
RocketMQ 消息堆积了怎么办?从消费者源码到 OS 层排查
场景:业务端到端耗时从 200ms 涨到 5s,消息堆积 50 万条。业务方怀疑生产者慢,链路追踪发现消费端才是根因——20 个消费者线程全部卡在同步 DB 写入上,形成 rebalance 死亡螺旋 路径:消费 lag 监控 → 消费者线程池 → 消费者源码 → 业务代码 → 修复方案
上篇讲了 10909 VIP 端口阻塞导致 RocketMQ 消息发送端大量超时,这次我们来看消费端最经典的问题——消息堆积。
下单接口耗时从 200ms 涨到 5s,业务方第一反应是数据库慢。DBA 查了一圈——数据库毫无压力。
看生产端监控,send OK 但 ack 耗时在涨。查 Broker 请求队列——PUT 请求在排队。看消费端——堆积了 50 万条消息,20 个消费者线程全部繁忙。
以后你看到接口变慢、数据库正常时: 先看调用链找到下游组件,再看这个组件的核心指标。
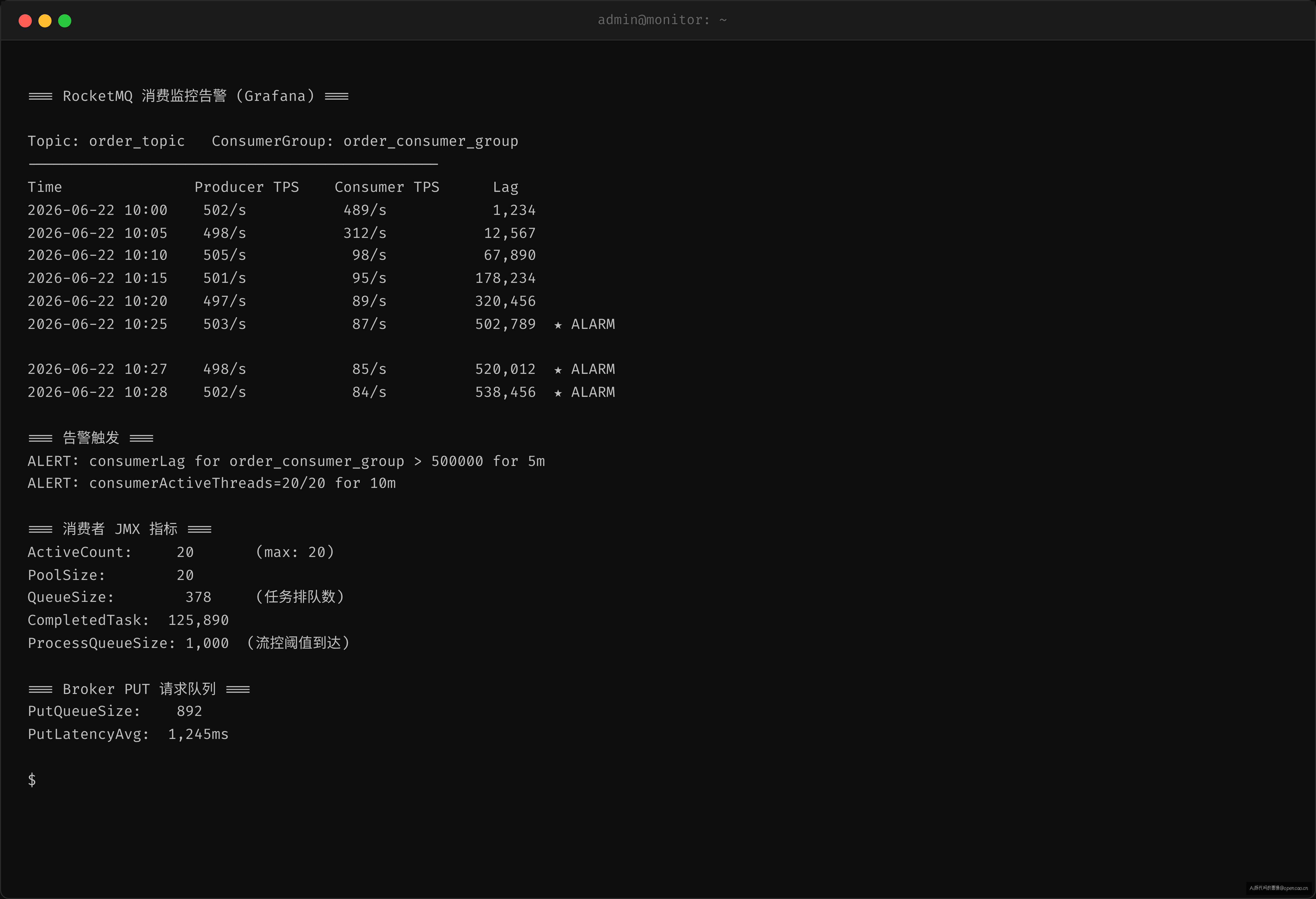
如果消费 lag 在涨——问题 90% 在消费端,不是生产端。
【现象】业务超时 + 50 万堆积
业务表现
"MQ 消费端负责人:你的 topic 堆积了 50 万。" "业务方:不是生产端的问题吧?"
这两句对话在中间件 team 很常见。消息堆积出现时,业务方天然先怀疑生产端——"我发不出去怎么能叫堆积呢?"
但监控数据给出了完全相反的画面: - 生产端 TPS 稳定在 500/s,send 成功率 99.99% - 消费端 lag(消费延迟——消费者当前位置与最新消息的距离,单位是消息条数)持续增长,从 0 到 50 万用了不到 2 小时
消息的"生产-消费"有两个独立路径。生产端正常不代表消费端没问题。
网络层排除
不先排网络就调配置是中间件排查的"七宗罪"之首。
# 测试 Broker 连通性
$ telnet 10.0.0.1 10911
Trying 10.0.0.1...
Connected to 10.0.0.1.
Escape character is '^]'.
# 测网络延迟和丢包
$ ping -c 10 10.0.0.1
rtt min/avg/max/mdev = 0.321/0.456/0.623/0.089 ms
0% packet loss
网络延迟 0.5ms,无丢包,连通性正常。
消费线程池全满
# 查看消费者线程池状态(JMX)
$ jmxterm -l localhost:18926
$ bean -d org.apache.rocketmq -n org.apache.rocketmq.client.internal.thread.pool
# 或者通过 jstack
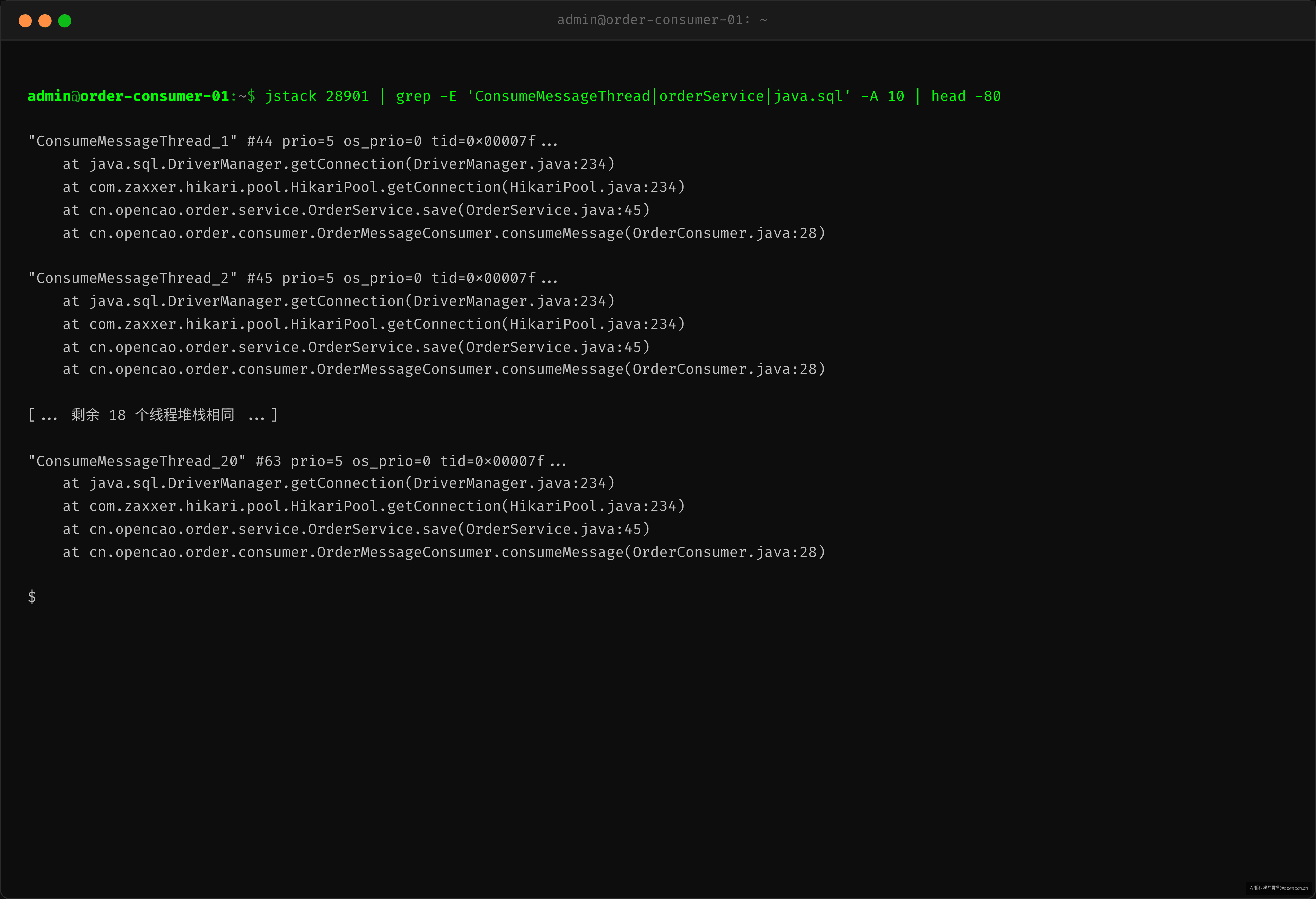
$ jstack <consumer_pid> | grep 'consumeExecutor' -A 5
"ConsumeMessageThread_1" #44 prio=5 os_prio=0 tid=0x00007f...
"ConsumeMessageThread_2" #45 prio=5 os_prio=0 tid=0x00007f...
...
"ConsumeMessageThread_20" #63 prio=5 os_prio=0 tid=0x00007f...
20 个 ConsumeMessageThread_* 全部处于 RUNNABLE 状态,但每个线程都阻塞在同一个堆栈——orderService.save() 的 JDBC 调用。
【联查】生产者 → Broker → 消费者
生产者层:send OK 但 ack 慢
生产者发送正常,但 sendResult 的耗时从正常 <50ms 涨到 1-2s。
这说明 Broker 收到了消息,但处理变慢了——Broker 的处理线程也在排队。
Broker 层:PUT 请求排队
# 查看 Broker 请求队列
$ jmxterm -l localhost:18925
$ get -d org.apache.rocketmq -b org.apache.rocketmq:type=BrokerServerStats
# requestQueueSize
requestQueueSize = 378
Broker 的 PUT 请求排队 378 个。为什么 Broker 处理不过来?不是因为 Broker 慢了,是因为消费端不消费了——Broker 的消费进度不更新,消息无法删除,CommitLog 写入越来越慢。
中间件是链式的,一端卡顿,全链降速。
消费者层:源码看消费线程模型
从监控数据来看,生产端和 Broker 都不是根因,它们是被消费端拖慢的。真正的问题在消费者。
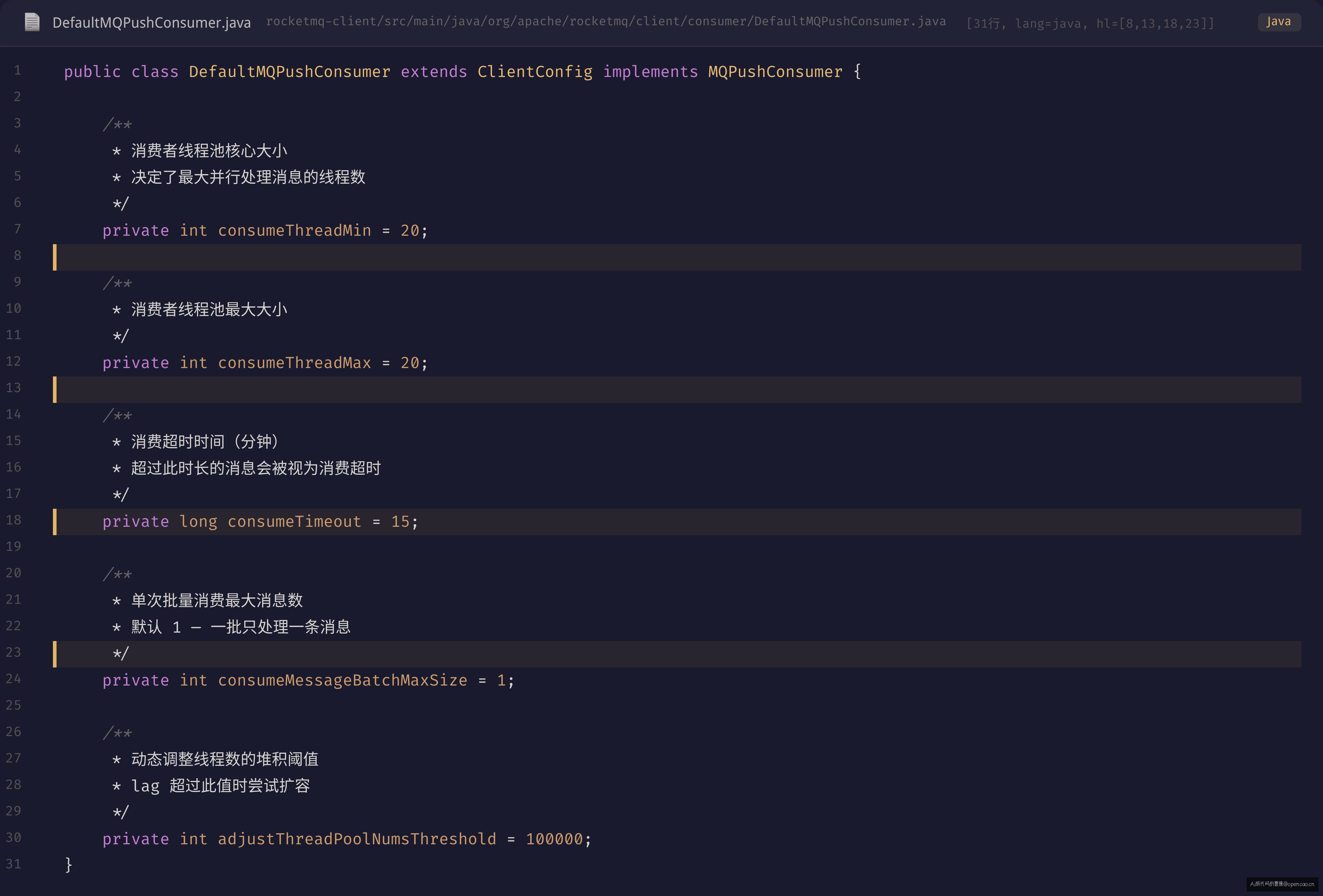
四个默认值,每个都是一颗定时炸弹——取决于你的业务场景是否满足 RocketMQ 的设计假设。
当 consumeThreadMin 和 consumeThreadMax 都是 20 时,线程池是固定大小的——高峰期用满就是 20 条线程,多出来的任务在 LinkedBlockingQueue 里排队。
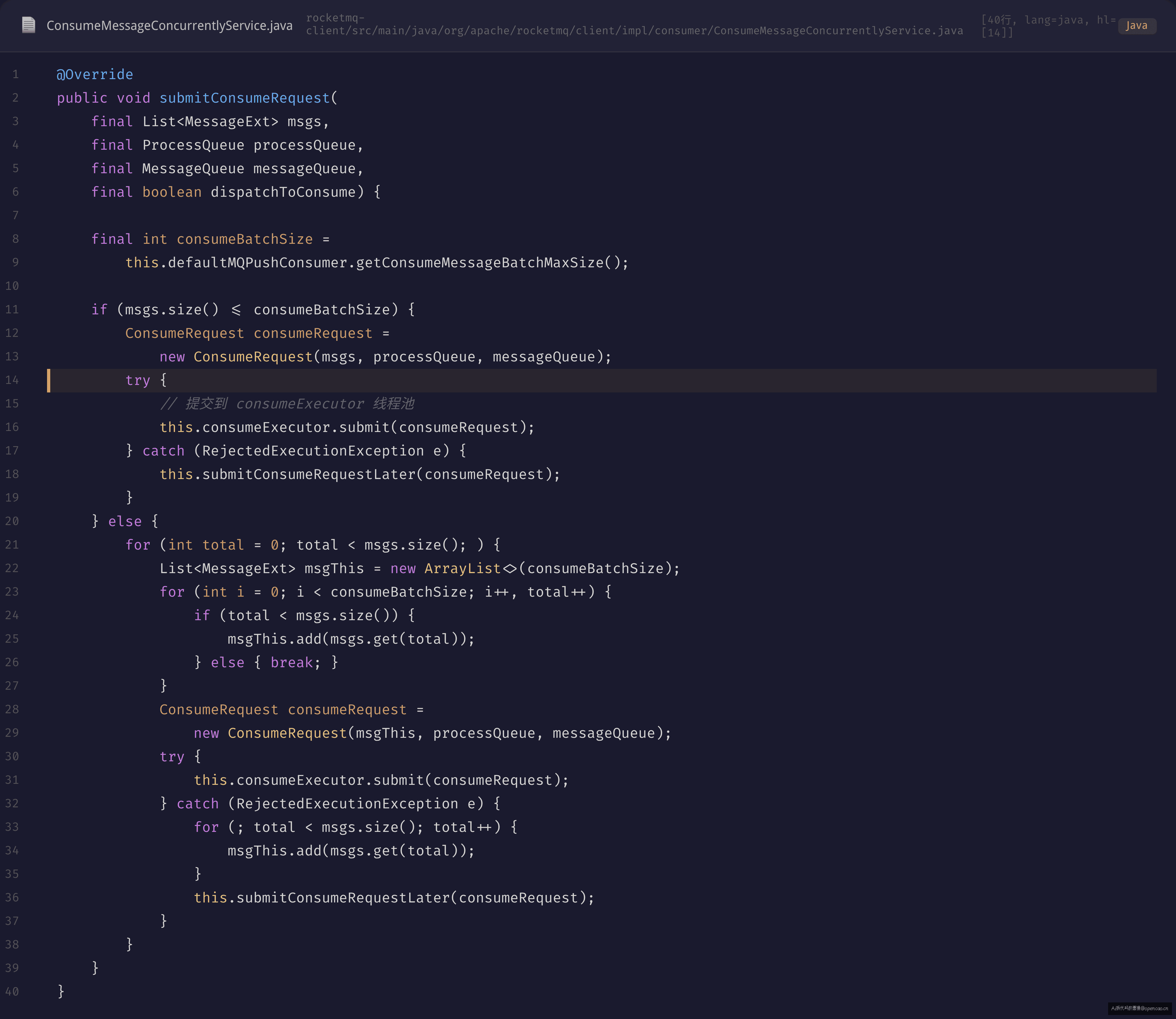
接着看消费任务怎么提交到线程池的:
这段代码揭示了两个关键设计:
1. consumeMessageBatchMaxSize=1 → 一次 ConsumeRequest 只处理 1 条消息
2. 线程池满时不会丢弃消息,而是 submitConsumeRequestLater(延迟 5s 重试)——但这意味着消费速度进一步下降
消费线程内部:ConsumeRequest.run()
每个 ConsumeRequest 最终会调用用户定义的 MessageListener:
// ConsumeMessageConcurrentlyService.ConsumeRequest.run() (简化)
public void run() {
if (this.processQueue.isDropped()) {
// 该队列已因 rebalance 被移除,不处理
return;
}
// 1. 校验消息
// 2. 调用用户 MessageListener.consumeMessage()
ConsumeConcurrentlyStatus status = messageListener.consumeMessage(msgs, context);
// 3. 处理消费结果(成功/失败/重试)
processConsumeResult(status, context, this);
}
// processConsumeResult 中更新 offset
private void processConsumeResult(...) {
// 计算 ackIndex
// 如果全部成功:更新 offset
// 如果部分失败:发送回 Broker 重试
long offset = consumeRequest.getProcessQueue()
.removeMessage(consumeRequest.getMsgs());
if (offset >= 0 && !consumeRequest.getProcessQueue().isDropped()) {
this.defaultMQPushConsumerImpl.getOffsetStore()
.updateOffset(messageQueue, offset, true);
}
}
offset 更新只发生在 processConsumeResult 中——在所有消息处理完成之后。如果 consumeMessage(msgs, context) 一直不返回(因为同步 DB 写入慢),offset 就不会更新,lag 只增不减。
消费者的业务代码:同步 DB 写入
翻到消费者的业务代码,根因浮出水面:
@Component
public class OrderMessageConsumer implements MessageListenerConcurrently {
@Autowired
private OrderService orderService;
@Override
public ConsumeConcurrentlyStatus consumeMessage(
List<MessageExt> msgs, ConsumeConcurrentlyContext ctx) {
// 一条消息一个订单
MessageExt msg = msgs.get(0);
OrderDTO order = JSON.parseObject(
new String(msg.getBody()), OrderDTO.class);
// ★ 同步 DB 写入 — 高峰期平均耗时 3s
// DB 连接池 20 个连接,高峰期全部被占满
orderService.save(order);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
}
消费逻辑本身是同步 DB 写入——高峰期 DB 连接池 20 个连接全忙,一次 save() 从正常 200ms 涨到 3-5s。
20 线程 * 5s/msg = 100 msg/min 极限吞吐,而生产者 TPS 是 500(每分钟 30,000 条)——吞吐差距 300 倍,堆积不奇怪。
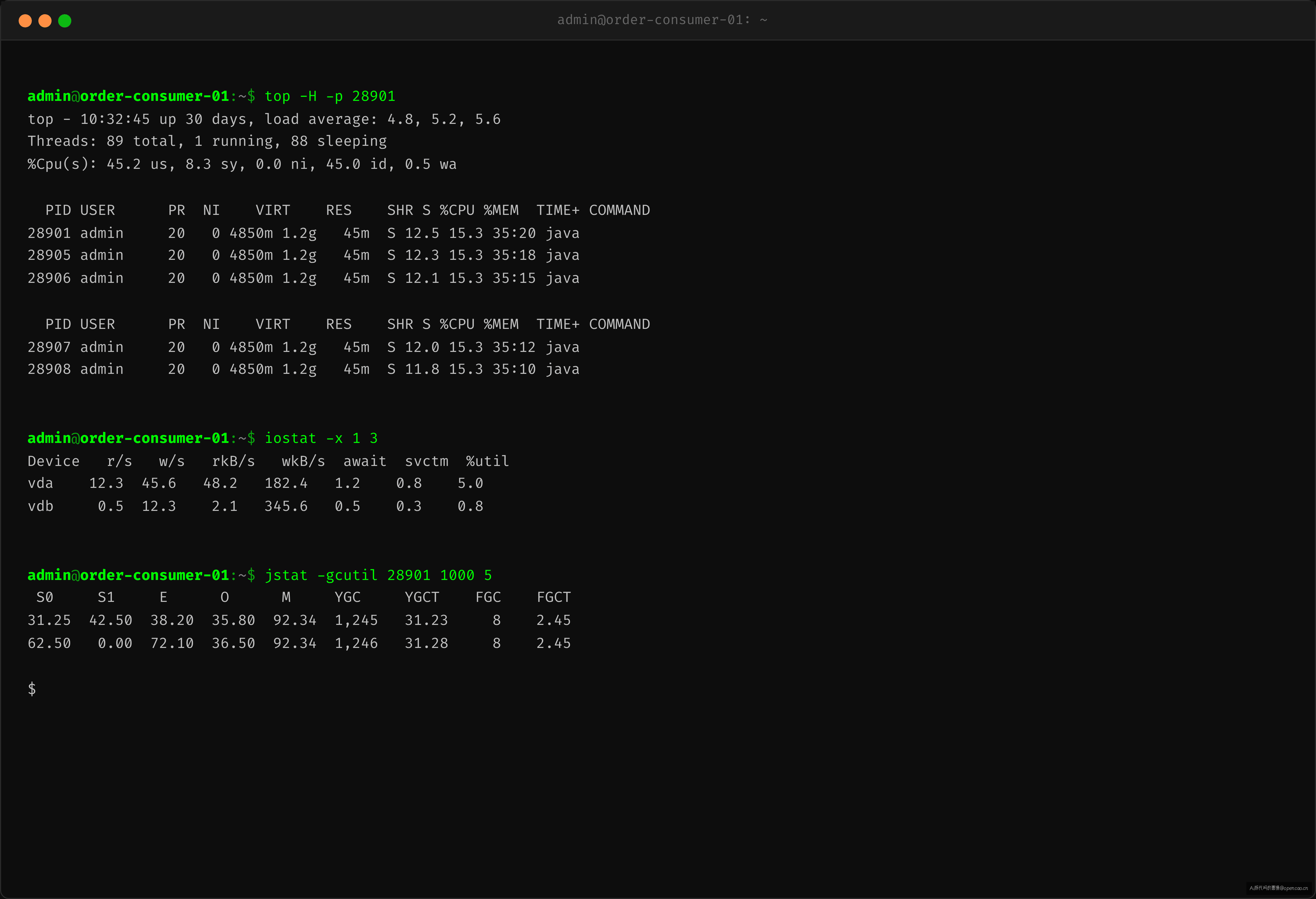
OS 层排查:排除系统资源竞争
当消费端瓶颈定位到"处理慢"后,需要确认是业务代码慢还是系统资源不够。这一步经常被跳过——结果调了半天配置,发现是磁盘 IO 打满了。
# 查看 CPU 使用率和线程级负载
$ top -H -p <consumer_pid>
top - 10:32:45 up 30 days, load average: 4.8, 5.2, 5.6
Threads: 89 total, 1 running, 88 sleeping
%Cpu(s): 45.2 us, 8.3 sy, 0.0 ni, 45.0 id, 0.5 wa
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
28901 admin 20 0 4850m 1.2g 45m S 12.5 15.3 35:20 java
28905 admin 20 0 4850m 1.2g 45m S 12.3 15.3 35:18 java
28906 admin 20 0 4850m 1.2g 45m S 12.1 15.3 35:15 java
# 查看磁盘 I/O 等待
$ iostat -x 1 3
Device r/s w/s rkB/s wkB/s await svctm %util
vda 12.3 45.6 48.2 182.4 1.2 0.8 5.0
# 查看 GC 频率
$ jstat -gcutil 28901 1000 5
S0 S1 E O M YGC YGCT FGC FGCT
31.25 42.50 38.20 35.80 92.34 1,245 31.23 8 2.45
三项指标全部正常:CPU 45% idle、磁盘 await <2ms、Young GC <30ms、无 Full GC。
OS 层不是根因——排除。把排查精力放回业务代码。
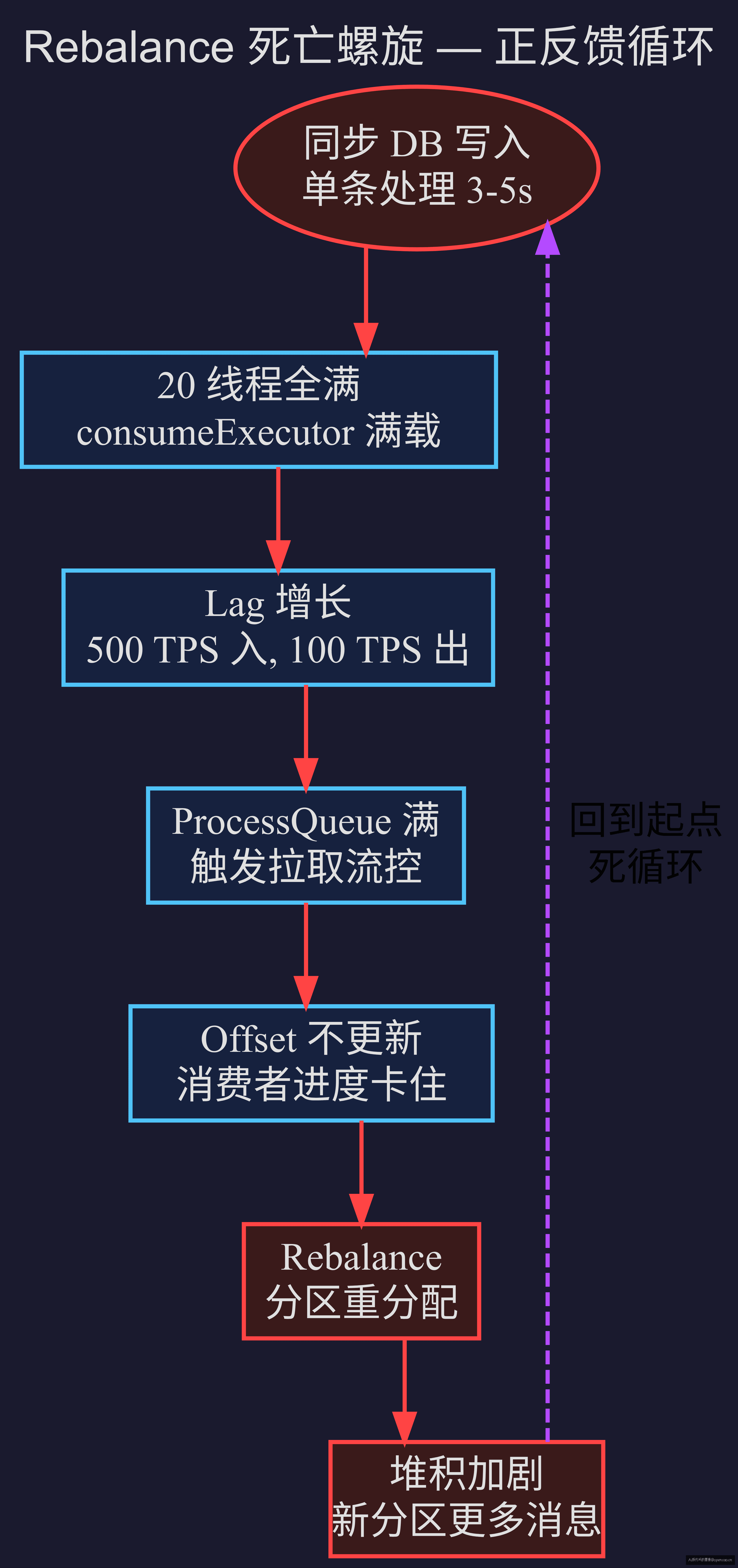
Rebalance 死亡螺旋
当消费者线程全部卡住时,会发生什么?
RocketMQ 消费者组的队列分配不是静态的。当消费者组内成员或负载变化时,RocketMQ 会重新分配每个消费者负责的队列——这个过程称为 rebalance(重平衡)。
消费者有一个定时任务 cleanExpireMsg,运行在 ConsumeMessageConcurrentlyService 的 cleanExpireMsgExecutors 中:
// ConsumeMessageConcurrentlyService 初始化时
this.cleanExpireMsgExecutors.scheduleAtFixedRate(
new Runnable() {
@Override
public void run() {
cleanExpireMsg();
}
},
this.defaultMQPushConsumer.getConsumeTimeout(), // 默认 15 分钟
this.defaultMQPushConsumer.getConsumeTimeout(), // 每 15 分钟执行一次
TimeUnit.MINUTES
);
cleanExpireMsg() 检查 ProcessQueue 中的消息是否已经待了超过 consumeTimeout 时间。如果是,这些消息被视为"消费超时",会被清除并允许重新投递。
与此同时,消费者的 offset 一直不动。消费者的 MQClientInstance 中有一个 RebalanceService 定时任务,默认每 10 秒运行一次,检查当前 consumer group 的队列分配是否均衡。当该消费者消费进度长期卡住,其他消费者的队列负载出现明显不均衡时——例如新分区分配给该消费者后进度也不动——rebalance 就会被触发。
rebalance 发生时,该消费者可能失去部分分区——但这些分区被分配给同组的其他消费者,而其他消费者也跑着同样的同步 DB 逻辑——同样慢。更糟的是,rebalance 期间所有涉及到的分区都会暂停消费,堆积进一步加剧。
1. 同步 DB 写入慢 → 20 线程全忙 → 处理速度 100/min
2. 生产速度 500/s → 堆积以 30,000/min 增长
3. ProcessQueue 满 → 拉取流控 → offset 不更新
4. Rebalance → 分区重分配 → 已有消费者负载更重
5. 堆积加剧 → 回到步骤 2
这个正反馈循环——我称它为 Rebalance 死亡螺旋。
三系统时间线对齐
下面这张表整理了同一时间窗口内三个系统的状态:
| 时间 | 生产端 | Broker | 消费端 |
|---|---|---|---|
| 10:00 | send OK, avg 42ms | PUT queue: 12 | activeCount=15/20, avg 800ms/msg |
| 10:05 | send OK, avg 156ms | PUT queue: 89 | activeCount=20/20, avg 3.2s/msg |
| 10:10 | send OK, avg 482ms | PUT queue: 378 | activeCount=20/20, ProcessQueue 1000 |
| 10:15 | send OK, avg 1.2s | PUT queue: 892 | Rebalance 触发, 失去 2 分区 |
时间已统一到 UTC+8。可见消费端从 10:00 就开始变慢,但真正的堆积从 10:05 线程池全满才开始爆炸。生产端和 Broker 是被消费端拖慢的——它们是受害者,不是根因。
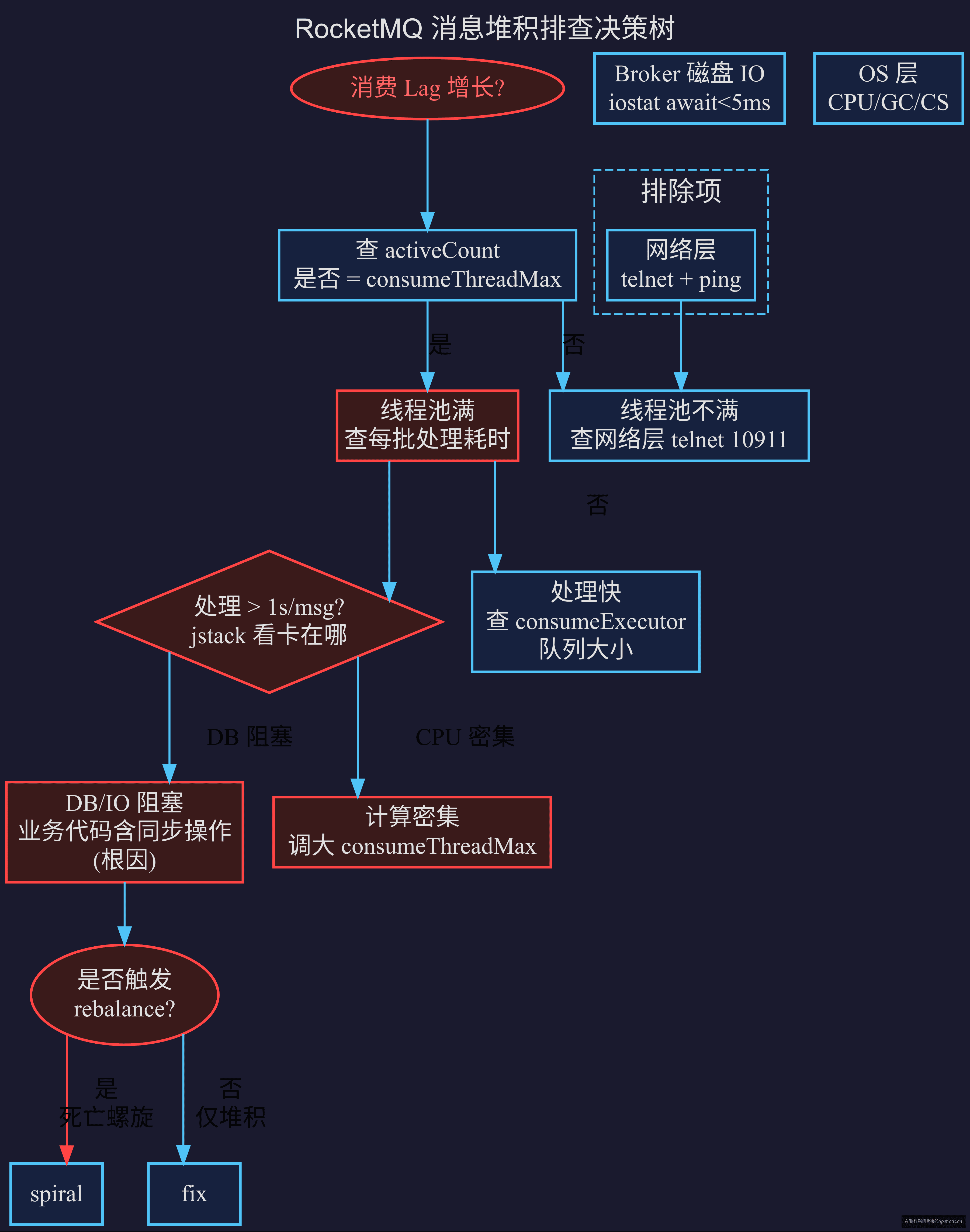
【路径】🔍 排查路径
下次你遇到消息堆积时,不用去猜——走这条路径:
消费 Lag 增长?
├── Yes → 查消费者线程池 activeCount
│ ├── 满 → 查 ConsumeRequest 处理耗时
│ │ ├── 慢(>1s/msg)→ jstack 看每个线程卡在哪
│ │ │ ├── DB/IO 阻塞 → 业务代码有同步阻塞操作(根因)
│ │ │ └── 计算密集 → 改 consumeThreadMax
│ │ └── 快 → 查 consumeExecutor 队列大小 → 任务排队
│ └── 不满 → 查网络层(telnet 10911)
├── No → 查生产端 send 耗时
│ ├── 慢 → 查 Broker 请求队列
│ └── 正常 → 查 NameServer 路由
└── 排除项:
- 网络层(telnet + ping)
- OS 层(CPU 使用率、GC 频率、磁盘 IO)
- Broker 层(请求队列、Page Cache 命中率)
先排网络,再查生产端,然后 Broker,最后消费者。每一步都有确定的指标可看,不是靠猜。
消费端排查命令
# 1. 查看消费者线程堆栈
jstack <consumer_pid> | grep -E "ConsumeMessageThread|consumeExecutor" -A 20
# 2. 查看消费 lag(Admin CLI)
mqadmin consumerProgress -g <consumerGroup>
# 3. 查看消费者线程池 JMX 指标
# 连接 JMX
jconsole <host>:<port>
# 或命令行
jmxterm -l <host>:<port>
bean -d org.apache.rocketmq -n org.apache.rocketmq:type=ConsumerStats
get consumeTps
get consumeMsgThroughtputIn
停一下,去你的项目里搜搜:
$ grep -r 'implements MessageListenerConcurrently' src/ --include='*.java'
$ grep -r 'implements MessageListenerOrderly' src/ --include='*.java'
看看有多少消费者。打开每个 consumeMessage 方法,看看里面有没有同步阻塞调用——DB 写入、RPC 调用、文件 IO。
也许你会发现不止一个这样的消费者。
【收敛】根因:同步 DB 写入 + Rebalance 死亡螺旋
排除其他可能原因
| 排除项 | 检查方法 | 结论 |
|---|---|---|
| Broker 磁盘 IO | iostat -x 1 查看 await <5ms |
正常,排除 |
| OS 层资源竞争 | CPU 50%、GC Young GC <200ms、Context Switch 正常 | 正常,排除 |
| 网络问题 | telnet 连通、ping 延迟 <1ms、无丢包 | 正常,排除 |
| 生产端慢 | send OK、TPS 稳定 500/s | 正常,排除 |
| consumeTimeout 过短 | 默认 15min,但单条处理 3s,远低于阈值 | 未触发超时淘汰,但属于间接因素 |
| 线程池太小 | 20 线程 × 5s = 100 msg/min,生产 30,000/min | 匹配问题,但不是根因 |
根因:消费者业务代码中嵌了同步 DB 写入。高峰期 DB 连接池全忙,单条消息处理从 200ms 涨到 3-5s。20 个消费线程全满,ProcessQueue 拉取流控,offset 不更新,触发 rebalance 死亡螺旋。堆积不是结果,是因果链的一环——它既是原因也是结果。
修复方案
长期修复:消费者中 DB 操作改为异步
@Override
public ConsumeConcurrentlyStatus consumeMessage(
List<MessageExt> msgs, ConsumeConcurrentlyContext ctx) {
MessageExt msg = msgs.get(0);
OrderDTO order = JSON.parseObject(
new String(msg.getBody()), OrderDTO.class);
// ✅ 改为异步写入 MQ,由独立消费者处理 DB 写入
// 消费线程不再阻塞
orderSaveProducer.send(order, (sendResult, err) -> {
if (err != null) {
log.error("order save async failed", err);
}
});
// 立即返回 SUCCESS,不等待 DB 完成
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
消费线程只做消息格式转换 + 异步投递,不再直接操作 DB。这样可以大幅降低消费耗时,让线程池不再阻塞。
这不是"用 MQ 解决 MQ 问题"——消费线程的瓶颈是同步阻塞(等 DB 返回),替换为非阻塞投递(发完立即返回)后,消费线程从"阻塞等待 IO"变成"内存级的消息路由"。DB 写入被解耦到专门的消费者处理,独立扩缩容。
短期止血:
| 配置 | 修改前 | 修改后 | 说明 |
|---|---|---|---|
| consumeThreadMax | 20 | 40 | 提升并行度,但只治标 |
| consumeThreadMin | 20 | 20 | 保持与 max 一致 |
| consumeMessageBatchMaxSize | 1 | 10 | 一批处理多条(需要注意业务幂等) |
| consumeTimeout | 15 min | 30 min | 给慢操作更多缓冲,防止 cleanExpireMsg 过早动作 |
验证修复
修改后观察 10 分钟: - 消费端 lag 是否开始下降(Grafana 面板) - 消费者线程池 activeCount 是否低于 20 - 接口端到端耗时是否从 5s 降回 200ms
【标记】📡 告警设置
监控项
在 Grafana/RocketMQ Dashboard 中添加以下告警——设了就不用等人报:
| 告警项 | 指标 | 阈值 | 级别 |
|---|---|---|---|
| 消费 Lag 持续增长 | consumerLag |
>10,000 持续 5 分钟 | P0 |
| Rebalance 频繁 | rebalanceTimes |
>5 次/分钟 | P1 |
| 消费者线程池满 | activeCount |
= consumeThreadMax 持续 30s | P1 |
| 消费处理耗时过长 | consumeAvgTime |
>1s 持续 5 分钟 | P2 |
| ProcessQueue 堆积 | processQueueSize |
>500 | P2 |
配置检查清单
□ consumeTimeout ≥ 期望最大处理时间的 2 倍(默认 15min)
□ consumeThreadMin/consumeThreadMax 根据分区数 × 2 估算
□ consumeMessageBatchMaxSize 设为 >1(需业务幂等)
□ 网络层告警(telnet + ping)与中间件告警同时部署
🔑 排查心法
消息堆积像发烧——体温不是病,是症状。排查堆积不是看堆积本身,是看消费者的线程模型。
排查消息堆积的三个心法:
1. 先看线程池,再看 Lag——线程池用完是病根,Lag 是症状
2. 先排网络,再排业务——网络不通调半天配置是浪费生命
3. 先看消费者,再怀疑生产者——堆积 90% 在消费端
下篇我们聊顺序消费队列变更导致消息乱序分析——当你换成顺序消费时,新的坑又来了。


