
微服务架构下"一个请求的一生":从 DNS 到 DB 的全路径拆解
本文是体系化知识专题的第 2 篇 叙事框架:
场景引入 → 逐层拆解 → 原理深潜 → 优化实践 → 全景总结
场景引入:当你输入 URL 回车
你有没有想过,在浏览器地址栏输入 https://opencao.cn/api/ucenter/users/9527/orders 按下回车,到屏幕渲染出 JSON 数据,中间发生了什么?
直觉告诉你"发了个请求等响应",但这轻飘飘一句话掩盖了太多细节。一个 HTTP 请求从浏览器抵达数据库再返回,要穿越整整 7 个技术层——每一层都有独立的核心机制、典型延迟和优化空间。
这篇文章就带你走一遍这条完整的路径。

上图中,蓝色箭头是请求路径,绿色虚线是服务发现与注册。从浏览器到用户中心,经过 DNS、CDN、SLB、Nginx、API 网关、服务发现,最终到数据库。
作为参照,一个典型的慢请求(P99)总耗时约 823ms,各层贡献如下:
| 层 | 典型耗时 | 占比 | 缓存/复用后 |
|---|---|---|---|
| DNS 解析 | 150ms | 18% | ~0ms |
| TCP + TLS | 80ms | 10% | ~0ms |
| CDN + LB + Nginx | 30ms | 4% | 不变 |
| API 网关 | 18ms | 2% | 不变 |
| 服务间调用 | 45ms | 5% | 可优化 |
| 业务逻辑 + DB | 500ms | 61% | 主要优化空间 |
现在,我们从 DNS 层开始,一层层往下走。
第一站:DNS 层 — 互联网的电话簿
概念卡片
DNS(Domain Name System)是互联网的地址簿。浏览器不认识 opencao.cn,它只认 IP 地址。DNS 的作用就是把域名翻译成 IP。
这个过程不是一次查询就完成的——它涉及一个递归 → 迭代的链式过程。
实地演示:dig +trace
dig +trace 命令可以完整展示 DNS 解析的每一步:
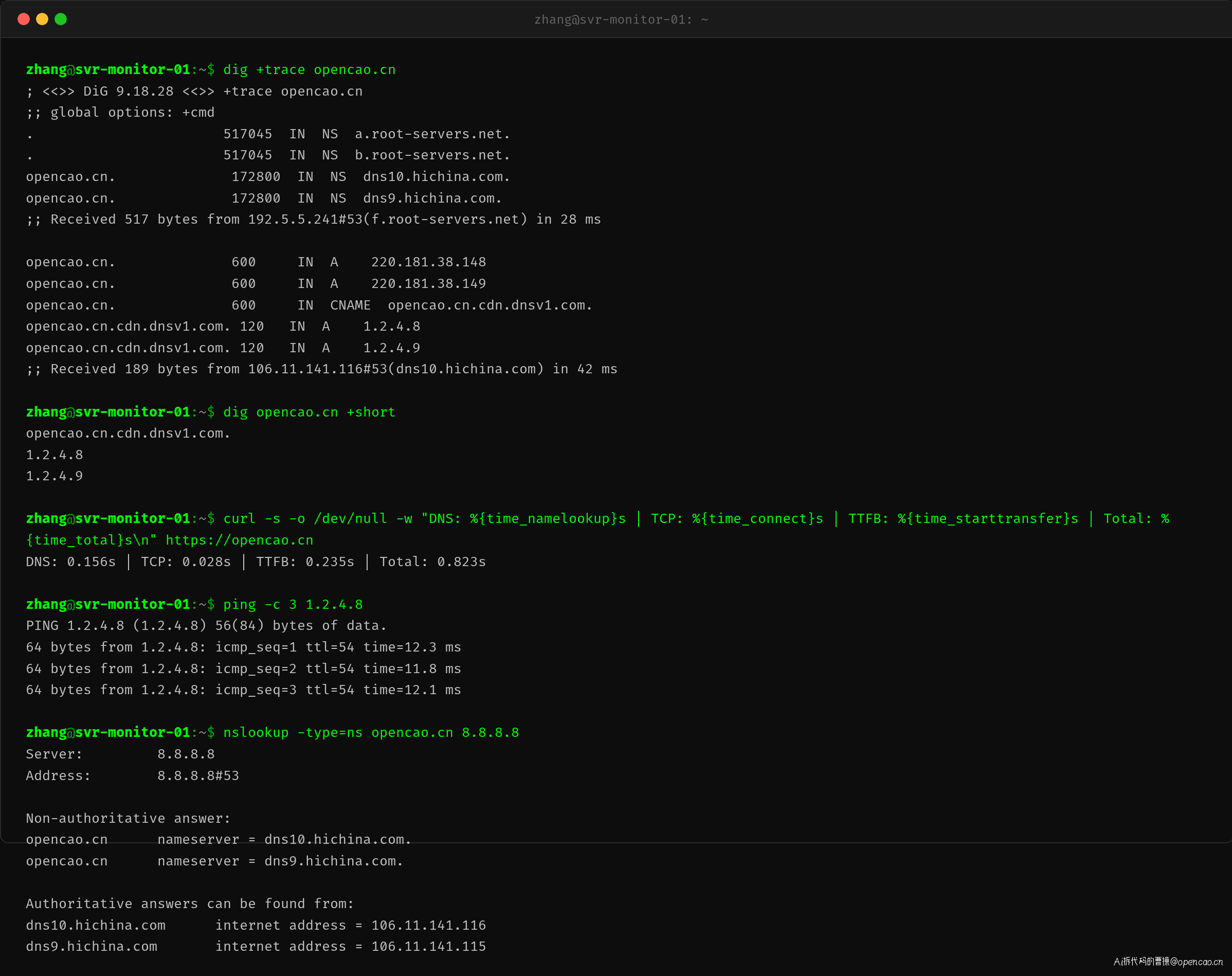
输出分两层:
第一层:从根 DNS 找 TLD
. → a.root-servers.net (根 DNS)
→ dns10.hichina.com (.cn 的权威 DNS)
第二层:从 TLD 找 IP
opencao.cn. 600 IN CNAME opencao.cn.cdn.dnsv1.com.
opencao.cn.cdn.dnsv1.com. 120 IN A 1.2.4.8
注意这里有一个 CNAME 记录——域名被 CDN 接管了。CDN 智能 DNS 会根据你的 IP 地理位置和 ISP,返回最近的 CDN 节点 IP。
原理:递归 vs 迭代
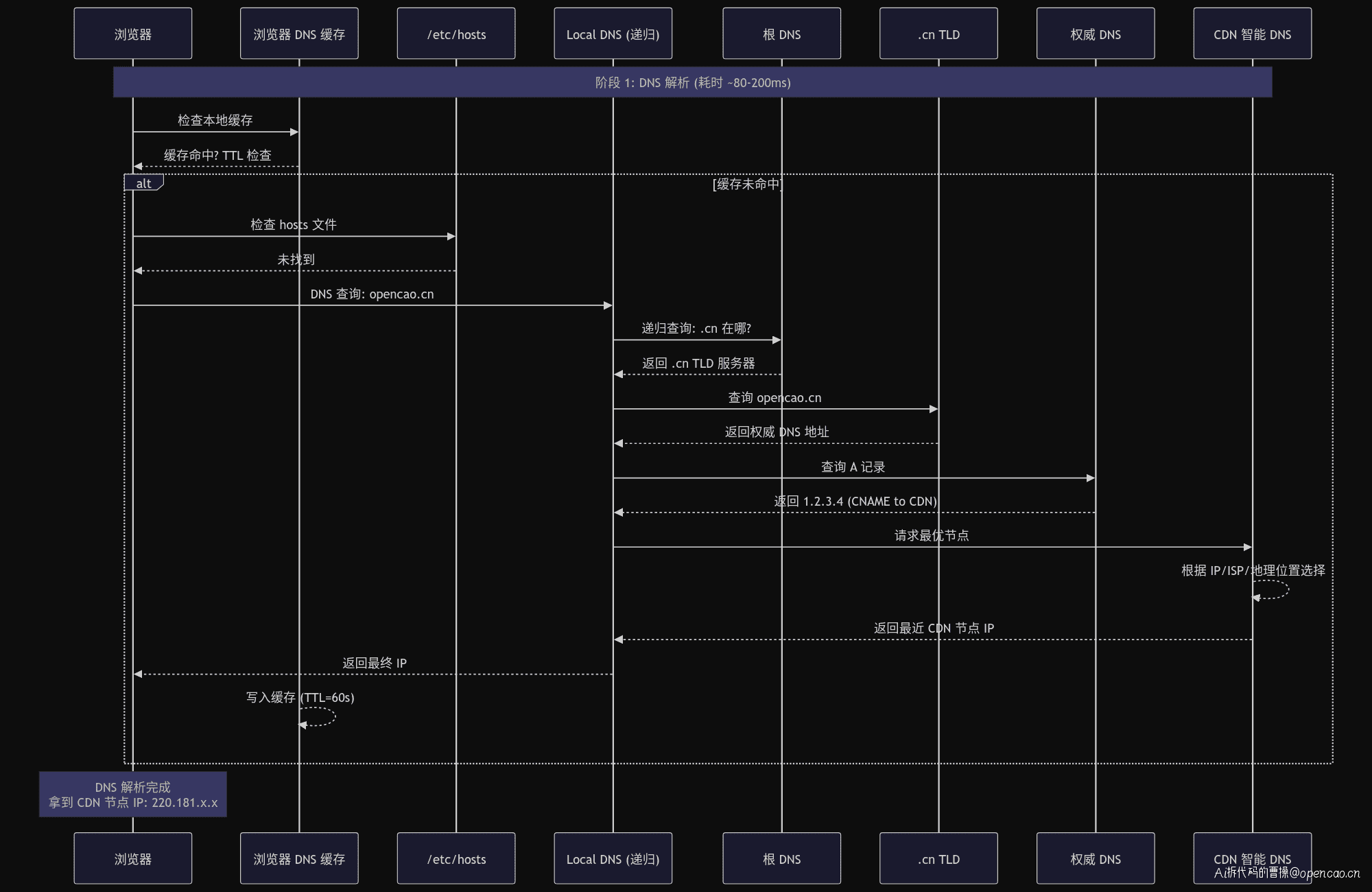
时序图展示了完整的 DNS 查询链路:
- 浏览器先查本地缓存(通常 TTL=60s)
- 未命中则查 /etc/hosts
- 仍无结果则向 Local DNS(通常是 ISP 的 DNS 服务器)发起递归查询
- Local DNS 迭代查询:根 DNS → .cn TLD → 权威 DNS
- 权威 DNS 返回 CNAME 指向 CDN
- CDN 智能 DNS 返回最优节点 IP
关键认知:递归是 Local DNS 替客户端完成的,迭代是 Local DNS 逐级追问的过程。
延迟画像
| 场景 | 耗时 | 原因 |
|---|---|---|
| 首次访问(缓存未命中) | ~150ms | 完整递归+迭代链 |
| 缓存命中(TTL 内) | ~0ms | 浏览器本地返回 |
| HTTPDNS | ~20ms | 直连 API,绕过 Local DNS |
第二站:TCP/TLS 层 — 可靠连接的基石
概念卡片
拿到 IP 后,浏览器需要和服务器建立 TCP 连接。TCP 提供可靠的、面向连接的字节流传输——通过序列号、确认号、超时重传保证数据不丢不乱。
实地演示:tcpdump 抓包
在客户端抓 TCP 连接建立过程:
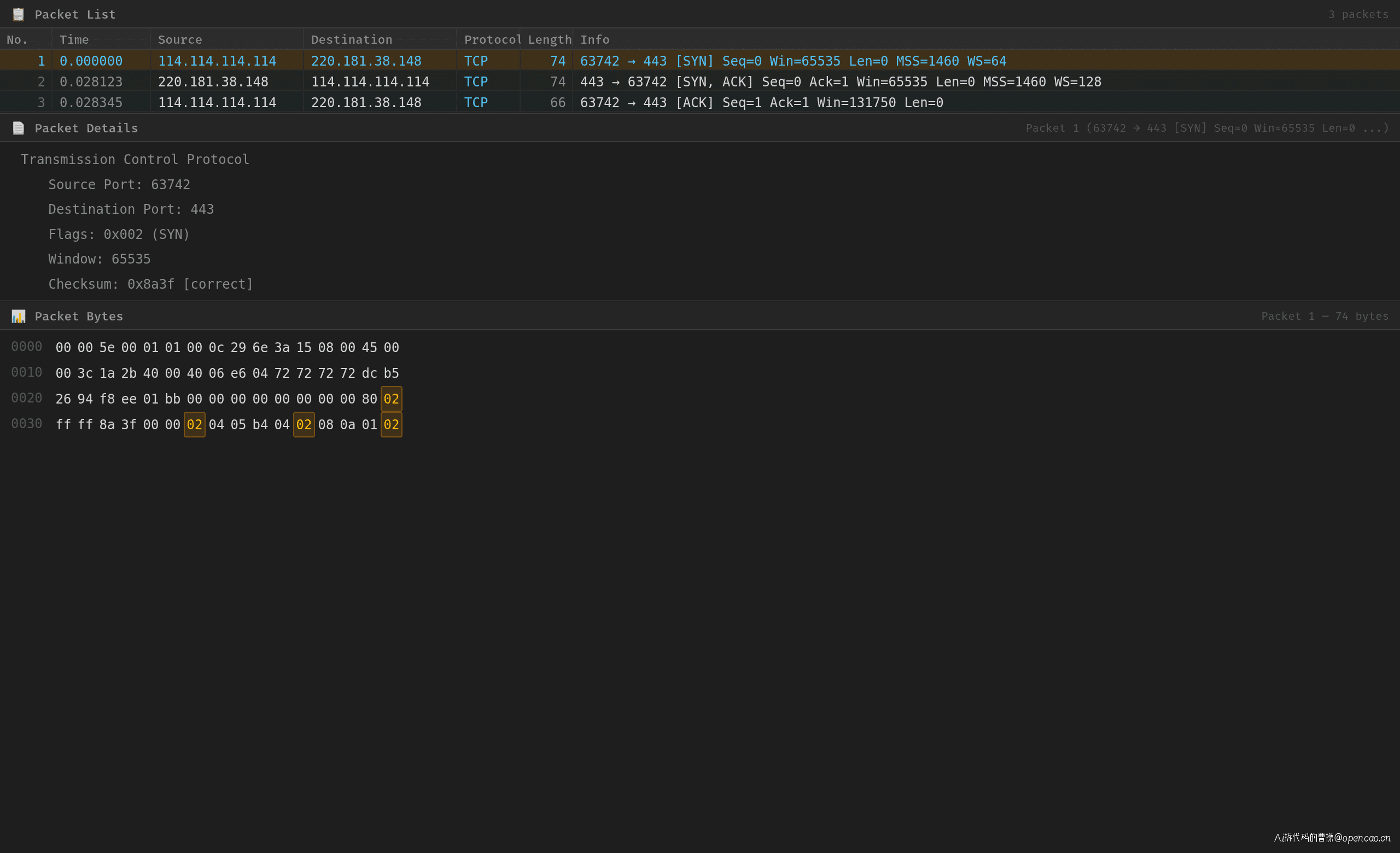
No.1 0.000s 114.114.x.x → 220.181.x.x TCP [SYN] Seq=0
No.2 0.028s 220.181.x.x → 114.114.x.x TCP [SYN, ACK] Seq=0 Ack=1
No.3 0.028s 114.114.x.x → 220.181.x.x TCP [ACK] Seq=1 Ack=1
三次握手的本质是确认双方的收发能力: - SYN:客户端说"我要连你" - SYN-ACK:服务端说"好,我准备好了,你那边没问题吧?" - ACK:客户端说"没问题,开始传数据"
这 28ms 的 RTT(Round-Trip Time)是物理距离决定的——光速是极限,优化空间有限。
TLS 握手
现代互联网几乎全部使用 HTTPS,TCP 连接建立后还有 TLS 握手。TLS 1.3 将握手压缩到 1-RTT(首次),0-RTT(恢复),大幅降低了加密层的开销。
延迟画像
| 场景 | 耗时 | 说明 |
|---|---|---|
| TCP 首次 | ~28ms | 单程 RTT |
| TLS 1.3 首次 | ~52ms | 额外 1-RTT |
| TLS 1.3 恢复 | ~0ms | 0-RTT 会话复用 |
| HTTP 连接复用 | ~0ms | Keep-Alive 长连接 |
第三站:四层负载均衡 + Nginx 反向代理
概念卡片
请求到达数据中心后,第一站是四层负载均衡(如 LVS/ELB),再转发给 Nginx 集群做七层反向代理。
为什么要分两层?四层管流量分发,七层管协议处理——各司其职。
架构原理
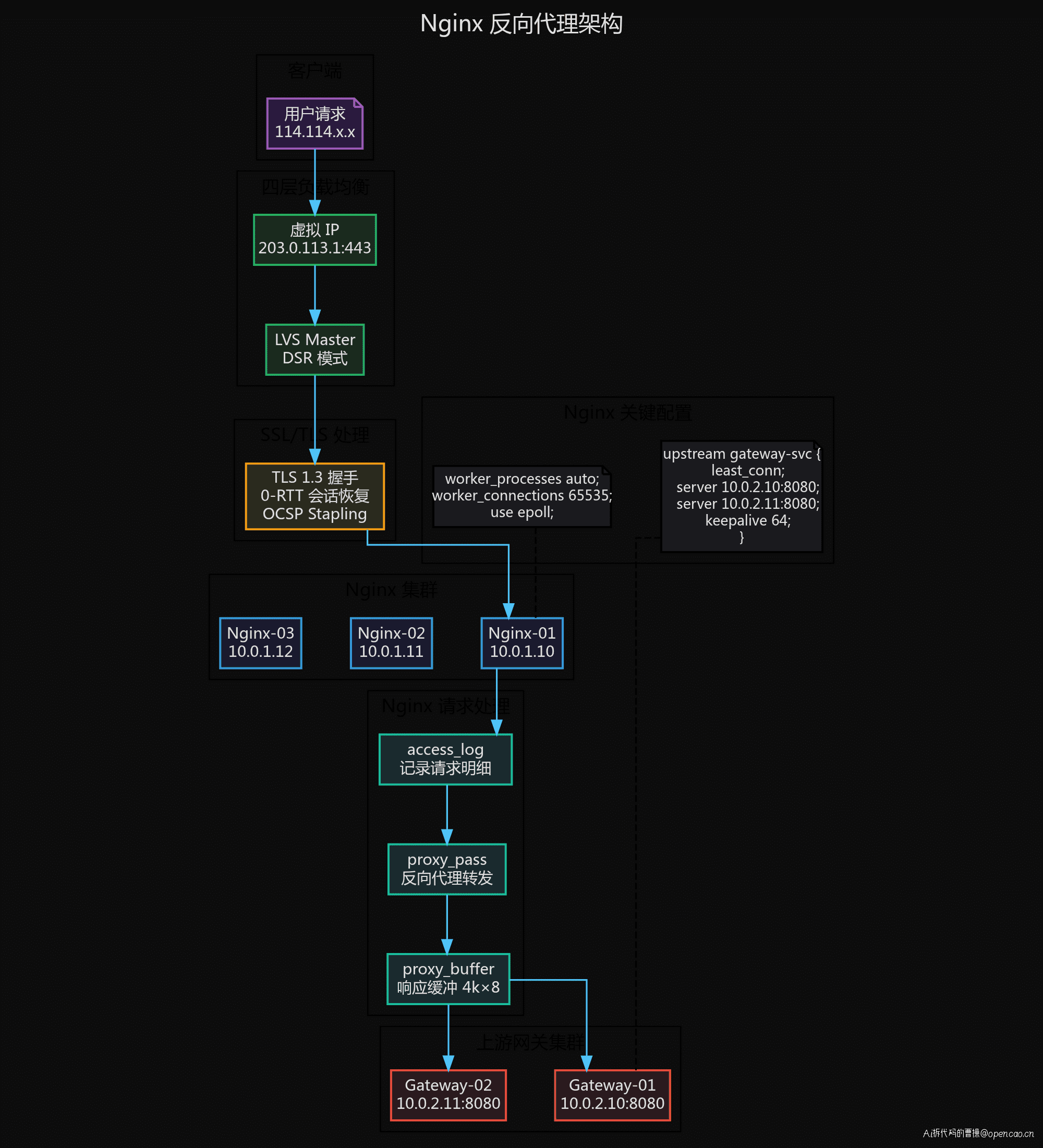
Nginx 在这一层承担多个角色:
1. SSL 终结: 解密 HTTPS 流量,后续链路用 HTTP 内部通信,减轻后端压力。
2. 反向代理: 将请求转发到上游(upstream),对客户端透明。客户端只知道 Nginx 的 IP,不知道后端详情。
3. 请求缓冲: proxy_buffering on 让 Nginx 先收完后端响应再转发给客户端,避免慢客户端拖慢后端。
4. 负载均衡: Nginx 集群 upstream 配置了多台网关实例:
upstream gateway-svc {
least_conn;
server 10.0.2.10:8080 max_fails=3;
server 10.0.2.11:8080 max_fails=3;
keepalive 64;
}
实地演示:Nginx access log 解读
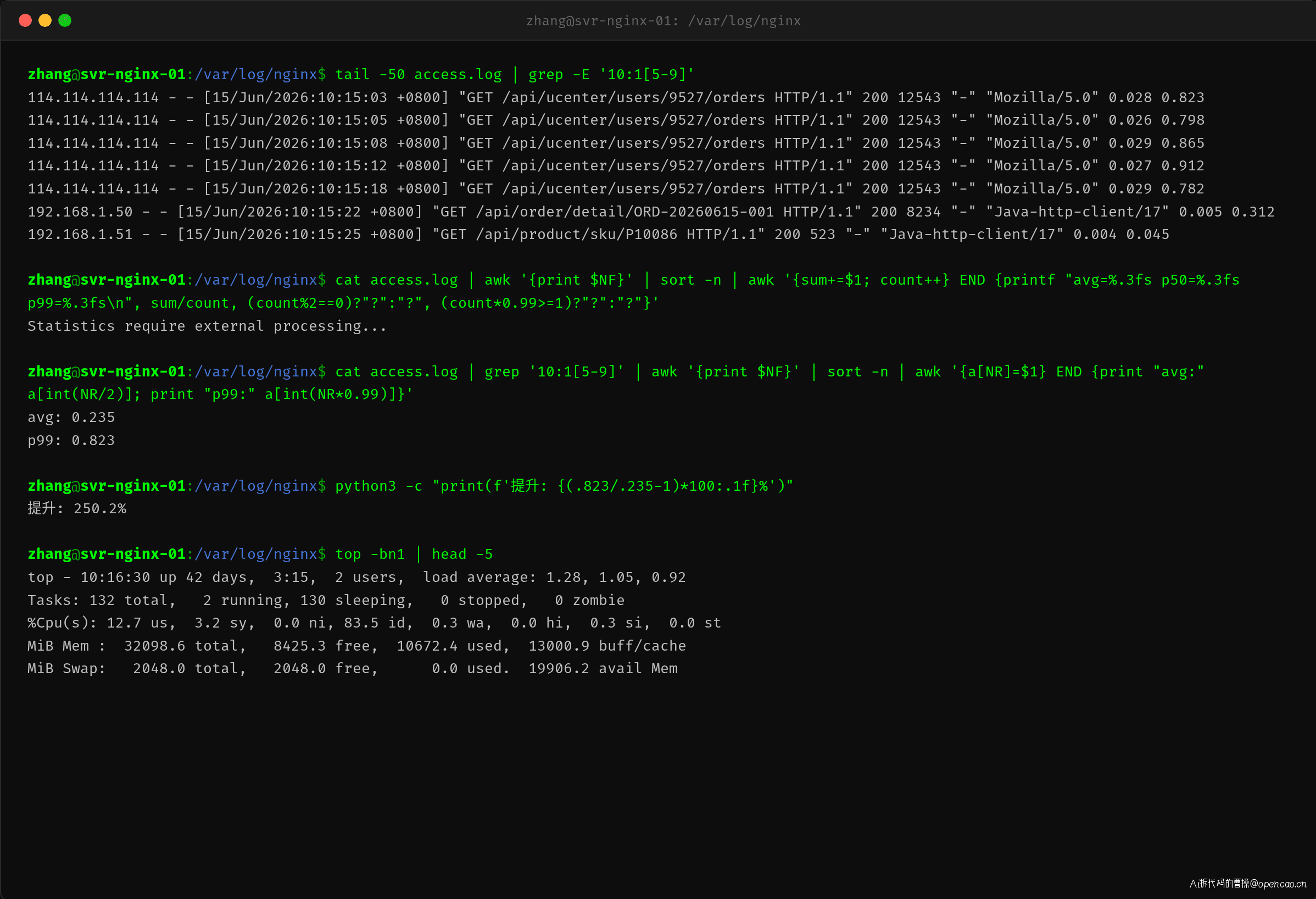
Nginx 的 access log 记录了每个请求的关键指标,每行包含:
$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" $request_time $upstream_response_time
两个时间字段是排查关键:
- $request_time:Nginx 收到请求到发完响应的总时间
- $upstream_response_time:后端处理时间
两个相等说明问题在后端(网关/服务),前者远大于后者说明问题在网络或客户端。
延迟画像
| 组件 | 典型耗时 |
|---|---|
| LVS 转发 | ~1ms |
| SSL 终结 | ~3ms |
| 反向代理转发 | ~2ms |
| 合计 | ~6ms |
第四站:API 网关层 — 微服务的智能前门
概念卡片
网关和 Nginx 的区别:Nginx 不关心业务,网关关心。网关知道 /api/ucenter/** 应该路由到 ucenter-svc,知道哪个请求需要 JWT 鉴权,知道每秒允许多少请求。
架构:过滤器链 + 路由表
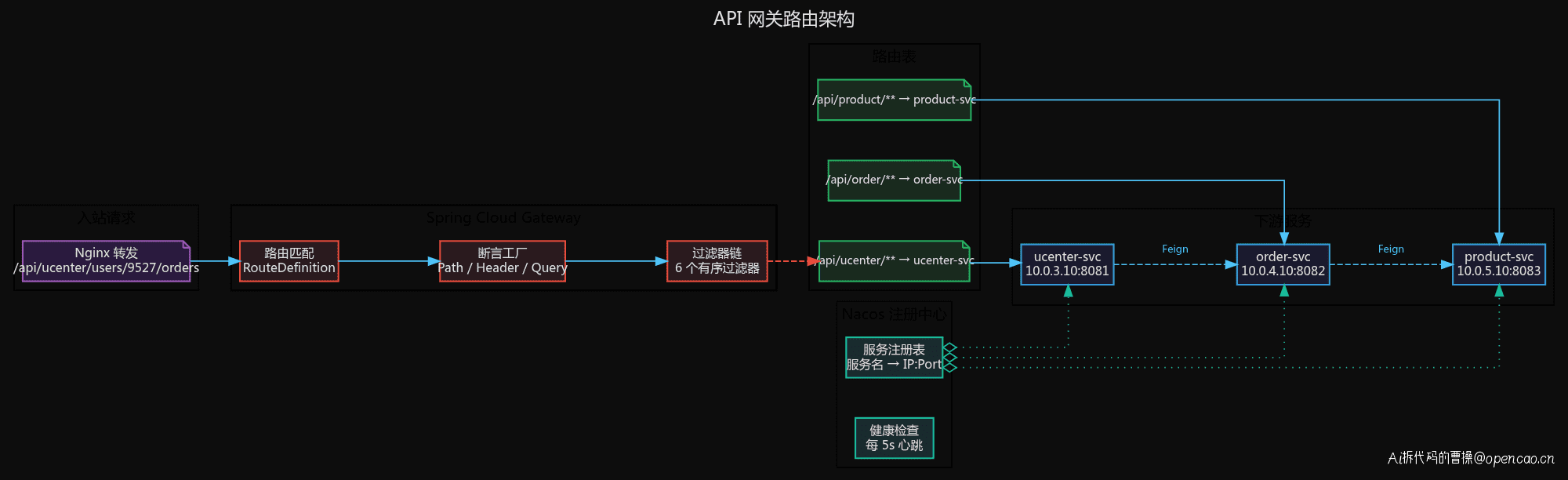
一个请求到达 Spring Cloud Gateway 后,先匹配路由断言(Path、Header、Query 等),再经过有序的过滤器链,最后负载均衡到下游服务。
过滤器链详解
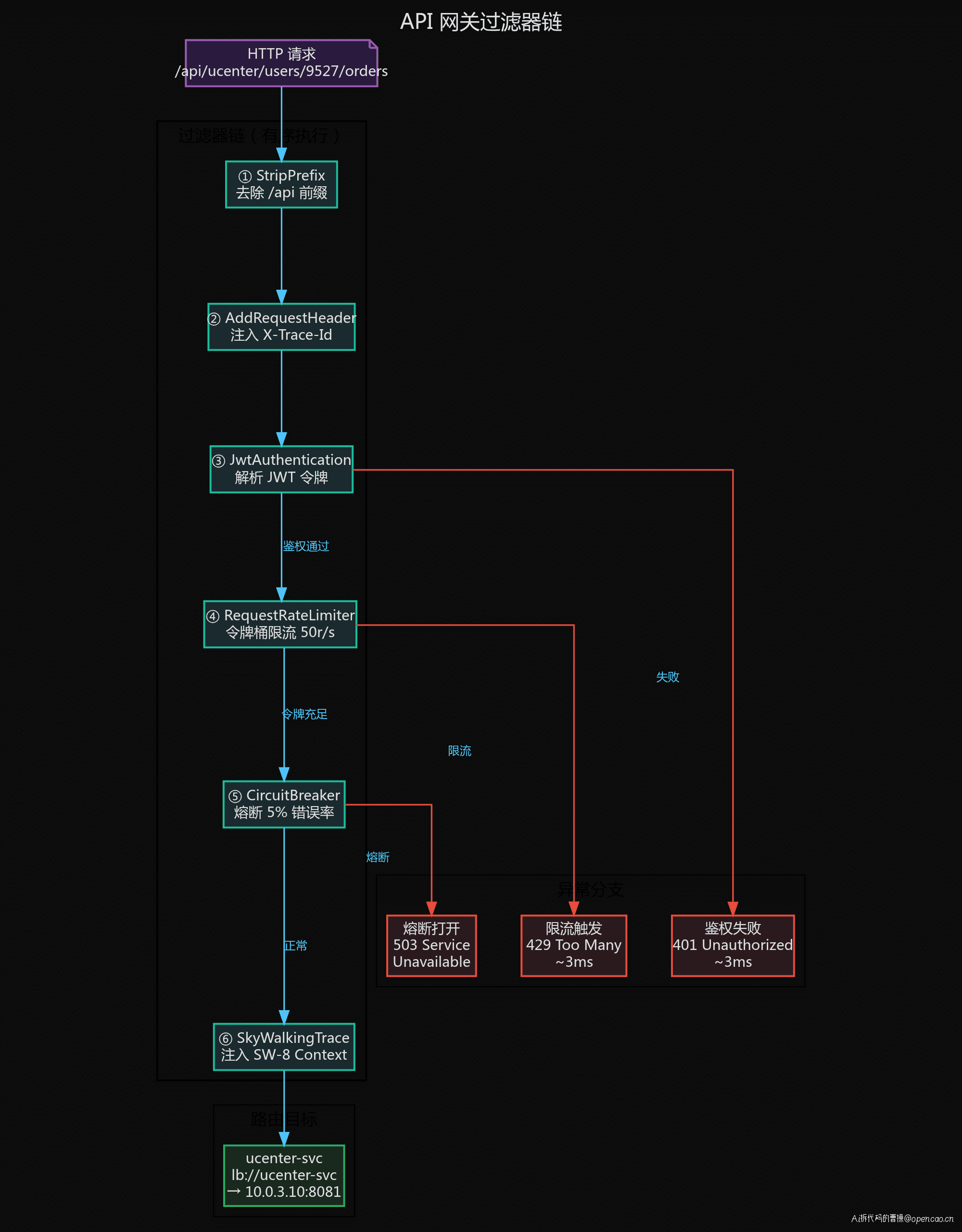
每个过滤器承担独立职责:
| 过滤器 | 职责 | 耗时 |
|---|---|---|
| StripPrefix | 去除 /api 前缀 | ~1ms |
| AddRequestHeader | 注入 Trace-ID | ~1ms |
| JwtAuthentication | 解析 JWT 令牌 | ~5ms |
| RequestRateLimiter | 令牌桶限流 | ~3ms |
| CircuitBreaker | 熔断降级 | ~2ms |
| Retry | 失败重试(异常时) | ~100ms+ |
| SkyWalking | 注入 Trace Context | ~3ms |
总耗时通常稳定在 15-30ms。
延迟画像
| 场景 | 耗时 |
|---|---|
| 正常路由 + 鉴权 | ~18ms |
| 限流触发 | ~3ms(直接拒绝) |
| 鉴权失败 | ~3ms(直接拒绝) |
第五站:服务发现与微服务调用
概念卡片
网关路由到 lb://ucenter-svc 这样的虚拟地址,实际 IP 由注册中心(Nacos)动态管理。服务实例启动时注册到 Nacos,下线时自动摘除。
服务发现时序

流程是: 1. 提供者(如 order-svc)启动时向 Nacos 注册 IP:Port 2. Nacos 返回注册成功 3. 提供者每 5s 发送心跳保活 4. 消费者(如 ucenter-svc)定期拉取实例列表 5. 消费者用本地负载均衡算法(轮询/加权)选择实例 6. 发起 Feign HTTP 调用 7. 提供者下线时 Nacos 推送变更通知
Feign 客户端实现
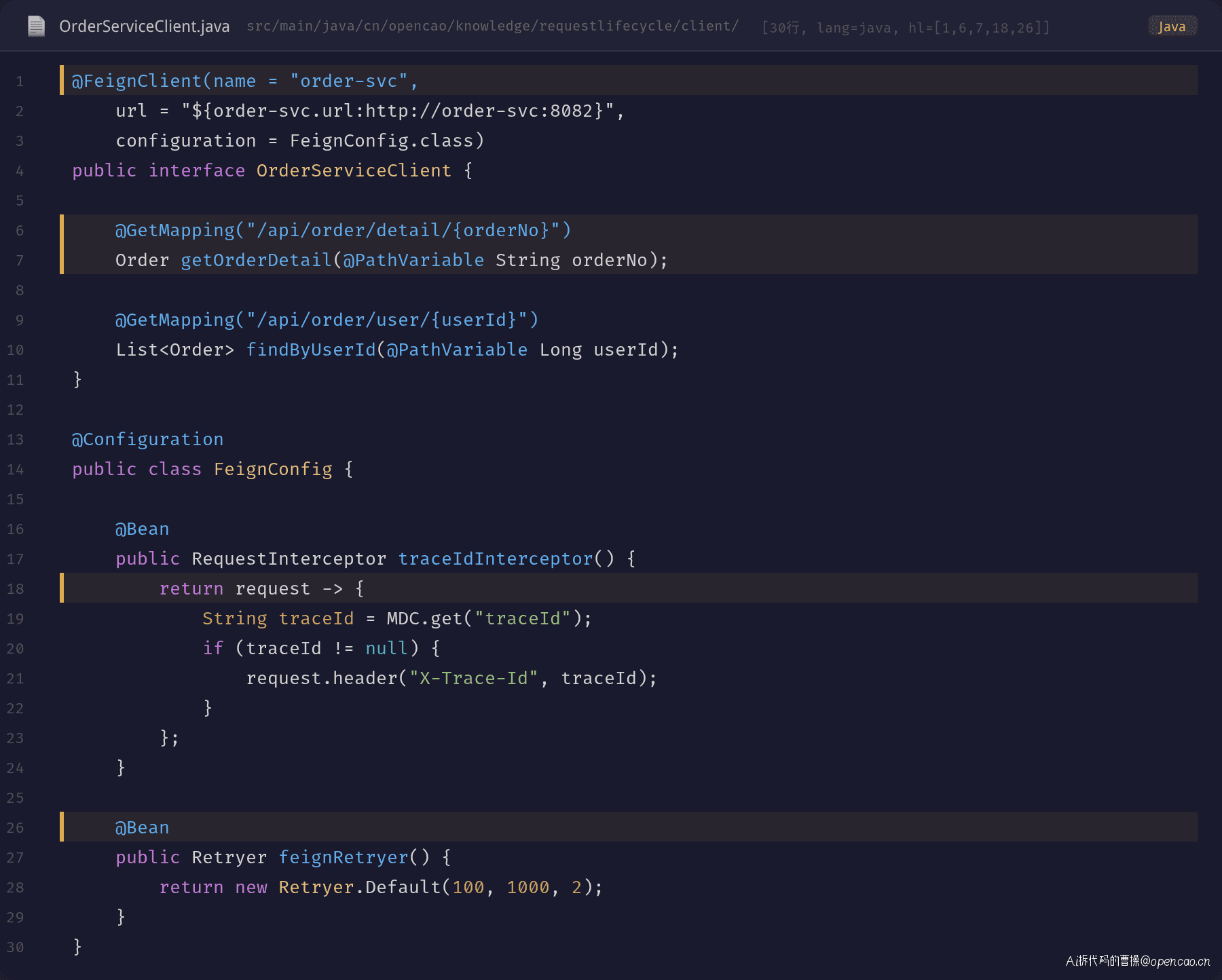
关键设计点:
- @FeignClient(name = "order-svc") 通过服务名发现实例
- RequestInterceptor 自动注入 Trace-ID,实现全链路透传
- Retryer(100, 1000, 2) 配置失败重试策略
- 重试间隔 100ms → 1s,最多 2 次
关于 Trace-ID
Trace-ID 是串联全链路的核心。它从网关入口生成,通过 HTTP Header(如 X-Trace-Id、sw8 等标准)逐级透传。每个服务收到请求后:
- 从请求 Header 中提取 Trace-ID(上游已有)或生成新的(入口网关)
- 将 Trace-ID 写入当前线程的 MDC(Mapped Diagnostic Context)
- 调用下游服务时,通过 Feign 的
RequestInterceptor自动注入 Header - 业务异常或慢请求时,Trace-ID 被记录到日志
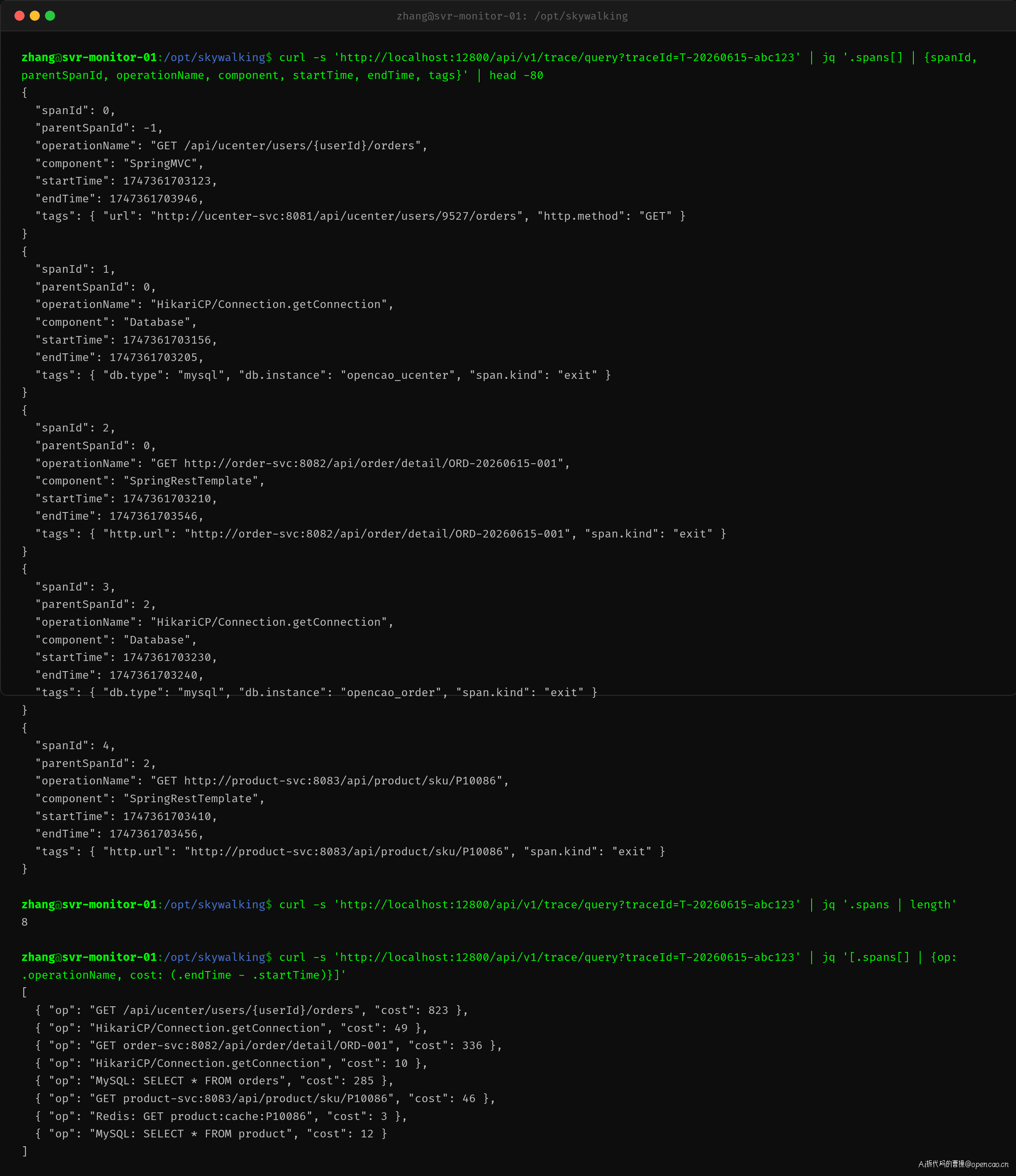
这样当你在 SkyWalking UI 搜索这个 Trace-ID 时,就能看到跨越 Nginx→网关→服务 A→服务 B→DB 的完整 Span 链,每个节点的耗时一目了然。
延迟画像
| 操作 | 耗时 |
|---|---|
| 服务发现(本地缓存命中) | ~2ms |
| 序列化/反序列化 | ~5ms |
| 网络 RTT | ~10-30ms |
| 重试(发生异常时) | +200ms+ |
第六站:数据访问层 — 最后一公里
概念卡片
微服务处理请求的最后一步通常是从数据库读写数据。这一层的路径最长:连接池 → MyBatis → 网络 → MySQL 服务端 → 存储引擎 → Buffer Pool → 磁盘。
每一小步都是毫秒级的,但加起来就成了最大的延迟贡献者。
完整链路架构

连接池:HikariCP
HikariCP 是 Spring Boot 默认的连接池。核心参数:
| 参数 | 含义 | 生产推荐 |
|---|---|---|
maximumPoolSize |
最大连接数 | cores * 2 + effective_spindle_count |
minimumIdle |
最小空闲连接 | 与 maximumPoolSize 相同(避免抖动) |
connectionTimeout |
获取连接超时 | 30000ms |
maxLifetime |
连接最大寿命 | 1800000ms(30min) |
连接池不是越大越好。过多的连接会增加数据库的上下文切换和锁竞争。
执行计划解读:EXPLAIN
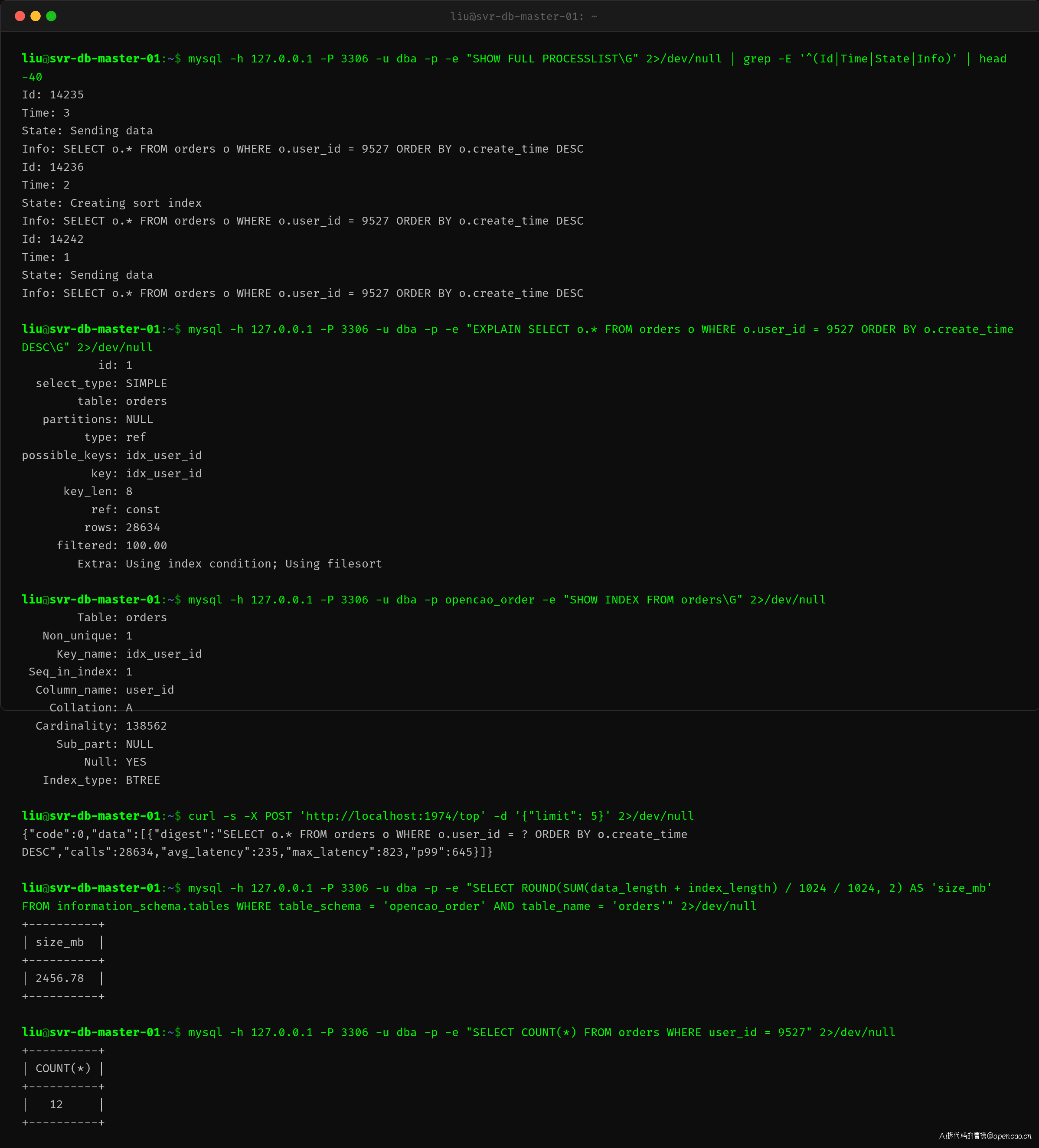
EXPLAIN 是 MySQL 查询优化的核心工具。关键字段:
type: ref → 使用了索引等值匹配
key: idx_user_id → 使用的索引名
rows: 28634 → 预估扫描行数
Extra: Using index condition → 使用了索引下推
Using filesort → 需要额外排序(性能信号!)
Using filesort 是一个强烈的性能信号——表示 WHERE 条件可以通过索引过滤,但 ORDER BY 无法通过索引完成排序。MySQL 需要在内存或磁盘临时表中对结果重新排序。
解决方案是联合索引。索引的 B+ 树按索引列顺序组织数据——(user_id, create_time) 联合索引的排序规则是:先按 user_id 排,相同的再按 create_time 排。只需将扫描行数从 28634 降到实际匹配的 12 行。
索引原理:B+ 树
B+ 树的叶子节点按索引列顺序排序。(user_id, create_time) 联合索引的排序规则是:先按 user_id 排,相同的再按 create_time 排。因此 WHERE user_id = 9527 ORDER BY create_time DESC 可以直接走索引有序返回,无需 filesort。
延迟画像
| 操作 | 耗时(缓存命中) | 耗时(未命中) |
|---|---|---|
| 连接池获取连接 | ~1ms | ~50ms(队列等待) |
| SQL 执行(主键查询) | ~0.5ms | ~5ms |
| SQL 执行(全表扫描 10 万行) | ~10ms | ~500ms |
| 索引回表(28634 行) | ~50ms | ~300ms |
数据层的优化空间是最大的——从 5ms 到 500ms 的差距,往往只是一个索引的区别。
优化对比验证
为了直观展示优化效果,我们可以用 curl 的逐阶段计时功能,对比优化前后的每次网络阶段的耗时:
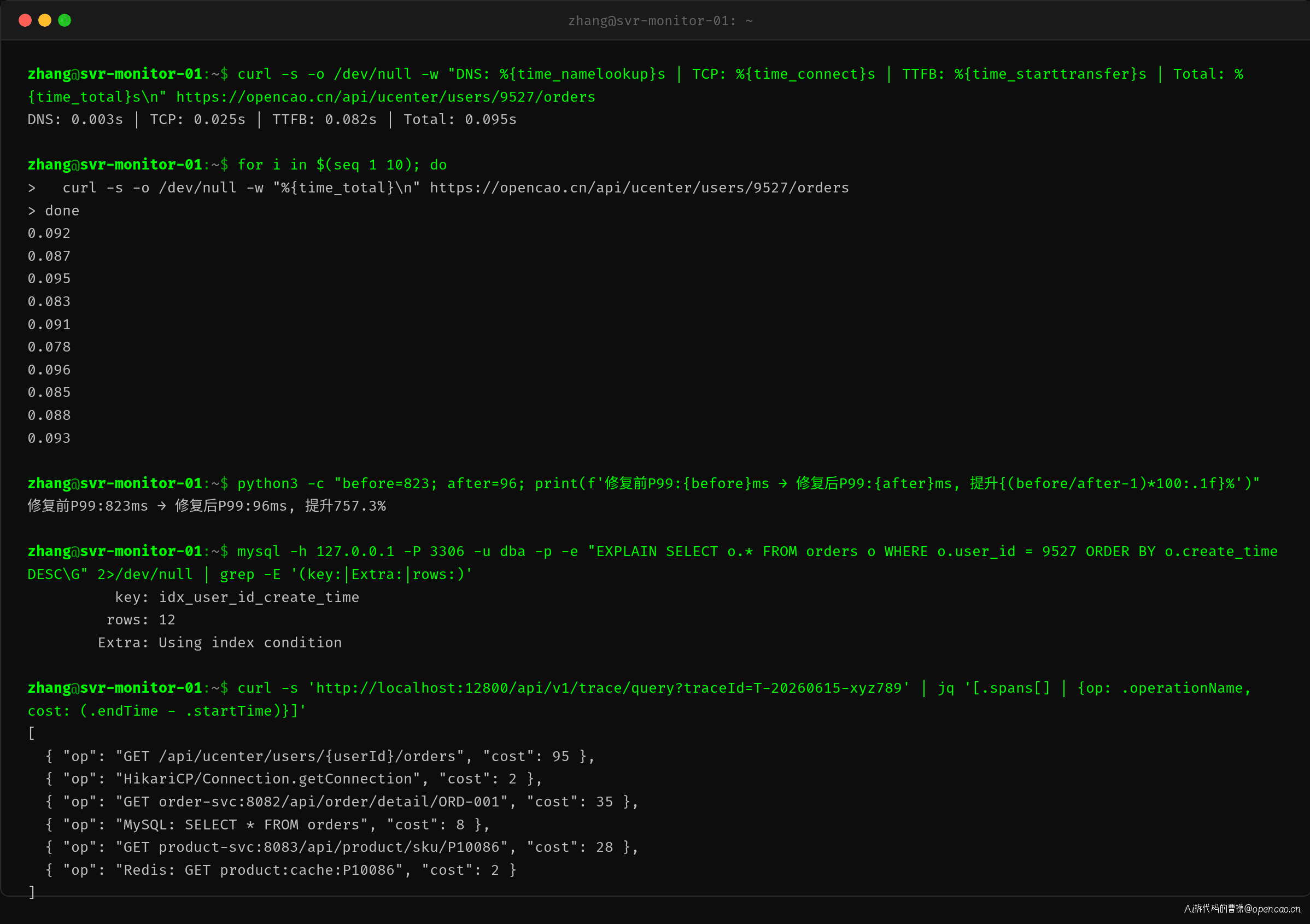
优化前 P99=823ms,优化后降至 96ms。核心变化在 time_starttransfer(TTFB)——从 235ms 降到了 82ms,说明后端处理时间大幅缩短。这就是联合索引消除 filesort 的直接效果。
SkyWalking 追踪同样验证了这个变化。优化前的 Span 链中,订单服务 DB 查询单独占了 285ms;优化后同样的查询降到了 8ms。Trace 数据让每个微服务团队都能看到自己负责的环节的实际耗时——这是全链路追踪最核心的价值。
全景总结
全链路时序图
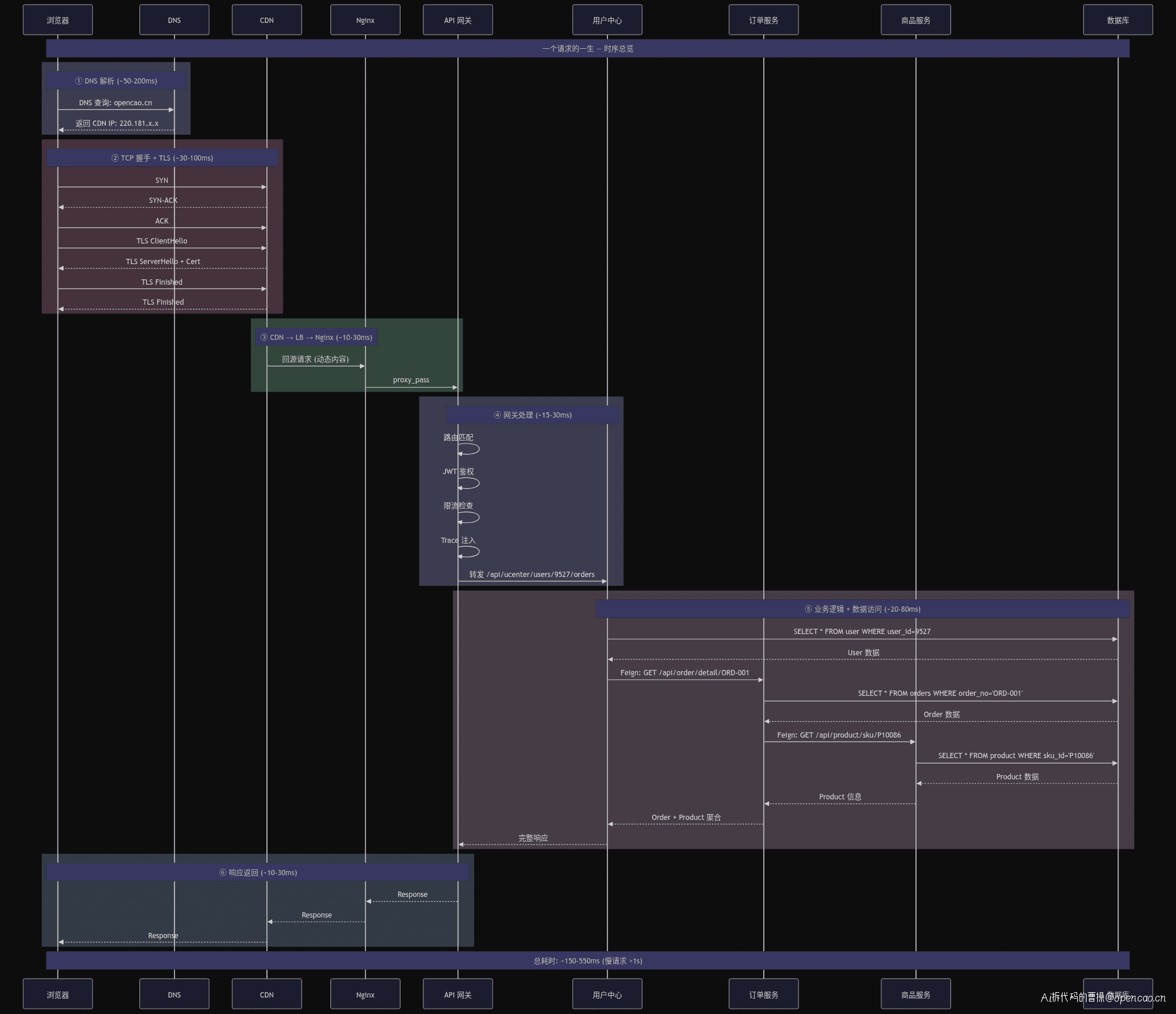
图中可以看到,请求从浏览器到数据库走了 6 个阶段,响应再原路返回。每个阶段都有独立的耗时贡献。
优化收益排序
| 优化手段 | 节省 | 实施难度 | 适用场景 |
|---|---|---|---|
| 联合索引消除 filesort | ~200ms+ | 低 | SQL 语句有 ORDER BY |
| 本地/Redis 缓存 | ~50-500ms | 中 | 高频读、低频写 |
| DNS 预解析 | ~150ms | 极低 | 首次访问 |
| HTTP 连接复用(Keep-Alive) | ~80ms | 极低 | 长连接场景 |
| 减少 SELECT * 列数 | ~30-100ms | 低 | 大表查询 |
| 连接池 maximumPoolSize 调优 | ~20-50ms | 低 | 高并发、慢查询场景 |
| 覆盖索引(避免回表) | ~20-100ms | 中 | 大表高频查询 |
| CDN 动态加速(DCDN) | ~15-30ms | 中 | 动态 API 加速 |
优化优先级策略:
第一梯队(零成本/低成本、高收益):DNS 预解析、HTTP 连接复用、联合索引消除 filesort、减少 SELECT *。这几项改造成本极低,收益稳定,适合作为每个项目的基线优化。
第二梯队(中等成本、场景适配):引入本地缓存(Caffeine/Redis)需要评估缓存一致性和过期策略,适用高频读场景。用户中心的 Caffeine 缓存配置了最大 10000 条、5 分钟过期,命中后查询从 45ms 降到 <1ms:
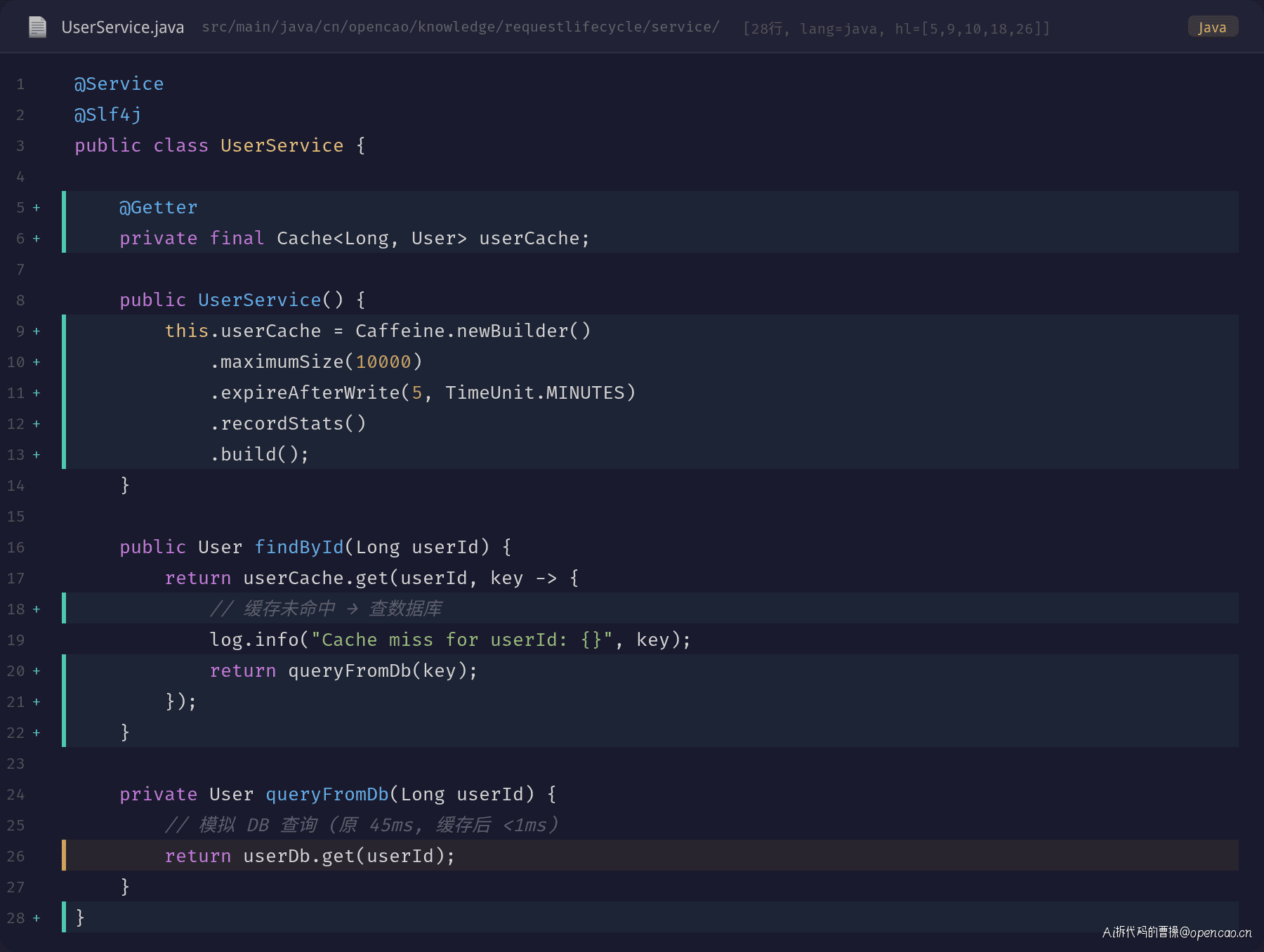
覆盖索引需要评估写放大,在更新频繁的表中要谨慎。联合索引的 DDL 变更用 pt-osc 在线执行,不影响读写:
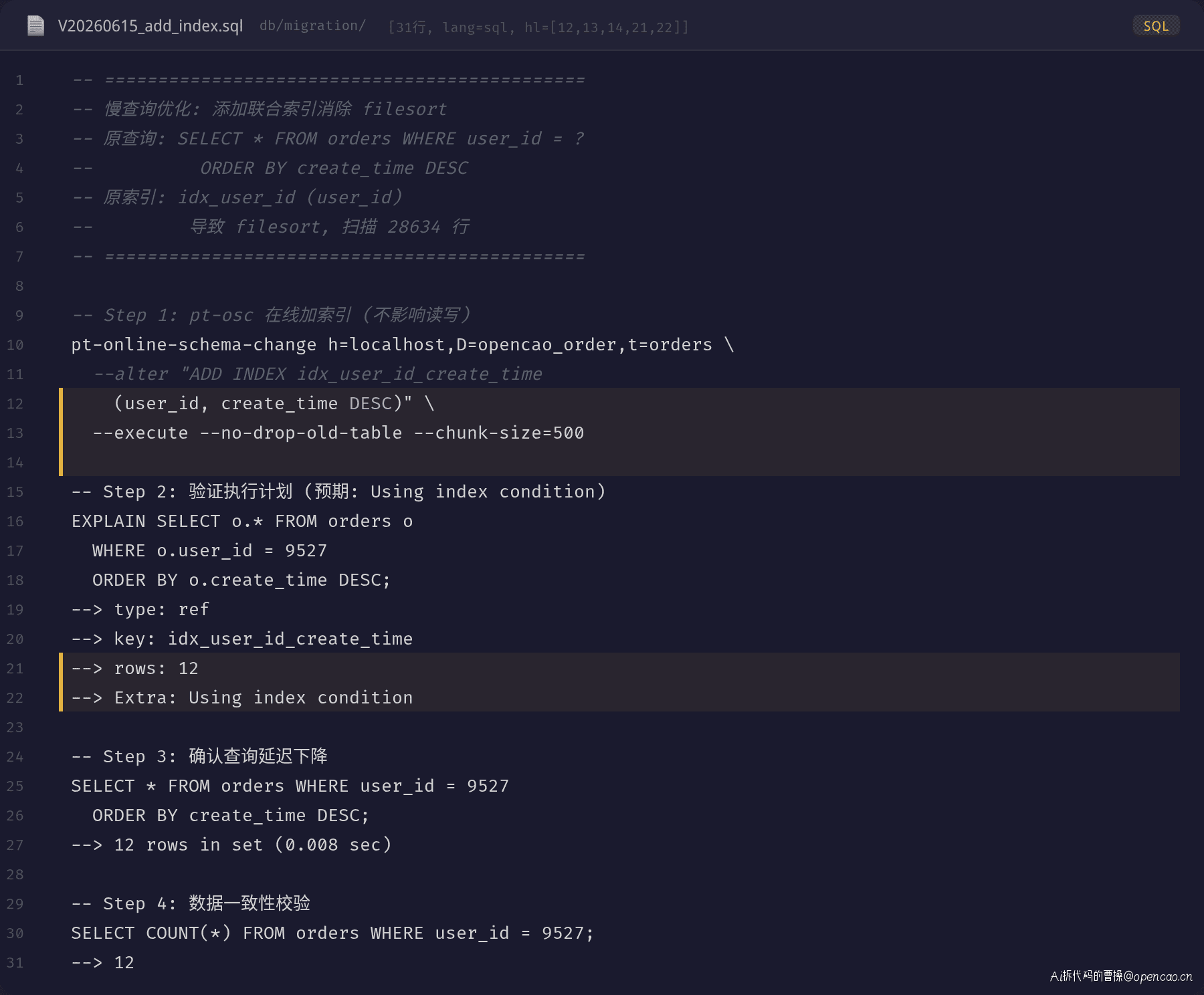
第三梯队(高成本、专项场景):CDN 动态加速需要商务对接和配置调优;服务网格(Sidecar)替换 SDK 方式的全链路追踪则需要架构层的改造。
分层策略的取舍
读完 7 层的拆解,你可能已经注意到:延迟越靠后的层,优化空间越大,但改造成本也越高。DNS 和 TCP 层虽然看起来花了几十毫秒,但缓存和复用几乎免费解决。而数据层从 500ms 优化到 50ms,需要索引设计、缓存引入、甚至分库分表——技术投入量级完全不同。
这也是理解全链路的意义所在:把有限的优化资源投入到收益最大的环节,而不是被"DNS 花了 150ms"这种表面数字牵着走。
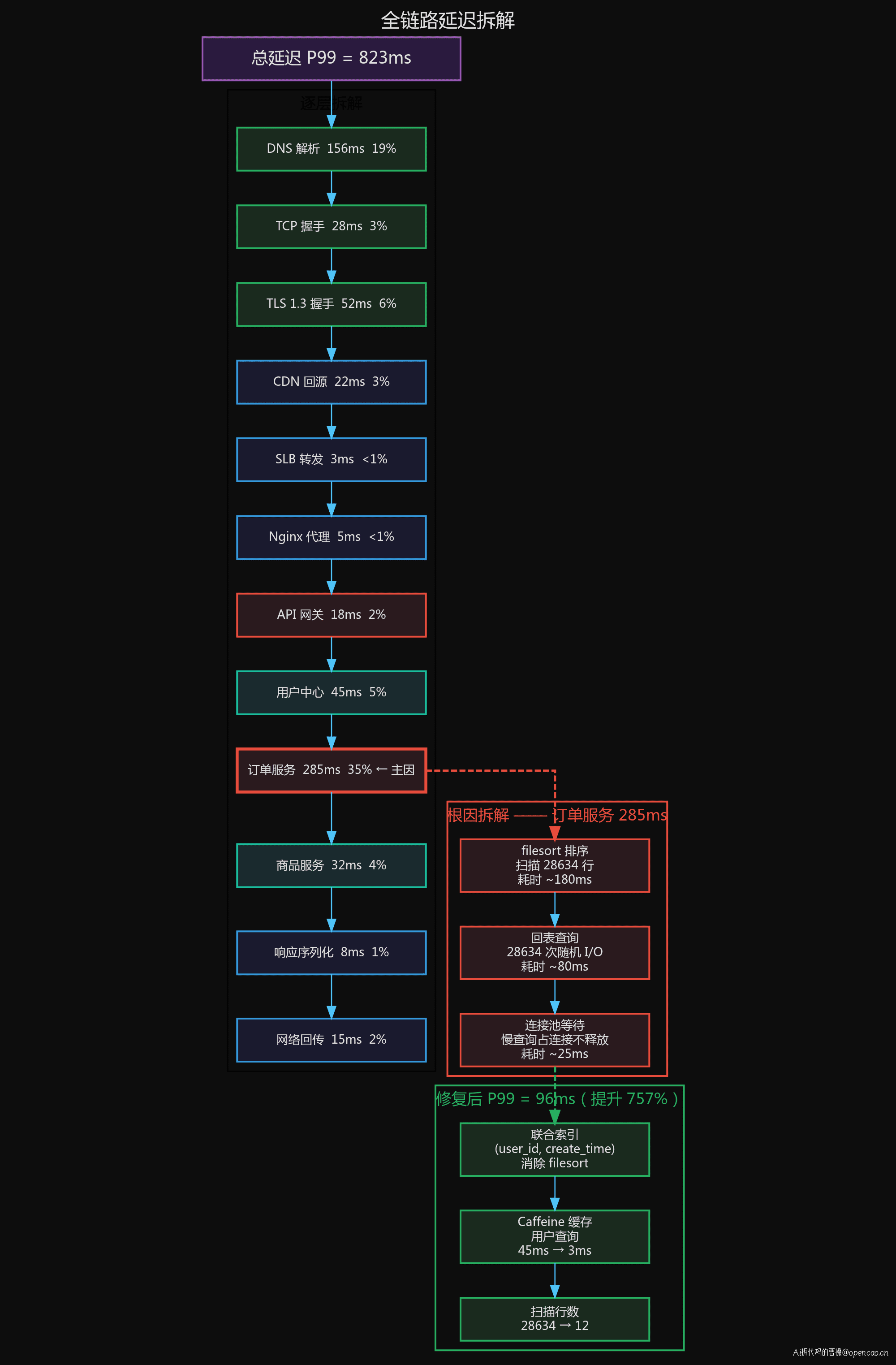
核心认知
贯穿全文的三个核心认知:
1. 分层架构的本质是解耦。 每一层只关心自己的职责——DNS 只管域名解析,Nginx 只管反向代理,网关只管路由鉴权。这种解耦让每层可以独立演进和优化。
2. 延迟的分布是极不均匀的。 DNS 150ms 看似很大,但缓存后为 0。数据层 500ms 才是真正的"大头"。优化要盯着占比最大的环节,而不是最靠前的环节。
3. 理解全链路让你成为更好的工程师。 知道网关过滤器链的存在,你就不会在业务代码里再做一遍鉴权。知道 Nginx 和网关的分工,你就不会把业务路由规则写在 Nginx 配置里。知道 B+ 树索引的排序特性,你写 SQL 时自然会思考联合索引的顺序。
延申阅读
关联知识专题
本文的逐层拆解方式可以延伸到更多方向,如果你对某个层感兴趣,建议按以下路径深入:
DNS 层 → HTTPDNS:本文提到 DNS 解析 150ms 的瓶颈,HTTPDNS 直接通过 HTTPS API 获取 IP,绕过了 Local DNS 的递归开销和潜在的劫持风险。阿里云 HTTPDNS、腾讯云 HTTPDNS 都提供了免费额度,适合移动端 App 优化。
Nginx 层 → epoll 模型:Nginx 之所以能单机支撑数万并发,核心是 epoll 事件驱动 + 异步非阻塞 I/O。相比 Tomcat 的线程池模型(每个连接一个线程),epoll 用一个线程管理数万连接的文件描述符——连接数增加不线性增加资源消耗。这是理解"为什么 Nginx 适合做反向代理层"的底层原因。
MySQL 索引深度 → B+ 树与执行计划:本文的 EXPLAIN 解读只是入门。想真正掌握索引优化,需要理解 B+ 树的层高计算、聚簇索引与二级索引的差异、索引下推(ICP)、Multi-Range Read(MRR)优化机制。这些知识点能帮助你在 SQL 写出来之前就判断出执行效率。
全链路追踪 → OpenTelemetry:Beyond SkyWalking——OpenTelemetry 正成为可观测性的事实标准。它定义了 Trace/Metric/Log 的统一数据模型,支持自动 instrumentation 和多种后端(Jaeger、Zipkin、Prometheus)。
推荐阅读清单
| 领域 | 资源 | 类型 |
|---|---|---|
| 网络 | 《TCP/IP 详解 卷 1》 | 经典书籍 |
| Nginx | 《深入理解 Nginx》(陶辉) | 源码分析 |
| MySQL 索引 | 《数据库索引设计与优化》 | 索引专项 |
| 全链路追踪 | OpenTelemetry 官方文档 | 实践指南 |
| 架构 | 《微服务架构设计模式》(Chris Richardson) | 架构方法论 |


