
一行代码导致 RocketMQ 大量消息发送失败
场景:订单服务灰度上线,消息发送成功率骤降 0%,Broker 端一切正常 路径:应用日志 → 端口特征 → 网络排查 → 源码追查
本文所有日志时间已统一到 UTC+8
上篇我们分析了 RocketMQ Broker 高负载下的 SYSTEM_BUSY 根因——磁盘 IO 打满导致发送队列排队超时。这次遇到的案例走向了另一个极端:所有指标都正常。
订单服务上线了一个新版本。5 分钟后,用户反馈"下单后收不到物流通知"——不是慢,是完全收不到。查监控:消息发送成功率 0%。第一时间查 Broker——CPU 35%、磁盘 util 12%、网络延迟 1ms,一切指标都在绿色区间。但下游系统坚称:没有收到任何订单状态变更。
【现象】业务异常
应用日志:全是 connect refused
值班 SRE 第一时间查看应用日志:
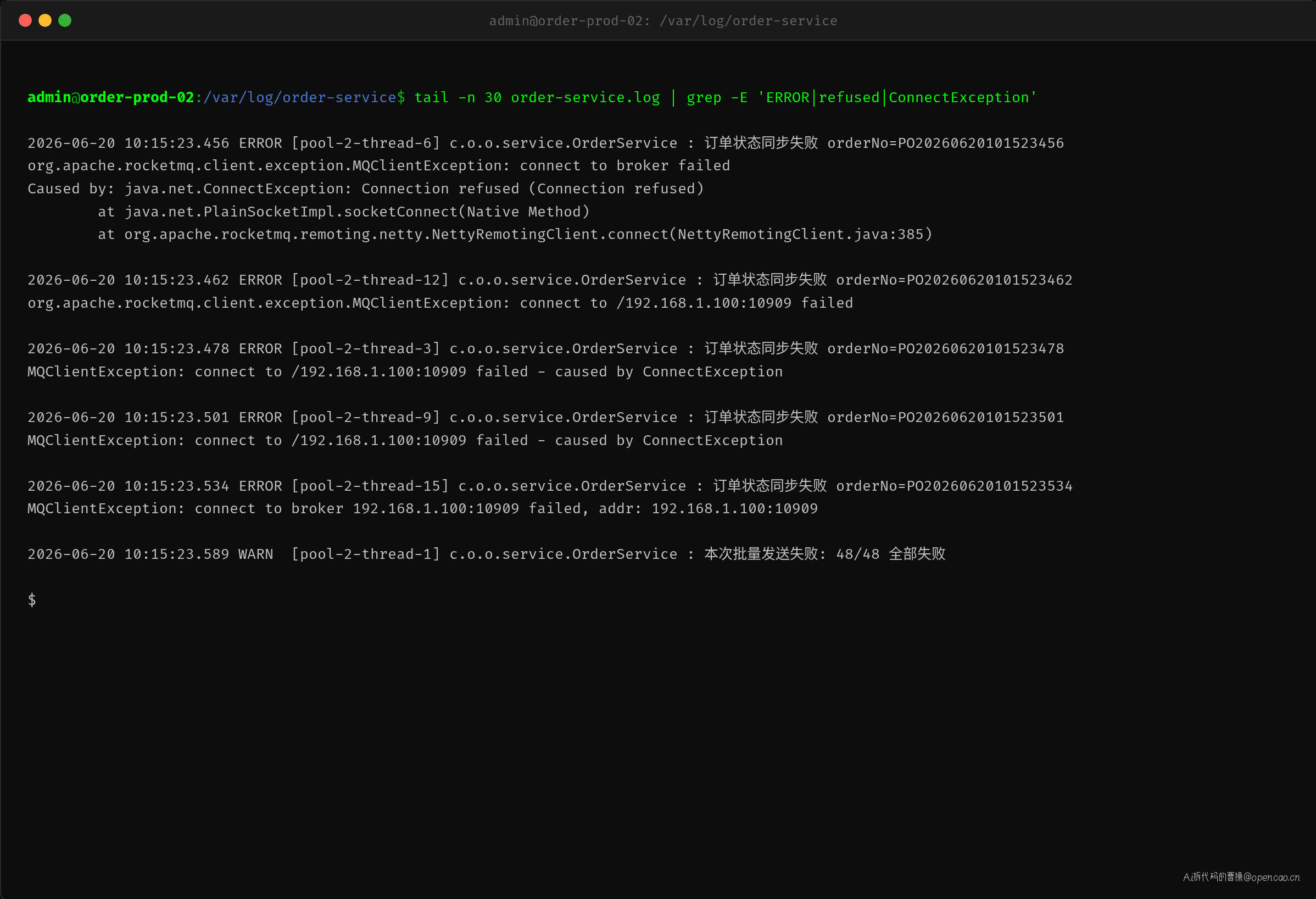
日志特征非常一致——每一条都是 connect to /192.168.1.100:10909 failed。注意这里的端口是 10909,不是 RocketMQ 默认的 10911。
错误类型是 connect refused——TCP 连接被主动拒绝。这跟上一篇的 SYSTEM_BUSY 完全不同:上一篇是请求在队列里排队超时后被 BrokerFastFailure 清理掉,Broker 还在处理但处理不过来;这次是连接都没建立起来。
业务影响:订单状态无法同步到下游的物流、积分、推送系统。支付链路虽然正常(交易已落库),但后续的业务闭环全部断联。
告警群:第一反应都是"MQ 挂了"
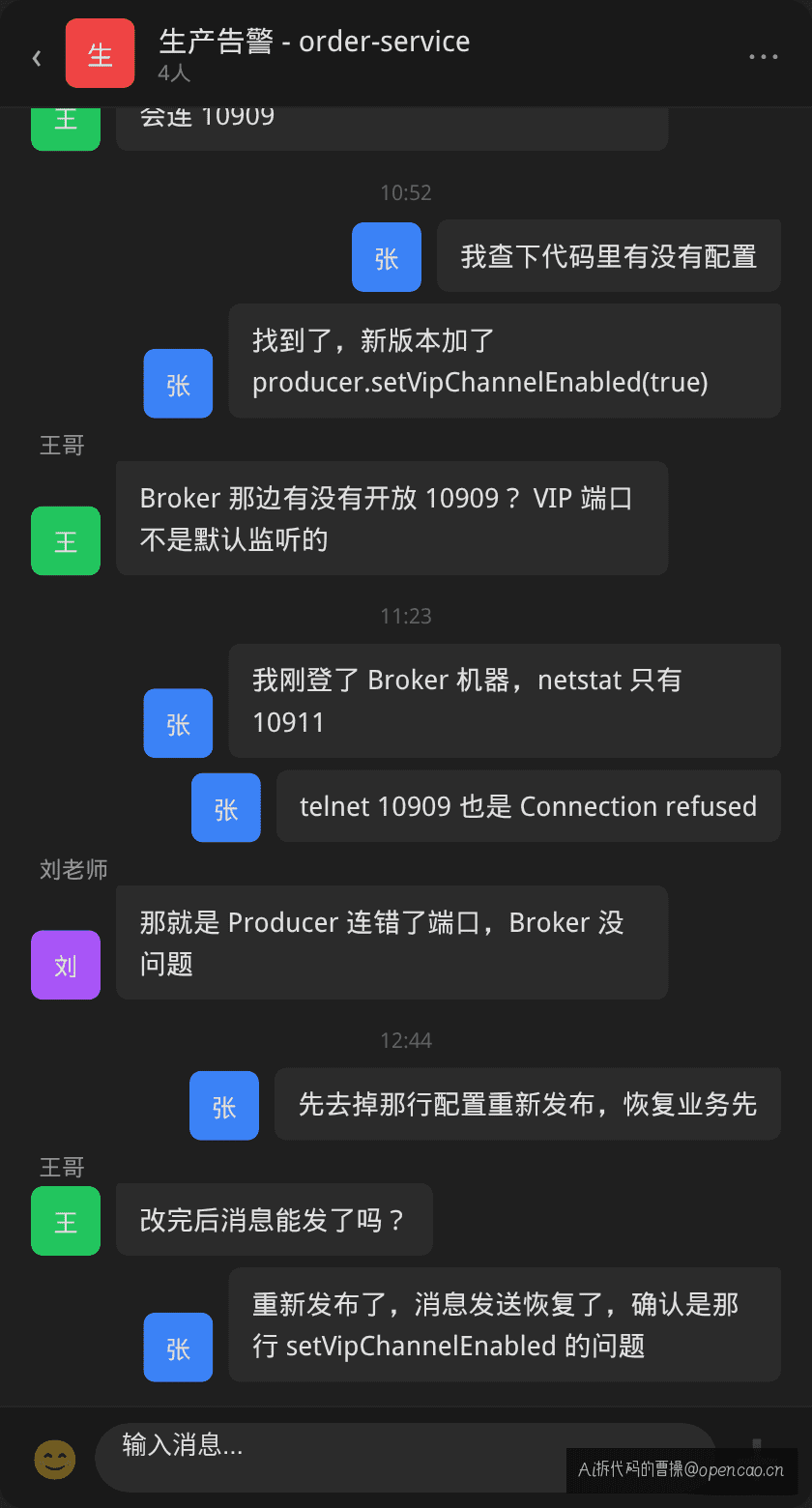
群里第一反应是"RocketMQ 挂了"。但这是典型的"中间件故障"直觉——出了问题先怀疑中间件。这次的事实恰恰相反:Broker 端没有任何异常。
【联查】调用链追查
第一步:Broker 端确认
Broker 机器 netstat -tlnp 只看到 10911 在监听,没有 10909。日志无 SYSTEM_BUSY、无 reject、无 FullGC。iostat -x 磁盘 util 12%,毫无压力。
Broker 端没有问题。问题在客户端连接的目标端口上。
拉一下两个端口的连通性就知道了——30 秒排除网络层:
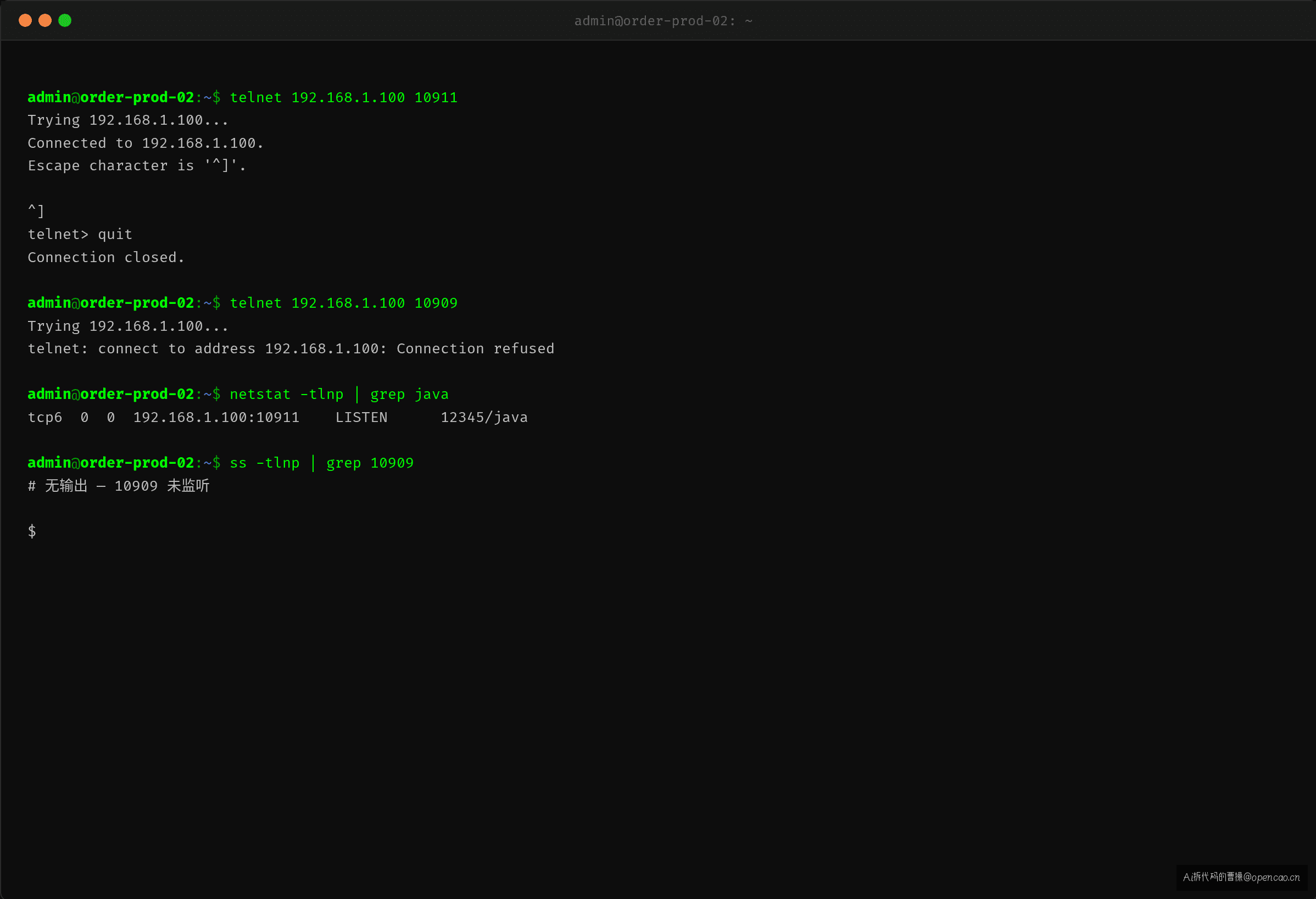
结论:10909 不通不是因为防火墙或网络—— refused 说明目标主机收到了连接请求但主动拒绝,因为没有进程在监听这个端口。
这里有一个排查中间件问题必知的基础网络信号:
10911(端口开放): SYN ──→ SYN-ACK ──→ ACK ✅ 三次握手完成
10909(端口未监听): SYN ──→ RST ❌ 连接被拒绝
防火墙拦截: SYN ──→ ⏳ timeout ❌ 无任何响应
connect refused 是最快排除防火墙的信号——RST 包说明请求已经到达目标主机,是主机上的应用程序主动拒绝了你。如果是防火墙拦截,你根本收不到任何响应,只能等 timeout 超时。很多人在这个地方绕弯路——看到 refused 还在查防火墙规则,其实是白费功夫。
第二步:谁决定 Producer 连哪个端口?
生产者在发送消息前从 NameServer 拉取主题路由信息。路由信息中的 Broker 地址包含两个字段:
| 地址字段 | 默认值 | 说明 |
|---|---|---|
brokerAddr |
ip:10911 |
普通消息收发端口 |
brokerAddrVip |
ip:10909(= 10911 - 2) |
VIP 通道端口 |
Producer 用哪个地址取决于一个配置项—— vipChannelEnabled。当它为 true 时,Producer 优先连接 VIP 地址。
【路径】🔍 排查路径
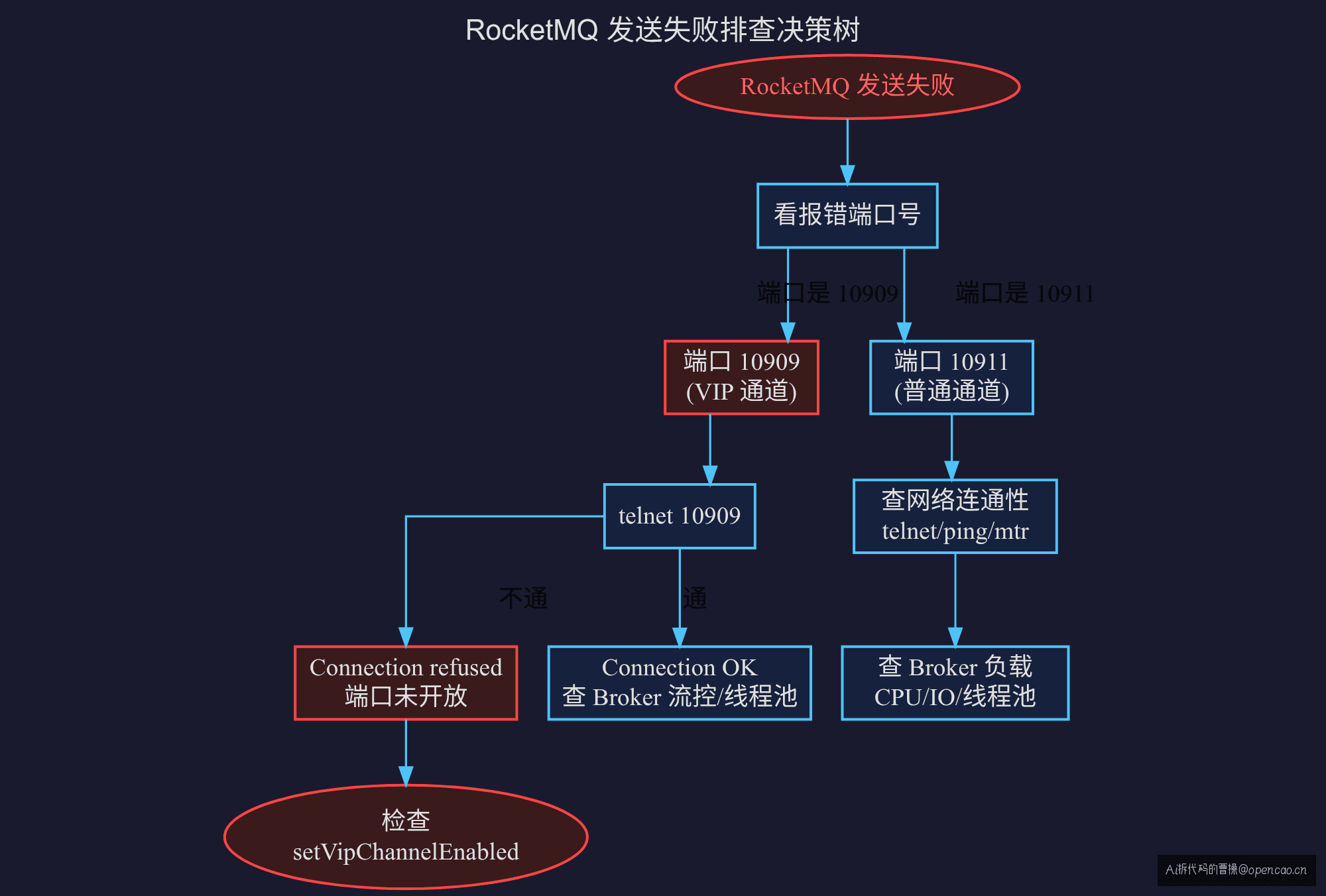
排查决策树
RocketMQ 发送失败
├── 看报错端口
│ ├── 10909(VIP 端口)
│ │ ├── telnet 不通 → 检查 vipChannelEnabled 配置
│ │ └── telnet 通 → 查 Broker 线程池/流控
│ └── 10911(普通端口)→ 常规排查
└── 确认网络层后再查中间件层
核心原则
telnet 两个端口花了 30 秒。如果没看端口直接上 Broker 查配置,两个小时都不一定能定位到原因。
排查中间件问题,第一步永远不是查中间件配置——是看应用日志报错的是什么端口。10909 出现,一定是 vipChannelEnabled 的问题,不需要怀疑防火墙、不需要怀疑 Broker 负载、不需要怀疑网络。
停一下,去你的项目里搜搜
现在搜一下你的代码仓库——grep -r "setVipChannelEnabled" src/。大概率你搜不到,这很好。
但如果你搜到了——而你不确认 Broker 有没有开 VIP 端口——那你离一个线上事故就差一次上线。
这不是段子。我让三个团队的同事去搜了,两个团队的 RocketMQ Client 版本里,这个配置的默认值跟部署拓扑不匹配。他们上线时没出问题,纯粹是因为"没人改过默认值",不是因为"配置是对的"。
【收敛】根因定位
Layer 1 — 一行代码
问题代码在订单服务新版本的 Producer 初始化中。老版本没有 setVipChannelEnabled(true)。开发者在做代码优化时加上了它,理由是"VIP 代表高优先级,消息走 VIP 通道应该更快"。但他们不知道的是:这个集群的 Broker 没有开放 VIP 端口(listenPort 默认为 10911,VIP 端口不独立配置)。
Layer 2 — 源码解读
// MQClientInstance — findBrokerAddressInSubscribe
if (this.clientConfig.isVipChannelEnabled()) {
String addr = bd.getBrokerAddrVip(); // ← 取 10909
if (addr != null && !addr.isEmpty()) {
return addr;
}
}
return bd.getBrokerAddr(); // 回退到 10911
当 vipChannelEnabled=true 时,Producer 从路由数据中提取 VIP 地址(brokerAddresses 映射中以 1 为键的条目,端口 10909)作为连接目标。如果 Broker 没有监听这个端口——TCP 连接被拒绝,DefaultMQProducer.send() 抛出异常。
这就是"一行代码导致全量发送失败"的完整链条:配置开关 → 地址选择变化 → 端口不可达 → 连接全部失败。
RocketMQ 为什么设计 VIP 通道?Broker 端有一个 BrokerFastFailure 机制,当请求队列积压时会主动拒绝低优先级请求。VIP 通道的设计初衷是让控制台命令、系统级通知等高优先级消息绕过这个流控——通过独立的线程池和端口隔离,确保 Broker 过载时管理指令仍能到达。但它有两个前提:Broker 端需要独立配置 VIP 端口,且业务 Producer 默认不应启用。大多数生产集群并不配置 VIP 端口(默认只开 10911),因此 vipChannelEnabled 的默认值是 false 而非 true——这个默认值的背后假设是:"你明确知道你需要 VIP 通道时,才去开启它"。
Layer 3 — 为什么之前没出问题?
| 版本 | vipChannelEnabled |
连接目标 | 结果 |
|---|---|---|---|
| 旧版本 | 未设置(默认 false) | 10911 ✅ | 正常发送 |
| 新版本 | setVipChannelEnabled(true) |
10909 ❌ | connect refused |
运维团队从未在 Broker 端配置过 VIP 端口——RocketMQ 4.9.x 默认 listenPort=10911,VIP 端口(10909)只在特定配置下才启用。之前的 Producer 用默认值 false,连接正常。新版本"优化"反而打破了平衡。
这里有一个更隐蔽的陷阱:vipChannelEnabled 的默认值在不同版本之间变过。
| RocketMQ Client 版本 | vipChannelEnabled 默认值 |
陷阱 |
|---|---|---|
| 4.7.x | true |
默认就去连 10909,跟旧版 Broker 不兼容 |
| 4.8.0+ | false |
默认值反转,版本升级可能静默改变行为 |
| 5.x | false(通道模型重构) |
已经不再叫 VIP 通道 |
这意味着:不需要有人改代码,一次 RocketMQ Client 的依赖版本升级,就可能把你的 Producer 从连 10909 变成连 10911——或者反过来。 你的配置没变过,但行为变了。
排除其他可能
- 防火墙拦截:防火墙拦截通常表现为
connect timeout(SYN 无响应)而不是connect refused(目标主机主动拒绝) - Broker 连接数满:连接数满时 Broker 日志有记录,实际日志无异常
【标记】📡 告警设置与预防
修复方案
// ✅ 修复:删除或明确设为 false(推荐)
DefaultMQProducer producer = new DefaultMQProducer("order_status_group");
producer.setNamesrvAddr("192.168.1.200:9876");
producer.setVipChannelEnabled(false);
producer.start();
监控告警规则
| 监控项 | 指标 | 阈值 | 级别 |
|---|---|---|---|
| 消息发送失败率 | rocketmq_send_failure_ratio |
> 1% | P0 |
| connect refused 次数 | rocketmq_connect_refused |
> 0 | P0 |
| 连接端口分布 | Producer 连接的 Broker 端口 | 10911(非 10909) | 异常检测 |
配置检查清单
上线新版本 Producer 前检查:
- [ ] diff Producer 配置变更,特别关注
setVipChannelEnabled的新增或修改 - [ ] 确认 Broker 集群端口拓扑:
netstat -tlnp | grep java看监听端口 - [ ] 预发环境 telnet Broker 的 10909 端口,确认是否可通
- [ ] 监控中增加「连接端口」维度,端口变化能及时发现
- [ ] 代码审查规则:
setVipChannelEnabled的修改需架构师审批
金句
10911 是业务端口,10909 是事故端口。 如果你不知道你的 Producer 在连哪个——先查清楚再上线。
下篇我们聊困扰半年的 RocketMQ timeout exception 破解实录——SendResult 返回了 SEND_OK,但业务方坚称消息没到,问题出在哪?
📺 公众号「Ai拆代码的曹操」 🌟 知识星球「Ai拆代码的曹操」


