
ReAct 不是循环——是 LLM 的调试器
场景:LLM 能回答问题但无法完成多步任务——ReAct 给 LLM 装上了"思考→行动→验证"的试错循环 路径:一个答不出的问题 → 最简实现 → 每轮 Token 账单 → 决策框架 → 一句话锚点
上篇我们提到 ReAct 是 Agent 最核心的执行模式——看一眼三元组图就懂了。但一张图能告诉你的事太少了;它不告诉你每轮消耗多少 Token、不告诉你什么情况下会死循环、不告诉你生产实现和教程实现差了多远。
这篇我们把工具箱掀开:12 行核心代码背后的隐藏成本、逐轮的 Token 增长曲线、以及一个决策框架——什么场景该用 ReAct,什么场景不该。
如果你上篇理解了"ReAct 是 Thought→Action→Observation",这篇帮你理解"ReAct 内部到底怎么运转,以及什么时候该用它"。
一个 LLM 答不出的问题
ReAct 不是 2025 年的新算法——它是人类解决问题最自然的方式:想一下,试一下,看看结果再想。
如果你观察过自己怎么解决一个复杂问题,你已经理解了 ReAct 的核心。区别只在于:你把"想"和"试"放在大脑里,ReAct 把"试"的结果显式写进下一轮的输入。
看一个具体问题:
帮我查明天上海天气,如果下雨就定一个早上 8 点的闹钟。
对普通 LLM 来说,这是一个"不可能完成"的任务——不是因为它难,而是因为它需要多步、需要外部信息、需要条件判断。传统 LLM 的调用模式是一次请求一次回答,没有"查完了再决定"的机制。
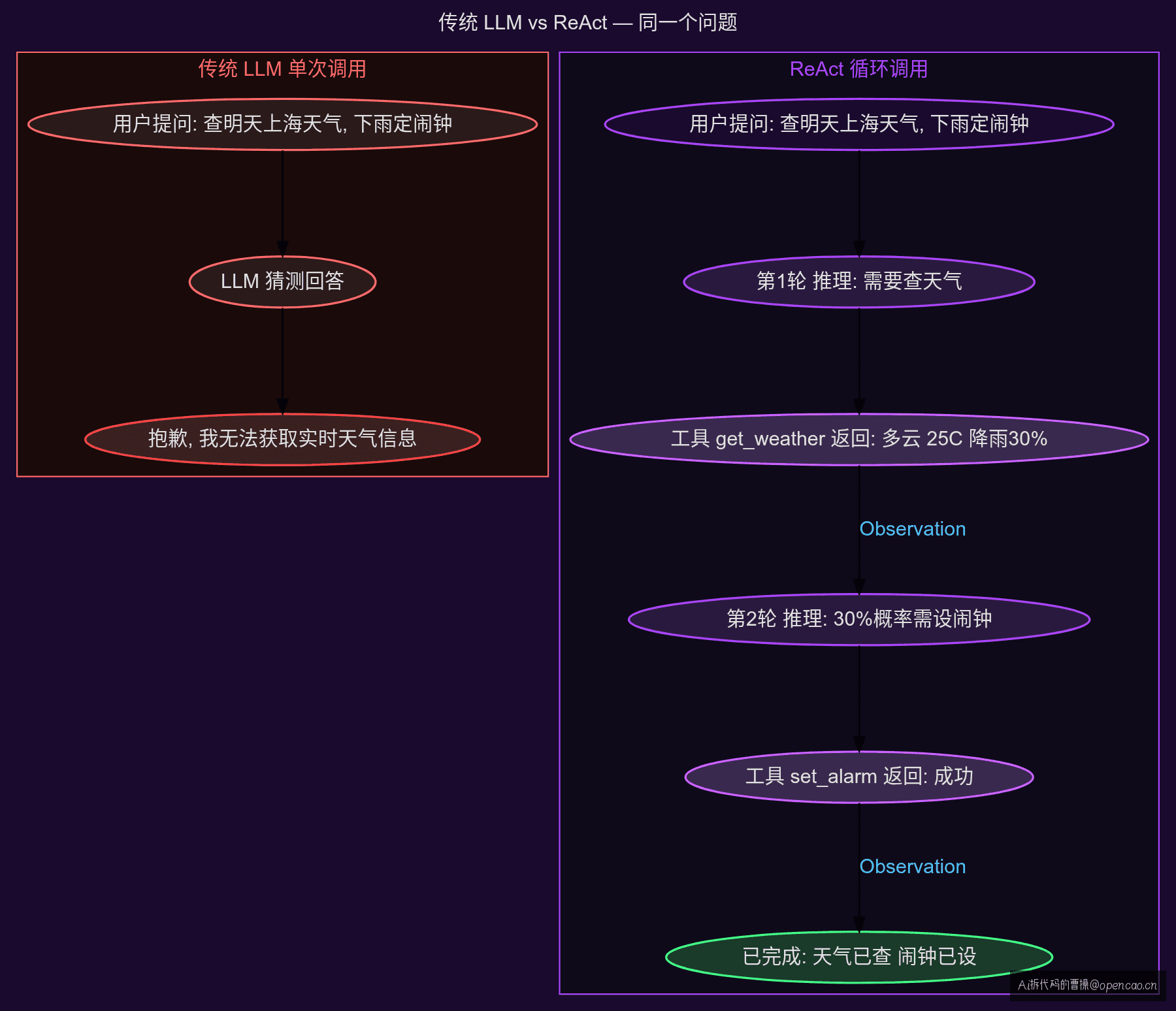
左半:传统模式——LLM 根据训练数据猜测答案。如果训练数据截止于某天、或者天气 API 不在训练集里,它只能编一个。右半:ReAct 模式——LLM 先推理"我需要查天气",然后调用工具获取真实数据,再基于真实数据做决策。
问题的本质
传统 LLM 调用是一次性的:User Input → LLM → Response。所有推理都发生在一次前向传播中。对于需要外部信息、多步推理、条件分支的任务,这种模式注定失败。
ReAct 把一次调用拆成了多次,每次只做三件事:推理当前状态、决定下一步行动、观察行动结果。每次行动的结果都成为下一次推理的上下文——这才是 ReAct 的核心机制。
ReAct 的驱动力
为什么需要 ReAct?因为 LLM 有一个根本局限:它无法验证自己的输出。
传统编程中,你写 a + b,编译器告诉你结果对不对。LLM 写一段文字,没有编译器——它自己不知道是对是错。ReAct 引入了一个"外部验证器":工具调用的结果。LLM 说"查一下天气",API 返回的数据就是验证——如果返回了温度,说明查成功了;如果返回了错误,说明参数不对。
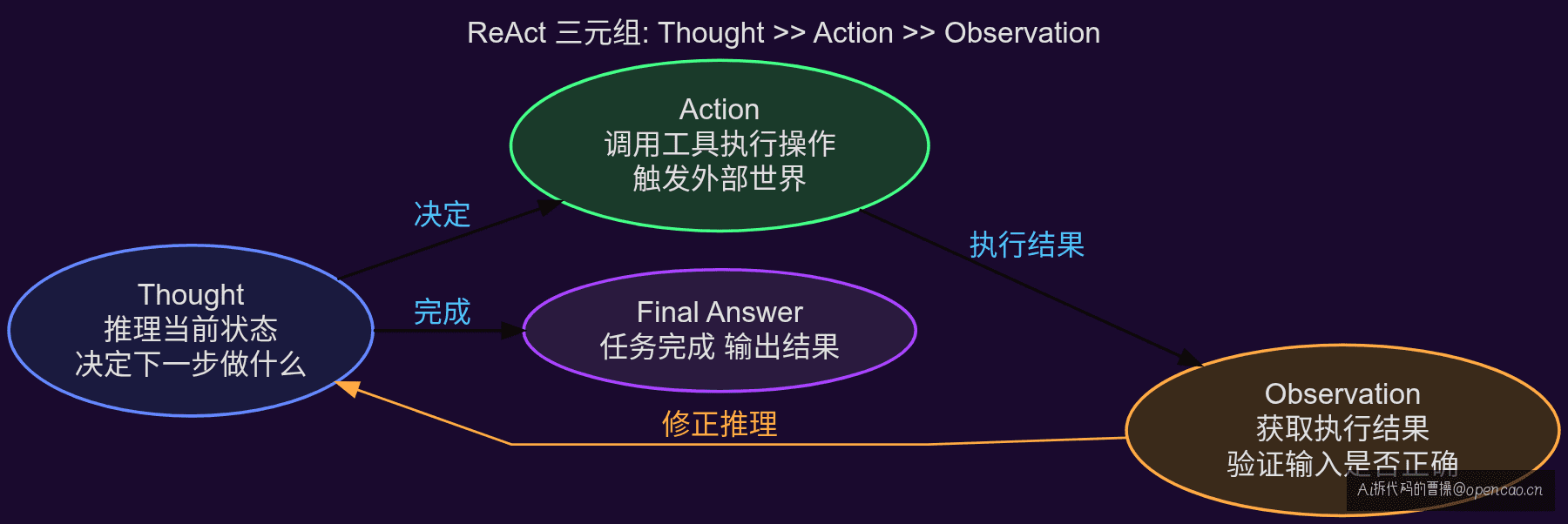
三元组:Thought → Action → Observation
ReAct 的每一轮输出包含三部分:Thought(当前状态分析)、Action(具体要执行的操作)、Observation(工具返回的结果)。下一轮的 Thought 基于上一轮的 Observation 做修正——形成闭环。
这三个词之间的关系不是串行的,是互相驱动的:Thought 决定 Action,Action 产生 Observation,Observation 修正下一轮的 Thought。上篇用一张图展示了这个循环,这篇我们用代码和逐轮拆解来看它到底怎么转。
最简 ReAct:12 行代码
抛开理论,ReAct 的核心就是一个循环:

这 12 行背后
表面上看是一个 while 循环,但有三个隐藏成本:
Token 消耗逐轮增长。 Token 是 LLM 处理文本的最小单位,类似编程语言的字符——英文一个词约 1-2 个 Token,中文一个字约 1-2 个 Token。每一轮的 Thought、Action、Observation 都追加到消息列表。第 1 轮可能 500 Token,第 5 轮可能 3000 Token(基于 GPT-4 典型对话场景估算,具体消耗取决于模型上下文窗口和工具返回数据量)。如果任务需要 10 轮,Token 消耗不是线性增长,是逐轮加速增长——因为每轮的输入包含前面全部输出。
工具执行有延迟和失败率。 tools.execute(reply.action) 这行代码隐藏了整个外部调用的复杂度。API 可能超时、可能返回错误、可能返回了数据但格式不对。ReAct 需要处理这些——最简实现没有,生产实现必须有重试和超时。
"最终答案"的判断标准不明确。 reply.type === "final" 是 LLM 自己决定的。LLM 可能过早宣布完成(幻觉),也可能永远不宣布完成(死循环)。生产系统中需要额外的判断逻辑:是否达到了目标?是否超过了预算?
教程 vs 生产:3 个差距
上面这个版本是每个 ReAct 教程都会展示的"玩具实现"。把它部署到生产环境,你至少还要加 3 样东西:
差距 1:容错。 玩具实现假设 tools.execute 永远成功。生产中每个 API 都可能超时或报错。真实的 ReAct 实现需要重试策略、超时阈值、降级方案——比如工具返回 500 错误时,LLM 应该重试还是换工具?
差距 2:Token 预算。 玩具实现假设无限上下文。生产中你必须给每轮对话设置 Token 预算上限。LLM 选了 128K 上下文窗口的模型,不等于你应该用完 128K。合理的做法:设定每轮最大 Token 数,超限就截断或归档。
差距 3:可观测性。 玩具实现无日志。生产系统必须记录每一步的 Thought、Action、Observation、Token 消耗和执行时间。否则当你发现 Agent 花了 1 万 Token 只做了两个 API 调用时,你根本不知道哪里出了问题。
传统方案的差异
对比传统的 if-else 状态机:
| 维度 | 传统状态机 | ReAct |
|---|---|---|
| 状态定义 | 开发者手动编码 | LLM 动态推理 |
| 转移逻辑 | 硬编码条件分支 | LLM 生成下一步 |
| 错误处理 | 预定义异常路径 | 观察结果后自适应 |
| 扩展成本 | 新增状态需改代码 | 新增工具即可 |
ReAct 不是"用 LLM 替代代码"——它是把决策逻辑从代码搬到模型里。传统状态机中,开发者必须预判所有可能的状态和转移。ReAct 中,LLM 根据当前上下文动态决定下一步,开发者只需要提供工具。
🔍 下次遇到 ReAct 这个概念,先理解这个核心机制——ReAct 不是循环,是 LLM 的调试器。每次行动都是断点,每次观察都是 print()。 传统编程中调试的流程是:设断点 → 运行 → 检查变量 → 调整代码 → 重新运行。ReAct 中:输出 Thought(像设断点前的推理) → 执行 Action(像运行到断点) → 拿到 Observation(像打印变量) → 修正下一步(像调整代码)。循环只是形式,调试才是本质。
逐轮拆解:当 LLM 学会"边做边看"
回到开头的例子——"查明天上海天气,如果下雨就定闹钟"。让我们逐轮跟踪 ReAct 的执行过程。
第 1 轮:LLM 根据已知知识推理
输入上下文只有用户问题。LLM 需要先理解任务,判断需要什么信息。

LLM 的输出:
- Thought: 用户想知道上海明天的天气,还需要根据是否下雨决定是否设闹钟。我需要先查天气。天气 API 需要城市名称和日期。
- Action: get_weather(city: "上海", date: "2026-07-06")
这里的关键是:LLM 没有任何"已知"的天气信息。它只是推理出"我需要先查",然后发出工具调用请求。它知道自己不知道。
第 2 轮:Observation 修正推理
工具返回了天气数据。现在 LLM 看到了真实信息,进入下一轮推理。

新的输入上下文 = 用户问题 + 第一轮的 Thought + 工具返回的天气数据。
LLM 的输出:
- Thought: 工具返回上海明天多云,25°C,降雨概率 30%。30% 不算高,但"多云"说明有降雨可能。用户说"如果下雨就定闹钟"。稳妥起见,我应该设闹钟。Set Alarm 工具需要时间和标签。闹钟定在早上 8 点。
- Action: set_alarm(time: "08:00", label: "上海明天可能有雨,起床注意")
这一轮的 Thought 和第二轮的 Observation 紧密相关。如果没有上一轮的工具返回,LLM 只能猜测天气——有了 Observation,它的推理有了事实基础。
第 3 轮:验证完成
工具返回闹钟设置成功。LLM 判断任务已完成。

LLM 的输出: - Thought: 天气已查,闹钟已设。所有子任务都完成了。给出最终回复。 - Final: "上海明天(7月6日)多云,25°C,降雨概率 30%。已帮你设置早上 8 点的闹钟,以防下雨影响出行。"
Token 账单:三轮下来花了多少
每一轮都在追加上下文。来看三轮下来的累计 Token 消耗(基于 GPT-4 典型对话估算,实际会有浮动):
| 轮次 | 本轮输入 | 本轮新增 | 累计 Token |
|---|---|---|---|
| 第 1 轮 | 用户问题 | ~150 | ~150 |
| 第 2 轮 | 第1轮全部输出 + 天气数据 | ~650 | ~800 |
| 第 3 轮 | 第2轮全部输出 + 闹钟结果 | ~1200 | ~2000 |
三轮下来用掉了约 2000 Token。 其中只有最后 ~100 Token 是输出给用户的 Final Answer,前面 95% 都是中间步骤——这是 ReAct 的固有开销:用大量 Token 换取准确性。
这也是为什么 ReAct 不适合简单问答——你本来可以用 200 Token 换一个直接回答,现在用了 2000 Token。换来了准确率从 70% 提升到 95% 左右,代价是成本翻 10 倍。值不值?取决于问题的重要性。
什么时候 ReAct 会失败?
ReAct 不是银弹。三个常见失败场景:
死循环。 LLM 不断重复相同的 Thought→Action→Observation,每次 Observation 都一样,但 LLM 认为"再试一次可能不同"。解决方法:最大步数限制 + 重复检测。
过早终止。 LLM 在关键工具还没调用时就认为"任务完成"。比如只查了天气就给出"任务完成"而忘记了设闹钟。解决方法:更详细的 System Prompt + 任务完成判断标准。
工具选择错误。 LLM 选了参数不对的工具,或者理解错了工具的功能。解决方法:更好的工具描述 + 错误信息的重试机制。
选型指南:什么时候用 ReAct?
上篇提到了三种 Agent 模式:ReAct、Plan-then-Execute、Reflection。它们不是互斥的,各有适用场景。
| 模式 | 适用场景 | 不适合 | 典型成本 |
|---|---|---|---|
| ReAct | 多步推理 + 工具调用 | 简单问答(浪费 Token) | 每轮 ~500 Token |
| Plan-then-Execute | 步骤明确、依赖清晰的流水线 | 信息不确定的动态任务 | 一次规划 ~1000 Token |
| Reflection | 需要质量验证的输出场景 | 对延迟敏感的场景 | 翻倍 Token |
| 标准 LLM 调用 | 单次问答、知识查询 | 需要外部信息的任务 | 最低 |
一个简单判断:如果任务需要"查完后决定下一步",用 ReAct;如果任务"步骤已知、每步做什么早就清楚",用 Plan-then-Execute;如果任务"不确定答案质量是否够好",加上 Reflection。
ReAct 和 Plan-then-Execute 也不是二选一——成熟的 Agent 系统会把两者组合使用:先规划再执行,每步执行内嵌 ReAct 循环。
记住一句话
理解 ReAct 不需要记住论文公式。
"ReAct = 把调试思维装进 LLM——每次行动都是断点,每次观察都是 print()"
下次有人问你 ReAct 是什么,先从这句话开始。然后问一个问题:"一个 LLM 答不出的多步问题,ReAct 怎么一步步解决?"
如果答案是"先想需要什么信息,去拿,看到结果再决定下一步"——你已经理解了 ReAct。
如果你对 AI 技术实战感兴趣,想看到更多类似 ReAct 这样的原理拆解和工程落地经验:
📺 公众号「Ai拆代码的曹操」
🌟 知识星球「Ai拆代码的曹操」
下篇我们聊 Plan-then-Execute——一种和 ReAct 完全相反的思维模式。ReAct 是边想边做,Plan-then-Execute 是先想好再做。什么场景用哪个?选错了会有什么代价?


