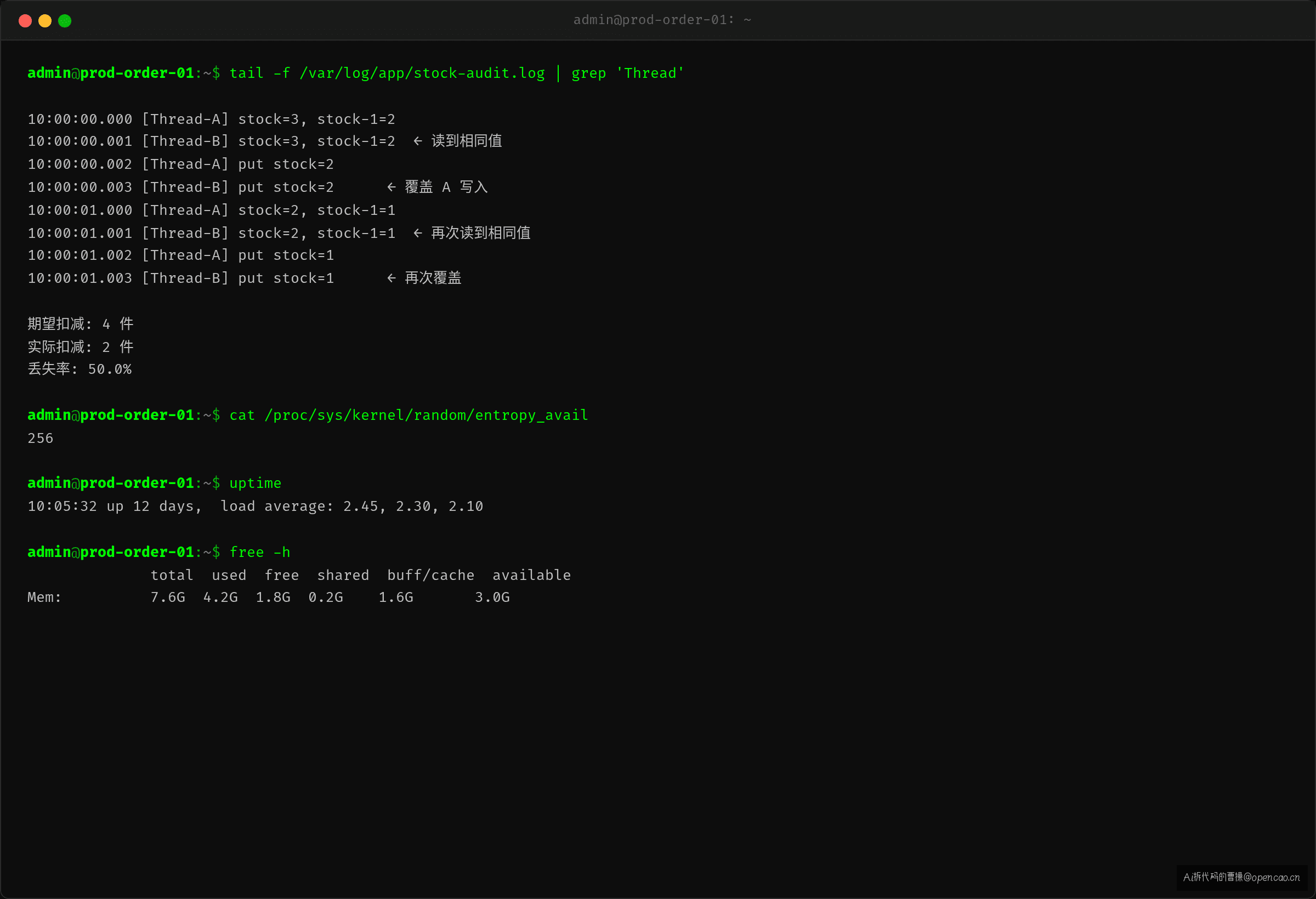
这不是 ConcurrentHashMap 线程不安全——是 get 和 put 各自线程安全,但它们之间没有原子性。两个线程同时读到 stock = 3,各自减 1 写回 2——卖了两件,只扣了一件。两个 get() 之间没有 happens-before 关系,所以读到了相同值。
面试的标准答案是对的:"put 和 get 是线程安全的。"——但你的业务代码不是 map.put(key, value),你的代码是 map.put(key, map.get(key) - 1)。
事故二:CPU 100%,所有线程卡在 get() 上
如果事故一还算温和(数据错但服务还在跑),事故二是直接宕机。
某网关服务,JDK 7,上线一个月没出过问题。某天 CPU 突然 100%,jstack 显示所有线程全部停在 ConcurrentHashMap.get() 上。
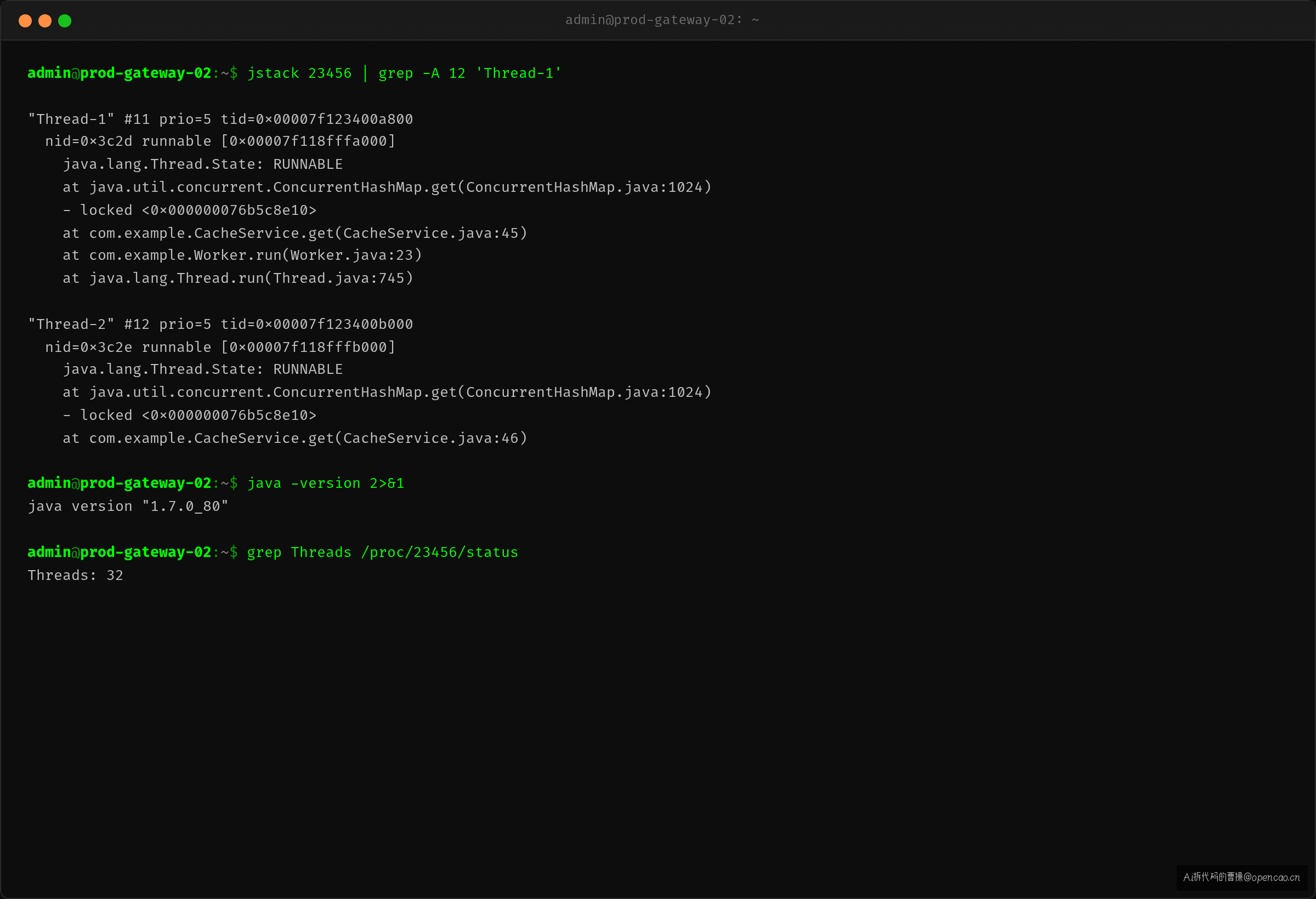
排查发现:服务需要定期刷新缓存,大量并发 put 触发了 ConcurrentHashMap 的 resize。JDK 7 的 resize 使用头插法迁移——多线程同时 resize,链表形成环,get() 遍历这个环永远停不下来。
JDK 8+ 换用了 ForwardingNode 做无锁迁移,不存在此问题。但问题在于:你的依赖 jar 可能还在用 JDK 7 编译的版本。Gateway 本身是 JDK 8,但引入的某个中间件客户端依赖了 JDK 7 版本的 ConcurrentHashMap 用法。
面试的标准答案也没错——JDK 8+ 确实没有这个问题。但它没告诉你:你的依赖可能悄悄拖着一个 JDK 7。
事故三:批量写入后 size 对不上
第三个事故最隐蔽——数据没丢、服务没挂,但报表对不上。
批处理任务批量写入 20 万条数据,写入完成后读 size():
cache.putAll(batch);
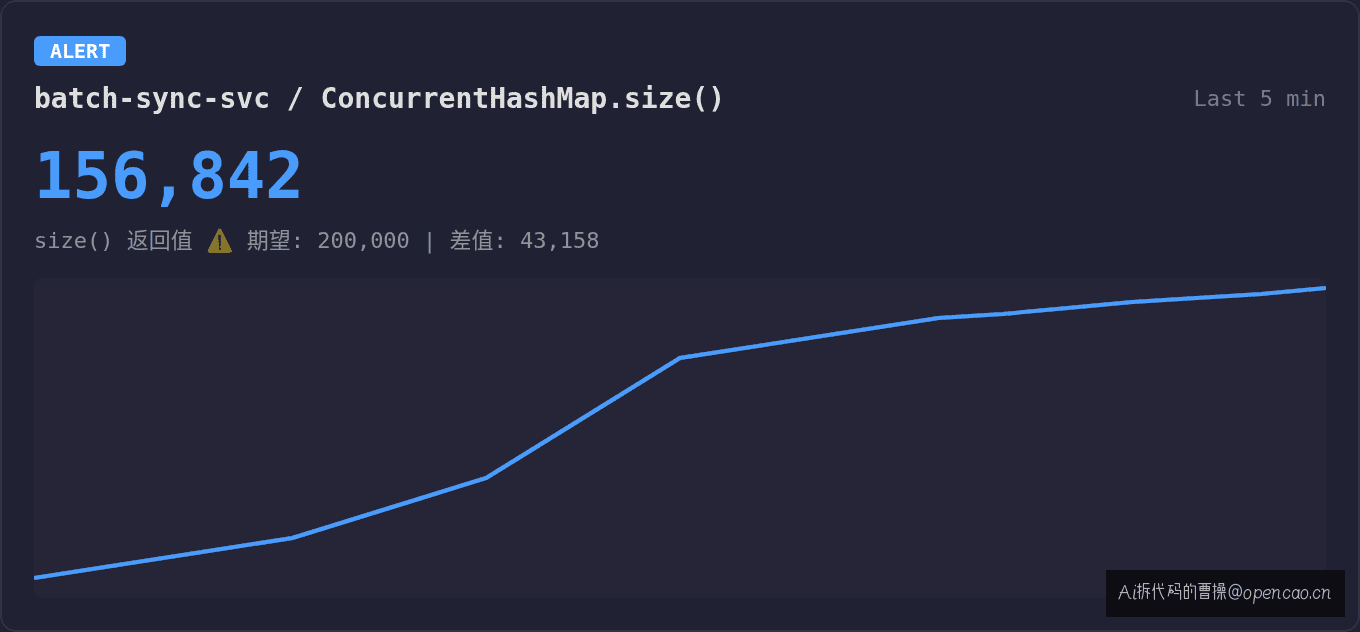
log.info("写入完成,总数:{}", cache.size()); // 输出:156,842
期望 200,000,实际 156,842。差了 43,158 条。
不是 bug——size() 在 JDK 8 中使用 CounterCell[] + baseCount 做近似计数。高并发写入时,size() 返回的是"能快速拿到的最新近似值",不是"精确的事务计数"。但业务方把它当精确值用了,下游系统按这个数做结算,差了 4 万多。
面试的标准答案继续成立——"ConcurrentHashMap 线程安全"。但"线程安全"不意味着 size() 是实时精确的。
为什么标准答案不够?
标准答案对在哪
- ✅ 单操作原子性:
put(k, v)、get(k)、remove(k)各自是线程安全的——面试说的这个,完全正确 - ✅ 弱一致性迭代:迭代器不抛
ConcurrentModificationException——对,面试说的也正确 - ✅ JDK 8 的演进方向对:从 Segment 到 CAS + synchronized,粒度更细、并发度更高——正确
标准答案漏了哪
| 漏了什么 | 面试场景 | 生产场景 |
|---|---|---|
| 组合操作 | 只问单操作是否安全 | 业务代码全是组合:get+put、containsKey+put、putAll |
| 版本差异 | 默认 JDK 8 | 依赖 jar 可能用 JDK 7 编译,间接拖入旧版本 |
| size() 语义 | "size 返回元素数量" | 近似计数,高并发下不准 |
| 修复手段 | 不讨论 | compute / putIfAbsent / mappingCount / 外部锁 |
ConcurrentHashMap 安全性的三层边界
安全级别 1:单操作原子性 ✅ ← 面试只问到这
put(k, v) / get(k) / remove(k) 各自线程安全
安全级别 2:弱一致性迭代 ✅ ← 面试偶尔问到
迭代器不抛 ConcurrentModificationException
但不保证看到全部最新写入
安全级别 3:组合操作原子性 ❌ ← 生产踩坑全在这
get + put、containsKey + put、putAll、size()
需要外部同步或使用 compute() / merge()
面试升级版答案
第一层:基础答案(及格线)
ConcurrentHashMap 用 CAS + synchronized 保证线程安全。JDK 7 用分段锁,JDK 8+ 锁粒度降到 bin 级别。
大多数候选人到此为止。能答出 JDK 版本差异的,算合格。
第二层:推导+边界(拉开差距)
"但'线程安全'只保证单操作的原子性。组合操作(get+put、containsKey+put)没有跨操作保证。一个线程 put 完另一个线程 get 能读到——但一个线程 get 然后 put,这两个操作之间的窗口另一个线程也能进来。
真正的安全边界面试不会考:三层——单操作 ✅、弱一致性迭代 ✅、组合操作 ❌。"
这一步把"背结论"变成了"讲边界"。面试官会意识到你不只是刷了八股。
第三层:生产案例(面试加分项)
结合真实案例讲:
"我之前维护过一个库存服务,用 ConcurrentHashMap 做缓存,也是标准的 get + put 扣库存——上线前压测正常,大促流量进来库存对不上。排查发现是 read-modify-write 丢失更新。
修复方案:把裸 put 改成 compute() 或 merge(),保证 read 和 write 的原子性。同时补充了 JDK 版本检查——某个依赖 jar 的 ConcurrentHashMap 用法从 JDK 7 编译过来的,修改了依赖版本才解决。"
同步展示三个事故的修复方案对比:

第四层:监控验证(真正的高阶)
面试官可能追问:"修复完你就放心了?"
"不放心。加了三道防线: 1. 代码审查:grep 检查
ConcurrentHashMap.*\.get(.*put模式——所有 RMW 都要改成 compute 2. JDK 版本审计:mvn dependency:tree检查所有传递依赖的 JDK 版本 3. 数据校验:重要业务加对账——ConcurrentHashMap 的 size 不用来做业务判断,用 mappingCount 做参考"
生产中这么用
安全操作速查
| 场景 | ❌ 面试八股写法 | ✅ 生产正确用法 |
|---|---|---|
| 原子增减 | map.put(k, map.get(k) + 1) |
map.compute(k, (k,v) -> v==null ? 1 : v+1) |
| 不存在时写入 | if (!map.containsKey(k)) map.put(k, v) |
map.putIfAbsent(k, v) |
| 批量写入后计数 | map.putAll(batch); map.size() |
map.putAll(batch); long n = map.mappingCount() |
| 遍历时删除 | for (Entry e: map.entrySet()) map.remove(...) |
map.forEach(2, (k,v) -> { map.remove(k); }) |
⚠ compute 内抛异常会删除该 key——短操作用 compute,长业务用外部锁。
grep 检查你的项目
# 检查 read-modify-write 模式(最常翻车)
grep -rn "ConcurrentHashMap.*\.get(" src/ | grep -E "put|remove"
# 检查裸 check-then-act
grep -rn "containsKey.*ConcurrentHashMap" src/
# 检查传递依赖的 JDK 版本
mvn dependency:tree | grep "concurrent"
# 检查 size() 做业务判断
grep -rn "ConcurrentHashMap.*\.size()" src/ | grep -v "log\|print"
"面试题的标准答案只是地图——只有到生产里走一次,才知道地图漏了哪条路。"
下篇我们聊强/软/弱/虚引用——面试全能背,生产 OOM 还是不会查。


