
线程池设多少线程?面试答 8核×2,生产却满屏超时
本文是面试转生产场景系列的第 2 篇 叙事框架:
面试题 → 标准答案验证 → 生产事故 → 公式修正 → 升级版答案
面试题:线程池大小怎么设?
几乎每个 Java 面试都会遇到这道题:
Q:线程池的 corePoolSize 和 maxPoolSize 怎么设置?
标准答案大部分人背得滚瓜烂熟:
CPU 密集型任务:N + 1(N = CPU 核心数) IO 密集型任务:2N
面试官听到 2N,一般点点头,进入下一个问题。这道题在面试题库中流传了十几年,从《Java Concurrency in Practice》到各大公司的面试题库,答案几乎一字不差。
但如果面试官多追问一句:
为什么 IO 密集就是 2N?换成 3N 行不行?什么情况下 2N 会失效?
大多数候选人会被问住。不是因为他们不聪明,而是因为面试考的是"结论",而理解这个答案需要的是"推导"。
标准答案的推导链路
把 2N 拆开看,它的完整推导是这样的:
IO 密集型任务的时间 = CPU 计算时间 + IO 等待时间
最优线程数 = CPU 核心数 × (1 + IO 等待时间 / CPU 计算时间)
这个公式的直觉是这样的:一个线程跑完 CPU 时间段后开始等 IO,在它等的过程中,CPU 核心是空闲的,可以处理另一个线程的 CPU 计算。如果 IO 等待时间是 CPU 计算时间的 1 倍(即 wait/cpu = 1),那一个 CPU 核心可以同时喂饱 2 个线程——一个在算,一个在等。这就是 2N 的来历。
看起来很有道理,不是吗?
"2"是怎么来的
问题就出在这个"2"上。
2N 公式成立的隐含前提:IO 等待时间 ≈ CPU 计算时间。
当 wait_time ≈ cpu_time 时,公式简化为:
N × (1 + 1) = 2N
但如果 wait/cpu 不等于 1,这个"2"就变成了一个没有物理意义的魔数。比如:
- wait/cpu = 10 → 最优线程数 = N × 11 = 11N
- wait/cpu = 0.5 → 最优线程数 = N × 1.5 = 1.5N
线程池大小的正确答案不是 2N 这个数字,而是 N × (1 + wait/cpu) 这个公式。 面试背的是结论,生产需要的是理解。
生产事故:按 2N 配的,上线就炸
陈姐所在的订单服务团队也是这么做的。8 核 16 线程的服务器,corePoolSize 设成 16:
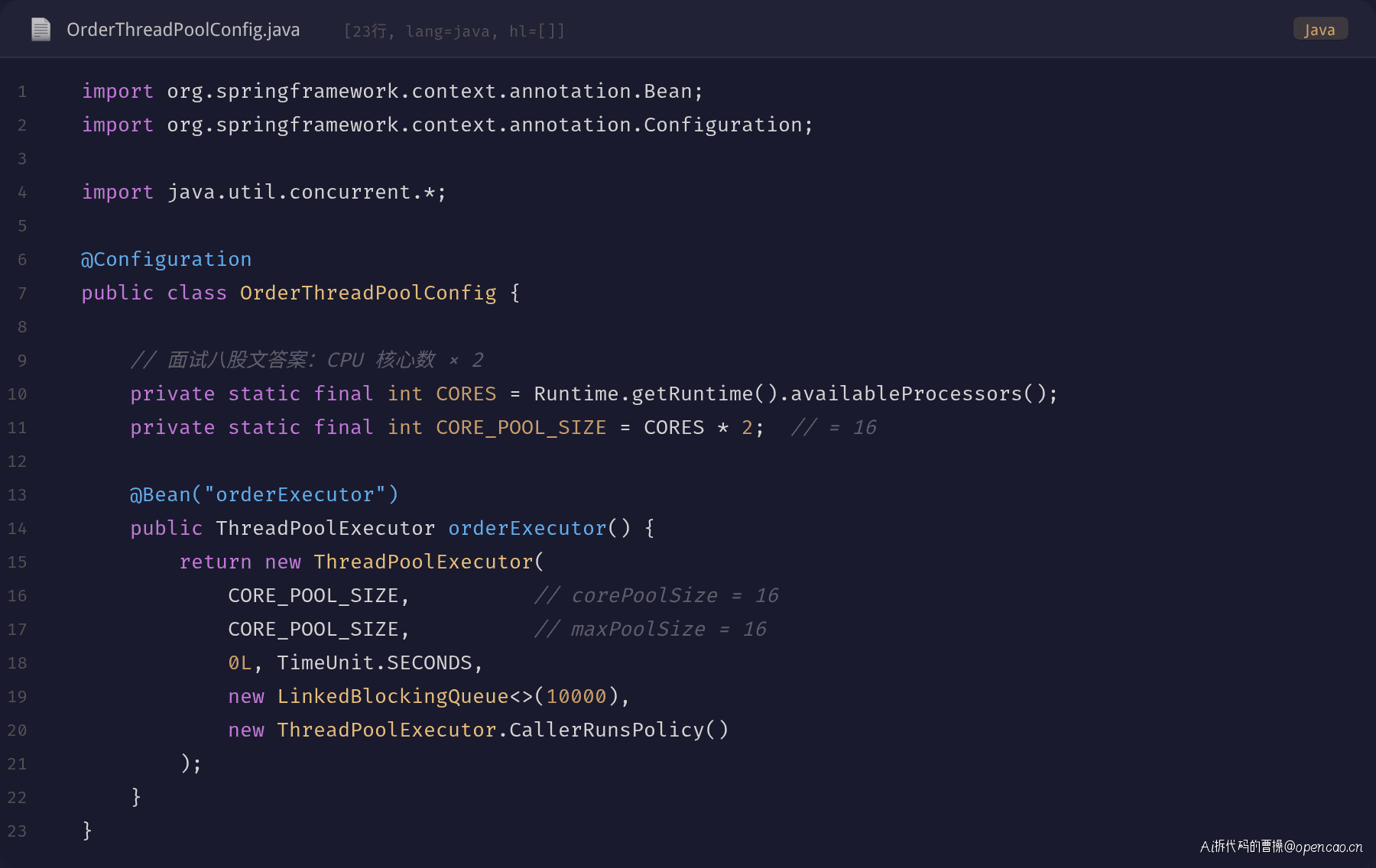
代码写得规规矩矩:CPU 核心数 × 2。注释里还写着"IO 密集型",说明当时是考虑过的。每个订单请求要调库存服务、写订单库、发消息通知,看着就像 IO 密集。16 线程,理论上成立。
面试答案写进了代码,没人觉得有问题。
告警在早高峰准时到达
某工作日,早高峰流量开始爬坡。SRE 值班群的告警机器人突然弹出消息:
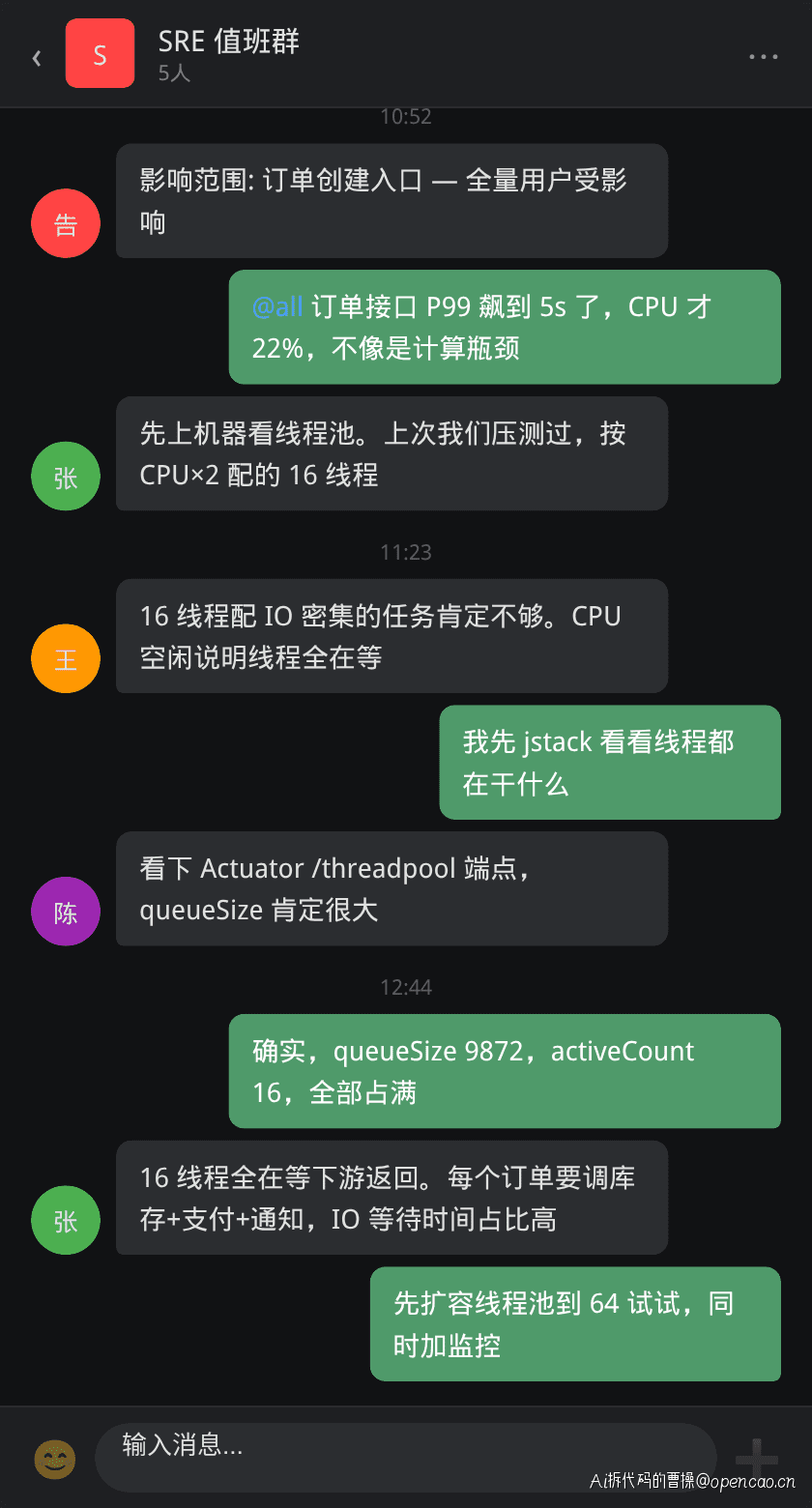
订单接口 P99 延迟从 200ms 飙到 5234ms,错误率 12.3%。更让人困惑的是监控面板上的其他指标:CPU 22%,内存充裕,GC 正常,磁盘 IO 平稳。所有"常规指标"都在安全范围内,但接口就是大面积超时。
张工在群里说了一句关键的话:"我们按 CPU×2 配的线程池,16 个线程,不会是这里的问题吧?"
上机排查:CPU 闲但 load 高
SSH 登入 prod-order-01,第一组数据就很矛盾:
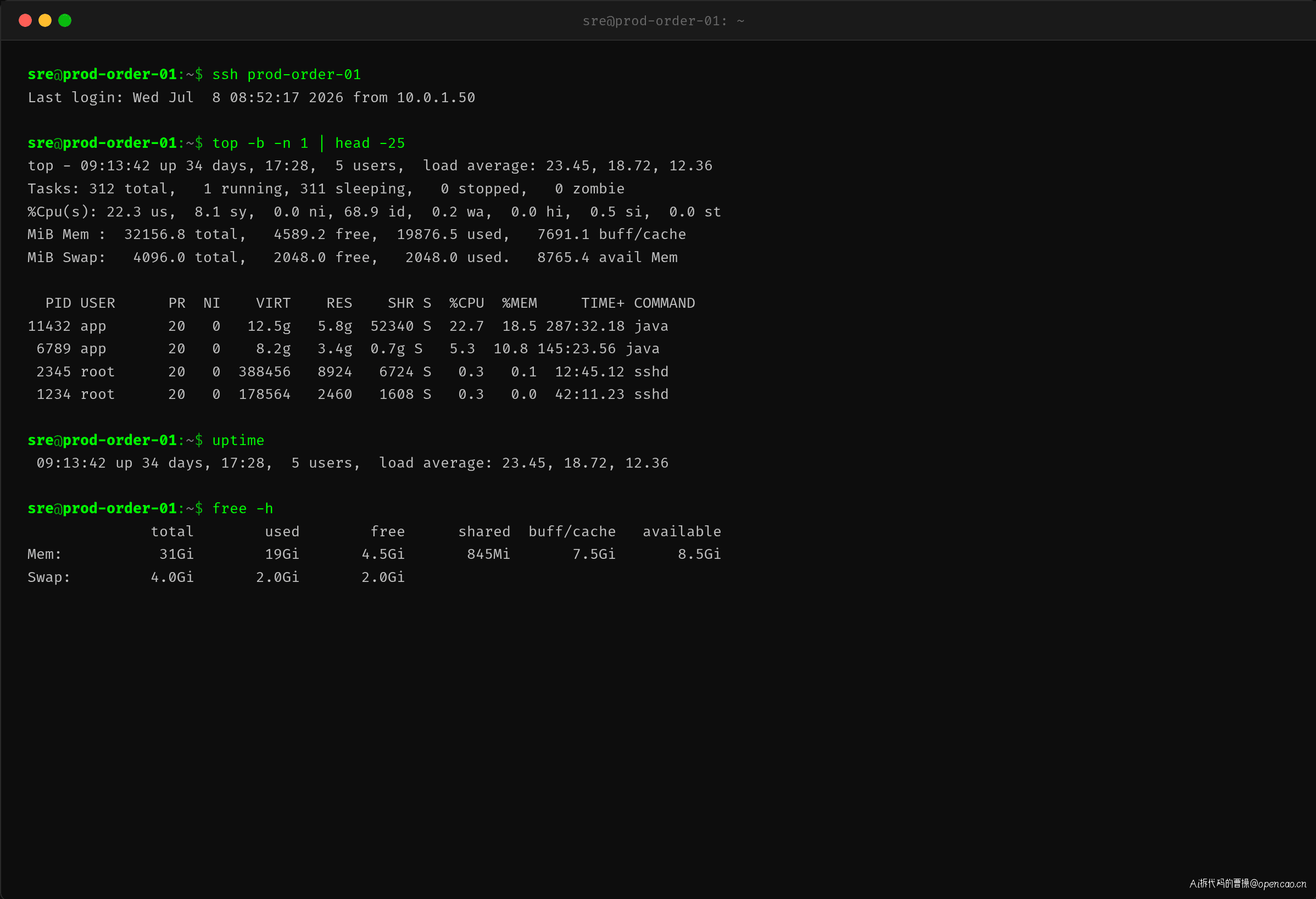
top - 09:13:42 up 34 days, 17:28, 5 users, load average: 23.45, 18.72, 12.36
%Cpu(s): 22.3 us, 8.1 sy, 0.0 ni, 68.9 id, 0.2 wa, 0.0 hi, 0.5 si, 0.0 st
CPU idle 68.9%——大部分核心在空转。但 load average 23.45——有 23 个以上的进程在等待调度。CPU 空闲但进程排队,这说明线程根本不在计算,而是在等待某种资源。如果是 CPU 密集型瓶颈,CPU 使用率应该在 90% 以上。
线程池状态触目惊心
常规排查思路是"CPU 高 → 找热点线程 → jstack 分析",但这里的 CPU 不高。换一个方向:直接看线程池的内部状态。
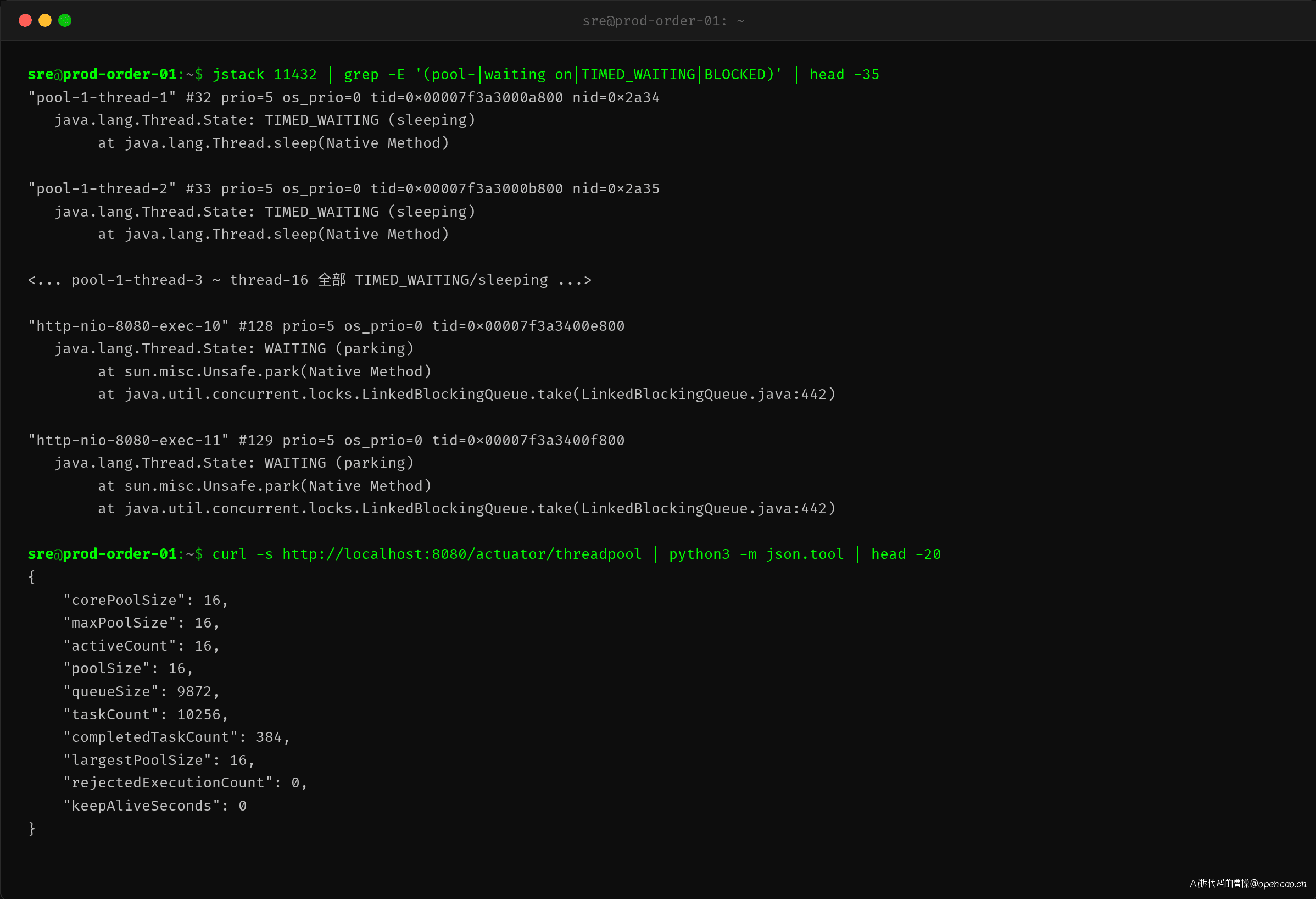
jstack 的输出显示所有 pool-1-thread-x 全部在 TIMED_WAITING(sleeping),而 http 处理线程在 WAITING(parking)——它们在等待放入任务,但队列拒绝了。Actuator 的数据更精确:
- corePoolSize = 16,maxPoolSize = 16(全部占满)
- activeCount = 16(没有闲置线程)
- queueSize = 9872(接近一万个任务在排队)
- completedTaskCount = 384(只完成了 3.7%)
- taskCount = 10256(总提交量)
- rejectedExecutionCount = 0(还没触发拒绝——队列还没满)
结合代码看,拒绝策略是 CallerRunsPolicy——当队列满时,提交任务的线程自己执行。这就是为什么 HTTP 线程也开始阻塞了——它们被 CallerRunsPolicy 拉去执行订单处理逻辑,Tomcat 的 HTTP 处理线程池随之被耗尽。
从 queueSize 9872 可以估算每个新任务的排队时间:
平均排队时间 ≈ queueSize × 平均处理时间 / 线程数
= 9872 × 80ms / 16 ≈ 49 秒
49 秒的排队时间,任何合理的超时设置(通常 3-5 秒)都不够用。每个请求要么等 49 秒超时,要么被 CallerRunsPolicy 拖死 HTTP 线程。这是双重重击。
为什么 2N 公式在这里失效了
逐层拆解,有三个层面的问题。
原因一:wait/cpu 比值和"2"差了一个数量级
回到推导公式。订单服务的每个请求的实际耗时分布:
| 阶段 | 耗时 | 类型 |
|---|---|---|
| HTTP 请求解析 | 1ms | CPU |
| 参数校验与鉴权 | 2ms | CPU |
| 调用库存服务(HTTP) | 30ms | IO |
| 价格计算 | 3ms | CPU |
| 写入订单库(MySQL) | 20ms | IO |
| 发送订单消息(MQ) | 15ms | IO |
CPU 总耗时约 6ms,IO 等待约 65ms。wait/cpu ≈ 10.8。
代入公式:
最优线程数 = 16 × (1 + 10.8) ≈ 189
16 和 189 之间差了 11.8 倍。这就是问题的核心:2N 公式没错,但 2 这个系数在生产场景下根本不成立。 面试时背的结论,在 wait/cpu=10.8 的场景下,误差是 11.8 倍——这个误差足够让一个系统从"正常"走向"崩溃"。
原因二:微服务架构放大了 IO 占比
为什么会差这么多?因为 2N 公式诞生于 2000 年代的单体应用时代。那时候的"IO 密集"主要是数据库读写,一个请求的 IO 等待可能只是几十毫秒的数据库查询,CPU 计算时间也有几十毫秒,比值通常在 2-5 之间。2N 虽然不精确,但大体在可接受范围内。
但现在的微服务架构已经完全改变了这个比例。一个订单请求要跨越:
- 本服务:参数校验、权限检查(CPU 1-2ms)
- 库存服务:HTTP REST 调用(IO 20-50ms)
- 数据库写入:MySQL 事务提交(IO 10-30ms)
- 消息队列:RocketMQ 发送(IO 10-20ms)
每增加一个下游调用,IO 时间就增加一段,CPU 时间几乎不变。wait/cpu 比从单体时代的 2-5 变成了现在的 10-20。2N 公式的适用场景已经不存在了。
原因三:黑洞效应——线程池从不犯错,只是安静地变慢
线程池有一个致命的特性:它不会主动报错,只是安静地变慢。
queueSize 从 0 涨到 9872 的过程中: - 100 的时候:接口延迟从 200ms 涨到 300ms,没人注意 - 1000 的时候:P99 涨到 800ms,可能收到一两个偶发超时告警 - 5000 的时候:P99 涨到 3s,开始有用户投诉 - 9872 的时候:P99 5s+,错误率 12%,告警炸了
整个过程是渐进的,没有一个明确的"状态变化"触发告警。queueSize 不在大多数公司的默认监控指标里,所以这个渐变过程完全在监控盲区中进行。
当 queueSize 达到 9872 时,每个新请求的排队时间已经超过 40 秒。客户端收到超时后发起重试,重试请求又进入队尾——队列越涨越快,形成正反馈循环。这就是从"接口偶尔变慢"到"服务雪崩"的完整路径。
面试升级版答案
回到面试题。如果你的面试官问"线程池大小怎么设",你可以给出一个层层递进的回答。
第一层:基础答案(及格线)
CPU 密集型用 N+1,IO 密集型用 2N。N 是 CPU 核心数。
大多数候选人到此为止。能答出这个,算合格。
第二层:推导公式(拉开差距)
这两个数字其实是特例。通用公式是 N × (1 + wait_time / cpu_time)。CPU 密集时 wait_time ≈ 0,公式退化为 N+1。IO 密集时 wait_time ≈ cpu_time,公式退化为 2N。当 wait/cpu 不等于 1 时,2N 会失效。
这一步把"背结论"变成了"讲推导"。面试官会意识到你不只是刷了题。
第三层:生产案例(面试加分项)
结合真实案例讲: "我之前维护过一个订单服务,按 2N 配了 16 线程。上线后下游延迟从 5ms 涨到 80ms,wait/cpu 从 1 变成 16,最优线程数从 16 变成 272。结果 queueSize 积压近万,接口超时率 12%。修复后线程数调到 64,P99 从 5s 降回 345ms。"
同步展示修复前后的配置:
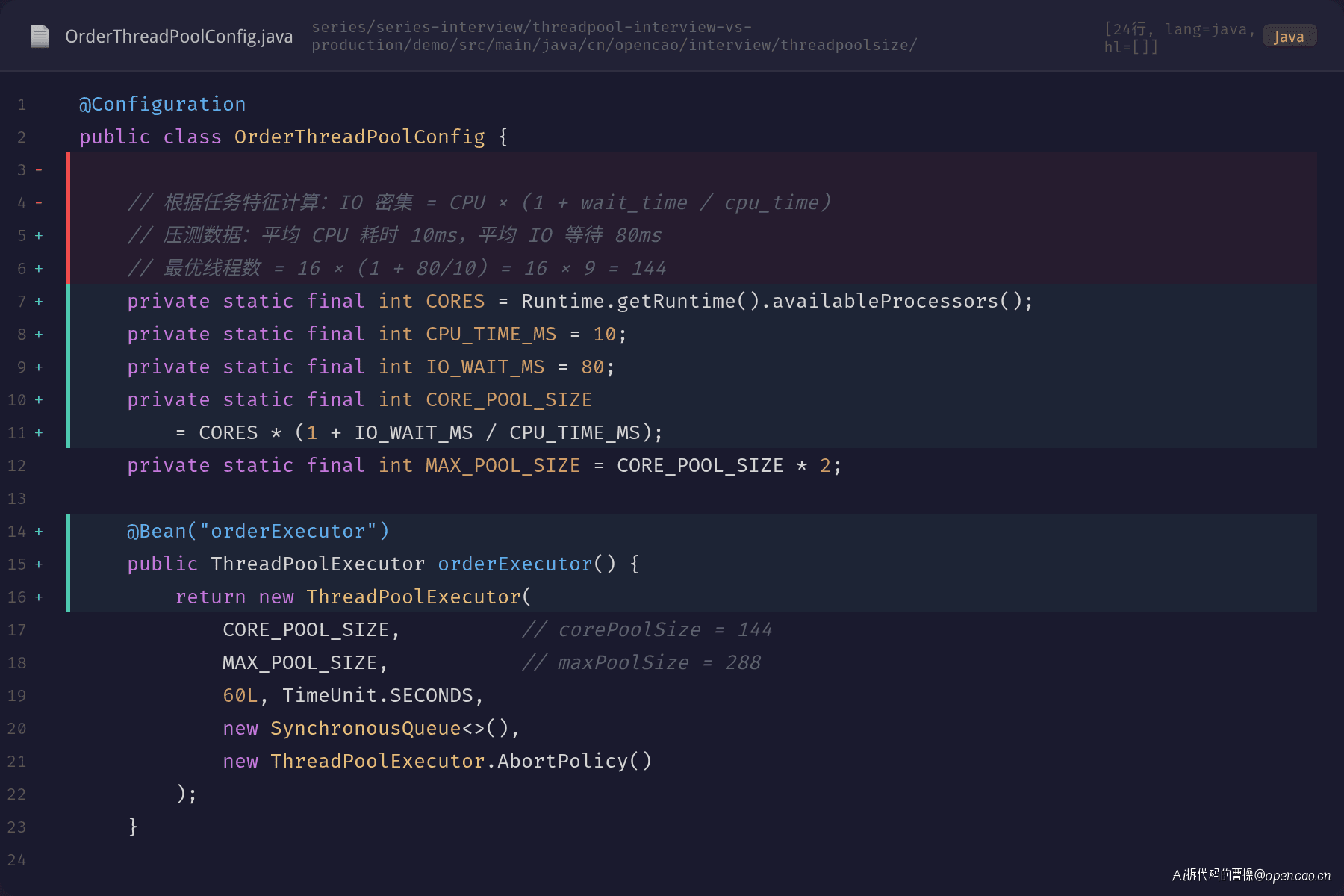
核心变更点: - 核心线程从 16 调到 64(基于 wait/cpu = 8,保留余量) - maxPoolSize = 128,支持突发流量 - keepAliveTime 60s,流量回落后自动缩容 - CallerRunsPolicy → AbortPolicy,避免 HTTP 线程被拖死 - 队列从 LinkedBlockingQueue 改为 SynchronousQueue,直接提交、不接受堆积
第四层:监控闭环(真正的高阶)
面试官可能会追问:"线程数配对了,你就放心了?"
答案是:不放心,需要监控验证。
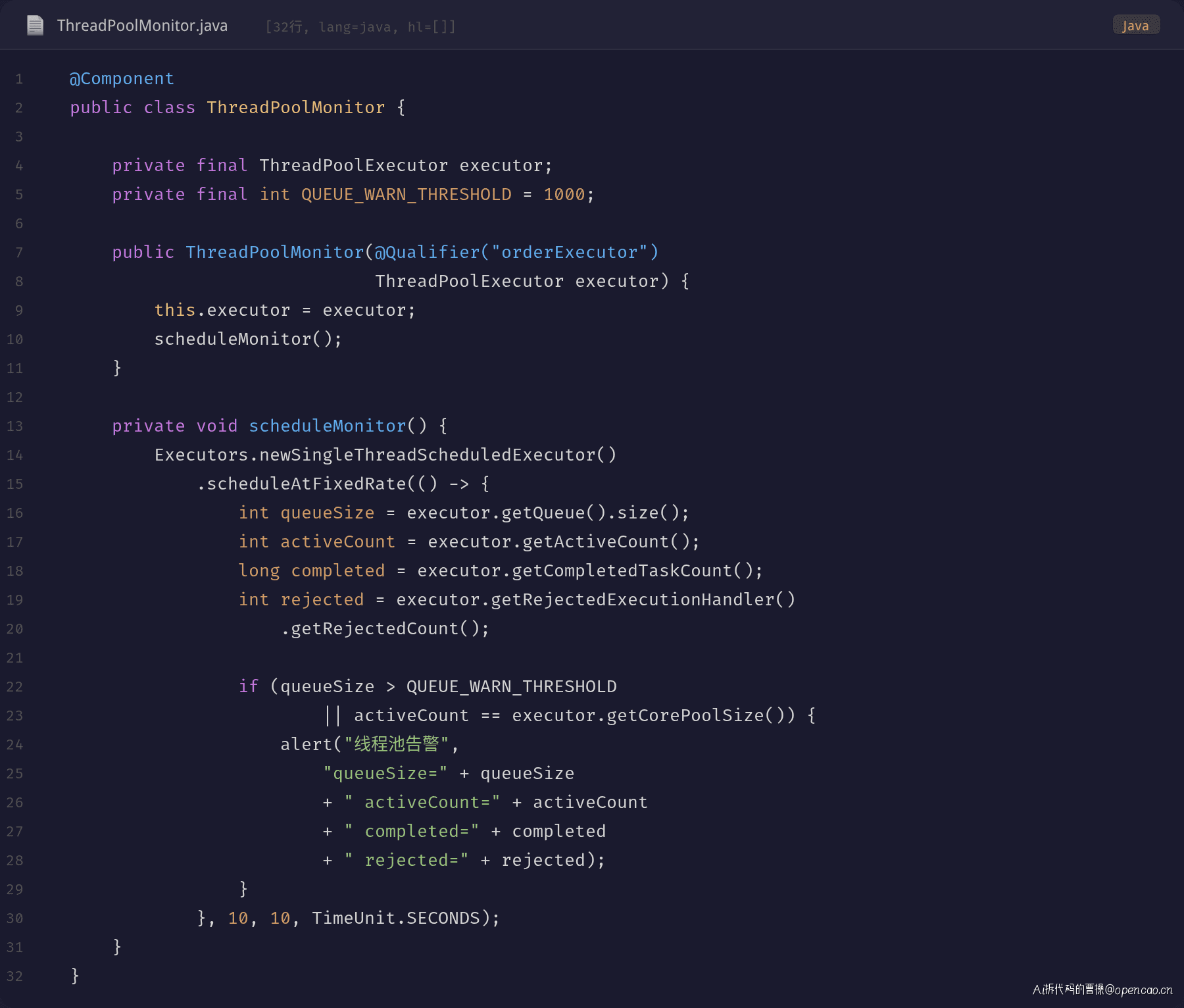
监控四维指标: 1. queueSize:阈值 1000,超过告警。这是最敏感的指标,队列一积压就发现问题。 2. activeCount vs corePoolSize:activeCount 长时间等于 corePoolSize 说明线程不够用。 3. completedTaskCount:一段时间内的完成量,衡量真实吞吐。 4. rejectedExecutionCount:>0 直接 P0 告警,任务已经开始丢了。
王哥在复盘时加了一句值得记住的话:
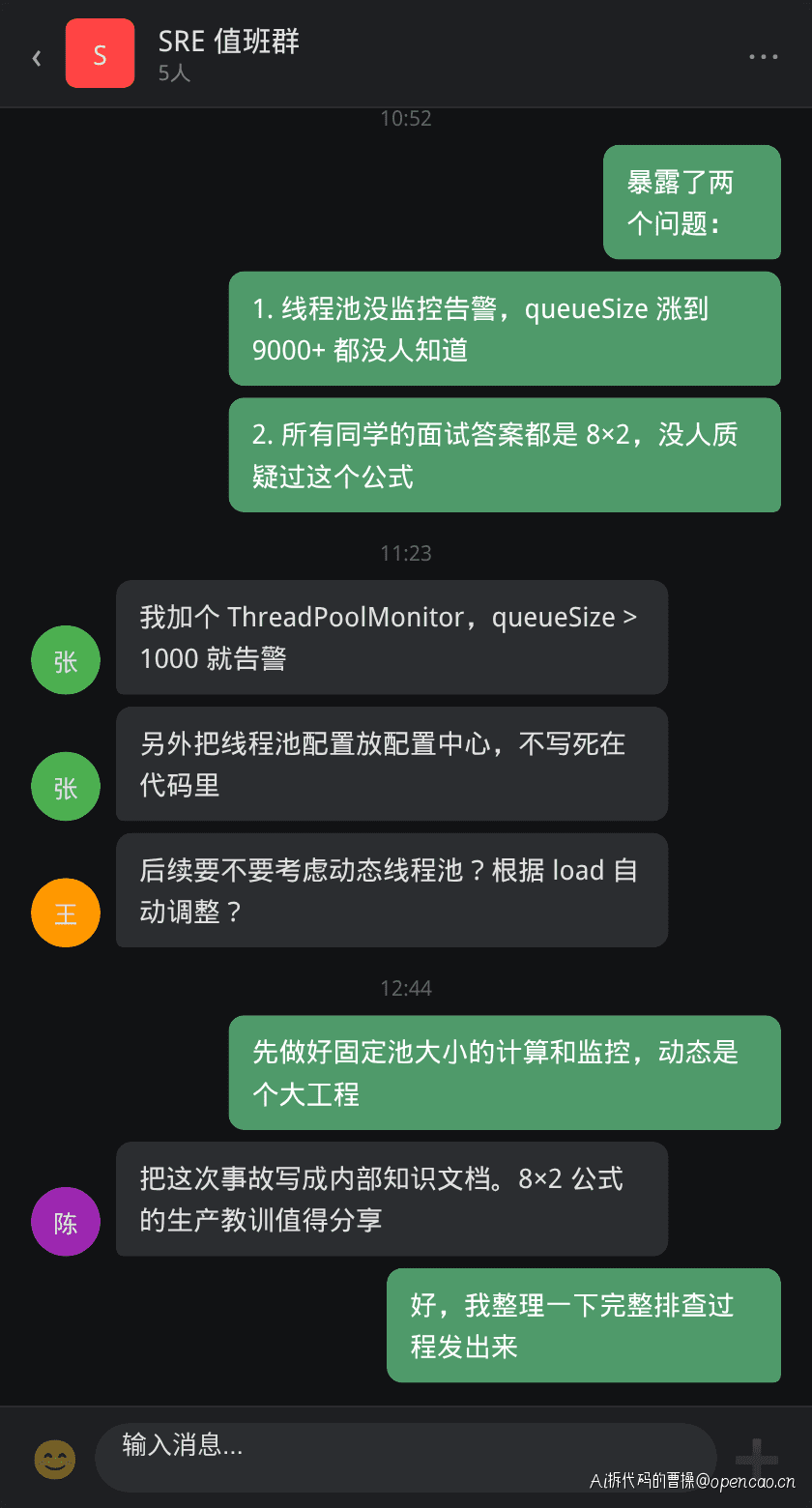
"面试考的是结论,生产要的是闭环。配置是答案,监控是验证。少一个都不行。"
验证——修复后的数据
修复后观测修复后的线程池状态和系统负载:
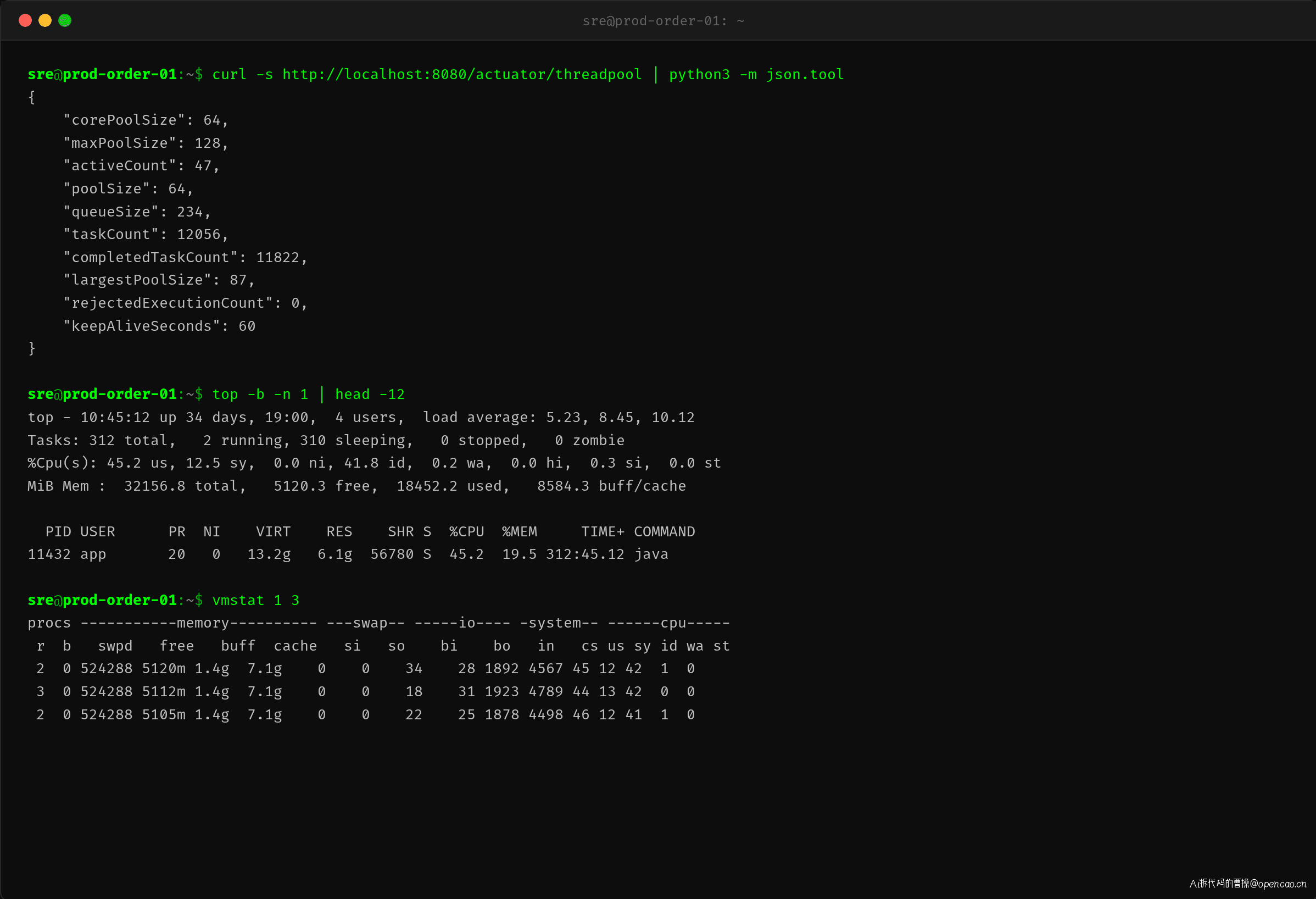
- queueSize 从 9872 降到 234(积压基本清空)
- activeCount 从 16 降到 47(线程数扩大后不需要全部占满)
- 接口 P99 从 5234ms 降到 345ms(恢复正常水平)
- CPU 利用率从 22% 升到 45%(这才是 IO 密集型的正常 CPU 使用率)
- load average 从 23.45 降到 5.23(排队大幅缓解)
- cs/sec 从 9000 降到 4500(上下文切换不升反降——队列通畅降低了切换频率)
避坑建议
-
别背 2N,推导公式才是面试加分项。 当你能说出 N×(1+wait/cpu) 并附带一个生产案例时,面试官给的评价不会是"基础扎实"而是"有生产深度"。这个差别在面试打分中至关重要。
-
Executors 工厂方法是生产禁区,没有任何例外。 newFixedThreadPool 的 LinkedBlockingQueue 无界,newCachedThreadPool 最大线程 Integer.MAX_VALUE。这两个 API 设计的初衷是实验和教学,不是生产。直接 new ThreadPoolExecutor,强迫自己思考每一个参数的意义。
-
CallerRunsPolicy 不是保底方案。 它看似"安全"——队列满了由调用者执行,至少不丢任务。但调用者线程执行任务意味着它不能再接收新请求。Tomcat 的 HTTP 线程池也会被拖垮,故障范围从线程池扩展到整个 Web 容器。
-
线程池配置后不做监控等于白配。 queueSize > 1000 告警、rejectedCount > 0 P0——这两条规则覆盖 90% 的线程池故障。配置 Spring Boot Actuator 或者 Micrometer,几行代码就能获取这些指标。
-
压测要包含降级场景。 Mock 下游延迟 1-2ms 的压测数据没有参考价值。生产环境的下游延迟会波动,一次数据库慢查询、一次网络抖动就能把 wait/cpu 从 2 变成 20。压测时加一个"下游变慢 10 倍"的场景,可以提前暴露线程池瓶颈。
-
线程池大小不是越大越好。 每个线程默认栈 1MB,144 个线程就是 144MB 栈内存。线程数过多还会增加上下文切换成本和锁竞争概率。合理的方式是用公式计算理论值,然后压测找到实际吞吐量的拐点。
附:完整命令清单
# 1. 查看线程池运行状态(通过 Spring Boot Actuator)
curl -s http://localhost:8080/actuator/threadpool | python3 -m json.tool
# 2. 查看 Java 线程状态分布
jstack <pid> | grep -E '(pool-|waiting on|TIMED_WAITING|BLOCKED)' | head -35
# 3. 查看系统负载和 CPU 使用率
top -b -n 1 | head -25
# 4. 查看上下文切换
vmstat 1 10
cat /proc/<pid>/status | grep -E '(Threads|voluntary)'
sar -w 1 5
# 5. 运行 Demo 对比不同线程池大小的吞吐差异
cd demo
./run_test.sh


