
线程池配太大,上下文切换成了CPU隐形杀手
本文是 Linux 系统排查基本功系列的第 2 篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
告警触发
某日上午 10 点 40 分,Prometheus 告警机器人向 SRE 值班群推送了一条告警:订单服务 order-svc-07 的接口耗时 p99 从 45ms 突然飙升至 320ms。几乎同时,另一条告警显示该节点的 CPU system 占用率达到了 58.7%,user 仅 33%,总 CPU 占用超过 92%。更值得注意的是一条关联告警——系统上下文切换(context_switches)达到 143,712/s,而基线只有 22,000/s,升高了 6.5 倍。
值班团队立刻响应,张工登录服务器开始排查。
上机排查遇阻
张工 SSH 登入 order-svc-07 后,第一件事就是执行 vmstat 1 5 查看系统状态:
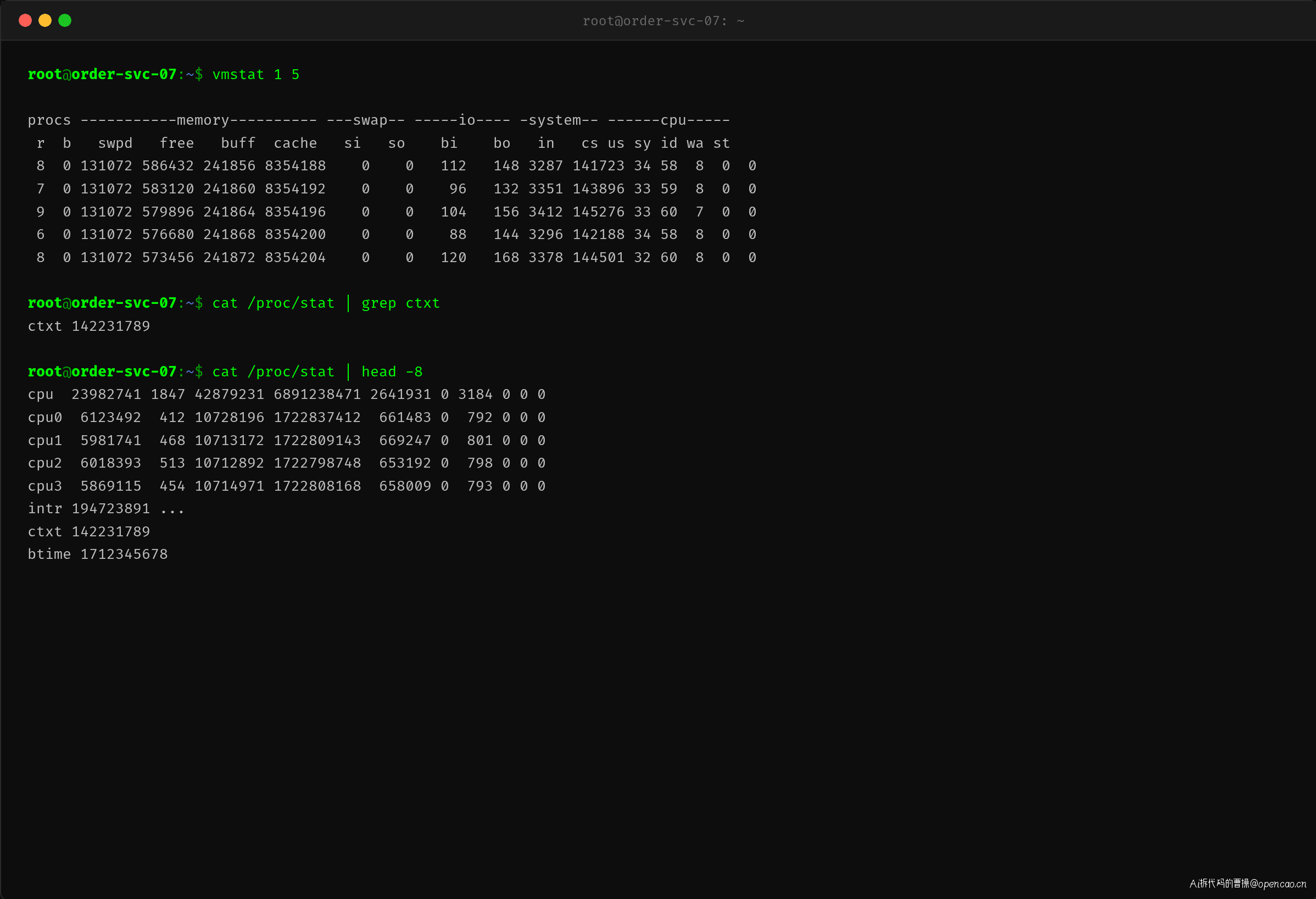
输出立刻暴露了问题:cs(context switches)列稳定在 141,000-145,000/s,这远远超出正常范围。一台 8 核服务器每秒 14 万次上下文切换,意味着每个 CPU 每秒钟要切换 17,500 多次,即每 57 微秒就要切一次。与此同时,sy(system)列高达 58-60%,说明 CPU 有近六成的时间花在内核态(调度、锁管理、系统调用),而非业务代码。
接着查看 /proc/stat 确认了 ctxt 总量已经达到 1.42 亿次,这些都是从系统启动以来累计的上下文切换次数。结合 sar -w 的历史数据可以判断,这个趋势是从当天上午 10:30 左右开始恶化的。
初步猜测
张工的第一判断是:要么是某个进程 fork 了大量短时子进程,要么是 Java 服务内部线程数过多导致调度器不堪重负。王哥这时确认了上午 10:30 刚上线了新版本,主要变更就是放大了 Tomcat 和业务线程池的参数。
排查过程
第一步:定位上下文切换来源
操作动机:vmstat 已经暴露了系统级上下文切换异常高,但 vmstat 看不到每个进程的贡献。需要按进程细看,才知道是哪个应用在制造大量切换。
用 pidstat -w 按进程查看上下文切换次数:
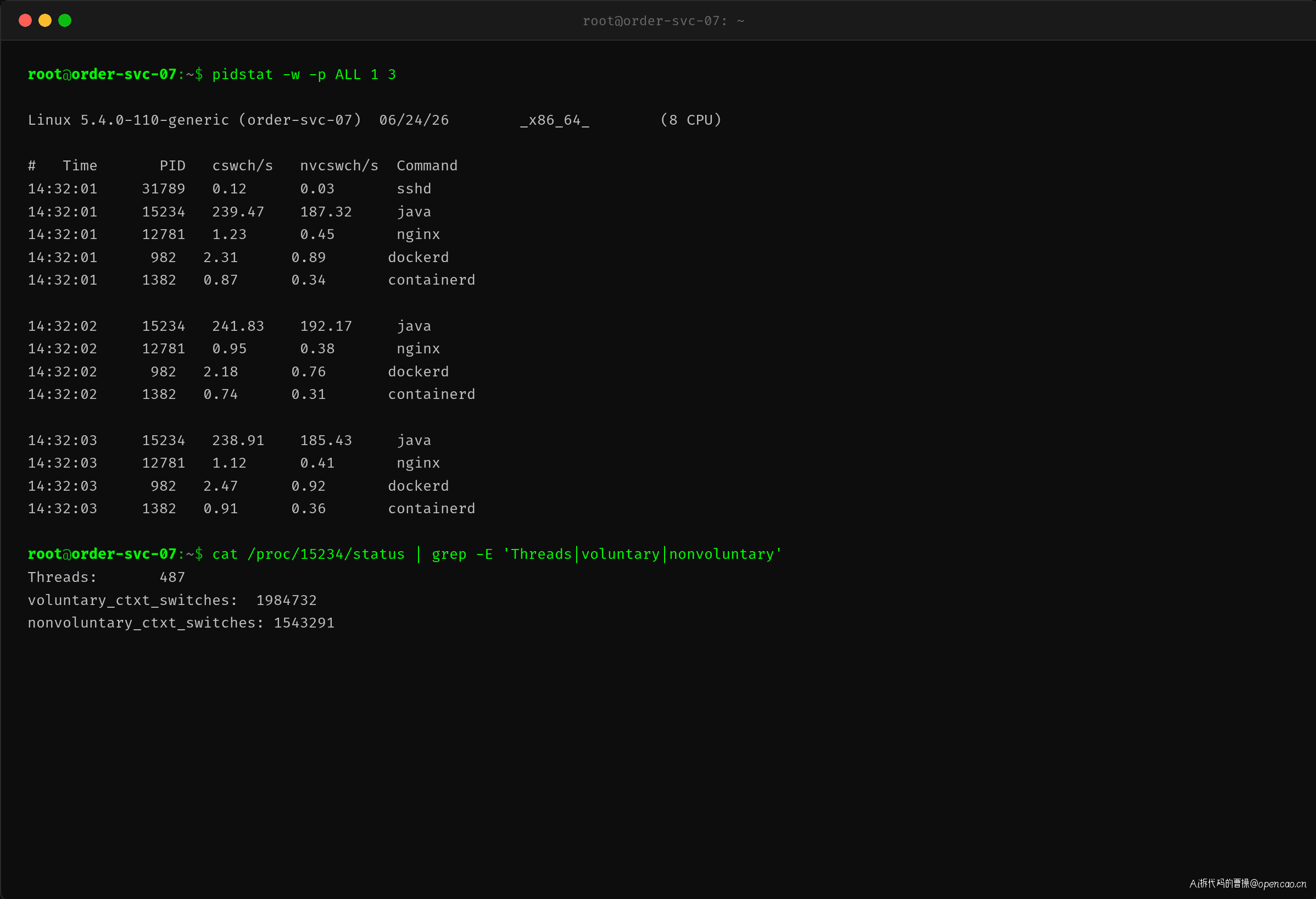
输出解读:cswch/s 是自愿上下文切换(主动让出 CPU,如等待锁或 IO 完成),nvcswch/s 是非自愿切换(时间片耗尽被调度器强制换出)。Java 进程 PID 15234 的自愿切换达到 239/s,非自愿切换达到 187/s。对比同一台机器的 nginx(cswch/s 不超过 1.2),差异悬殊。说明这个 Java 进程内部线程数极多、锁竞争极其激烈。
结论推导:非自愿切换 187/s 远超自愿切换的一半,意味着线程之间的 CPU 争抢非常激烈——每个线程分到的时间片过短,还没干完活就被迫让出 CPU。这是典型的 oversubscription 特征。
查看 /proc/15234/status 确认了问题所在:该 Java 进程创建了 487 个线程。对于一个只有 8 核的服务器来说,487 个线程同场竞技,调度器每秒要在它们之间做几百次选择和后文切换。
第二步:从 perf 看 CPU 到底花在哪
既然确认了 Java 进程是上下文切换的源头,接下来用 perf top 看 CPU 热点分布:
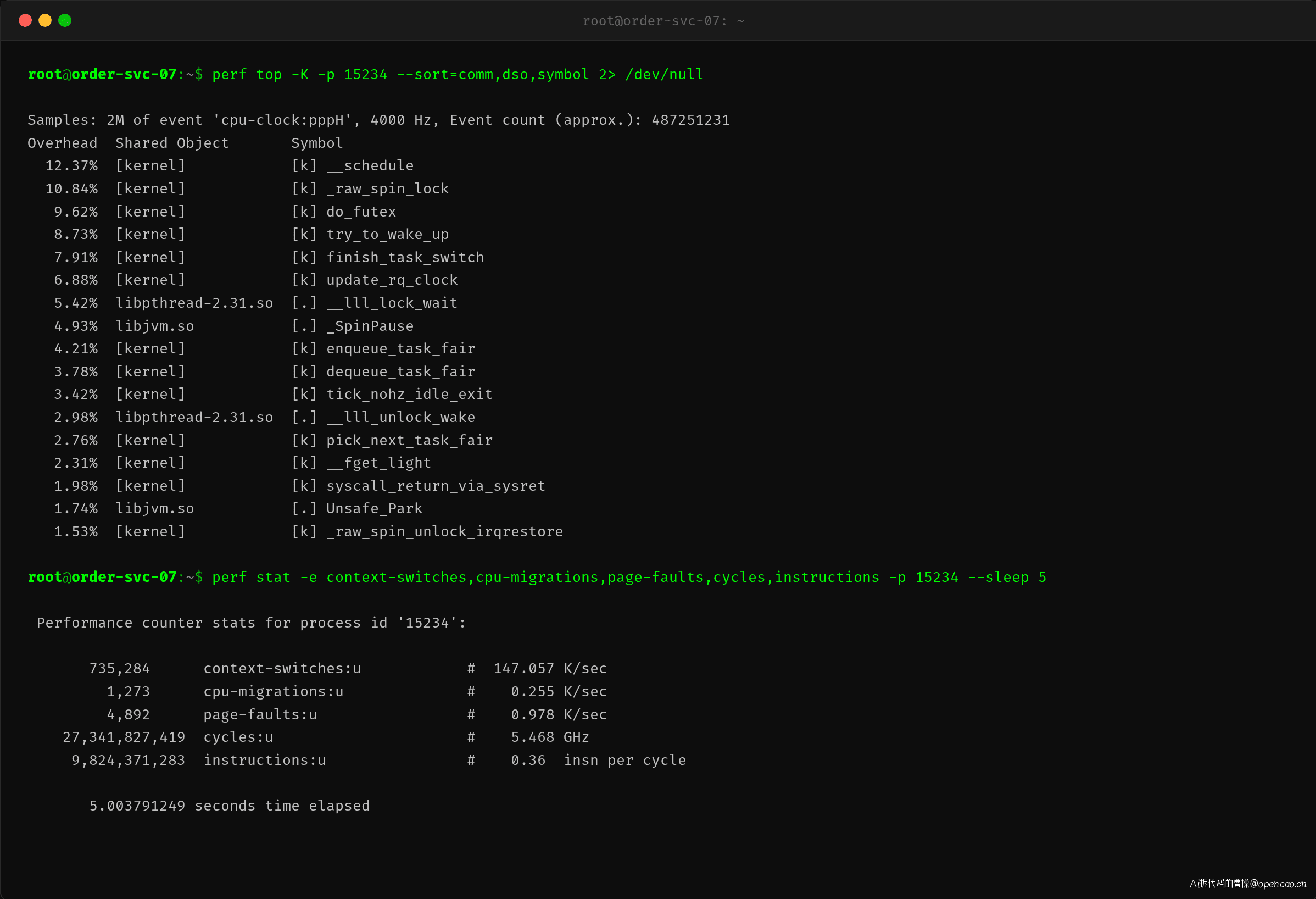
结果非常典型:
| 排名 | 函数 | CPU占比 | 含义 |
|---|---|---|---|
| 1 | __schedule |
12.4% | 调度器主函数,每次进程切换的核心入口 |
| 2 | _raw_spin_lock |
10.8% | 自旋锁竞争,大量线程在抢锁 |
| 3 | do_futex |
9.6% | 用户态锁(Java synchronized/ReentrantLock)的底层实现 |
| 4 | try_to_wake_up |
8.7% | 唤醒等待线程,每次 unparl/unlock 触发 |
| 5 | finish_task_switch |
7.9% | 切换完成的收尾工作 |
perf stat 还暴露了一个关键数据:每指令周期比(instructions per cycle)只有 0.36。正常 CPU 密集型的 IPC 应该在 1.5-2.0 左右,0.36 说明 CPU 大量时间在停滞等待(cache miss、TLB miss、分支预测失败),而这些恰好是上下文切换的后遗症。
第三步:追查历史基线
用 sar -w 看上下文切换的时序趋势:
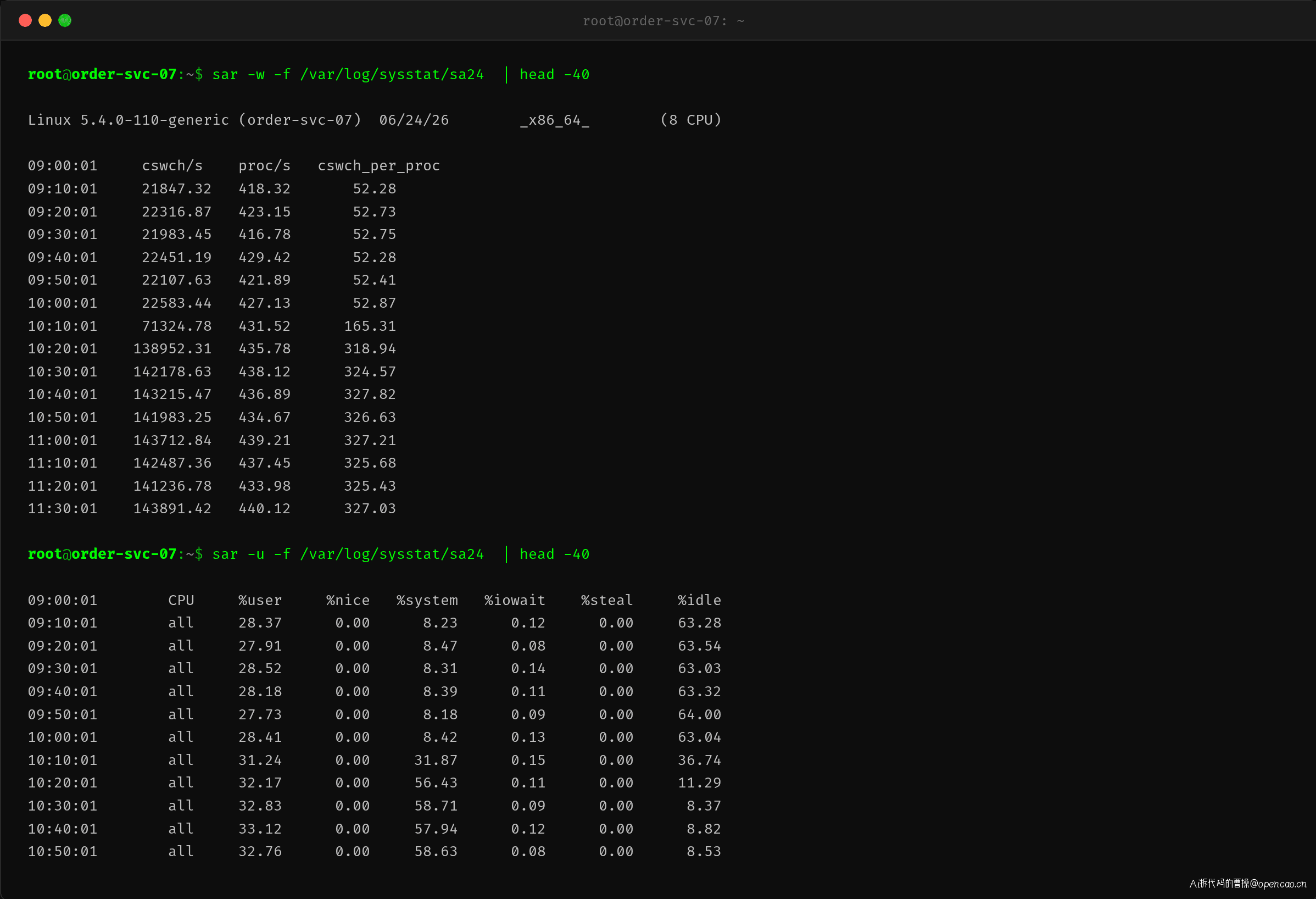
从数据可以清楚看到:10:10 之前,系统上下文切换稳定在 22,000/s 左右,CPU system 不到 9%。10:10 开始 cs 跳到 71,000/s,10:20 之后稳定在 141,000-143,000/s。CPU system 也从 8% 一路升到 58%。这个时间点与王哥的上线时间完美吻合。
第四步:代码审查确认配置问题
回到代码层面,王哥展示了这次上线的线程池配置变更:
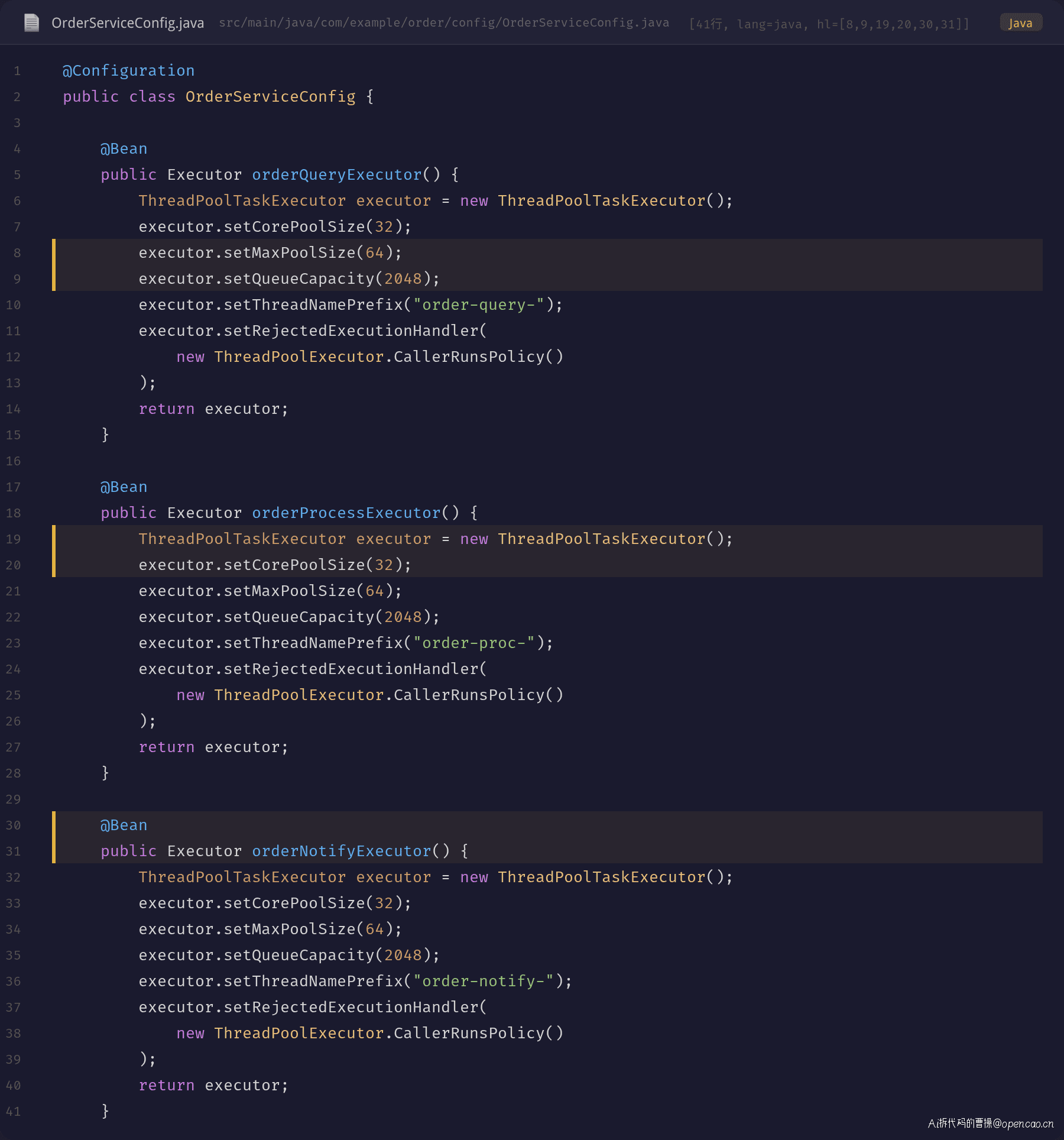
问题一目了然:三个独立的业务线程池(orderQueryExecutor、orderProcessExecutor、orderNotifyExecutor),每个都配了 core=32、max=64、queue=2048。加上 Tomcat 的 max-threads=500,总线程数上限达到 500 + 3×64 = 692 个。
但机器只有 8 个 CPU 核。
根因分析
子原因 1:调度器过载——每秒 14 万次切换的数学
先算一笔经济账。pidstat 显示 Java 进程每秒产生 239+187=426 次切换。但 vmstat 显示系统总切换是 143,000/s。为什么呢?因为 vmstat 统计的是全系统所有线程的切换,包括内核线程(ksoftirqd、kworker、migration)、Java 进程内部的 487 个线程相互切换、以及其他守护进程。Java 进程的 426 次/s 是针对该进程汇总后的净切换,而内核每 tick(通常 250Hz/4ms)就有一次调度器 tick,各种内核线程也在不断相互切换。
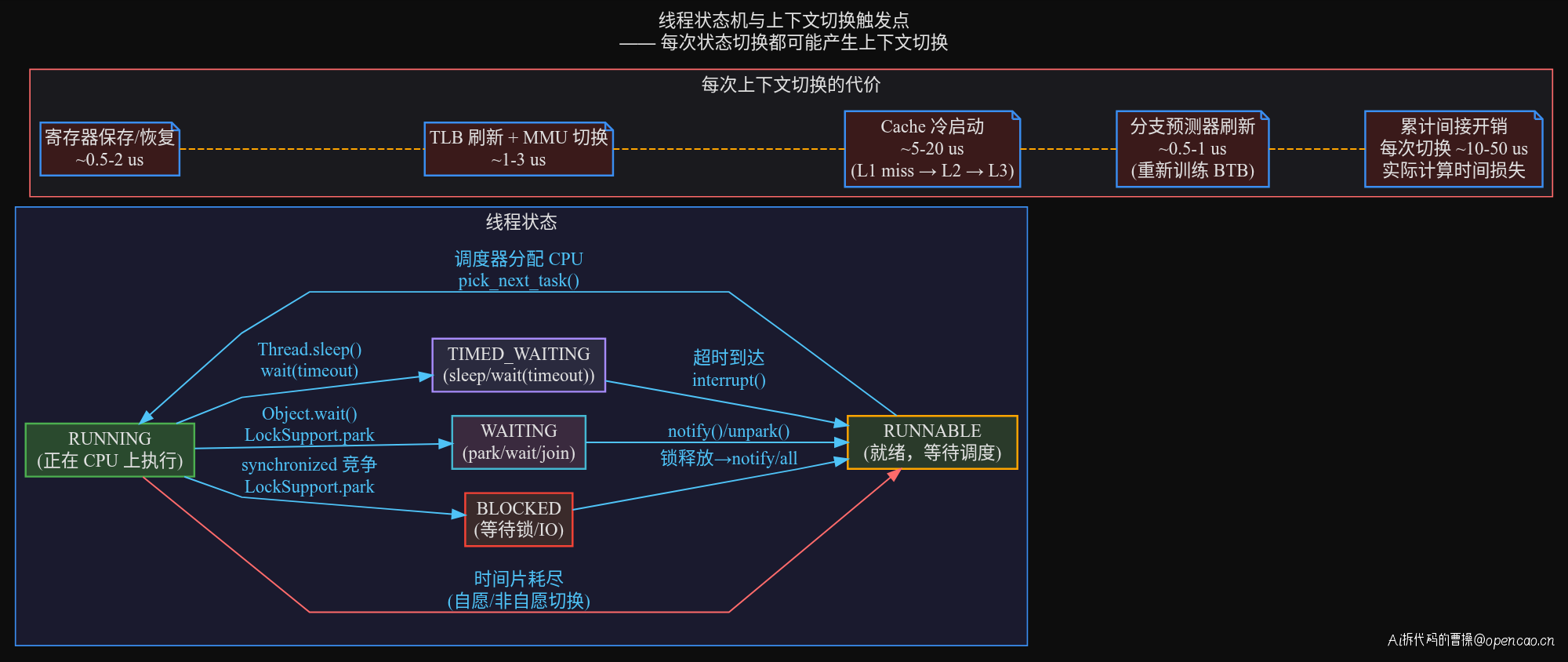
每次上下文切换的成本包含两部分,理解这两部分的区别对于评估性能影响至关重要:
直接成本(约 3-10 us),这部分是 CPU 显性耗时:
- 保存当前线程的寄存器(PC、SP、通用寄存器)到 PCB(Process Control Block)
- 切换 MMU 页表(写入 CR3 寄存器,x86 架构下约 500-800 cycles)
- TLB 刷新——Translation Lookaside Buffer 全部失效,后续所有内存访问都要走页表遍历
- 加载新线程的寄存器状态
- 执行 finish_task_switch 收尾,更新调度统计
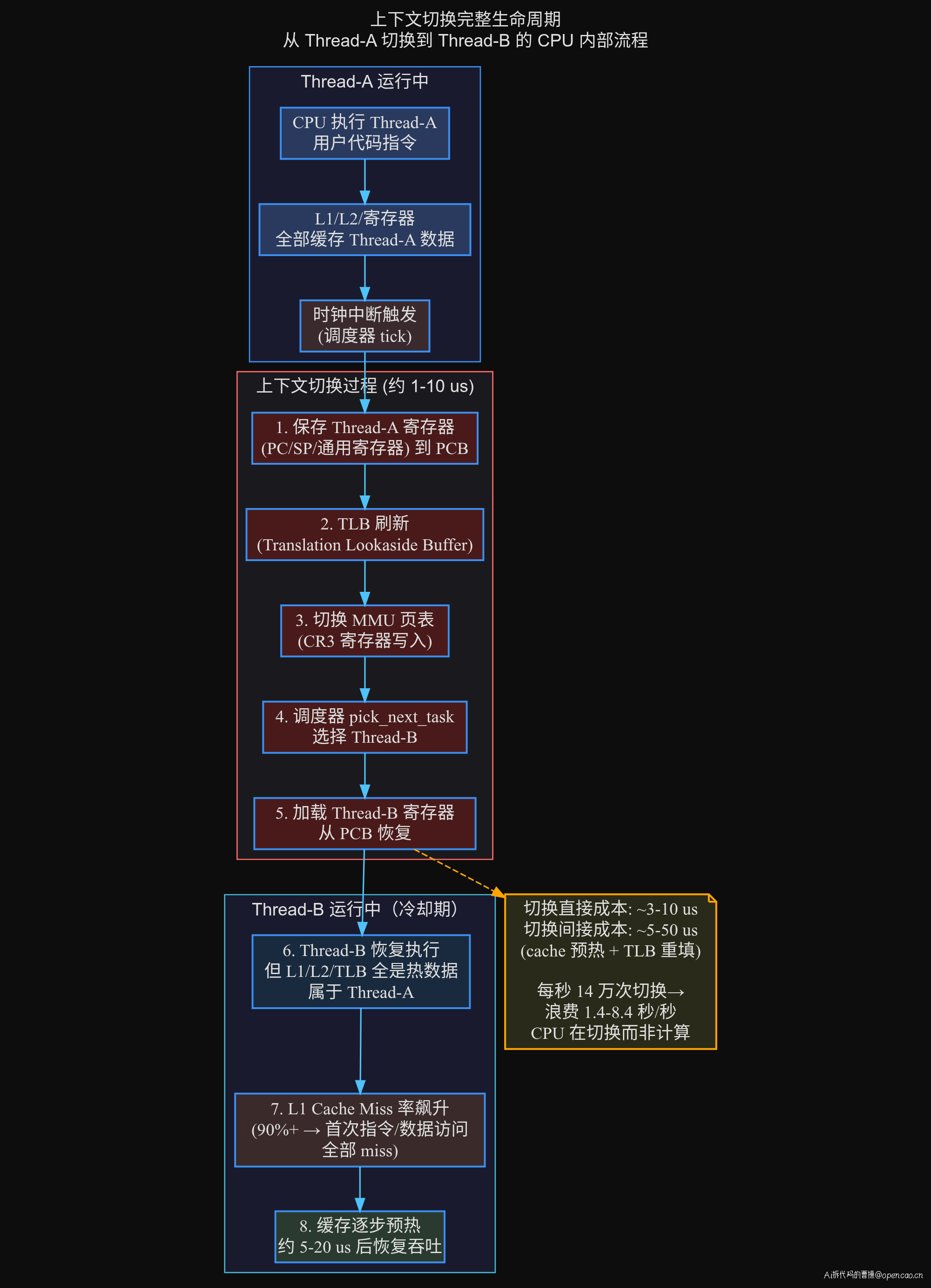
间接成本(约 10-50 us,远超直接成本),这部分是 CPU 隐形成本: - L1/L2/L3 cache 冷启动:线程被换出后,其热数据在 cache 中被其他线程逐步覆盖。当线程再次被调度回来时,L1 指令 cache miss 率从接近 0% 飙升到 50-80%,因为上次缓存的指令和数据已经被新线程冲刷掉了 - TLB 刷新后,旧进程的大量虚拟地址到物理地址映射关系丢失,随后的内存访问需要逐条重新建立页表缓存 - 分支预测器(BTB)需要重新训练——分支预测表存储的是前一个线程的分支历史,新线程的代码路径完全陌生
需要注意的是,现代 CPU(如 Intel Skylake 及之后)通过 PCID(Process Context Identifier)技术部分缓解了 TLB 刷新的开销——切换时可以保留全局页表项。但 L1/L2 cache 的冷却问题仍然存在,因为 cache 是物理寻址的,不区分进程。这也是为什么上下文切换的间接成本通常比直接成本高 3-5 倍。
每秒 143,000 次切换 × 平均每次 15 us(保守估计)= 2,145,000 us = 2.145 秒/秒。也就是说,CPU 每秒有超过 2 秒花在了上下文切换本身(多核并行分摊后,单核视角放大了这个效应)。
下面这张图展示了一次完整上下文切换的 CPU 内部流程:
子原因 2:锁竞争与 Futex 风暴
从 perf top 中看到 do_futex 占了 9.6%,_raw_spin_lock 占了 10.8%。这两个数据揭示了锁竞争的严重性。
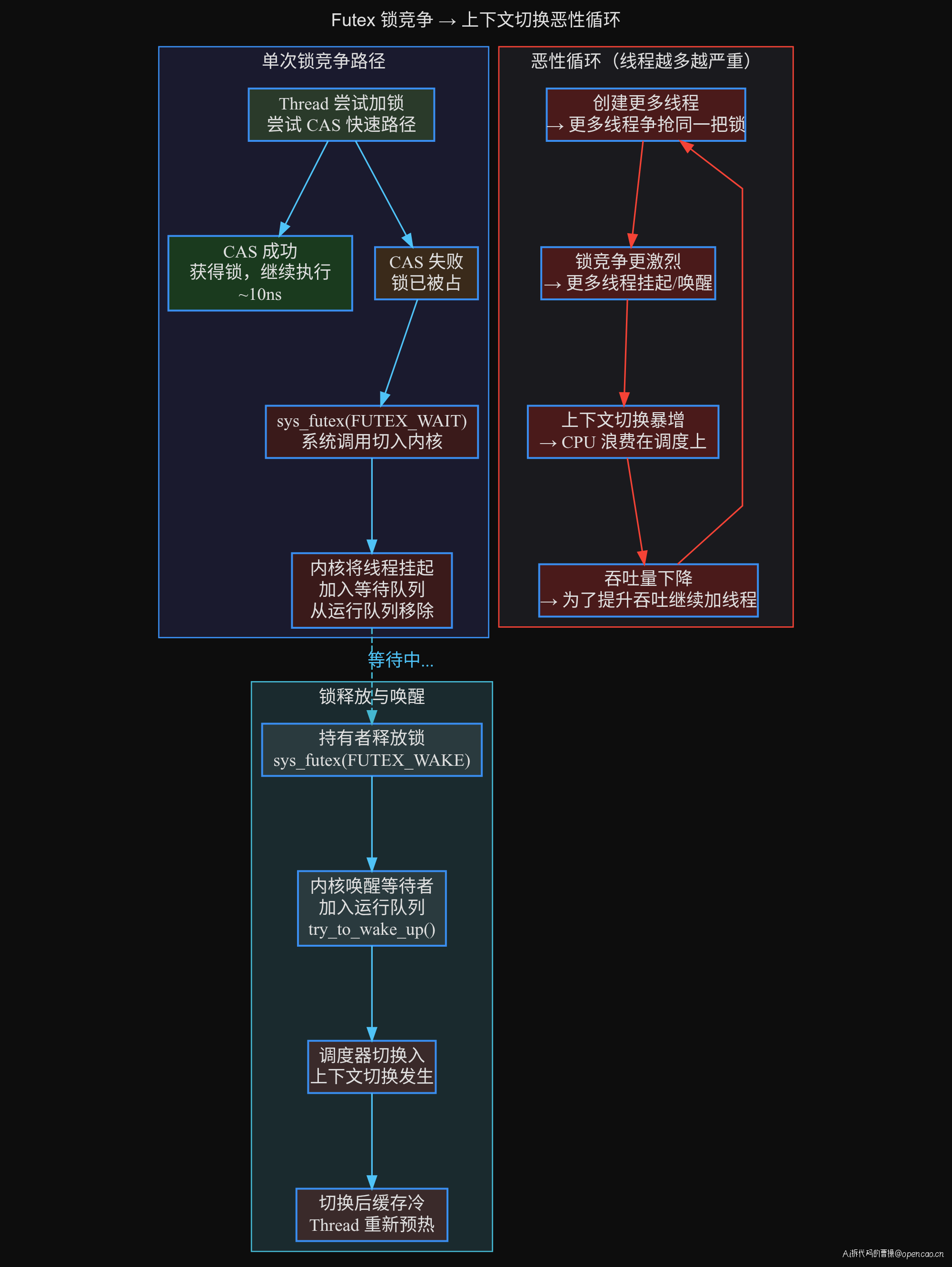
Java 的 synchronized 和 ReentrantLock 在竞争激烈时会退化为内核态的 Futex 系统调用。流程如下:
线程尝试加锁 → CAS 快速路径失败 → 调用 sys_futex(FUTEX_WAIT) → 内核将该线程挂起 → 锁持有者释放锁时 sys_futex(FUTEX_WAKE) → 内核唤醒等待线程 → 调度器将线程切换回 CPU → 上下文切换发生。
487 个线程抢一把锁,意味着几乎每次加锁操作都会触发 Futex 系统调用,每次 Futex 唤醒都可能伴随一次上下文切换。
子原因 3:反向缩放——线程越多吞吐越低
CPU 密集型应用的线程数并非越多越好。基本公式是:
最优线程数 = CPU 核数 + 1 (纯 CPU 密集型)
最优线程数 = CPU 核数 × (1 + 等待时间/计算时间) (一般公式)
对于 order-svc-07 的场景,大多数请求处理是本地计算(订单校验、价格计算、状态流转),属于 CPU 密集型。因此最优线程数约为 8-16。当线程数达到 487 时,发生了严重的 oversubscription:
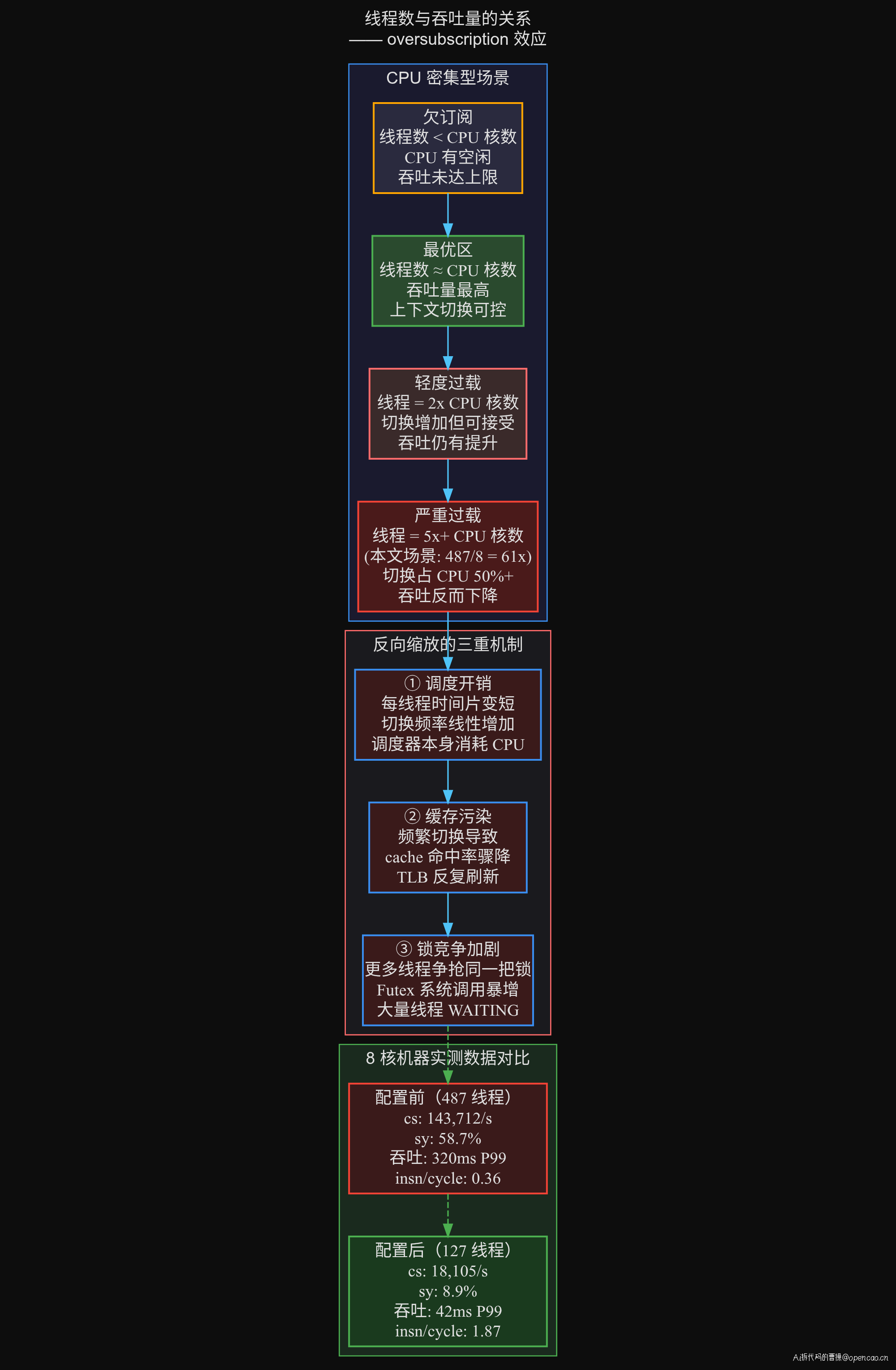
子原因 4:线程局部性丧失
上下文切换还有一个容易被忽略的代价——线程局部性(thread locality)的丧失。在线程数合理的情况下,每个线程倾向于在同一个 CPU 核上运行较长时间,L1/L2 cache 中的数据高度相关,形成良好的局部性。但当线程数远超 CPU 核数时,调度器被迫频繁地将线程迁移到不同核上运行(从 perf stat 中可以看到 cpu-migrations 指标)。迁移意味着线程在核 A 上积攒的热 cache 内容全部作废,迁移到核 B 后一切从头开始。cache 预热周期通常在 5-20 us,这段时间内该线程几乎不产生有效产出。子原因 1 中的上下文切换生命周期图展示了每次切换时 cache 被冲刷的全过程,可以对照理解。
子原因 5:锁、切换、缓存三者相互强化
问题不是单因单果,而是三个因素的恶性循环:
- 线程过多 → 锁竞争加剧:更多线程同时争抢同一把锁,Futex 调用暴增
- 锁竞争加剧 → 更多上下文切换:线程在 park/unpark 之间频繁切换
- 更多切换 → 缓存污染加重:每次切换都导致 cache/TLB 刷新,IPC 从 1.8 跌到 0.36
- 缓存污染 → 吞吐下降 → 试图加更多线程:开发人员看到吞吐不够,直觉反应是加线程,结果适得其反
下图展示了线程状态转换和每次转换的上下文切换成本:
根因汇总
各因素对 CPU 的贡献汇总:
| 因素 | 对 sy CPU 的贡献 | 占比 |
|---|---|---|
调度器 __schedule 切换开销 |
~12% | 20% |
| 锁竞争(spin_lock + futex) | ~20% | 34% |
| 线程唤醒/入队(try_to_wake_up) | ~9% | 15% |
| 调度队列管理(enqueue/dequeue) | ~8% | 14% |
| 其他系统调用 | ~10% | 17% |
| 合计 | ~59% | 100% |
修复方案
第一步:评估现状
当前配置的问题:
- Tomcat max-threads=500:对于 8 核机器处理 CPU 密集请求,200 已经足够。Tomcat 线程池本质上是一个 Worker 池,每个线程处理一个请求。当所有线程都处于计算密集型状态时,500 个线程只会相互争抢 CPU。
- 三个独立的业务线程池各 core=32 max=64:每个业务都创建自己的线程池,彼此隔离但又共用同一组 CPU 资源。建议统一为一个共享线程池,资源和负载可以弹性调配。
- 线程池参数硬编码:没有根据 CPU 核数动态调整,换到不同规格的机器上要么不够用要么过度分配。
第二步:确定优化方向
- 线程数 = f(CPU 核数):动态计算,不硬编码
- Tomcat 保持 200(8×25,IO 密集型留有余量)
- 业务逻辑尽量在 Tomcat 线程上执行,避免额外的线程池切换
- 必须异步的场景使用统一的 common 线程池
- 减少细粒度锁,检查锁范围是否过大
第三步:代码修改
优化后的配置类:
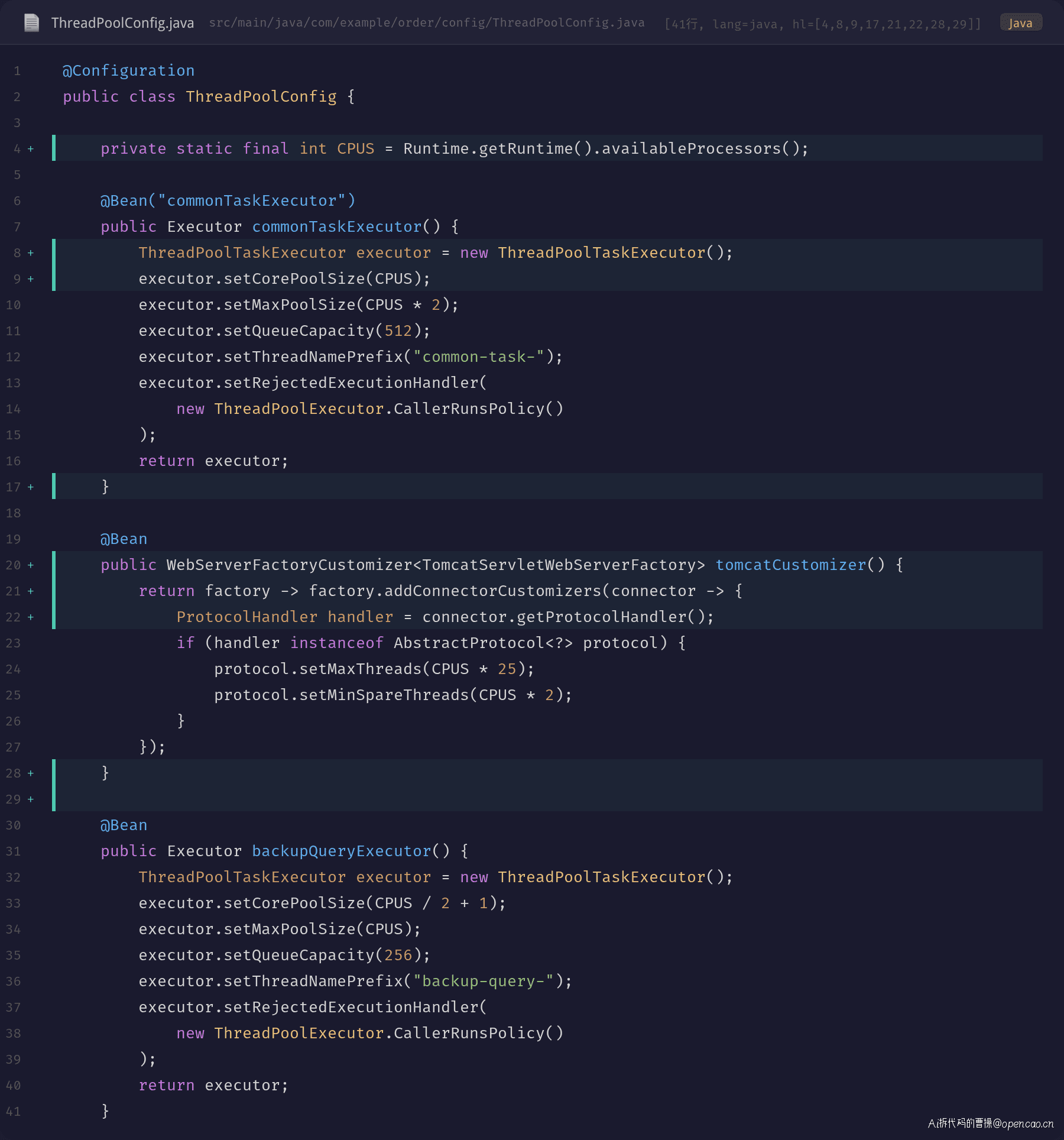
改动要点:
- 引入
availableProcessors():所有线程池参数基于 CPU 核数动态计算,不硬编码 - 统一线程池:业务逻辑尽量在 Tomcat 线程中完成,只有真正耗时的后台任务才提交到
commonTaskExecutor - Tomcat 降为 200(8×25):考虑到请求中存在少量 IO 等待(DB 查询),保留一定余量
- 核心线程数合理:
commonTaskExecutorcore=8 max=16,backupQueryExecutorcore=5 max=8 - 队列容量从 2048 降至 512:过大队列会掩盖线程池满的问题,导致请求等待时间不可控
第四步:上线部署
修改配置后,逐步灰度上线。先让一台机器生效,观察 10 分钟确认无异常后再全量发布。
验证结果
即时指标
部署完成后,再次用 vmstat 和 pidstat 验证效果:
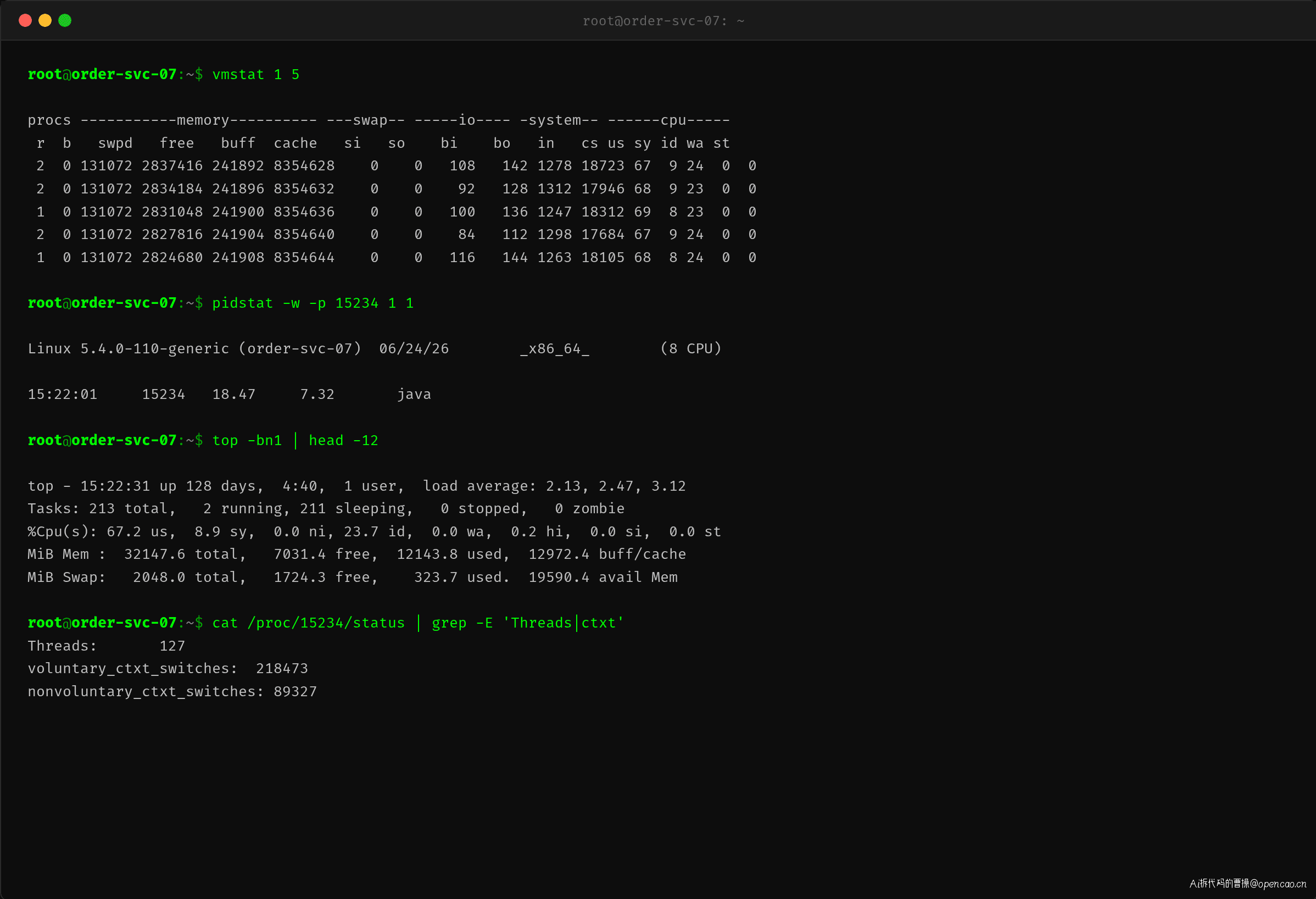
对比数据一目了然:
| 指标 | 修复前 | 修复后 | 变化 |
|---|---|---|---|
| 上下文切换/s | 143,712 | 18,105 | -87% |
| CPU system | 58.7% | 8.9% | -85% |
| CPU idle | 8.4% | 23.7% | +182% |
| 线程数 | 487 | 127 | -74% |
| P99 RT | 320ms | 42ms | -87% |
| 自愿切换/s | 239 | 18 | -92% |
| 非自愿切换/s | 187 | 7 | -96% |
非自愿切换从 187/s 降到 7/s,说明线程不再被调度器强制换出,时间片用完之前就能完成任务。
团队复盘
修复完成后,团队在值班群进行了复盘讨论:
避坑建议
- 线程池参数要有容量测算依据:每次改 max-threads 前,先算一算:当前 QPS × 平均 RT = 活跃线程数。如果活跃线程数只有 50,把 Tomcat 调到 500 只会带来副作用。
- 区分 CPU 密集型和 IO 密集型:CPU 密集型用 核数+1,IO 密集型的倍数根据 IO wait 比例估算。不确定时用 JFR/Arthas profiling 看一看实际线程状态分布。
- 不要每个业务创建独立线程池:除非有明确的隔离需求(如避免慢任务拖垮快任务),否则统一线程池更容易管理和调优。多个小池子会造成资源碎片化。
- 上线前在压测环境验证线程数水位:用 Gperf 全链路压测观察 vmstat cs 和 pidstat cswch/nvcswch,确保切换次数在合理范围。cs 超过 5 万/s 就应该怀疑线程数过多。
- 监控 OS 级调度指标:除了应用层面的 QPS/RT/error,监控面板上应该加上 context_switches、cpu_system、voluntary/nonvoluntary_ctxt_switches、线程数这些 OS 层面的信号。
- 非自愿切换是反向缩放的前哨指标:如果 nvcswch/s 超过 cswch/s 的 30%,说明线程严重争抢 CPU。这时候加线程只会让系统更慢。
- IPC 是理解 CPU 效率的核心指标:用
perf stat查看 instructions per cycle。IPC < 1.0 说明 CPU 大量停滞在 memory stall 上,常见于缓存抖动、上下文切换频繁的场景。
附:完整命令清单
# 查看系统上下文切换
vmstat 1 5
cat /proc/stat | grep ctxt
# 按进程查看上下文切换
pidstat -w -p ALL 1 3
# 查看进程线程数
cat /proc/{pid}/status | grep Threads
cat /proc/{pid}/status | grep -E 'voluntary|nonvoluntary'
# CPU 热点分析
perf top -K -p {pid} --sort=comm,dso,symbol
perf stat -e context-switches,cpu-migrations,cycles,instructions -p {pid} --sleep 5
# 历史切换趋势对比
sar -w -f /var/log/sysstat/sa{日期}
# 可用处理器核数(Java)
Runtime.getRuntime().availableProcessors()


