
Nginx Content-Length 与实际 body 不匹配导致 upstream keepalive 池中毒与连接泄漏
场景:Nginx 反代部分请求 502 / body 错乱 / 上游报"invalid header field" | 路径:tcpdump → keepalive 连接请求边界错位 → Content-Length 不匹配 → Nginx event-driven state machine 未校验 socket 残留
上篇我们看了中间层通过 conntrack 超时静默发 RST 导致连接断裂的情况,这篇来看另一种连接异常——连接没断,但数据被悄无声息地污染了。
路况
第一反应——重启上游
线上某 Java 服务通过 Nginx 反代调用 Go 编写的上游服务。下午两点,监控告警炸了:
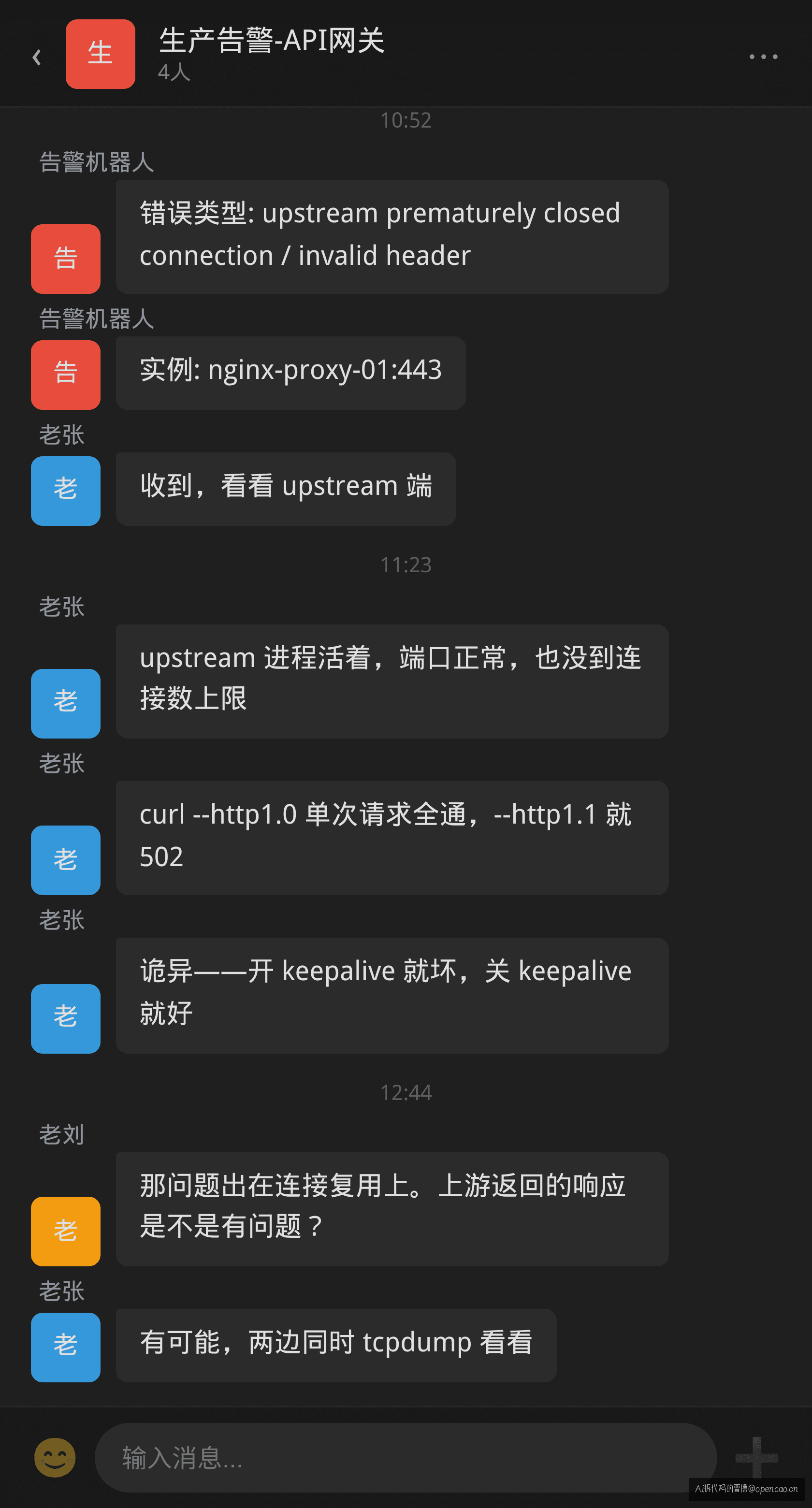
排障的人登录上去,ss -tlnp 看 upstream 端口正常监听,进程活着。curl --http1.0 单次请求通过。重启上游服务,好了。
第二天同一时段,告警又来了。
规律不是按流量比例触发——低峰期反而更容易出现。重启能好 2-3 小时,然后复发。如果用 curl --http1.1 测,直接 502。
用数字说话
监控面板上两条关键曲线:
- upstream 502 率:从 0% 突增到 3-5%,持续波动,没有明显业务流量规律
- upstream keepalive 复用次数:出问题的连接总是那些复用次数很高的连接。新建连接的请求全通
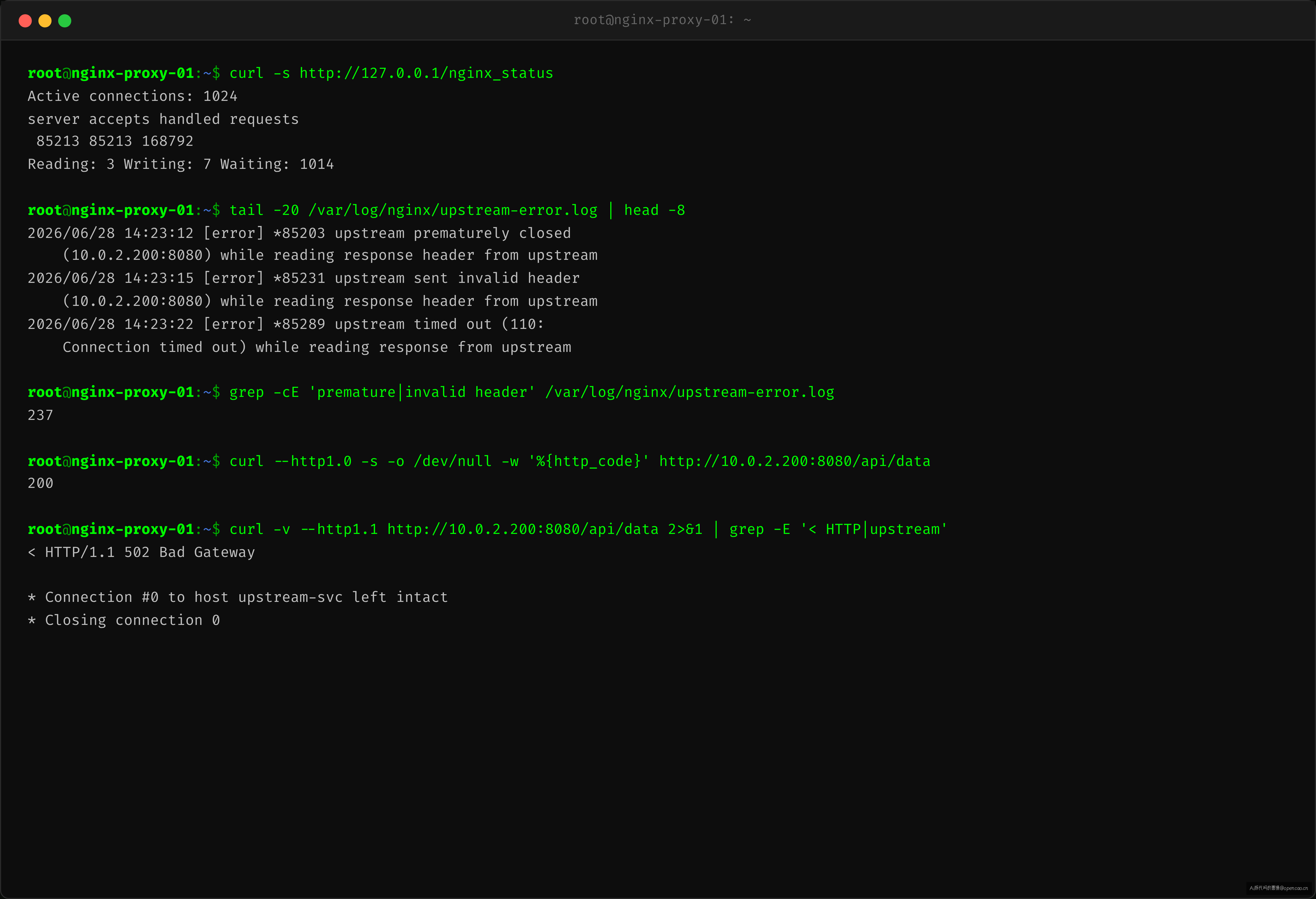
常态排查走不通
□ 端口监听? ➔ ss -tlnp → 正常
□ 进程活着? ➔ ps aux | grep go → 正常
□ 连接数? ➔ ss -s → 正常,未到上限
□ 内存/CPU? ➔ 指标正常
□ 应用日志? ➔ 上游服务日志无业务异常
□ 单次请求? ➔ curl --http1.0 全通
□ keepalive 请求? ➔ curl --http1.1 502
闭 keepalive 就好,开 keepalive 就坏——问题出在 keepalive 连接复用上,不是上游服务本身。那就在 Nginx 和上游之间抓包,看 keepalive 连接上到底发生了什么。
排查网络问题不是在抓包——是在还原数据包在内核中的命运。
回放
抓包
在 Nginx 机和上游机同时抓:
# Nginx 端
tcpdump -i any port 8080 -s0 -w nginx-upstream-keepalive.pcap
# 上游端
tcpdump -i any port 8080 -s0 -w upstream-side.pcap
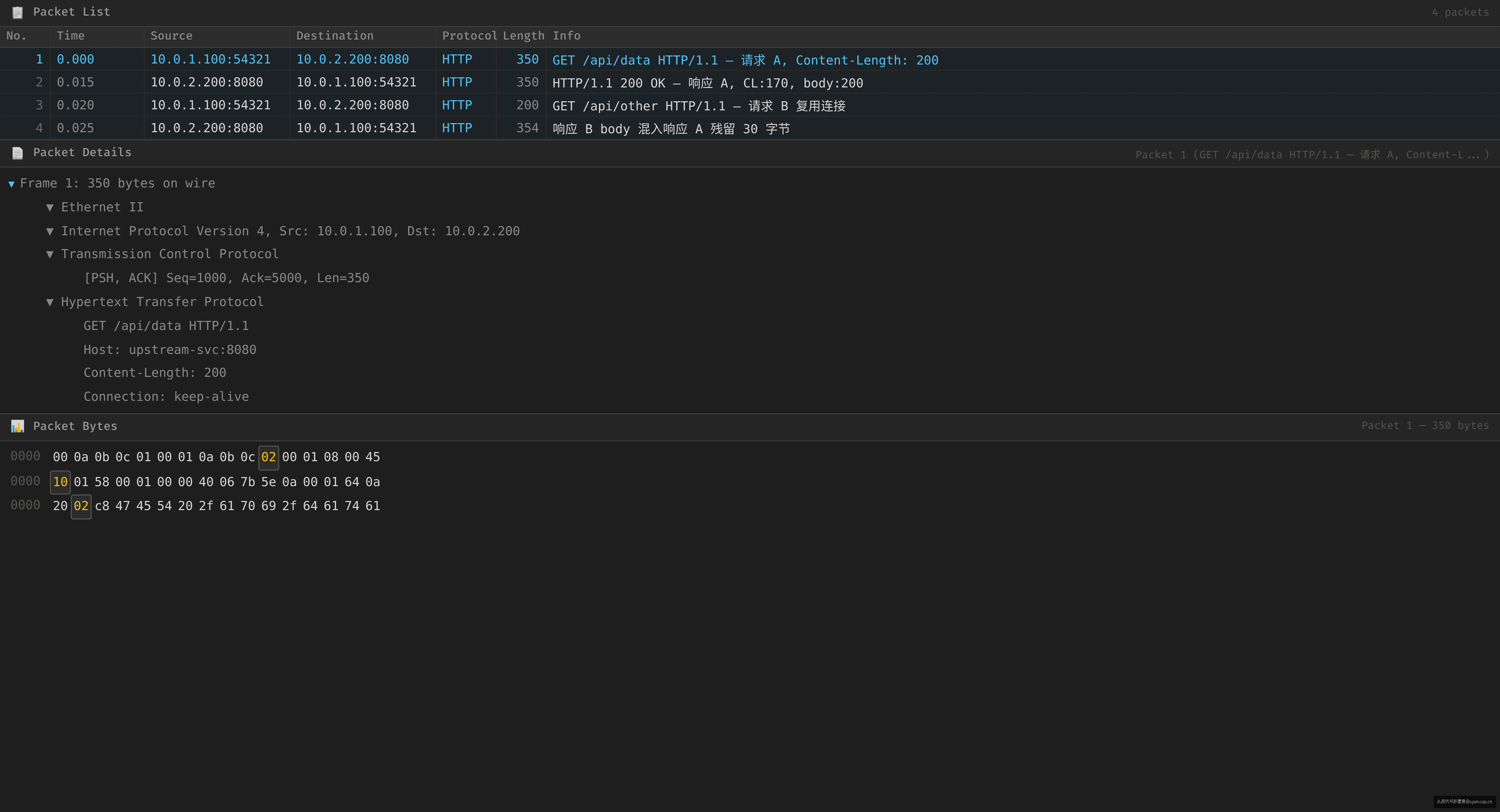
关键时序
T0.000 Nginx → upstream : 请求 A (GET /api/data, CL=200)
T0.015 upstream → Nginx : 响应 A (200 OK, CL=170, 实际 body=200)
T0.018 Nginx 读完 170 字节 → pipe 打标 upstream_done → 连接归还池
socket recv 缓冲区还剩 30 字节
T0.020 Nginx → upstream : 请求 B (复用同一连接)
T0.025 upstream → Nginx : 响应 B
T0.026 Nginx 读到的响应 B payload:
[30 字节 响应 A 残留] + [响应 B 的 header + body]
HTTP 解析器:这开头 '}{...}' 是什么?→ invalid header → 502
包序列
留意响应 A 的 Content-Length 和实际 payload 长度的差异:
# 请求 A:Nginx→upstream, PSH, len 350(header + 200 body)
# 响应 A:upstream→Nginx, PSH, len 350(header + 200 body, CL 写 170)
# Nginx 只读 header(150) + CL 指定的 170 body = 320 字节,留 30 在 socket
# 请求 B:Nginx→upstream, PSH, len 200(header + 50 body)
# Nginx 读响应 B 的 payload:先吐出 30 字节残留,再接响应 B 数据
证据:Content-Length 与实际 body 的差异
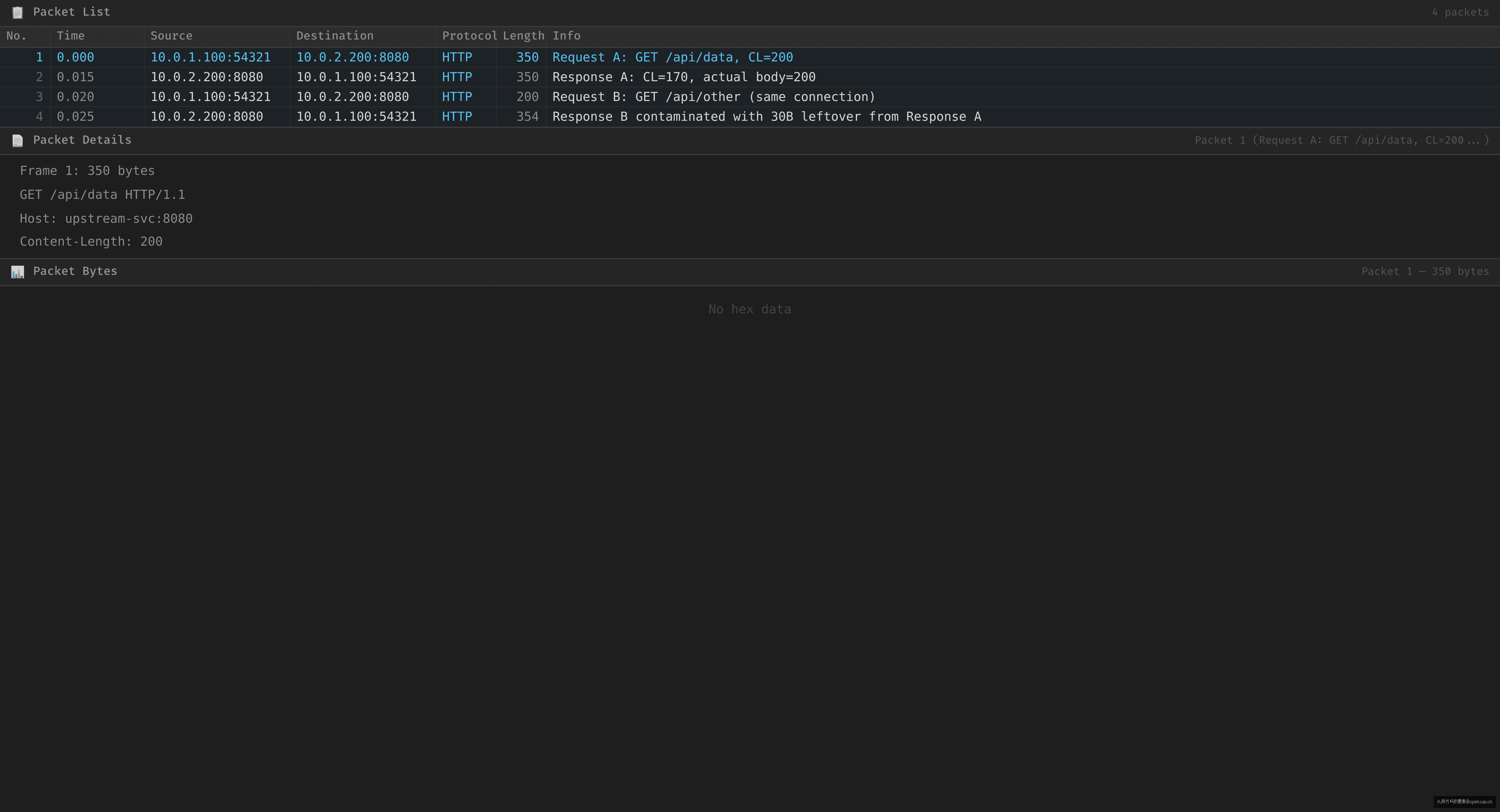
不是上游处理不过来,是上游发回的 Content-Length 和实际 body 不一致时,Nginx 按 Content-Length 消费完就认为「响应结束」,把连接还回 keepalive 池,但 TCP socket 里还有 30 字节残留。下一个复用到这条连接的请求,一上来就读到了残留数据。
🔍 路径:排查命令
看到上游报 header 解析失败 / body 错乱 / keepalive 连接间歇性 502,按以下顺序排查:
# 第一步:确认是否是 keepalive 相关
# 改 proxy_http_version 1.0 临时观察
# 如果 502 消失 → 问题在 keepalive 连接复用上
# 第二步:在 Nginx 端或上游端抓包,看请求边界
tcpdump -i lo -A port 8080 -c 50 -w /tmp/keepalive-trace.pcap
# 第三步:用 -A 看 payload 内容,检查下一个请求的开头
tcpdump -r /tmp/keepalive-trace.pcap -A port 8080 | head -100
# 正常:请求 B 的 payload 以 "GET" 或 "POST" 开头
# 异常:请求 B 的 payload 开头是上一个响应残留("}\n" 或 "\r\n")
# 第四步:打开 Nginx debug 日志观察 keepalive 池
echo "error_log /var/log/nginx/debug.log debug;" >> nginx.conf
nginx -s reload
tail -f /var/log/nginx/debug.log | grep -E "keepalive|free keepalive"
预期输出:
正常 keepalive 归还日志:
[debug] ngx_http_upstream_keepalive.c:XXX keepalive pool push: fd 12, reuse count 3
异常情况(Nginx 不会报"有残留",因为根本没检查这个):
[debug] ngx_http_upstream_keepalive.c:XXX keepalive pool push: fd 12, reuse count 3
Nginx 不会在这里输出 "有残留数据"——它根本不知道。证据只能从 tcpdump 看到。
定位:根因
哪一跳
Nginx → upstream 的中间代理层。不是上游宕了,是上游返回了错误的 Content-Length。
什么层
这个问题横跨应用层(HTTP Content-Length 语义)+ 传输层(TCP stream 边界 + keepalive 连接复用)。它不是传统意义的网络问题,但它暴露在抓包工具之下——你只有在 TCP 字节流层面才能看到请求边界错位的证据。
Nginx 源码行为:为什么它不检查
Nginx 的 upstream keepalive 模块(ngx_http_upstream_keepalive_module)是一段事件驱动的状态机,核心在 ngx_event_pipe.c:
// ngx_event_pipe.c — pipe 读完 content_length 就认为上游响应完毕
if (p->upstream_done) {
// Content-Length 指定的字节数已读完 → 归还连接
ngx_http_upstream_keepalive_close_handler(r);
}
upstream_done 只由 Content-Length 驱动——Nginx 读到指定字节数后就设为 Done,完全不检查 TCP socket 是否还有未读数据。
原因:Nginx 的事件驱动架构决定了 ngx_event_pipe 是一个 state machine,content_length_n 是唯一的计数器。计数器和实际数据对不上时,state machine 不会报错,只会读错位置。Nginx 的哲学是"上游告诉我多少字节,我就消费多少"——信任 Content-Length 的语义,不自作聪明做二次校验。
两种 mismatch 路径:
Content-Length 小于实际 body(池中毒路径):
响应 A CL=170,实际 body=200
Nginx 读到 170 → pipe 达到 content_length_n → upstream_done = 1
归还连接,socket 缓冲区还剩 30 字节
Content-Length 大于实际 body(读超时路径):
响应 A CL=200,实际 body=170
Nginx 读 170 → 等读事件 → upstream 不发更多 → read timeout → upstream_done = 1
归还连接(缓冲区干净,但多了 30s 超时延迟)
——相对无害,只是慢
keepalive 池管理的源码也不会检查 socket 是否 clean:
// ngx_http_upstream_keepalive.c — 归还逻辑
// ❌ 从不检查 recv 缓冲区是否为空
static void
ngx_http_upstream_keepalive_close_handler(ngx_event_t *ev)
{
// 检查连接是否被 client 关闭了
// 检查连接是否 idle 超时了
// 但不检查 socket 里还有数据没读完
}
池中毒的完整时序

应用层 vs 网络层
这个问题属于应用层范畴——根因是上游返回了错误的 Content-Length。但网络排查工具(tcpdump)是发现它的唯一手段,因为应用层日志只会报 "header 解析失败",不会告诉你 "TCP socket 里多了 30 字节残留"。
路况段的 502 / body 错乱 ← 业务层表象
↓
回放段抓包发现请求边界错位 ← tcpdump(网络层)
↓
定位段确认是 Content-Length 与实际 body 不一致 ← 应用层根因
↓
结论:网络工具发现,应用层解决
通路:修复 + 监控
方案一(根治):保证上游响应 Content-Length 正确
- Java:
HttpServletResponse.setContentLength(n)的值必须与实际getOutputStream().write()的字节数一致 - Go:
http.ResponseWriter自动计算 CL,但你如果在WriteHeader()之后手动修改 body,务必确保 body 长度与 CL 匹配 - 最快验证:对上游发一次请求,
wc -c < response_body与响应头的 Content-Length 对比
方案二(Nginx 侧防护)
upstream backend {
server 10.0.2.200:8080;
keepalive 32;
keepalive_requests 100;
}
location /api/ {
proxy_pass http://backend;
proxy_http_version 1.1;
proxy_set_header Connection "";
# 遇到 502 重试其他节点
proxy_next_upstream http_502 http_503 error timeout;
proxy_next_upstream_tries 3;
}
keepalive_requests 100 限制每条连接的最大请求数。即使池中毒,最多 100 个请求后连接自动关闭重建——用超时来自愈。
方案三(紧急止血)
proxy_http_version 1.0;
# 关闭 keepalive 后每次请求建新连接,无毒池风险
# 代价:增加建连开销,延迟略微上升。仅临时止血
监控项
| 指标 | 来源 | 阈值 | 说明 |
|---|---|---|---|
| upstream 502 率 | Nginx 监控 | > 0.1% 告警 | 池中毒的宏观表现 |
| keepalive 复用计数 | Nginx status | 异常集中在高复用连接 | 池中毒的微观特征 |
| tcpdump 请求边界错位 | 定期抓包采样 | > 0 即需调查 | 唯一能直接确认的方法 |
一句命令
# 怀疑 keepalive 池中毒?上游端抓 50 个包,看请求开头是否混杂残留
tcpdump -i any port 8080 -A -c 50 | grep -E "^GET|^POST" | head -5
# 正常输出全是 GET/POST
# 如果混入 "}\n" 或 "\r\n" → 请求边界错位 → Content-Length 不匹配
下篇我们聊 TCP 半连接队列满导致大量连接超时——SYN 已经到了网卡,内核为什么等了 500ms 才回复。


