
Pod 启动慢——Init Container / 镜像拉取策略优化
场景:灰度 5% 流量 → 超时率飙升 → 回滚 → 新版 Pod 启动慢了 3 分钟 路径:坐标 → 分层 → 路径 → 定位 → 标点
以下排查基于 K8s v1.25,容器运行时为 containerd 1.6。
坐标
上篇我们看了 Pod 一直 Pending 的根本原因——调度器(scheduler)因为资源或 PVC 问题无法分配节点,Pod 连调度这关都过不去。这回换个角度:Pod 调度成功了,从 Running 到 Ready 却花了 3 分钟——这又是 K8s 哪一层在拖后腿?
灰度上线后的异常告警
下午 2 点,支付团队将 payment-service v3.2 灰度上线到生产集群,只放了 5% 的流量。2 分钟后 SRE 群告警机器人弹出消息:
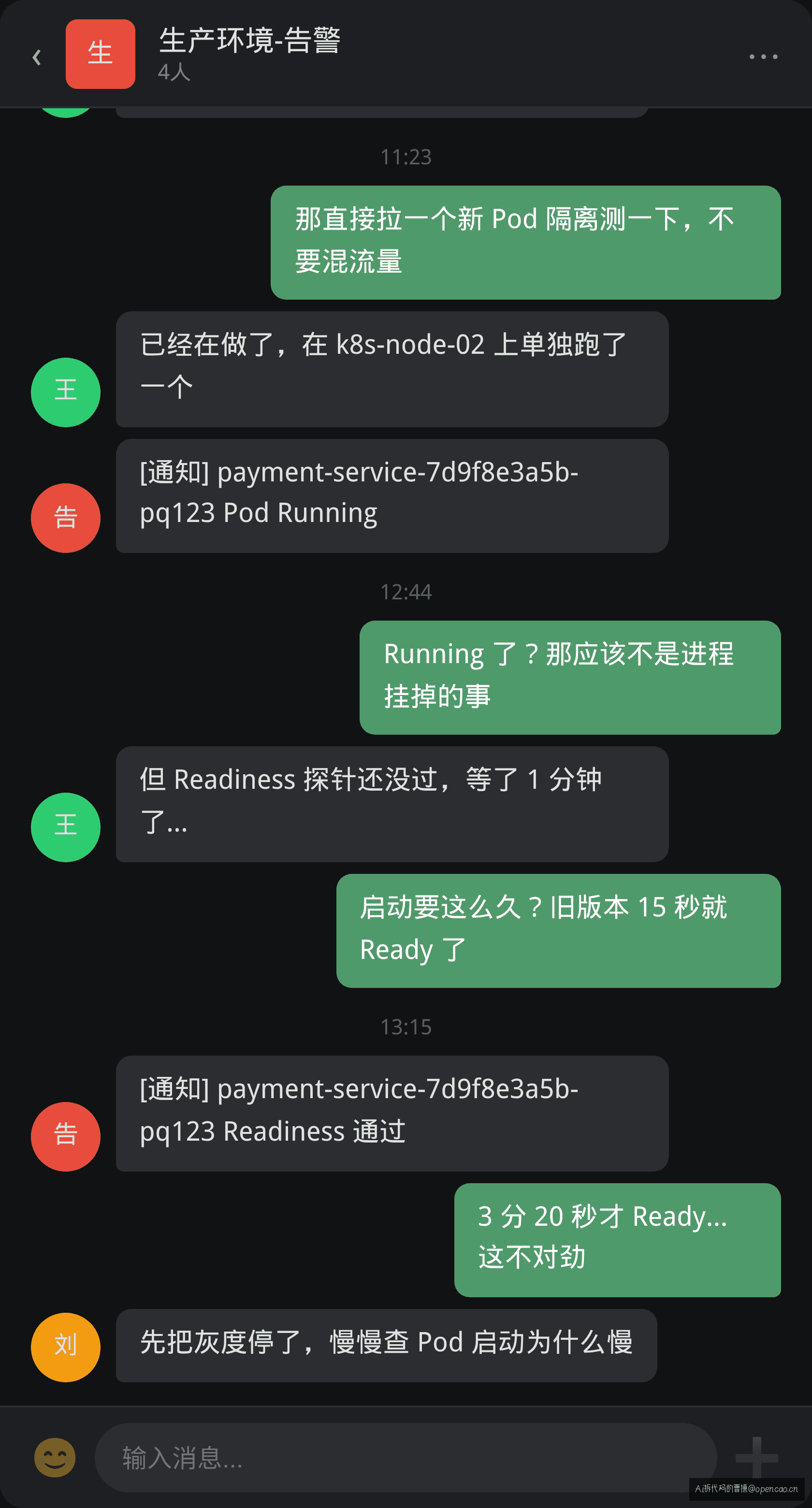
接口超时率从 0.1% 飙升到 8.2%,部分用户支付失败。回滚到 v3.1,超时率秒回 0.1%。确认是新版本的问题。
这篇的关键数字:旧版本 15s Ready,新版本 3m20s Ready。差了 13 倍。Init Container 占了 95 秒,镜像拉取占 90 秒,两者合计占 Pod 启动总耗时的 92%。
团队直接重启了一个新版本的 Pod 做隔离验证——在旧版本还在正常服务的节点上单独跑一个新版本 Pod。结果一样:Pod 状态很快变成 Running,Readiness 探针却连续超时,直到 3 分 20 秒后才真正 Ready。
一个 Pod 启动花了 3 分 20 秒。旧版本只需要 15 秒。
第一层线索:Pod 启动时序
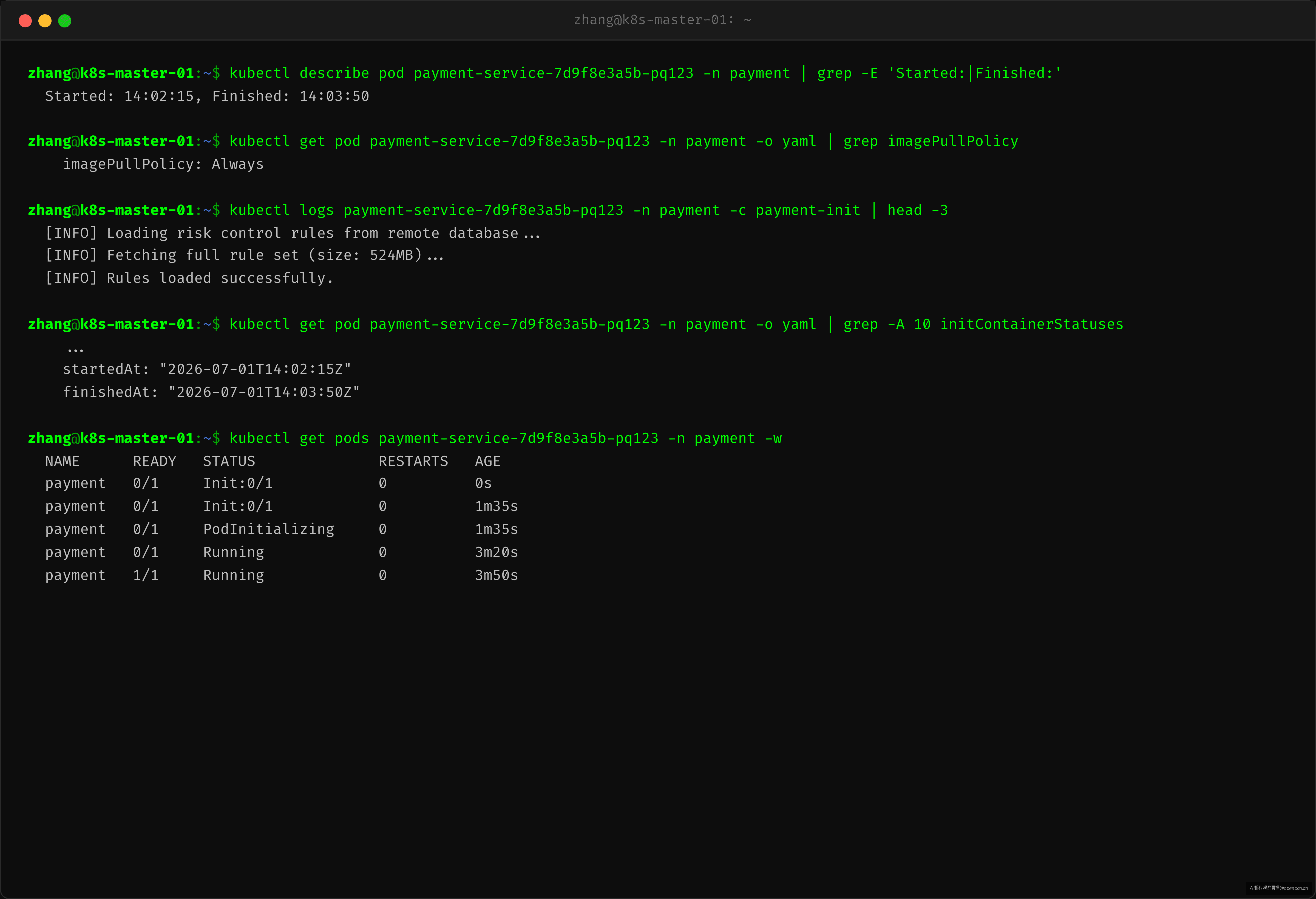
kubectl describe pod 的输出暴露了第一层线索:
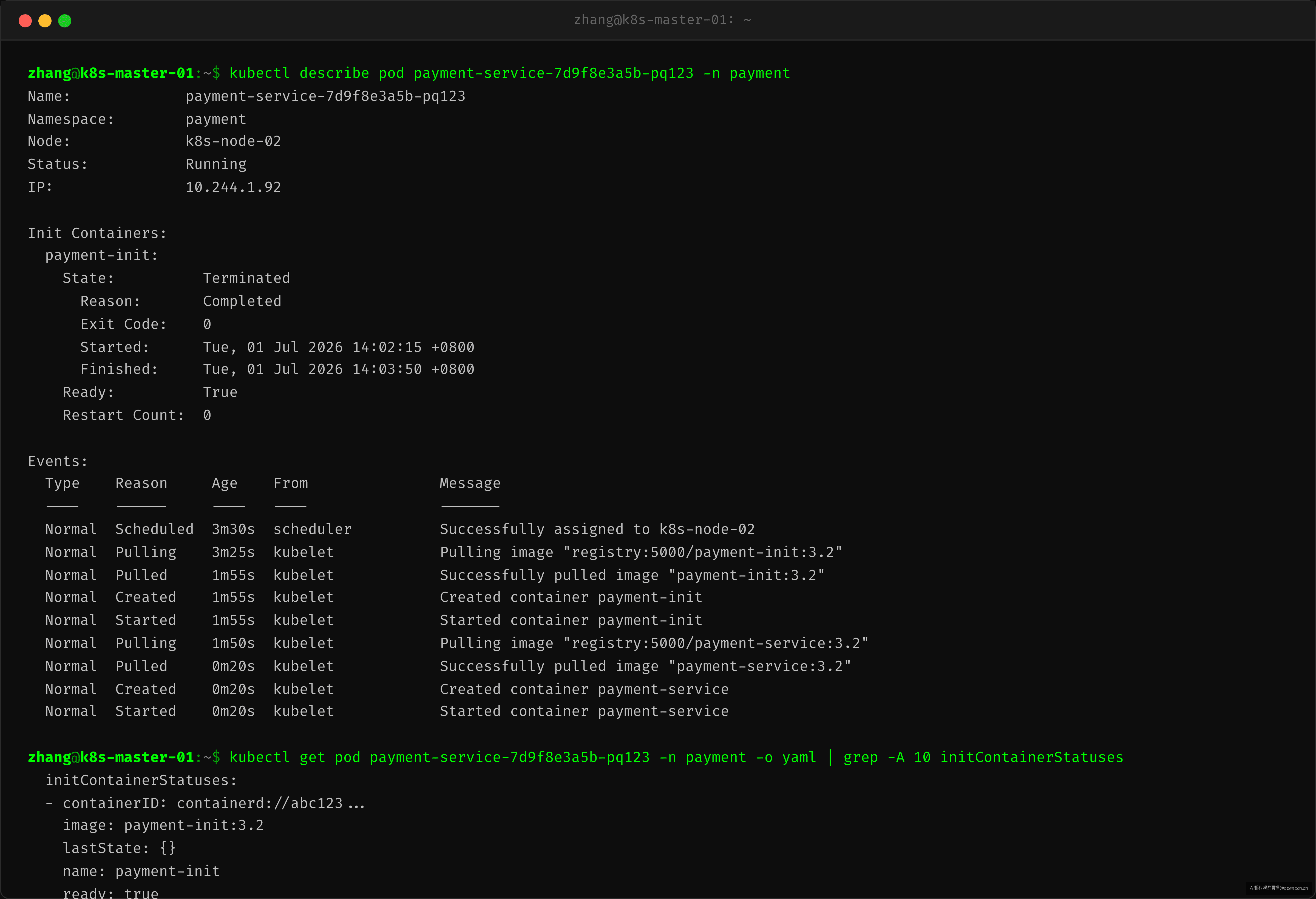
关键看几个时间戳。从 Events 段可以看到两个异常时间差:
Pulling(Init 容器)→Pulled:花了 90 秒拉取 Init Container 的镜像- Init Container 从
Started到 exit(0):花了 1 分 35 秒——Init Container 在做什么? - 主容器
Pulling→Pulled:又花了 90 秒拉取主容器镜像
但 Events 只显示了"什么时候拉完",没显示 Init Container 自身的执行耗时。截图中的 Init Container 状态段给出了精确时间——Init Container 执行了 1 分 35 秒。
加上主容器镜像拉取的 90 秒,再加上 Readiness 探针首次探测通过的几十秒——总耗时就是这么堆出来的。
两个嫌疑对象
现在有两个嫌疑对象需要分清楚:
- Init Container:kubelet 在 Pod Sandbox(Pod 的隔离环境,由 CRI 运行时创建)创建完后,串行启动 Init 容器。所有 Init 容器必须依次 exit(0),一个没跑完下一个不会启动,更不会启动主容器。
- 镜像拉取:kubelet 调用 CRI(Container Runtime Interface,K8s 与容器运行时的通信接口)拉取镜像。ImagePullPolicy=Always 时,每次创建容器 kubelet 都让 CRI 重新拉取——哪怕镜像根本没变。
两个因素叠加,Pod 启动时间从 15 秒膨胀到 3 分 20 秒。
分层
Pod 启动慢不能只查 Pod 层。Pod Running 但不可用——根因可能在 Pod 内(Init Container)、在 CRI 层(镜像拉取)、或在 Node 层(磁盘 I/O)。一层层来,不跳步。
Pod 启动的完整时序
先从整体看 Pod 从创建到 Ready 经过哪些阶段:
用 kubectl get pods -w 可以实时看到 Pod 状态的变化过程:
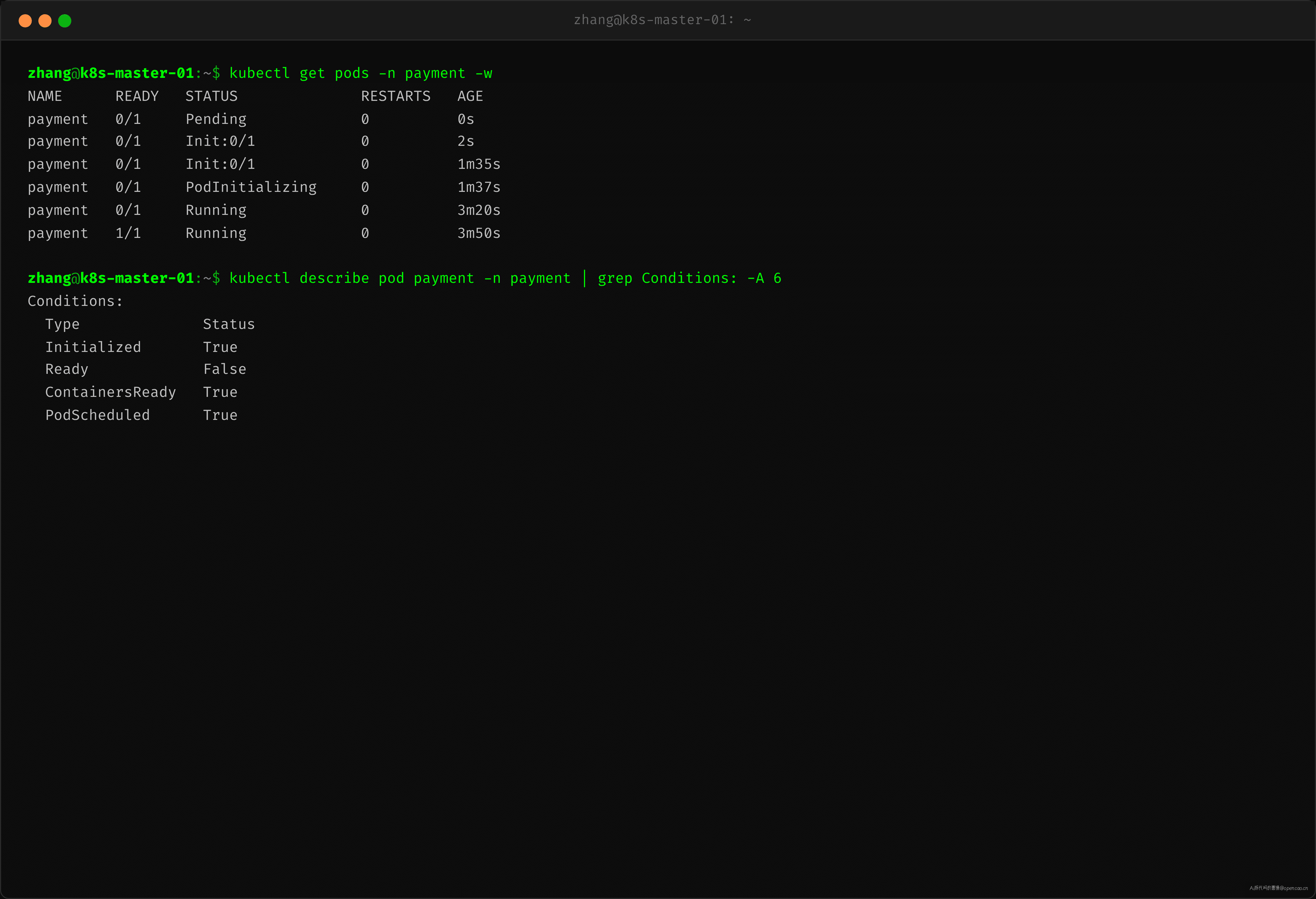
Pod 状态依次经过 Pending → Init:0/1 → PodInitializing → Running → Ready。从时间戳可以看到,Init:0/1 状态持续了 1 分 35 秒,PodInitializing 到 Running 花了约 1 分 43 秒——两者占总启动时间的 92%。
kubelet 在 Pod Sandbox 创建完成后按以下顺序推进:
- 串行启动 Init 容器(kubelet 管理),每个必须 exit(0)
- Init 容器全部完成后,kubelet 并行启动主容器和 sidecar
- kubelet 调用 CRI(containerd)拉取主容器镜像
- containerd 通过 snapshotter(快照器,管理容器文件系统的组件)解压镜像层到 overlay 文件系统
- 主容器启动后,Readiness 探针(kubelet 定期检查)通过,Pod 标记为 Ready
其中 1、3、4 是三个主要耗时环节。
第一层(Pod):Init Container 在做什么
kubectl logs -n payment payment-service-xxxx -c payment-init 看到了 Init Container 的执行内容:
Init Container 在做一个全量操作——从远程数据库拉取风控规则数据,加载到本地文件。这个数据集约 500MB,每次 Pod 启动都全量拉一次。
kubelet 的行为:Pod Sandbox 就绪后立即执行 Init 容器,串行。Init Container payment-init 没有 exit(0) 之前,主容器的镜像拉取根本不会开始。
这就是第一个卡点——Init Container 的设计把串行等待时间拉到了 1 分 35 秒。
第二层(CRI):镜像拉取为什么慢
主容器的镜像拉取花了 90 秒,但代码和依赖都没变——为什么还要 90 秒?
罪魁祸首是 ImagePullPolicy=Always。
查看 Pod 的 YAML 配置:
spec:
containers:
- name: payment-service
image: registry:5000/payment-service:3.2
imagePullPolicy: Always # ← 每次重启都重新拉取
kubelet 在启动主容器时检查 ImagePullPolicy:
- Always:kubelet 每次都调用 CRI 的 PullImage 接口,containerd 重新拉取镜像
- IfNotPresent:kubelet 让 CRI 只拉取本地不存在的镜像,已存在则直接使用
- Never:kubelet 不触发拉取,本地没有就报 ErrImageNeverPull
ImagePullPolicy 的默认值:
- 镜像 tag 为 latest:默认为 Always
- 其他 tag(如 :3.2):默认为 IfNotPresent
payment-service:3.2 不是 latest,但 YAML 里显式写了 Always。每次重启 Pod,kubelet 都调用 containerd 重新拉取镜像。
containerd 在 ImagePullPolicy=Always 时的流程:
- 检查远端 manifest(镜像清单,描述镜像层和配置的文件)
- 逐层对比 layer digest(层摘要,内容的 SHA256 哈希值)——即使镜像没变也走一遍对比
- 确认没有新增层后,标记为"已是最新"
- 调用 snapshotter 解压到 overlay 文件系统
虽然不下载新数据,但 manifest 检查 + layer digest 对比 + snapshotter unpack 加起来,一个 2GB/40 层的镜像就要 90 秒。
第三层(Node):磁盘 I/O 瓶颈
Pod 启动慢的第三层排查要登到 Node 上。镜像拉取不只是"下载完成"——containerd 还要通过 snapshotter(快照器,管理容器文件系统的组件)把镜像层解压到 overlay 文件系统。对于 2GB/40 层的镜像,unpack 阶段会产生大量小文件写入,IOPS 成为瓶颈。
用 iostat 看在 Pod 启动期间的 Node 磁盘状况:
Device r/s w/s rkB/s wkB/s aqu-sz %util
vda 342.0 45.0 142000 52000 12.3 92.5
%util 接近 100%,aqu-sz(平均队列长度)12.3——I/O 请求明显排队。更精确的排查可以看 containerd 的 unpack 日志:
journalctl -u containerd --since "5 min ago" | grep -E "unpack|snapshot"
输出类似于:
Jul 01 14:02:20 k8s-node-02 containerd[1234]: unpacking layer sha256:abc...
Jul 01 14:02:45 k8s-node-02 containerd[1234]: unpacking layer sha256:def...
Jul 01 14:03:50 k8s-node-02 containerd[1234]: unpacking layer sha256:ghi...
每行之间的时间间隔就是每层解压耗时。40 层镜像即使没有网络下载,仅本地解压就可能超过 60 秒。snapshotter 的工作方式是:
- containerd 从镜像仓库拉取 layer blob
- snapshotter 将每个 layer 解压为独立的 overlayfs 层目录
- 所有层通过 overlay mount 合并为容器可读的 rootfs
- 层数越多、单层文件越多,inode 和 IOPS 消耗越大
如果 Node 使用的是 SSD,60 秒解压 40 层属于正常范围。如果是 HDD 或 IOPS 受限的云盘,unpack 时间可能翻倍——这也是为什么同一套配置在压测环境没问题(SSD+低负载),到了生产环境(共享云盘+多 Pod 并发拉取)就暴露出来的常见原因。
分层排查顺序总览
不同层级的排查要按顺序来,不跳层。
| 层级 | 排查目标 | 关键命令 |
|---|---|---|
| Pod 层 | Init Container 耗时和日志 | kubectl describe pod 看 Init 容器时间戳,kubectl logs -c <init> 看执行内容 |
| CRI 层 | 镜像拉取耗时和策略 | crictl inspect 看容器创建时间,检查 ImagePullPolicy |
| Node 层 | 磁盘 I/O 和 snapshotter | iostat -x 1 看磁盘利用率,检查 containerd 日志 |
路径
下次遇到 Pod Running 但 Readiness 探针迟迟不通过,先按这个命令集排查。每个命令都带 -o wide 或 -o yaml,不只用默认输出。
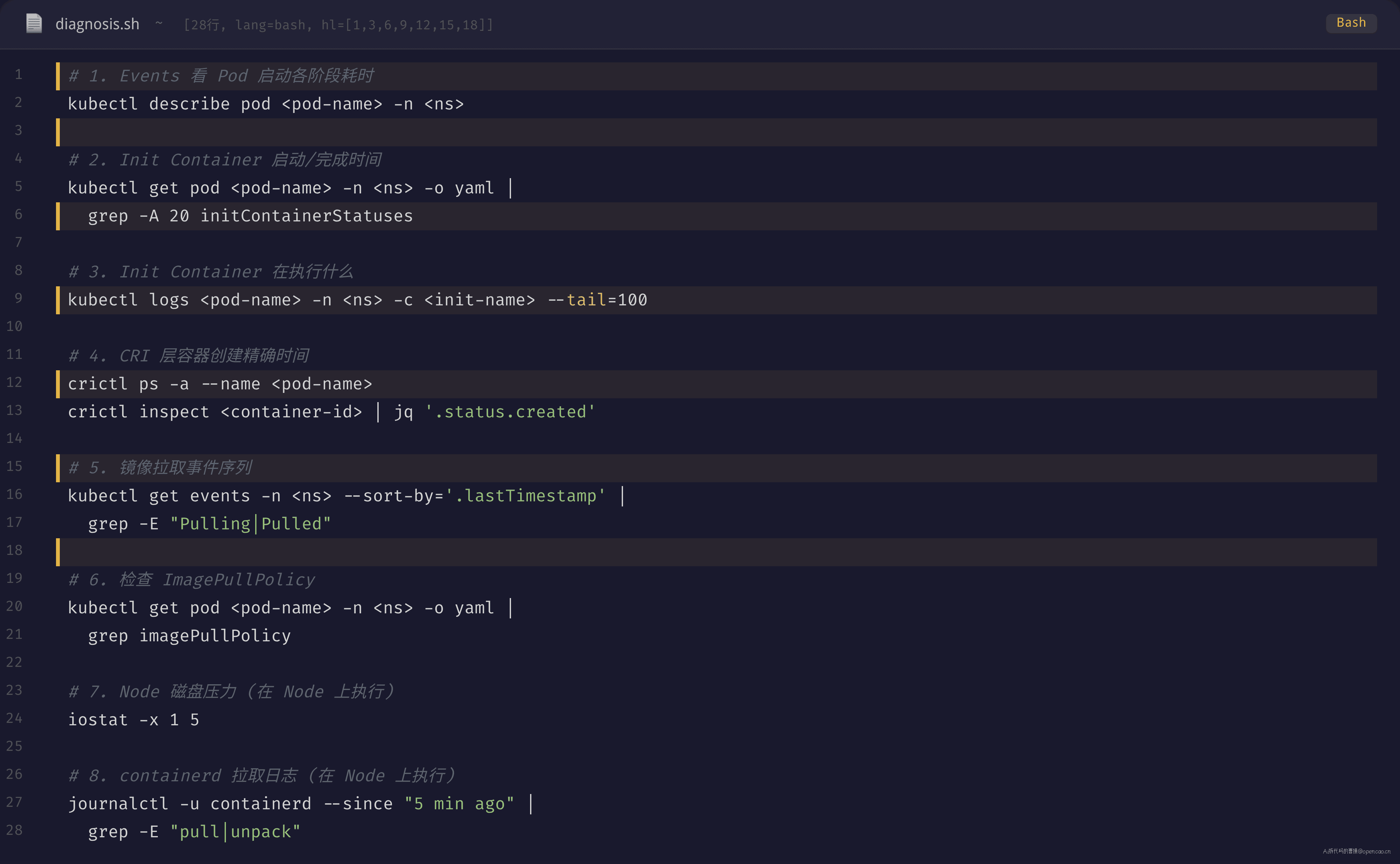
异常判断标准
| 命令 | 正常值 | 异常信号 |
|---|---|---|
kubectl describe pod Events 的 Pulling→Pulled |
< 10s | > 30s → 镜像拉取慢 |
| Init Container Started→Finished | < 5s | > 30s → Init Container 执行耗时过大 |
iostat %util |
< 60% | > 90% → 磁盘 I/O 瓶颈 |
定位
Pod 启动慢的问题最容易踩两个误判,一层比一层隐蔽。两个都避开才算真正定位。
❌ 误判 A:"改 ImagePullPolicy=IfNotPresent 就行"
第一直觉:ImagePullPolicy=Always 导致每次拉取,改成 IfNotPresent 就省了 90 秒。
改了。重建 Pod——主容器镜像不再拉取,确实省了 90 秒。但 Pod 启动时间从 3 分 20 秒降到了 1 分 50 秒——还是比旧版本的 15 秒慢了一个数量级。
1 分 50 秒里的大头是什么?Init Container 的 1 分 35 秒。
根因不在镜像拉取策略——即便不拉取镜像,Init Container 的全量数据加载仍然占着串行时间段。ImagePullPolicy 只是背锅的,Init Container 的设计才是主犯。
❌ 误判 B:"那优化镜像分层"
第二层直觉:镜像太大(2GB/40 层)导致 containerd 解压慢,优化镜像分层能提速。
优化了——拆了基础层和应用层,镜像降到了 600MB/15 层。但 Init Container 还在全量拉数据,1 分 35 秒没变。
实际上镜像解压在 Init Container 退出后、主容器启动前就已经完成了。真正阻塞 Readiness 的是 Init Container 的执行时间。
✅ 正确的排查路径
先看 Init Container 在执行什么!→ 再看镜像拉取本身耗时 → 最后看 Node 磁盘 I/O
分层排查的顺序不能跳:
- 第一刀切在 Pod 层:Init Container 耗时是不是异常。如果是它在做全量操作,改镜像策略和分层都没用
- 第二刀切在 CRI 层:ImagePullPolicy 和镜像拉取耗时。但只有先确认 Init Container 没问题,这一刀才有意义
- 第三刀切在 Node 层:磁盘 I/O 是否达到瓶颈。通常这是叠加因素,不是主因
两个误判的共同模式:只看表象不看时序。Always→IfNotPresent 解决了第一个 90 秒,但 Init Container 的 95 秒才是主阻塞点。不按时序分层排查,找到的永远是背锅的不是元凶。
排查 K8s 问题不是在查 Pod——是在查 Pod 所在的整条链路。
标点
修复方案按排查结果来,分三步。
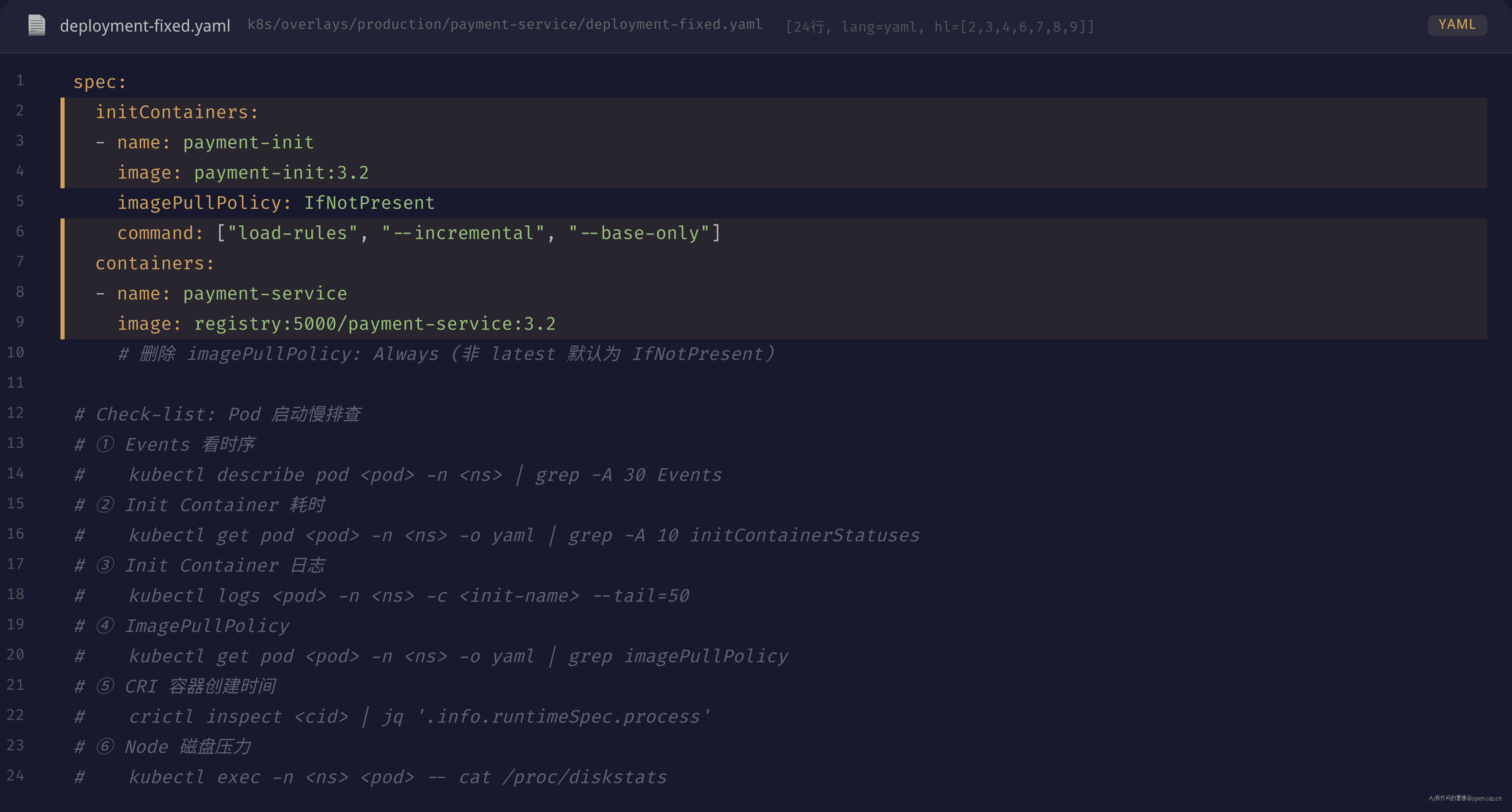
修复 1:Init Container 拆增量
全量加载改为增量预热。Init Container 只拉取最近 24 小时变更的风控规则增量,首次启动也只需要加载基础规则集(从 500MB 降到 15MB)。全量数据迁移改到应用启动后的异步任务——进入 Ready 状态后再后台加载,不对 Pod 启动过程产生阻塞。
修复 2:合理设置 ImagePullPolicy
生产环境 tag 为 semver(如 :3.2)的镜像,ImagePullPolicy 设为 IfNotPresent 或直接删除该字段(非 latest tag 默认为 IfNotPresent):
spec:
containers:
- name: payment-service
image: registry:5000/payment-service:3.2
imagePullPolicy: IfNotPresent # 或删除此行
需要强制更新时才手动改 tag 或设置 imagePullPolicy: Always 触发一次。
修复 3:镜像分层优化
将基础 JDK 层、应用依赖层、应用代码层分离。公共层复用后减少每 Pod 的解压量:
# Base layer — 几乎不变
FROM eclipse-temurin:17-jre AS base
RUN apt-get update && apt-get install -y --no-install-recommends ... && rm -rf /var/lib/apt/lists/*
# Dependencies layer — 低频变化
FROM base AS deps
COPY lib/ /app/lib/
# Application layer — 高频变化
FROM deps AS app
COPY target/payment-service.jar /app/
公共基础层只拉一次,后续 Pod 启动只解压新增层。
故障排查的终点不是修好了——是把排查路径写成 check-list。
下篇我们聊 Pod 状态 CrashLoopBackOff——容器挂了但 kubectl logs 拿不到日志怎么办。容器退出后日志还在不在?kubelet 什么时候清理容器?CRI 层能抢救回来吗?


