
Plan-then-Execute:让 Agent 先规划再行动
场景:ReAct 每一步都做"推理→行动"循环,Token 消耗大、执行慢。Plan-then-Execute 把推理集中到规划阶段,一次性制定完整计划再执行。 路径:理解了"规划与执行分离",你就知道为什么有些场景 Token 可以省一半。
上篇我们把 ReAct 拆成了"推理→行动"的每步循环——每一步 LLM 都先想再干。这篇我们来看一个反直觉的进化:如果让 Agent 先一次性规划好所有步骤再执行,Token 能省多少?
Plan-then-Execute 不是 ReAct 的替代品——它是把 Agent 的"思考"从执行中分离出来的架构决策。你可以把它想象成写代码 vs 编译执行:ReAct 是 REPL(边写边跑),Plan-then-Execute 是先写完整程序再编译。两者都有用,但用错了场景等于浪费 Token。
理解这个分离,你就掌握了 Agent 架构设计中最重要的一个权衡:什么时候该让 Agent 思考,什么时候该让它干活。
【起源】Single-shot LLM 的局限
从无状态到 ReAct
上两篇文章已经覆盖了 Single-shot 和 ReAct 的细节,这里只提炼核心冲突:
| 模式 | 每步调用 LLM? | 推理次数 | Token 效率 |
|---|---|---|---|
| Single-shot | 1 次 | 1 次 | 最高,但做不了多步 |
| ReAct | 每步都调 | N 次 | 灵活,但 80% Token 花在内部独白 |
| Plan-then-Execute | 仅规划阶段调 | 1 次 | 省 ~44% |
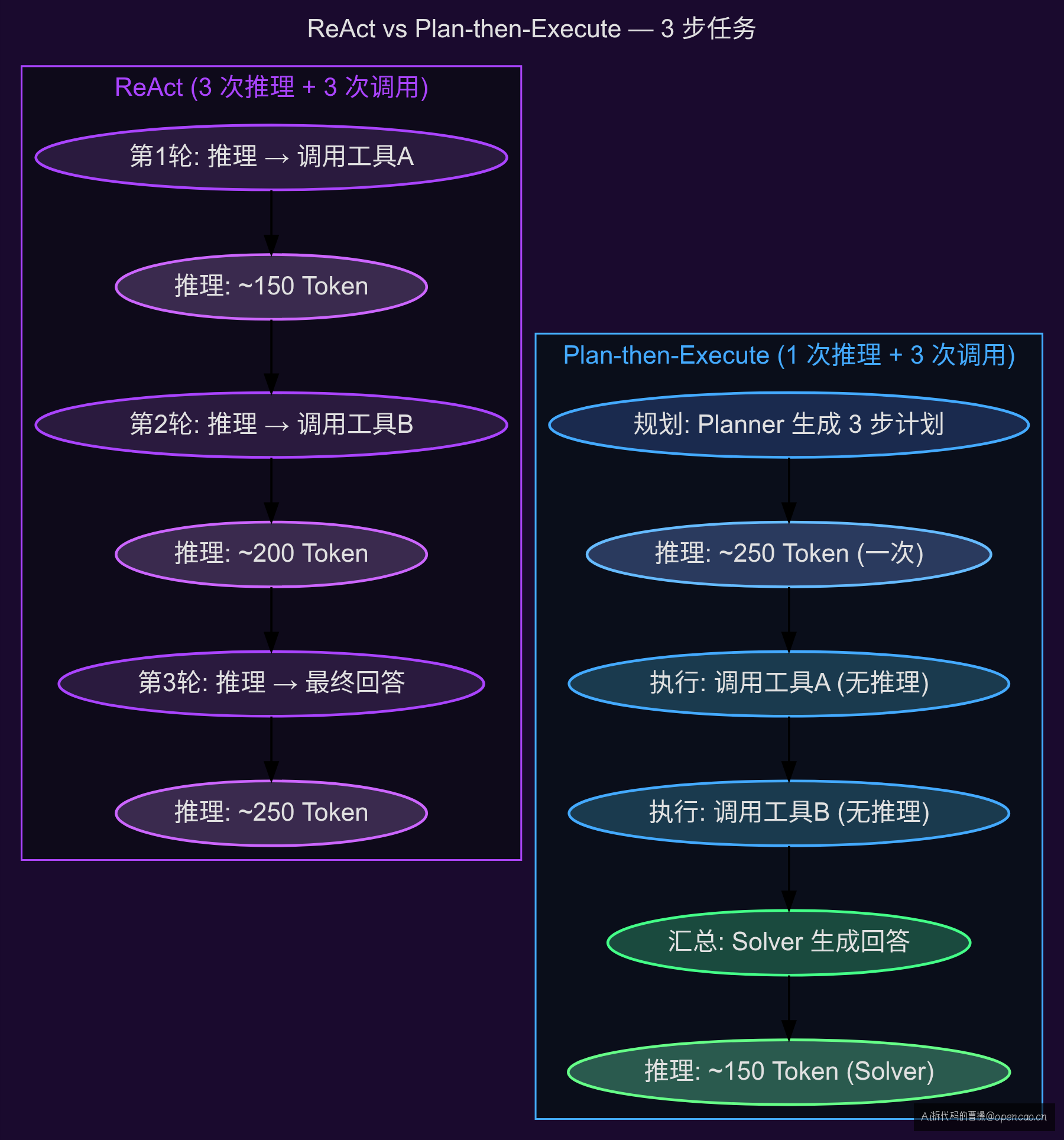
ReAct 解决了"让 LLM 自己决定下一步做什么",但代价是每步都推理——3 步 = 3 次昂贵的 LLM 调用。Plan-then-Execute 打破了这个假设。

一眼看懂的代码对比
把两段伪代码并列,核心差异一目了然:

ReAct 的推理在循环内部(每步都要 llm.think),PtE 的推理在循环外部(仅规划阶段)。"省 Token"的本质就是把推理从循环体内拉到循环体外。
【演进】从 ReAct 到 Plan-then-Execute
ReAct 的隐性成本
ReAct 解决了"让 LLM 自己决定下一步做什么"的问题,但没有解决"每步都做推理的 Token 开销"。 让我们用数据说话。一次典型的 ReAct 多步调用中,Token 消耗结构如下:
| 阶段 | LLM 调用 | 推理 Token | 工具调用 Token | 合计 |
|---|---|---|---|---|
| Thought 1 + Action | 第 1 次推理 | ~150 Token | ~30 Token | ~180 |
| Observation → Thought 2 + Action | 第 2 次推理 | ~200 Token (含上下文) | ~30 Token | ~230 |
| Observation → Thought 3 + Final | 第 3 次推理 | ~250 Token (含上下文) | ~50 Token | ~300 |
3 步任务 = 3 次推理调用,约 710 Token 的推理消耗。 其中约 80% 的 Token 消耗在"Thought"上——即 LLM 对自己说"我看到了什么、我现在要做什么"的内部独白。
这个模式的核心洞察来自 ReAct 论文(Yao et al., 2023):LLM 需要这些中间思考来维持推理的连贯性,但这些思考对最终用户来说是无价值的开销。
规划与执行的分离
Plan-then-Execute 解决了"多步任务中推理次数与步骤数成正比"的问题——把 N 次推理压缩到 1 次。 核心思想来自 ReWOO(Reasoning WithOut Observation,Xu et al., 2023):
把 Agent 的工作分成两个阶段:
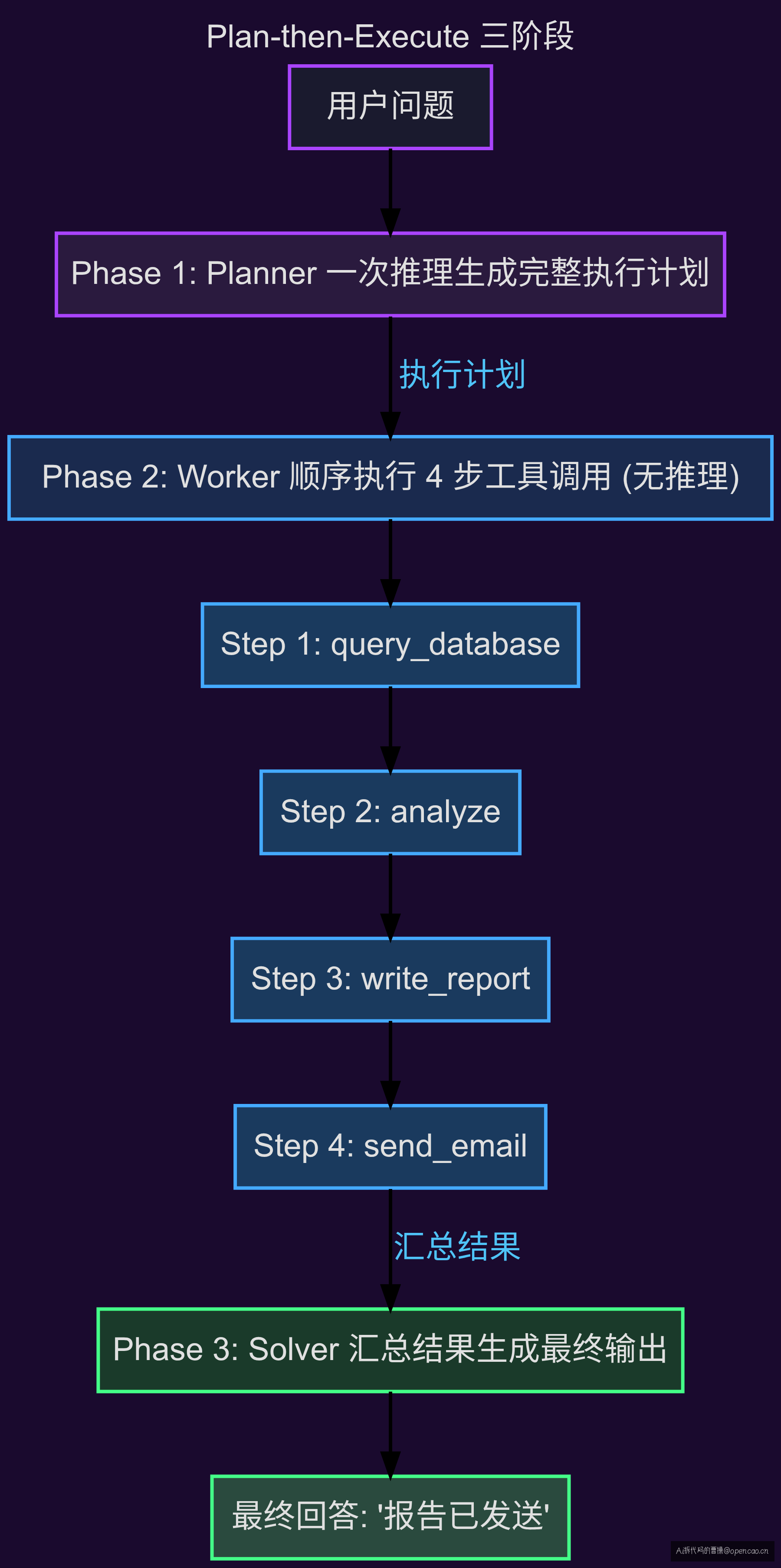
Phase 1 — 规划(Planning) LLM 一次性生成完整的执行计划,声明每一步的工具调用和参数,但不执行任何工具:
Plan:
1. tool: query_database | param: "SELECT * FROM users WHERE status='active'"
2. tool: analyze | param: "$1" (上一步的输出)
3. tool: write_report | param: "$2"
4. tool: send_email | param: "report_recipient@company.com"
Phase 2 — 执行(Execution) 按计划顺序执行工具调用,每步只做工具调用,不再触发 LLM 推理。前一步的输出自动作为后一步的输入。
这种方法的核心改变是:推理调用从 N 次减为 1 次。
| 维度 | ReAct | Plan-then-Execute |
|---|---|---|
| 推理次数 | N 次(每步一次) | 1 次(仅规划阶段) |
| Token 消耗(3 步) | ~710 | ~400(含规划输出) |
| Token 节省 | — | ~44% |
| 灵活性 | 高(可中途改变策略) | 低(规划后不修改) |
| 执行速度 | 慢(每步都调 LLM) | 快(纯工具调用) |
为什么能省 Token
用一个类比来理解:ReAct 做三步任务是"每搬一块砖都想一次怎么搬",Plan-then-Execute 是"先想好整个砌墙顺序再一次性搬完"。
规划阶段的输出虽然也消耗 Token,但它是一次性的思维产物。执行阶段没有推理开销——所有步骤都是预定的工具调用,类似编排好的函数链。
Token — 模型处理的最小单位,类似编程语言的字符。越多 Token 意味着越多推理开销和越高延迟。
【路径】🔍 "理解了规划与执行分离,你就知道为什么 Token 可以省一半"
一句话驯服 Agent 性能讨论
下次身边的人问"为什么 Agent 这么慢",你可以说:
Agent 的慢通常不是因为工具调用(毫秒级),而是因为每次工具调用前的推理(秒级)。ReAct 每一步都要推理,所以 3 步至少 3 秒。Plan-then-Execute 只在开头推理一次,所以 3 步 1 + 3×0.1 = 1.3 秒。
Token 优化的本质不是"少输出"——而是"少推理"。
最实用的 Agent 选型法则
下次跟团队争论 Agent 框架选型,先抛一个问题:
你的场景是"已知路径"还是"探索路径"?
- 已知路径(数据处理流水线、定时报表、ETL)→ Plan-then-Execute:快、省 Token、不需要中途改主意
- 探索路径(客服对话、Web 搜索、Debug 排查)→ ReAct:慢但灵活,每一步都可以根据上一步结果调整方向
这个二选一能解决 80% 的 Agent 架构争论。剩下 20% 才是框架层面的差别。
【现状】ReWOO:Plan-then-Execute 的经典实现
ReWOO 架构
ReWOO(Reasoning WithOut Observation)是 Plan-then-Execute 模式最有影响力的实现之一。它的核心架构包含三个组件:
| 组件 | 角色 | 类似传统架构中的 |
|---|---|---|
| Planner | 制定执行计划,不执行 | 项目经理(画甘特图) |
| Worker | 执行具体工具调用,不思考 | 搬砖工(按图施工) |
| Solver | 汇总执行结果,生成最终答案 | 质检员(检查交付物) |
工作流程:
- Planner 接收用户问题,输出一组工具调用计划(完全放弃 Observation 的 ReAct 循环)
- Worker 按顺序执行计划中的每个工具调用,每步只做调用,不调用 LLM
- Solver 将 Worker 各步骤的结果汇总,进行一次最终推理,生成回答
这个分离的意义在于:Planner 只做推理不做操作,Worker 只做操作不推理。 推理和执行的关注点完全解耦。
适用边界
ReWOO 不是 ReAct 的全面替代品——它有自己的适用场景限制:
适合 Plan-then-Execute 的场景: - 执行步骤可预定义(如数据处理流水线、定时报表、ETL 管道) - 每步输入输出类型固定(查询→处理→生成→发送) - 不需要在执行过程中看中间结果改变策略
不适合 Plan-then-Execute 的场景: - 需要在执行中根据动态结果调整方向(如客服对话、debug 排查) - 上一步的执行结果会影响到下一步做什么(如 Web 搜索后根据结果决定下一步搜什么) - 用户可能中途中断或修改输入(如交互式对话)
用一句话概括:Plan-then-Execute 适合"已知路径"的任务,ReAct 适合"探索路径"的任务。
实际 Token 节省估算
用 ReWOO 论文的数据结合实测,一个 3 步工具调用任务的 Token 消耗:
| 模式 | 规划 Token | 执行 Token | 合计 |
|---|---|---|---|
| ReAct | ~710(3 次推理) | 0 | ~710 |
| Plan-then-Execute | ~250(1 次规划) | ~150(Worker + Solver 调用消耗) | ~400 |
| 节省 | — | — | ~44% |
注意:Solver 的最终推理在一次执行中也是必需的——它把各步骤结果整合成用户能读的答案。即使 ReAct 模式,最终也需要一次推理来生成回答。
【趋势】从静态规划到自适应规划
当前局限
Plan-then-Execute 目前最常用的实现是"静态规划"——Planner 一次生成完整计划,之后完全不修改。如果执行过程中发现第一步的结果不符合预期,Agent 只会继续按原计划走,不会停下来重新评估。
如果你已经在用 LangGraph 或 CrewAI,这些框架对 PtE 模式有原生支持。LangGraph 的 StateGraph 支持在任意节点设置检查点(checkpoint),当节点输出偏离预期时触发重新规划。CrewAI 的 Process.hierarchical 模式天然实现了 Manager→Worker 的规划-执行分离——Manager 负责制定任务计划,Worker 执行,Manager 审查结果。改框架就是改一个配置的事。
下一站:Plan-then-Replan
下一代优化方向是引入"检查点":
- Planner 先生成初步计划
- Worker 执行到检查点
- 检查是否符合预期?→ 是则继续,否则触发 Replanner
- Replanner 修改剩余计划
这样就融合了 ReAct 的灵活性(能改)和 Plan-then-Execute 的效率(大部分步骤不推理)。
再下一站:Tree-of-Thought
更进一步的方向是用 Tree-of-Thought(ToT)代替线性规划——同时生成多条规划路径,在执行过程中基于中间结果切换最优路径。这个方案虽然推理成本更高,但在需要大量探索的场景(如代码生成、研究分析)中效果更好。

每个选择都对应一个权衡: - 全部推理(ReAct):最灵活,最贵 - 规划→执行(Plan-then-Execute):最便宜,最死板 - 规划→检查→再规划(Plan-then-Replan):折中 - 多路径并行(Tree-of-Thought):最贵,但探索最彻底
【锚点】"记住一句话"
脑中的锚点
"Plan-then-Execute = 先画施工图再施工,ReAct = 边施工边改图纸。"
如果你在搭一个步骤确定的 Agent 流水线,先用 Plan-then-Execute 省下那 40% 的 Token。如果 Agent 需要在执行中看情况变通,回到 ReAct 的每步推理。
下篇我们聊 Reflection——Agent 如何像程序员 review 自己代码一样自我纠错。
🔗 个人博客:https://opencao.cn 📺 公众号:Ai拆代码的曹操 🌟 知识星球:Ai拆代码的曹操


