
Pod 状态 CrashLoopBackOff:日志拿不到怎么办?
场景:Pod 一直 CrashLoopBackOff,kubectl logs 看不到崩溃前的错误日志 路径:坐标 → 分层 → 路径 → 定位 → 标点
以下排查基于 K8s v1.25,容器运行时为 containerd v1.6。crictl 命令在 containerd v1.6+ 支持
-a参数查看所有容器。
坐标
上篇我们讲了 Init Container 耗时导致 Pod 启动慢——串行执行的 Init Container 把启动时间从 15 秒拉到了 3 分 20 秒。这次换个场景:Pod 不是启动慢,是一直重启——CrashLoopBackOff 状态,而且 kubectl logs 看不到日志。
一个 Pod 上线后状态在 CrashLoopBackOff 和 Running 之间反复切换。kubectl get po -w 看到的节奏:Running → CrashLoopBackOff → Running → CrashLoopBackOff——每次 Running 只维持几秒。团队的第一反应:看日志。kubectl logs 一看——空的。或者说,只有 JVM 启动的几行日志,崩溃前的错误栈完全看不到。
"应用是不是没打日志?"——排查方向一开始就歪了。
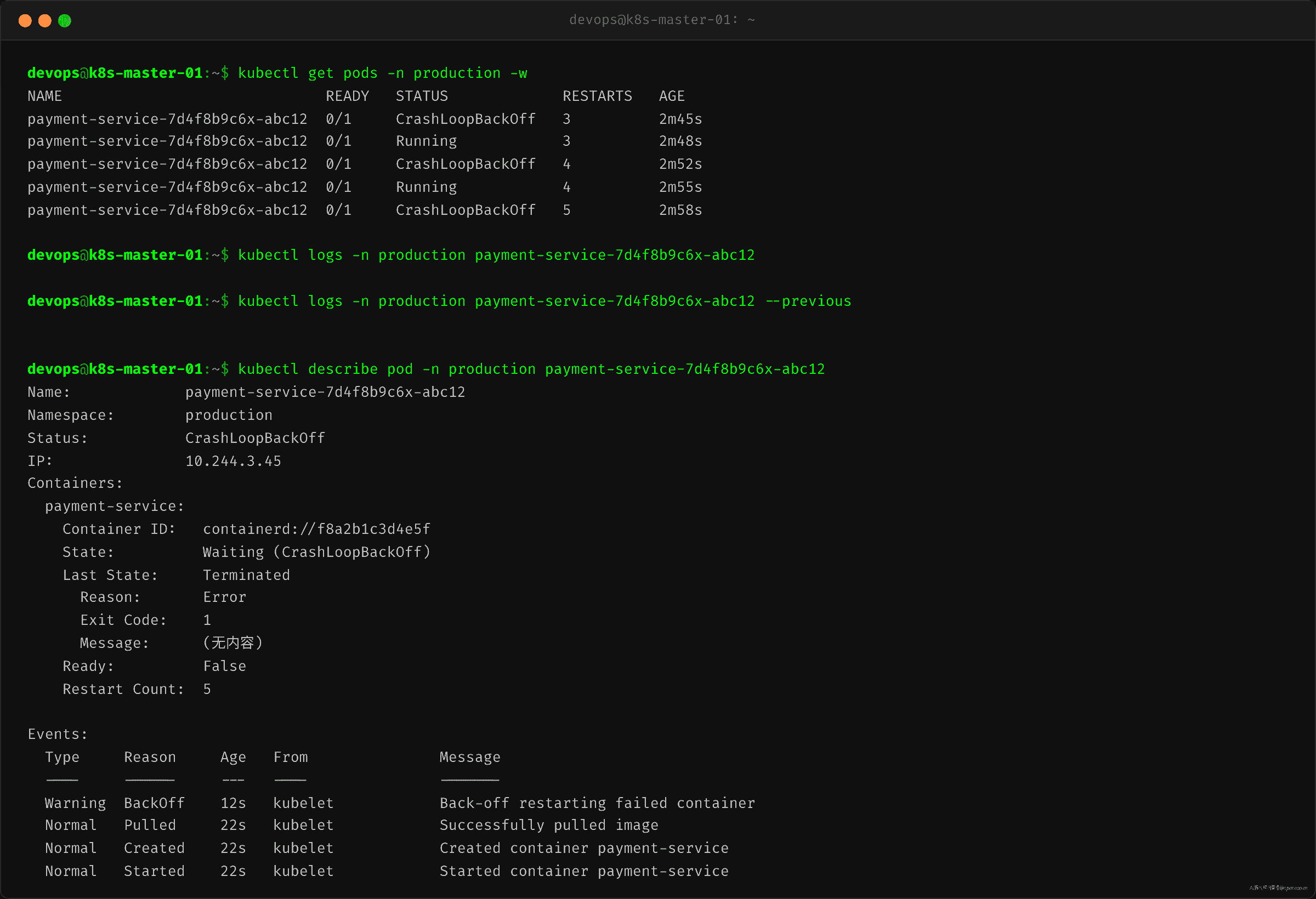
日志不是消失了——是容器每重启一次,上一个容器的 stdout/stderr 就被新容器"覆盖"了。kubectl logs 读的是当前 running 容器实例的 stdout,不是持久化存储。
理解这点需要先看 K8s 的日志链路:kubectl logs → kubelet(每个 Node 上的节点代理,管理 Pod 生命周期)→ CRI(Container Runtime Interface,K8s 与容器运行时之间的通信接口)→ 容器的 stdout/stderr。kubelet 收到 logs 请求后,调用 CRI 的 ContainerStatus() 获取当前容器 ID,再调用 ContainerLogs() 拉取这个实例的 stdout。上一个实例退出了,它的容器 ID 就从"当前"变成了"前一个"。如果不告诉 kubelet 你要看上一个人的日志,它默认只给你看当前这个人。
分层
CrashLoopBackOff 日志拿不到的问题,核心涉及 Pod 层和 CRI 层。Node 层和集群层与容器 stdout/stderr 获取无关,跳过。
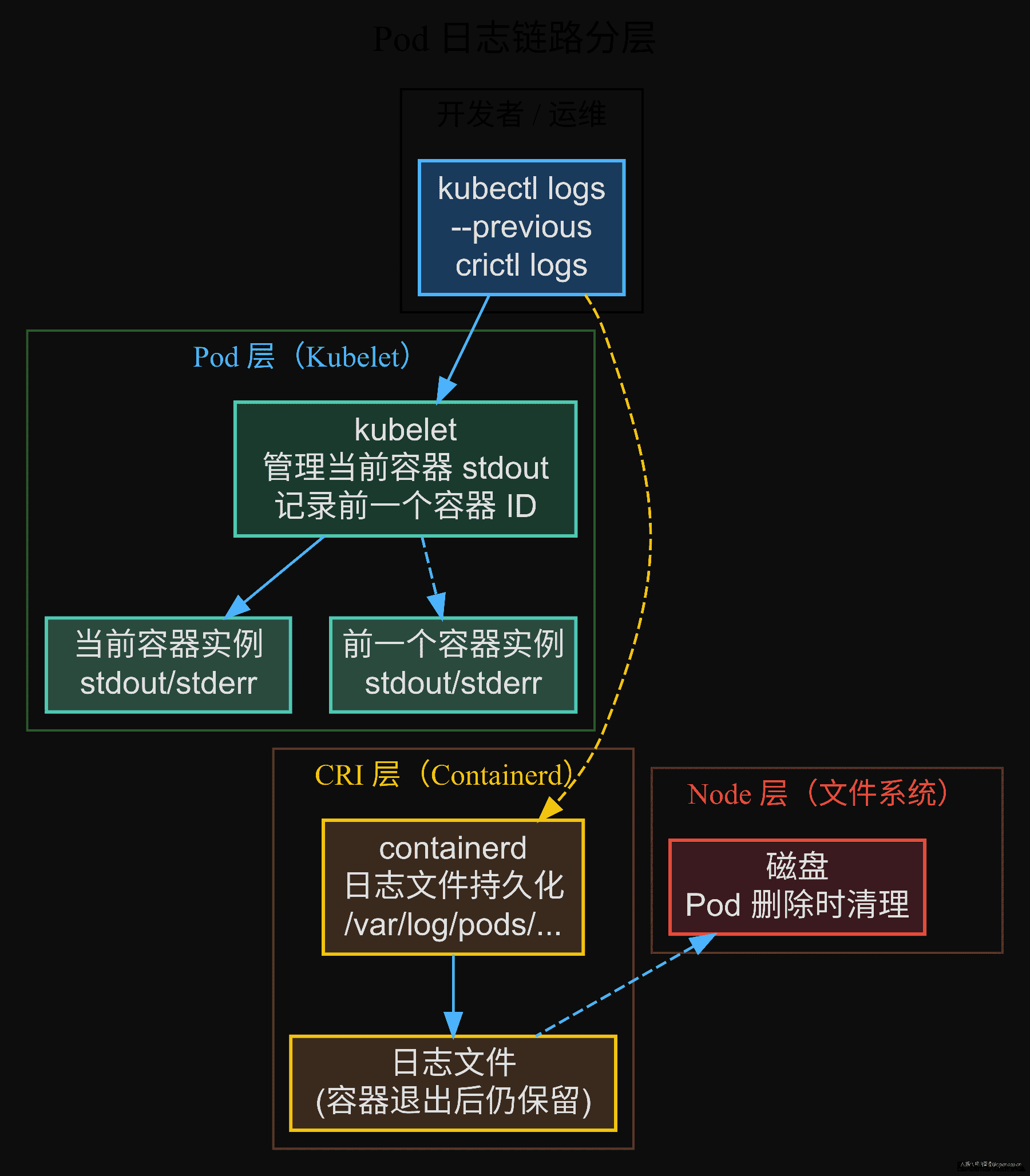
第一层(Pod):kubectl logs 的边界
kubectl logs 默认读取当前正在运行的容器实例的 stdout/stderr。容器崩溃→kubelet 重启→新容器实例产生新容器 ID——这时 kubectl logs 指向的是新实例,它的 stdout 只有启动日志。
kubectl logs --previous 可以拿到上一个实例的日志。kubelet 在容器重启时会记录前一个容器 ID,--previous 参数让 kubelet 用这个 ID 发起 CRI 的 ContainerLogs() 请求。
但 --previous 也不是万能的。如果容器启动后还没来得及写数据到 stdout 就崩溃——比如 JVM 在类加载阶段因为配置冲突直接 abort——上一个人的 stdout 也几乎没有内容。
第二层(CRI):crictl logs 的兜底
当 kubectl logs 和 --previous 都拿不到时,排查要下沉到 CRI 层。容器运行时(containerd)不只在容器运行时管理 stdout/stderr——每个容器的日志会被写入宿主机文件系统,即使容器退出,这个文件也不会被立即删除。
# 查看所有容器(包括已退出的)
crictl ps -a
# 查看已退出容器的日志
crictl logs <container-id>
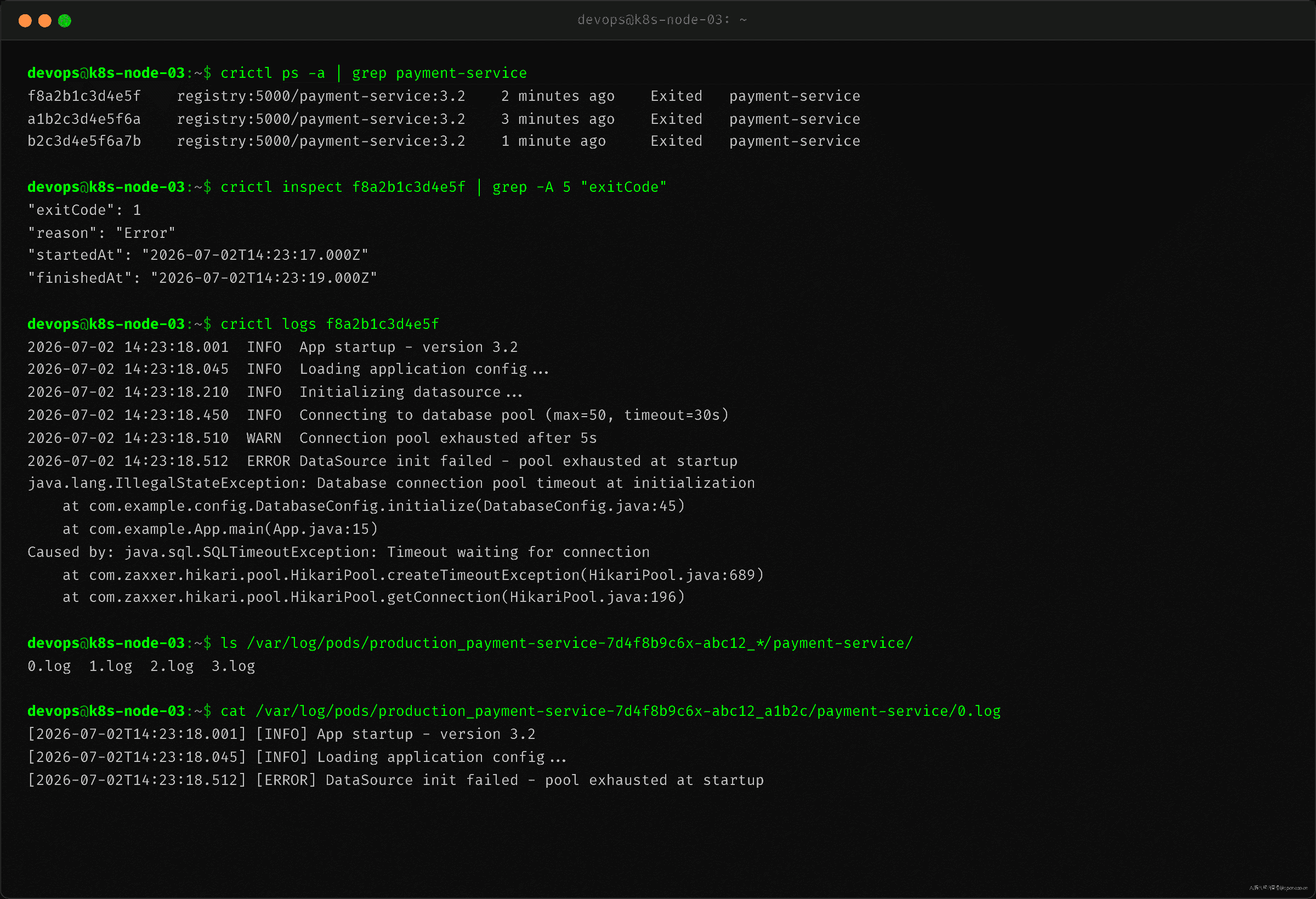
containerd 把每个容器的 stdout/stderr 写入 /var/log/pods/<namespace>_<pod>_<uid>/<container>/0.log。容器退出后这个文件仍然存在,直到 Pod 被删除。所以即使容器已经 restart 了三次,crictl logs 拿到的是第一次启动时的 stdout——包括那个导致崩溃的异常堆栈。
kubectl logs 和 crictl logs 的差别在于一个经过 kubelet 的"当前容器"语义层,一个直接拿容器的日志文件。前者有"实例"概念(当前 vs 前一个),后者没有——只要 Pod 没删,CRI 层的日志文件就在。
分层排查顺序总览
| 层级 | 排查目标 | 关键命令 | 适用场景 |
|---|---|---|---|
| Pod 层 | 当前容器日志 | kubectl logs <pod> -n <ns> |
容器还在 running |
| Pod 层 | 上一个实例日志 | kubectl logs <pod> -n <ns> --previous |
容器已重启 1 次 |
| CRI 层 | 已退出容器日志 | crictl logs <container-id> |
容器重启多次,--previous 拿不到 |
| CRI 层 | 日志文件直读 | ls /var/log/pods/<ns>_<pod>_<uid>/<c>/0.log |
crictl 不可用时 |
路径
下次遇到 Pod CrashLoopBackOff 但日志拿不到,按这个三层兜底策略来:
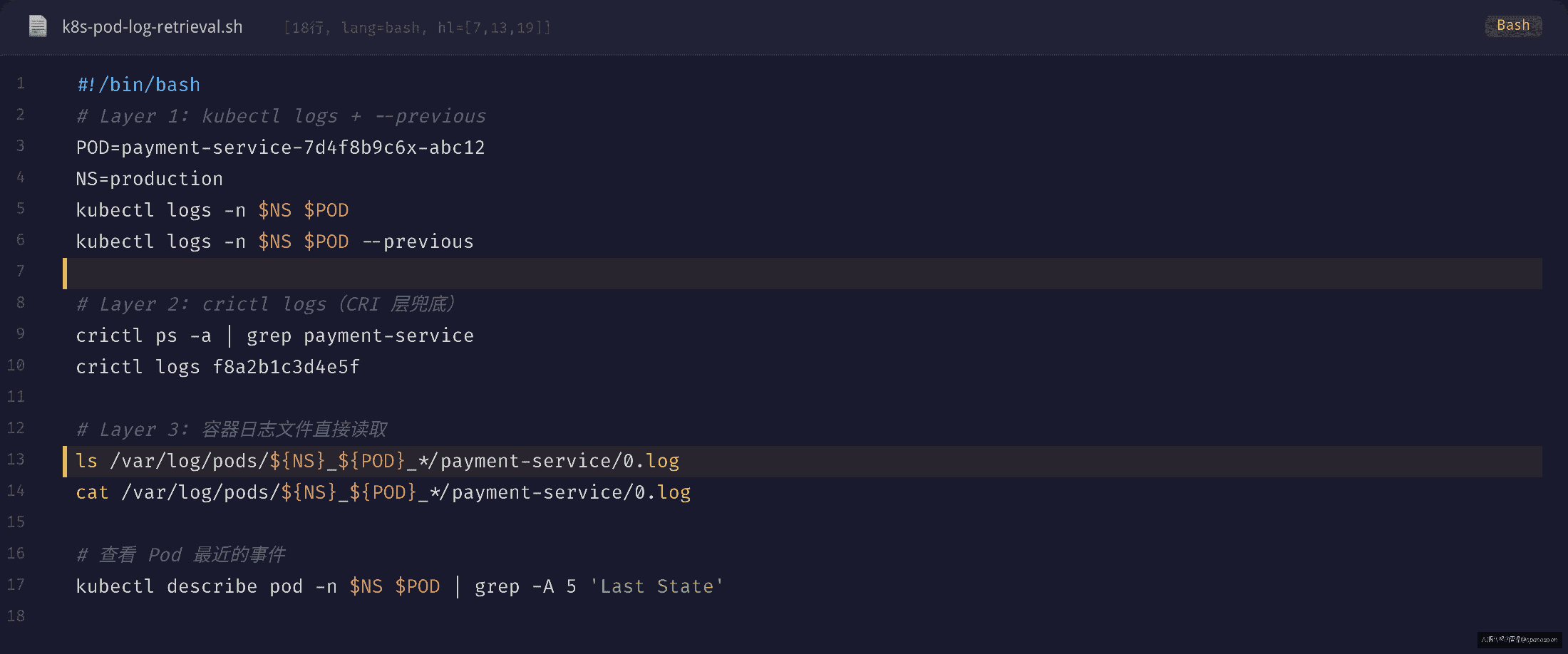
第一层:kubectl logs + --previous
kubectl logs -n production <pod> — 当前容器日志
kubectl logs -n production <pod> --previous — 上一个实例日志
第二层:crictl logs(CRI 层兜底)
crictl ps -a | grep <image> — 查看已退出容器
crictl logs <container-id> — 读退出容器日志
第三层:容器日志文件直接读取
ls /var/log/pods/<ns>_<pod>_<uid>/<c>/0.log — 直接访问日志文件
journalctl -u containerd --since "10 min ago" | grep -i "error\|exception" — journalctl 兜底
异常判断标准
| 命令 | 正常 | 异常 |
|---|---|---|
kubectl logs <pod> |
返回应用日志 | 空或只有启动日志 → 容器已重启 |
kubectl logs --previous |
返回崩溃前日志 | 空 → 容器在写 stdout 之前就崩了 |
crictl ps -a |
显示 exited 容器 | 容器全部清除 → Pod 已重新调度 |
crictl logs <id> |
返回完整日志 | 空 → 日志驱动未配置或文件轮转丢失 |
定位
CrashLoopBackOff 日志丢失的问题牵涉两个常见误判,从表及里。
❌ 误判 A:"应用没打日志"
第一直觉:kubectl logs 拿不到日志 → 应用 stdout 没配置 → 加日志配置再部署。
加配置、重建、重启——还是空的。这个问题不在应用侧,在 K8s 的容器实例隔离机制上。
kubectl logs 读的是当前 running 容器的 stdout/stderr。容器只要重启过,之前的 stdout 就被新实例覆盖了。不是应用没打日志,是日志打在了"上一个实例"的 stdout 上。
❌ 误判 B:"那直接用 crictl logs"
第二层直觉:kubectl logs 不行就用 crictl logs。
crictl logs 确实能拿到已退出容器的日志——前提是这个容器实例还没被 GC 清理。kubelet 的容器 GC 由 --maximum-dead-containers-per-container 控制,默认只保留 1 个前一个实例。容器重启超过 2 次后,最早的那个实例已经被 kubelet 清理,它的日志文件也随之删除。如果排查时 Pod 已经重启了多次或者 Pod 已被重新调度,crictl logs 也会返回空。
此外,如果容器在打印任何 stdout 之前就崩溃了——比如 JVM 因配置错误在类加载阶段直接 abort——即使 crictl logs 也只能读到一个空的 stdout。这种场景需要另一个机制:terminationMessagePath。
✅ 正确的排查路径
按层兜底:kubectl logs → kubectl logs --previous → crictl logs → container log file
先配兜底:为所有 Pod 加上 terminationMessagePath + FallbackToLogsOnError
分层排查的顺序不能跳:
- 第一刀(Pod 层):kubectl logs 和 --previous。大多数场景下 --previous 就够了——90% 的 CrashLoopBackOff 在第一个 restart 后日志就在前一个实例里
- 第二刀(CRI 层):crictl ps -a + crictl logs。容器重启多次后用到。crictl 的日志文件在 Pod 删除前永久保留
- 第三刀(Node 层):terminationMessagePath 配置。这是兜底的兜底——在容器不写 stdout 就崩溃时,从容器内部捕获最后的输出
排查 K8s 日志不是在查 kubectl logs——是在查容器实例的 stdout/stderr。每个容器实例都有自己的 stdout,重启即丢失。
标点
修复方案分两步:配置兜底机制 + 建立 CrashLoopBackOff 排查 check-list。
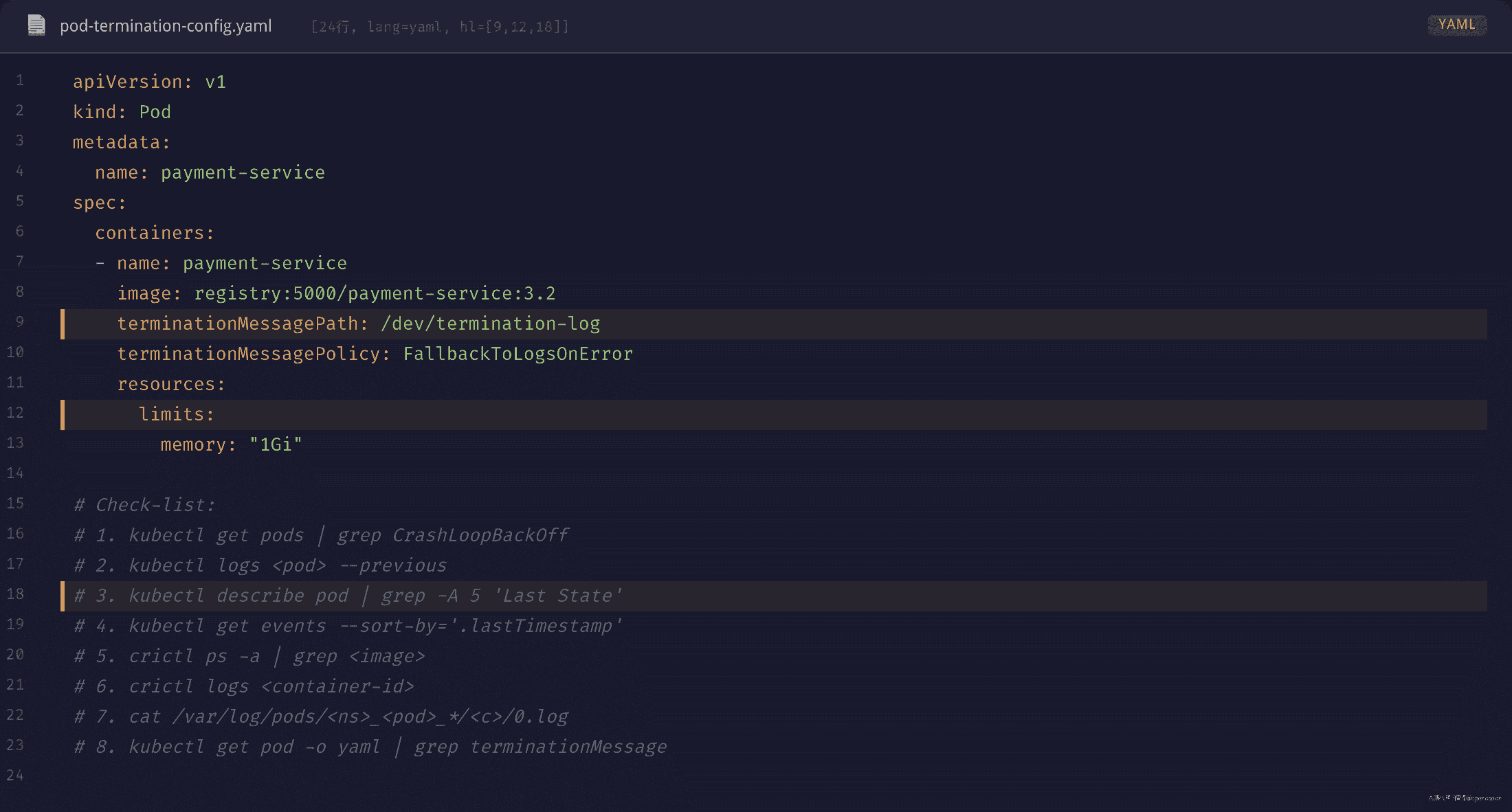
配置 terminationMessagePath
kubelet 在容器退出时会检查容器内的 terminationMessagePath 文件(默认为 /dev/termination-log)。如果该文件存在,kubelet 读取其内容作为 Pod 状态的理由。结合 terminationMessagePolicy: FallbackToLogsOnError,当该文件为空或不存在时,kubelet 会回退到容器最后一段 stdout/stderr 日志。
apiVersion: v1
kind: Pod
metadata:
name: payment-service
spec:
containers:
- name: payment-service
image: registry:5000/payment-service:3.2
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: FallbackToLogsOnError # ← 崩溃时回退到最后 4KB 日志
resources:
limits:
memory: "1Gi"
配置后,kubelet 在容器退出(exit code != 0)时的行为:
- 检查
terminationMessagePath文件内容 - 如果文件为空或不存在 → 读取容器最后 4KB 的 stdout/stderr
- 将结果写入 Pod 的
status.containerStatuses.lastState.terminated.message kubectl describe pod的 Last State 段即可看到崩溃原因
kubectl describe pod payment-service-7d4f8b9c6x-abc12 | grep -A 5 "Last State"
kubectl describe pod 的输出就会显示类似:
Last State: Terminated
Reason: Error
Exit Code: 1
Message: Exception in thread "main" java.lang.IllegalStateException:
Database connection pool exhausted at initialization
at com.example.App.main(App.java:15)
这段 message 就是从崩溃容器的最后 4KB stdout 截取的。即使容器在写 stdout 后瞬间崩溃、kubectl logs 还没来及读,这段内容也已经被 kubelet 捕获了。
CrashLoopBackOff 排查 Check-list
每条对应一个命令:
kubectl get pods -n <ns> -o wide | grep CrashLoopBackOff— 确认哪些 Pod 处于 CrashLoopBackOffkubectl logs -n <ns> <pod>— 读当前容器 stdoutkubectl logs -n <ns> <pod> --previous— 读上一个容器实例 stdoutkubectl describe pod -n <ns> <pod>— 看 Last State Message(如配了 terminationMessagePath)kubectl get events -n <ns> --sort-by='.lastTimestamp' -o wide | grep <pod>— 看 Events 中的 BackOff 信息crictl ps -a | grep <image>— 找到所有已退出容器crictl logs <container-id>— 读退出容器的日志ls /var/log/pods/<ns>_<pod>_<uid>/<c>/0.log— 直接从文件系统读取日志kubectl get pod -n <ns> <pod> -o yaml | grep terminationMessage— 验证 terminationMessage 配置
故障排查的终点不是修好了——是把排查路径写成 check-list。
下篇我们聊 Pod 调度不均衡——nodeAffinity/podAntiAffinity 配置错误导致 Pod 堆积在部分节点上,一个节点挂了影响面比预想的大很多。


