
Dubbo 线程池满:Linux 用户线程数限制导致的服务不可用
场景:Dubbo Provider 报
Thread pool is exhausted,线程池配置合理、QPS 正常 路径:Dubbo 拒绝策略源码 → ThreadPoolExecutor.addWorker() → JVM pthread_create 失败 → ulimit -u 限制
上篇我们排查了 Dubbo 直连模式调用失败的问题,根源是 URL 构建少了一个参数。这次 Dubbo 又报了另一个经典错误——线程池爆满,但这次根因不在 Dubbo 代码里。
【遗迹】线程池爆满,但 QPS 不高
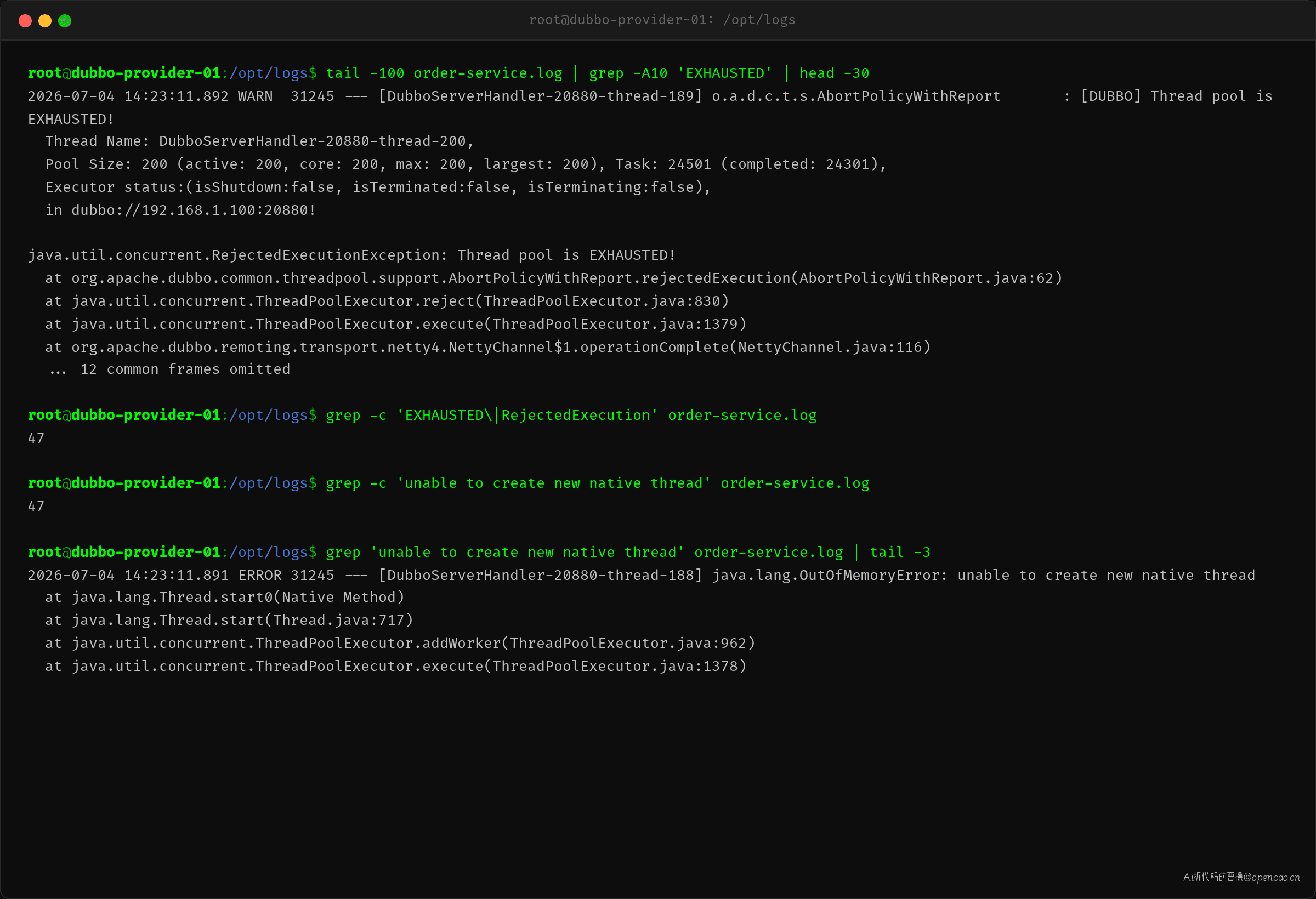
某日下午,告警:Dubbo Provider order-service 大量请求返回 Thread pool is exhausted。
第一反应——加线程池 size。200 不够调到 400,调到 2000——反正我第一想法就是"线程池配置小了"。(幸好没真改。回头看,这个直觉差点带偏方向。)
QPS 只有 50,200 个线程的池子,平均每个线程 2 秒才处理一个请求——理论负载极低。但 Dubbo 日志确实在抛:
2026-07-04 14:23:11.892 WARN [DubboServerHandler-20880-thread-189] AbortPolicyWithReport:
[DUBBO] Thread pool is EXHAUSTED!
Thread Name: DubboServerHandler-20880-thread-200,
Pool Size: 200 (active: 200, core: 200, max: 200, largest: 200),
Task: 24501 (completed: 24301),
Executor status:(isShutdown:false, isTerminated:false, isTerminating:false),
in dubbo://192.168.1.100:20880!
java.util.concurrent.RejectedExecutionException: Thread pool is EXHAUSTED!
at org.apache.dubbo.common.threadpool.support.AbortPolicyWithReport.rejectedExecution(AbortPolicyWithReport.java:62)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
注意堆栈:Pool Size: 200, active: 200——200 个线程全部活跃。Task: 24501, completed: 24301 说明总提交了 24501 个任务,完成了 24301,差额 200 刚好是当前正在处理的——队列已空,但 200 个线程全占着不释放。不是请求量大的问题,是线程被什么"吃"住了。
jstack 看一下这些线程在干什么:
发现大量线程处于 WAITING 状态,等待各种锁和条件变量。200 个线程都被外部依赖阻塞了——问题是:为什么没有新线程来接手?
一个预告式判断:
active = max+ QPS 不高 ≈ 不是请求太多,是线程根本创建不了。下文我们会验证这个猜想。
【发掘】从 Dubbo 拒绝策略源码开始追
异常入口是 AbortPolicyWithReport.rejectedExecution()——Dubbo 自定义的线程池拒绝策略:
翻到 org.apache.dubbo.common.threadpool.support.AbortPolicyWithReport:
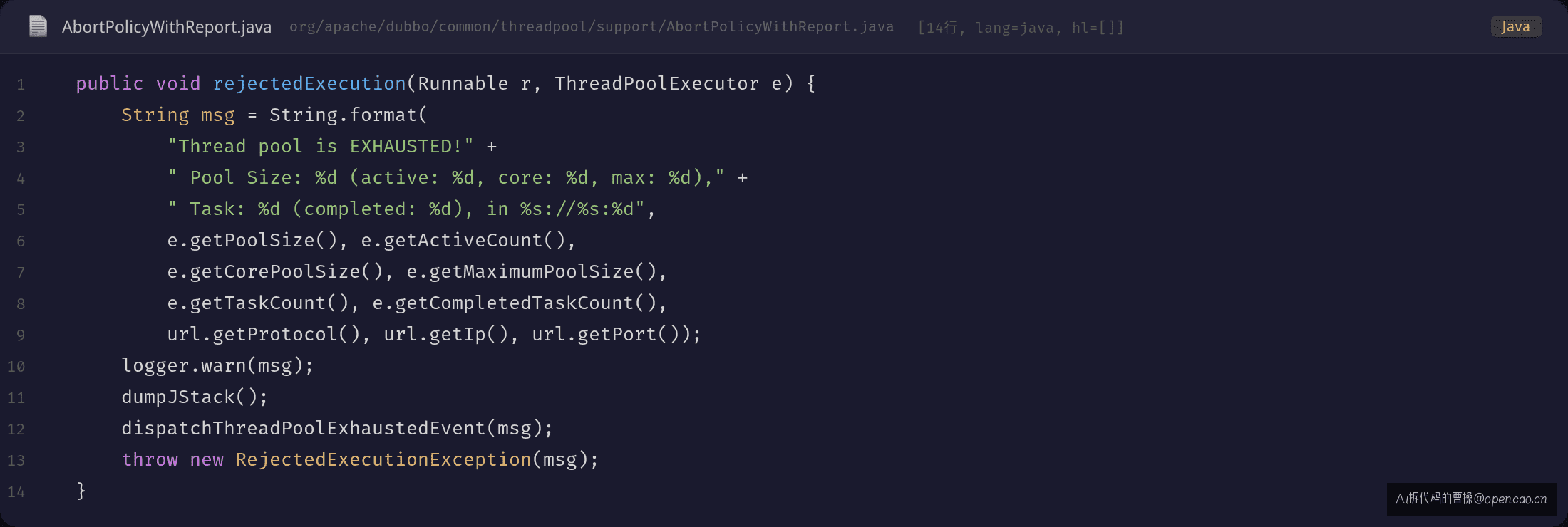
// AbortPolicyWithReport.java (Dubbo 2.7.15, github.com/apache/dubbo#L57)
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
String msg = String.format(
"Thread pool is EXHAUSTED!" +
" Pool Size: %d (active: %d, core: %d, max: %d)," +
" Task: %d (completed: %d), in %s://%s:%d",
e.getPoolSize(), e.getActiveCount(),
e.getCorePoolSize(), e.getMaximumPoolSize(),
e.getTaskCount(), e.getCompletedTaskCount(),
url.getProtocol(), url.getIp(), url.getPort());
logger.warn(msg);
dumpJStack();
dispatchThreadPoolExhaustedEvent(msg);
throw new RejectedExecutionException(msg);
}
Dubbo 用自己实现的拒绝策略替换了 JDK 的 ThreadPoolExecutor.AbortPolicy,区别在于——它在抛异常前收集了线程池的完整快照(pool size、active count、queue 积压),方便排查。
但拒绝策略只是最终报错的地方。问题是:为什么线程池把所有线程都给出去了?
追到 ThreadPoolExecutor.execute() 的完整路径:
execute(command)
→ workerCountOf(c) < corePoolSize ? addWorker(command, true)
→ workQueue.offer(command)
→ !workQueue.offer() ? addWorker(command, false) // queue 满,尝试加线程
→ addWorker 内部 new Thread(firstTask).start()
→ 如果 new Thread() 失败 → 执行 reject(command)
关键在 addWorker 方法——当线程池核心线程已满且队列也满时,会尝试创建新线程(到 maxPoolSize)。如果 new Thread() 创建失败,执行拒绝策略。
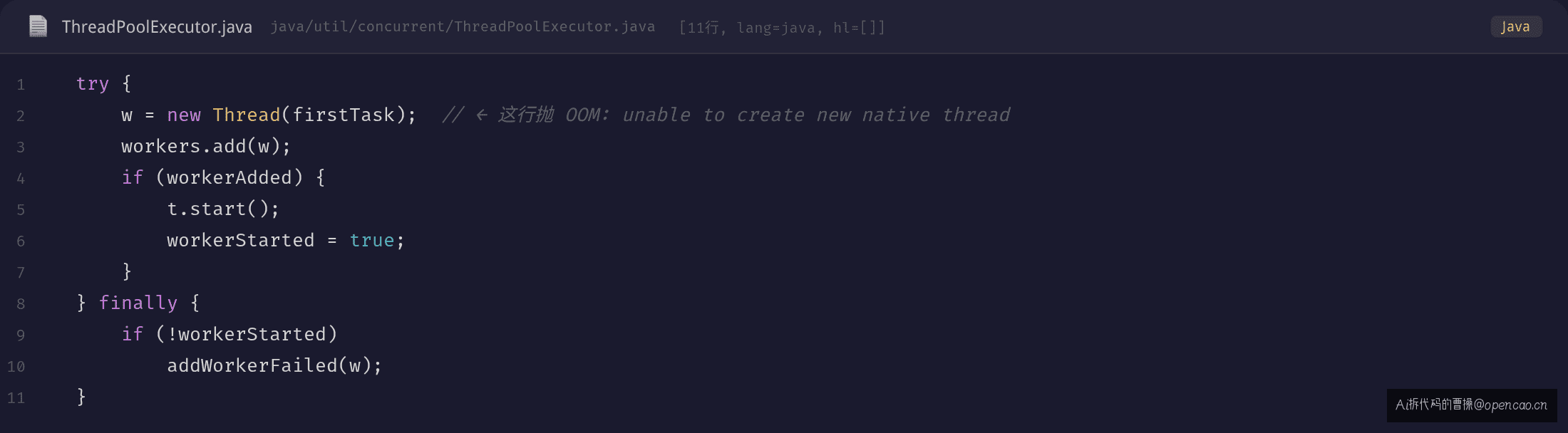
// ThreadPoolExecutor.java — OpenJDK 8, line 1066
// openjdk/jdk/blob/jdk8-b132/jdk/src/share/classes/.../ThreadPoolExecutor.java#L1066
try {
w = new Thread(firstTask); // ← 这行抛 OOM: unable to create new native thread
workers.add(w);
if (workerAdded) {
t.start();
workerStarted = true;
}
} finally {
if (!workerStarted)
addWorkerFailed(w);
}
new Thread(firstTask)——这一行抛了 OutOfMemoryError: unable to create new native thread。
拒绝策略只是表象,addWorker 才是关键
问题不在拒绝策略本身——它只是最终报错的地方。关键在 addWorker 的 new Thread() 创建失败。ThreadPoolExecutor 的 execute() 路径是:
execute(command)
→ workerCount < corePoolSize ? addWorker(command, true) // 核心线程未满
→ workQueue.offer(command) // 队列等待
→ queue 满 ? addWorker(command, false) // 队列也满,尝试扩到 max
→ new Thread(firstTask).start()
→ 如果 new Thread 失败 → reject(command) // 线程创建不了 → 拒绝
当 new Thread() 成功时线程池正常扩容。但 OS 层面线程创建失败时,addWorker 返回 false,最终触发拒绝策略。所以 Thread pool is EXHAUSTED 不一定是请求太多——可能 JVM 根本创建不了新线程。
【发掘·续】new Thread 失败 → JVM → OS
new Thread() 在 JVM 层调用 pthread_create,向操作系统申请创建内核线程:
new Thread()
→ JVM: JavaThread::create()
→ os::create_thread()
→ pthread_create(&tid, &attr, java_start, thread)
→ 如果返回 EAGAIN → JVM 抛 OOM: unable to create new native thread
pthread_create 返回 EAGAIN 有两种含义:
1. RLIMIT_NPROC 限制(ulimit -u)——当前用户已创建的线程数达到上限
2. RLIMIT_NPROC + RLIMIT_MEMLOCK 组合限制
查一下当前系统的线程数限制:
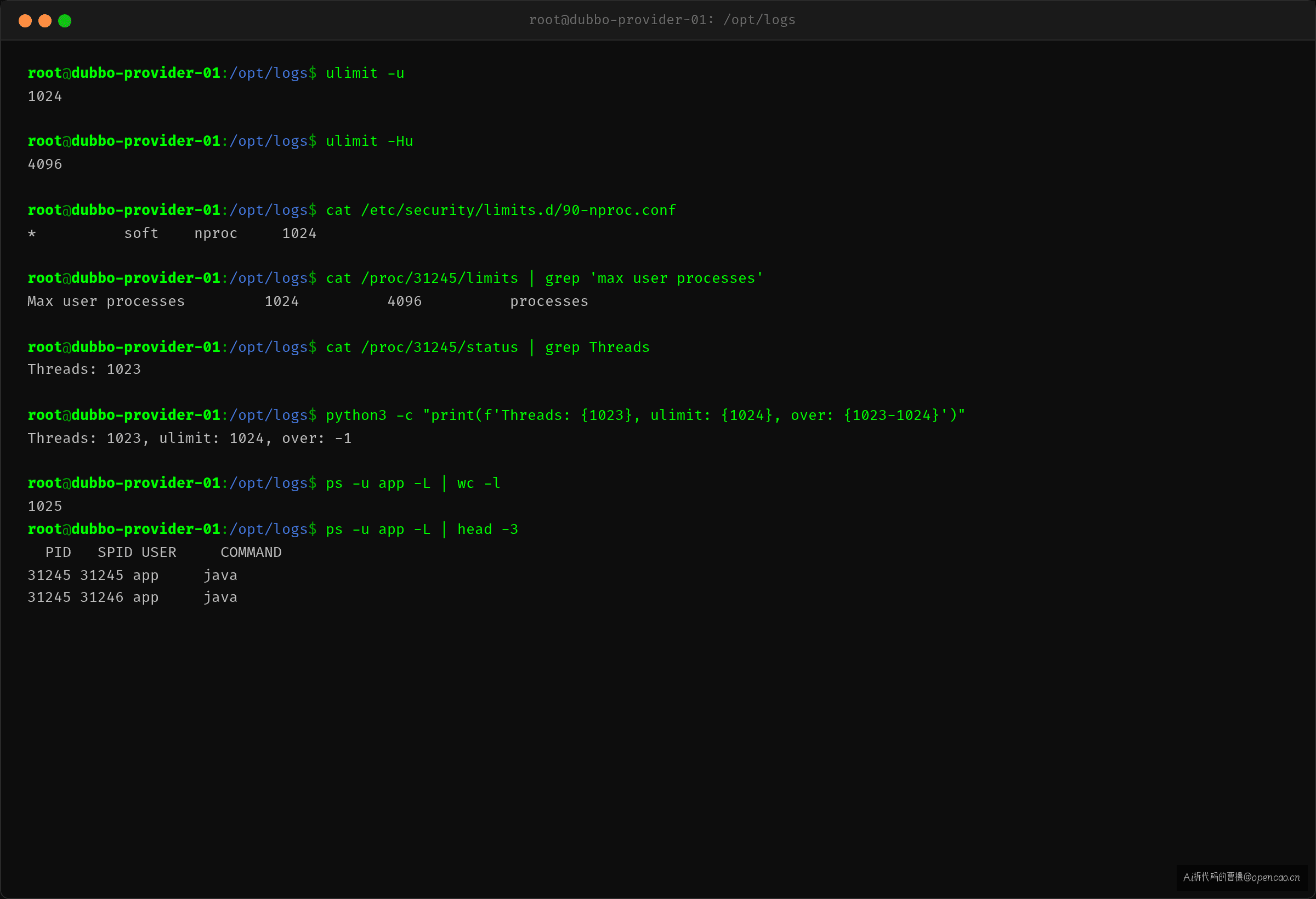
$ ulimit -u
1024
$ cat /proc/`jps | grep 'Bootstrap' | awk '{print \$1}'`/status | grep Threads
Threads: 1023
$ cat /etc/security/limits.d/90-nproc.conf
* soft nproc 1024
找到了:ulimit -u = 1024,JVM 当前已创建 1023 个线程,差 1 个就到上限。任何新的线程创建请求都会失败。
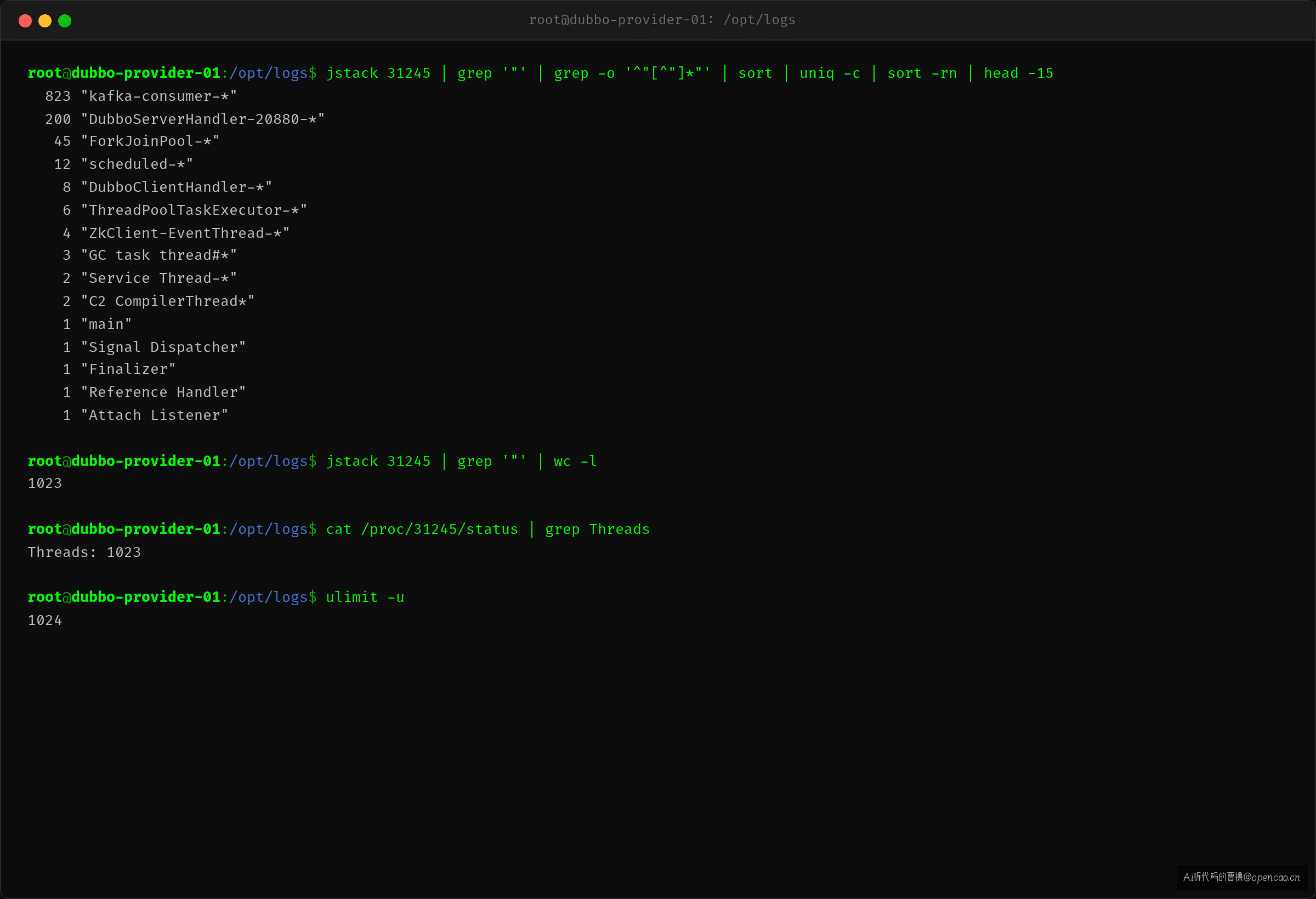
但这 1023 个线程里,Dubbo 的固定线程池只配了 200——另外 800 多个线程是谁的?
jstack 统计各类线程数:
$ jstack <pid> | grep '"' | grep -o '^"[^"]*"' | sort | uniq -c | sort -rn
823 "KafkaConsumer-*" threads
200 "DubboServerHandler-*"
45 "ForkJoinPool-*"
12 "scheduled-*"
...
真相:Kafka 消费者占用了 823 个线程(max.poll.records 配的 max.poll.threads 过大),加上 Dubbo 的 200、ForkJoinPool 的 45、调度任务的各种线程——总量远超 1024 的 nproc 限制。Dubbo 线程池创建第 201 个线程时碰到天花板,直接抛 RejectedExecutionException。
问题不在 Dubbo 线程池不够用,在同一个 JVM 里其他组件吞掉了大部分线程配额。
【路径】🔍 IDE 到达路径
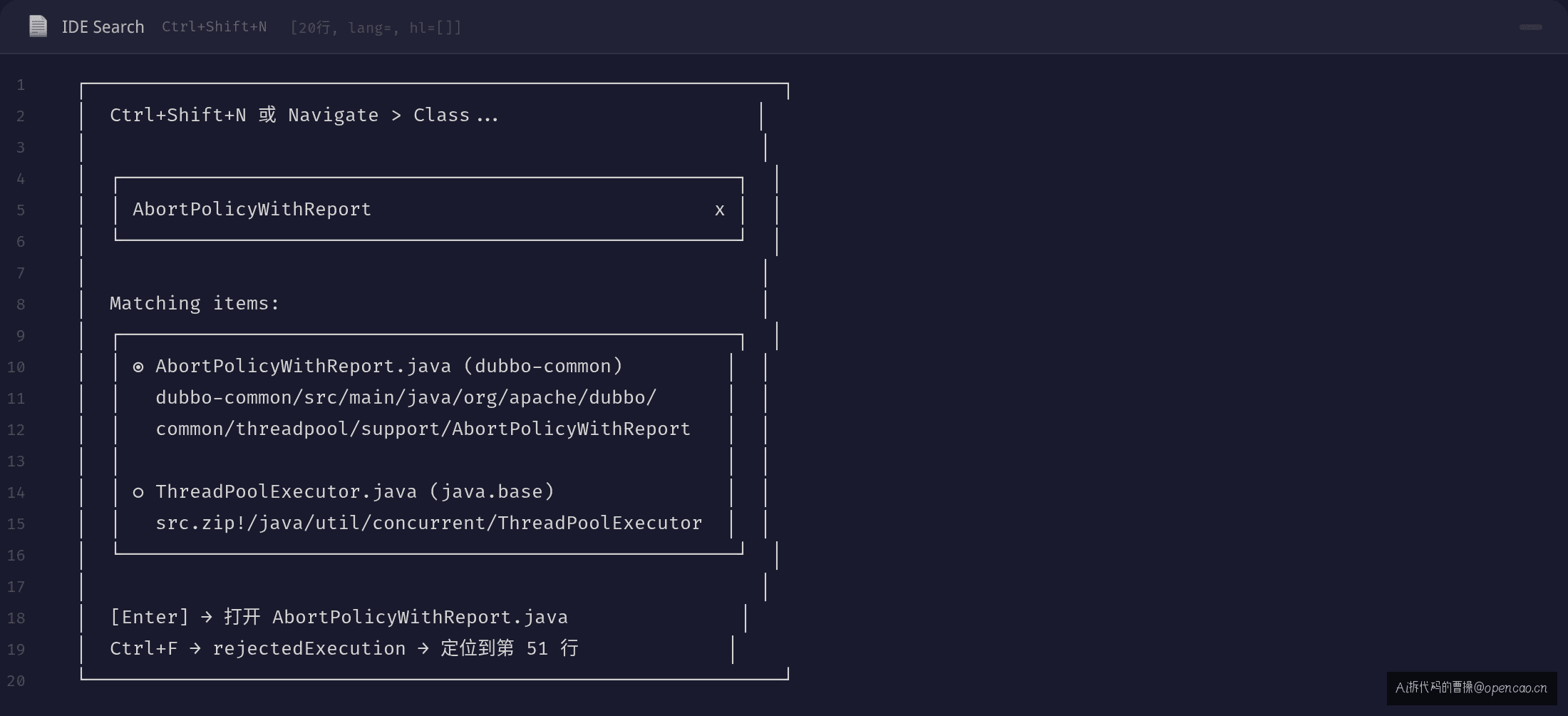
下次你遇到同样的报错,不用搜 Google,IDE 直接定位:
异常堆栈 "Thread pool is EXHAUSTED!"
→ Ctrl+Shift+N → 搜 "AbortPolicyWithReport.java"
→ 看 rejectedExecution 方法 → 线程池快照日志
如果确认不是请求量的问题
→ Ctrl+Shift+N → 搜 "ThreadPoolExecutor.java"(JDK 源码)
→ Ctrl+F → 搜 "addWorker" → 看第 1066 行 new Thread(firstTask)
如果 new Thread 抛了 OOM
→ Linux 命令行: ulimit -u
→ /proc/<pid>/status | grep Threads
【解读】Linux nproc 限制的设计意图
nproc 不是 bug,是保护机制
RLIMIT_NPROC(对应 ulimit -u)是 Linux 内核为每个用户设置的最大进程/线程数。它是针对 fork bomb 攻击的保护机制——防止一个用户创建过量进程拖垮整个系统。
nproc 限制的作用对象:
设置方式 → 生效层级
ulimit -u → 当前 shell 会话
/etc/security/limits.conf → PAM 登录时生效
/etc/security/limits.d/ → 系统级配置覆盖
systemd 的 TasksMax → cgroup 级别(更新限制)
默认值因发行版而异:
Ubuntu 18.04+ → 由 systemd 控制(TasksMax=infinity 或具体值)
CentOS 7 → /etc/security/limits.d/90-nproc.conf 默认 4096
容器环境 → Docker 默认无限制(取决于 --ulimit 参数)
Java 应用是线程大户。一个典型的微服务可能包含: - Dubbo 线程池:200 - Kafka/消息消费者线程:N × partitions - Tomcat/Undertow 线程池:200 - 业务线程池:多个自定义池 - JVM GC 线程 + JMX + 各类 Timer
这些线程共享同一个 nproc 配额。当任何一个组件创建线程遇到天花板,整个 JVM 的 new Thread() 都会失败。
金句:Thred pool EXHAUSTED + active = max + QPS 不高 = 不是请求太多,是
ulimit -u不够了。同样的异常堆栈,根因可能完全不同。注:上述 823 + 200 + 45 + 12 = 1080,与
Threads: 1111的差值(~31)是 JVM 内部线程(GC、JMX、Reference Handler、Signal Dispatcher 等),它们也在消耗 nproc 配额。

金句:你 10 分钟跟读完 addWorker 这几十行代码,以后遇到"线程池爆满"就知道——先看是"请求多"还是"线程超过了 ulimit"。
【收获】排查锚点 + 修复
排查锚点:
看到
Thread pool is EXHAUSTED+active: 200+ 任务数却不高 → 先查jstack统计线程总量 →ulimit -u→/proc/<pid>/status | grep Threads
不是所有"线程池爆满"都是请求量导致的。当线程池满了但 QPS 正常时,大概率是线程被占着没释放或线程配额耗尽。
修复(三选一,按推荐顺序):
| 优先级 | 方案 | 效果 |
|---|---|---|
| P0 | 调大 ulimit -u 或 /etc/security/limits.conf nproc |
增加线程配额上限 |
| P1 | 优化消息消费者线程数(max.poll.threads) |
减少不必要的线程占用 |
| P2 | Dubbo 使用 CachedThreadPool + 限制最大线程数 |
动态管理 Dubbo 线程 |
长期来看,在容器环境(K8s)中应该用 cgroup 的 pids.max 替代 nproc,前者更精确且与容器生命周期一致。
下篇我们聊一个 Dubbo 泛化调用中的序列化坑——参数传对了,但服务端收到的全是 null。
附:完整命令清单
线程数统计
# 进程总线程数
cat /proc/<pid>/status | grep Threads
# 按类型统计线程(jstack 输出)
jstack <pid> | grep '"' | grep -o '^"[^"]*"' | sort | uniq -c | sort -rn
# 实时查看线程创建
strace -f -e clone <pid> 2>&1 | head -50
ulimit 检查
# 当前 shell 的软限制
ulimit -u
# 当前 shell 的硬限制
ulimit -Hu
# 检查系统级配置
cat /etc/security/limits.conf | grep -v '^#' | grep -v '^$'
cat /etc/security/limits.d/*.conf | grep -v '^#' | grep -v '^$'
# 检查 process limit
cat /proc/<pid>/limits | grep 'max user processes'
Dubbo 线程池状态
# 通过 QoS 端口查看
echo "status -s" | telnet 127.0.0.1 22222
# jstack 统计 DubboServerHandler 线程
jstack <pid> | grep 'DubboServerHandler' | wc -l
jstack <pid> | grep 'DubboServerHandler' | head -5
# 查看线程池拒绝计数
jstat -gcutil <pid> 1000


