
Reflection 与 Self-Critique:Agent 的自我纠错能力
场景:Agent 输出了一个错误的 SQL 查询——没有人类介入,它自己能发现并修正吗? 路径:黑盒 → 入口 → 核心机制 → 三层实现 → 锚点
前三篇我们做了三件事:给 Agent 装上了大脑(ReAct 的推理循环)、装上了计划能力(PtE 的规划执行分离)、以及看清了它们的 Token 账单。Agent 从"能回答问题"进化到了"能完成多步任务"。
但有一个根本问题还没解决:Agent 怎么知道自己做对了?
ReAct 每步都推理但不会检查推理对不对。PtE 先规划再执行但不会验证计划合不合理。Agent 像一个一直写代码但从不做单元测试的程序员——输出量大,但质量不可控。
Reflection 填补的就是这个缺口。它是 Agent 架构中缺失的质量门——在输出后加一层自我验证。10 行代码就能给你的 Agent 加上自我纠错能力,是 Agent 所有能力中投入产出比最高的一个。
Agent 最反直觉的一个能力是自我纠错(Self-Critique)——它会输出答案,然后"检查"一遍自己的答案,发现错误,再重新生成。看起来像"有意识"的行为。但拆开来看,机制极其简单:模型在自己的概率分布中存在正确答案,第一次采样没选到,重新审视一遍就能修正采样偏差。
Reflection 不是魔法——是把"一次性生成"拆成了"生成 + 审视 + 修正"三步。就像你写完代码后做单元测试——不是让代码变聪明,是让代码变可靠。
Token — 模型处理的最小语义单元,类似编程语言的字符。"Hello World"在编程中是 2 个词,在 LLM 中是 2 个 Token。
【黑盒】Reflection:Agent 为什么能自我纠错
一个看起来"有意识"的行为
用户:查询过去 30 天销售额前 10 的商品
Agent:SELECT ... WHERE order_date > NOW() - INTERVAL 30 DAY
GROUP BY product_id ORDER BY SUM(amount) DESC LIMIT 10
Agent(自我纠正):等一下——忘记排除退款订单了。
SELECT ... WHERE order_date > NOW() - INTERVAL 30 DAY
AND status != 'refunded' AND env = 'production'
GROUP BY product_id ORDER BY SUM(amount) DESC LIMIT 10
Agent 自己发现了遗漏——不是人类告诉它的。这是怎么做到的?
拆开来看:Self-Check 的真相
Reflection 不是"模型有自我意识"——是同一个 LLM 被调用了两次。第一次生成答案,第二次用另一个 Prompt 去检查这个答案:
第一次调用(生成):
"写一条 SQL 查询过去 30 天销售额前 10 的商品"
第二次调用(检查):
"评估这条 SQL 是否忽略了退款订单、测试数据或边界情况"
第二次调用的 Prompt 不要求"写",要求"审视"。LLM 在做"审视"任务时,会从不同的角度看待自己的输出——因为审视的 Prompt 激活了训练数据中"审阅者"的模式,而不是"写代码者"的模式。
Self-Critique(自我批评) — 模型评估自身输出的过程。不是"模型有意识",是 LLM 在"审稿"模式下看到的盲区 vs "写稿"模式下的惯性。
【入口】从最简单的 Self-Check 开始
最简实现:生成 → 审视 → 修正
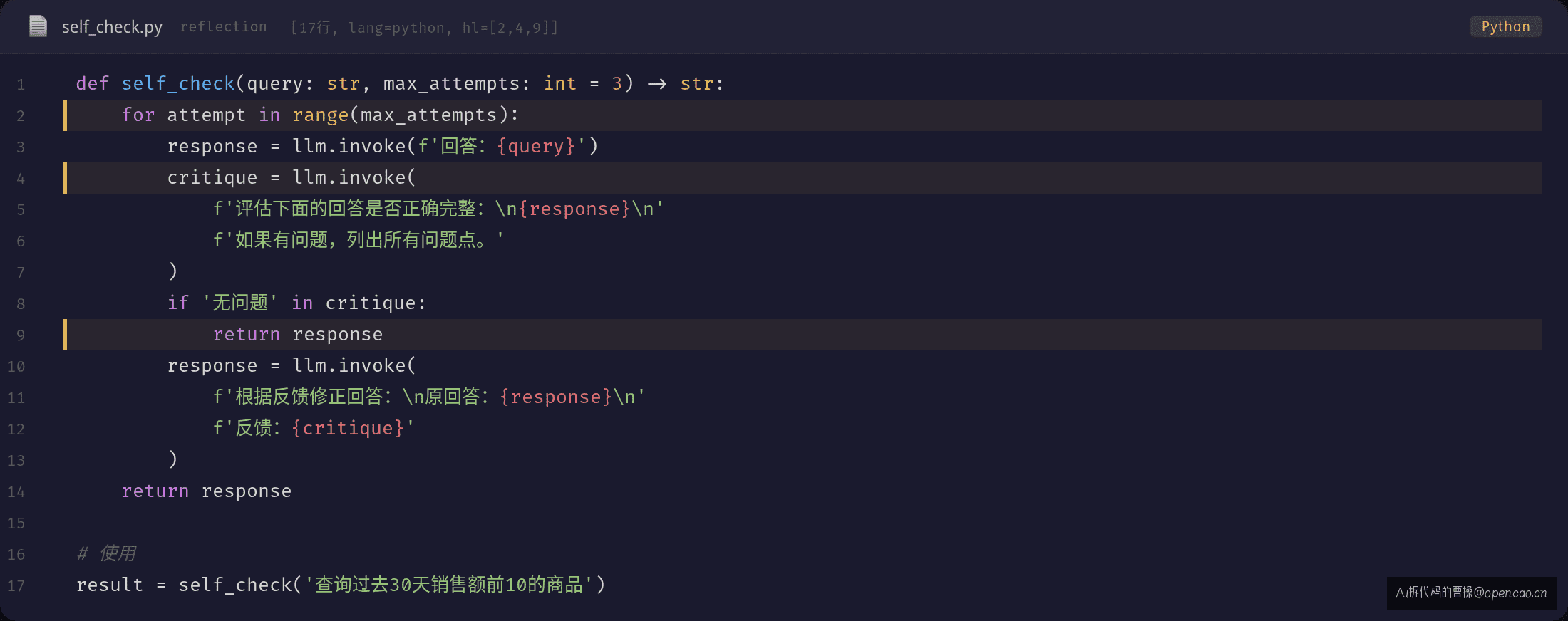
这段代码就是 Reflection 最原始、最核心的形态:
- 生成 — LLM 以"写"模式输出答案
- 审视 — 同一个 LLM 以"审阅"模式评估答案
- 修正 — 根据审阅反馈重新生成
Self-Check 为什么有效?
直觉上这说不通——一个模型怎么可能发现自己的错误?
原因:模型输出时采样的 Token 只是概率分布中的一组路径。正确答案的概率可能排在第 2 或第 3,但第一次采样选了第 1。 当你换一个角度(审视模式)重新评估时,LLM 使用的上下文不同,激活的路径也不同。
类比:你写了一个函数,debug 了三遍没发现问题。让同事 review 一眼——"这里 race condition"。不是同事比你聪明,是他的视角和上下文不一样。
实验数据:Google DeepMind 的 Self-Consistency(Wang et al., 2023)论文显示,同一个模型对同一个问题的多次采样取多数投票,准确率提升 10-20%。Self-Check 相当于给模型一次"换个角度看自己"的机会。
Self-Consistency(自一致性) — 对同一个问题多次采样,取出现频率最高的答案。不是"模型变得更聪明",是"减少了单次采样偏差"。
【路径】🔍 Self-Critique 的核心机制:概率分布中的纠错空间
理解了这个机制,你就知道为什么"换一个 Prompt 让模型审视自己"能发现错误。
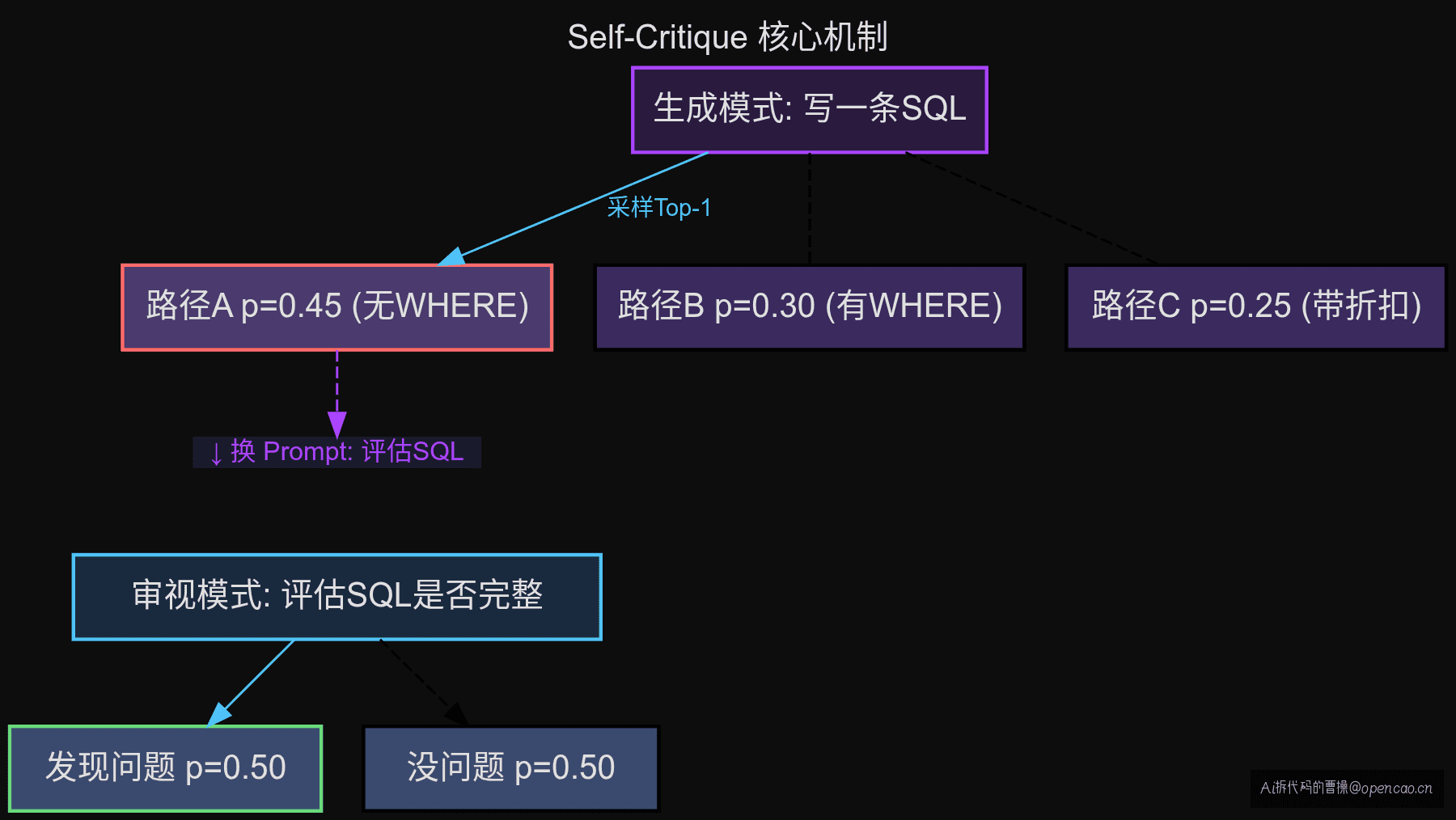
采样偏差
LLM 输出是一个概率分布采样过程。对于同一个输入,模型可以生成多个合理的输出,只是概率不同。
输入:"查询销售额前 10 的商品"
输出路径 A(概率 0.45):
SELECT product_id, SUM(amount) FROM orders ... ❌ 没考虑退款
输出路径 B(概率 0.30):
SELECT product_id, SUM(amount) FROM orders WHERE status != 'refunded' ... ✅ 对了
输出路径 C(概率 0.25):
SELECT product_id, SUM(amount * 0.9) FROM orders ... ✅ 对了还考虑了折扣
第一次采样选了路径 A——概率最高的。但路径 B 也在分布中,只是被忽略了。
换 Prompt = 换采样分布
当你用"审视"Prompt 调用同一个模型时:
审视 Prompt 下的输出分布:
"这条 SQL 有问题"(概率 0.50)——因为"审阅者"模式更注重完整性
"这条 SQL 没问题"(概率 0.50)
两个分布不是独立的——但"审视"Prompt 改变了模型的注意力焦点。审阅者模式更关注"遗漏了什么"而不是"写了什么"。
Reflection 不是发现了新知识——是让模型从"写代码模式"切换到"审阅代码模式",激活了训练数据中不同的分布区域。
关键结论
- Model knows more than it says — 模型的概率分布包含正确答案,只是第一次采样没选到
- Reflection = 换一种方式来采样同一个分布
- Self-Consistency(多次采样投票)和 Self-Check(生成→审视→修正)本质是一回事——只是方式不同
读到这里,你已经掌握了 Agent 架构的三层能力模型:
| 层 | 能力 | 对应文章 | 编程类比 |
|---|---|---|---|
| 执行层 | ReAct 循环——让 Agent 动起来 | 第 2 篇 | 写代码 |
| 效率层 | PtE 规划——让 Agent 省 Token | 第 3 篇 | 编译优化 |
| 质量层 | Reflection——让 Agent 不出错 | 本篇 | 单元测试 |
三层缺一不可。一个生产级 Agent 必须同时具备行动力、经济性和质量门禁。你现在可以用这个框架来分析任何 Agent 框架的取舍了。
【拆解】Reflection 的三种实现层级
Layer 1:Simple Self-Check
最简单的形式——上面已经展示过了。生成 → 审视 → 修正。
优缺点: - ✅ 实现极简单:几行代码搞定 - ✅ 通用:不依赖特定模型 - ❌ 低效:每次修正都重新审视整段输出 - ❌ 同质化审视:同一个模型的"审视模式"和"生成模式"差异有限
适合场景: 快速原型验证、对准确率要求不高的任务。
Layer 2:Structured Critique(结构化审视)
不只是让 LLM"检查一下",而是定义明确的评估维度和评分标准:
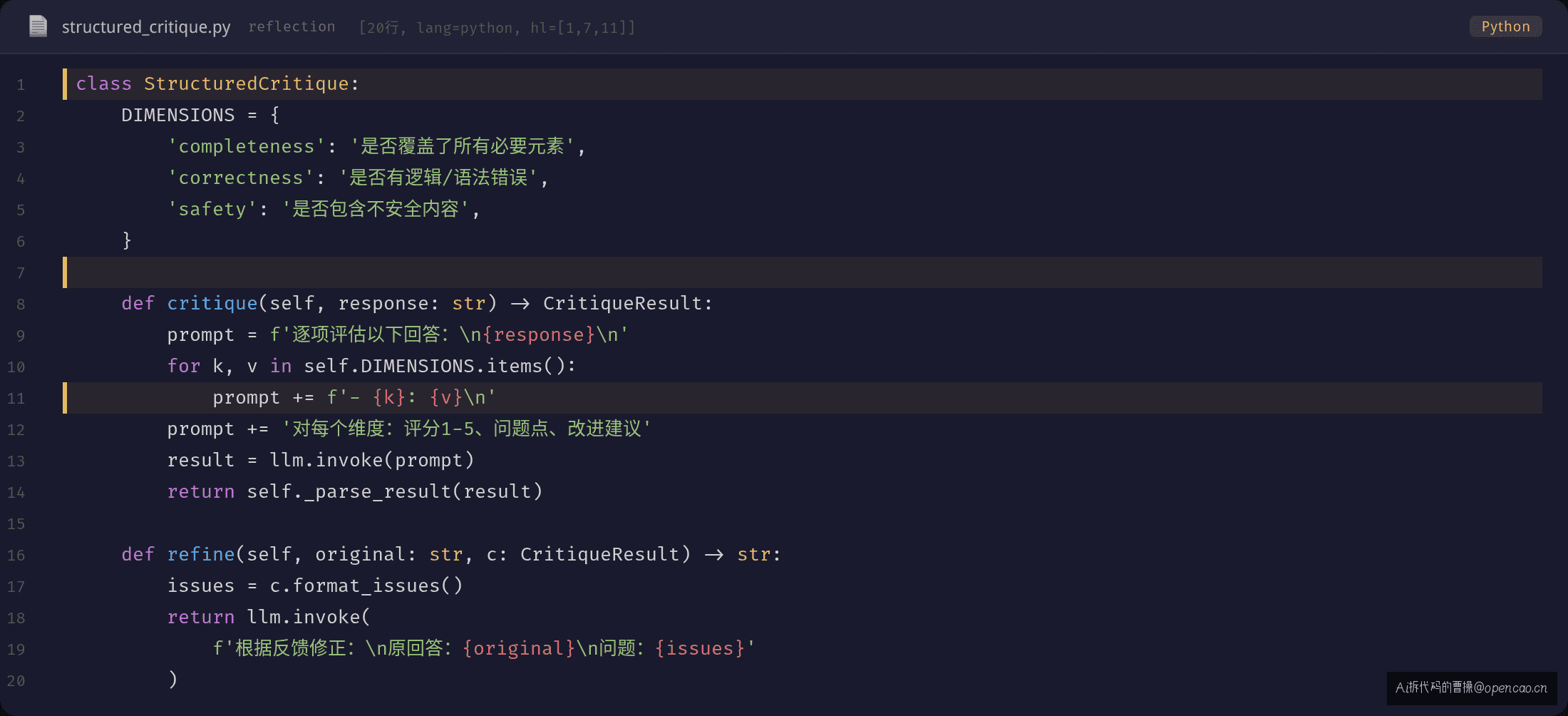
与 Layer 1 的核心区别: Layer 1 让 LLM 自由审视,Layer 2 告诉 LLM"从哪些维度看"。这相当于给审阅者一份 Checklist——"检查完整性"、"检查安全性"、"检查格式",而不是笼统的"看看有没有问题"。
效果提升: - 结构化审视比自由审视的覆盖面更广——维度框架迫使 LLM 逐项检查,而不是只看最明显的错误
优缺点: - ✅ 覆盖面更广:不会漏掉关键维度 - ✅ 可定制:不同场景可以定义不同的评估标准 - ❌ Prompt 更长:Token 消耗增加 - ❌ 维度设计本身需要人工思考
Layer 3:Multi-Perspective Reflection
最高级的形式——让多个不同的"角色"从不同角度审视同一个输出:
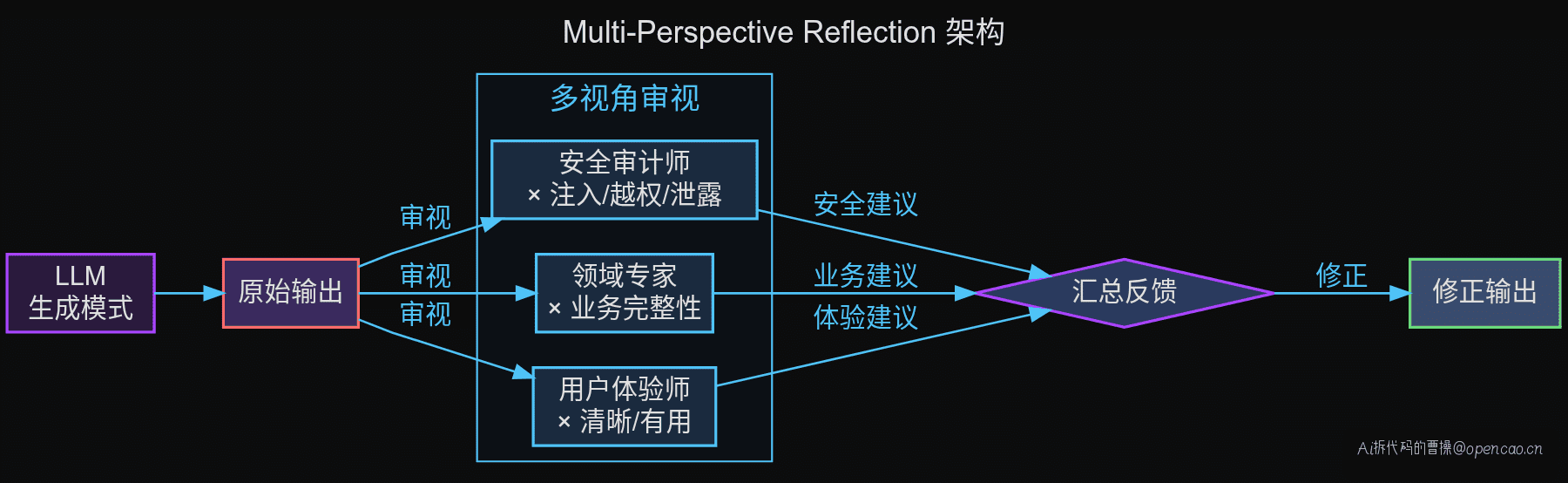
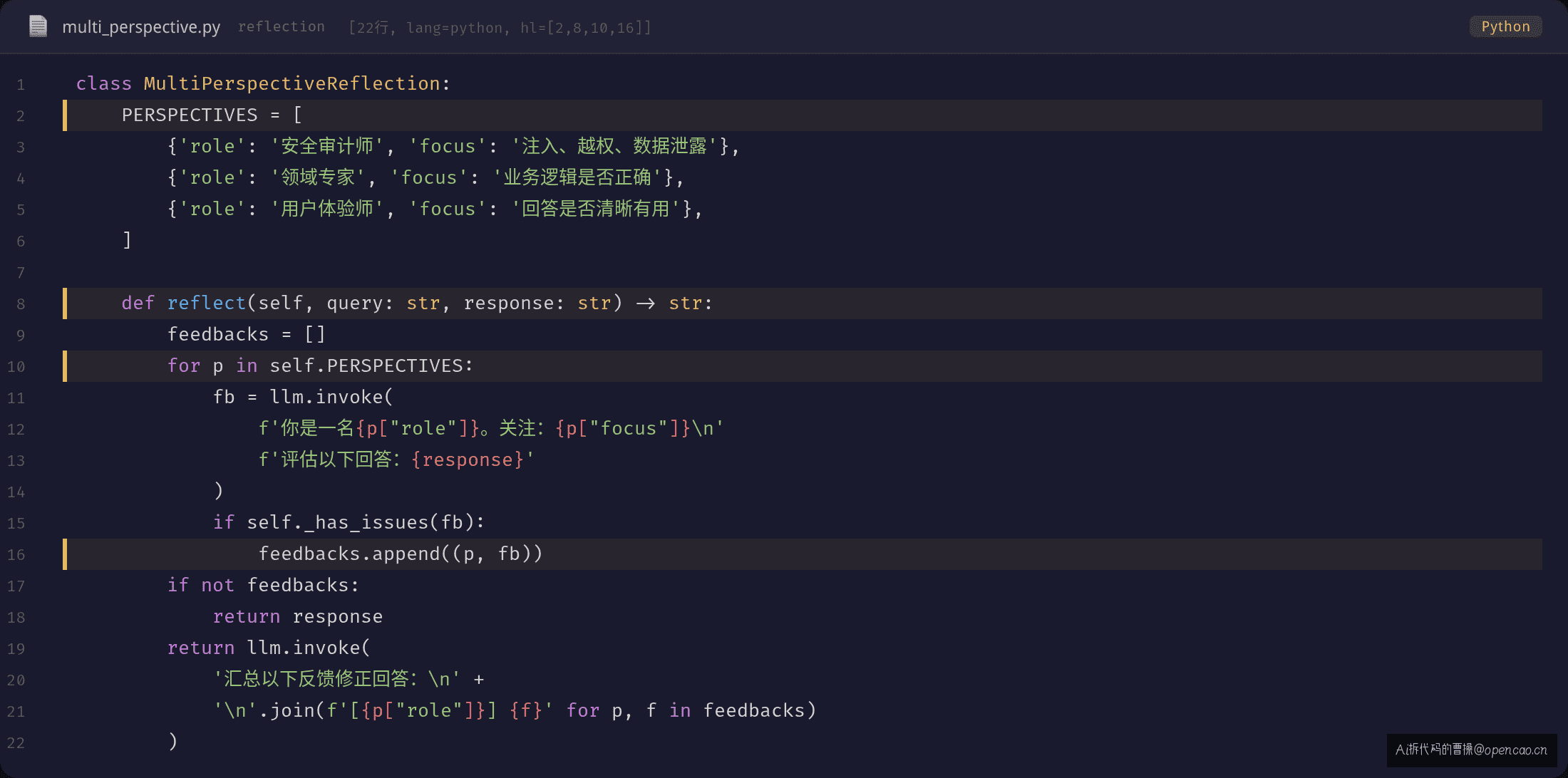
为什么三个视角比一个视角好?
同一个 LLM,当 Prompt 设定为"安全审计师"时,它关注的是攻击面和权限控制。设为"领域专家"时,关注的是业务完备性。设为"用户体验师"时,关注的是理解和满意度。
每个 Prompt 激活了训练数据中不同的分布区域——安全审计师激活了"安全审查"的知识,领域专家激活了"业务完整性"的知识。同一个模型,不同的视角调用 = 采样了不同的概率分布。
优缺点: - ✅ 最全面的审视:覆盖安全、业务、体验多个维度 - ✅ 接近人工 Code Review 的效果 - ❌ Token 消耗最高:每增加一个视角就多一次 LLM 调用 - ❌ 视角需要精心设计:不合适的视角会产生噪音反馈
三层的选型指南
| Layer | Token 成本 | 复杂度 | 覆盖率 | 适合场景 |
|---|---|---|---|---|
| 1-Self-Check | 低(2-3 次调用) | 极低 | 有限 | 快速原型、低风险任务 |
| 2-Structured | 中(2-3 次+结构框架) | 低 | 中 | 生产级、对准确率有要求 |
| 3-Multi-Perspective | 高(N+2 次调用) | 中 | 较高 | 高风险场景、用户交互内容 |
选型法则:Token 预算越低,选 Layer 越低。覆盖要求越高,Layer 越高。
生产中的 Reflection
当前主流 Agent 框架对这几种 Reflection 都有内置支持:
- LangGraph 的
reflect_node— 在 Agent 循环中插入一个"反思"节点,对历史对话做结构化审视(Layer 2)。典型用法:代码生成 Agent 在生成后自动 review 代码质量。 - CrewAI 的层级协作 — 多个 Agent 互相 review 输出(天然 Multi-Perspective)。典型用法:研究报告 Agent 写初稿 → 审核 Agent 标记问题 → 修正 Agent 重写。
- OpenAI Structured Outputs — 用 JSON Schema 约束输出格式,模型自动校验结构完整性(最轻量的 Self-Check 变体)。
这些框架的本质都是在做同一件事:在"输出"和"交付"之间加了一层验证。区别只是验证的维度多少和深度。
【锚点】记住一句话
Agent 不仅仅是输出答案——它在输出后还会问自己一遍"这个答案对吗?" 模型不是不知道自己错了——是第一次没选对答案。Reflection 给了它第二次选择的机会。
Reflection 的核心洞察:
- 不是魔法 — 是同一模型调了两次,只是 Prompt 不同
- 不是自我意识 — 是换了一种方式来采样概率分布
- 不是万能 — Self-Check 不能发现训练数据中不存在的知识盲区
衡量 Reflection 效果的标准:给非技术人员演示时,能不能几十秒内展示"Agent 自己发现了错误"。 如果做不到,说明你的 Reflection 流程不够直观。
下篇我们聊 Function Calling 与 Tool Use——Agent 如何调用外部工具,让 Agent 从"只能回答问题"变成"能执行操作"。
🔗 个人博客:https://opencao.cn 📺 公众号:Ai拆代码的曹操 🌟 知识星球:Ai拆代码的曹操


