
DaemonSet 滚动更新导致节点逐个宕机
场景: DaemonSet 滚动更新 CNI 配置 → DaemonSet Pod 逐节点终止重建 → 节点逐台 NotReady 路径: Pod → CRI → Node → 集群 逐层排查 版本: K8s v1.25
上篇讲了 Pod 调度不均衡问题——nodeAffinity 配置写反导致 Pod 挤在同一台节点,资源利用率一边倒。这篇我们来看另一个因配置引发的连锁反应:DaemonSet 滚动更新导致节点逐个宕机。
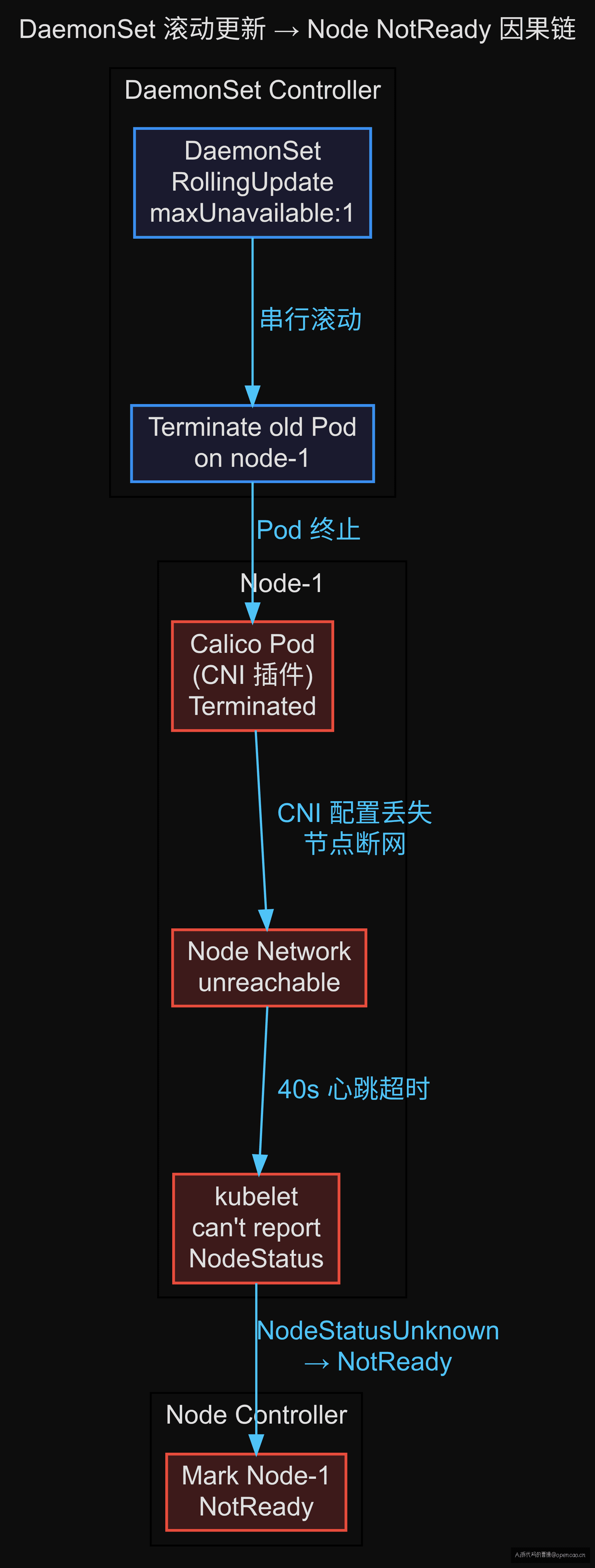
更新一个 DaemonSet 的配置,发布后节点一台接一台变成 NotReady——不是硬件故障,不是 kubelet 挂了,是 DaemonSet controller 的 RollingUpdate 策略在每个节点上执行 terminate → 等待 Ready → 再继续下一节点。当被终止的是 CNI 网络插件 Pod(如 Calico),节点网络瞬间断连,kubelet 的 NodeStatus 上报超时,node controller 直接判 NotReady。
K8s 的 RollingUpdate 只保证你的 Pod 被替换——不保证你的节点还在线上。
【坐标】→ 节点逐台失联
现象很直接:发布一个 DaemonSet 配置更新后,监控面板上节点开始一台一台变红。
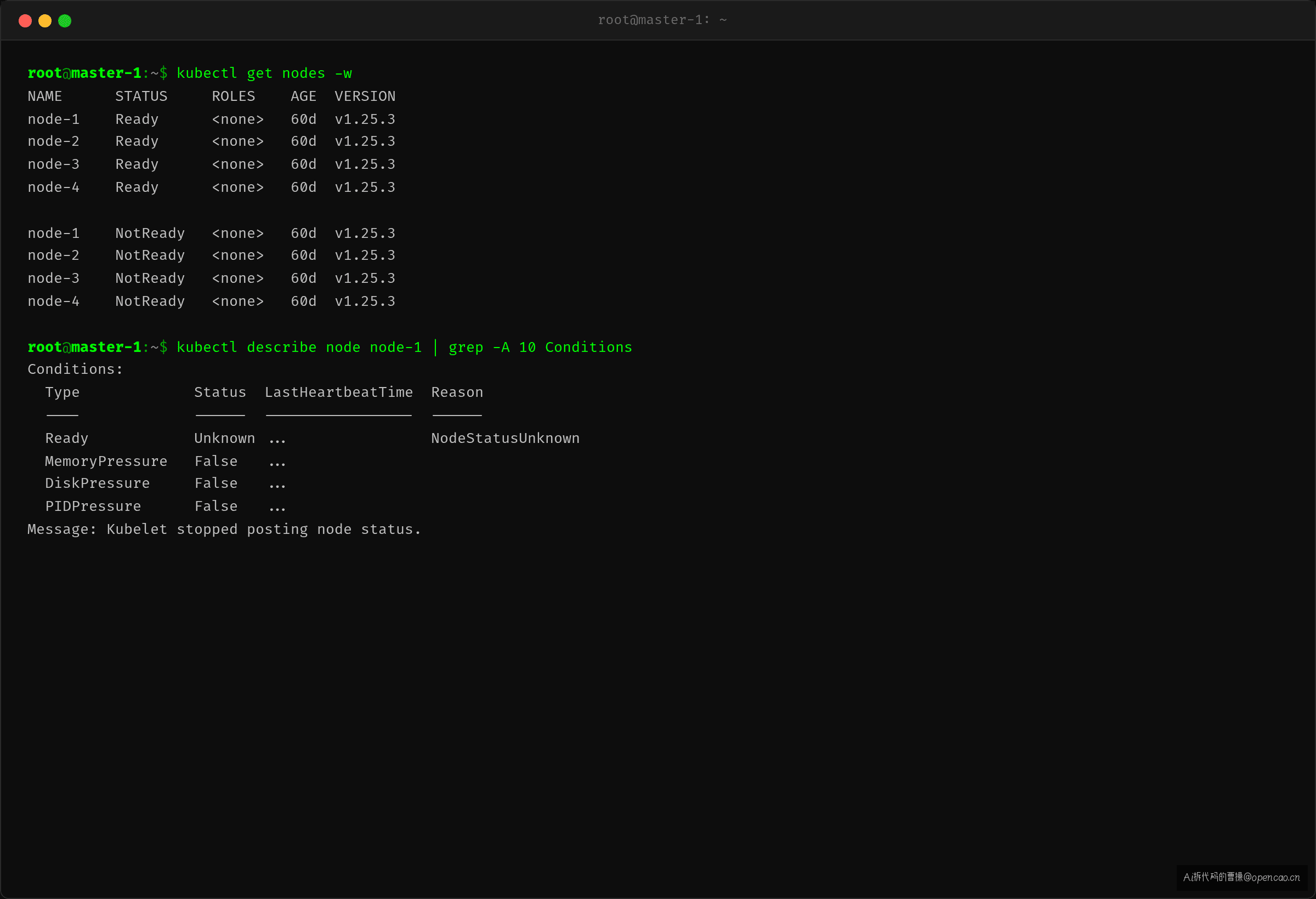
用 kubectl get nodes -w 能看到 Node 状态变化的时间线——间隔大约 1-2 分钟一台,完全跟 DaemonSet 滚动更新的节奏吻合。
kubectl describe node <node-name> 查看 NotReady 节点的 Condition:
Conditions:
Type Status LastHeartbeatTime Reason Message
---- ------ ----------------- ------ -------
Ready Unknown ... NodeStatusUnknown Kubelet stopped posting node status.
...
MemoryPressure False ...
DiskPressure False ...
关键信息:Kubelet stopped posting node status——kubelet 不再上报心跳。不是 kubelet 进程挂了,是它无法跟 API server 通信了。
这里立即引发直觉:kubelet 的网络依赖什么?答案是 CNI 插件(Container Network Interface),它通常以 DaemonSet 形式运行在每个节点上。如果 CNI Pod 被终止了,节点就失去了网络能力。
---> 去查 DaemonSet 状态。
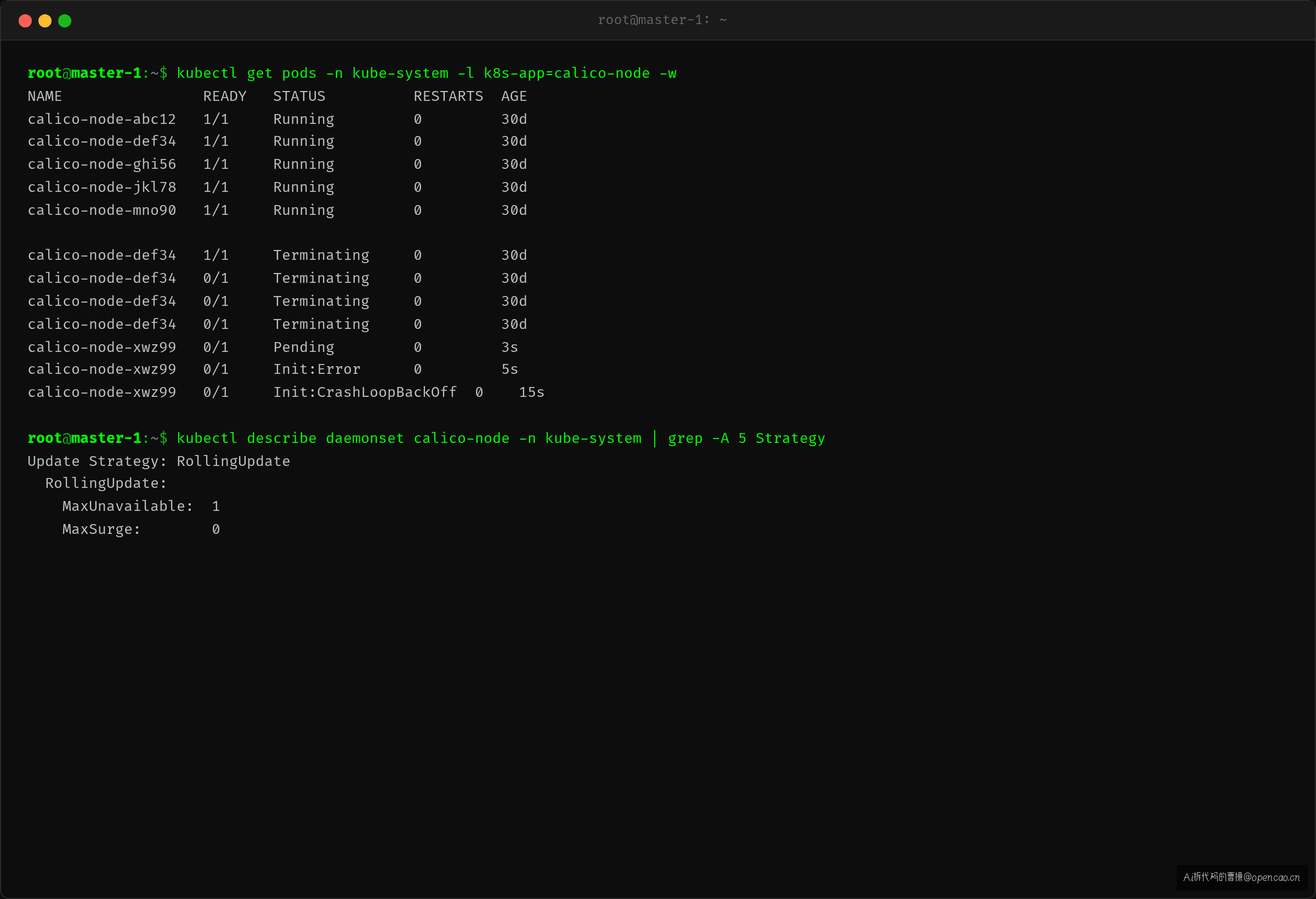
Pod 层:kubectl get pods -n kube-system -l k8s-app=calico-node -w。DaemonSet(DaemonSet——在每个节点上运行一个 Pod 的控制器,常用于网络插件、监控代理等基础设施组件)正在逐节点更新,新 Pod 全部卡在 Init 阶段。
【分层】→ 逐层排查
排查路径从 Pod 内(日志/Events)出发,逐层往下到 CRI 运行时,再到 Node 层面,最后看集群范围。不跳过任何一层。
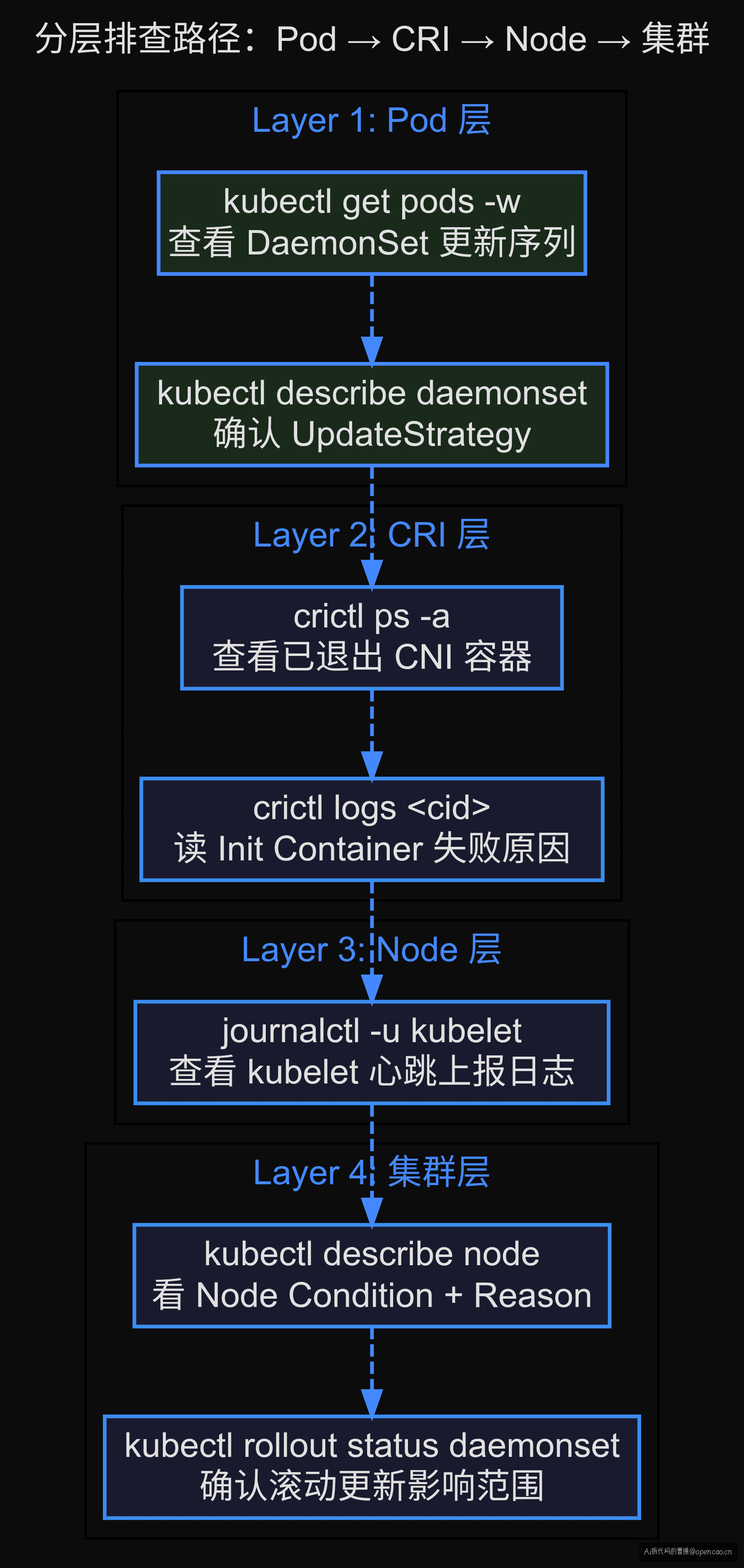
Pod 层:DaemonSet 更新序列
kubectl describe daemonset calico-node -n kube-system 确认更新策略。 C2 — DaemonSet controller 的 RollingUpdate 逻辑:DaemonSet controller 在 RollingUpdate 模式下,每次选择一个节点,终止其上的旧 Pod,等待新 Pod 变为 Ready,然后才继续下一个节点。maxUnavailable: 1 意味着同一时间最多只有一个节点的 Pod 处于不可用状态。这不是"并发的"——是逐节点的串行操作。当新 Pod 永远无法 Ready 时,controller 卡在当前节点,不再继续更新其他节点。
但这里的现象是节点逐个宕机——说明新 Pod 虽然没 Ready,但旧 Pod 已经被终止了,节点网络已经断了。
kubectl logs calico-node-def34 -n kube-system 看不到日志(Pod 在 Init 阶段),需要用 crictl(CRI 命令行工具,用于直接与容器运行时交互,比 kubectl logs 能看到已退出容器的历史日志)查已退出的 Init Container。
CRI 层:CNI 容器启动失败
先找到节点上的容器 ID:
# 在 NotReady 节点上执行
crictl ps -a | grep calico
crictl ps -a | grep calico 输出如下:
CONTAINER IMAGE CREATED STATE NAME
a1b2c3d4e calico-node:v3.26 2 minutes ago Exited install-cni
e5f6g7h8i calico-node:v3.26 1 minute ago Exited calico-node
两个容器都 Exited。crictl logs a1b2c3d4e 看 Init Container 输出:
2026/07/03 10:22:15 [INFO] Installing CNI binaries...
2026/07/03 10:22:16 [ERROR] Failed to create CNI config: config file /host/etc/cni/net.d/10-calico.conflist not found
根因明确:新版本 Calico 的 CNI 配置文件路径变了,旧配置挂载没有覆盖新路径,导致 CNI 安装失败。节点上没有 CNI 配置 → kubelet 无法设置 Pod 网络 → 节点失去网络能力。
Node 层:kubelet 心跳断连
journalctl -u kubelet -f --since "10 minutes ago" 查看 kubelet 日志:
Jul 03 10:22:20 node-1 kubelet[1234]: E Failed to update node status:
Post "https://api-server:6443/api/v1/nodes/node-1/status":
dial tcp 10.0.0.1:6443: connect: no route to host
Jul 03 10:22:30 node-1 kubelet[1234]: E Failed to update node status: ...
C2 解释:kubelet 每隔 10s(--node-status-update-frequency)向 API server 报告一次 Node 状态。当 CNI 不可用,kubelet 无法通过网络连接 API server,NodeStatus 上报连续超时。node controller(controller-manager 内的节点管理组件,负责监控节点心跳状态)在 --node-monitor-grace-period(默认 40s)内没收到上报,将 Node 标记为 Unknown;再过 --node-monitor-period(默认 5s),标记为 NotReady。
时间线:
| 时间 | 事件 |
|---|---|
| T+0s | DaemonSet controller 终止 node-1 的 calico-node Pod |
| T+5s | CNI 配置丢失,节点网络断连 |
| T+10s | kubelet 首次上报失败 |
| T+40s | node controller 标记 node-1 为 Unknown |
| T+50s | node controller 标记 node-1 为 NotReady |
| T+60s | DaemonSet controller 继续下一个节点(用 maxUnavailable: 1 的串行滚动) |
集群层:DaemonSet controller 的 RollingUpdate
回到集群视角。DaemonSet controller 的行为是"保证每个节点上有一个 Pod 运行",它在滚动更新时并不知道节点的网络能力依赖它的 Pod。controller 的职责边界止于 Pod 生命周期——它检查新 Pod 是否 Ready,不是检查节点是否 Ready。
# DaemonSet controller 的逻辑(简化)
for each node:
terminate old Pod on node
create new Pod on node
wait for new Pod to become Ready
if timeout: stop, don't continue
else: next node
这个循环里,新 Pod 的 ready 检查依赖于 kubelet 的健康检查。但 kubelet 的健康检查依赖于 CNI。CNI 依赖于 DaemonSet 自己。这是一个循环依赖——DaemonSet controller 不知道,也无法知道。
【路径】→ 🔍 下次先查 DaemonSet 状态
遇到节点逐台宕机,第一反应不是查节点——是查 DaemonSet。
# 1. 看哪个 DaemonSet 在滚动更新
kubectl rollout status daemonset --all -n kube-system
# 2. 看更新策略
kubectl describe daemonset <name> -n <ns> | grep -A 5 UpdateStrategy
# 3. 看 DaemonSet Pod 更新序列
kubectl get pods -n kube-system -l k8s-app=<app> -w
# 4. 看 Node NotReady 时间线
kubectl get nodes -o wide | grep NotReady
# 5. 定位节点失联时间点
kubectl describe node <node-name> | grep -A 10 Conditions
判断标准:如果 NotReady 节点的数量和时间跟某个 DaemonSet 的 Pod 终止节奏吻合——问题在 DaemonSet,不在节点。
【定位】→ 最常误判
❌ 大多数人会这么查:
"节点 NotReady → 登录节点查 kubelet 状态 → systemctl restart kubelet → 短暂恢复 → 又挂了 → 再重启 → 重复。"
浪费大量时间在节点层打转,重启 kubelet 只是暂时恢复了网络连接,但 CNI 问题没解决,网络会再次断连。
✅ 正确的排查思路:
遇到节点逐个宕机,先做两件事:
- 检查 DaemonSet 状态:
kubectl rollout status daemonset --all -n kube-system——看是否某个 DaemonSet 正在更新 - 对比时间线:DaemonSet Pod 终止时间 vs Node NotReady 时间
如果吻合,直接定位到 DaemonSet。然后:
- 如果是 CNI 插件 DaemonSet → 节点网络依赖它,更新前必须评估对节点网络的影响
- 如果是其他基础设施 DaemonSet(log agent / monitoring agent)→ 影响范围较小,但同样可能引发级联问题
两者的差异:前者从节点现象出发(Node NotReady),后者从集群视角出发(DaemonSet 更新 + 时间线交叉)。不出节点层,永远找不到根因。
【标点】→ 修复 + Check-list
紧急止损
直接回滚 DaemonSet 到上一个版本:
kubectl rollout undo daemonset/calico-node -n kube-system
回滚后,DaemonSet controller 重新在每个节点上创建旧版本的 Pod。CNI 恢复,节点网络恢复,kubelet 重新上报,node controller 将 Node 状态恢复为 Ready。
回滚效果对比:
# before: 新版本 CNI 配置路径不对
volumes:
- name: cni-config
configMap:
name: calico-config-v2 # ❌ 新路径,新版本
# after: 旧版本
volumes:
- name: cni-config
configMap:
name: calico-config # ✅ 旧路径,正常工作
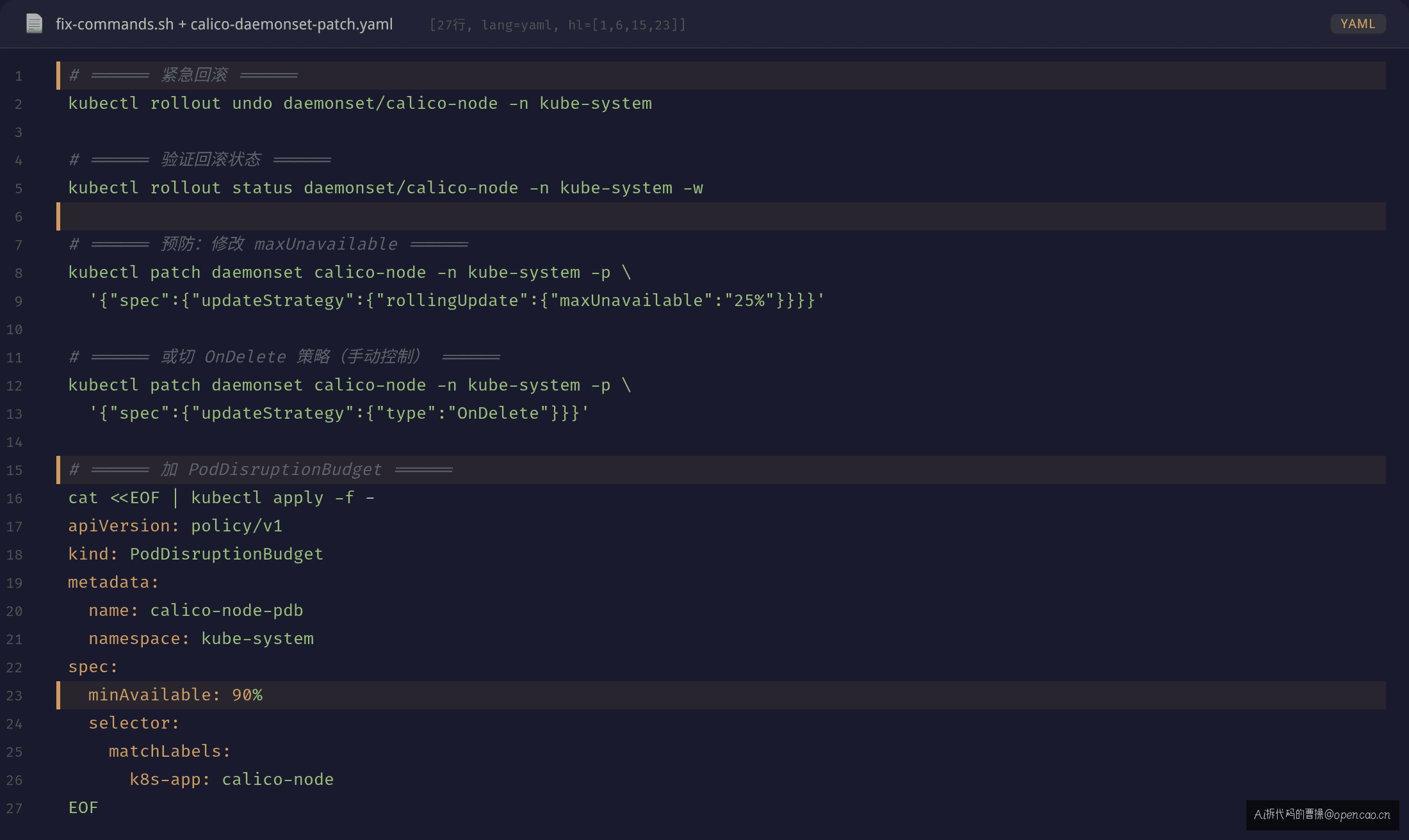
预防配置
# 方案 A:maxUnavailable: 25%(先建后删比例)
updateStrategy:
rollingUpdate:
maxUnavailable: 25%
# 方案 B:OnDelete(手动控制每台节点更新)
updateStrategy:
type: OnDelete
# 方案 C:加 PodDisruptionBudget(PDB - Pod 中断预算,保证最少可用的 Pod 数量)
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: calico-node-pdb
namespace: kube-system
spec:
minAvailable: 90%
selector:
matchLabels:
k8s-app: calico-node
maxUnavailable: 25%限制同时不可用的 Pod 数,不会整节点断网OnDelete策略要求手动删除 Pod 才触发更新,适合 CNI 等关键基础设施- PDB 保证至少 90% 的节点有 CNI 可用
排查 Check-list
故障排查的终点不是修好了——是把排查路径写成 check-list。
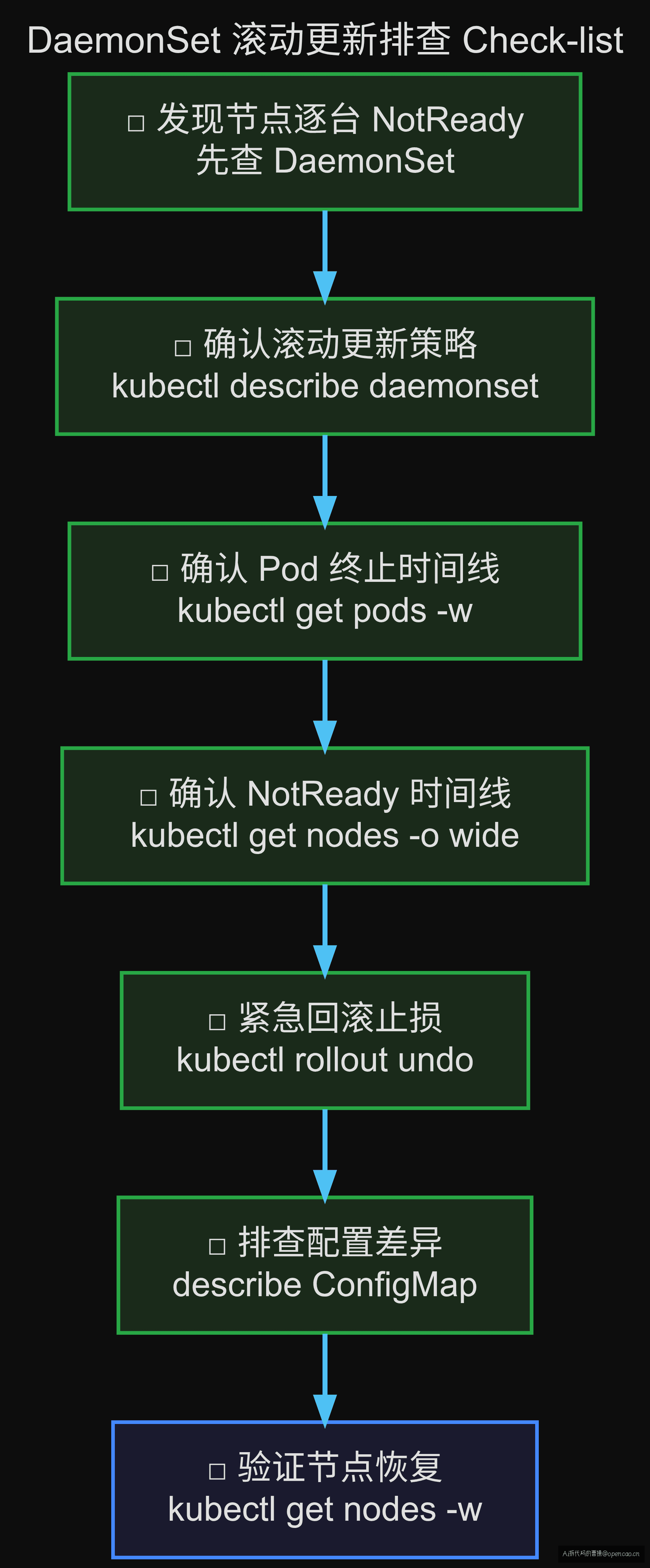
□ 发现节点逐台 NotReady → 先查 DaemonSet
kubectl rollout status daemonset --all -n kube-system
□ 确认滚动更新:
kubectl describe daemonset <name> -n kube-system | grep -A 5 UpdateStrategy
□ 确认 DaemonSet Pod 终止时间线:
kubectl get pods -n kube-system -l k8s-app=<app> -w
□ 确认节点 NotReady 时间线:
kubectl get nodes -o wide | grep NotReady
kubectl describe node <node-name> | grep -A 10 Conditions
□ 回滚止损:
kubectl rollout undo daemonset/<name> -n kube-system
□ 排查新版本配置差异:
kubectl describe daemonset <name> -n kube-system > before.yaml
# 对比版本间 ConfigMap / 环境变量 / 卷挂载变化
□ 验证回滚后节点恢复:
kubectl get nodes -w
kubectl get pods -n kube-system -l k8s-app=<app> -w
附:完整命令清单
# 查看 DaemonSet 滚动更新状态
kubectl rollout status daemonset/calico-node -n kube-system
# 查看 DaemonSet 更新策略
kubectl describe daemonset/calico-node -n kube-system | grep -A 5 UpdateStrategy
# 查看 DaemonSet Pod 状态(持续监听)
kubectl get pods -n kube-system -l k8s-app=calico-node -w
# 查看节点状态
kubectl get nodes -o wide
kubectl describe node <node-name> | grep -A 10 Conditions
# 回滚 DaemonSet
kubectl rollout undo daemonset/calico-node -n kube-system
# 查看 DaemonSet 历史版本
kubectl rollout history daemonset/calico-node -n kube-system
# 回滚到指定版本
kubectl rollout undo daemonset/calico-node -n kube-system --to-revision=<N>
# 节点上查看已退出容器(CRI 层)
crictl ps -a | grep calico
crictl logs <container-id>
# 查看 kubelet 日志
journalctl -u kubelet -f --since "30 minutes ago"
下篇我们聊 DaemonSet OnDelete vs RollingUpdate 选择陷阱——什么场景该用哪种策略,以及为什么你的基础设施 DaemonSet 应该用 OnDelete。


