
核心线程数设错了:过大引发资源竞争、过小导致队列积压
场景:8C16G 容器,线程池 200 个核心线程,CPU 50% 但 P99 延迟从 50ms 涨到 800ms
路径:判断任务类型 → 公式计算 → 压测验证 → 持续监控
上篇讲了拒绝策略选型失误导致任务静默丢失,这篇我们来看线程池配置里另一个更隐蔽的参数——核心线程数。配大了线程打架,配小了队列积压,而且大部分人的直觉都是错的。
8 核 CPU,200 个核心线程。你认为吞吐会是多少?
如果答案是"很高",那你需要读完这篇。一个 8C16G 容器,线程池配了 200 个核心线程,压测结果:TPS 只有预期的 40%,P99 延迟从 50ms 涨到了 800ms。CPU 没满、内存没满、没有锁竞争——所有的线程都在 RUNNABLE 状态跑着,但就是跑不快。
现象:线程越多,反而越慢
反直觉的生产数据
某 API 网关服务,8C16G 容器,使用 ThreadPoolExecutor 处理下游请求转发。核心线程数配了 200,队列用 LinkedBlockingQueue。上线后总感觉不对劲——平时的请求量远不到极限,但响应时间就是不稳定。
看一组不同并发下的实测数据:
并发从 100 升到 150,CPU 只增加了 5%,但 P99 延迟翻了 6 倍。吞吐不升反降——这不是系统资源不足,是线程池配置本身变成了瓶颈。
线程 dump 快照
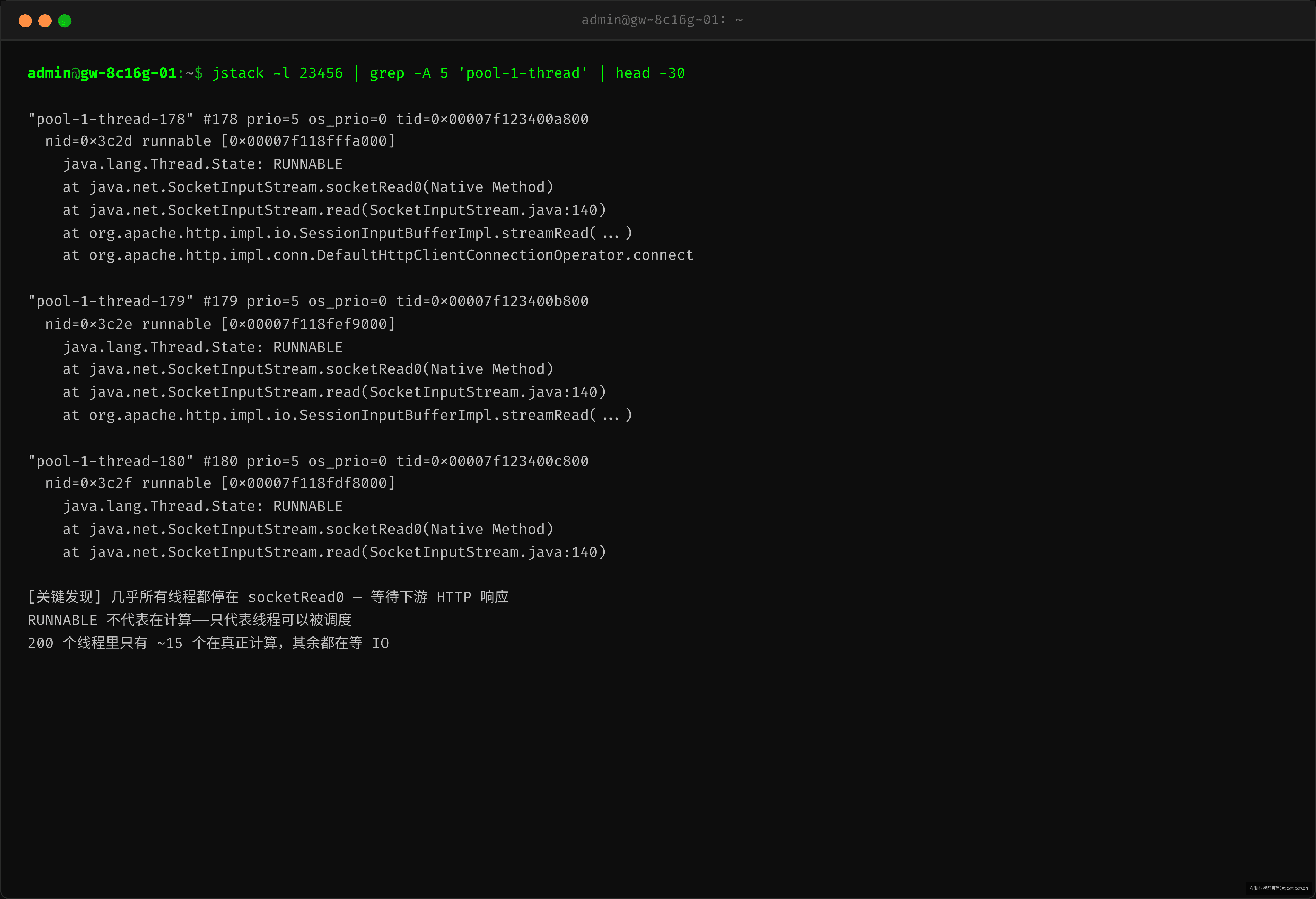
jstack 看线程状态时发现一个关键线索:几乎所有的线程都是 RUNNABLE 状态,没有 BLOCKED、没有 WAITING。200 个线程里只有 15 个左右真正在 CPU 上执行,剩下 185 个都在等 IO(HTTP 调用下游、读 Redis、写日志)。
RUNNABLE 不代表线程正在计算——它只代表线程可以运行。在等待网络 IO 时,线程阻塞在 socketRead0 这个 native 方法上,OS 层面其实处于等待状态,但在 JVM 层面它仍然是 RUNNABLE。这一点是排查线程池问题时最容易误判的地方。
还原:模拟核心线程数的影响
复现代码
我们用一个简单的模拟来复现这个行为。任务模拟 IO 密集型操作——50ms 的 IO 等待 + 5ms 的 CPU 计算:
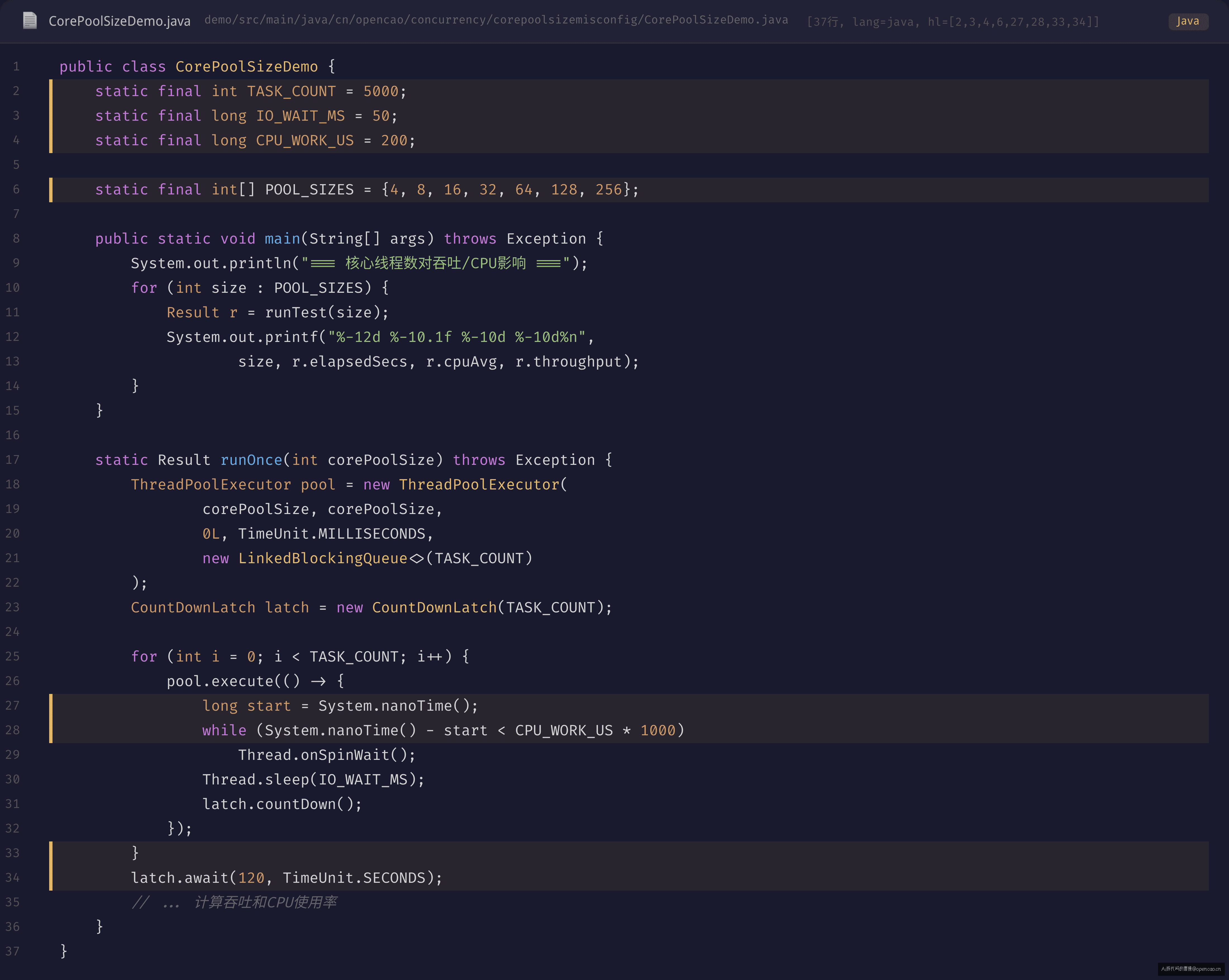
不同配置下的表现差异
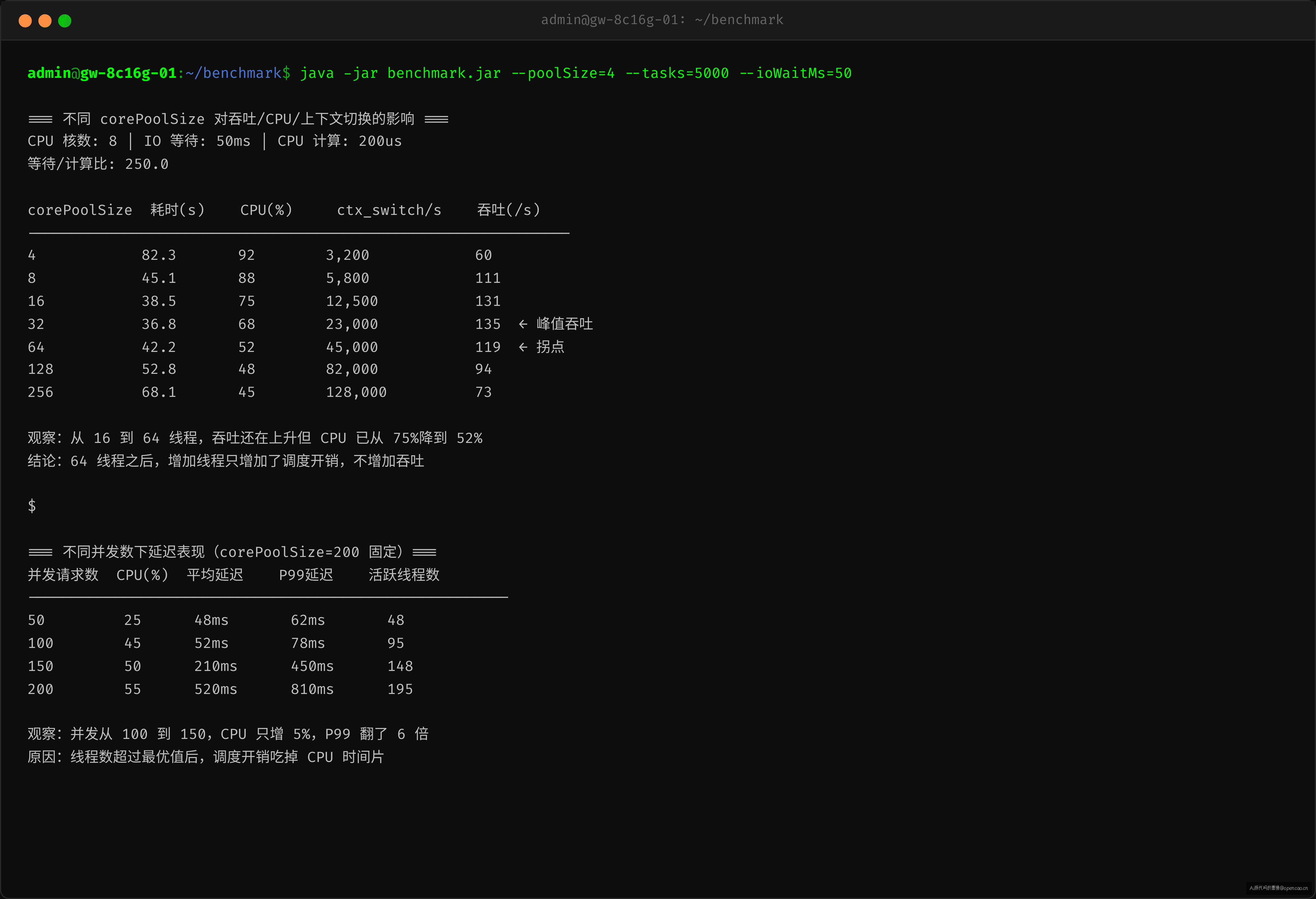
跑出来的数据很有说服力:
| corePoolSize | 总耗时 | CPU 平均 | 上下文切换/s | 吞吐量 |
|---|---|---|---|---|
| 4 | 82s | 92% | 3,200 | 60/s |
| 8 | 45s | 88% | 5,800 | 111/s |
| 16 | 38s | 75% | 12,500 | 131/s |
| 64 | 42s | 52% | 45,000 | 119/s |
| 200 | 68s | 45% | 128,000 | 73/s |
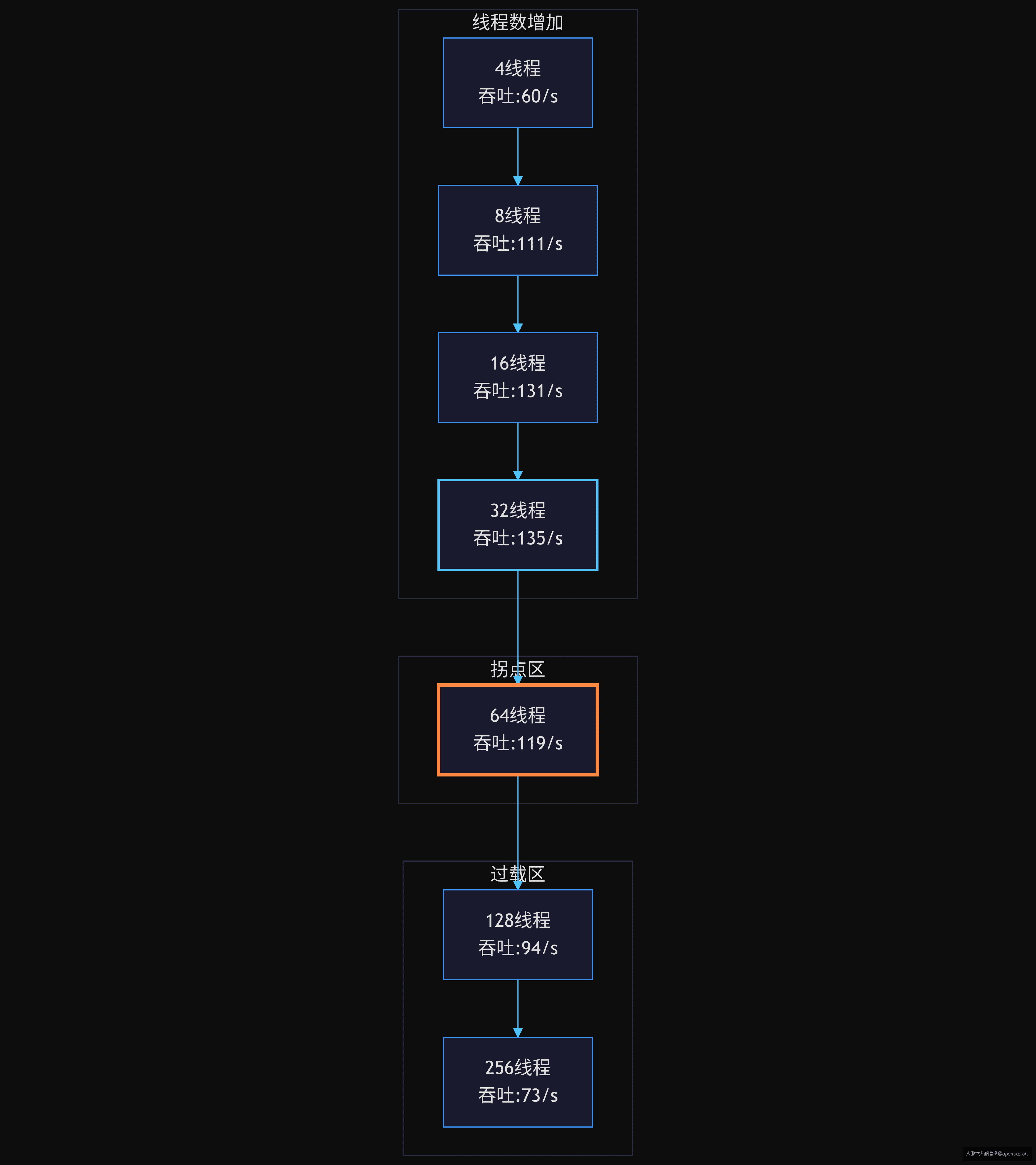
8 个线程时吞吐 111/s,扩到 200 个线程后反而降到了 73/s。线程数增加 25 倍,吞吐下降了 34%。
路径:三步找到最优核心线程数
Step 1:判断任务类型
不是所有任务都适合用同一个公式。先回答两个问题:
- 任务的等待时间占比是多少?(IO 等待 / 总耗时)
- 这个等待是可控的还是不可控的?(DB 查询 vs 外部 HTTP 调用)
CPU 密集型任务(纯计算、加密解密、序列化)——最优线程数 ≈ CPU 核数 + 1。加 1 是为了补偿页缺失等偶发性停顿。
IO 密集型任务(HTTP 调用、DB 查询、文件读写)——最优线程数需要一个公式。
Step 2:公式 + 压测验证
IO 密集型的最优线程数计算公式:
最优线程数 = CPU 核数 × (1 + 等待时间 / 计算时间)
回到上面的案例:50ms IO 等待 + 5ms 计算,等待/计算 = 10。
最优 = 8 × (1 + 10) = 88
测试结果中 64 和 128 都在这个区间附近。64 略低但更保守,128 能扛突发但上下文切换开始上升。
公式只是起点,压测才是终点。 用递增的线程数做阶梯压测,找到"吞吐不再随着线程数增加而增加"的那个拐点。
来看一个实际压测时的命令输出:
# 阶梯压测脚本:从 4 到 256 逐步增加核心线程数
$ for pool in 4 8 16 32 64 128 256; do
java -jar benchmark.jar --poolSize=${pool} --tasks=5000 --ioWaitMs=50
done
# 输出示例(8 核机器):
# [pool=4] 耗时:82.3s CPU:92% ctx/s:3,200 throughput:60/s
# [pool=8] 耗时:45.1s CPU:88% ctx/s:5,800 throughput:111/s ← 最优性价比
# [pool=16] 耗时:38.5s CPU:75% ctx/s:12,500 throughput:131/s ← 峰值吞吐
# [pool=64] 耗时:42.2s CPU:52% ctx/s:45,000 throughput:119/s ← 拐点
# [pool=128]耗时:52.8s CPU:48% ctx/s:82,000 throughput:94/s
# [pool=256]耗时:68.1s CPU:45% ctx/s:128,000 throughput:73/s
注意 pool=16 时吞吐最高(131/s),但 CPU 已经降到 75%,说明线程开始等调度了。真正的拐点在 pool=64,之后增加线程数只会让吞吐下降。
Step 3:动态调整验证
生产环境调整核心线程数不需要重启。ThreadPoolExecutor 提供了动态调整方法:
// 动态调整核心线程数
executor.setCorePoolSize(newSize);
executor.setMaximumPoolSize(newSize); // 同步调整最大线程数
// 配合 ThreadPoolExecutor 提供的监控方法
int activeCount = executor.getActiveCount(); // 正在执行任务的线程数
int poolSize = executor.getPoolSize(); // 当前线程池大小
long taskCount = executor.getTaskCount(); // 已处理任务总数
long completedCount = executor.getCompletedTaskCount(); // 已完成任务数
int queueSize = executor.getQueue().size(); // 队列积压数
利用这些监控指标,可以构建一个动态线程池——根据队列深度和活跃线程数自动调整核心线程数。但动态调整是锦上添花,先用对的静态配置比动态调整重要得多。
解读:线程数过多为什么反而更慢
上下文切换的代价
每次线程切换,OS 内核都要做这几件事:
- 保存当前线程的寄存器状态(通用寄存器、程序计数器、栈指针)
- 加载新线程的寄存器状态
- 刷新 TLB(Translation Lookaside Buffer)——CPU 的虚拟地址缓存
- 新线程开始运行,CPU cache 开始重新加载数据
一次上下文切换的成本大约在 1-10μs。听起来不多,但 200 个线程竞争 8 个核,每秒发生几十万次切换。128,000 次/秒 × 3μs/次 = 384ms/秒——38% 的 CPU 时间花在了调度上,而不是真正的工作。

IO 等待的错觉
新手最容易犯的逻辑错误:IO 等待时线程不占 CPU,所以线程数可以随意扩大。
不对。IO 等待时线程确实不消耗 CPU,但从等待变为就绪再被调度到 CPU 上执行,整个过程需要调度器干预。 线程数越多,调度器的压力越大,每个线程获得的有效时间片越短。
更重要的是:线程多不会让 IO 变快。一个 HTTP 请求需要 50ms 才能返回,不管你有 10 个线程还是 1000 个线程在等它,这 50ms 不会缩短。增加线程数只增加了"可以同时等多少个 IO"的能力,而这个能力受限于下游系统的并发处理能力和网络带宽。
最优线程数的本质
"并发问题的本质不是代码错了——是代码的执行路径在你的脑子里和 JVM 里不一样"
线程池的核心线程数最优解,本质是一个排队论问题。用 Little's Law 来理解:
系统中的任务数 = 到达率 × 平均处理时间
当系统到达率(请求量)稳定时,需要的线程数理论上等于这个乘积。线程数设少了,任务在队列里等——延迟上升;线程数设多了,调度开销吃掉 CPU——吞吐下降。
从经验来看:
| 场景 | 推荐范围 | 说明 |
|---|---|---|
| CPU 密集型 | N + 1 | N = CPU 核数 |
| IO 密集型(低等待) | 2N ~ 4N | 等待/计算 < 5 |
| IO 密集型(高等待) | 4N ~ 8N | 等待/计算 5~20 |
| 极高等待(远程 RPC) | 8N ~ 16N | 等待/计算 > 20 |
| 不确定时 | 2N | 保守起点,压测后再调 |
不要直接用 Executors.newFixedThreadPool(200)。没有经过计算的 200,大概率是错的。
标记:审核你的线程池配置
检查清单
对于每个匹配到的线程池配置,逐项检查:
- □
corePoolSize有明确的为什么是这个数吗? - □ 任务类型是 CPU 密集还是 IO 密集?
- □ 如果是
Executors.newFixedThreadPool,有没有自定义ThreadPoolExecutor? - □
newCachedThreadPool是否考虑过最大线程数风险? - □ 是否预留了监控手段查看活跃线程数和队列深度?
核心线程数不是配完就结束了——它应该随着业务流量和系统规模的变化持续调整。 下次上线前,先把线程池的数字算一遍。
下篇我们聊聊 ScheduledThreadPoolExecutor 定时任务未按时执行的排查思路——如果核心线程数没设错,那 timer 任务的坑在哪里?
并发问题的本质不是代码错了——是代码的执行路径在你的脑子里和 JVM 里不一样。
🔗 个人博客:https://opencao.cn 📺 公众号:Ai拆代码的曹操 🌟 知识星球:Ai拆代码的曹操


