
DaemonSet 更新策略不一致——OnDelete vs RollingUpdate 选择陷阱
场景: 给 fluent-bit DaemonSet 改了镜像版本,
kubectl rollout restart命令成功了——但 Pod 一个都没重启 路径: Pod 状态 → 策略分层对比 → Node 版本漂移 → 集群策略选择 版本: K8s v1.25
上篇讲了 DaemonSet RollingUpdate 导致节点逐个宕机——原因是 CNI Pod 被终止后节点网络断连,kubelet 无法上报心跳,node controller 直接判 NotReady。教训是"关键基础设施 DaemonSet 别用 RollingUpdate"。但如果你看完上篇后把集群里所有 DaemonSet 都改成了 OnDelete——那你可能掉进了另一个陷阱。
你给 fluent-bit DaemonSet 改了镜像版本,kubectl rollout restart daemonset/fluent-bit,命令返回 daemonset.apps/fluent-bit restarted。两天后检查——Pod 镜像还是 v2.8。命令成功了,什么都没发生。
不是 K8s 出错了——是 OnDelete 策略告诉 DaemonSet controller(在每个节点上运行一个 Pod 的控制器):「等他手动删 Pod,你再建新的。」你改了 YAML,但要等到 Pod 被删除的那天,新版本才真正跑起来。
K8s 的 OnDelete 不帮你更新 Pod——它等你手动删。
【坐标】→ 命令成功,Pod 没动
现象很直接:你做了更新操作,K8s 告诉你"已更新",但 Pod 没变。
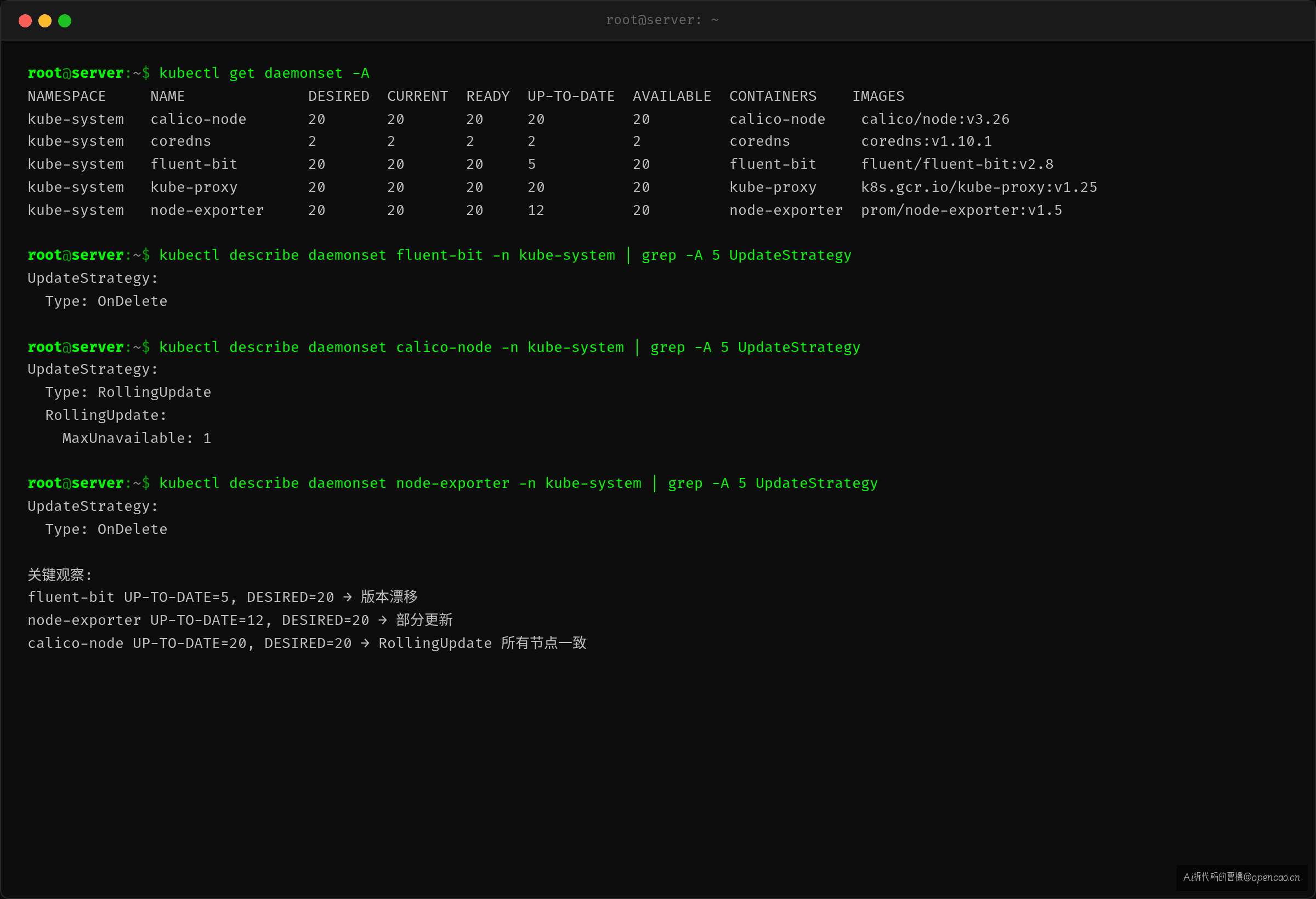
$ kubectl get daemonset -A
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE CONTAINERS IMAGES
kube-system calico-node 20 20 20 20 20 calico-node calico/node:v3.26
kube-system fluent-bit 20 20 20 5 20 fluent-bit fluent/fluent-bit:v2.8 # ← UP-TO-DATE 只有 5
kube-system node-exporter 20 20 20 12 20 node-exporter prom/node-exporter:v1.5
关键字段:UP-TO-DATE 表示当前运行版本与 spec 中 image 一致的 Pod 数量。fluent-bit 的 DESIRED 和 CURRENT 都是 20(所有节点都有 Pod 在跑),但 UP-TO-DATE 只有 5——只有这 5 个 Pod 的镜像版本跟 spec 一致。剩下 15 个节点跑的还是旧版本。
kubectl describe daemonset fluent-bit -n kube-system 看策略配置:
UpdateStrategy: OnDelete
OnDelete(手动删除触发更新——DaemonSet 的一种更新策略,controller 不主动替换 Pod,只在 Pod 被手动删除时才用新模板重建)。C2 — DaemonSet controller 的 syncLoop 在 OnDelete 模式下跳过 Pod 替换逻辑:它只保证"每个节点有一个 Pod 运行"(DESIRED == CURRENT),不保证"每个 Pod 运行的是最新版本"(CURRENT == UP-TO-DATE)。这个跳过的代价就是版本漂移——节点间 DaemonSet 版本不一致。
对比旁边 calico-node 用 RollingUpdate,UP-TO-DATE 等于 DESIRED——所有节点版本一致。
【分层】→ 两种策略,两种命运
排查路径不走传统的 Pod → CRI → Node → 集群逐层式——因为 OnDelete 下的"问题"不是异常行为,而是策略语义本身。这里用对比式分层,直接对照两种策略在不同层面的行为差异。
Pod 层:谁控制 Pod 生命周期
RollingUpdate:DaemonSet controller 在滚动更新模式下,每次选择一个节点,终止其上的旧 Pod,创建新 Pod,等待 Ready,然后继续下一个节点。maxUnavailable 控制同时最多有多少 Pod 不可用。
# DaemonSet RollingUpdate 逻辑(简化)
for each node:
terminate old Pod on node
create new Pod on node
wait for new Pod to become Ready
if timeout: stop
else: next node
controller 在这里是主动驱动者——它决定什么时候替换 Pod,什么时候继续下一台。
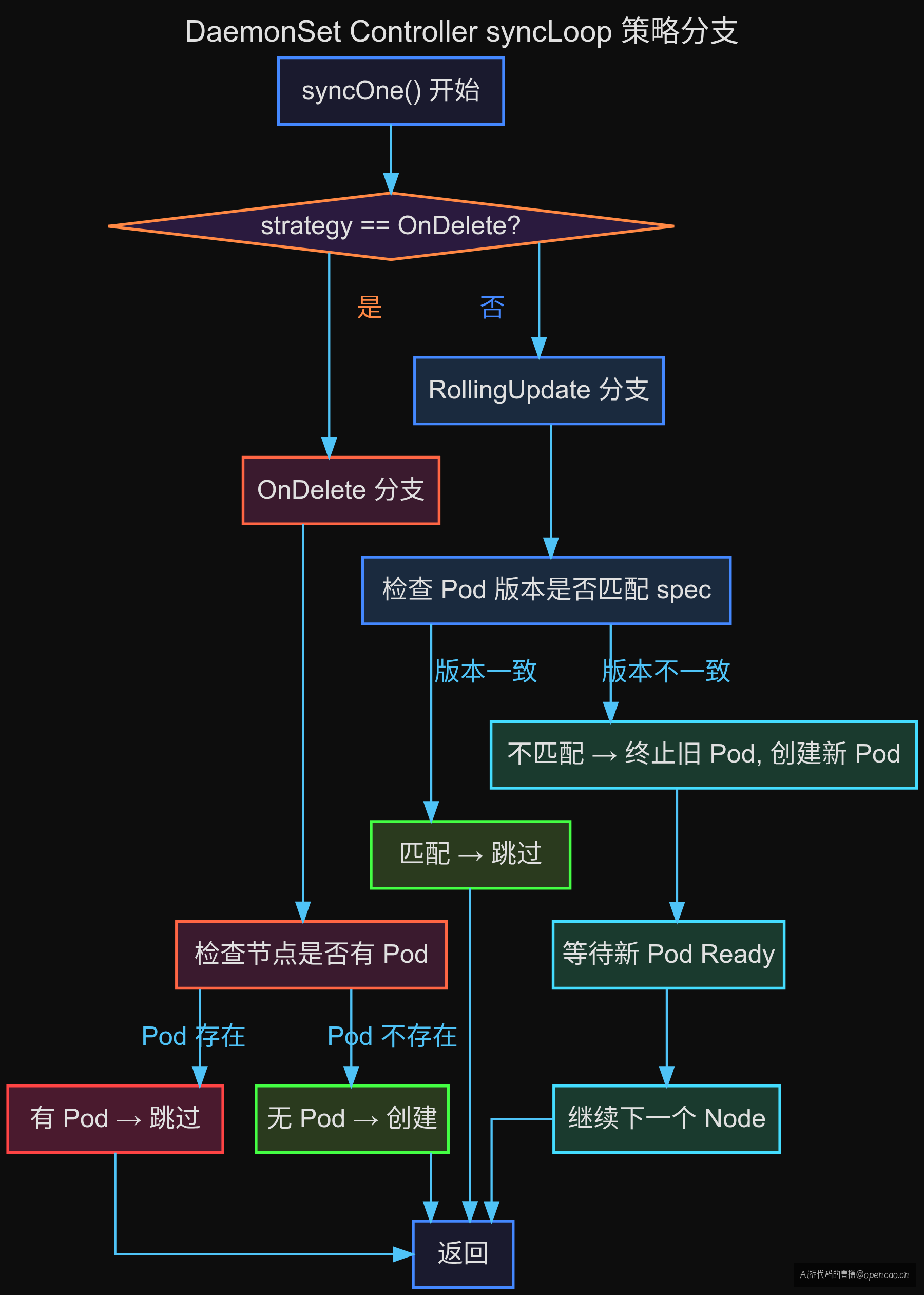
OnDelete:DaemonSet controller 的逻辑完全不同(C2 — 同一个 controller,同一个 syncLoop,一个条件分支区分两种行为):
# DaemonSet OnDelete 逻辑(简化)
for each node:
if strategy == RollingUpdate:
check if Pod needs update → terminate → create → wait
if strategy == OnDelete:
skip update check
only create Pod if node has no Pod
controller 在这里是被动响应者——它只保证"每个节点有 Pod",不保证"每个 Pod 是最新版本"。Pod 不删除,controller 就不重建。
这就是 "kubectl rollout restart 成功了但什么都没发生" 的根因:rollout restart 对 Deployment 会触发滚动更新,但对 OnDelete 模式的 DaemonSet,K8s 只是更新了模板,然后等着——等到有人手动删除 Pod,controller 才用新模板重建。
集群层:策略分支的源码级差异
DaemonSet controller 的核心 sync loop 在处理 Pod 时有一个关键分支:
// DaemonSet controller sync logic(概念代码)
func (dsc *DaemonSetController) syncOne(key string) error {
// ... 获取 DaemonSet、Node 列表、现有 Pod ...
if ds.Spec.UpdateStrategy.Type == apps.OnDeleteDaemonSetStrategyType {
// OnDelete: 只保证每个节点有 Pod
// 跳过所有替换逻辑
for _, node := range nodes {
if !podExistsOnNode(node) {
dsc.createPod(ds, node)
}
}
return nil
}
// RollingUpdate: 检查 Pod 是否需要替换
for _, node := range nodes {
pod := getPodOnNode(node)
if needsUpdate(pod, ds) {
if canReplace(node, maxUnavailable) {
dsc.deletePod(pod)
dsc.createPod(ds, node)
}
}
}
return nil
}
C2 — 关键发现:OnDelete 分支中完全没有"检查 Pod 版本是否匹配 spec"的逻辑。它只检查"节点上有没有 Pod",有就跳过。这意味着即使你改了 image、改了 command、改了环境变量——只要 Pod 还在,controller 就当没看见。
这就是 UP-TO-DATE 不等于 DESIRED 的技术原因:不是 controller 没能力检查——是 OnDelete 策略让它跳过了检查。
Node 层:版本漂移的产生
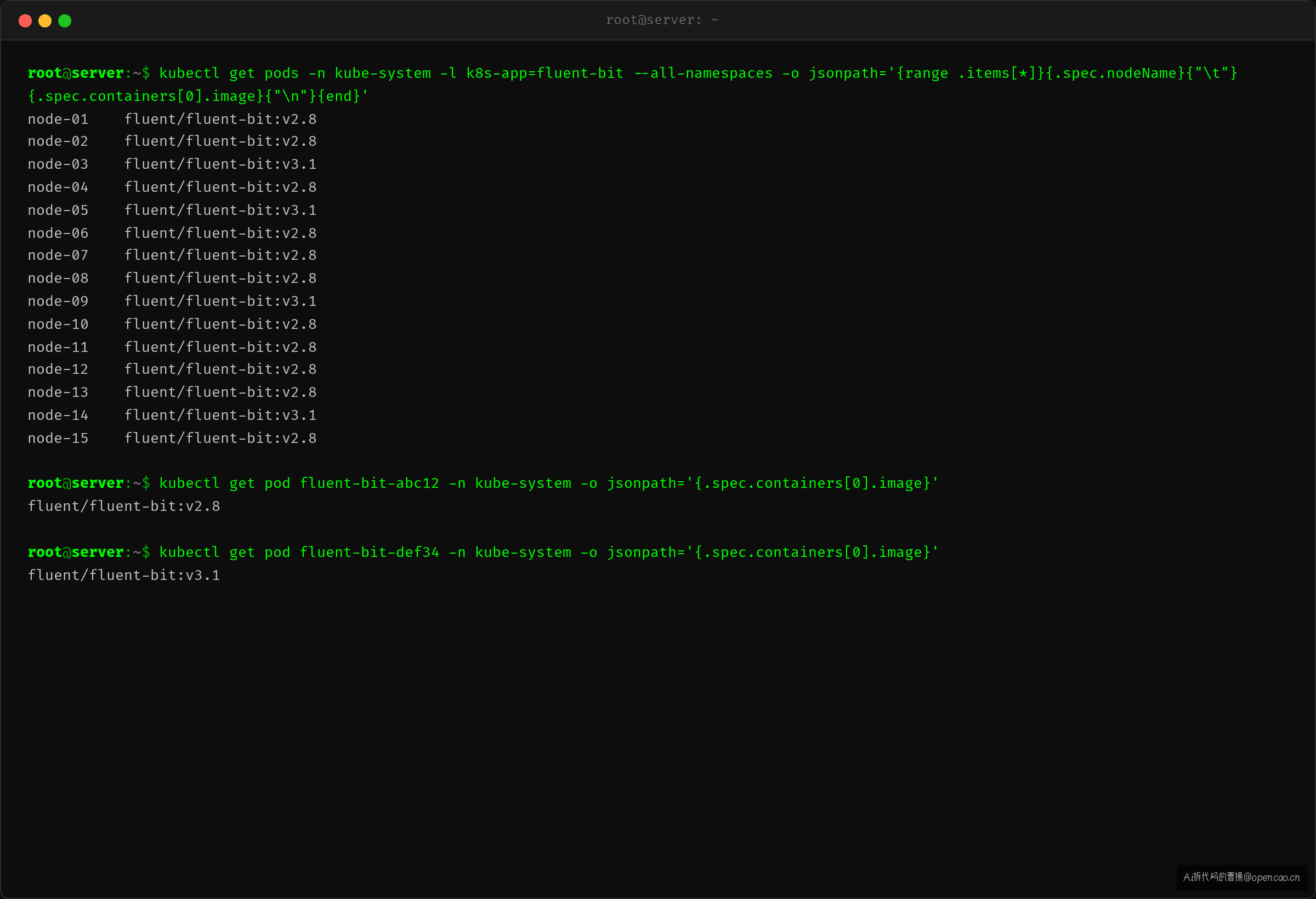
OnDelete 下,版本一致性取决于"哪些节点的 Pod 被人为删除过"。
# 节点 A — 从未手动删过 Pod
$ kubectl get pod fluent-bit-abc12 -n kube-system -o jsonpath='{.spec.containers[0].image}'
fluent/fluent-bit:v2.8
# 节点 B — 运维曾经手动删除 Pod 排障
$ kubectl get pod fluent-bit-def34 -n kube-system -o jsonpath='{.spec.containers[0].image}'
fluent/fluent-bit:v3.1
两个节点,同一个 DaemonSet,两个版本。这不是故障——是 OnDelete 的语义本身导致了版本漂移。集群规模越大,节点间版本差异越明显——因为时间越长,不同节点的 Pod 被删除和重建的"机缘"就越不同。
【路径】→ 🔍 诊断命令
遇到"改了 DaemonSet 但 Pod 没更新",三步确认策略和版本分布:
# 1. 看 DaemonSet 更新策略
kubectl describe daemonset <name> -n <ns> | grep -A 5 UpdateStrategy
# 输出: Type: OnDelete → 手动更新,不是 RollingUpdate
# 2. 看版本一致性(UP-TO-DATE vs DESIRED)
kubectl get daemonset -A -o custom-columns=\
NAME:.metadata.name,NS:.metadata.namespace,\
DESIRED:.status.desiredNumberScheduled,\
CURRENT:.status.currentNumberScheduled,\
UP-TO-DATE:.status.updatedNumberScheduled,\
IMAGE:.spec.template.spec.containers[0].image
# 3. 检查各节点实际运行的镜像版本
kubectl get pods -n <ns> -l k8s-app=<app> \
-o jsonpath='{range .items[*]}{.spec.nodeName}{"\t"}{.spec.containers[0].image}{"\n"}{end}'
判断标准:UP-TO-DATE < DESIRED 且策略为 OnDelete → 正常行为,不是异常。需要直接触发更新。
【定位】→ 最常误判
❌ 大多数人会这么想:
"上篇说 RollingUpdate 导致节点宕机 → 全改成 OnDelete 更安全 → 以后不管了。" 或者:"改了 image 但 Pod 没变 → K8s 有 bug → 重装 DaemonSet → 重装后发现还得手动删 Pod。"
✅ 正确的排查思路:
策略选择取决于 DaemonSet 的角色,不是一刀切"全用 RollingUpdate"或"全用 OnDelete"。选择标准是回答两个问题: 1. 这个 DaemonSet 的 Pod 如果重启,会影响节点可用性吗? 2. 这个 DaemonSet 需要及时更新吗?

| DaemonSet 类型 | 推荐策略 | 为什么 |
|---|---|---|
| CNI(Calico/Cilium/Flannel) | OnDelete | Pod 终止 = 节点断网,更新必须手动控制窗口 |
| kube-proxy | OnDelete | 节点网络规则依赖,中断影响已有连接 |
| 存储插件(csi-node) | OnDelete | 数据面关键组件,Pod 终止可能影响挂载卷 |
| 日志采集(fluent-bit/filebeat) | RollingUpdate | 中断可接受,安全补丁和格式更新需及时 |
| 监控 agent(node-exporter/datadog) | RollingUpdate | 版本一致性重要,短时中断不影响业务 |
| 安全 agent(falco/trivy) | RollingUpdate | 安全规则更新必须及时推送到所有节点 |
两者的差异:前者只看到了 RollingUpdate 的问题(激进的自动更新 → 级联故障),直接跳到"全用 OnDelete"(保守的手动更新 → 版本漂移)。正确的做法是按组件角色做策略分类,而不是按"安全 vs 危险"做一刀切。
紧急处理方法
OnDelete 下,三种方式触发更新:
# 方式 1:逐个节点删除 Pod(推荐 —— 粒度最细)
kubectl delete pod fluent-bit-abc12 -n kube-system
# controller 自动用新模板重建
# 方式 2:滚动删除全部 Pod(一次性全部重建)
kubectl delete pod -n kube-system -l k8s-app=fluent-bit
# 所有 fluent-bit Pod 同时被删除并重建(注意这个更快但有风险)
# 方式 3:临时改策略触发全量更新(然后记得改回)
kubectl patch daemonset fluent-bit -n kube-system \
-p '{"spec":{"updateStrategy":{"type":"RollingUpdate"}}}'
kubectl rollout restart daemonset/fluent-bit -n kube-system
kubectl patch daemonset fluent-bit -n kube-system \
-p '{"spec":{"updateStrategy":{"type":"OnDelete"}}}'
C2 — 方式 3 的原理:改为 RollingUpdate 后 controller 的 syncLoop 再次进入"检查 Pod 版本 → 发现不匹配 → 终止旧 Pod → 创建新 Pod"的分支。所有 UP-TO-DATE < DESIRED 的 Pod 会被逐节点替换。替换完再改回 OnDelete,恢复保守策略。
【标点】→ 策略选择矩阵 + Check-list
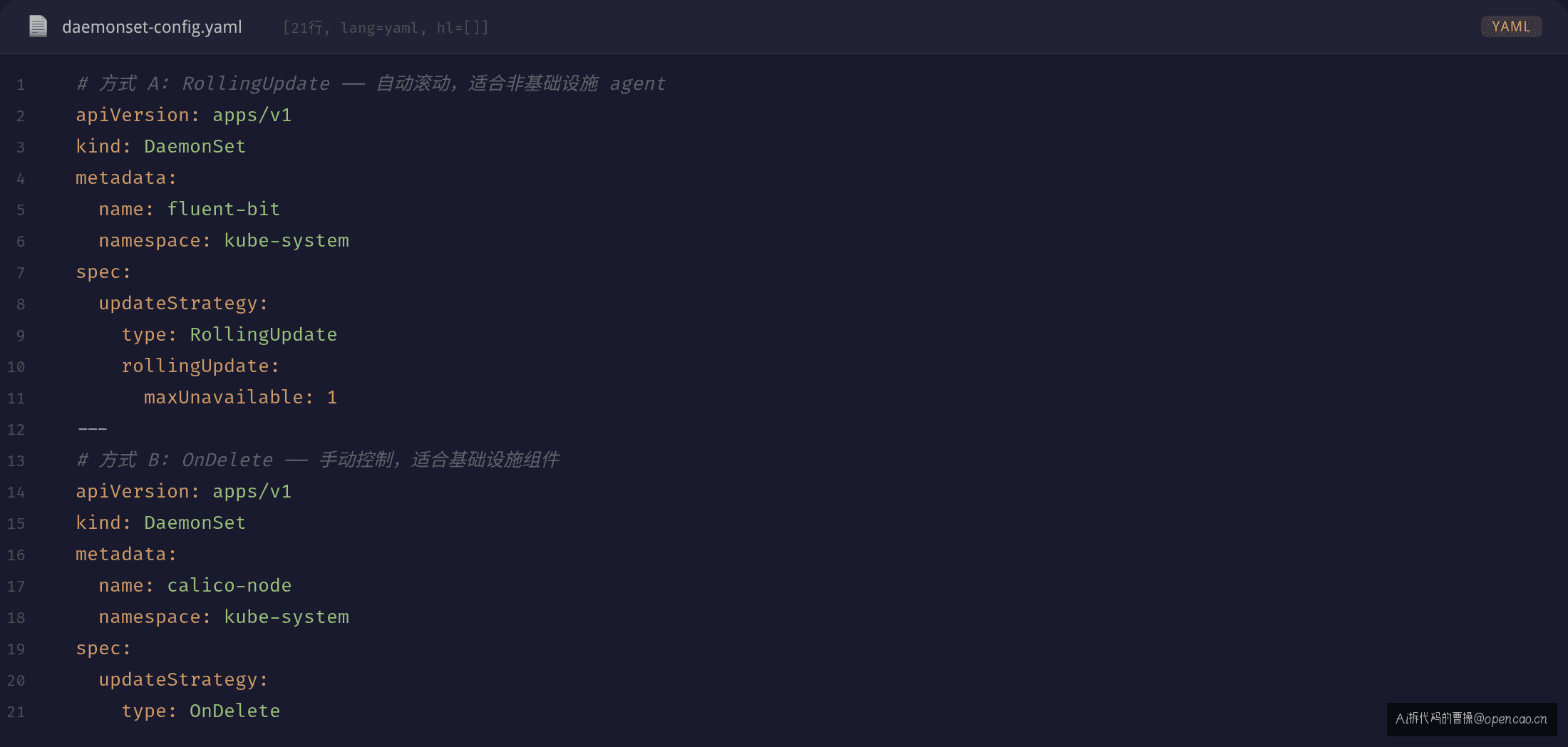
# 策略配置模板
# 方式 A:RollingUpdate —— 自动滚动,适合非基础设施 agent
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluent-bit
namespace: kube-system
spec:
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # 同一时间最多 1 个节点不可用
# 方式 B:OnDelete —— 手动控制,适合基础设施组件
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: calico-node
namespace: kube-system
spec:
updateStrategy:
type: OnDelete
一个 YAML 字段没配,不是 K8s 会帮你兜底——是它会按默认值运行,而默认值往往不适合你的场景。DaemonSet 的默认更新策略是 RollingUpdate,这在大多数场景下正确——但恰好对 CNI、kube-proxy 这种最关键的组件是危险的。而 OnDelete 看起来"安全"——却又藏了版本漂移的陷阱。
排查 Check-list
故障排查的终点不是修好了——是把排查路径写成 check-list。
□ 确定 DaemonSet 策略:
kubectl describe daemonset <name> -n <ns> | grep -A 5 UpdateStrategy
□ 检查版本一致性:
kubectl get daemonset -A | grep -v "UP-TO-DATE"
□ 如果 UP-TO-DATE < DESIRED 且策略为 OnDelete:
这不是异常——是 OnDelete 的语义。
需要手动删除 Pod 触发重建,或用 patch 临时切到 RollingUpdate。
□ 选择策略时回答两个问题:
① "这个 DaemonSet 的 Pod 终止会影响节点可用性吗?"
是 → OnDelete 否 → RollingUpdate(往下看第 ②)
② "这个 DaemonSet 需要及时更新吗?"
是 → RollingUpdate 否 → 两者均可
□ 滚动更新关键基础设施前,确认 maxUnavailable 和 PDB:
kubectl describe daemonset <name> -n <ns> | grep maxUnavailable
kubectl get pdb -n <ns> | grep <app>
□ 更新后验证版本一致性:
kubectl get daemonset -A -o wide
kubectl get pods -n <ns> -l k8s-app=<app>
附:完整命令清单
# 查看 DaemonSet 更新策略
kubectl describe daemonset <name> -n <ns> | grep -A 5 UpdateStrategy
# 查看版本一致性
kubectl get daemonset -A -o custom-columns=\
NAME:.metadata.name,NS:.metadata.namespace,\
DESIRED:.status.desiredNumberScheduled,\
CURRENT:.status.currentNumberScheduled,\
UP-TO-DATE:.status.updatedNumberScheduled,\
IMAGE:.spec.template.spec.containers[0].image
# 查看各节点 Pod 实际镜像版本
kubectl get pods -n <ns> -l k8s-app=<app> \
-o jsonpath='{range .items[*]}{.spec.nodeName}{"\t"}{.spec.containers[0].image}{"\n"}{end}'
# OnDelete 下触发更新 —— 单个节点
kubectl delete pod <pod-name> -n <ns>
# OnDelete 下触发全量更新 —— 临时改策略
kubectl patch daemonset <name> -n <ns> \
-p '{"spec":{"updateStrategy":{"type":"RollingUpdate"}}}'
kubectl rollout restart daemonset/<name> -n <ns>
kubectl patch daemonset <name> -n <ns> \
-p '{"spec":{"updateStrategy":{"type":"OnDelete"}}}'
# 回滚 DaemonSet 版本
kubectl rollout undo daemonset/<name> -n <ns>
# 查看 DaemonSet 历史版本
kubectl rollout history daemonset/<name> -n <ns>
# 查看节点 NotReady 时间线(发现 RollingUpdate 级联问题时用)
kubectl get nodes -o wide | grep NotReady
kubectl describe node <node-name> | grep -A 10 Conditions
下篇我们聊 DaemonSet 优雅终止与 PodDisruptionBudget——当你的 DaemonSet 用 RollingUpdate 时,如何保证更新过程中服务不中断。
📺 公众号「Ai拆代码的曹操」 🌟 知识星球「Ai拆代码的曹操」


