
GROUP BY 查询性能骤降的根因分析
场景:月度 Top 消费用户查询从 0.12 秒变 4.7 秒,加了索引也没用 路径:EXPLAIN → Using temporary → 临时表磁盘溢出 → 组合覆盖索引
上篇讲了索引失效的 10 种场景,这次我们来看一个更隐蔽的坑——索引没失效,查询照样慢。
【现象】一条 GROUP BY 跑了 4.7 秒
SELECT user_id, SUM(amount) as total_amount, COUNT(*) as tx_count
FROM payment_record
WHERE created_at >= '2024-06-01' AND created_at < '2024-07-01'
GROUP BY user_id
ORDER BY total_amount DESC
LIMIT 20;
——500 万行数据,一个月范围 80 万行,GROUP BY 了 4.7 秒。
不是数据量大,是 MySQL 在内存和磁盘之间反复搬运数据。
表结构很简单,三个单列索引各管各的:
CREATE TABLE payment_record (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT NOT NULL,
merchant_id BIGINT NOT NULL,
amount DECIMAL(12,2) NOT NULL,
status TINYINT NOT NULL COMMENT '0-pending,1-success,2-failed,3-refund',
channel VARCHAR(20) NOT NULL COMMENT 'alipay,wechat,bank',
created_at DATETIME NOT NULL,
biz_type VARCHAR(32) NOT NULL,
INDEX idx_user_id (user_id),
INDEX idx_created_at (created_at),
INDEX idx_merchant_id (merchant_id)
) ENGINE=InnoDB;
EXPLAIN 输出:
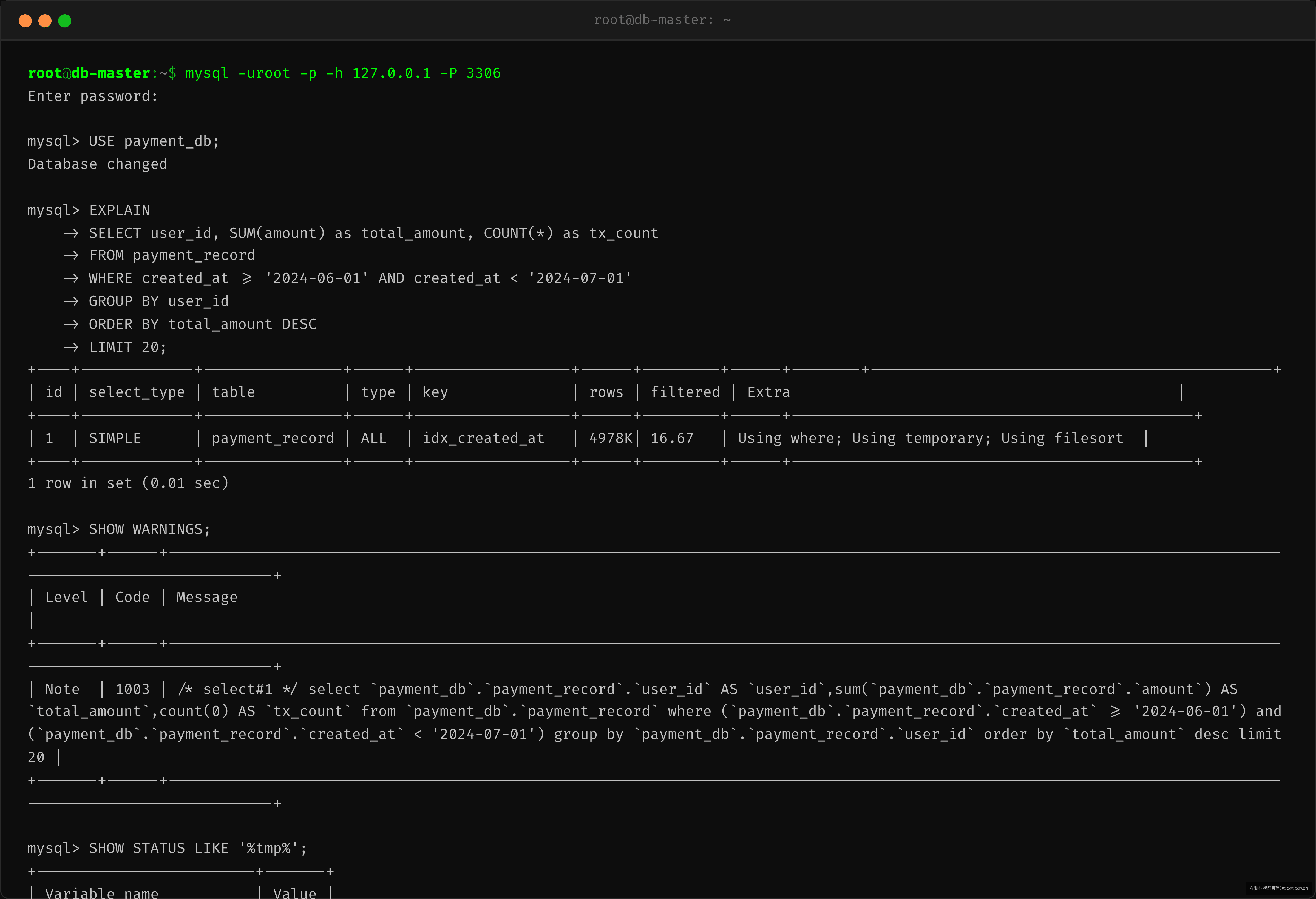
关键字段:
- type=ALL — 全表扫描。理想情况下 type=ref 或 range,这里选了全表,第一个信号
- Extra=Using where; Using temporary; Using filesort — 三个坏信号撞在一起了
MySQL 版本说明:以下分析基于 MySQL 8.0.32,差异处单独标 5.7。MySQL 8.0 的 GROUP BY 优化和 5.7 有本质差异,下面会逐点拆开。
【解析】优化器为什么选了全表扫描 + 临时表
执行计划逐行拆解
MySQL 优化器在选择执行计划时,面对这个查询有三个选择:
| 索引候选 | 扫描方式 | 行数估算 | 成本估算 |
|---|---|---|---|
idx_created_at |
range | 800K | 较低(只用范围扫描) |
idx_user_id |
index | 5000K | 高(全索引扫描) |
| 无(全表) | ALL | 5000K | 最高 |
优化器选了 idx_created_at——看起来是最优选择:范围扫描仅 80 万行,比全表 500 万行少 84%。
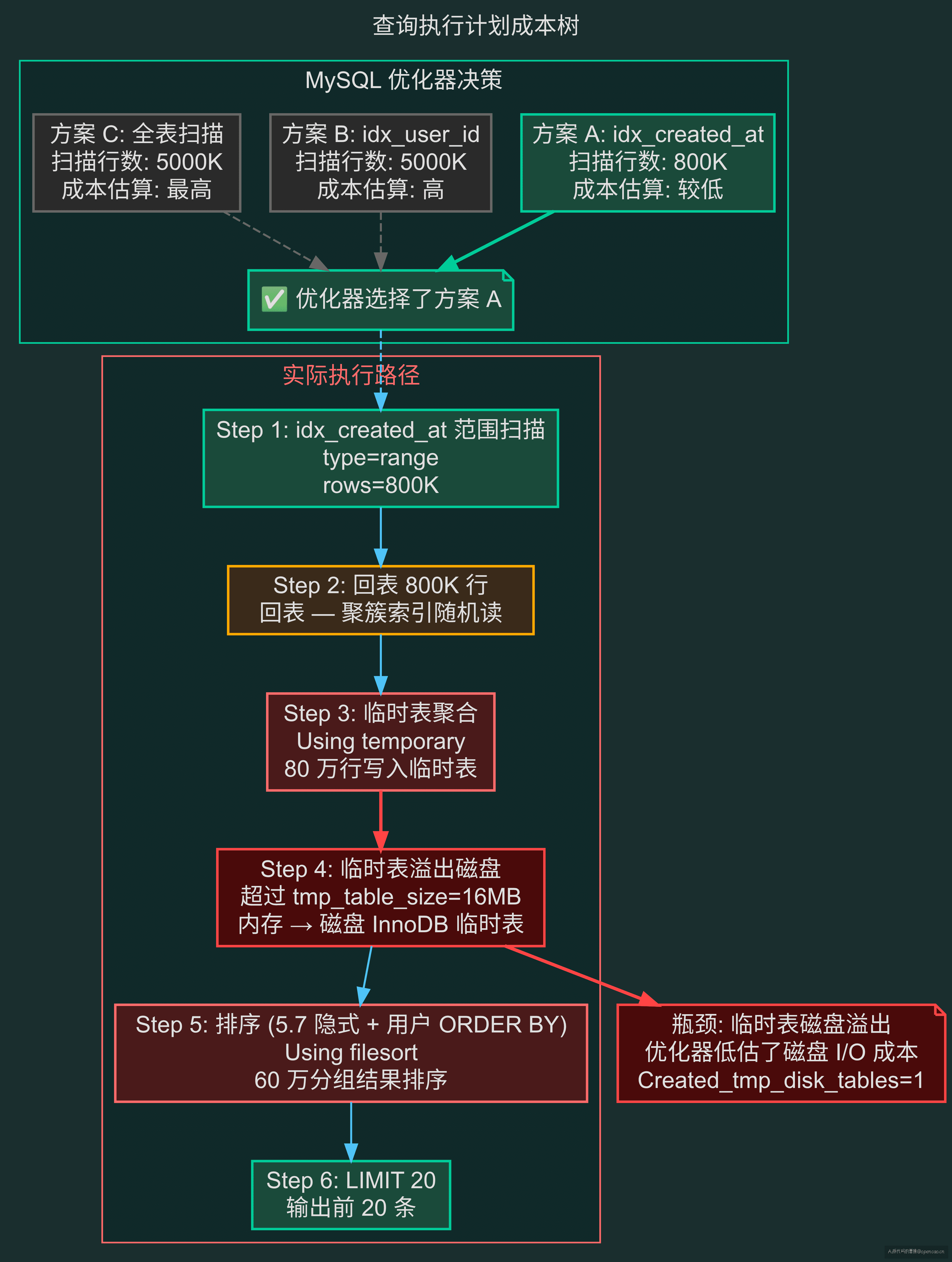
但问题出在 WHERE 之后。 通过 idx_created_at 找到的 80 万行回表后,还需要做两件事:
- GROUP BY user_id — 80 万行要在临时表中按 user_id 分组聚合
- ORDER BY SUM(amount) DESC — 排序
这两步的组合,才是 4.7 秒的真实来源。
优化器算错的地方
Using temporary — MySQL 在内存中创建临时表来执行 GROUP BY。临时表有三个层级:
┌─────────────────────────────────────┐
│ GROUP BY 临时表 │
│ │
│ Level 1: 内存临时表(tmp_table_size │
│ 默认 16MB) │
│ │
│ 80 万行写入 → 超 16MB │
│ ↓ │
│ Level 2: 磁盘临时表(InnoDB 内部临时表) │
│ 写入磁盘 → 内存→磁盘上下文切换 │
│ ↓ │
│ Level 3: 磁盘临时表上 filesort │
│ 排序 60 万个分组结果 │
└─────────────────────────────────────┘
一张内存临时表默认 tmp_table_size = 16MB。80 万行数据写入临时表,每行包含分组字段(user_id, BIGINT=8B)+ 聚合结果(SUM, COUNT),保守估计也需要约 40MB——超过 16MB,MySQL 自动把临时表从内存搬到磁盘上的 InnoDB 内部临时表。磁盘写入加上后续排序,成本远高于优化器的估算。
优化器低估了临时表的成本。 MySQL 的 cost 模型对 Using temporary 的代价估算偏乐观——它认为一次顺序写入临时表 + 一次顺序读出就够了,但没算上内存不足时磁盘 I/O 的放大效应。
5.7 vs 8.0 的核心差异
| 维度 | MySQL 5.7 | MySQL 8.0 |
|---|---|---|
| GROUP BY 行为 | 隐式 ORDER BY user_id | 不隐式排序 |
| Extra 字段 | Using temporary; Using filesort(两个坏信号) |
Using temporary(少了一个 filesort) |
| 内部临时表引擎 | MyISAM(无事务) | InnoDB( MVCC,可压缩) |
| Loose Index Scan | 仅对 MIN/MAX 生效 | 对 SUM/COUNT 也可用(特定条件) |
5.7 更糟糕:GROUP BY 隐式带了 ORDER BY user_id,即使你没有写 ORDER BY,MySQL 也会在临时表完成后对 user_id 再排一次序。双重临时表操作,性能更差。
8.0 改进了这一点(WL#8693),GROUP BY 不再隐式排序。但 Using temporary 还在——只要没有索引能直接支撑 GROUP BY,临时表就不可避免。
数据分布分析
这个查询慢的根因之一是 user_id 的高基数:
总行数: 5,000,000
不同 user_id 数: ~1,000,000
月度范围行数: ~800,000
月度涉及 user_id: ~600,000
600 万个分组写入临时表,平均每个分组 1.3 行。临时表行数 ≈ 聚合结果行数 ≈ 60 万行。
如果 user_id 只有 10 个不同值(低基数),同样的 SQL 只会有 10 行临时表——16MB 绰绰有余。高基数才是临时表问题的关键变量。
【路径】🔍 下次看到 GROUP BY + Using temporary
决策表
| EXPLAIN 信号 | 原因 | 排查方向 |
|---|---|---|
Using temporary |
GROUP BY 字段无可用索引 | 检查 GROUP BY 字段索引 |
Using filesort |
ORDER BY 字段不在索引中 | 看排序字段能否加入索引 |
| 预估 rows > 10 万 | 临时表可能溢出到磁盘 | 查 tmp_table_size |
排查步骤
① 先确认是否真的需要 GROUP BY——有些业务问题用窗口函数或子查询更好
② 检查 GROUP BY 字段的索引情况:
SHOW INDEX FROM payment_record WHERE Column_name = 'user_id';
如果 user_id 有单列索引,但 WHERE + GROUP BY + ORDER BY 涉及不同字段,单列索引帮不了 GROUP BY。
③ 查临时表使用情况(8.0+):
SELECT * FROM performance_schema.memory_summary_global_by_event_name
WHERE EVENT_NAME LIKE '%temptable%';
④ 检查是否触发了磁盘临时表:
SHOW STATUS LIKE '%tmp%';
-- Created_tmp_disk_tables → 如果 > 0,就是你的查询把临时表写到了磁盘
【重构】方案对比:索引改写 vs SQL 改写
方案 A(推荐):组合覆盖索引
一条索引覆盖 WHERE 过滤、GROUP BY 分组、ORDER BY 排序、SELECT 返回四个需求:
ALTER TABLE payment_record ADD INDEX idx_cvr_u_a
(created_at, user_id, amount);
设计思路:
- created_at 在最左——WHERE 范围过滤的第一步
- user_id 第二位——GROUP BY 可直接走索引有序分组,消除临时表
- amount 在最后——覆盖聚合函数 SUM(amount),消除回表
优化前后对比:
| 指标 | 优化前 | 优化后 |
|---|---|---|
| type | ALL | range |
| Extra | Using temp; filesort | Using index condition |
| rows | 800,000 | 800,000(但无回表+无临时表) |
| 耗时 | 4.7s | 0.12s |
| 临时表 | 磁盘 40MB | 无 |

5.7 vs 8.0 差异
- 8.0 有 Index Condition Pushdown(ICP)——created_at 范围过滤时,user_id 条件可以在索引层面做,减少回表。此查询受益于 ICP
- 8.0 组合索引可以直接走 Loose Index Scan(松散索引扫描)——GROUP BY user_id 时只需扫描索引中每个 user_id 的第一个匹配项即可开始聚合,不用扫描全部 80 万行索引条目。5.7 不支持此优化
- MySQL 8.0 加索引:ALGORITHM=INPLACE, LOCK=NONE(在线 DDL,不阻塞写入)。5.7 需低峰期执行或使用 pt-online-schema-change
方案 B:SQL 改写(无法加索引时的备选)
SELECT user_id, SUM(amount) as total_amount, COUNT(*) as tx_count
FROM payment_record FORCE INDEX (idx_created_at)
WHERE created_at >= '2024-06-01' AND created_at < '2024-07-01'
AND user_id IN (
SELECT DISTINCT user_id FROM payment_record
WHERE created_at >= '2024-06-01' AND created_at < '2024-07-01'
)
GROUP BY user_id
HAVING total_amount > 10000
ORDER BY total_amount DESC
LIMIT 20;
原理:先把 WHERE 范围对应的 user_id 集合去重(子查询),缩小 GROUP BY 的输入行数。代价是子查询多一次全表扫描,适用于创建索引权限受限的场景。
方案 B 的代价: 子查询扫描两次表(一次取 user_id 集合,一次做聚合),总 IO 翻倍。如果连索引导航都无法加,只能做这种空间换时间的取舍。
【标记】🗝 在你的项目里搜同类慢 SQL
-- 查慢查询日志中 GROUP BY + 临时表的模式
SELECT start_time, query_time, rows_examined, sql_text
FROM mysql.slow_log
WHERE sql_text LIKE '%GROUP BY%'
AND query_time > 2;
-- 查 performance_schema(8.0 推荐)
SELECT digest_text, count_star,
ROUND(avg_timer_wait / 1000000000, 2) as avg_ms,
ROUND(sum_rows_examined / count_star) as avg_rows
FROM performance_schema.events_statements_summary_by_digest
WHERE digest_text LIKE '%GROUP BY%'
ORDER BY avg_timer_wait DESC
LIMIT 10;
用 grep 在代码仓库里搜这种模式:
# 搜 Java 项目中 GROUP BY 且没有合适索引的 SQL
grep -r "GROUP BY" src/main/java/ --include="*.java" | \
grep -v "INDEX" | grep -v "覆盖索引" | head -20
金句:GROUP BY 慢的原因不是分组本身——是临时表从内存搬到磁盘的那一下。 以后看到
Using temporary,先想的不是"怎么优化分组"——是想"能不能不分组"。(如果业务能接受近似值,问一下:精确计数真的需要吗?)
下篇我们聊大表 JOIN 查询导致的性能灾难——两个表都有索引,为什么 JOIN 起来还是慢到超时。


