
Pod 一直 Pending:从资源不足到 PVC 挂载层层排查
本文是 K8s 与云原生故障排查 系列的第 2 篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
告警触发
某日上午,认证服务(auth-service)新版本上线后,SRE 值班群突然弹出告警。
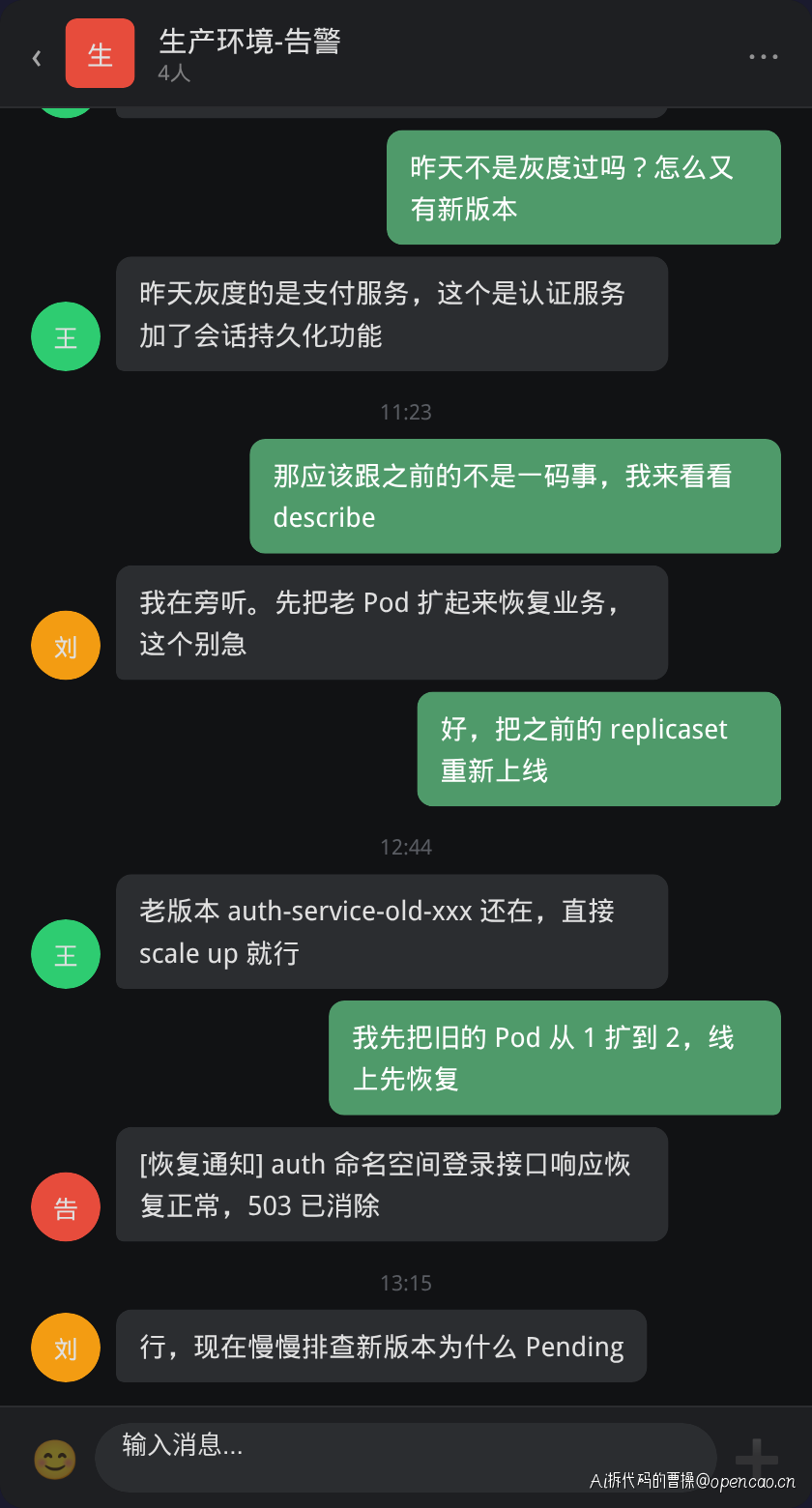
告警显示 auth 命名空间下两个 Pod 持续处于 Pending 状态已达 8 分钟,用户登录接口 /api/auth/login 返回 503。王姐确认是刚上线的认证服务新版本——这次上线新增了会话持久化功能,需要挂载持久卷存储用户会话数据。
张工第一时间将旧的 Pod 重新上线恢复业务,然后开始排查新版本为什么一直 Pending。
上机排查遇阻
张工登录 K8s 集群控制节点,发现 Pod 确实卡在 Pending,且没有被调度到任何节点上。
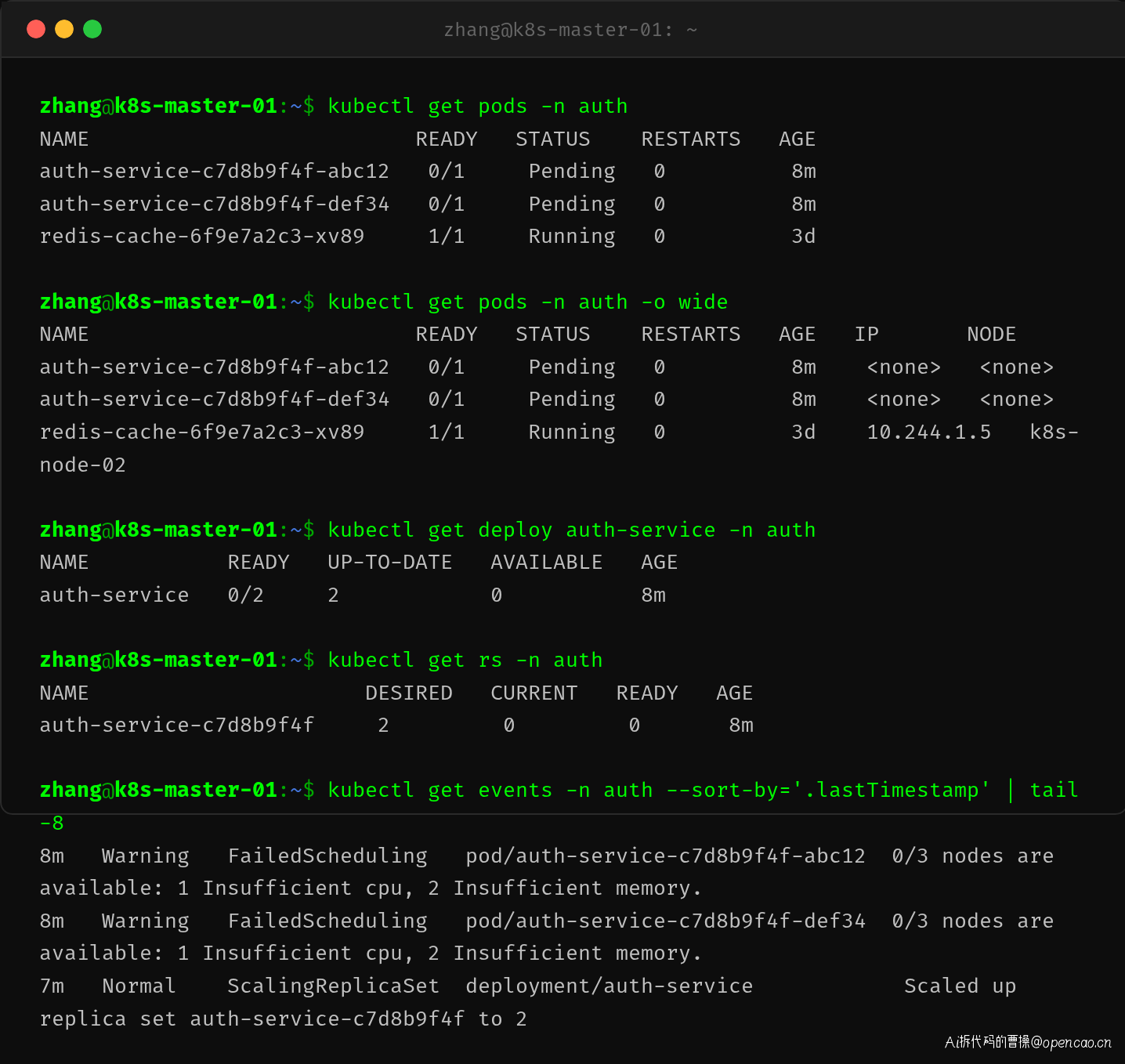
kubectl get pods -o wide 显示两个新 Pod 的 IP 和 NODE 均为 \<none\>,说明调度器(scheduler)尚未完成分配。而 ReplicaSet 的 DESIRED=2 但 CURRENT=0,说明调度器连一个 Pod 都没放出去。
初步猜测
Pod Pending 最常见的原因是资源不足——集群中没有任何一个节点能满足 Pod 申请的 CPU 或内存。也可能涉及节点选择器(nodeSelector)、亲和性(affinity)或污点(taints)配置。张工决定先用 kubectl describe pod 查看具体事件。
排查过程
第一步:查看调度事件,锁定资源不足
Pod Pending 的排查起点永远是 kubectl describe pod。这条命令输出的 Events 字段会记录调度器(scheduler)、kubelet 和 volume controller 在各个阶段发出的关键事件。对于 Pending 状态的 Pod,Events 是唯一能直接定位根因的入口。

describe 输出确认了猜测:FailedScheduling 事件明确指出 0/3 nodes are available: 1 Insufficient cpu, 2 Insufficient memory。
这里的关键信息是: - 3 个节点中,有 1 个 CPU 不足、2 个内存不足 - preemption(抢占)机制没有生效——要么找不到可驱逐的受害者 Pod,要么该 Pod 的优先级不支持抢占
这说明 Pod 申请的资源和集群当前可分配资源之间存在冲突。到底是请求设太高,还是集群确实满载?张工决定查一下节点层面的资源用量。
第二步:查看节点资源,发现请求冲突
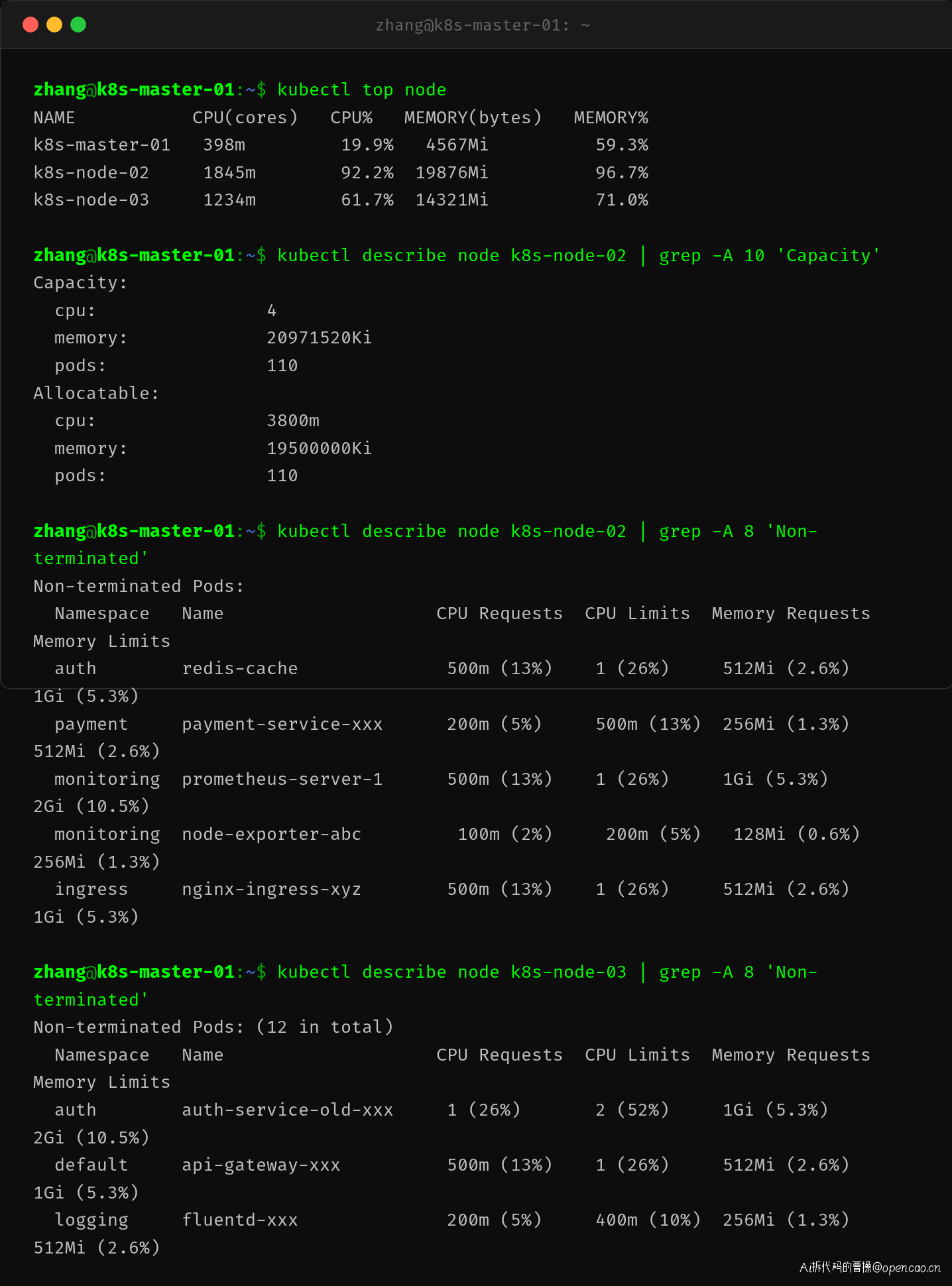
kubectl top node 显示 k8s-node-02 的 CPU 使用率已达 92.2%,内存 96.7%,接近饱和。但问题不仅仅是节点满载这么简单。
通过 kubectl describe node 查看节点已分配资源,可以发现两个关键线索:
- k8s-node-02 上已经运行了 prometheus-server(CPU request 500m)、nginx-ingress(500m)、支付服务(200m)等多个 Pod,
Non-terminated Pods合计的 CPU Requests 已经很接近节点的 allocatable 上限(3800m)。 - k8s-node-03 上运行着 auth-service 的旧版本(CPU request 1,即 1000m),加上其他 Pod 后剩余资源已经不足。
再看新版本的 Deployment 配置:CPU request 设为了 2(2000m)。这意味着新 Pod 需要单核 2 个 CPU 的空闲资源,而集群中三个节点各自剩余的可调度资源都不足以容纳。
第三步:调低资源后仍然 Pending
张工调整了 Deployment 的 CPU request 从 2 降为 500m,重新部署后还是 Pending。
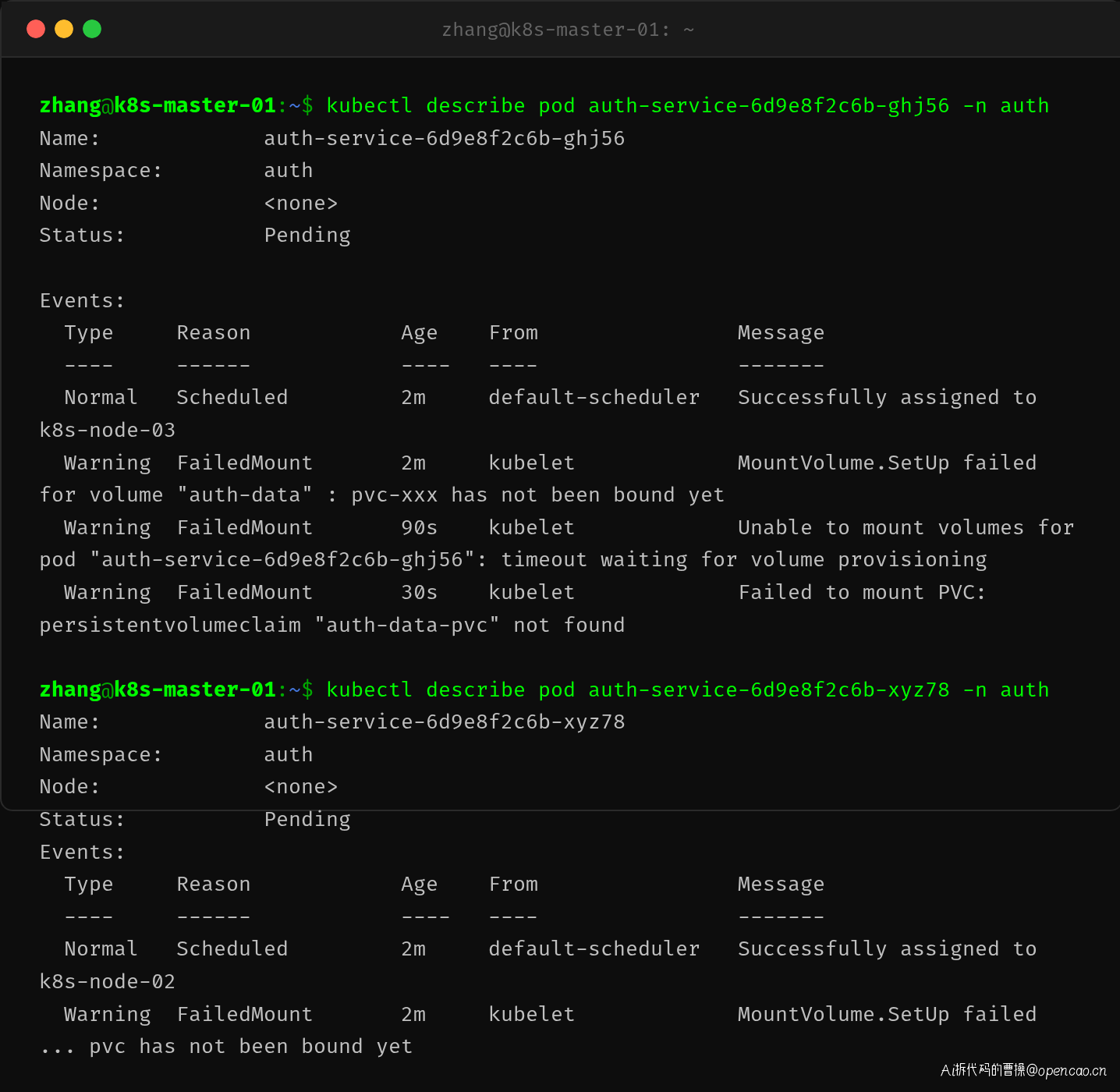
这次 describe 显示的事件发生了变化。Pod 被调度器成功分配到了节点(Scheduled),但 kubelet 在挂载卷的阶段失败了:
MountVolume.SetUp failed for volume "auth-data": pvc-xxx has not been bound yet
Failed to mount PVC: persistentvolumeclaim "auth-data-pvc" not found
这说明 Pod 通过了调度阶段,但在 kubelet 启动容器前挂载 PersistentVolumeClaim 时卡住了。PVC 没有绑定到 PV,导致 Pod 无法继续推进到 Running。
第四步:检查 PVC 和 StorageClass
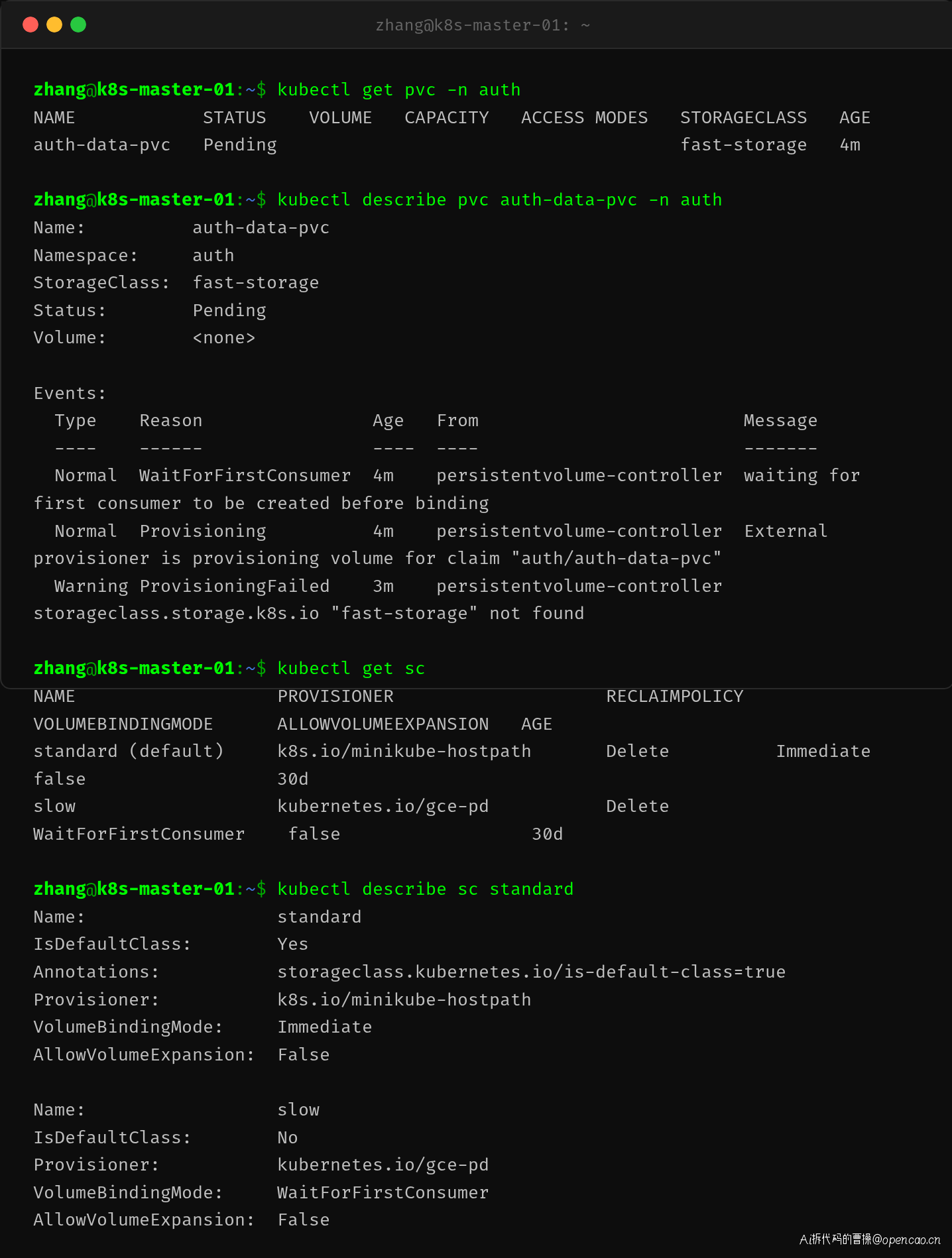
kubectl get pvc -n auth 确认 auth-data-pvc 状态为 Pending。进一步 describe pvc 发现了真正的根因:
Warning ProvisioningFailed: storageclass.storage.k8s.io "fast-storage" not found
PVC 中指定的 storageClassName: fast-storage 在集群中不存在!集群只注册了两个 StorageClass:
- standard(默认,provisioner: k8s.io/minikube-hostpath)
- slow(provisioner: kubernetes.io/gce-pd)
没有 fast-storage 这个 StorageClass,动态存储 provisioner 无法自动创建 PV,PVC 永远卡在 Pending 状态。
第五步:确认 StorageClass 清单
kubectl get sc 确认了集群中的可选 StorageClass。standard 被标记为 (default),slow 使用 GCE 持久化磁盘。
问题本质上是两方面叠加: 1. Deployment 的 CPU request 设得太高(2核),导致调度阶段就失败 2. PVC 引用了一个不存在的 StorageClass,即使调度通过,卷挂载也无法完成
根因分析
子原因一:CPU request 严重偏离基线
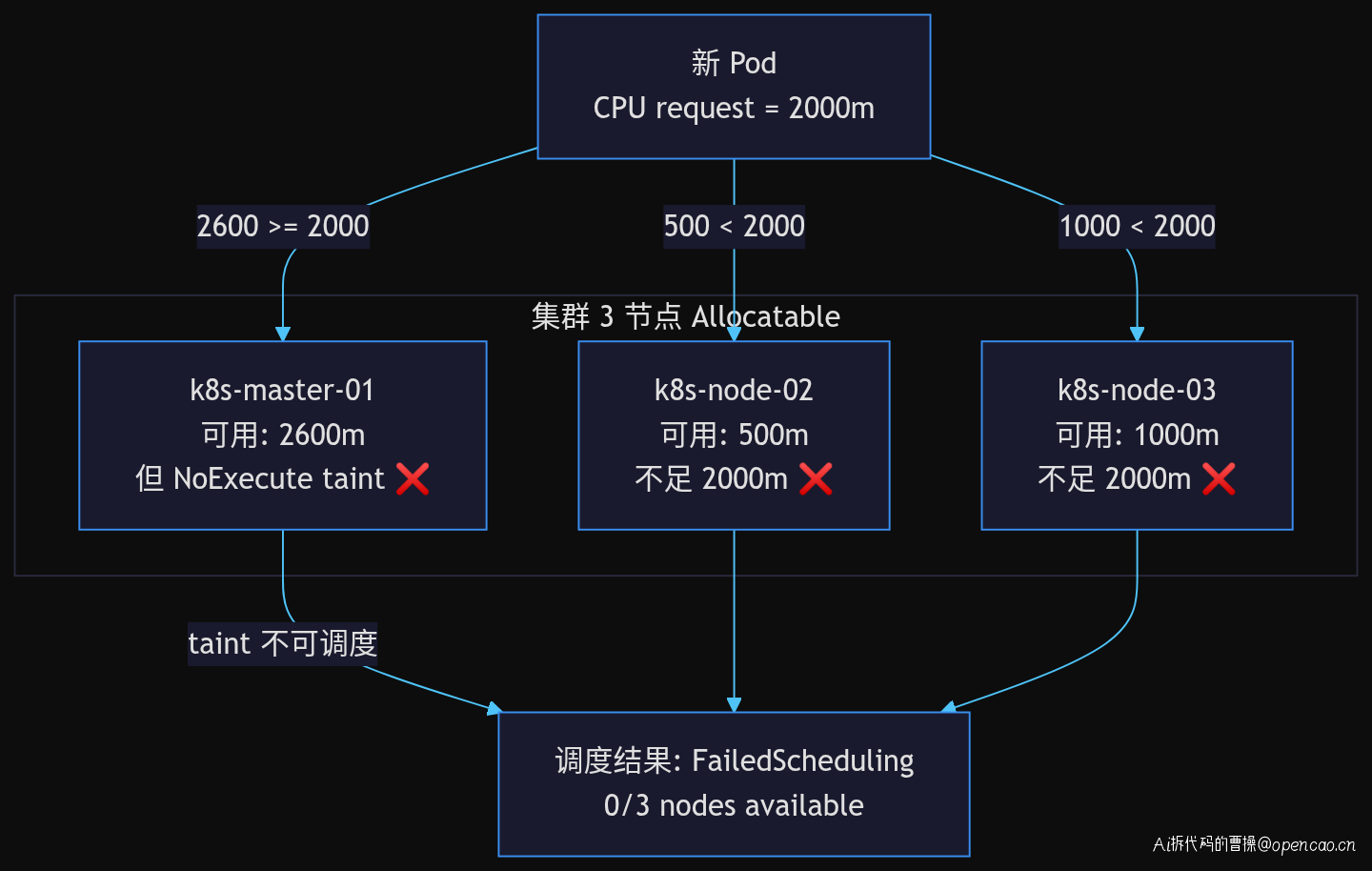
上图清晰展示了 2000m CPU request 与三个节点实际剩余资源的冲突。从修复后的反馈来看,认证服务实际运行时的 CPU 消耗在 200-400m 之间。但新版本 Deployment 中 CPU request 却写死了 2(2000m),远超实际需要。
产生这个偏差的原因是多方面的:
- 缺乏历史监控数据:新版本重构了会话管理模块,团队预估的 CPU 开销偏大
- 未参考旧版本基线:旧版本 auth-service-old 的 request 为 1000m(1核),但这是包括了未优化的缓存逻辑。优化后实际 CPU 消耗下降,request 却反而翻倍
- 资源超分问题:k8s-node-02 的 allocatable CPU 为 3800m,但 Non-terminated Pods 中 CPU Requests 总和已达 3300m(减去系统预留),新 Pod 的 2000m request 完全超出剩余空间
子原因二:Pod 排障只停留在第一层

张工的排查过程揭示了一个典型的排障陷阱:看到 FailedScheduling → 调整资源 → 以为万事大吉。如上图所示,故障链实际上是多层的——修复第一层后,第二层才暴露出来。
Pod Pending 的原因可能层层叠加: - 第一层:调度阶段失败(FailedScheduling) - 第二层:卷挂载阶段失败(FailedMount) - 第三层:镜像拉取失败(ImagePullBackOff) - 第四层:Init 容器执行失败
每次修复一个原因后,Pod 会推进到下一个阶段再卡住。如果只修复第一个错误就认为问题已解决("降了资源应该就好了"),会被表象迷惑。
子原因三:StorageClass 缺乏一致性校验
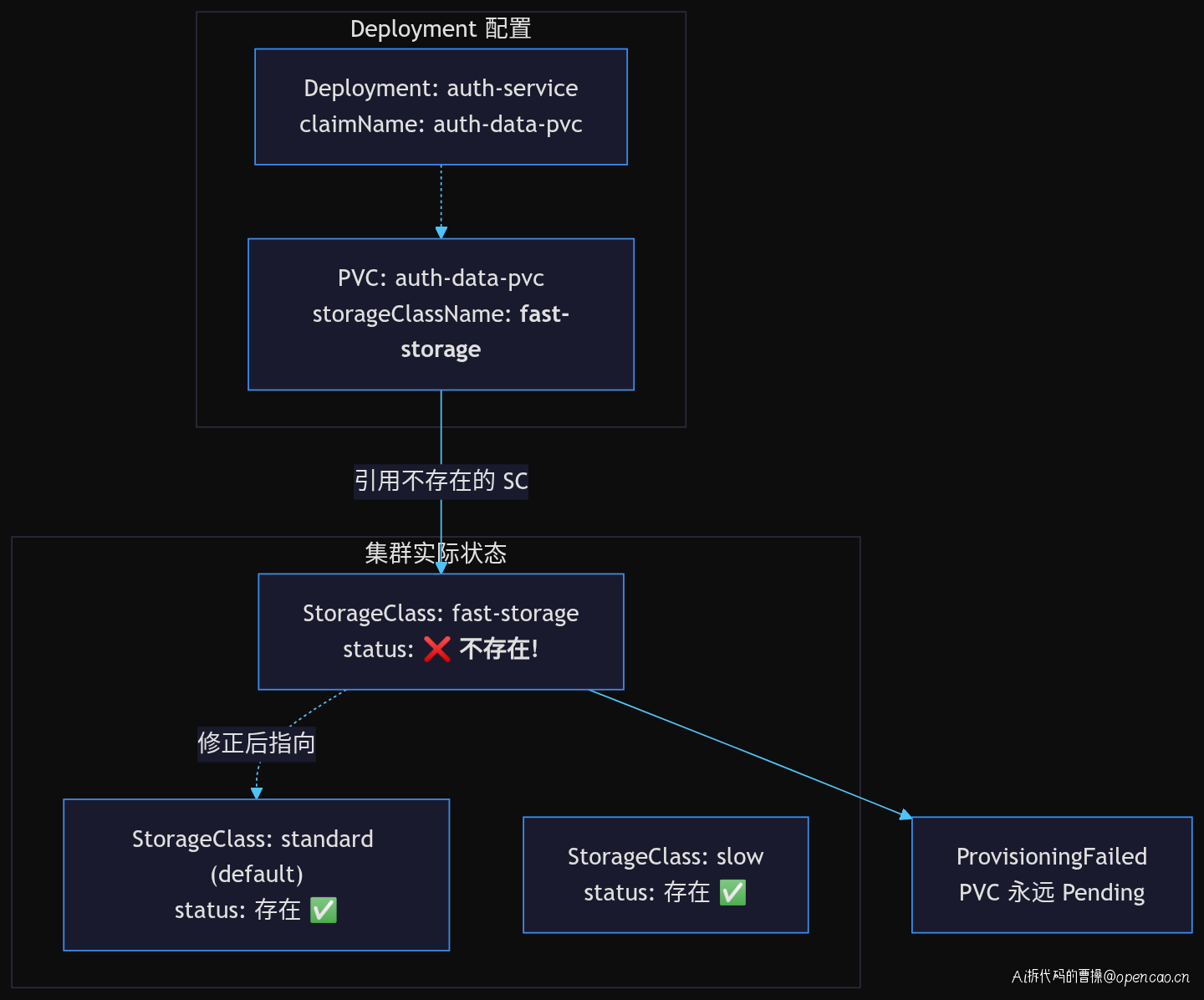
PVC 中引用了一个集群中不存在的 StorageClass fast-storage。进一步追溯发现:
- 方案的评审文档中确实写着 fast-storage
- 集群管理员实际创建的是 standard 和 slow
- 评审到部署之间没有任何自动校验环节
这种"命名不一致"的问题在 K8s 生态中非常常见,因为 Resource 之间的关系是声明式的,K8s 不会在 kubectl apply 时检查引用的 StorageClass 是否存在——它只会在 PVC 真正需要绑定时才报错。
更深层的问题在于,集群中的 standard StorageClass 的 provisioner 是 k8s.io/minikube-hostpath,这是 minikube 自带的轻量级 provisioner。而 fast-storage 原本期望对应的是 SSD 类型的云盘 provisioner(如 pd-ssd.csi.storage.gke.io)。命名背后的语义在评审阶段丢失了——文档写的是"性能目标",而非"实际存在的资源名称"。
累计效应:调度 + 存储组合拳
两个问题叠加的结果是: 1. 即便资源问题修复后 Pod 被调度到了节点,PVC 绑定失败会再次阻滞 2. 排障者看到 FailedScheduling 后容易忽略后续可能出现的 FailedMount 3. 两个问题互不相关,但出现在同一次上线中,排查时间直接翻倍
从时间线上看,资源问题让张工花了约 10 分钟定位和修复,StorageClass 问题又花了 15 分钟。如果一开始就能完整查看 Events 并识别出可能存在多层问题,可以更早地将两部分工作并行——王姐调资源的同时张工检查 PVC 配置。
修复方案
第一步:修正资源限制
将 CPU request 从 2 调低到 500m,memory request 调整为 512Mi,limits 相应下调。
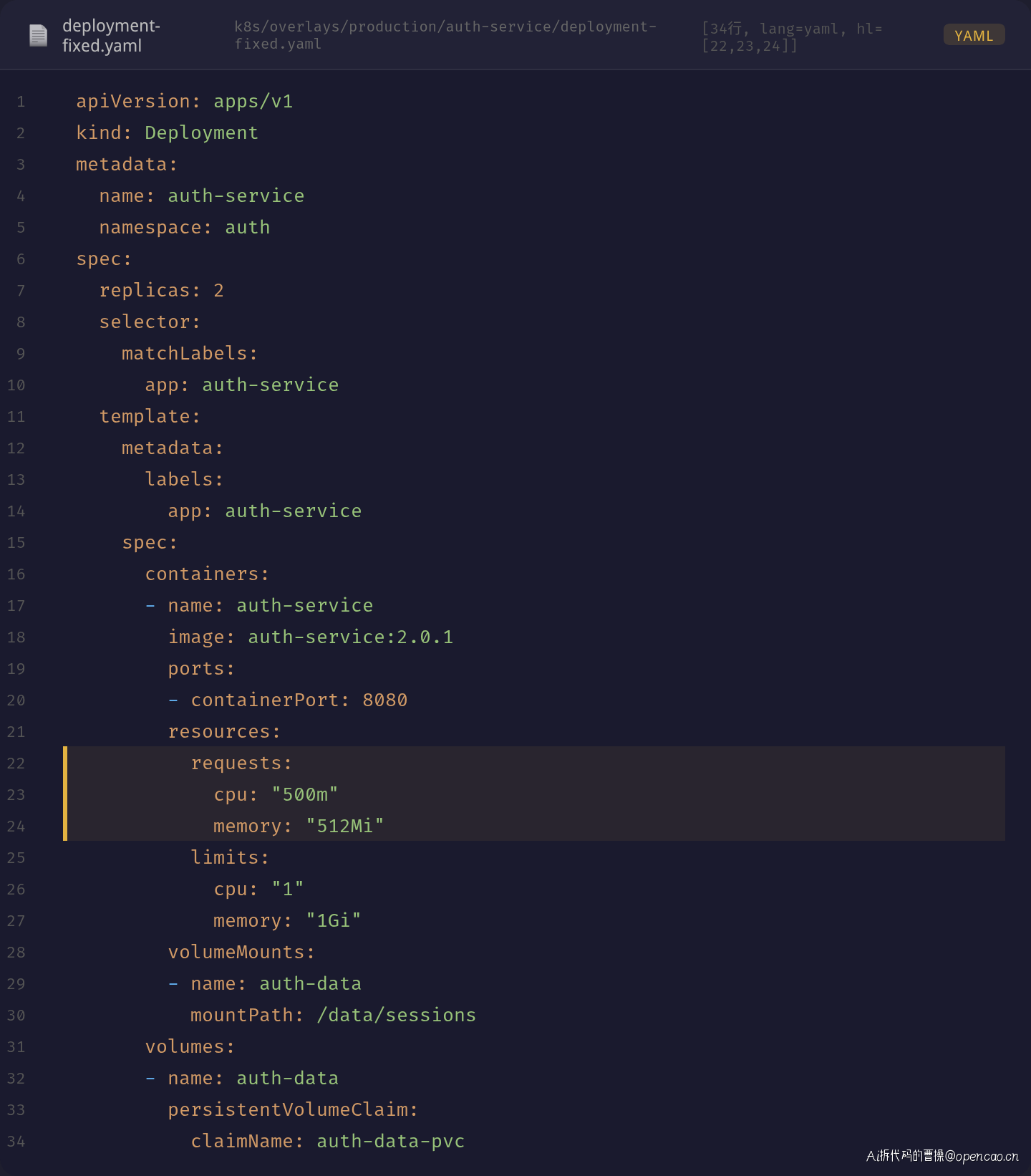
对比有问题的配置:
- ❌ requests.cpu: "2" → 太激进,无节点可容纳
- ✅ requests.cpu: "500m" → 基于旧版本实际用量的合理值
- limits 从 4 核降为 1 核,防止单个 Pod 过度抢占节点资源
第二步:修正 StorageClass
将 PVC 中的 storageClassName 从 fast-storage 改为 standard(集群中实际存在的默认 StorageClass)。
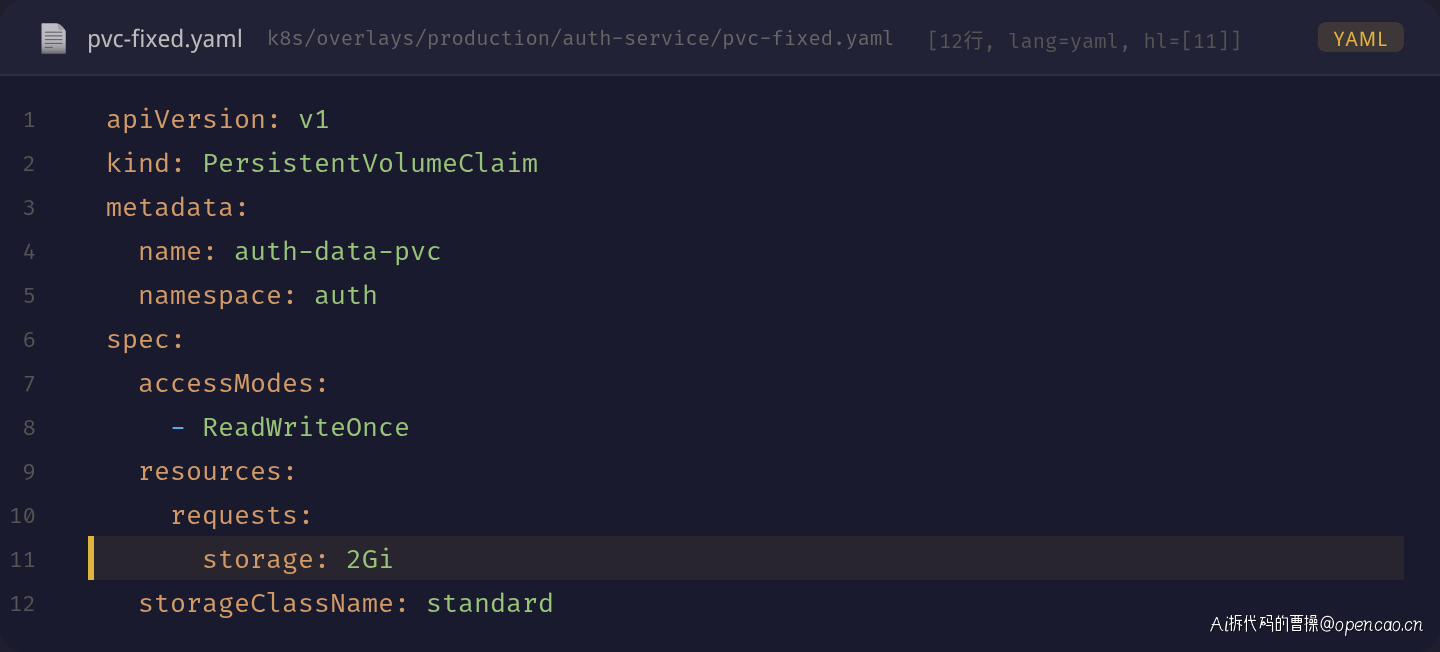
关键变更:
- storageClassName: fast-storage → storageClassName: standard
- 注意:如果集群没有安装动态存储 provisioner,即使 StorageClass 存在也无法自动创建 PV。本例中 standard 的 provisioner 为 k8s.io/minikube-hostpath,支持动态供给
第三步:CI 流水线增加 pre-deploy 校验
为了避免类似问题再次发生,团队在 CI 部署流水线中增加了两步检查:
1. 资源请求合理性校验:对比新版本的 resource request 与旧版本的历史监控数据,偏差超过一定阈值则告警
2. PVC StorageClass 存在性校验:通过 kubectl get sc 获取集群中的 StorageClass 清单,校验所有 PVC 引用的 StorageClass 是否真实存在
验证结果
即时指标:Pod 成功运行
修复后重新部署,两个 Pod 很快进入 Running 状态。
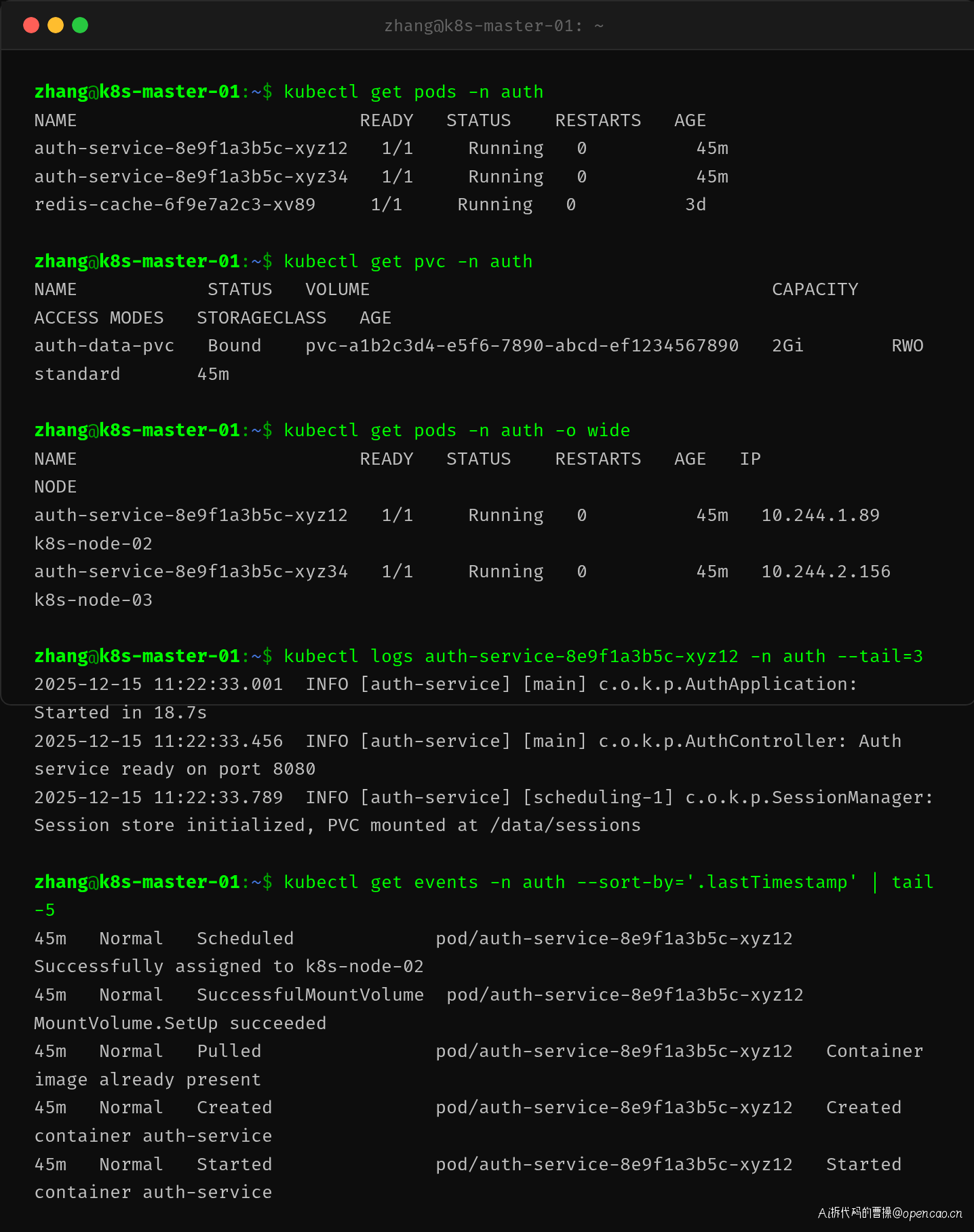
验证指标:
- Pod 状态:1/1 Running,无重启
- PVC 状态:Bound,已成功绑定到 PV
- 应用日志显示 Session store 初始化成功,PVC 挂载路径 /data/sessions 正常
- 登录接口 /api/auth/login 响应正常
持续观察
修复后观察了 45 分钟,两个 Pod 的 CPU 使用稳定在 200-400m 之间,内存使用约 350Mi,远低于设置的 limit(1 核 / 1Gi)。资源设置合理,没有触发 OOM 或 CPU throttling。PVC 的状态也一直保持 Bound,/data/sessions 目录读写正常。
值得注意的一个细节:旧版本 CPU request 为 1000m 时实际只用了 300m 左右,但新版本资源优化后 CPU request 反而翻倍到 2000m——这说明资源评估不能靠"感觉",必须基于监控数据做决策。这次修复后将 request 设为 500m,实际使用 200-400m,留了约 30% 的余量应对流量高峰。
团队复盘
复盘会上,团队总结了这次故障的三个改进点:
1. Resource request 设置必须有基线数据支撑——不能拍脑袋写 cpu: "2"
2. 排查 Pod Pending 时要看全 Events,不能只看第一条错误
3. CI 中预部署检查必须覆盖 PV/PVC/StorageClass 的存在性
刘老师特别指出:集群没有安装动态存储 provisioner 时,PVC 根本不会自动创建 PV——这不是 StorageClass 名字写对就能解决的问题,需要先确认集群的存储基础设施。
避坑建议
- Resource request 参考历史基线:不要靠估算设置 request/limit。从 Prometheus 取过去 7 天的实际用量,取 P95 或 P99 作为 request 基线,再乘以安全系数
- Pod Pending 排查要看全 Events:
kubectl describe pod的 Events 字段可能包含多个阶段的问题。修完第一个 Event 后重新 describe,确认没有新的错误 - PVC 引用的 StorageClass 必须事前确认:在 YAML 提交 PR 之前,先确认目标集群中是否存在对应的 StorageClass
- 区分 scheduling 和 mounting 阶段:Pod 从 Pending 到 Running 要经过调度→拉镜像→挂载卷→启动容器等多个阶段。先用
kubectl describe确认卡在哪个阶段 - 动态存储 provisioner 不是默认存在的:minikube 集群自带 hostpath provisioner,但云厂商或自建集群可能需要额外安装 CSI 驱动。确认集群的存储能力后再写 PVC
- Node Allocatable ≠ Node Capacity:节点上有系统预留(kube-reserved/system-reserved),实际可调度资源小于 Capacity。
kubectl describe node的 Allocatable 才是真正可用的值 - CPU request 影响调度,limit 影响 throttling:区分两者的作用。request 高导致调度失败,limit 高会导致节点超分和 CPU 竞争
- Deployment 更新策略和资源不足的交互:滚动更新时,旧 Pod 销毁和新 Pod 创建可能有短暂重叠,如果集群资源紧张,新 Pod 可能 pending 更长时间。考虑用
maxSurge: 0先停旧再启新
附:Pod Pending 排查流程图
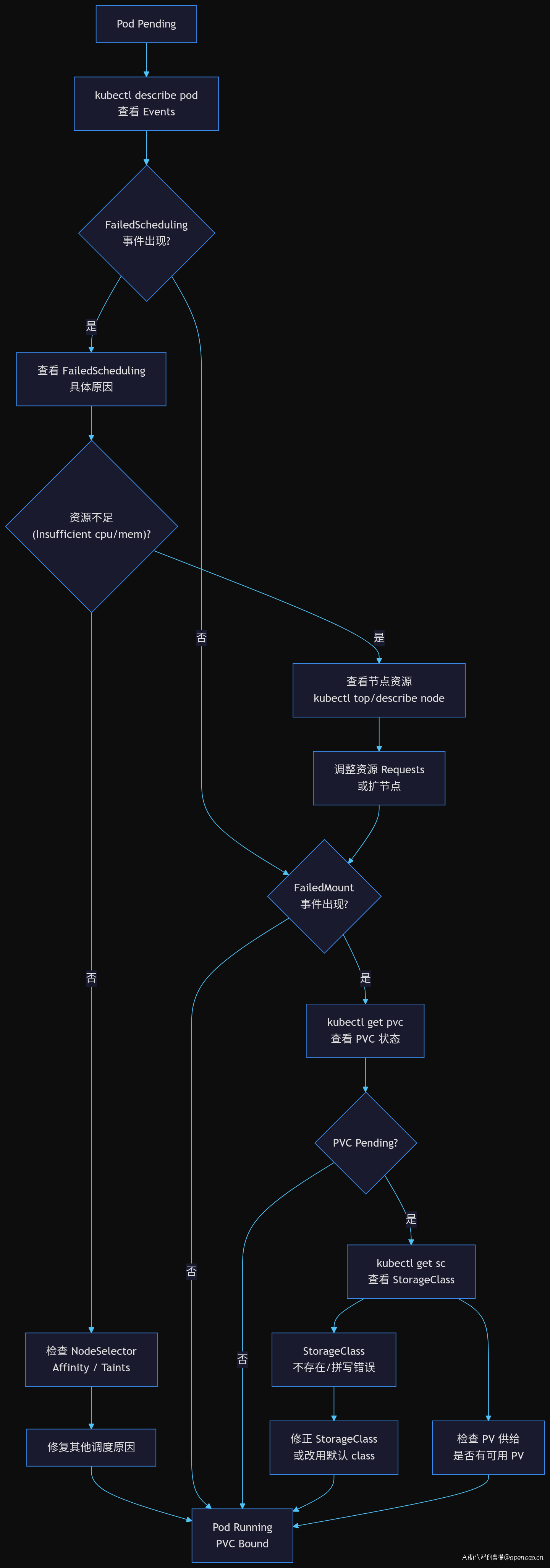
这个决策树覆盖了从 FailedScheduling 到 PVC 挂载的逐层排查路径,遇到 Pod Pending 时可以按图索骥。
附:完整命令清单
# 1. 查看 Pod 状态
kubectl get pods -n auth
kubectl get pods -n auth -o wide
# 2. 查看调度事件
kubectl describe pod auth-service-c7d8b9f4f-abc12 -n auth
# 3. 查看节点资源
kubectl top node
kubectl describe node k8s-node-02 | grep -A 10 'Capacity'
kubectl describe node k8s-node-02 | grep -A 8 'Non-terminated'
# 4. 卷挂载阶段的 events
kubectl describe pod auth-service-6d9e8f2c6b-ghj56 -n auth
# 5. 查看 PVC 状态
kubectl get pvc -n auth
kubectl describe pvc auth-data-pvc -n auth
# 6. 查看 StorageClass
kubectl get sc
kubectl describe sc standard
# 7. 查看 Deployment 配置
kubectl get deploy auth-service -n auth -o yaml
# 8. 查看 ReplicaSet
kubectl get rs -n auth
# 9. 查看 Events
kubectl get events -n auth --sort-by='.lastTimestamp'
# 10. 应用修复后的配置
kubectl apply -f deployment-fixed.yaml
kubectl apply -f pvc-fixed.yaml
# 11. 验证修复
kubectl get pods -n auth
kubectl get pvc -n auth
kubectl logs auth-service-8e9f1a3b5c-xyz12 -n auth --tail=5
# 12. 检查集群 storage provisioner
kubectl get storageclass
kubectl get pods -n kube-system | grep provisioner


