
ScheduledThreadPoolExecutor 定时任务未按时执行排查
场景:每 5 秒执行一次的定时任务,实际间隔变成了 8 秒、15 秒、30 秒——越来越慢
路径:检查执行时间 → 区分 fixedRate vs fixedDelay → 验证异常处理 → 监控线程池状态
上篇讲了核心线程数设错导致吞吐下降,这篇我们来看线程池配置里一个更隐蔽的定时器陷阱——ScheduledThreadPoolExecutor 的任务"丢"了,但实际上不是丢了,是排不上队。
一个定时任务,配了 scheduleAtFixedRate(task, 0, 5, SECONDS),每 5 秒执行一次。上线第一周正常。第二周发现:任务执行间隔变成了 8 秒、15 秒、30 秒——不是膨胀,是"堵车"了。而代码里只有一个人在开车。
现象:定时任务越跑越慢
反直觉的时序数据
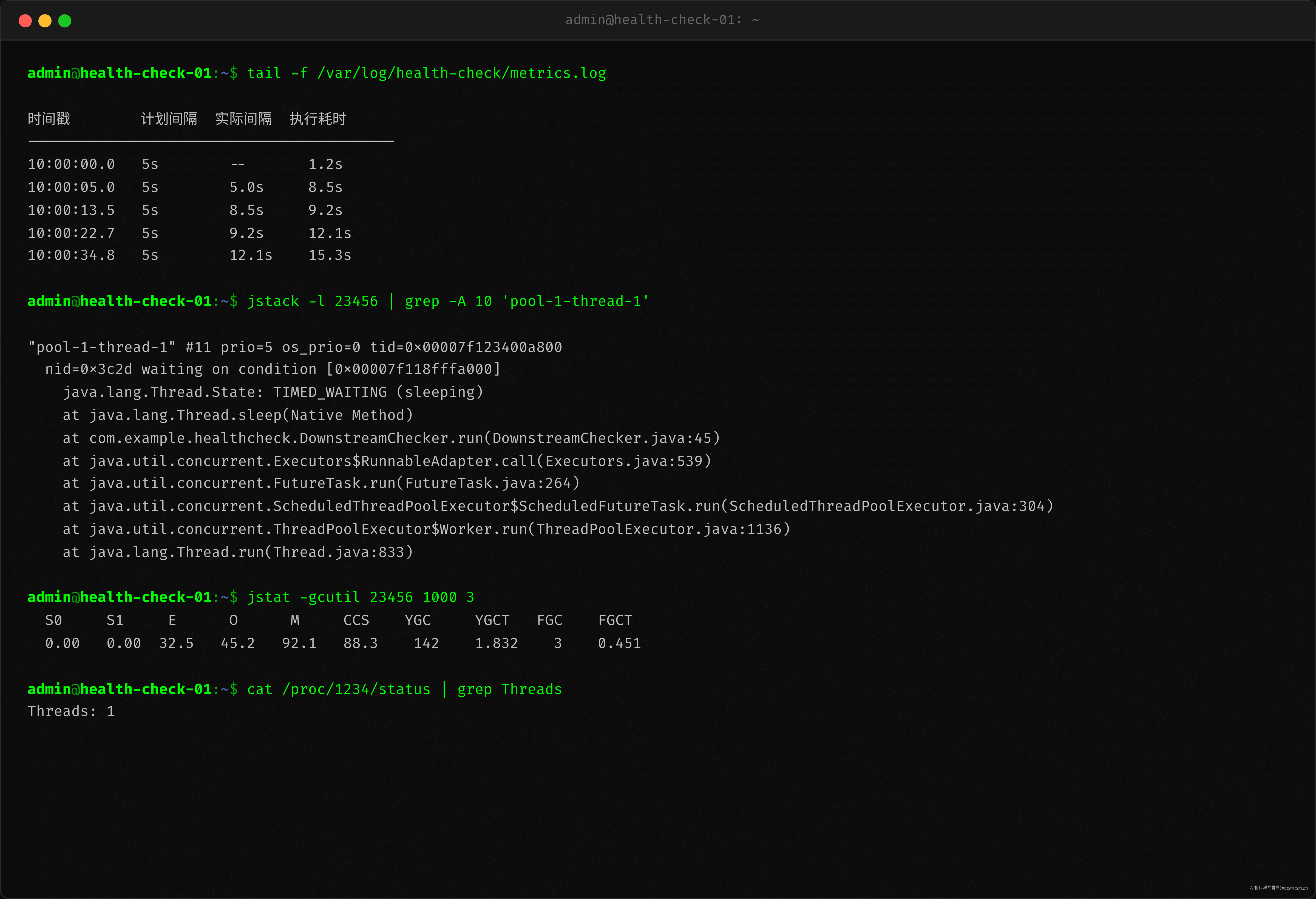
某健康检查服务,使用 ScheduledThreadPoolExecutor 每隔 5 秒检测下游依赖状态。上线后前几天的 P99 间隔稳定在 5.1 秒。一周后开始异常:
| 时间戳 | 计划间隔 | 实际间隔 | 任务执行耗时 | 备注 |
|---|---|---|---|---|
| 10:00:00.0 | 5s | — | 1.2s | 正常 |
| 10:00:05.0 | 5s | 5.0s | 8.5s | DB 慢查询 |
| 10:00:13.5 | 5s | 8.5s | 9.2s | 补偿执行 |
| 10:00:22.7 | 5s | 9.2s | 12.1s | 排队加剧 |
| 10:00:34.8 | 5s | 12.1s | 15.3s | 持续恶化 |
关键发现:任务的实际执行耗时一直不稳定,从最初的 1.2s 逐渐增长到 15s+,导致 scheduleAtFixedRate 的"固定速率"保证被打破。但排查人员的第一反应都是"定时器不准了",而不是"任务执行太慢了"。
核心问题:默认只有一个线程
ScheduledThreadPoolExecutor 的默认构造函数只创建一个线程:
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
如果调用 Executors.newSingleThreadScheduledExecutor(),corePoolSize 就是 1。一个线程意味着:同一时间只能执行一个定时任务。如果当前任务还没跑完,下一个到期的任务就得等。
更严重的是 scheduleAtFixedRate 的语义:它不是"到点就中断当前任务、启动下一个"——而是"当前任务跑完后,检查是不是已经过了下次执行时间,如果是,立即启动下一次"。这使得一次慢执行会产生链式反应。
还原:模拟定时任务堆积
复现代码
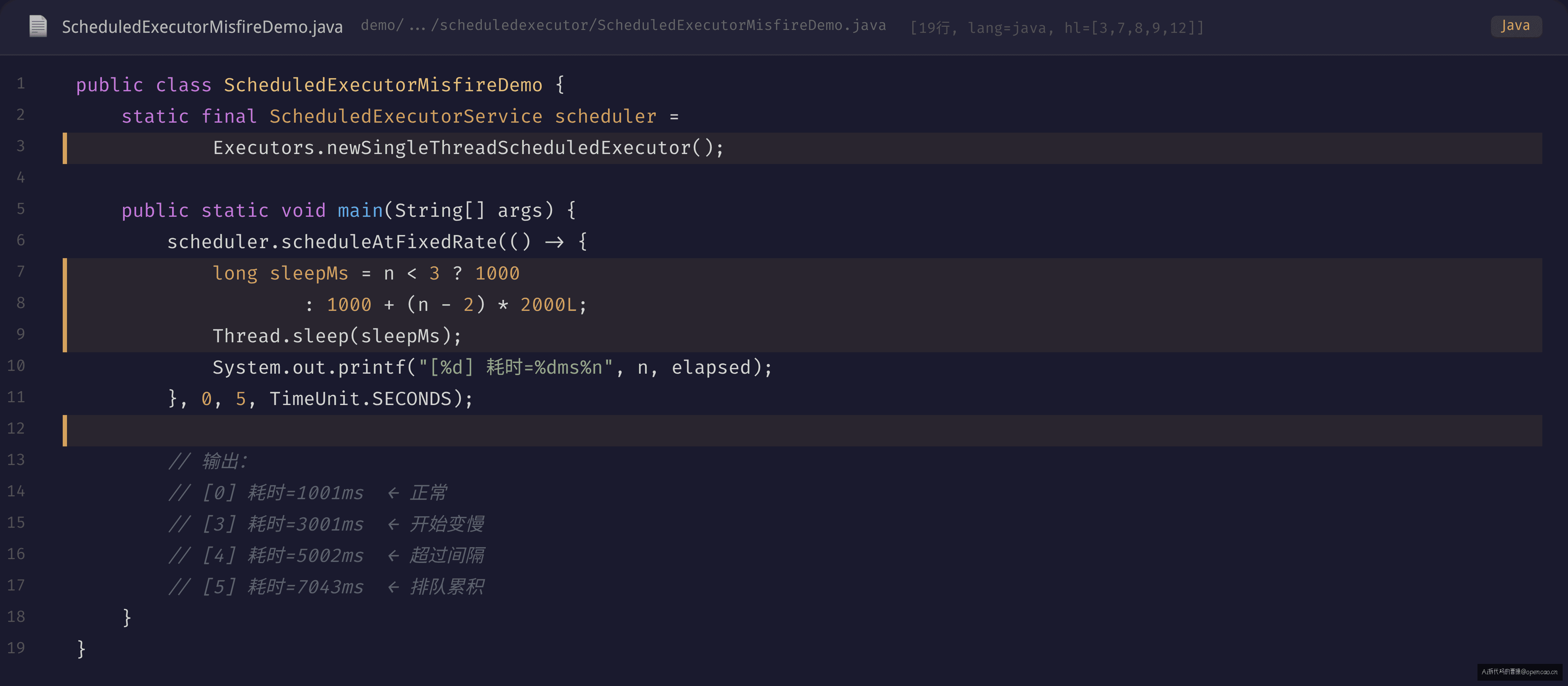
第 4 次执行后,实际耗时已经超过 5 秒的间隔。由于 scheduleAtFixedRate 的实现是"当前任务执行完毕后,立即补偿错过的执行",后续每次执行都紧接着上一次,实际间隔等于 任务执行耗时,而不是计划的 5 秒。
这就引出了关键问题:如果换一种调度策略,行为会不会不同?
scheduleAtFixedRate vs scheduleWithFixedDelay
这两种策略的行为完全不同,是排查定时任务延迟时必须区分的:
| 策略 | 间隔计算方式 | 任务超时后果 |
|---|---|---|
scheduleAtFixedRate |
以上次任务开始时间为基准 + period | 下次执行会排队等待当前任务完成,完成后立即执行补偿 |
scheduleWithFixedDelay |
以上次任务结束时间为基准 + delay | 不影响计时——delay 是"结束后等多久",与执行时长无关 |
用一个简单的比喻:
- fixedRate = 每隔 5 分钟发一班车,不管上一班是否堵在路上。如果堵车,车一到站立刻发下一班(补偿机制)。
- fixedDelay = 上一班车到站后,等 5 分钟再发下一班。堵车只会让下一班推迟,但不会连续补偿。
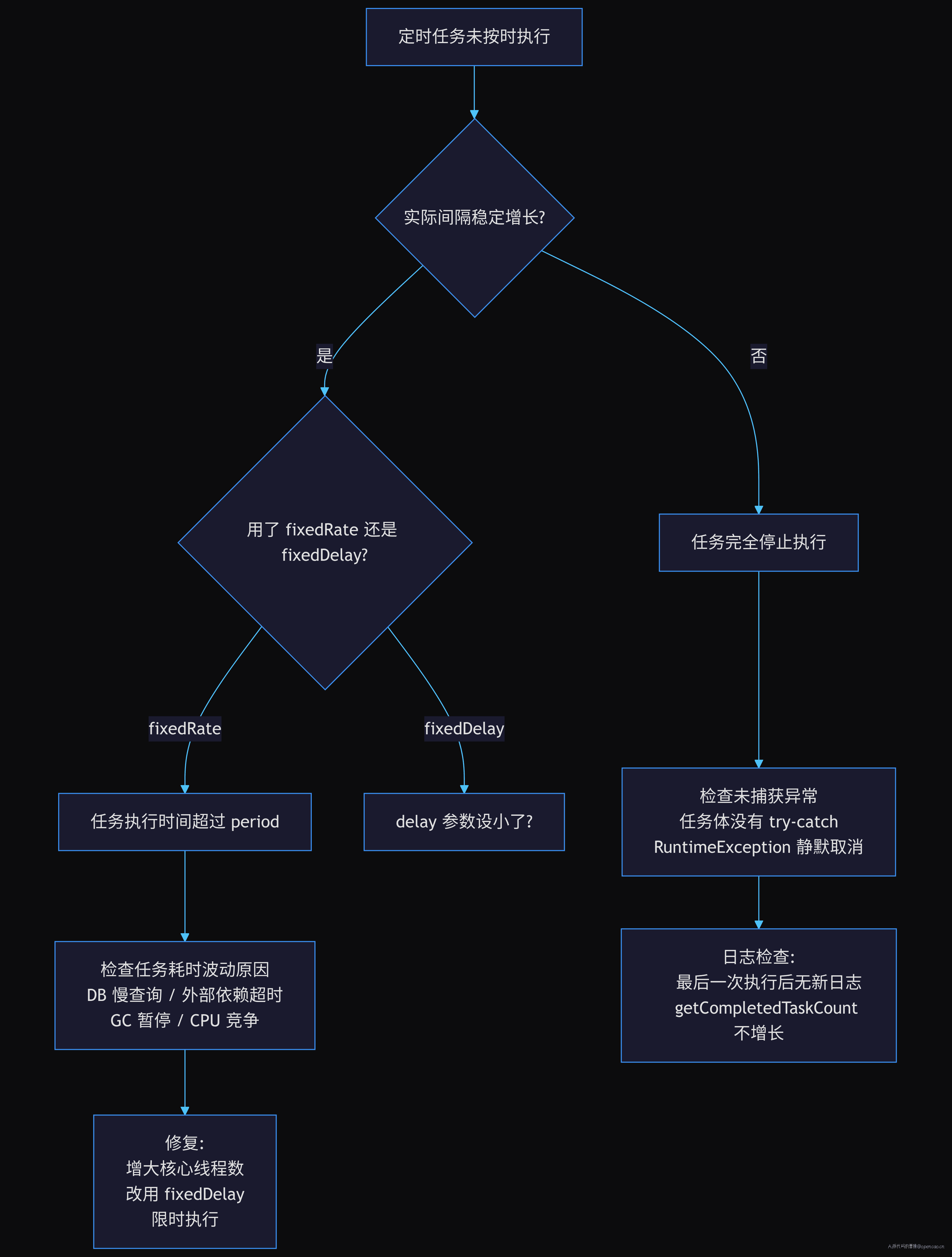
路径:三步定位定时任务延迟
Step 1:确认是 fixedRate 还是 fixedDelay
先看代码用的是哪个 API:
grep -rn "scheduleAtFixedRate\|scheduleWithFixedDelay" src/main/java/
如果是 scheduleAtFixedRate + 单线程调度器,任务执行时间波动会直接导致间隔不稳定。
Step 2:检查任务实际执行时间
在任务开始和结束时打日志,或者用 ScheduledExecutorService 的监控方法:
// ScheduledThreadPoolExecutor 继承自 ThreadPoolExecutor
ScheduledThreadPoolExecutor executor = (ScheduledThreadPoolExecutor) scheduler;
int activeCount = executor.getActiveCount(); // 当前执行线程数
long completedCount = executor.getCompletedTaskCount(); // 已完成任务数
int queueSize = executor.getQueue().size(); // 等待队列中的任务数
如果 queueSize > 0,说明有定时任务堆积在队列里等待执行。
# 阶梯压测输出示例:
# 任务耗时 1s → 实际间隔 5s(正常)
# 任务耗时 3s → 实际间隔 3s(fixedRate 补偿)
# 任务耗时 6s → 实际间隔 6s(超过周期,不再补偿)
Step 3:检查未捕获异常
ScheduledThreadPoolExecutor 的一个隐秘陷阱:如果 scheduleAtFixedRate 或 scheduleWithFixedDelay 的任务抛出了未捕获异常,该任务会被静默取消,不再调度。
scheduler.scheduleAtFixedRate(() -> {
// 如果这里抛 NullPointerException 或任何 RuntimeException
// 后续所有调度都会被取消,没有任何日志!
// 除非在任务外层 try-catch
}, 0, 5, TimeUnit.SECONDS);
这是 ScheduledThreadPoolExecutor 源码 ScheduledFutureTask.run() 中的行为——捕获到异常后,调用 setException(ex) 并返回,不再重新加入延迟队列。定时器就这样无声地停了。
排查方法:在执行前和执行后分别检查 executor.getQueue().size()。如果任务消失且队列为空,大概率是未捕获异常导致的任务取消。
解读:ScheduledThreadPoolExecutor 的调度机制
核心数据结构:DelayedWorkQueue
ScheduledThreadPoolExecutor 使用 DelayedWorkQueue(基于二叉堆实现)而不是 LinkedBlockingQueue。每次 take() 时,堆顶元素如果未到期,当前线程会等待剩余时间;如果已到期,立即取出执行。
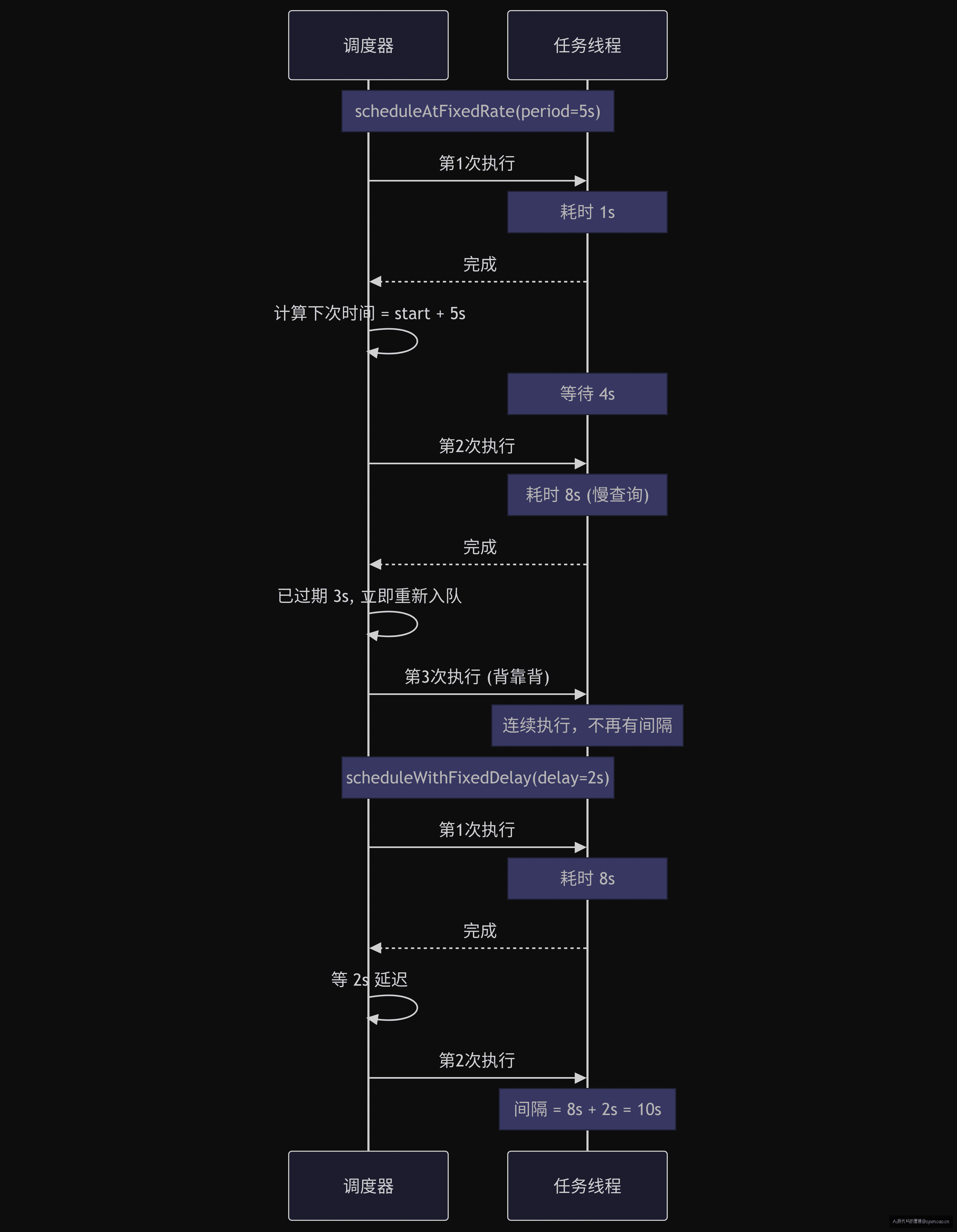
scheduleAtFixedRate 的执行流程:
任务 A 执行完毕
→ 计算下次执行时间 = 任务 A 的开始时间 + period
→ 检查当前时间是否 ≥ 下次执行时间
→ 如果是 → 立即将任务 A 重新放入 DelayedWorkQueue(delay=0)
→ 如果否 → 将任务 A 放入队列,设置 delay = 剩余时间
关键:"下次执行时间"是基于任务开始时间计算的,而不是结束时间。这意味着如果任务每次执行耗时 6s,period=5s,那么当前任务结束时,"下次执行时间"已经过期了 1s,所以会立即重新入队(delay=0),变成连续执行。
单线程的隐形成本
newSingleThreadScheduledExecutor 创建的调度器只有一个核心线程。如果这个线程被一个长时间任务占用,所有到期的定时任务都在 DelayedWorkQueue 中排队等待。当队列中堆积了多个任务时,后面的任务即使已经"到期",也只能等前面的任务完成。
解决方案:
- 增大 corePoolSize:用
new ScheduledThreadPoolExecutor(N),N 取决于有多少个长期存活的定时任务。一般来说,独立的任务可以共享一个多线程调度器。 - 区分 fixedRate 和 fixedDelay:如果任务执行时间不可控,优先用
scheduleWithFixedDelay,避免链式补偿。 - 异常保护:所有定时任务的方法体必须用 try-catch 包裹顶层逻辑。
ScheduledExecutorService scheduler = new ScheduledThreadPoolExecutor(4);
// 不要用:
// Executors.newSingleThreadScheduledExecutor()
fixedRate 补偿机制的数学本质
设 period = P,任务第 N 次执行耗时 = T_N
第 N 次开始时间 = S_N
第 N+1 次开始时间 = S_{N+1} = max(S_N + P, S_N + T_N)
如果 T_N ≤ P → S_{N+1} = S_N + P(正常间隔)
如果 T_N > P → S_{N+1} = S_N + T_N(连续执行,间隔 = T_N)
一旦 T_N > P,后续所有执行都变成"背靠背"连续执行,直到某次 T_M < P 才能恢复正常的周期调度。但如果在 T_M 期间又有多次 T > P,恢复时间会进一步推迟。
标记:审查你的定时任务
grep 清单
# 扫描所有 ScheduledThreadPoolExecutor 使用点
grep -rn "ScheduledThreadPoolExecutor\|newSingleThreadScheduledExecutor\|scheduleAtFixedRate\|scheduleWithFixedDelay" src/main/java/
检查标准
对于每个匹配项,逐条检查:
- □ 使用的线程池是
newSingleThreadScheduledExecutor吗?如果是,确认所有定时任务的总执行时间不会超过最短间隔。 - □ 使用了
scheduleAtFixedRate还是scheduleWithFixedDelay?如果任务执行时间波动大,优先用 fixedDelay。 - □ 定时任务的
run()方法体是否有 try-catch 包裹?未捕获异常会静默取消整个定时任务。 - □ 多个定时任务是否共用一个调度器?如果它们的执行周期不同,考虑分开用不同的调度器实例。
- □ 是否监控了
executor.getCompletedTaskCount()和executor.getQueue().size()?如果完成数不再增长、队列不为空,说明有任务卡住了。
"定时任务没执行"排查时的第一反应不应该是"定时器坏了"——而是"任务执行时间超过了间隔,或者抛了一个没人知道的异常"。
下篇我们聊 Executors 创建线程池的陷阱——无界队列引发 OOM。从定时任务到固定线程池,Executors 工具类的每个工厂方法都有软肋。
🔗 个人博客:https://opencao.cn 📺 公众号:Ai拆代码的曹操 🌟 知识星球:Ai拆代码的曹操


