
上篇我们聊了 Pod CrashLoopBackOff 时日志拿不到的排查思路,用 crictl 绕过 kubectl 直接读容器运行时日志。这篇看一个完全不同的方向——Pod 不是起不来,是起来了但分布不均衡。
场景:Deployment 20 副本上线后,Pod 全堆在 2 台 Node,其余 Node 资源充裕但无 Pod 被调度 路径:Events 发现 FailedScheduling → 统计匹配标签的 Node 数 → 审阅亲和性配置 → 修正为 preferred → Pod 分布均匀
以下排查基于 K8s v1.28+,使用 apps/v1 API
【坐标】— Pod 调度困局
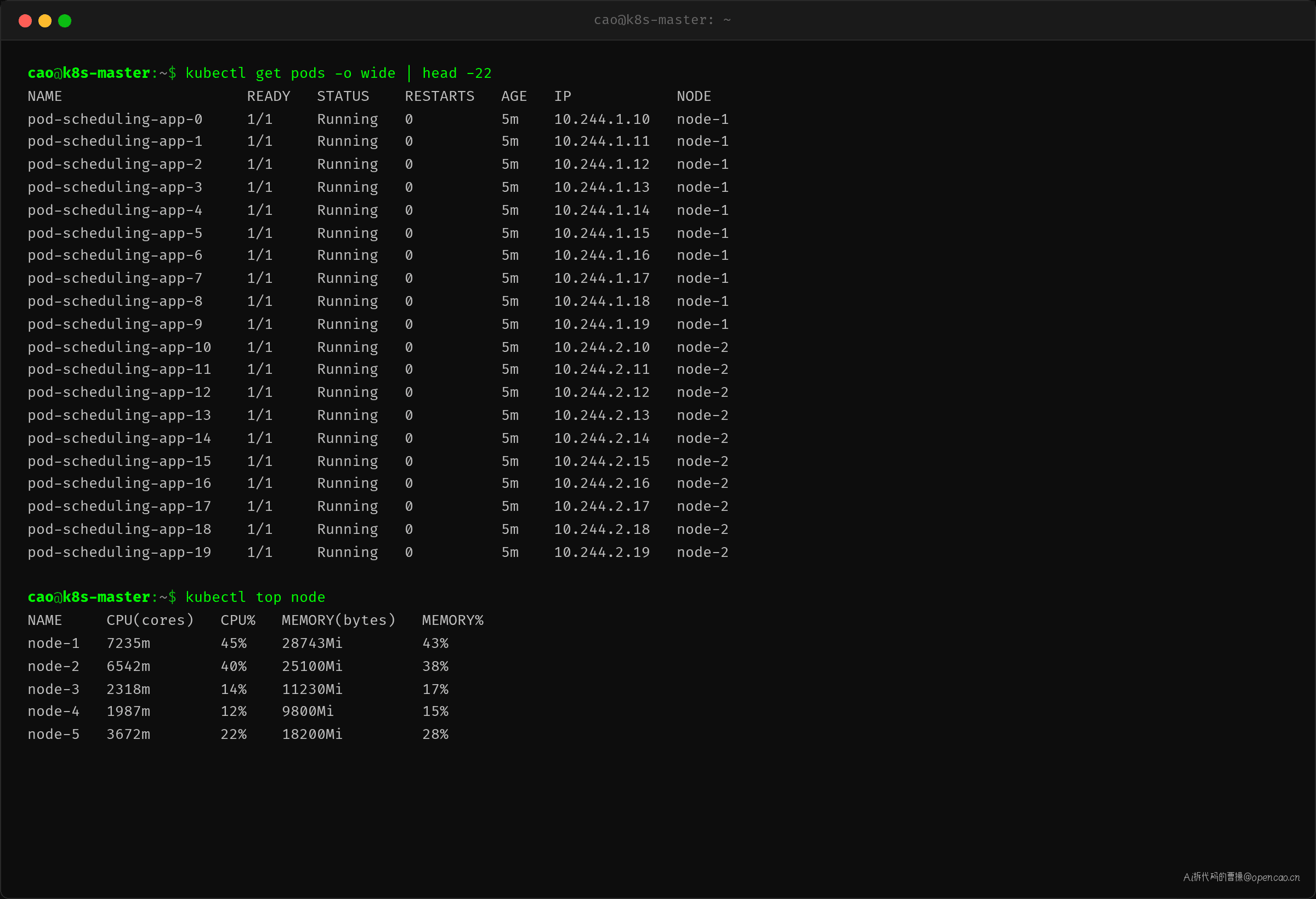
20 副本 Deployment 上线,新 Pod 全部堆在 node-1 和 node-2——node-3、node-4、node-5 一台 Pod 都没有。
"资源不够吧?"第一反应。kubectl top node 一看——node-3 CPU 18%、内存 32%,node-4、node-5 也类似,资源充裕得很。
不是资源不够——是 affinity 配置把调度范围锁死了。
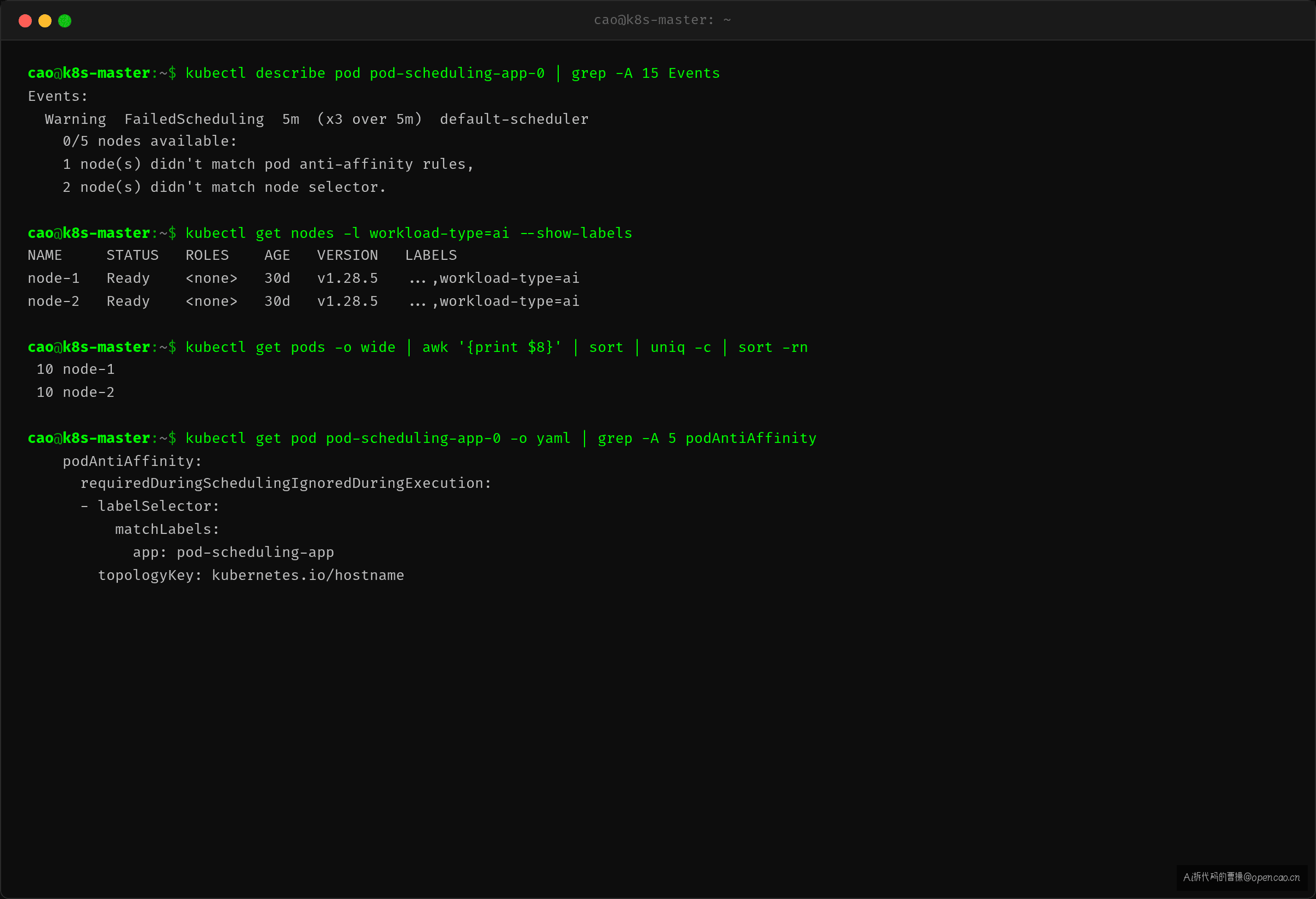
kubectl describe pod 看 Events,答案直接贴脸了:
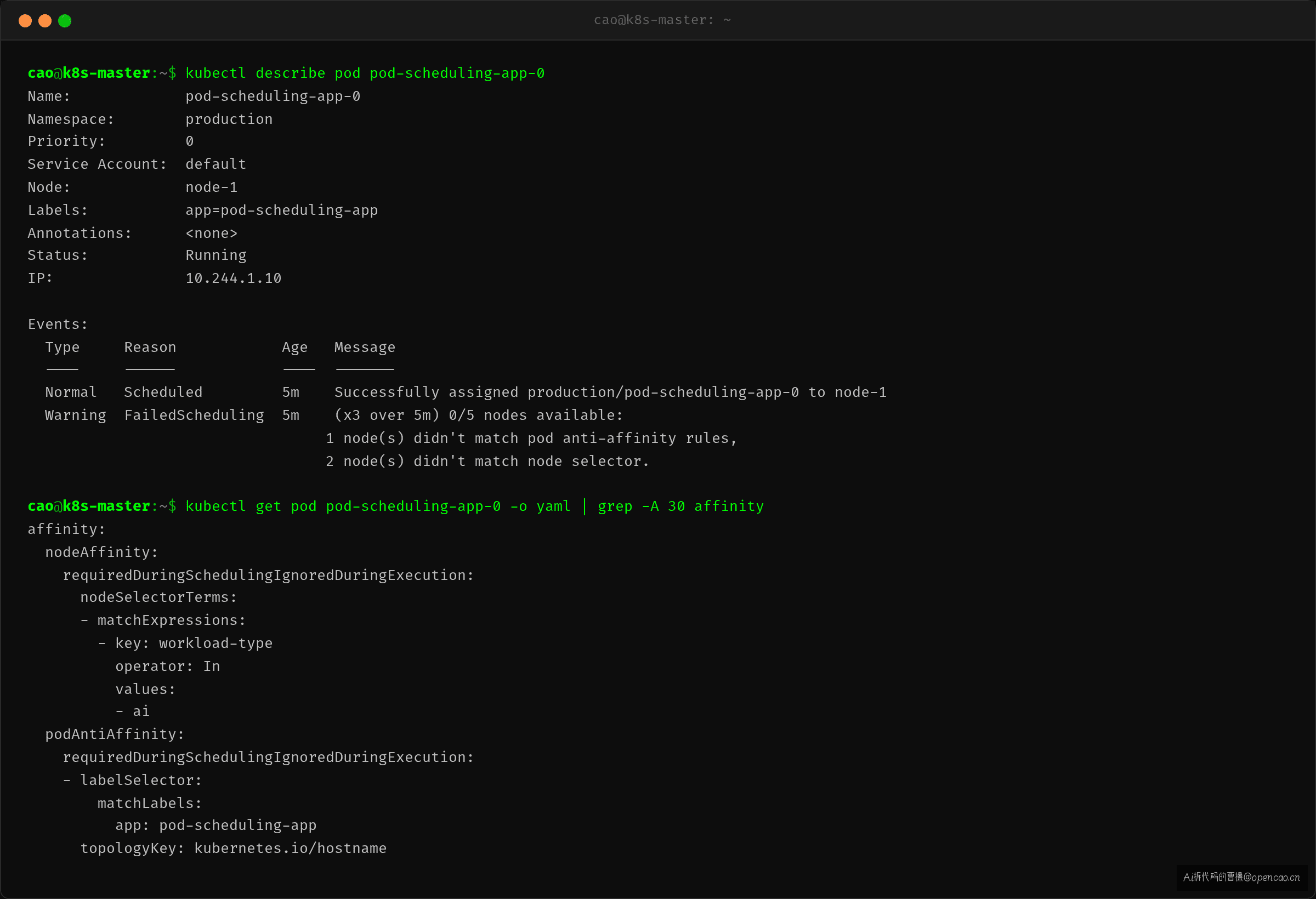
调度器(kube-scheduler,K8s 集群的控制面组件,负责将 Pod 分配到合适的 Node)在 predicate 阶段过滤掉了 3 台 Node。剩下 2 台,刚好塞下 20 个副本——但这不是我们想要的效果。
金句:K8s 不是没有告诉你问题在哪——Events 已经说了,只是你没看
【分层】— 从 Pod 到集群逐层排查
调度问题发生在容器启动前,CRI 层(容器运行时)不涉及,跳过。排查从 Pod 层直接进入 Node 层 → 集群层。
金句:排查 K8s 问题不是在查 Pod——是在查 Pod 所在的整条链路
① Pod 层 — Events 缩小范围
Events 给出了两条线索: - node selector 不匹配 —— nodeAffinity(节点亲和性,Pod 声明"我只想跑在打了特定标签的 Node 上")只匹配了 2 台 Node - pod anti-affinity rules —— podAntiAffinity(Pod 反亲和性,Pod 声明"我不想和其他同标签 Pod 挤在同一台 Node 上")让同组 Pod 互斥
Pod 的 YAML 是这样声明的:
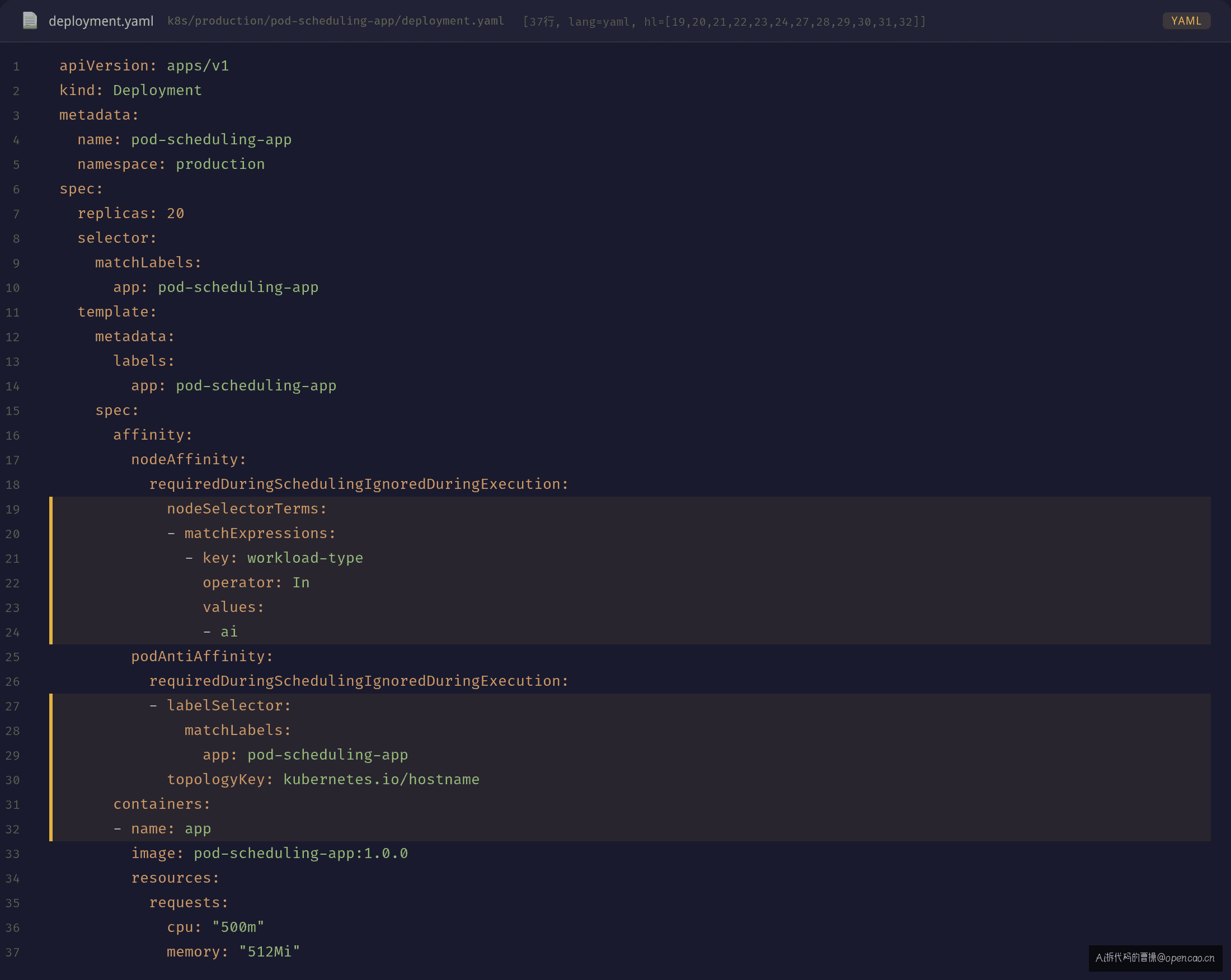
两个都是 requiredDuringSchedulingIgnoredDuringExecution(硬约束,Pod 调度时必须满足的条件,调度器在 predicate 阶段直接过滤不满足的 Node;不满足直接报 Unschedulable,不会降级尝试)——调度器必须满足才能调度,不满足就直接判 Unschedulable。
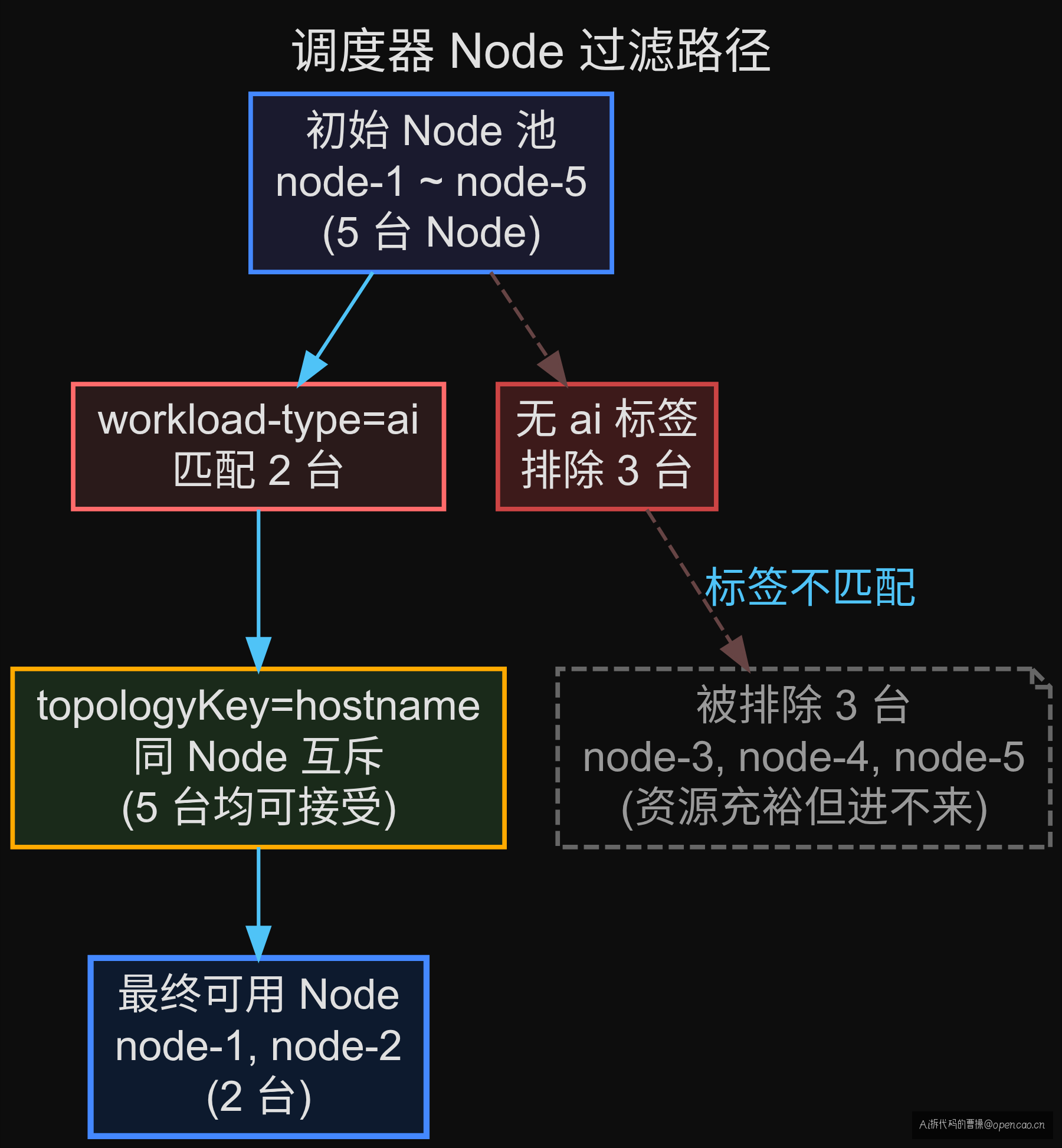
② Node 层 — 统计匹配标签的 Node
nodeAffinity 要求 Node 有 workload-type=ai 标签。查一下集群里有多少 Node 满足:
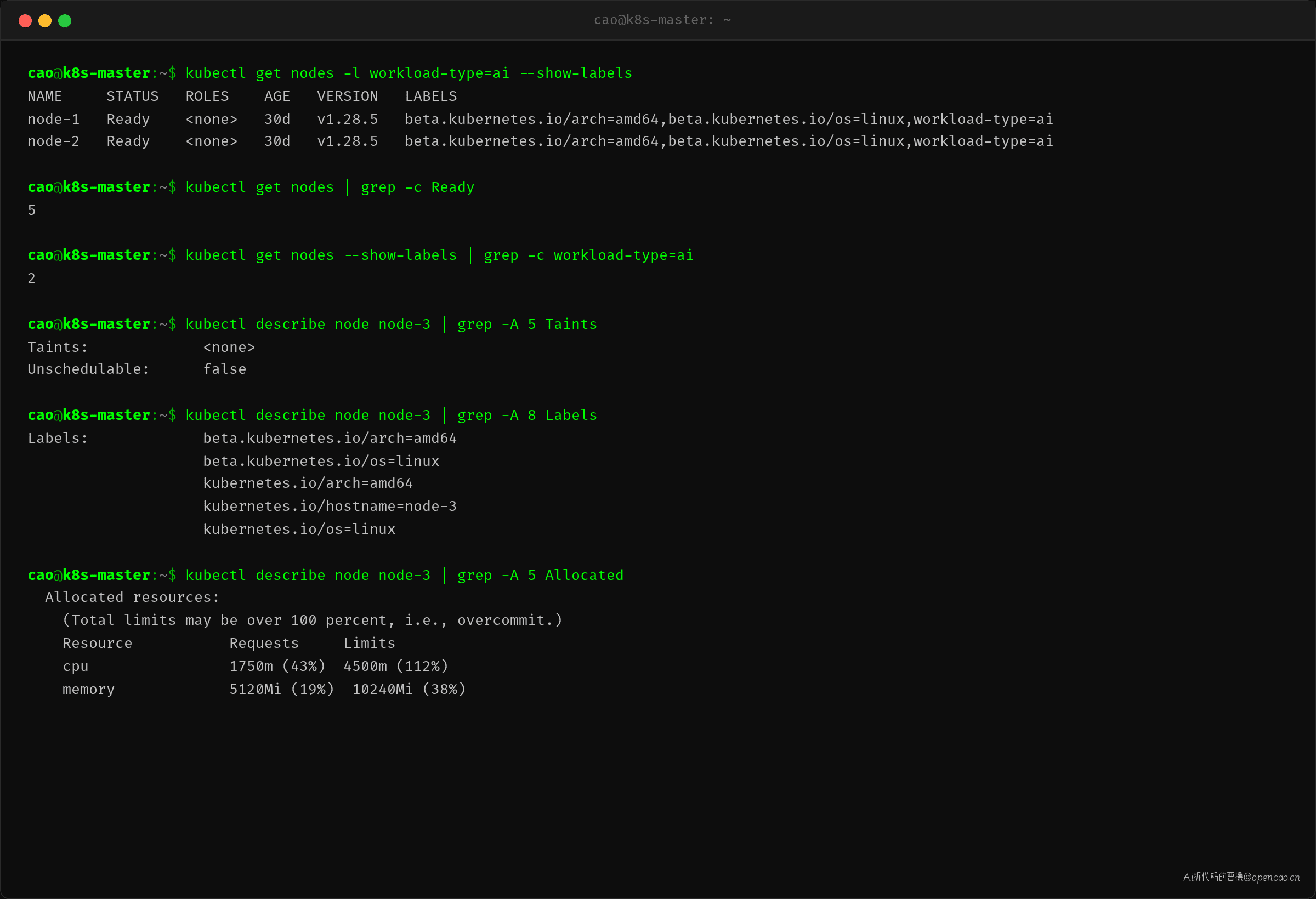
只有 2 台。node-3、node-4、node-5 没有这个标签。
那 podAntiAffinity 的作用是什么?topologyKey: kubernetes.io/hostname 表示"同一台 Node 上的 Pod 互斥"——每台 Node 最多一个同组 Pod。但 Node 池只有 2 台,所以上限就是 2 个 Pod?
不对,requiredDuringScheduling 的 podAntiAffinity 只是不允许同组 Pod 在同一台 Node,只是说"不同 Node 可以各放一个",并不限制每台 Node 的数量。但加上 nodeAffinity 后 Node 池只剩 2 台:
- Predicate 阶段:
nodeAffinity过滤掉 3 台(无workload-type=ai),podAntiAffinity不作额外过滤(没有同 Node 冲突) - 剩下 2 台 → Score 阶段按资源打分 → 均匀分布 → 各 10 个
验证 node-3 是否被污点拒绝——kubectl describe node node-3 显示 Taints: <none>。没有污点,没有资源压力,单纯是 workload-type=ai 标签不匹配,调度器在 predicate 阶段就没把它列入候选。
【路径】— 🔍 下次先跑这套命令
排查调度不均衡的核心三板斧:
# ① 看调度失败原因
kubectl describe pod <pod> | grep -A 15 Events
# ② 统计匹配 nodeAffinity 的 Node 数
kubectl get nodes -l <key>=<value> --show-labels
# ③ 看 Pod 跨 Node 分布密度(黄金命令)
kubectl get pods -o wide | awk '{print $8}' | sort | uniq -c | sort -rn
异常判断标准:
- Events 出现 didn't match pod anti-affinity rules + didn't match node selector → 亲和性配置过严,两个约束将可用 Node 池的交集缩小了
- kubectl get nodes -l <label> 匹配数量 < 3 → nodeAffinity 的 label 覆盖太窄,考虑扩标签或改 preferredDuringScheduling
- 分布密度 uniq -c 显示某个 Node 集中度 > 60% → 调度不均衡,检查亲和性 + 调度器打分策略
【定位】— ❌ 两个常见误判
Pod 调度不均衡这个现象,最容易被带偏的方向有两个。
误判 1:"加副本就能自然打散"
Naive 思路:"Pod 分布不均 → 加副本让它自己散开。"但 podAntiAffinity 只是互斥同 Node,Node 池只有 2 台的话加再多副本也只堆在这 2 台上。
有经验的人会说:"加 Node 就能分散。"新 Node 没有 workload-type=ai 标签,不匹配 nodeAffinity,加了也白加。
正确做法:查 nodeAffinity 和 podAntiAffinity 的组合范围。两个亲和性叠加,可用 Node 是两者调度的交集,不是并集。取交集后只剩 2 台——加副本只在 2 台里堆,加 Node 不打对应标签仍然进不来。
误判 2:"requiredDuringScheduling 是更安全的选择"
很多人直觉认为"required 比 preferred 靠谱,它能保证规则被执行"。但 requiredDuringScheduling 是硬约束——调度器在 predicate 阶段必须找到满足条件的 Node,找不到就直接报 Unschedulable,不会尝试打分阶段的软性优化。
preferredDuringScheduling 是软约束——调度器在 scoring 阶段优先推荐满足条件的 Node,但如果不满足,仍然可以调度到其他 Node。
选择规则:
- Node 池 < 5 台 → 一律用 preferredDuringScheduling
- Node 池 ≥ 5 台且对分布有硬要求 → 才考虑 requiredDuringScheduling,但必须评估缩减后的 Node 池是否足够
【标点】— 修复 + Check-list
YAML 修正
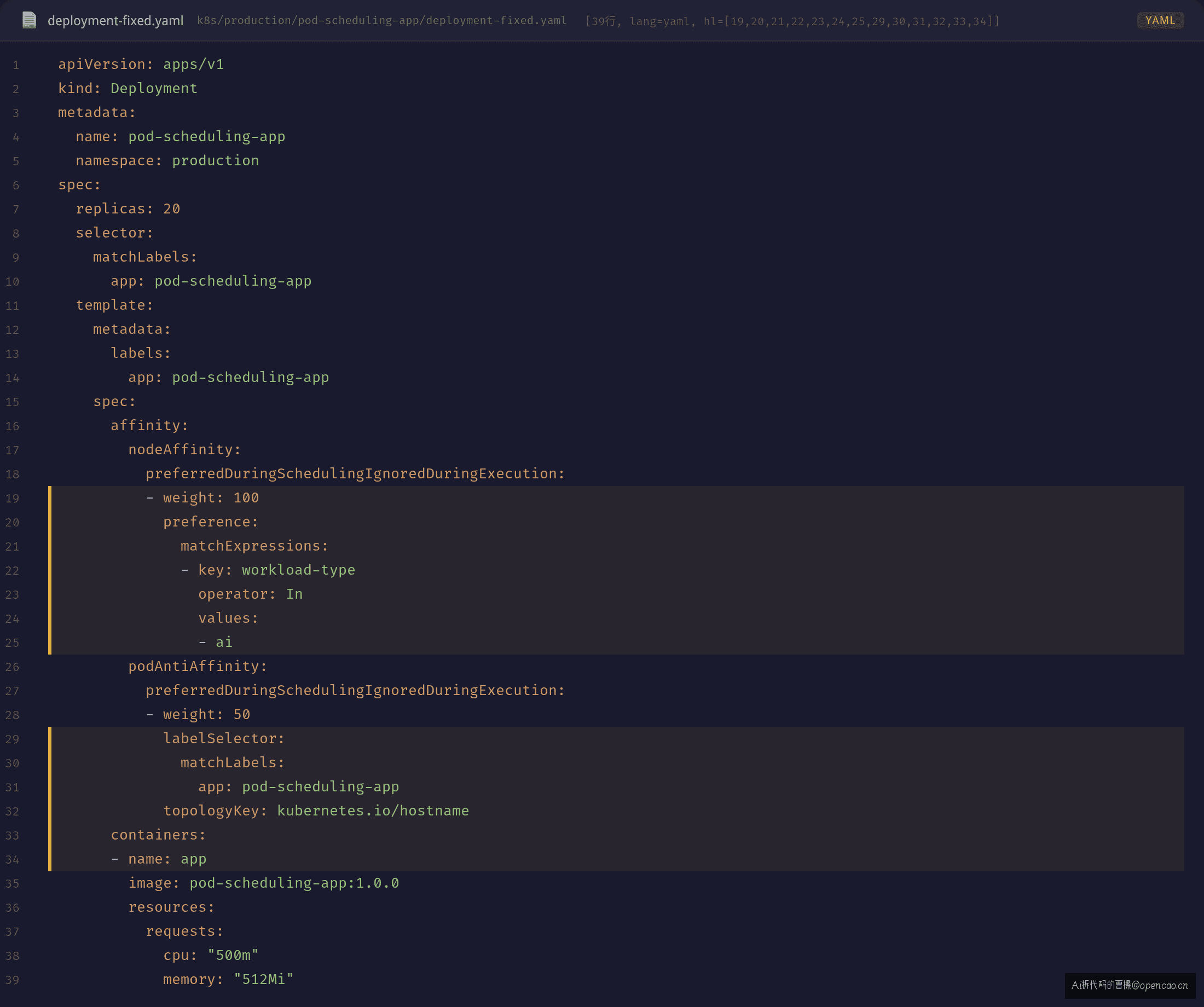
两个关键改动:
- requiredDuringScheduling → preferredDuringScheduling:调度器不再因不匹配而拒绝调度,改为优先调度到匹配的 Node
- podAntiAffinity 权重 50 < nodeAffinity 权重 100:尽量走 AI 标签的 Node,但如果都满了可以落到其他 Node
金句:一个 YAML 字段没配,不是 K8s 会帮你兜底——是它会按默认值运行,而默认值往往不适合你的场景
Check-list
kubectl describe pod <pod> | grep -A 15 Events→ 看调度失败原因kubectl get nodes -l <key>=<value>→ 统计匹配 nodeAffinity 的 Node 数量kubectl get pods -o wide | awk '{print $8}' | sort | uniq -c | sort -rn→ 看 Pod 跨 Node 分布kubectl get pod <pod> -o yaml | grep -A 30 affinity→ 审阅完整亲和性配置- Node < 5 台一律用
preferredDuringScheduling,≥ 5 台才考虑requiredDuringScheduling
金句:故障排查的终点不是修好了——是把排查路径写成 check-list
附:完整命令清单
# ============ 排查阶段 ============
# 查看调度 Events
kubectl describe pod <pod> | grep -A 15 Events
# 查看 Pod 分布
kubectl get pods -o wide
# 统计匹配标签的 Node
kubectl get nodes -l workload-type=ai --show-labels
# 查看 Node 详情(污点、标签、资源)
kubectl describe node <node>
# ============ 修复阶段 ============
# 应用修正后的 YAML
kubectl apply -f deployment-fixed.yaml
# 观察分布变化
kubectl get pods -o wide -w
# ============ 持续监控 ============
# 分布密度快速检视
kubectl get pods -o wide | awk '{print $8}' | sort | uniq -c | sort -rn
下篇我们聊 DaemonSet 更新策略导致节点逐个宕机的排查——当 maxUnavailable 设错,rolling update 会一台接一台地干掉你的 Pod。


