
两端连接都是 ESTABLISHED,中间层却悄悄断了——conntrack 超时引发 RST
场景:连接空闲 30 分钟后复用报错 | 路径:ss → tcpdump → conntrack → sysctl
上篇我们分析了 TCP RST 包的常见原因——端口未监听、防火墙拦截、应用层主动关闭。这篇来看一个更隐蔽的场景:两端连接都是 ESTABLISHED,中间层却悄悄断了。
T0.000 客户端发出业务数据。T0.001 中间设备回了 RST——中间这 1ms,数据包在 conntrack 表里查无此人。 不是端口问题,不是进程挂了——是内核的 conntrack 表项被清了,而两端都不知道。
路况
第一反应——重启
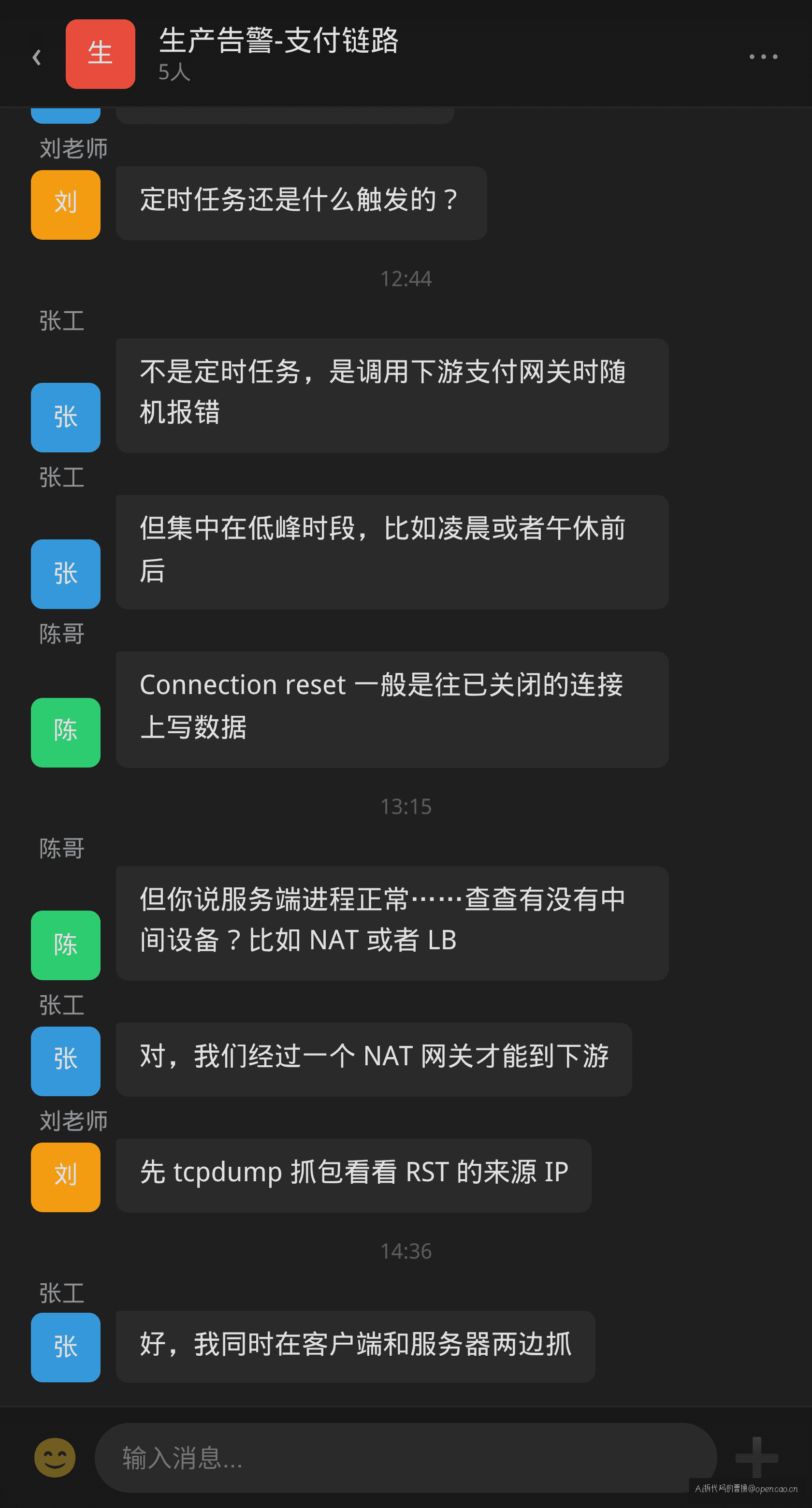
某天下午,定时任务报错:java.net.SocketException: Connection reset by peer。排障的人登录服务器,ss -tlnp 看端口正常监听,进程活着。重启服务,好了。第二天同一时段,同样的报错又来了。
只在低峰空闲期出现。每次重启能好 2-3 小时,然后复发。
用数字说话
看监控曲线——连接数在空闲期后有一段"断崖式下降",然后"陡升":

断崖下降对应 RST 断开连接,陡升对应客户端重连。周期固定,每次间隔约 40-50 分钟。不是偶发,是确定的规律。
常态排查走不通
□ 端口监听? ➔ ss -tlnp → 正常
□ 进程活着? ➔ ps aux | grep java → 正常
□ 内存/CPU? ➔ 指标正常
□ 应用日志? ➔ 无业务异常
□ 连接数? ➔ 不过高
不是常规问题。那就 tcpdump 抓包。
回放
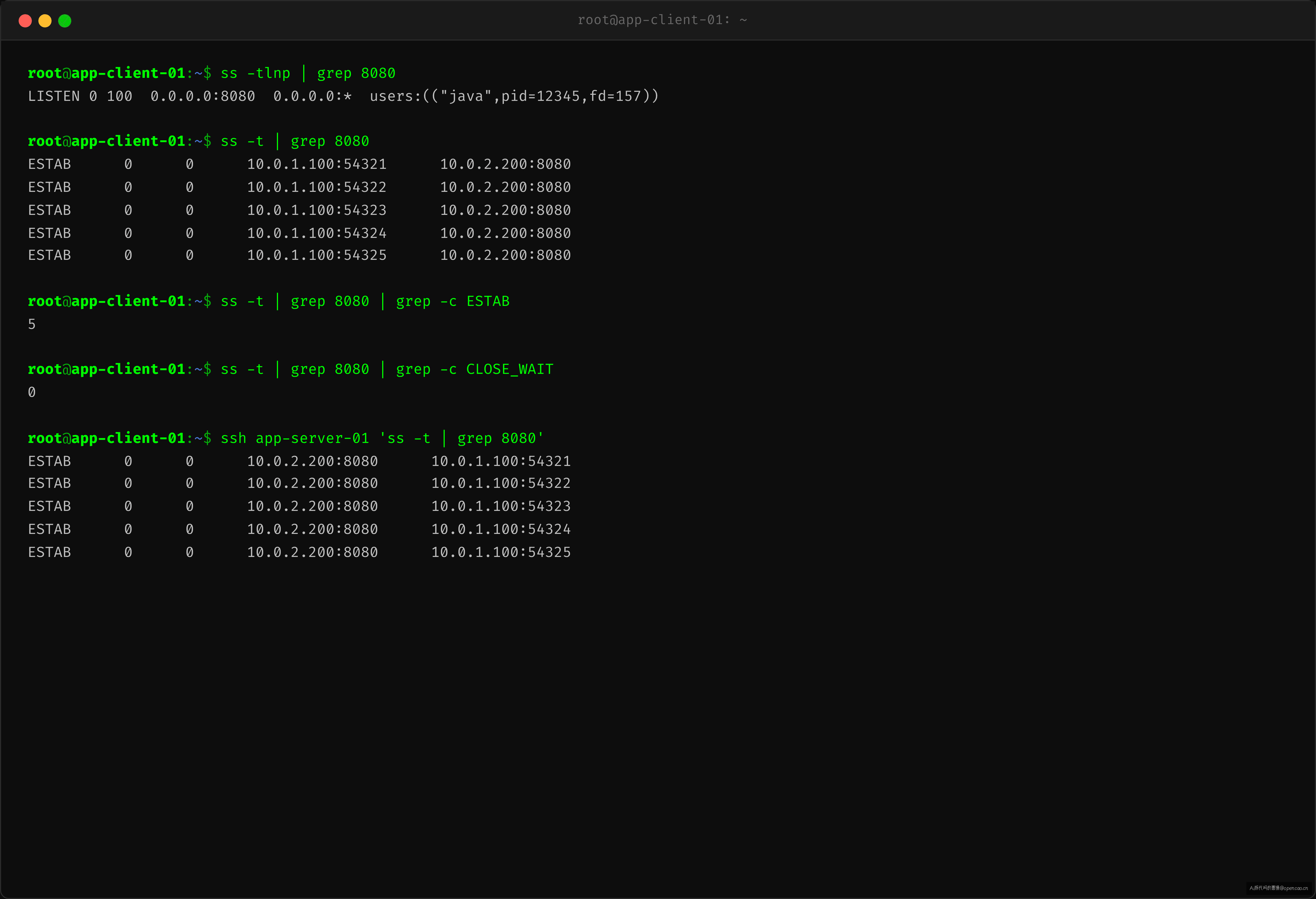
先看连接:两端都是 ESTABLISHED
在客户端执行 ss -tlnp:
$ ss -tlnp | grep 8080
ESTAB 0 0 10.0.1.100:54321 10.0.2.200:8080 users:(("java",pid=1234))
ESTAB 0 0 10.0.1.100:54322 10.0.2.200:8080 users:(("java",pid=1234))
ESTAB 0 0 10.0.1.100:54323 10.0.2.200:8080 users:(("java",pid=1234))
服务端同样:
$ ss -tlnp | grep 8080
ESTAB 0 0 10.0.2.200:8080 10.0.1.100:54321 users:(("java",pid=5678))
ESTAB 0 0 10.0.2.200:8080 10.0.1.100:54322 users:(("java",pid=5678))
ESTAB 0 0 10.0.2.200:8080 10.0.1.100:54323 users:(("java",pid=5678))
端口监听正常,进程活着,连接也是 ESTABLISHED——那 RST 从哪来的?
抓包:建连阶段
在客户端起 tcpdump,等报错复现:
tcpdump -i eth0 host 10.0.2.200 -c 20 -nn -S -w /tmp/conntrack-rst.pcap
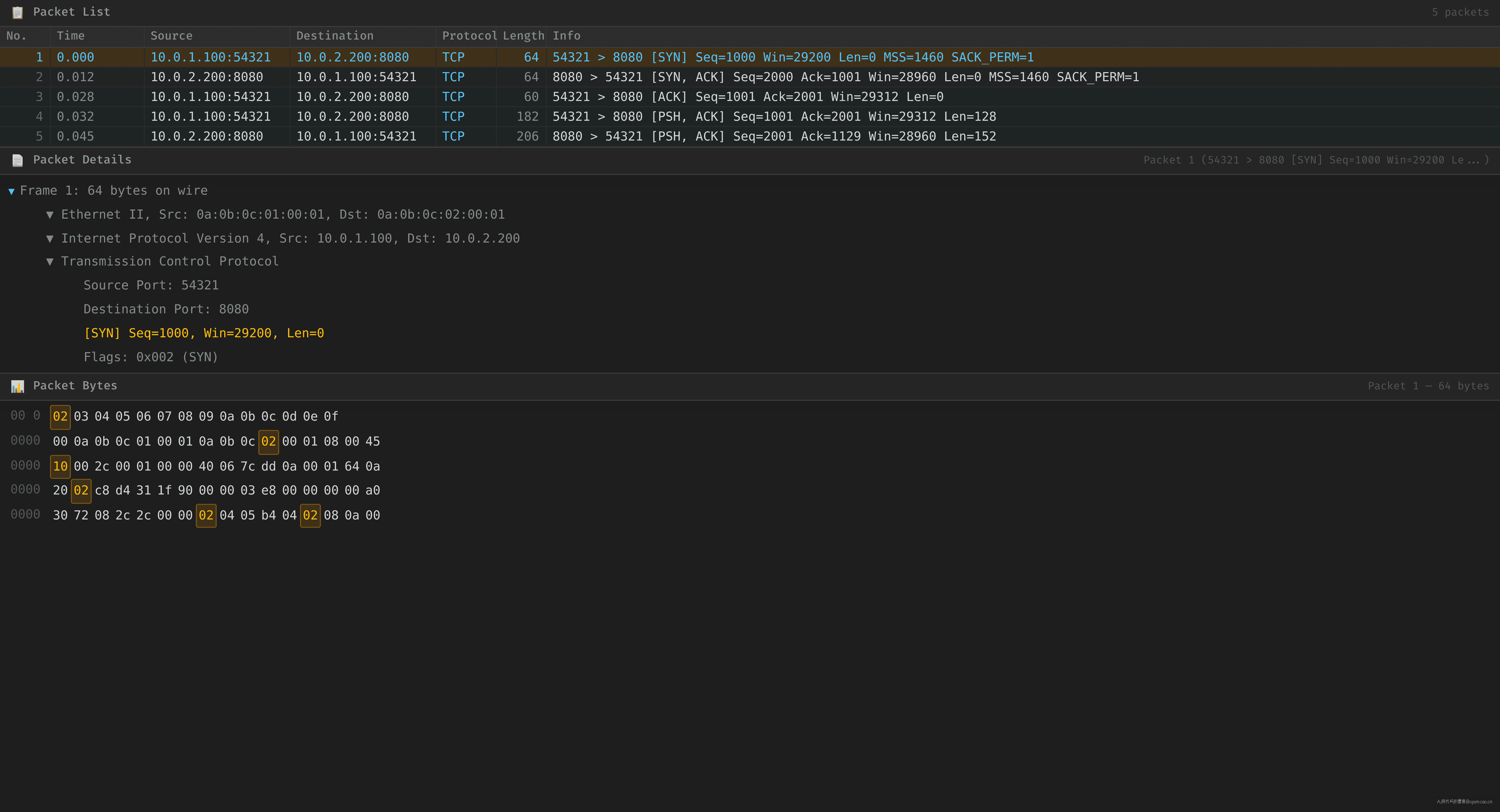
捕获到建连阶段的包(约 3 小时前的记录):
T -10800.000 Client:54321 → Server:8080 [SYN] seq=1000
T -10799.988 Server:8080 → Client:54321 [SYN, ACK] seq=2000 ack=1001
T -10799.972 Client:54321 → Server:8080 [ACK] seq=1001 ack=2001
SYN(SYNchronize)——TCP 建连的第一次握手,标志位为 1。SYN-ACK 是服务端对 SYN 的确认。 三次握手正常,连接建立。
抓包:空闲期后的第一条数据
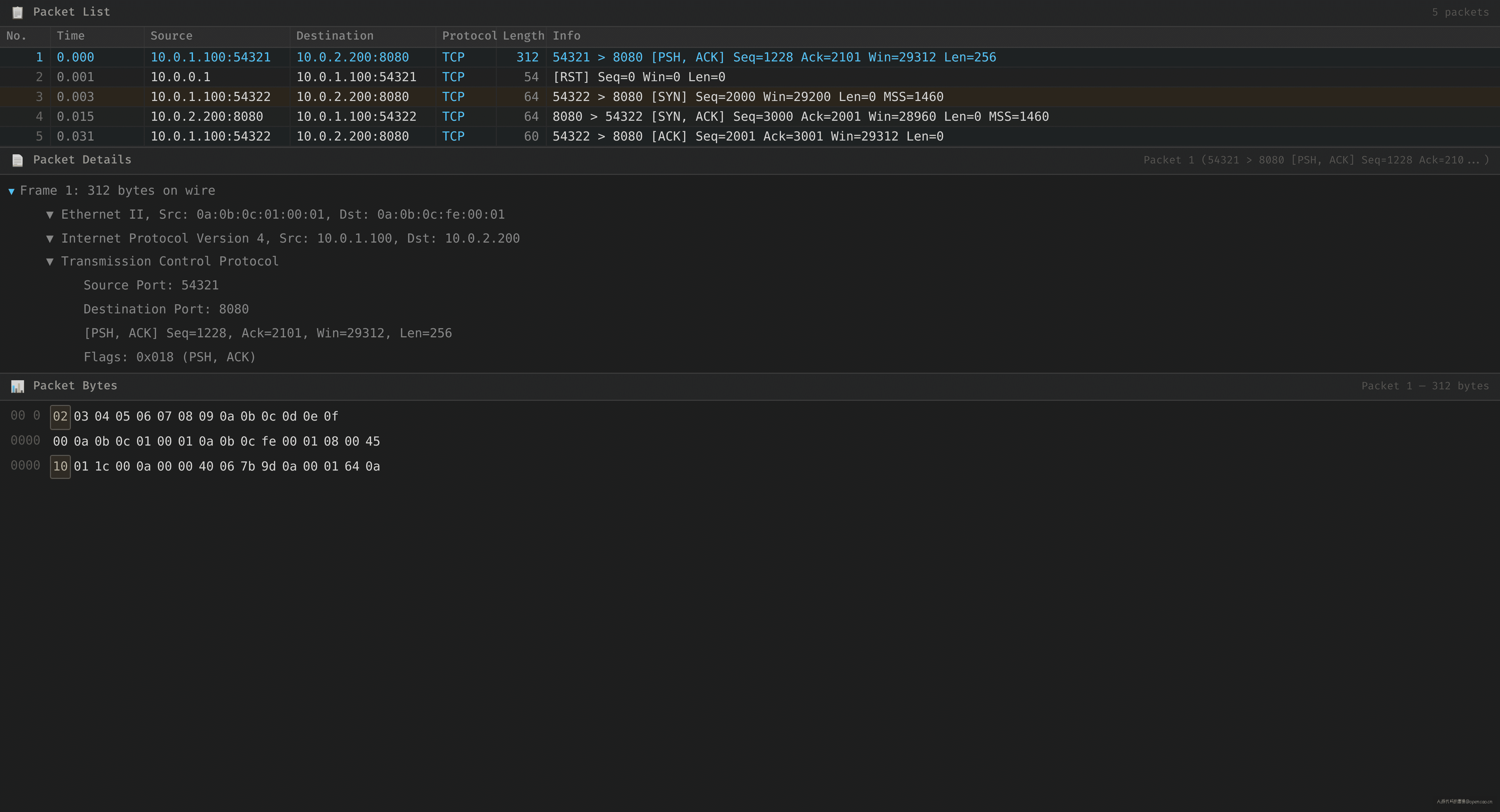
继续滚动 tcpdump 输出,到了 40 分钟后的关键时刻:
T -10500.000 Client:54321 → Server:8080 [PSH, ACK] seq=1100 ack=2100 len=128 ← 最后一条业务数据
...
(以下省略约 2700s ≈ 45 分钟的无流量时段)
...
T 0.000 Client:54321 → Server:8080 [PSH, ACK] seq=1228 ack=2100 len=256 ← 复用连接
T 0.001 10.0.0.1:0 → Client:54321 [RST] seq=0 win=0 ← 来源:中间设备
注意第 2 行 RST 的来源 IP——10.0.0.1,既不是客户端(10.0.1.100)也不是服务端(10.0.2.200)。这是中间 NAT/LB 设备的 IP。
RST 的 seq=0,win=0——这是内核主动发出的 RST(不是应用层 close() 产生的 FIN 序列)。内核在什么情况下会主动发 RST?它收到了一个"不属于任何已知连接"的数据包。
查 conntrack:空的
在中间 NAT/LB 设备上查 conntrack:
# conntrack(connection tracking)——Linux netfilter 的连接跟踪表
# 它记录每个经过的 TCP/UDP 连接的状态
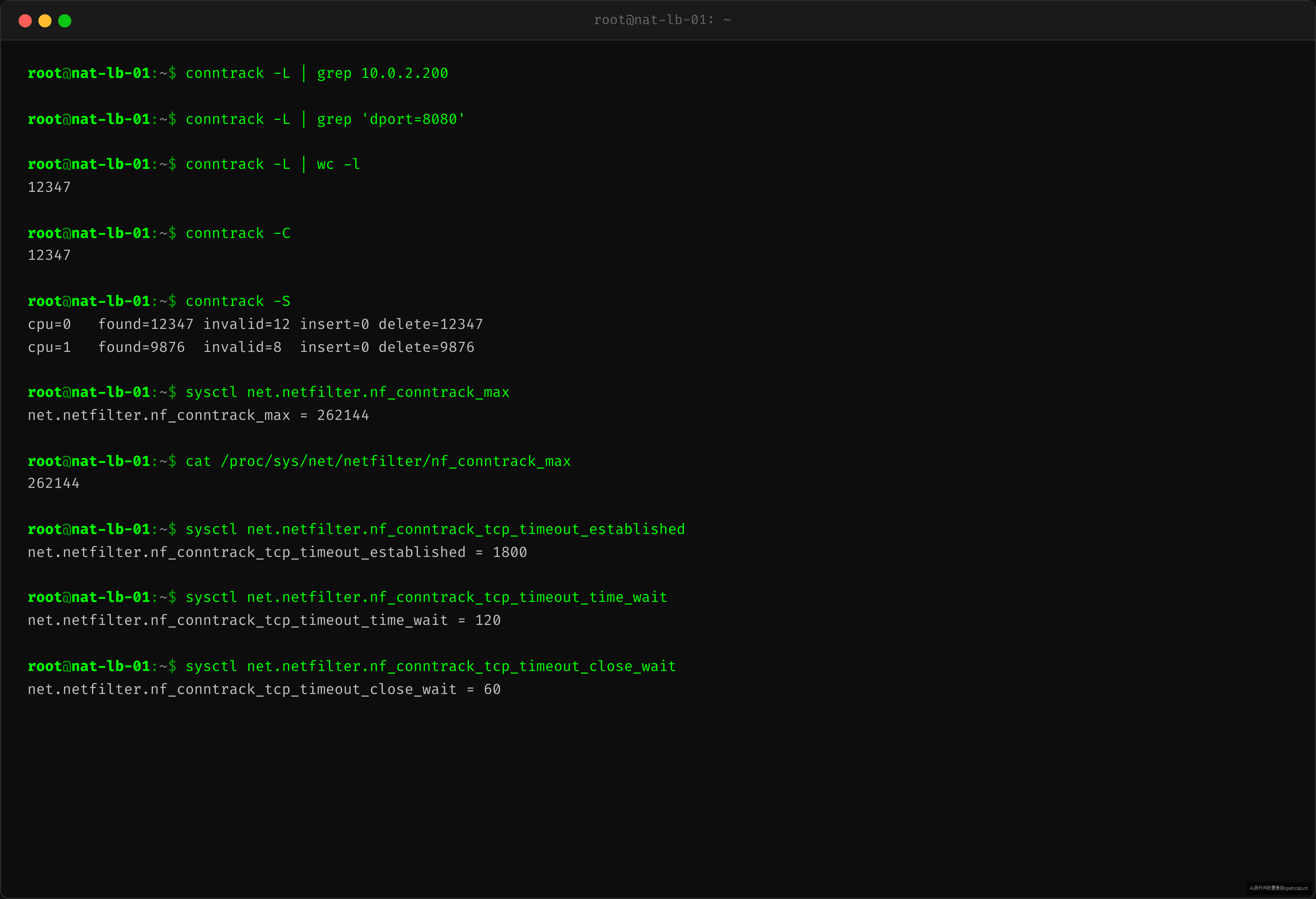
$ conntrack -L | grep 10.0.2.200
# 空——表项已被清除
conntrack 表里没有这条流的记录。为什么?因为 nf_conntrack_tcp_timeout_established 默认只有 1800s(30分钟)。
路径
下次看到"两端 ESTABLISHED 但收到 RST"的现象,按这个顺序排查:
1. 确认 RST 来源
# 抓 RST 包,看来源 IP
tcpdump -i eth0 port 8080 -c 10 -nn 'tcp[tcpflags] & tcp-rst != 0'
看 RST 包的源 IP。如果是中间设备的 IP(不是客户端也不是服务端),问题大概率出在 conntrack。
2. 查 conntrack 超时
# 当前 conntrack ESTABLISHED 超时值
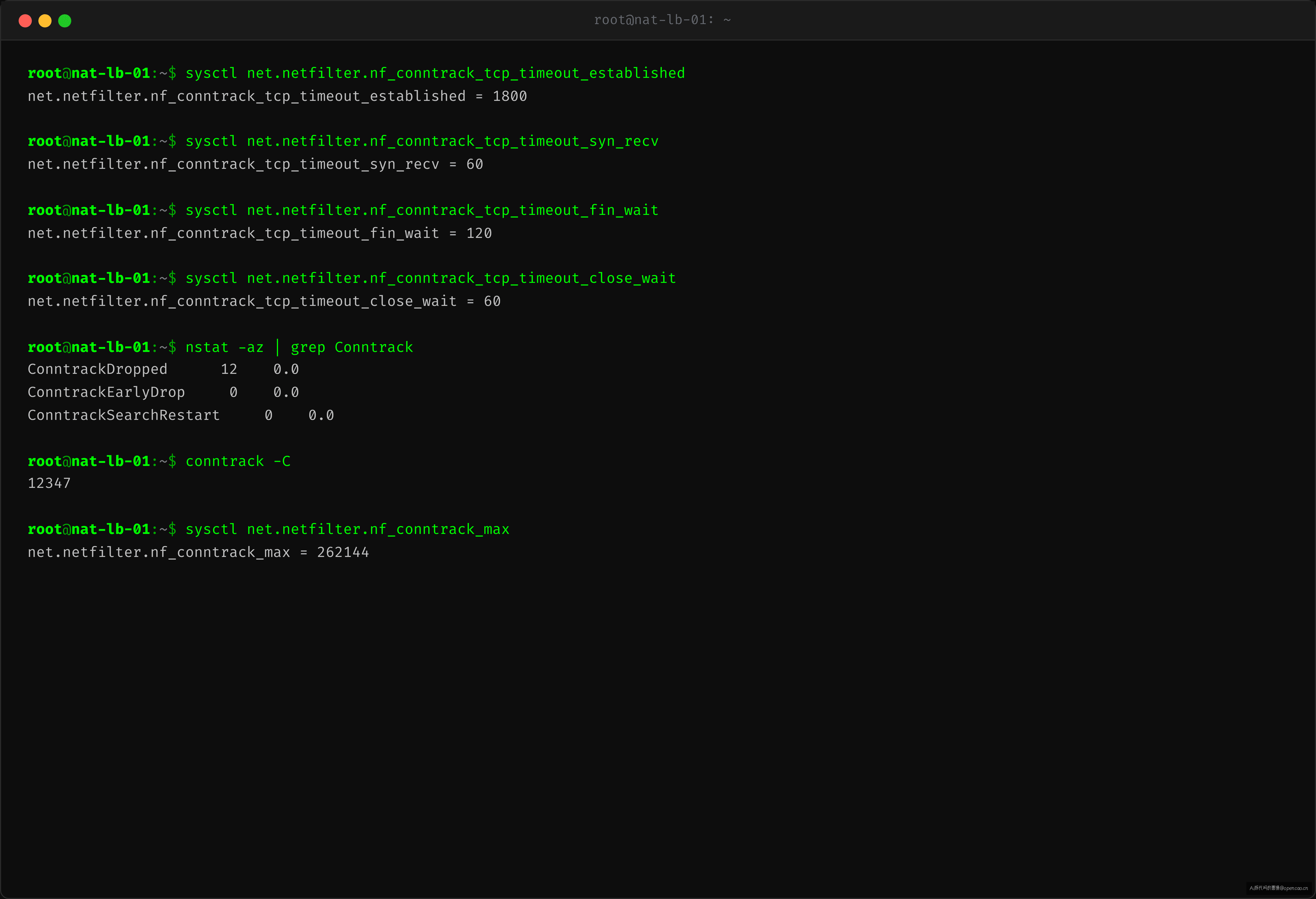
$ sysctl net.netfilter.nf_conntrack_tcp_timeout_established
net.netfilter.nf_conntrack_tcp_timeout_established = 1800
# conntrack 丢弃统计
$ nstat -az | grep Conntrack
ConntrackDropped 12 0.0
ConntrackDropped > 0 意味着 conntrack 曾经丢弃过数据包——可能就是因为表项过期。
3. 查客户端 keepalive 配置
# TCP keepalive 空闲时间——连接空闲多久后发第一个探测包
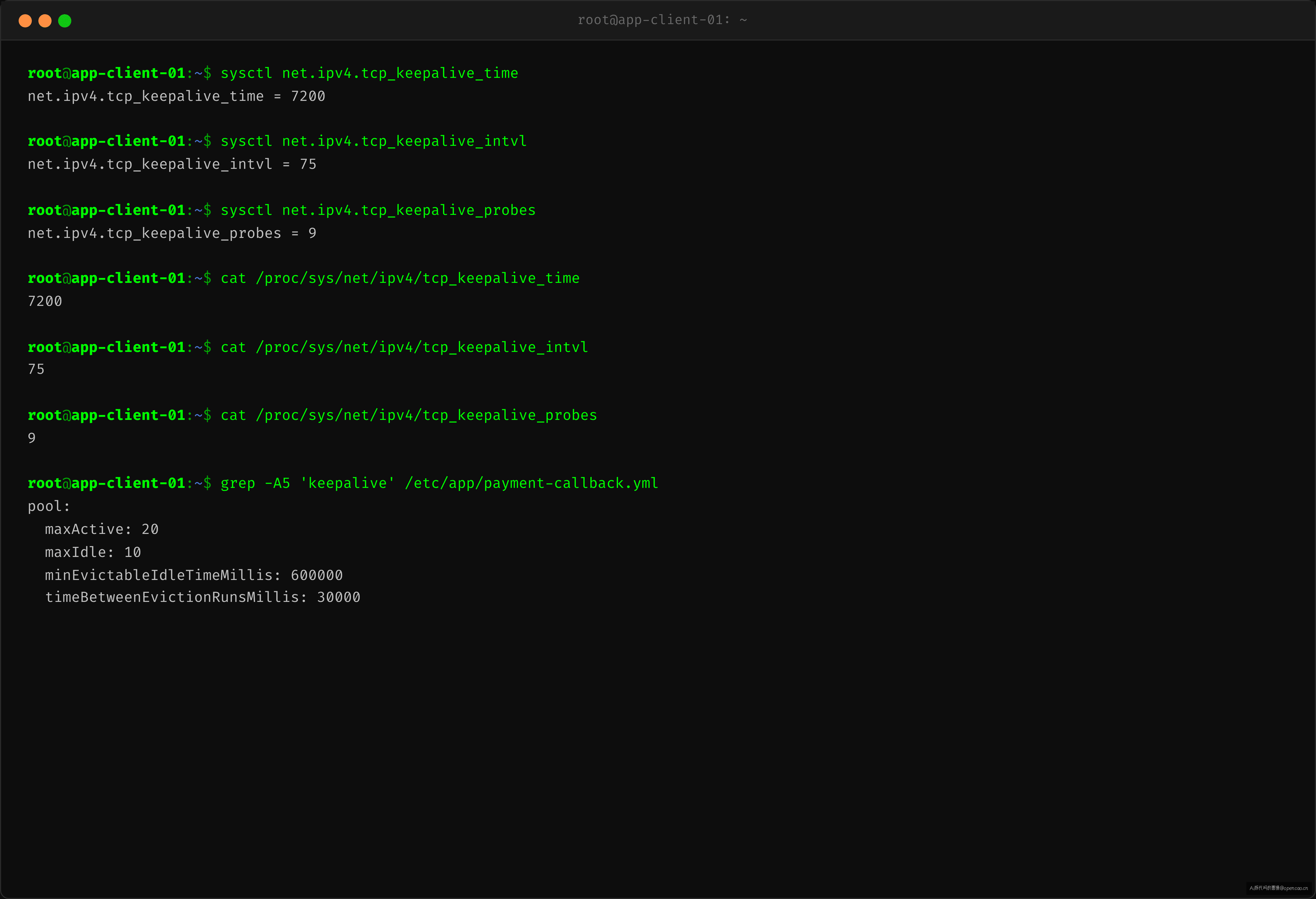
$ sysctl net.ipv4.tcp_keepalive_time
net.ipv4.tcp_keepalive_time = 7200
# keepalive 探测间隔
$ sysctl net.ipv4.tcp_keepalive_intvl
net.ipv4.tcp_keepalive_intvl = 75
# keepalive 最大探测次数
$ sysctl net.ipv4.tcp_keepalive_probes
net.ipv4.tcp_keepalive_probes = 9
对比 conntrack timeout(1800s)和 keepalive time(7200s),差距 5400s——中间有 1.5 小时的空窗期。
定位
哪一跳
中间 NAT/LB 设备(10.0.0.1)。它的 conntrack 表项过期后,客户端复用连接发包——中间设备查 conntrack 找不到对应流,认为这是个"非法包",直接 RST。
什么层
这个问题属于传输层 + 网络层的交汇: - 传输层:TCP keepalive 机制决定了客户端什么时候检测连接健康 - 网络层:conntrack(netfilter 框架)决定了中间节点什么时候"遗忘"这条流
不是应用层代码的问题——业务逻辑没有写错,连接池配置也没有出错。
内核路径
还原数据包在中间设备内核中的完整路径:
根本原因
conntrack timeout_established = 1800s (30min)
TCP keepalive_time = 7200s (2h)
↑ 差 5400s = 1.5h 的空窗期
连接空闲 30 分钟后,conntrack 清除表项。TCP keepalive 要等 2 小时后才发第一个探测包。在这 1.5 小时的空窗期里,任何复用连接的尝试都会触发中间设备发 RST。
金句:排查网络问题不是在抓包——是在还原数据包在每个节点内核中的命运。

通路
修复方案按控制力和实施成本排序:
| 方案 | 操作 | 内核参数路径 |
|---|---|---|
| ① 应用层心跳 | 业务代码加 ≤1800s(30min)的空闲探活 | 不涉及内核参数 |
| ② 缩短 TCP keepalive | sysctl -w net.ipv4.tcp_keepalive_time=600 |
/proc/sys/net/ipv4/tcp_keepalive_time |
| ③ 调大 conntrack 超时 | sysctl -w net.netfilter.nf_conntrack_tcp_timeout_established=7200 |
/proc/sys/net/netfilter/nf_conntrack_tcp_timeout_established |
方案①:应用层心跳(推荐)
在业务代码中实现连接池空闲探活,间隔设为 ≤1800s(30min):
// HikariCP 示例
HikariConfig config = new HikariConfig();
config.setConnectionTimeout(5000);
config.setKeepaliveTime(300000); // 5min 探活一次
config.setMaxLifetime(1800000); // 30min 连接最大寿命
好处:精确控制、不修改全局内核参数、只对业务连接生效。
方案②:缩短 TCP keepalive
# 全局修改
sysctl -w net.ipv4.tcp_keepalive_time=600
echo "net.ipv4.tcp_keepalive_time=600" >> /etc/sysctl.conf
# 或 setsockopt 单连接(Java 方式)
Socket socket = new Socket();
socket.setKeepAlive(true);
// Java 不支持设置 keepalive 间隔——需要 JNI 或系统级配置
方案③:调大 conntrack 超时(需中间设备权限)
# 在 NAT/LB 设备上执行
sysctl -w net.netfilter.nf_conntrack_tcp_timeout_established=7200
echo "net.netfilter.nf_conntrack_tcp_timeout_established=7200" >> /etc/sysctl.conf
监控
# 定期检查 conntrack 丢弃计数
nstat -az | grep Conntrack
# 告警阈值:ConntrackDropped > 0
# 查看当前 conntrack 使用率
echo "当前 conntrack 条目: $(conntrack -C)"
sysctl net.netfilter.nf_conntrack_max
下篇我们聊 keepalive 的另一个坑——Nginx 的 Content-Length 与上游实际 body 不匹配,导致 upstream keepalive 池被毒化。原因不在网络层,在 HTTP 协议的语义违规。
附:完整排查命令清单
# 1. 看连接状态
ss -tlnp | grep <port>
# 2. 抓 RST 包并确认来源
tcpdump -i eth0 port <port> -c 10 -nn 'tcp[tcpflags] & tcp-rst != 0'
# 3. 查 conntrack
conntrack -L | grep <server_ip>
sysctl net.netfilter.nf_conntrack_tcp_timeout_established
nstat -az | grep Conntrack
# 4. 查 TCP keepalive 配置
sysctl net.ipv4.tcp_keepalive_time
sysctl net.ipv4.tcp_keepalive_intvl
sysctl net.ipv4.tcp_keepalive_probes
# 5. 修复后验证
# 缩短 keepalive 时间
sysctl -w net.ipv4.tcp_keepalive_time=600
# 或调大 conntrack 超时
sysctl -w net.netfilter.nf_conntrack_tcp_timeout_established=7200


