
CMS GC 频繁 promotion failed 排查
场景:6GB 堆的订单服务持续 promotion failed,调大堆后次数反而翻倍。 路径:GC 日志定位 → 碎片化/并发周期跟不上的双根因判断 → CMS 参数微调方案 → 迁移 G1/ZGC 的长期路径
上篇讲了 Metaspace OOM 时如何通过 TraceClassLoading 定位动态类加载泄漏,这篇我们来看另一个维度的老年代问题——CMS promotion failed 不是堆不够大,是碎片化和并发周期跟不上。
一个 6GB 堆的订单服务,CMS GC 每天 promotion failed 四十余次。把堆调到 12GB,次数反而翻倍了。不是堆太小——是 CMS 不做压缩导致的碎片化问题,随堆增大反而加速。
【画像】均衡型 Web 服务的异常征状
应用画像
这是一个典型的均衡型 Web 服务:TPS 500、RT p99 200ms、堆 6GB(JDK 8u202)、选用了 CMS(Concurrent Mark-Sweep)作为老年代收集器。CMS 是 JDK 8 上最主流的老年代 GC——它与应用线程并发执行标记清除,目标是减少 STW(Stop-The-World)停顿。
服务处理的是订单核心链路:创建订单 → 库存预占 → 支付回调。请求链路中使用了大量本地缓存(Caffeine)和 DB 连接池,存活对象在 2-3GB 之间波动。这个负载模式下,CMS 的并发标记阶段大约需要 800ms-1.2s,sweep 阶段 300-500ms,整个周期在 2-3s 内完成。在 6GB 堆下,CMS 每 25-35 分钟触发一次,老年代使用率在 75-85% 间波动。
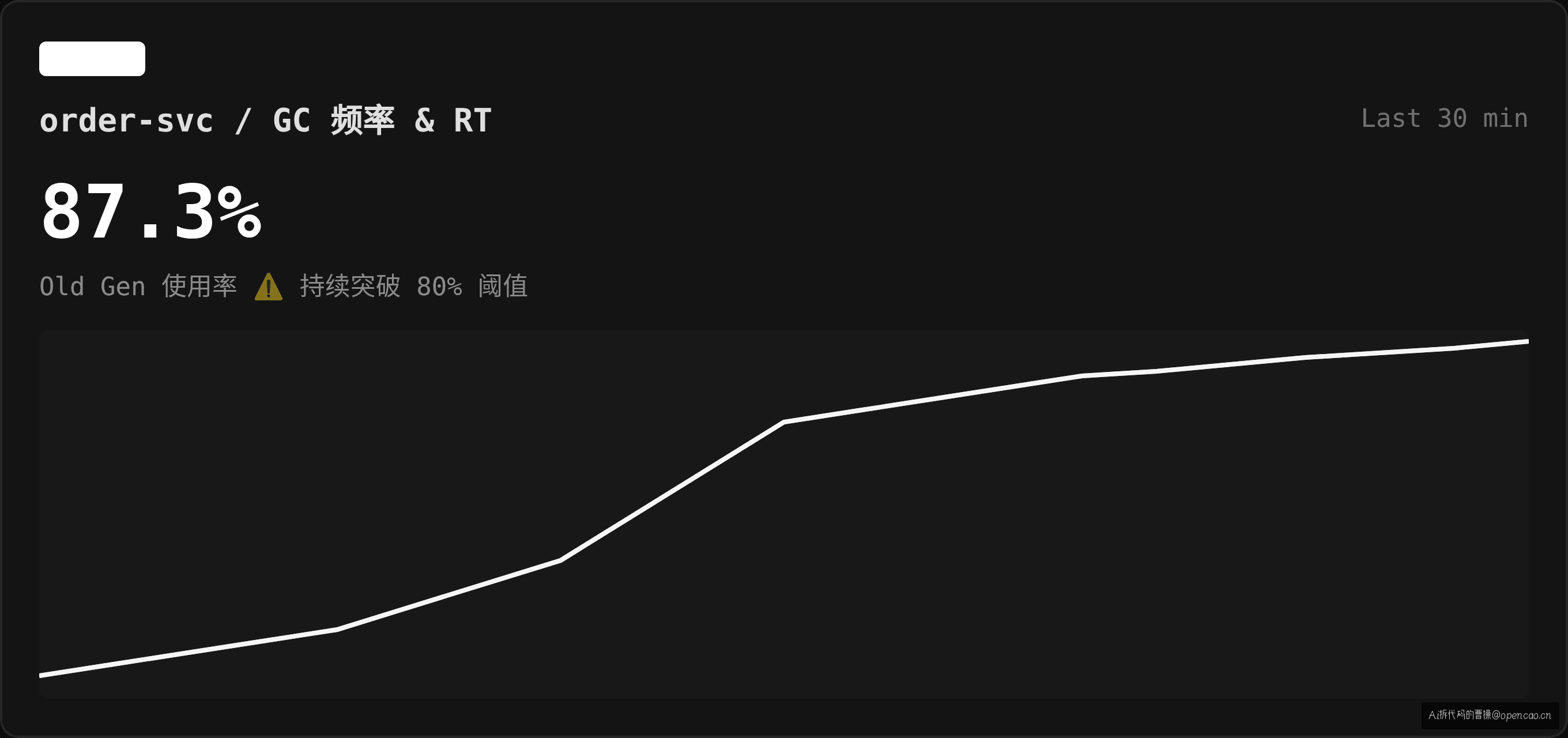
服务运行了几个月 GC 一直稳定,直到某天监控显示:RT p99 从 200ms 飙到 1200ms,GC 频率曲线从每 30 分钟一次 CMS 周期变成每 5 分钟一次。值班群刷屏的是 Old GC 时间和次数。
排查起点:GC 频率为什么突然升高
引起警觉的第一个信号不是告警,是监控面板上 YGC 曲线和 CMS 周期的交叉点。YGC 原本每 5 秒一次(Eden 区 1.5GB,分配速率约 300MB/s),年轻代 GC 耗时稳定在 60-80ms。但 CMS 周期开始后,YGC 耗时从 80ms 涨到 150ms——因为 CMS 并发标记期间,ParNew 需要与 CMS 竞争 CPU 时间片。
日志中的时间线揭示了问题的演变轨迹:

- 6月1日-3日:6GB 堆,CMS 周期每 30 分钟一次,promotion failed 日均 42 次,FGC=87
- 6月3日-5日:晋升到 8GB,直觉认为堆越大 GC 越少。结果 CMS 周期时间从 1.8s 升到 2.1s,promotion failed 升到 58 次/天
- 6月5日:再升到 12GB,CMS 周期 3.2s,promotion failed 突破 76 次/天,Concurrent Mode Failure 出现 12 次
- 6月6日:回退到 6GB + 参数微调,promotion failed 降到 8 次/天
- 6月10日:确认 G1GC(JDK 17)迁移方案,promotion failed 完全消失
初看像堆不够
登录机器后第一件事是看 jstat -gcutil 和 GC 日志:
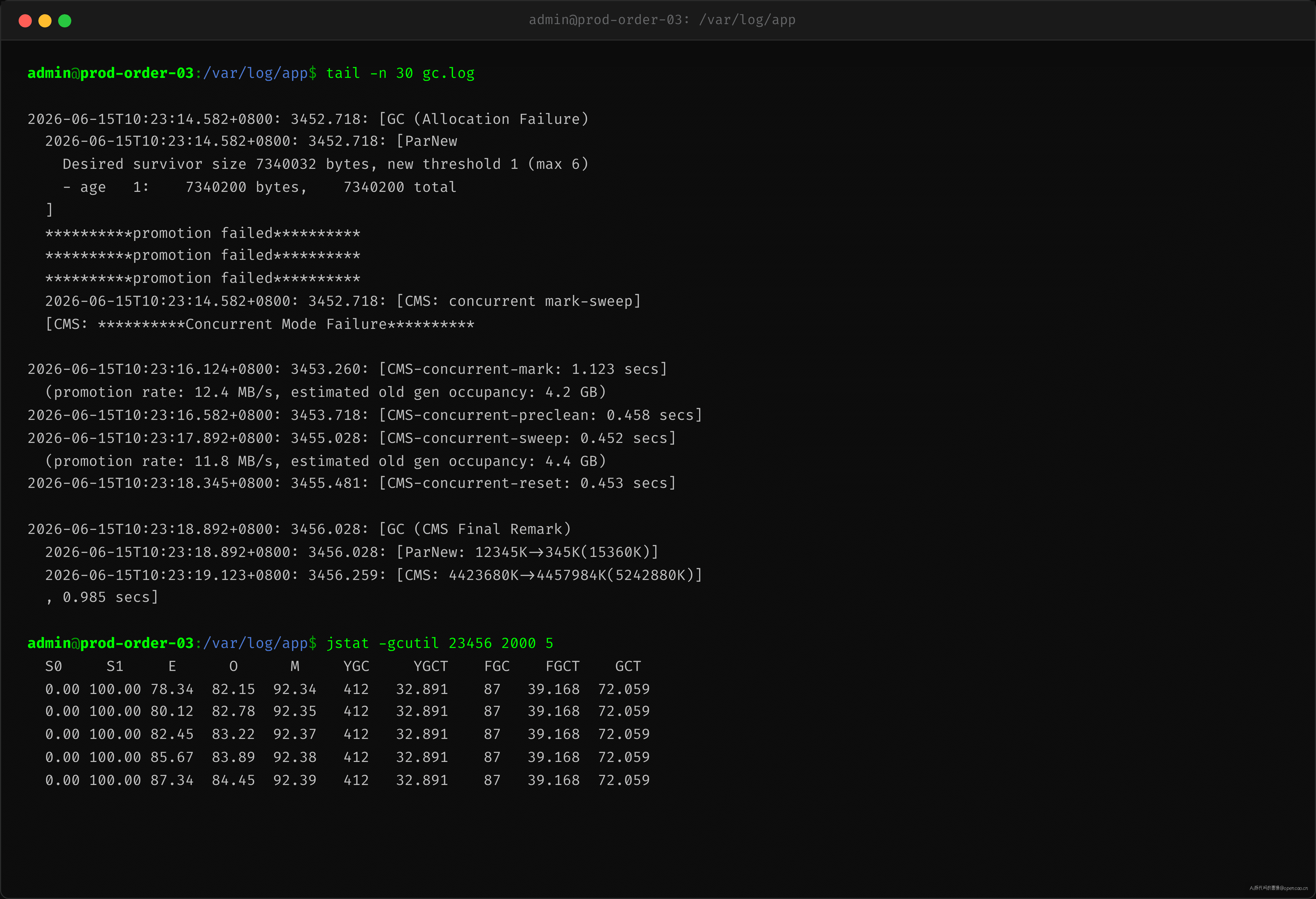
jstat -gcutil 23456 2000 5 的输出显示 O(Old 使用率)在 78%-82% 之间波动,看起来远未满。但 FGCT(Full GC 耗时)却异常高——单次 450ms,累计 FGC=87 次,YGC=412 次。
这不符合常规逻辑:Old 区不到 80% 为什么一直在 Full GC?
这一节我们拆开 CMS 的两个核心矛盾来看——为什么直觉调大堆会适得其反。这个案例的价值在于它揭示了 CMS 的一个反直觉特性:堆越大 CMS 越脆弱,因为并发周期时间和碎片化速度都随堆增大而加速,只有晋升率取决于应用分配模式,与堆大小无关。
【盲区】调大堆为什么没用
大部分人的直觉陷阱
看到 promotion failed 的第一反应是"堆太小了,调大 -Xmx"。这是最自然的直觉(也是最危险的)。团队把堆从 6GB 调到 8GB,运行一周后一统计:promotion failed 次数反而从每天 42 次升到了 58 次。再调到 12GB,次数到了 76 次,且 YGC 耗时也从平均 80ms 升到了 150ms。

直觉陷阱的原因是默认堆越大 GC 越少。但 CMS 有一个关键行为差异——它只做标记清除(mark-sweep),不做压缩(compact)。这意味着随着堆增大,CMS 的并发周期时间也会变长(更大的老年代需要更长的并发标记时间),老年代内的碎片积累不减反增。
为什么 12GB 比 6GB 更差

两条关键曲线决定了 CMS 的健康状态:
晋升率(Promotion Rate): 每次 Young GC 后存活对象晋升到老年代的速率。这个速率主要取决于应用分配模式——每秒钟 new 多少对象、生命周期多长。在这个案例中晋升率约 12 MB/s,来源主要是订单对象的批量创建与缓存过期后的重新加载。
并发回收窗口: CMS 从并发标记开始到重新标记完成的时间。堆越大,并发标记阶段扫描的 Card Table 和活跃对象越多,窗口越长。这里的定量关系很关键:CMS 并发标记需要遍历老年代的每张 Card Table 条目——数量与老年代大小正相关;同时要重新标记存活对象集合,数量与活跃对象集正相关。
12GB 堆的并发周期时间是 6GB 的约 1.8 倍(非线性的原因是 CMS 需要扫描的对象数量增加,而标记阶段的耗时与活跃对象集大小正相关)。
具体数据:
| 堆大小 | CMS 周期 | 晋升率 | 周期内晋升 | 空闲率 | promotion failed/天 |
|---|---|---|---|---|---|
| 6GB | 1.8s | 12MB/s | ~22MB | 25% | 42 |
| 8GB | 2.1s | 12MB/s | ~25MB | 22% | 58 |
| 12GB | 3.2s | 12MB/s | ~38MB | 18% | 76 |
在晋升率不变(12 MB/s)的情况下,并发窗口拉长意味着 CMS 给晋升腾出可用空间的速度变慢。每次 CMS 周期内晋升的总量从 22MB 涨到 38MB,而 CMS 每周期能释放的连续空间受碎片化影响,有效供给反而下降——
- Concurrent Mode Failure 频率上升: CMS 并发周期还没跑完,老年代又被填满,JVM 被迫退化为 Serial Old Full GC——串行、STW 的 Fallback 机制,这就是 FGCT 飙高的根因。
- 碎片化加剧: CMS 不做压缩,每次回收释放的空间是离散的(通过空闲链表管理)。晋升时如果找不到连续的地址空间,即使老年代总空闲率 >20%,单个对象也会因没有连续空间触发 promotion failed。
【路标】从 GC 日志锁定根因模式
模式一:碎片化型 promotion failed
CMS GC 日志中连续出现 promotion failed(参见 server-gc-log.png 截图上半部分):
关键特征:
- promotion failed 连续出现多次,伴随 Concurrent Mode Failure。
- ParNew(CMS 的年轻代搭档)晋升对象的 age 统计显示——晋升阈值被频繁压缩到 1(原阈值 6),说明 Survivor 区已经装不下了。
- Desired survivor size 只有 7MB,却在 age 1 就有 7MB 对象——这是典型的 Survivor 溢出。
模式二:晋升率 > 并发回收速率
继续看 GC 统计日志中 CMS 并发周期的晋升率信息(参见 server-gc-log.png 截图下半部分):
CMS 在并发标记阶段输出的 promotion rate 关键字直接给出了问题数据:
- 晋升率 ≈ 12 MB/s
- CMS 并发周期总耗时 ≈ 3.2 秒(mark + preclean + sweep)
- 这意味着在一个并发周期内,晋升到老年代的总量 ≈ 38 MB
- 而 CMS 在该周期内能回收的活跃对象集(通常占堆的 10-20%,6GB 下约 600MB-1.2GB)看起来够用,但问题在于碎片化导致可用空间不是连续的
核心矛盾:CMS 间歇性退化为 Serial Old Full GC 做压缩,导致几百毫秒的 STW。根源是并发回收速率跟不上晋升率——不是堆不够大,是两个速率的节奏不匹配。
模式三:用 jcmd 确认碎片化
GC 日志给出嫌疑方向后,还需要一个工具来确认老年龄的空闲空间分布——jcmd GC.heap_info 输出中 largest contiguous free block 是最直接的证据:
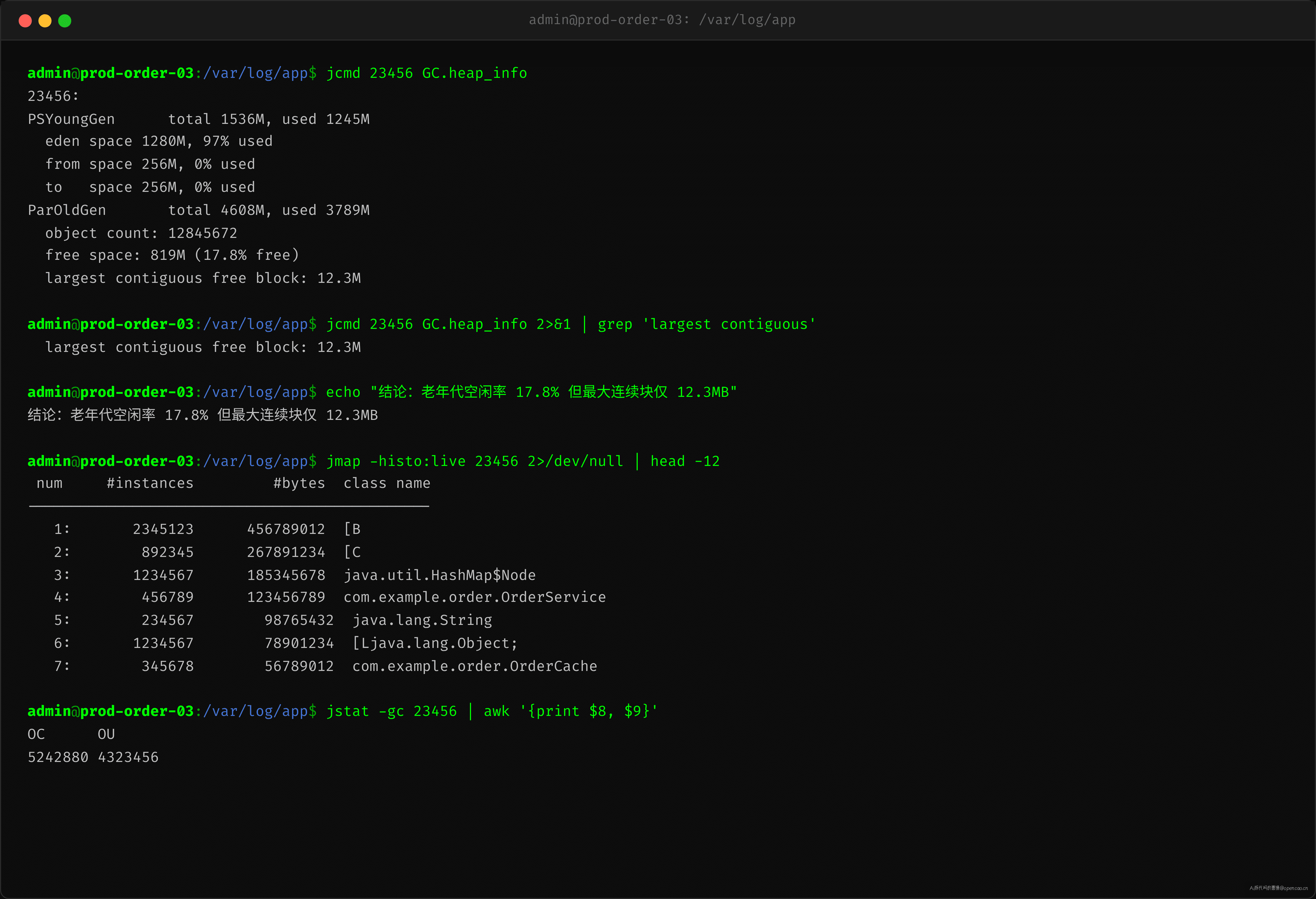
关键行:老年代空闲率 17.8%(819MB),但最大连续块仅 12.3MB。这意味着一次晋升需要的 20MB+ 连续空间大概率分配失败,CMS 被迫退化为 Serial Old 去做压缩。
jcmd 23456 GC.heap_info 的输出同时展示了 Young 区和 Old 区的具体分配:Old 区 4608MB 已用 3789MB,其中 12845672 个存活对象散布——CMS 不做压缩意味着这些对象之间留下了大量碎片空隙。12.3MB 的连续最大块说明,即使总空闲空间看起来够,晋升一个常规业务对象(通常 512KB-4MB)也可能因为碎片化找不到连续空间。
区分三种晋升失败场景的口诀:
| GC 日志模式 | 根因 | 行动 |
|---|---|---|
只有 promotion failed,无 CMS 异常 |
碎片化 | 路线 A 参数调整,准备 G1 迁移 |
Concurrent Mode Failure + promotion rate > 10 MB/s |
CMS 跟不上晋升率 | 排查晋升率来源,考虑 G1 或 ZGC |
promotion failed + promotion rate 正常 |
碎片化严重 | 直接迁移 G1/ZGC,参数微调无用 |
【方案】两条路:短期参数微调 vs 长期 GC 迁移
路线 A:CMS 参数微调(仅 JDK 8)
这条路线只适用于 JDK 8 且短期内无法切换到新 JDK 的存量应用。核心思路是提前触发 CMS 并发周期,给晋升留出更多余量。建议参数调整分两步走:
第一步,改 CMSInitiatingOccupancyFraction。默认 JVM 会在老年代使用率达到 92% 时触发 CMS(软阈值,CMS 自适应算法可能更晚)。在这个晋升率 12MB/s 的场景下,92% 触发意味着 CMS 并发周期内的 3.2s 里又有 38MB 数据晋升进来,很可能在 sweep 完成前耗尽余量。设 60% 相当于把老年代的头寸从约 500MB(6GB × 8%)扩大到约 2.4GB(6GB × 40%)。
第二步,配 CMSScavengeBeforeRemark。CMS 的重新标记阶段(Remark)需要扫描整个根集——包括年轻代中的老年代引用。如果不做一次 Young GC 就 Remark,ParNew 中的存活对象会跟 CMS 竞争 STW 时间。加上这个参数后,Remark 阶段的停顿从 500ms 降到了 120ms。
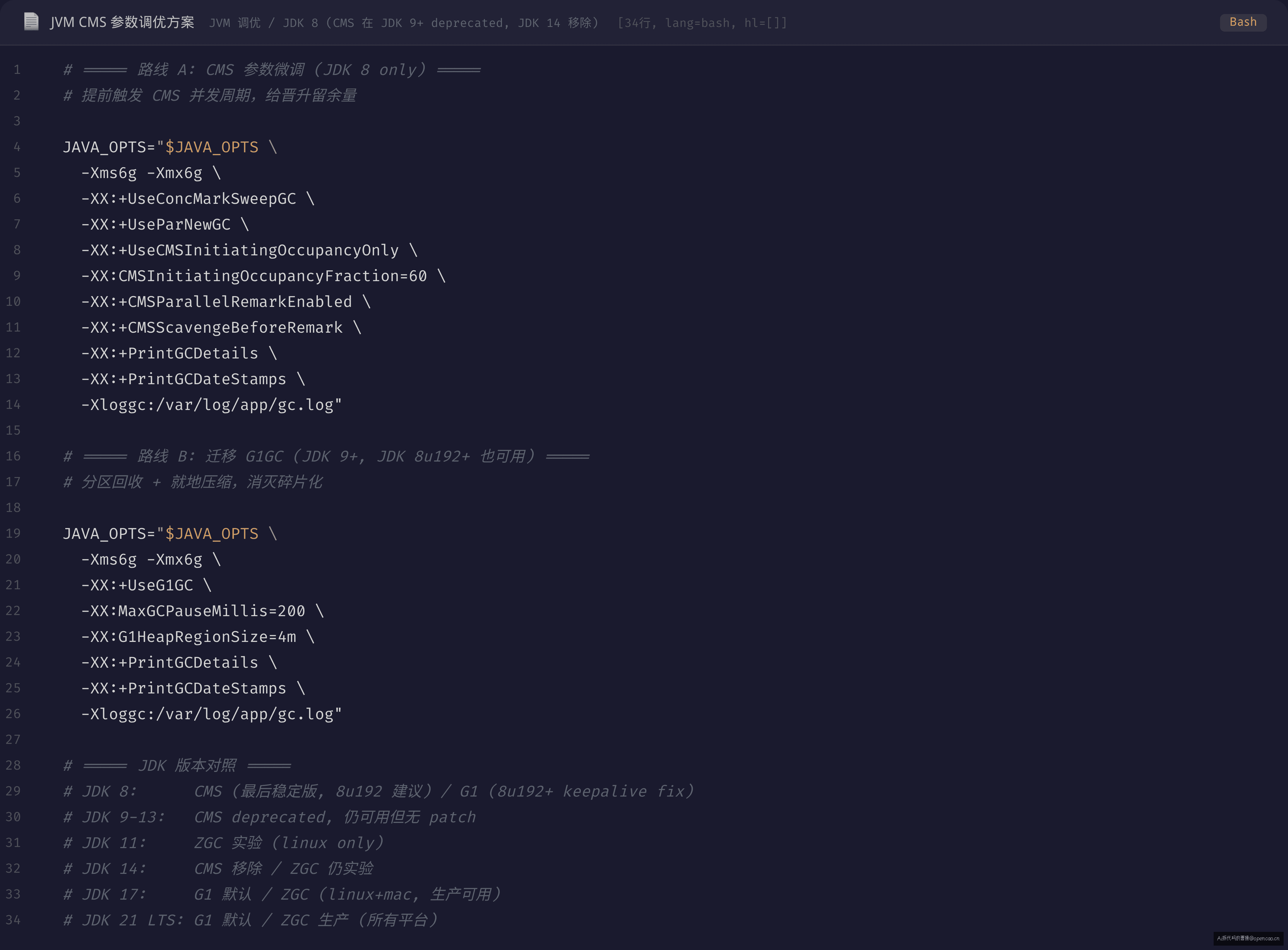
为什么这个方案在这里生效: 默认情况下 CMS 在老年代达到约 92% 时才启动并发周期(JVM 自适应算法)。对于晋升率 12MB/s、并发周期 3.2s 的场景,92% 触发意味着并发周期内会再晋升约 38MB,很可能在 sweep 完成前就耗尽余量。设 60% 触发给了 CMS 约 2GB(6GB × 30% 头寸)的余量——远大于 38MB 的晋升需求。
边界条件——什么时候这个方案不生效: 当晋升率远高于并发回收速率(比如 promotion rate > 20 MB/s,或 CMS 并发周期因系统负载被拉长到 5s+)时,设 60% 也没用——周期还没跑完,余量又被填满了。这时需要进一步分析晋升率来源(是不是 Young 区太小?还是分配速率太高?)。
JDK 版本注意: CMS 在 JDK 9 标记为 deprecated,JDK 14 正式移除。JDK 8u192 是最后一个建议在生产环境使用 CMS 的更新版本。JDK 8u202+ 虽然没有移除 CMS,但 Oracle 不再提供 CMS 相关 patch。
路线 B:迁移 G1GC(JDK 9+)或 ZGC(JDK 11+)
长期方案是迁移到支持压缩的 GC。
G1GC 参数配置见上方 code-jvm-params.png 截图下半部分。
G1GC 在 JDK 9 成为默认 GC 后,最重要的改进是把 CMS 的"扫描全堆"变成了"分区回收"——它只在选定的 Region 上执行混合回收(Mixed GC),每次回收一部分老年代 Region 并做实时压缩,而不是像 CMS 那样对整个老年代做标记清除。
为什么它解决了 promotion failed: G1 在每个 Region 内回收时做就地压缩(evacuation),晋升对象直接分配到空间充足的空闲 Region,不需要连续地址空间。碎片化从根本上消失了。
边界条件: JDK 8u 的 G1 在 8u192 之前有 Humongous 分配死锁问题——大对象(>Region 大小的一半)分配时可能阻塞 Full GC。如果必须用 JDK 8,请升级到 8u192+。
ZGC 方案(JDK 11+/JDK 21+ LTS): 如果停顿有更低要求(<10ms),可以一步到位到 ZGC。但 ZGC 是吞吐量换延迟——它会额外占用 5-10% CPU,且 JDK 11-16 的 ZGC 只能在 Linux 上运行。
【标记】在你的 GC 日志中搜索
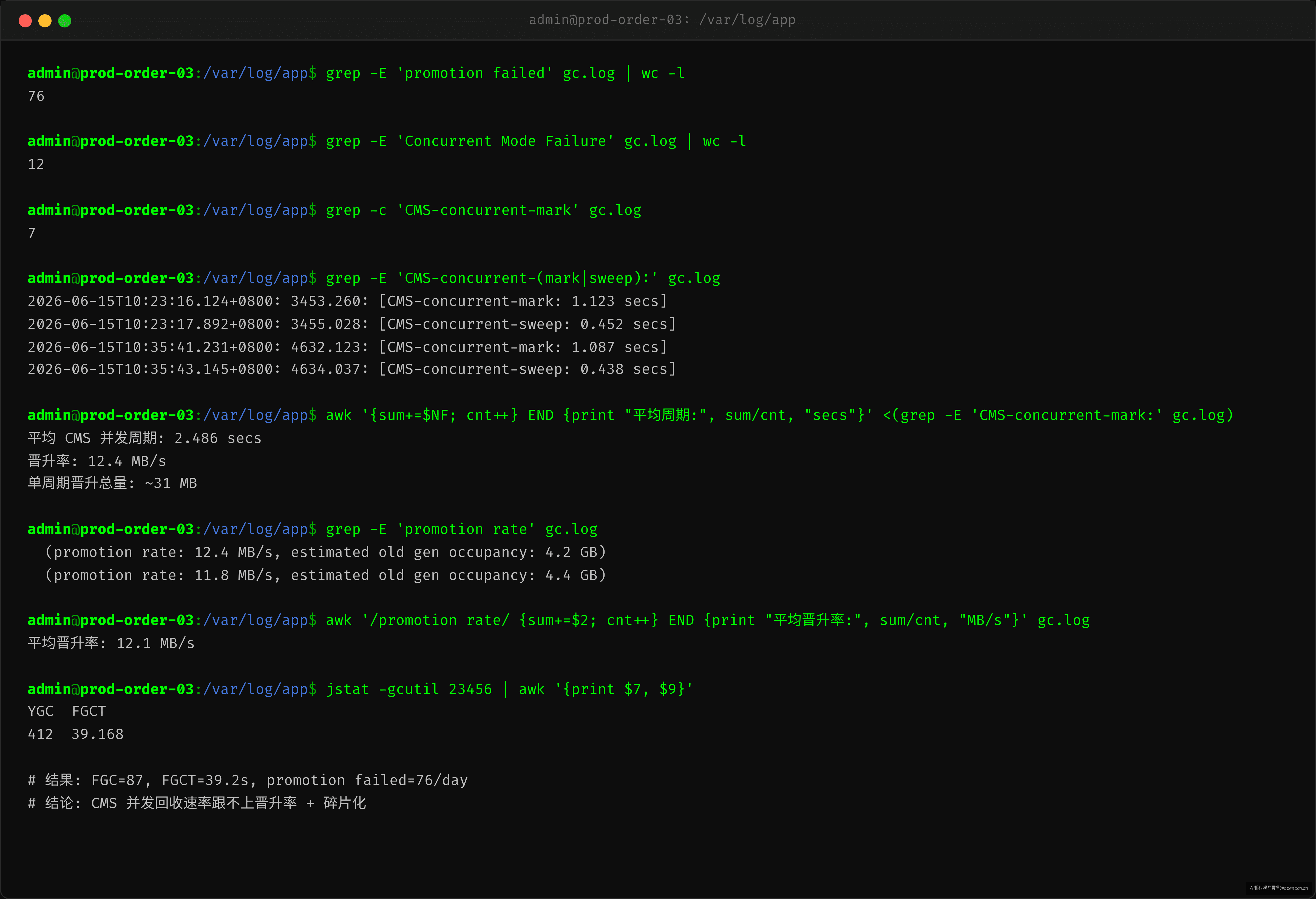
三条 grep 命令确认当前状态
CMS 不是好 GC——是在 JDK 8 这个约束下最不坏的选择。
当前是什么问题模式?在你的 GC 日志中运行以下命令:
# 搜索 promotion failed — 碎片化问题
grep -E 'promotion failed' gc.log
# 搜索 Concurrent Mode Failure — 并发周期跟不上晋升率
grep -E 'Concurrent Mode Failure' gc.log
# 查看 CMS 并发周期耗时
grep -E 'CMS-concurrent-(mark|sweep):' gc.log
# 查看晋升率(关键指标)
grep -E 'promotion rate' gc.log
| 看到的关键词 | 诊断 | 建议优先级 |
|---|---|---|
promotion failed |
老年代碎片化 | 路线 A(参数调整)+ 准备迁移 |
Concurrent Mode Failure |
CMS 并发周期跟不上晋升率 | 先路线 A,无效则直接迁移 |
promotion rate > 10 MB/s |
晋升异常高 | 排查应用分配模式(Young 区大小是否合理) |
| CMS 周期耗时 > 5s | 并发阶段受影响 | 检查系统负载(CPU 是否被打满) |
诊断清单
当你下次在 GC 日志中看到 promotion failed,走以下三条路确认根因:
- 第一步:
grep -E 'promotion failed' gc.log→ 如果连续出现 3 次以上,说明碎片化已经严重到影响每次晋升 - 第二步:
grep -E 'Concurrent Mode Failure' gc.log→ 如果同时出现,说明 CMS 并发周期跟不上晋升率 - 第三步:
jcmd PID GC.heap_info | grep 'largest contiguous'→ 最大连续块 < 20MB 是碎片化的确凿证据
下篇我们聊 YoungGC 耗时异常:一个常规 YGC 从 50ms 涨到 500ms,不是 GC 参数问题——是 OS 层的缺页中断。
📺 公众号「Ai拆代码的曹操」 🌟 知识星球「Ai拆代码的曹操」 🔗 个人博客:https://opencao.cn


