
抛硬币10次8次正面,第11次是多少?——频率派 vs 贝叶斯派,两种看世界的方式
本文是 AI 技术实战系列的第 1 篇(AI 基础与原理) 叙事框架:
认知冲突 → 核心思想 → 历史脉络 → 深度对比 → 原理拆解 → 实战抉择 → 全景总结
一枚硬币引发的认知冲突
你抛一枚硬币 10 次,看到 8 次正面、2 次反面。现在我问你:第 11 次抛出正面的概率是多少?
你的第一反应可能是 80%——因为观测频率是 80%。但冷静想想:如果硬币是均匀的,真实概率应该是 50%。10 次样本太小,不足以得出可靠结论。那么,你到底该相信观测结果,还是相信先验知识?
这个问题看似简单,却把统计学界撕裂了 300 年。更让人困惑的是——两种完全不同的推理方式,都给出了各自合理但结论不同的答案。
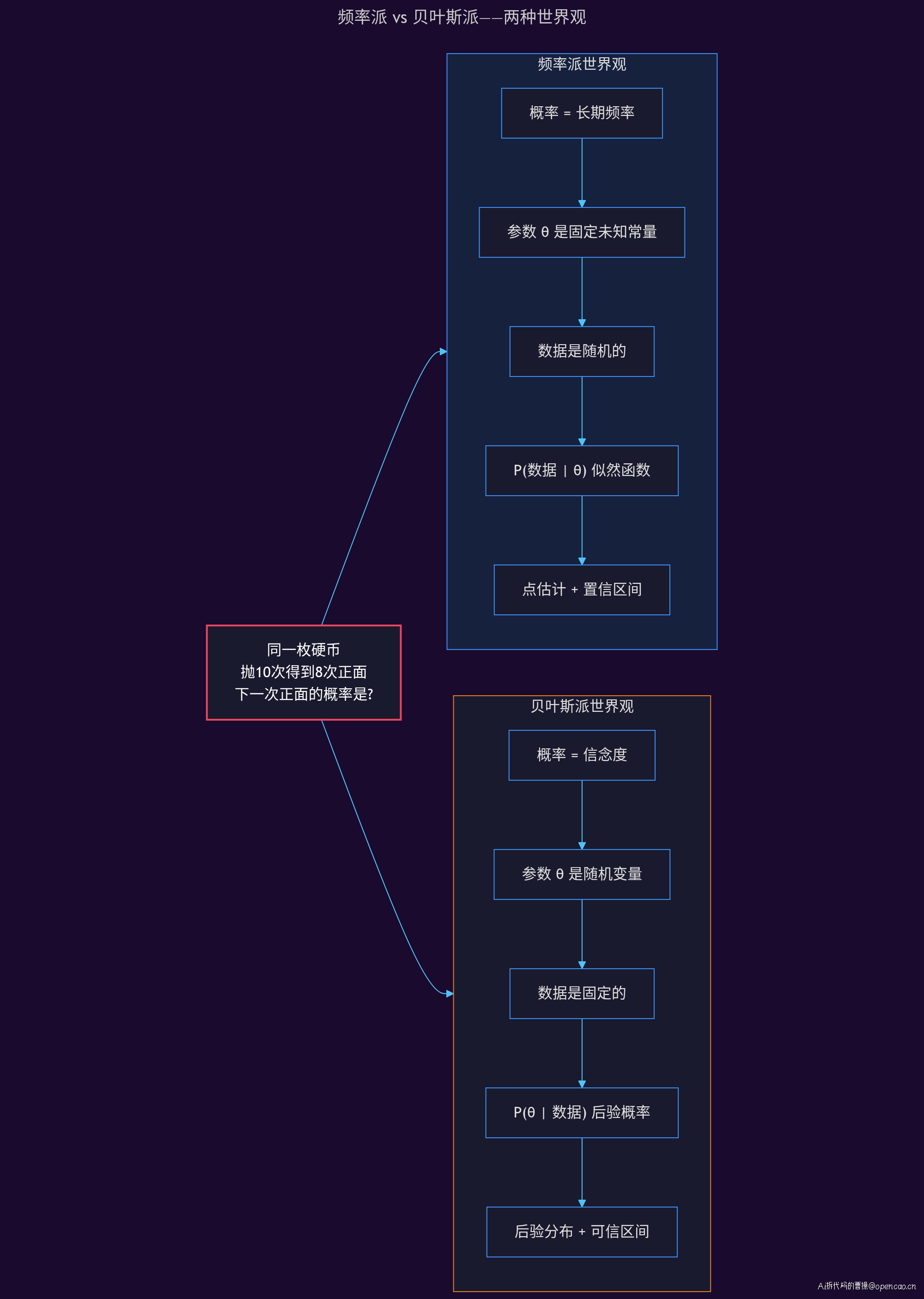
频率派会说:概率是长期频率的极限值。10 次观测不足以做出可靠推断,但随着样本量增加,估计会收敛到真实值。
贝叶斯派会说:概率是你对一件事的信念度。在观测到数据之前,我可能认为硬币是均匀的(先验信念),观测数据后更新这个信念(后验)。80% 的观测频率和 50% 的先验信念,取一个加权平均才是正确答案。
这不是单纯的学术争论。这两种思维方式对应着完全不同的方法论体系——你的参数估计方法、不确定性表达方式、甚至你对「学习」本身的理解,都会因立场不同而天差地别。
理解频率派与贝叶斯派的区别,不只是为了看懂统计教科书的开篇章节。它直接关系到你如何选择模型、如何解释结果、如何处理小样本问题、甚至如何设计机器学习算法。这是进入 AI 世界的第一道门槛。
两种世界观
频率派:概率是频率的极限
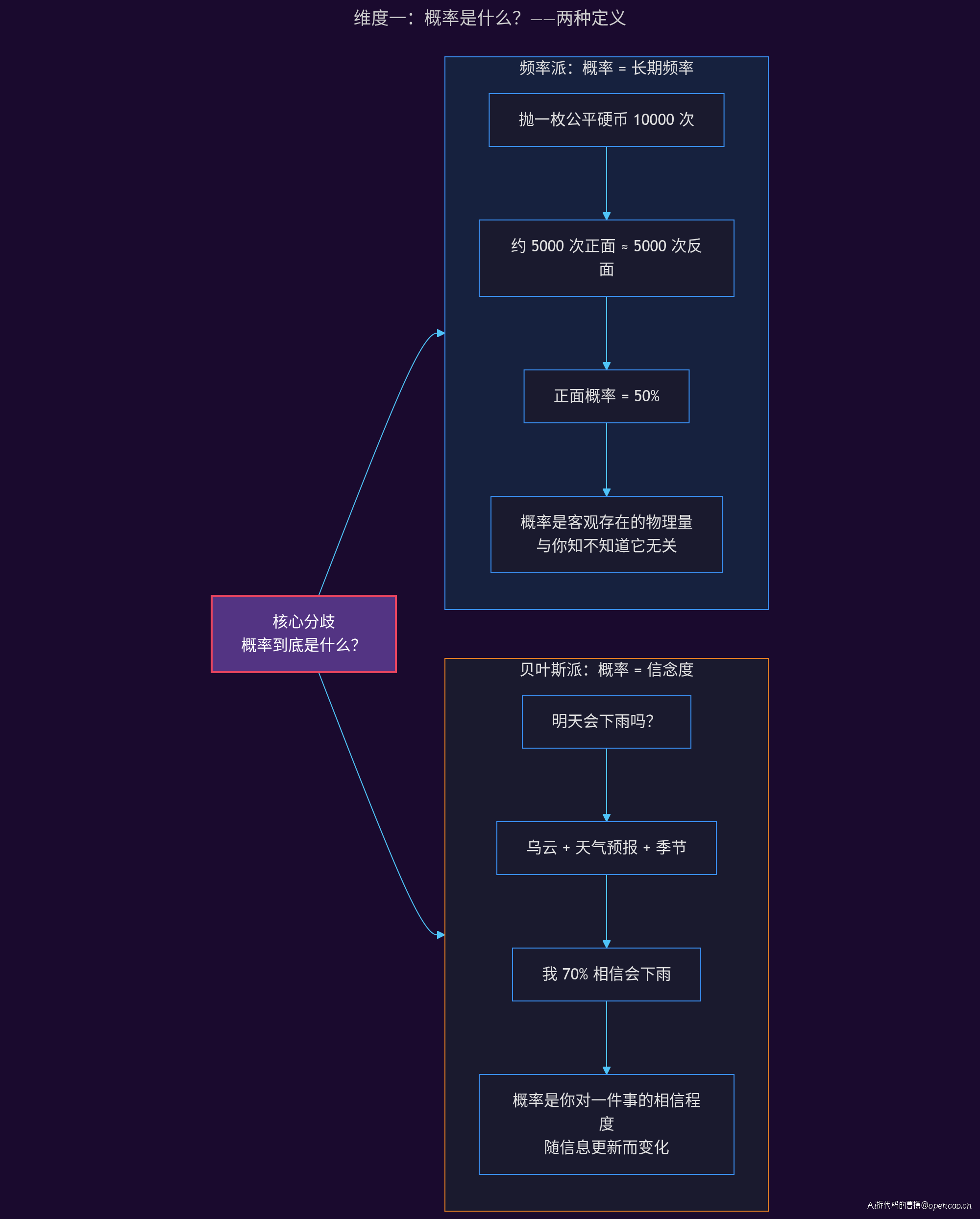
频率派(Frequentist)的核心信念只有一句话:概率是大量重复试验中事件发生的长期频率。
抛一枚均匀硬币 10000 次,正面出现的比例会趋近于 50%。这 50% 就是正面的概率。在这个框架下,概率是一个客观存在的物理量,与你是否知道它无关。
这种世界观下,模型的参数 θ 是客观存在的固定值。如果你抛硬币 10 次得到 8 次正面,你不会说「正面概率的估计值是 80% 左右」,而是说「在某个未知的固定值 θ 下,观测到 8/10 的概率是 C(10,8)·θ^8·(1-θ)^2」。你做的所有推断,都是围绕这个固定的 θ 展开的。
贝叶斯派:概率是信念度
贝叶斯派(Bayesian)的核心信念截然不同:概率是对某个命题相信程度的主观度量。
明天会下雨的概率是 70%,不是说在 100 个平行宇宙中有 70 个明天会下雨,而是说你基于当前信息(乌云、天气预报、季节),有 70% 的信心认为明天会下雨。
这种世界观下,模型的参数 θ 不再是固定值,而是随机变量。你对 θ 的认知用一个概率分布来表达——在观测数据之前,你有「先验分布」P(θ);看到数据后,你通过贝叶斯定理更新为「后验分布」P(θ|D)。这个过程正是人类学习的数学建模:经验(先验)+ 证据(数据)→ 更新认知(后验)。
这张图直观展示了两种世界观的差异:
为什么这个问题重要?
频率派和贝叶斯派的根本分歧不在数学推导,而在对不确定性的态度。频率派认为不确定性来自随机性——数据是随机的,参数是固定的。贝叶斯派认为不确定性来自知识的不完备——参数也是随机的,你只是在用数据不断缩小它的不确定范围。
这种分歧在实际应用中会产生完全不同的行为:
- 小样本场景:频率派的估计完全依赖数据,样本少时方差极大;贝叶斯派可以用先验知识「拉住」估计,让结果更稳健
- 在线学习:频率派需要重新训练整个模型来吸收新数据;贝叶斯派天然支持增量更新——昨天的后验就是今天的先验
- 不确定性量化:频率派的置信区间解释很绕(「区间覆盖参数的概率是 95%」而非「参数在区间内的概率是 95%」);贝叶斯派的可信区间直白易懂(「参数有 95% 的概率落在这个区间内」)
300 年思想史
两种思想的交锋不是一夜之间发生的。理解这段历史,有助于你把握它们各自的长处与局限。
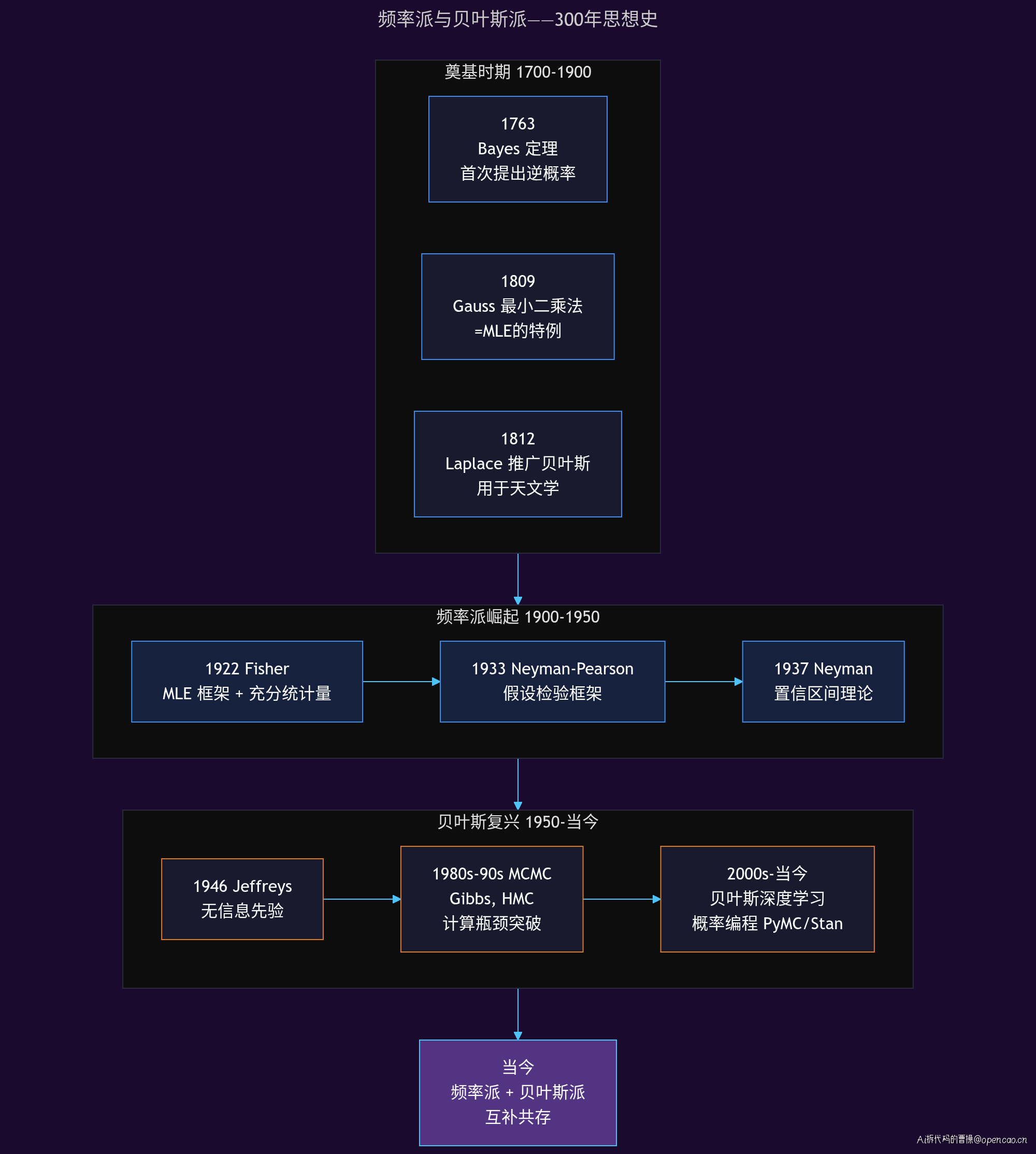
奠基时期(1700-1900)
1763 年,英国牧师托马斯·贝叶斯(Thomas Bayes)去世后,他的朋友 Richard Price 整理并发表了一篇论文,其中包含后来被称为「贝叶斯定理」的公式。贝叶斯本人可能没意识到这个公式的深远意义——它给出了「从结果反推原因」的数学框架。
1809 年,高斯(Carl Friedrich Gauss)在研究天文观测误差时,独立推导出最小二乘法。后来人们发现,最小二乘法本质上是正态分布下 MLE 的一个特例。高斯的这项工作为频率派方法奠定了数学基础。
1812 年,拉普拉斯(Pierre-Simon Laplace)发表《概率分析理论》,系统地推广了贝叶斯方法,并将其应用于天文学、人口统计等领域。拉普拉斯是贝叶斯方法的早期巨擘——他提出的「等可能原则」(无信息先验的雏形)至今仍有影响。
频率派崛起(1900-1950)
20 世纪上半叶是频率派的黄金时代。
1922 年,费希尔(Ronald Fisher)发表了 MLE(最大似然估计)的系统框架。Fisher 是频率派的灵魂人物——他定义了充分统计量、似然原理、Fisher 信息量等核心概念。MLE 成为频率派参数估计的标配。
1933 年,内曼(Jerzy Neyman)和皮尔逊(Egon Pearson)提出了假设检验的完整框架。Neyman-Pearson 引理给出了最优检验的构造方法。到今天,绝大多数科学论文中的 p-value 和显著性检验,都源于这个框架。
1937 年,内曼定义了置信区间(Confidence Interval)的概念。这个概念的微妙之处在于:它不是说「参数在区间内的概率是 95%」,而是说「重复抽样 100 次,大约 95 次构造的区间会覆盖真实参数」。这种绕口的解释,正是频率派哲学在不确定性表达上的直接体现。
贝叶斯复兴(1950-今)
1946 年,杰弗里斯(Harold Jeffreys)出版了《概率论》一书,提出了无信息先验(Jeffreys Prior)的构造方法——在缺乏先验知识时,如何选择「最客观」的先验分布。这回应了频率派对贝叶斯方法「主观」的批评。
但贝叶斯方法在 20 世纪大部分时间处于边缘地位,主要原因不是哲学争议,而是计算瓶颈——贝叶斯推断需要计算高维积分,这在手工计算时代几乎不可能。
转折点出现在 1980-1990 年代。随着 MCMC(马尔可夫链蒙特卡洛)方法的成熟——尤其是 Gibbs 采样和 Hamiltonian Monte Carlo——贝叶斯方法的计算障碍被突破。PyMC、Stan、BUGS 等概率编程语言让贝叶斯建模变得可操作。
2000 年代至今,贝叶斯方法迎来了全面复兴:贝叶斯神经网络、高斯过程、变分推断、贝叶斯深度学习——这些方法将贝叶斯的「不确定性量化」能力与现代深度学习的表示能力结合,产生了深远的影响。
五个维度的深度对比
现在进入最核心的部分——从五个维度正面交锋两种范式。
维度一:概率的定义
| 维度 | 频率派 | 贝叶斯派 |
|---|---|---|
| 概率是 | 长期频率的极限 | 信念度的量化 |
| 参数 θ | 固定但未知的常量 | 随机变量,有分布 |
| 数据 D | 随机(可重复抽样) | 固定(已观测到的事实) |
| 推断对象 | P(D|θ) 似然函数 | P(θ|D) 后验分布 |
这种差异不是哲学游戏,它直接决定了你用什么公式做估计。
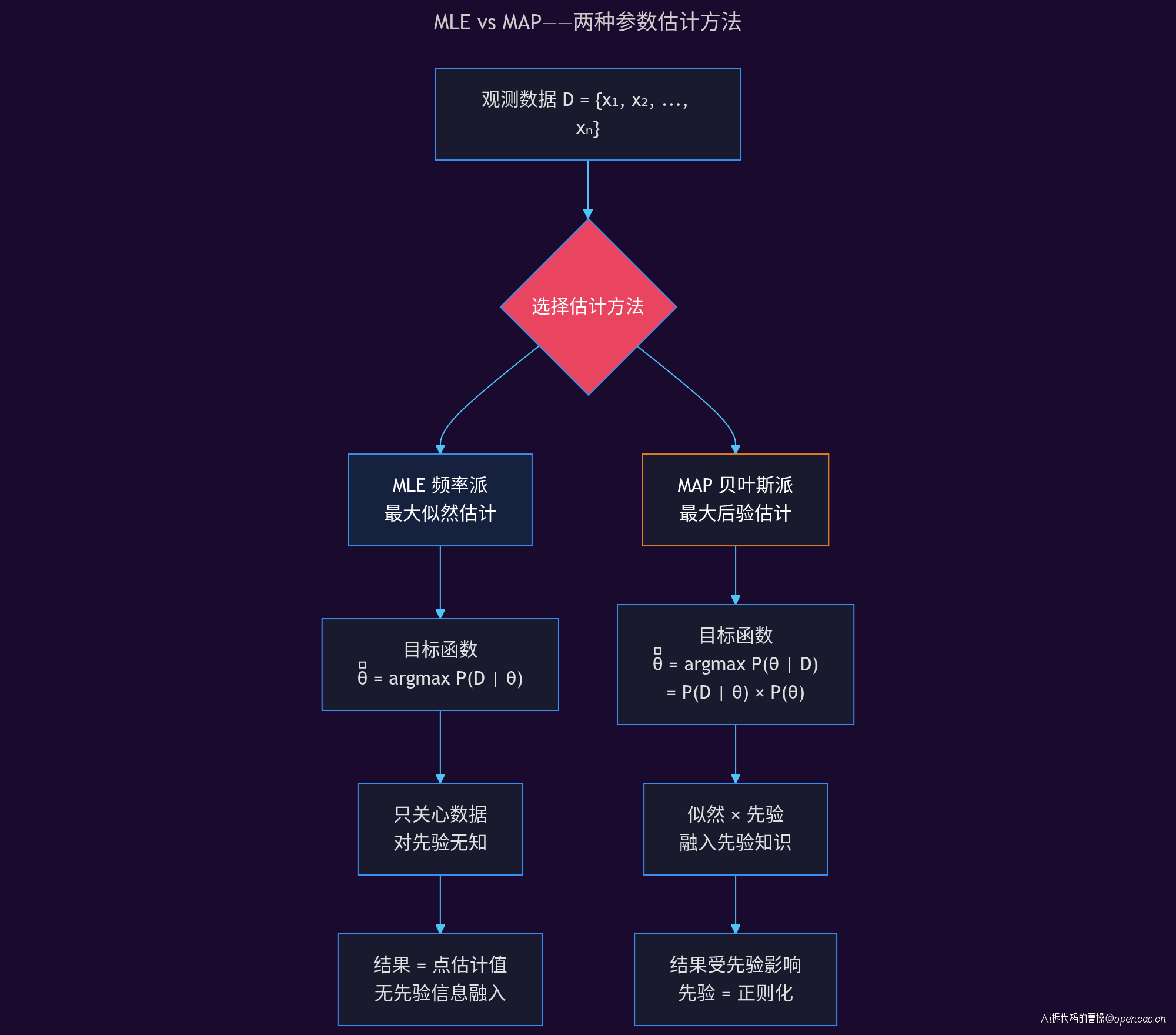
维度二:参数估计方法
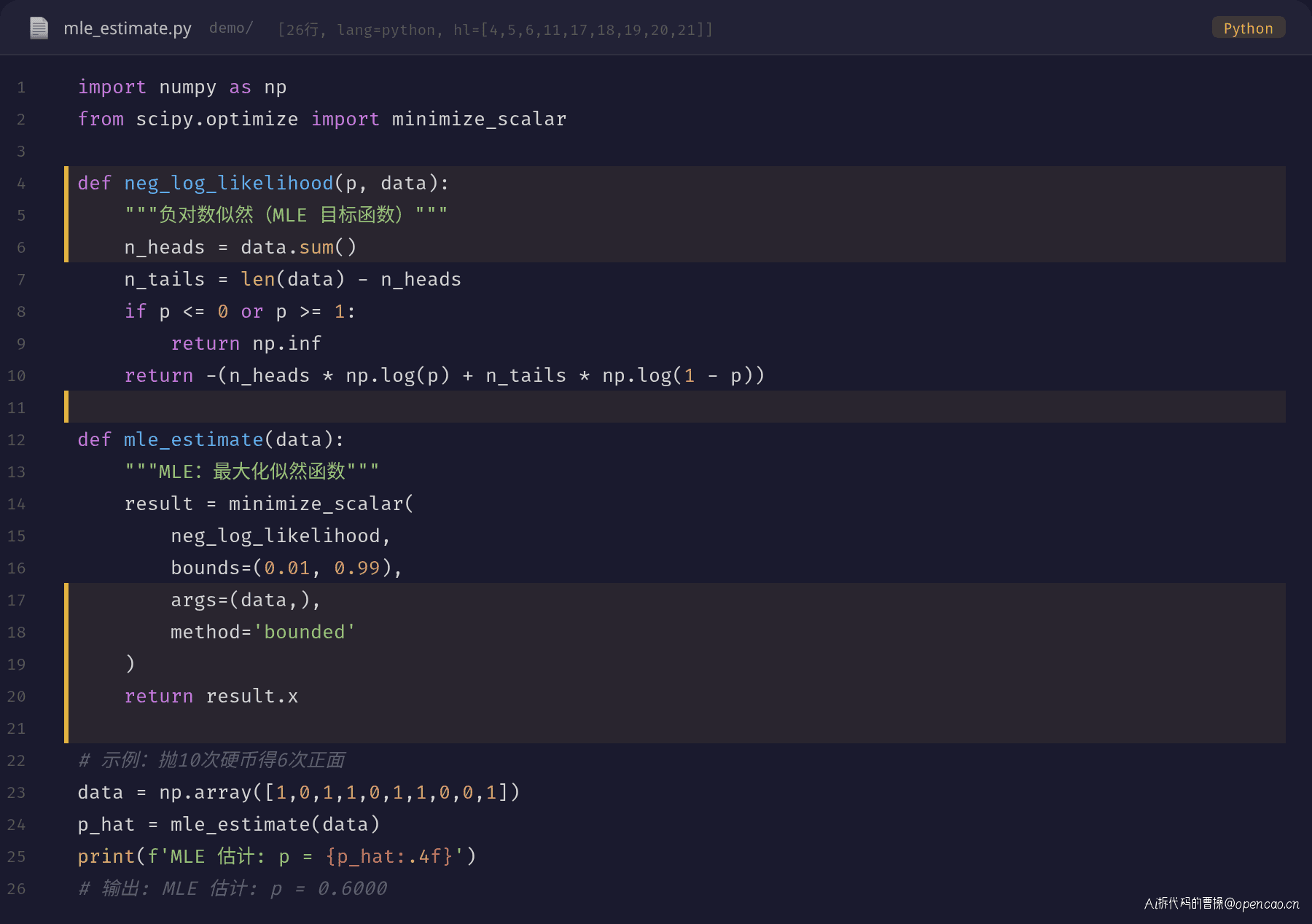
频率派使用 MLE(最大似然估计):找到使观测数据出现概率最大的 θ。
θ̂_MLE = argmax_θ P(D|θ)
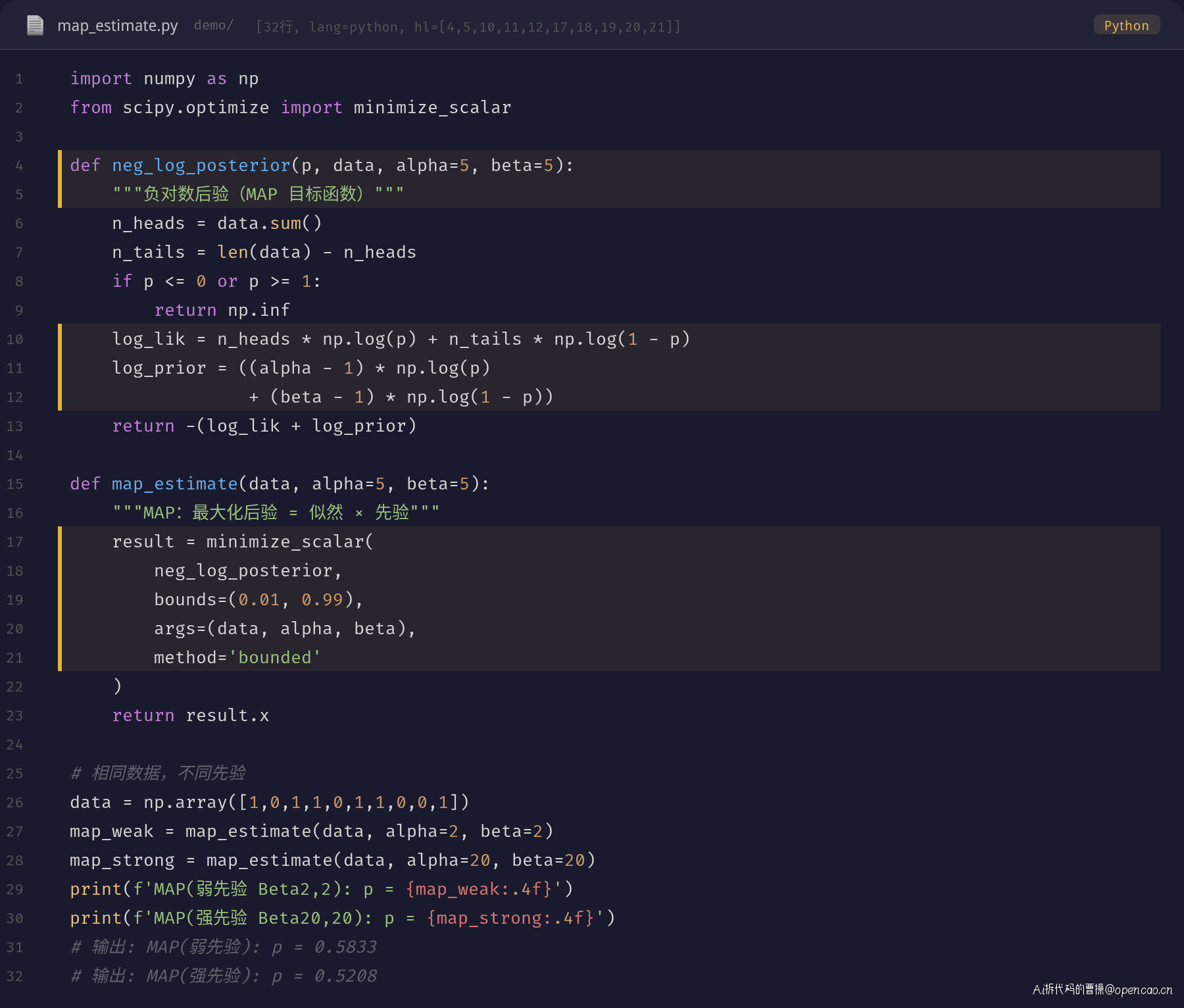
贝叶斯派使用 MAP(最大后验估计)或 Full Bayesian:
θ̂_MAP = argmax_θ P(θ|D) = argmax_θ P(D|θ) · P(θ)
两者的区别在代码层面一目了然:
对比两段代码可见,MLE 只关心「似然」部分(数据告诉你的),MAP 多了一项「先验」(你事先知道的)。这个看似微小的修改,产生了深远的影响——先验本质上是一个正则化项,它把参数估计向先验均值方向「收缩」,减少过拟合。
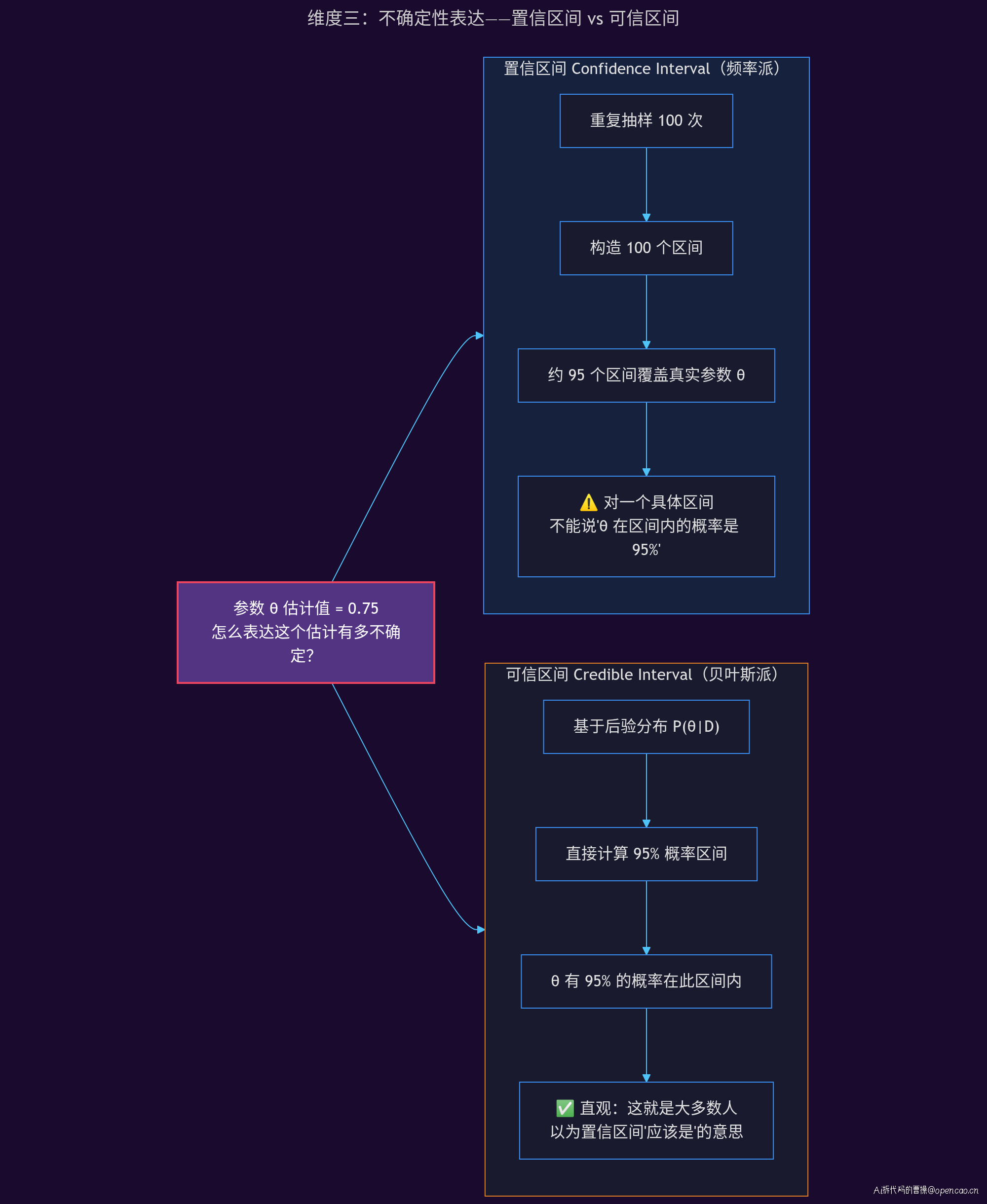
维度三:不确定性表达
频率派用置信区间(Confidence Interval)表达不确定性。但它的解释非常反直觉:「重复抽样 100 次,约 95 个区间会覆盖参数」。这意味着对于任何一个具体的区间,你无法说参数在里面的概率是多少——因为参数是固定的,要么在要么不在。
贝叶斯派用可信区间(Credible Interval)表达不确定性。它的解释非常直觉:「参数有 95% 的概率落在这个区间内」。这是大多数人以为置信区间「应该是」的意思,但实际上是可信区间才有的性质。
维度四:先验知识的态度
频率派严格拒绝使用先验知识——如果数据不够,那就收集更多数据。MLE 的估计结果完全由数据驱动。
贝叶斯派欢迎先验知识——如果已经有相关经验,为什么不用?MAP 和 Full Bayesian 可以自然地融入先验信息。
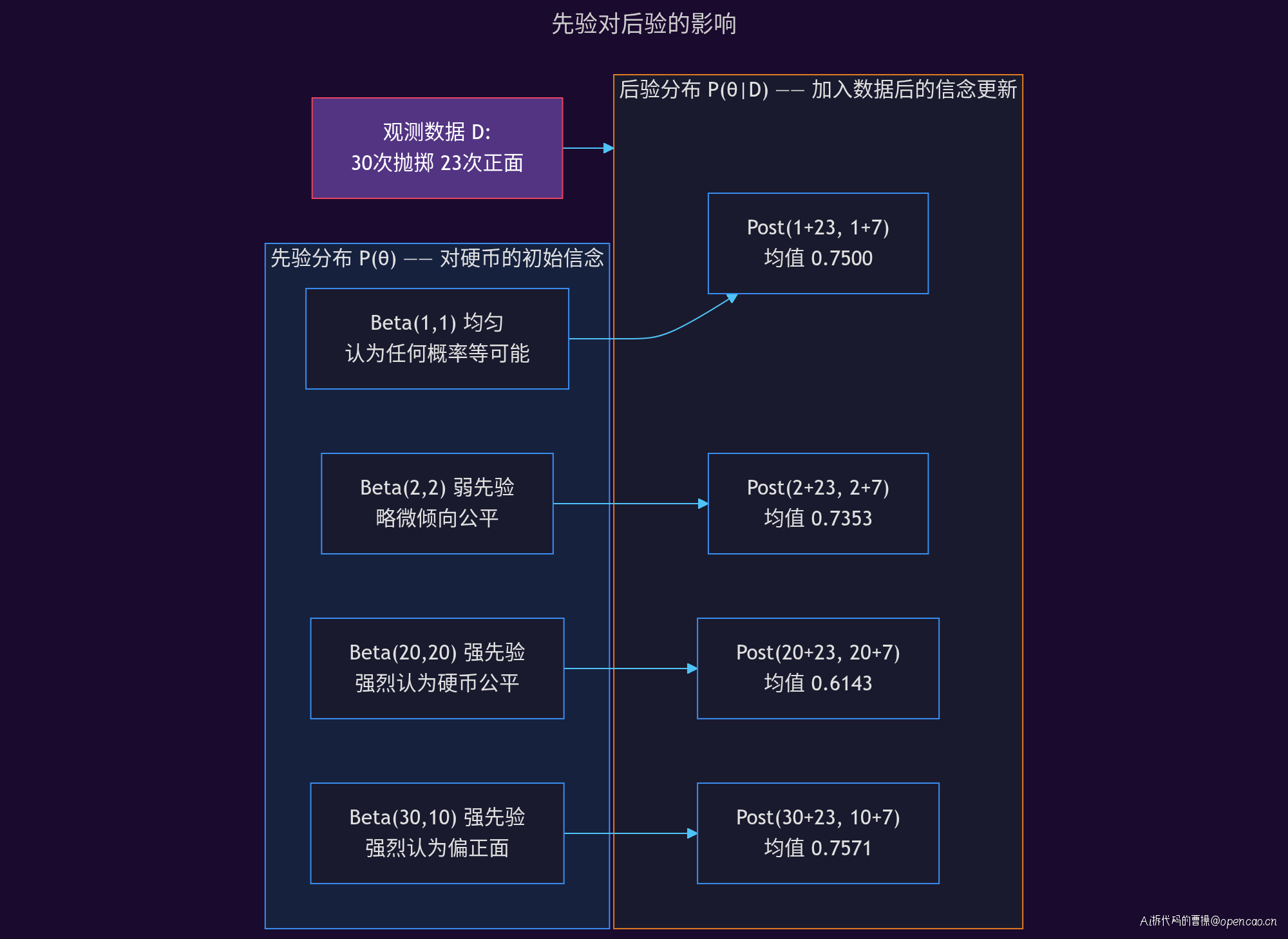
实际运行代码看看先验对后验的具体影响:
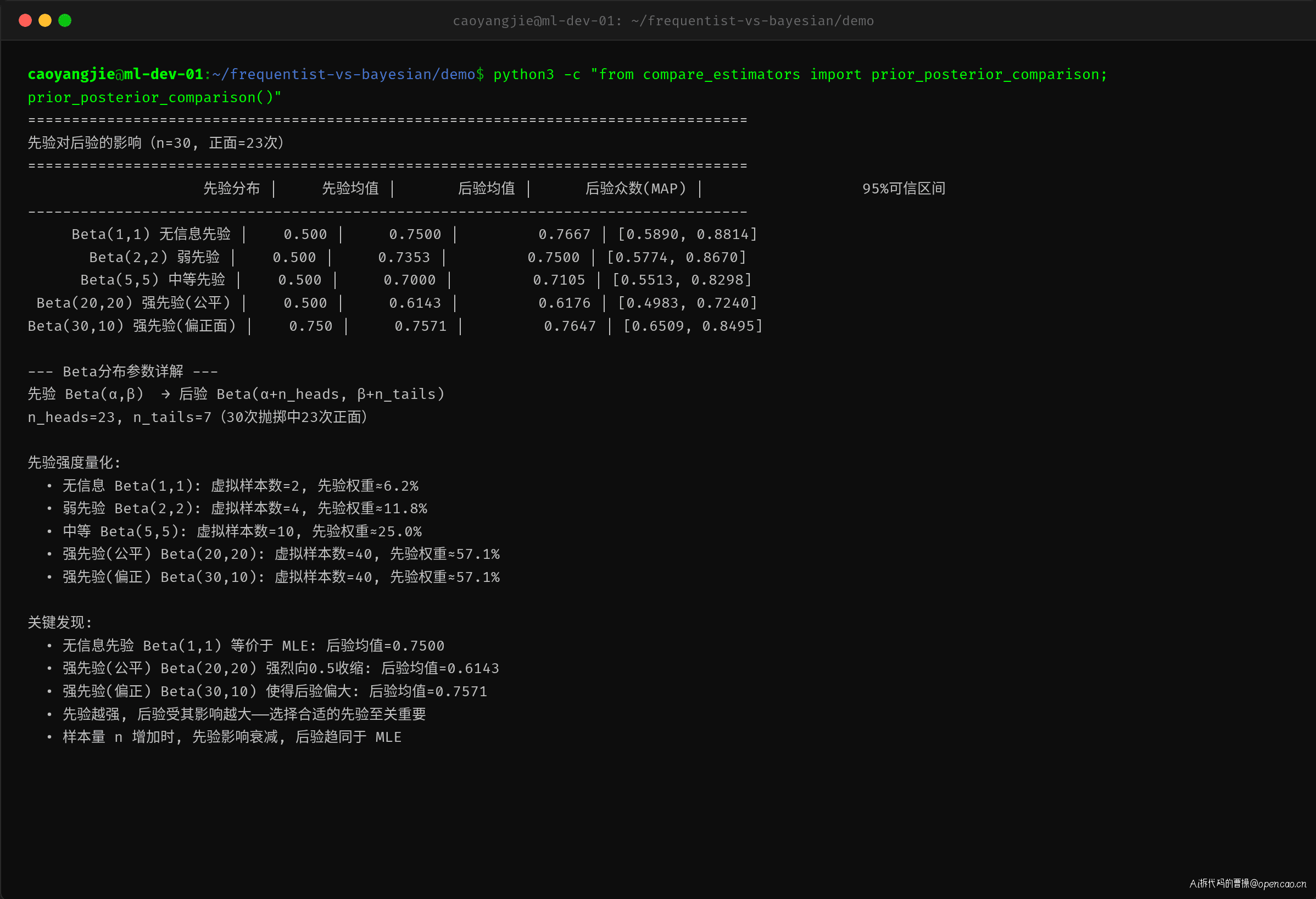
关键发现: - 无信息先验 Beta(1,1) 等价于 MLE,后验完全由数据驱动 - 强先验(公平信念 Beta(20,20))使估计显著向 0.5 收缩,n=30 时后验均值仅 0.6143 - 强先验(偏正面信念 Beta(30,10))使估计偏大,后验均值为 0.7571 - 先验的「强度」可以量化——虚抛样本数越大,先验权重越高
维度五:大样本下的趋同
样本量 | 正面数 | MLE | MAP(弱先验) | MAP(强先验) | Bayes均值 | 95%可信区间
------|-------|------|-----------|------------|----------|-------------
10 | 6 | 0.6000 | 0.5833 | 0.5208 | 0.5833 | [0.3079, 0.8325]
30 | 24 | 0.8000 | 0.7812 | 0.6324 | 0.7812 | [0.6253, 0.9041]
100 | 66 | 0.6600 | 0.6569 | 0.6159 | 0.6569 | [0.5625, 0.7454]
1000 | 707 | 0.7070 | 0.7066 | 0.6994 | 0.7066 | [0.6780, 0.7344]
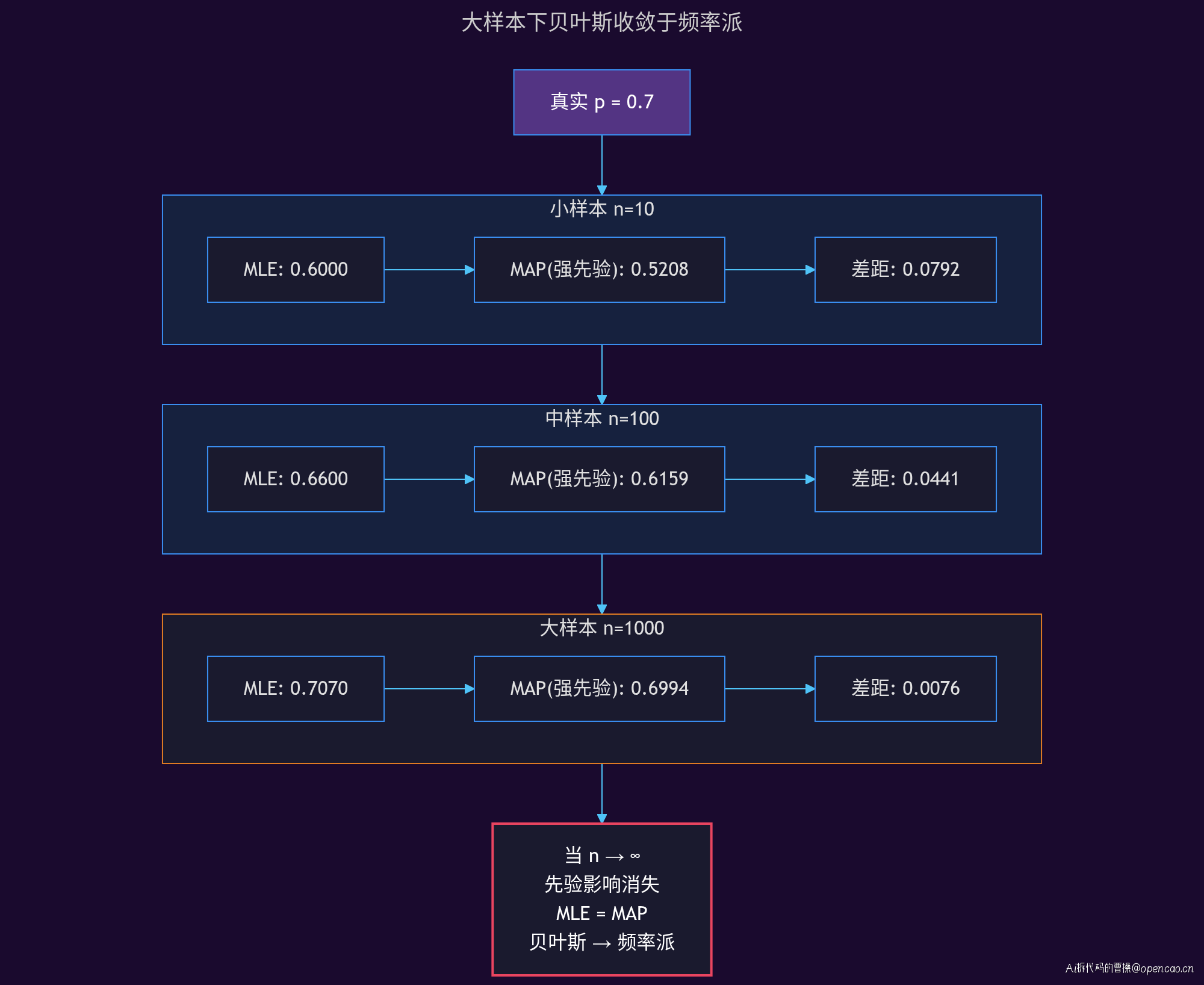
完整 CLI 对比输出:
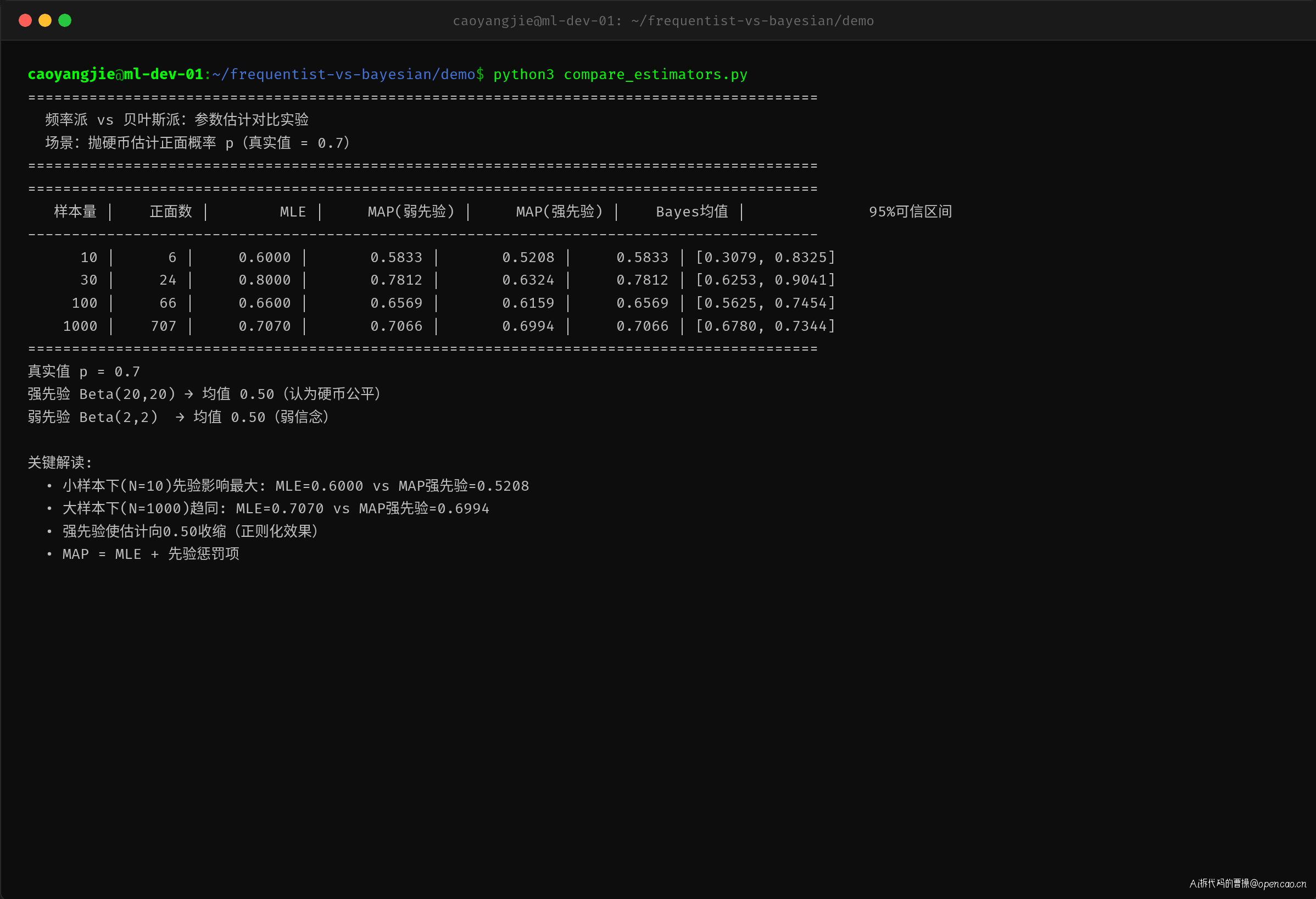
这张表完美展示了频率派和贝叶斯派的关系规律。小样本下(n=10),先验差异最大:MLE=0.6000 而 MAP(强先验)=0.5208。大样本下(n=1000),两者几乎重合:MLE=0.7070 vs MAP(强先验)=0.6994。
原理拆解:从数学到代码
现在深入三个核心方法的数学原理和代码实现。
MLE:最大似然估计
MLE 的目标是找到使数据出现概率最大的参数值。对抛硬币问题,似然函数是:
L(θ) = P(D|θ) = θ^k · (1-θ)^{n-k}
其中 k 是正面次数,n 是总次数。取对数后求导,得到解析解:
θ̂_MLE = k / n
这就是为什么 MLE 的估计结果就是样本均值——它只依赖数据,不要任何先验。
MAP:最大后验估计
MAP 在 MLE 的基础上乘了一个先验分布。当我们使用 Beta(α, β) 作为先验时:
P(θ|D) ∝ θ^{k+α-1} · (1-θ)^{n-k+β-1}
MAP 估计值:
θ̂_MAP = (k + α - 1) / (n + α + β - 2)
当 α=β=1(均匀先验)时,MAP = MLE。当先验强于数据时,MAP 向先验均值收缩。
Full Bayesian:完整后验分布
Full Bayesian 不追求一个点估计,而是计算完整的后验分布。对于 Beta-Binomial 共轭模型:
θ|D ∼ Beta(α + k, β + n - k)
从后验分布中,你可以计算任意分位数、可信区间、概率密度——完整的不确定性画像。
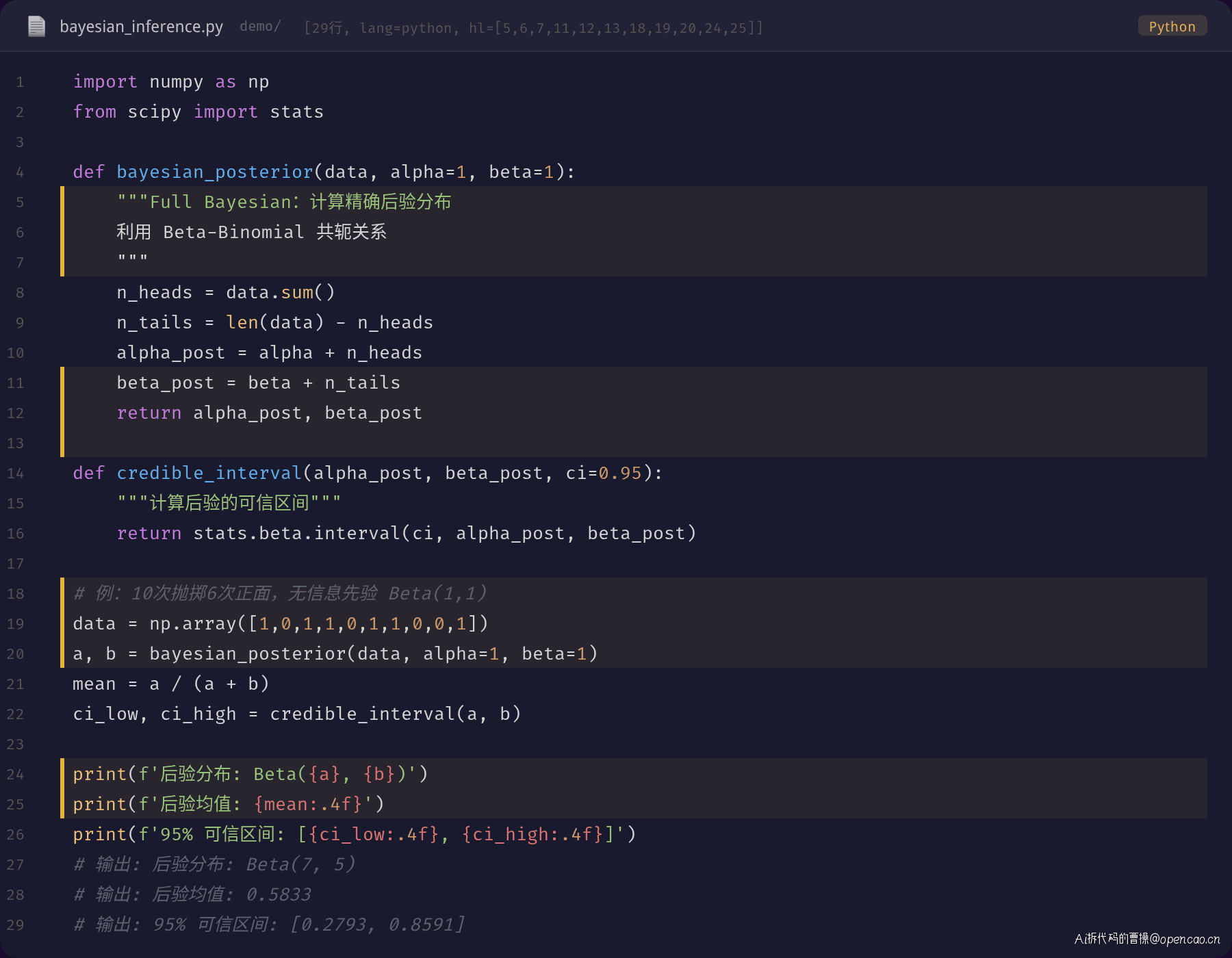
完整对比的主程序代码:
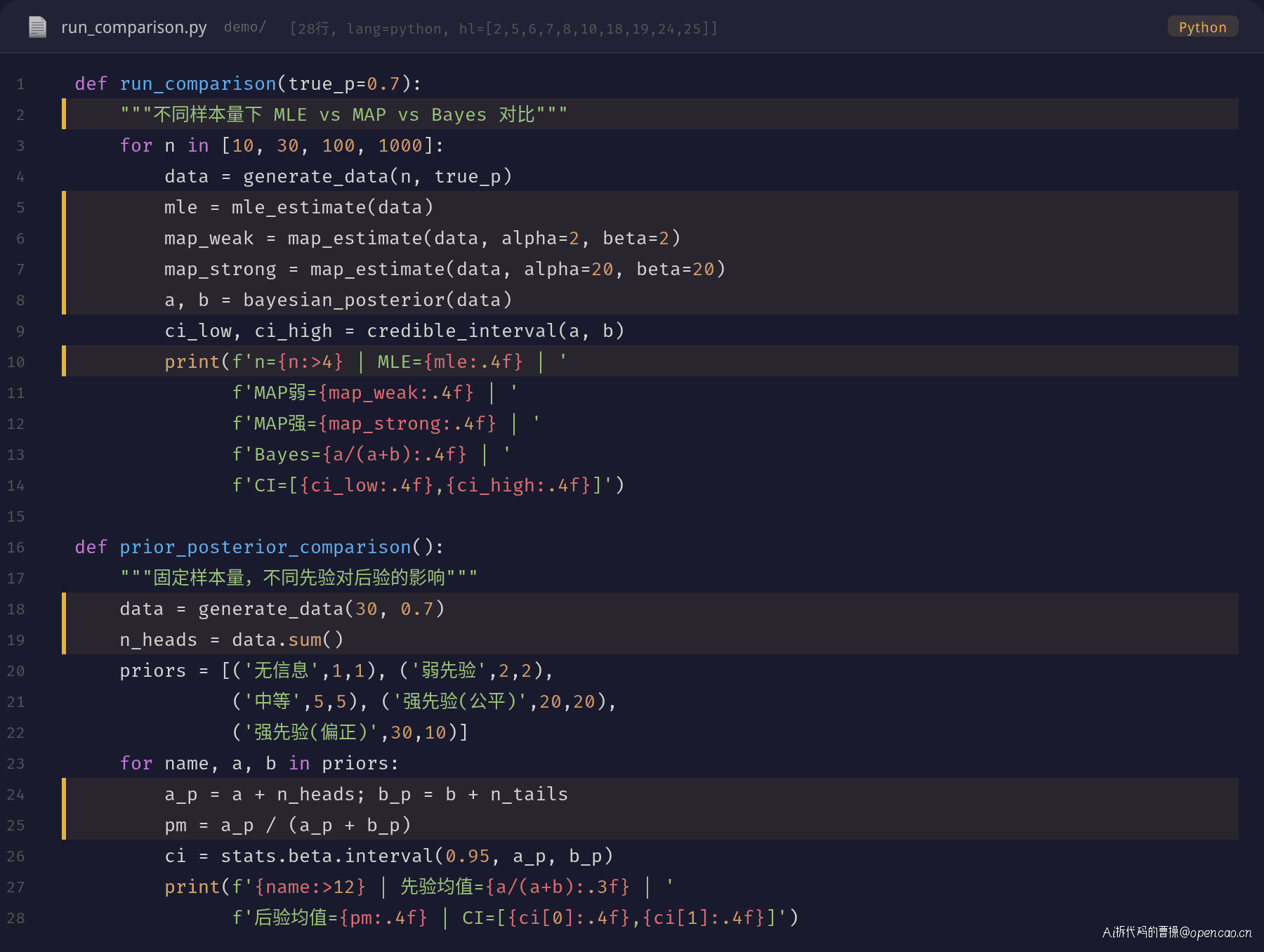
三个方法的递进关系
MLE → MAP → Full Bayesian 是递进的关系:
- MLE 是最简单的点估计,只告诉你怎么回事
- MAP 在 MLE 上加先验正则化,减少小样本过拟合
- Full Bayesian 给出完整的后验分布,不仅告诉你估计值是多少,还告诉你对这个估计有多大的信心
从 MLE 到 Full Bayesian,信息量递增,计算复杂度也递增。实践中,根据场景在上述光谱中取一个合适的位置。
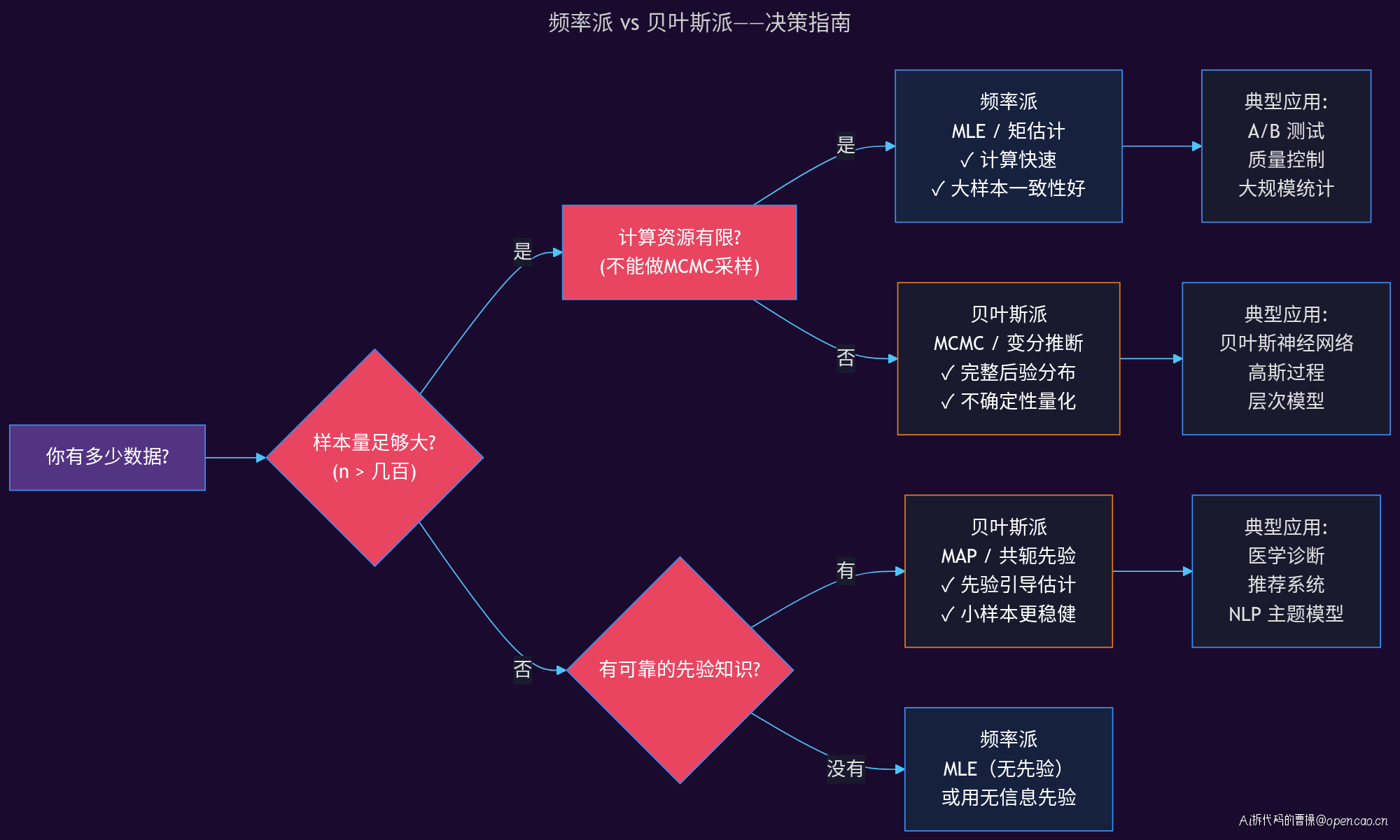
实战抉择:什么时候用什么
理解了两种范式的区别后,最实际的问题是:工作中到底用哪个?
选择频率派
以下场景频率派是更好的选择:
大样本 + 计算资源有限:A/B 测试的数据量通常以百万计,此时先验的影响微乎其微。使用频率派的假设检验,计算快速、结果可靠。Python 中用 scipy.stats 几个函数就能搞定。
标准化报告:临床试验、质量控制等需要严格遵守标准的场景,频率派的 p-value 和置信区间是行业标准。你用贝叶斯方法得出的结果,评审者可能不认可。
无可靠先验信息:如果你对参数确实没有任何先验知识,贝叶斯方法带来的复杂度可能不值得。此时 MLE 或无信息先验的 MAP 等价。
选择贝叶斯派
以下场景贝叶斯派优势明显:
小样本 + 有先验:医学诊断中,某种罕见病只有几十个病例。频率派的估计方差极大,无法得出可靠结论。贝叶斯方法用先验知识(如类似疾病的历史数据)可以大幅提升估计质量。
在线学习 / 增量更新:推荐系统中,用户行为数据持续流入。贝叶斯方法自然支持增量更新——每天凌晨用昨天的后验作为今天的先验,吸收当天的数据。频率派需要定期重训。
层次模型:多个相关组(如不同地区的销售数据)共享信息。贝叶斯层次模型天然处理这种结构,频率派方法处理起来很复杂。
需要表达不确定性:贝叶斯可信区间的直觉解释(「参数有 95% 的概率在此区间内」)比置信区间更容易与非技术人员沟通。
决策流程
深度学习中的贝叶斯视角
即使你在深度学习实践中「感觉自己用的是频率派」,很多核心思想本质上带着贝叶斯色彩:
- L2 正则化(Weight Decay):等价于给权重施加高斯先验的 MAP 估计
- Dropout:可以解释为贝叶斯变分推断的近似(MC Dropout)
- Batch Normalization:引入的随机性可以看作贝叶斯的一种近似
- Bayes by Backprop:直接为网络权重学习分布而非点估计
- Prompt Engineering:从贝叶斯视角看,System Prompt 就是先验分布
当我们走进 LLM 时代,贝叶斯视角变得尤其相关——模型的不确定性校准、RAG 系统的置信度判断、Agent 系统是否需要「知道它不知道什么」,这些都和贝叶斯思维同源。
全景总结
频率派和贝叶斯派不是非此即敌的对立关系。它们是同一枚硬币的两面:
频率派擅长「我做对了什么」——在大数据时代,它的方法简单、快速、标准化,是工业界的主力。
贝叶斯派擅长「我有多确定」——在小样本、增量学习、不确定性量化场景中,它的框架更优雅、更自然。
理解两者的关键,不是选择站队,而是在正确的场景使用正确的工具。
推荐学习路径
- 入门:先掌握频率派统计——MLE、假设检验、p-value,这是理解现代 AI 论文的基础。推荐《Statistical Inference》by Casella & Berger
- 进阶:学习贝叶斯方法——先验选择、MCMC、变分推断。推荐《Bayesian Data Analysis》by Gelman et al.(免费在线)
- 融会贯通:在实际项目中两种方法交替使用,理解它们的互补关系。推荐《Machine Learning: A Probabilistic Perspective》by Kevin Murphy
- 前沿:探索贝叶斯深度学习——Pyro(Uber)、PyMC、TensorFlow Probability 等概率编程框架
附:完整命令清单
# 运行完整对比实验
python3 demo/compare_estimators.py
# 仅看先验影响
python3 -c "from compare_estimators import prior_posterior_comparison; prior_posterior_comparison()"
# 单次 MLE 估计
python3 -c "import numpy as np; data = np.random.binomial(1, 0.7, 100); print(f'MLE: {data.mean():.4f}')"
# 单次 MAP 估计(Beta 先验)
python3 -c "
from scipy import stats
import numpy as np
data = np.random.binomial(1, 0.7, 30)
k, n = data.sum(), len(data)
alpha_post, beta_post = 5 + k, 5 + n - k
print(f'后验: Beta({alpha_post},{beta_post}), 均值: {alpha_post/(alpha_post+beta_post):.4f}')
print(f'95% 可信区间: {stats.beta.interval(0.95, alpha_post, beta_post)}')
"


