
第三章总结:三源合流——opencode 为何选扁平不选分层
上篇我们跟了错误从 throw 到用户提示的完整路径,这篇跳出单篇视角看第三章的全景。
如果你要设计一个 AI Agent 的命令系统——斜杠 /review、MCP 工具 prompt、skill 文件定义的模板——它们来自不同源头,放到同一个注册中心里如何不打架?更棘手的是,每个命令执行时可能涉及 Git 操作、Project 持久化、配置读取、错误处理——这些模块之间是什么关系?
第三章拆了五个模块(斜杠命令、config 命令、Git 集成、project/workspace 管理、错误处理),但它们不是五个独立的功能,而是一条"从注册到执行"的链上的五个环节:三源合流 → 统一模型 → 状态共享 → 失败兜底。
本文不重复五篇正文的技术细节——它们已经在 03-01 到 03-05 里了。本文做三件事:揭示这条链的因果传导、提炼跨模块的设计权衡、定位第三章在整个 opencode 中的角色。
因果链:三源合流 → 统一模型 → 状态共享 → 失败兜底
起点:命令从三个世界汇聚
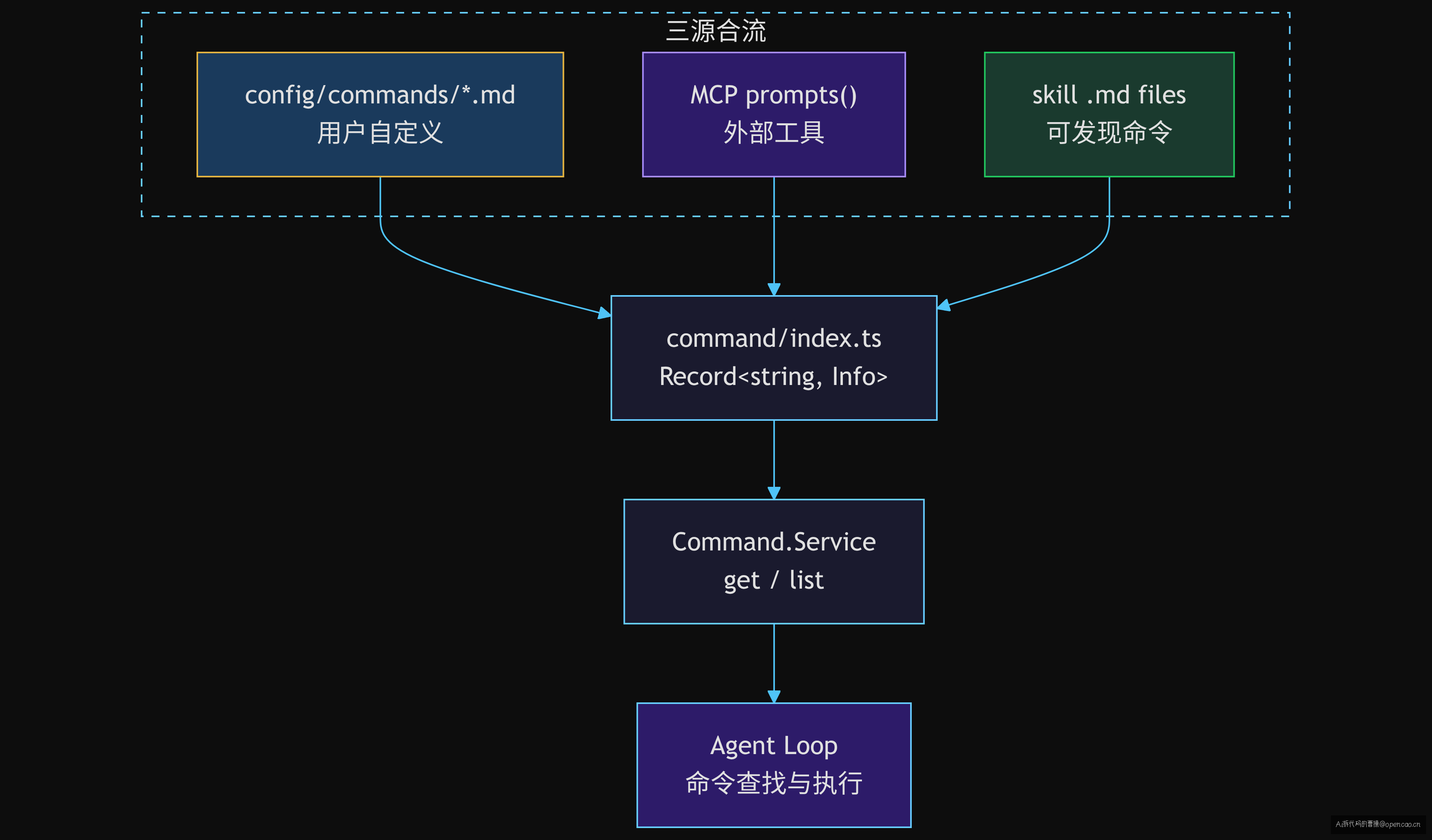
如果只从 yargs 命令行理解 opencode 的"命令",你会漏掉一大半。opencode 运行时的命令系统有三个来源:
第一来源:config 文件。 用户在 opencode.json 的 command 字段或 commands/ 目录的 Markdown 文件中定义自定义命令。这是"用户写给自己用"的命令——就像 .gitconfig 里的 alias。
第二来源:MCP 服务器。 MCP 协议暴露 prompts 端点,每个 prompt 自动注册为一个命令。这些命令来自外部工具——语法检查器、代码生成器、文档搜索器。
第三来源:skill 文件。 .opencode/ 目录下的 skill 文件内容也被注册为命令。这是"运行时可发现"的命令——无注册步骤,丢个文件就生效。
这三个来源在 packages/opencode/src/command/index.ts:76-153 的初始化函数中被逐一扫描并合并到一个 Record<string, Info> 中:
// command/index.ts:78-153 (骨架,保留关键跳过逻辑)
const commands: Record<string, Info> = {}
commands[Default.INIT] = { /* 内置 init 命令 */ }
commands[Default.REVIEW] = { /* 内置 review 命令 */ }
for (const [name, command] of Object.entries(cfg.command ?? {})) {
commands[name] = { /* config 中的自定义命令 */ }
}
for (const [name, prompt] of Object.entries(yield* mcp.prompts())) {
commands[name] = { /* MCP prompt 可覆盖 config */ }
}
for (const item of yield* skill.all()) {
if (commands[item.name]) continue // skill 跳过已存在的命令,仅补缺
commands[item.name] = { /* skill 文件转命令 */ }
}
注意合并逻辑不是"后面的覆盖前面的"这么简单。MCP 确实会覆盖 config 的同名命令(无冲突检查),但 skill 会跳过已存在的命令(if (commands[item.name]) continue)。所以实际优先级是:MCP > config > built-in,skill 仅补缺——这不是实现上的疏忽,而是设计意图:skill 文件是运行时发现的可执行 prompt,不是自定义命令的覆盖机制。
这也意味着三源合流有一个代价:MCP 和 config 之间同名冲突时静默覆盖。opencode 没有抛出"命令名冲突"异常,而是让后注册的 MCP prompt 覆盖前面 config 的自定义命令。这个 trade-off 的合理性在于:LLM 查找命令时用的是模糊匹配(Agent 根据用户意图推测命令名),不需要 namespace 隔离带来的精确性。
传导:统一模型驱动下游模块
Command.Info 的数据结构(command/index.ts:30-40)只有 8 个字段:
const Info = Schema.Struct({
name: Schema.String,
description: Schema.optional(Schema.String),
agent: Schema.optional(Schema.String),
model: Schema.optional(Schema.String),
source: Schema.optional(Schema.Literals(["command", "mcp", "skill"])),
template: Schema.Unknown, // 提示词模板
subtask: Schema.optional(Schema.Boolean),
hints: Schema.Array(Schema.String), // 占位符列表
})
这个精简的模型是整个第三章的"数据契约"——它足够简单,三个来源都能填充;它又足够完整,Agent Loop 仅凭这 8 个字段就能决定如何执行命令。8 个字段里唯一的元数据 source 目前只写不读——这是为未来审计留的锚点,零成本的预留。
这个统一模型传导到三个下游模块:
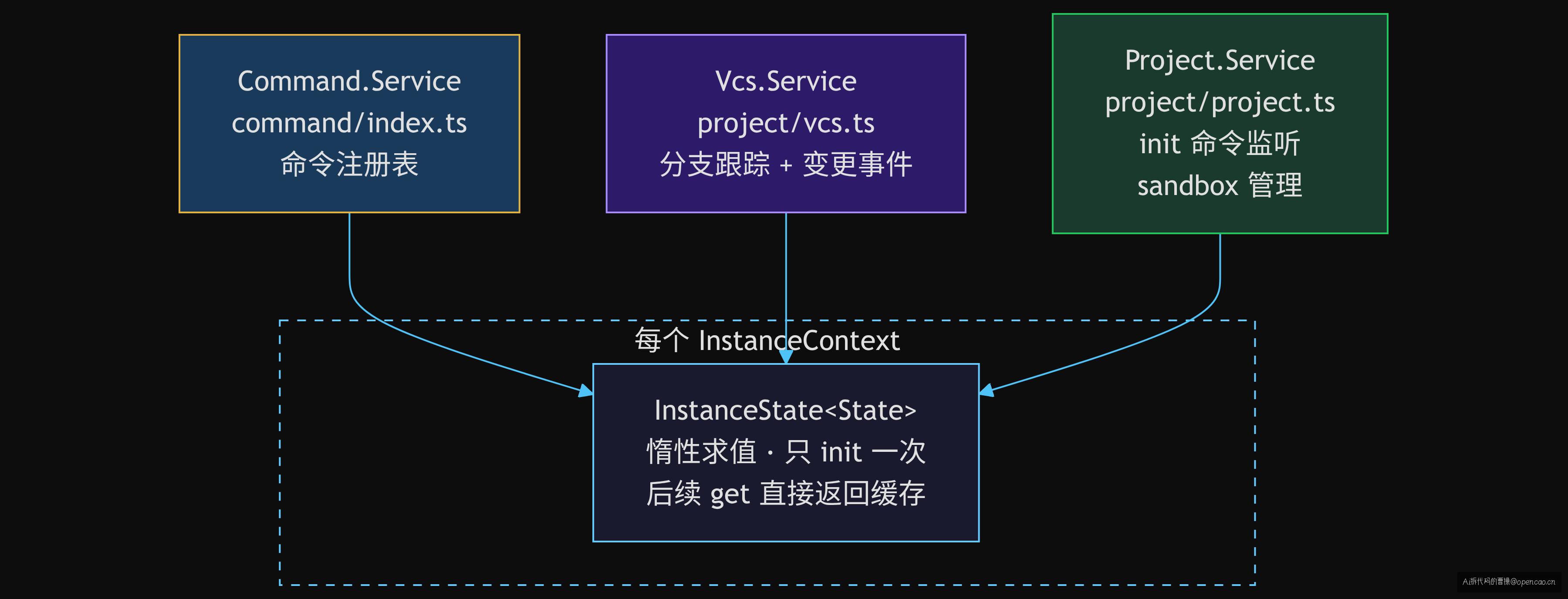
Project 订阅命令事件。 packages/opencode/src/project/project.ts:415-425 中,Project Service 监听了 Command.Event.Executed,当 init 命令执行时触发 setInitialized:
// project.ts:417-421
const unsubscribe = yield* events.listen((event) => {
if (event.type !== Command.Event.Executed.type) return Effect.void
const data = event.data
return data.name === Command.Default.INIT
? setInitialized(ctx.project.id) : Effect.void
})
VCS 共享 InstanceState 模式。 packages/opencode/src/project/vcs.ts:311-341 中,Vcs Service 用 InstanceState.make 在 InstanceContext 上初始化分支跟踪,并订阅文件系统的 HEAD 变更事件——当分支切换时自动更新、主动推送 Event.BranchUpdated。
Git Service 提供原子化操作。 packages/opencode/src/git/index.ts:110-132 的 Git.run 函数是所有 Git 操作的核心,它封装了 12 个 git config 参数(--no-optional-locks、core.longpaths=true 等),并统一处理进程调用的错误。每个 Git 方法(status、diff、patch、apply)都是一行 yield* run([...args]),15 个方法共享同一个进程创建模板。
汇聚:InstanceState 作为共享契约
第三章五个模块中,Command、Vcs、Project 三个都使用了 InstanceState。这不是巧合——它是本章的"隐形主线"。
InstanceState.make<T>(init) 接受一个初始化函数,返回一个 Effect 状态槽。初始化函数只在 每个 InstanceContext 首次被访问时执行一次(惰性求值)。后续调用 InstanceState.get(state) 直接返回缓存值。
这意味着:不论命令执行多少次,Command Service 的 3 个来源扫描只做一次。不论 git branch 调用多少次,Git 的 symbolic-ref 只在分支切换时才重新执行(通过 watcher 事件驱动)。
兜底:错误处理的分发网络
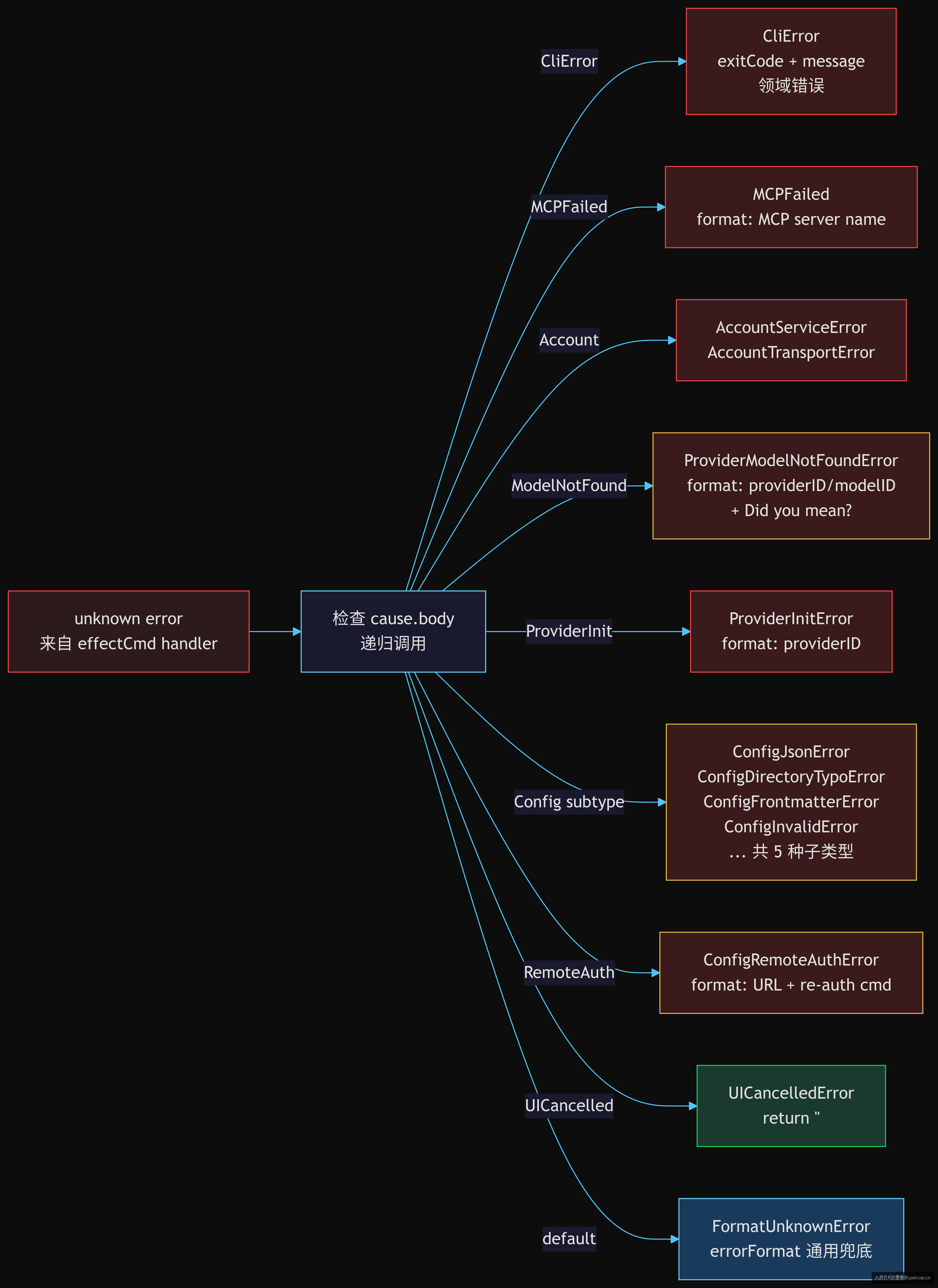
packages/opencode/src/cli/error.ts 的 FormatError 函数处理 12+ 种错误类型——从 CliError(领域错误)到 UICancelledError(用户取消),每种都有独立的格式化逻辑。
关键在于它的分发模式:先用 input instanceof Error 检查嵌套 cause,再用 isTaggedError 或 configData 匹配具体类型,每种匹配输出一段定制化的用户提示。
这不是 try { ... } catch { generic message } 那种一次性兜底。每一类错误都有独立的用户语言。比如模型找不到时的提示比配置无效时的提示多了 opencode models 命令建议和 Did you mean: 模糊匹配——因为模型选择是高频操作,用户需要快速修正路径。
这种分发的代价是 FormatError 有 130 行和 12+ 个分支。但收益是:用户看到"模型未找到"时立刻知道下一步做什么,而不是面对抽象的 Error: 500。
两条跨模块的设计权衡
权衡一:InstanceState 共享 vs 每次独立创建
第三章的三个服务(Command、Vcs、Project)都选择了 InstanceState.make 共享状态。替代方案是每次操作无状态执行——每次 Command.list() 都扫描配置文件、MCP prompts、skill 文件。
共享方案的风险是:InstanceState 缓存了初始化结果,如果 config 文件在运行中被修改,Command.list() 不会反映变更。opencode 的选择是"运行时配置不变"的假设——你修改了 opencode.json,需要重启会话。这不优雅,但简单可靠。
无状态方案的风险正相反:每次操作都要扫描磁盘、调用 MCP 的 prompts() 方法、读取 skill 文件。——对于 Command.list()(Agent Loop 中高频调用)来说,性能不可接受。
这条权衡的精确表述是:用运行时不变性假设,换来高频操作 O(1) 的查找延迟。这不是谁对谁错,而是 opencode 选择了"AI 会话中配置不变"这个场景假设。
权衡二:Git 进程封装 vs 裸 ChildProcess 调用
Git.Service 的 350 行代码里真正跑 Git 命令的核心逻辑只有 Git.run 函数。其余全是:类型定义(15+ 个接口类型)、工具函数(kind/parseQuotedPath/fileFromDiffPath)、封装方法(15 个 Git 子命令的 Effect 包装)。
如果跳过这层封装,每条 Git 操作直接 ChildProcess.spawn("git", [...]),代码量可以减半。但代价是:
- 无法统一设置 12 个 git config 参数(每个调用者都要手动加)
- 错误处理分散在 15 个地方
- 无法注入 mock 进行测试
opencode 选了封装,而且封装得很彻底——Git.run 用 Effect.catch 兜底,所有 Git 错误统一为 { exitCode: 1, text: "" } 的 Result 对象。这意味着 Git 命令永不抛异常,调用者永远拿得到一个"安全的结果"。
第三章的全局定位
核心产出:不是命令,是 InstanceState 共享模式
如果把第三章的五个模块串起来看,它们共同定义了一个概念:"命令"不仅是 Agent 和用户的交互单位,更是组织周边服务的编排单位。
每执行一条命令,Agent Loop 内部发生了这些事:
1. Agent 从 Command.get(name) 拿到命令的 Info(包含 template、hints、subtask 标记)
2. 如果需要 Git diff,Agent 调用 Vcs.diff("git") 获取变更
3. 如果需要写回项目元数据,Project Service 处理持久化
4. 如果整个过程出错,FormatError 产出用户可读的提示
这一章的架构在没有标题的意义上给自己起了个名字——"命令服务架构":一个注册中心 + 一组上下文敏感的服务 + 统一的失败处理。
如果一定要用一句话概括第三章做了什么,那就是:把三种分散的定义(config + MCP + skill)塞进同一个 Record<string, Info>,然后用 InstanceState 让它们和其他模块不打架。
与前后章节的关系
| 章节 | 关系 | 具体连接点 |
|---|---|---|
| 第二章 CLI 入口 | 上游:产出 InstanceContext | 第三章所有模块消费 Chapter 02 初始化的 InstanceContext |
| 第四章 Agent 调度 | 下游:消费命令 | Agent Loop 调用 Command.get() 获取命令定义并执行 |
| 第六章 Tool 系统 | 平行:工具 vs 命令 | Tool 中的 bash/git 操作底层调用 Git.Service |
| 第零章 设计哲学 | 呼应:Effect-ts 设计落地 | InstanceState 是 Effect-ts Scope 模式的具体实例化 |
没有第二章的 InstanceContext,Command Service 不知道当前目录,Vcs 不知道 git 仓库位置,Project 不知道工作单元。没有第三章的命令服务,第四章的 Agent 没有"预置技能"/"自定义命令"的概念——每轮对话都从零开始拼 prompt。
读完第三章应该记住的两个心智模型
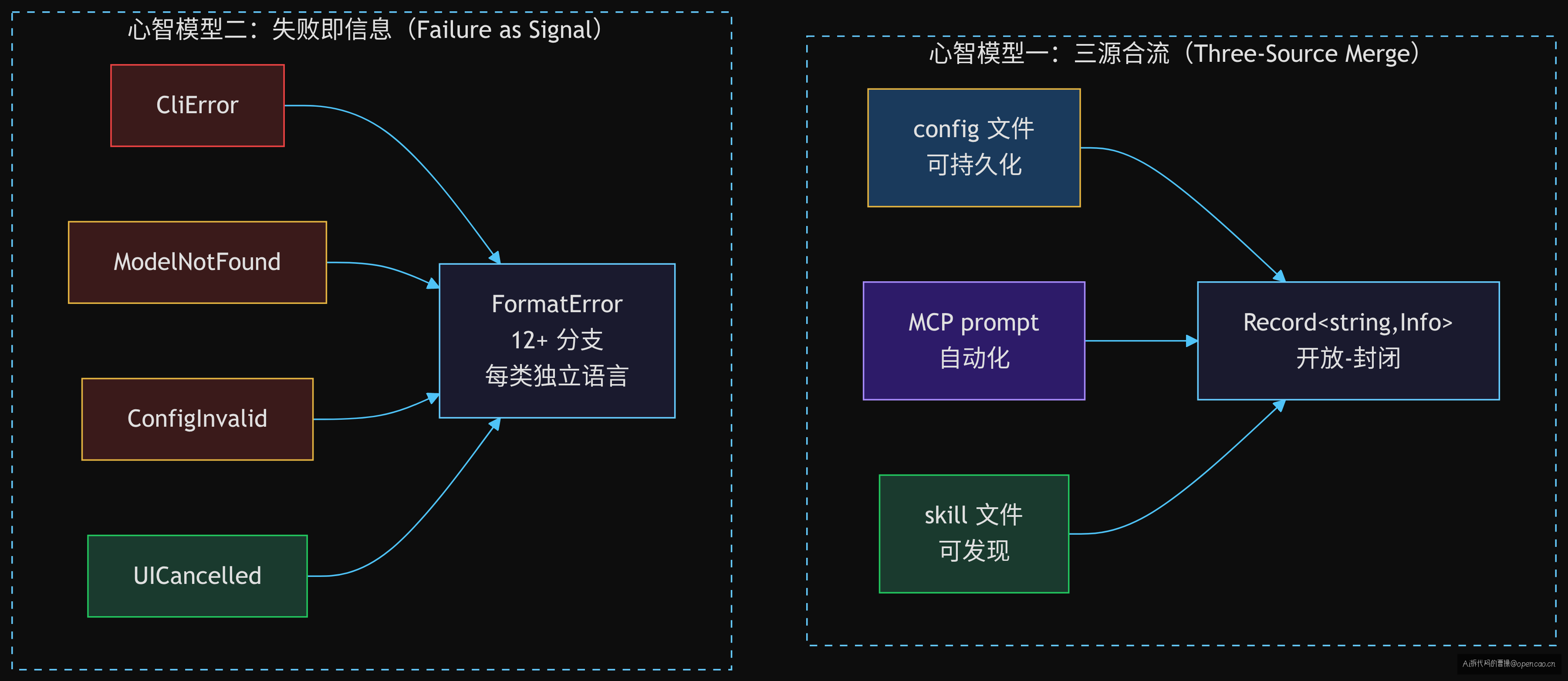
心智模型一:三源合流(Three-Source Merge)
同一个接口从三个不同来源收集数据,互不影响。新增来源不修改现有代码——config 命令的添加不涉及 MCP 的任何代码,skill 命令的添加不涉及 config 的任何代码。这是"开放-封闭原则"(OCP)在现实中的一次干净实践。
心智模型二:失败即信息(Failure as Signal)
FormatError 不是 try-catch 包一切,而是每种错误独立格式化。代价是代码量大(130 行 12+ 分支),但收益是每类错误都有针对性的用户语言。下次你做 AI 产品时问自己:用户的错误提示能告诉他下一步做什么吗? 这个思路不限于 AI——设计 API 网关错误响应、CLI 工具的 --help 输出、甚至表单校验文案时都可以用:不抛通用异常,给针对性指引。
三源合流的代价只有一条:MCP 可覆盖 config 的同名命令,且静默无声。opencode 选了它,因为 LLM 的模糊匹配不需要 namespace 隔离级别的精确性。
下篇我们进入第四章 Agent 系统——看命令如何从注册中心走到真正的执行环。
🔗 个人博客:https://opencao.cn 📺 公众号「Ai拆代码的曹操」 🌟 知识星球「Ai拆代码的曹操」
如果这篇帮你理清了第三章模块间的关系,点赞转发让更多人看到 👉 下篇第四章 Agent 调度见


