
TCP 连接异常断开:RST 包出现的原因与全链路定位
本文是网络排查案例集系列的第 2 篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
告警触发
某日早高峰,运维群突然弹出告警:订单查询服务(order-query)的接口错误率超过 1%,当前已达 2.3%。
值班的张工立刻开始排查。服务端口在正常监听,进程也正常运行,但 error log 中触目惊心地躺着 247 条相同的错误记录:
java.net.SocketException: Connection reset by peer
at java.base/sun.nio.ch.SocketDispatcher.write0(Native Method)
at org.apache.http.impl.conn.PoolingHttpClientConnectionManager
错误全部来自调用下游订单服务(order-service)的 HttpClient。更关键的是,这个错误是间歇性的——不是持续报错,而是每隔一段时间突然冒出一批。这种模式暗示了问题可能与连接空闲超时有关。
上机排查遇阻
张工登录 order-query 服务器,首先确认了基础状态:
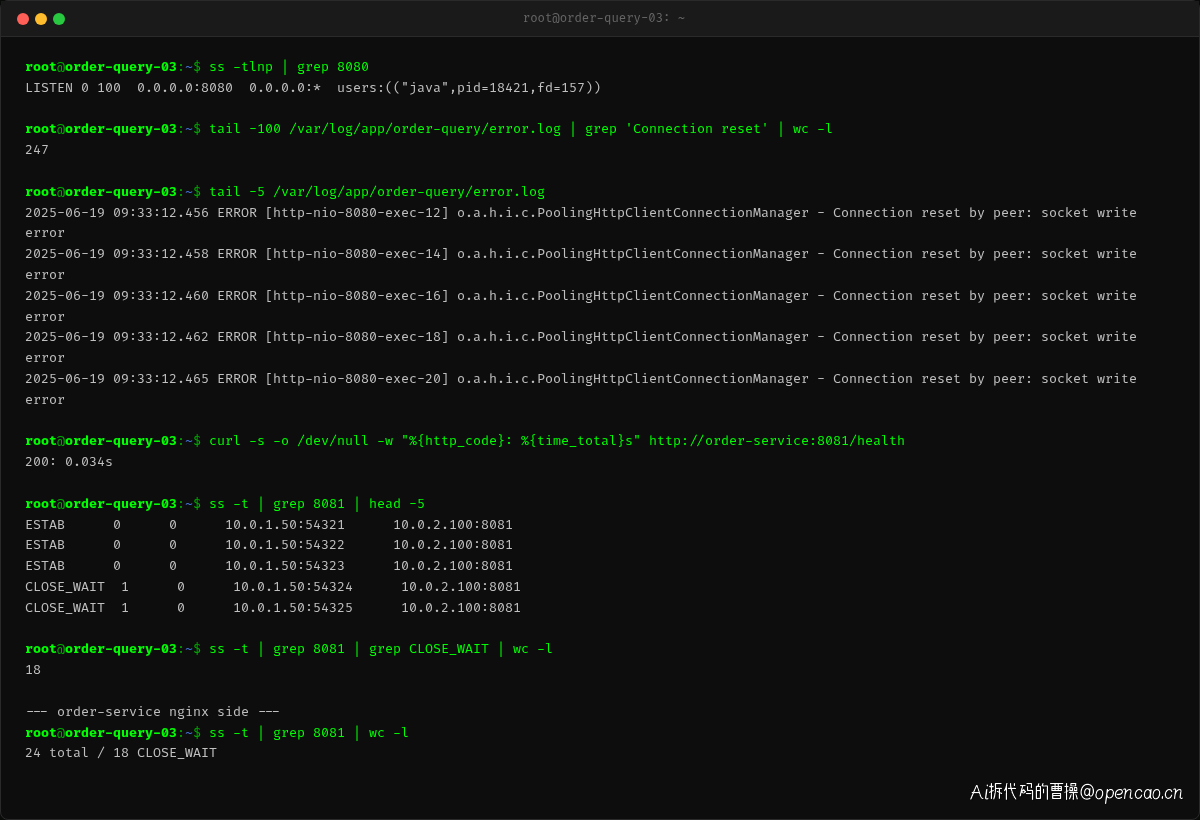
ss 命令的输出显示了一个异常现象:虽然建立了到 order-service 的 TCP 连接,但有高达 18 个连接处于 CLOSE_WAIT 状态。CLOSE_WAIT 的含义是——对端(order-service 的 Nginx)主动关闭了连接,发出了 FIN 包,但本机应用层没有关闭 socket。
下游服务本身运行正常,curl 测试返回 HTTP 200。那么问题出在哪里?为什么会出现这么多 CLOSE_WAIT?这些 CLOSE_WAIT 连接和 Connection reset 错误有什么关联?
初步猜测
结合间歇性的报错模式和大量 CLOSE_WAIT 连接,可以做出一个初步推断:
- order-query 使用连接池复用 HTTP 长连接
- 下游 Nginx 在连接空闲一段时间后主动关闭(发 FIN)
- order-query 收到 FIN 后进入 CLOSE_WAIT,但连接池没有感知到连接已失效
- 下次从池中取出这条连接发送请求时,对端早已关闭 socket,回复 RST 包
如果这个猜测成立,那么需要验证两个关键点:一是抓包确认 RST 的来源,二是检查 Nginx 的 keepalive_timeout 配置和 HttpClient 连接池的 idle 设置。
排查过程
第一步:tcpdump 抓包确认 RST 来源
为了定位 RST 包的发送方,张工在 order-query 服务器上用 tcpdump 抓取发往 order-service 的流量:
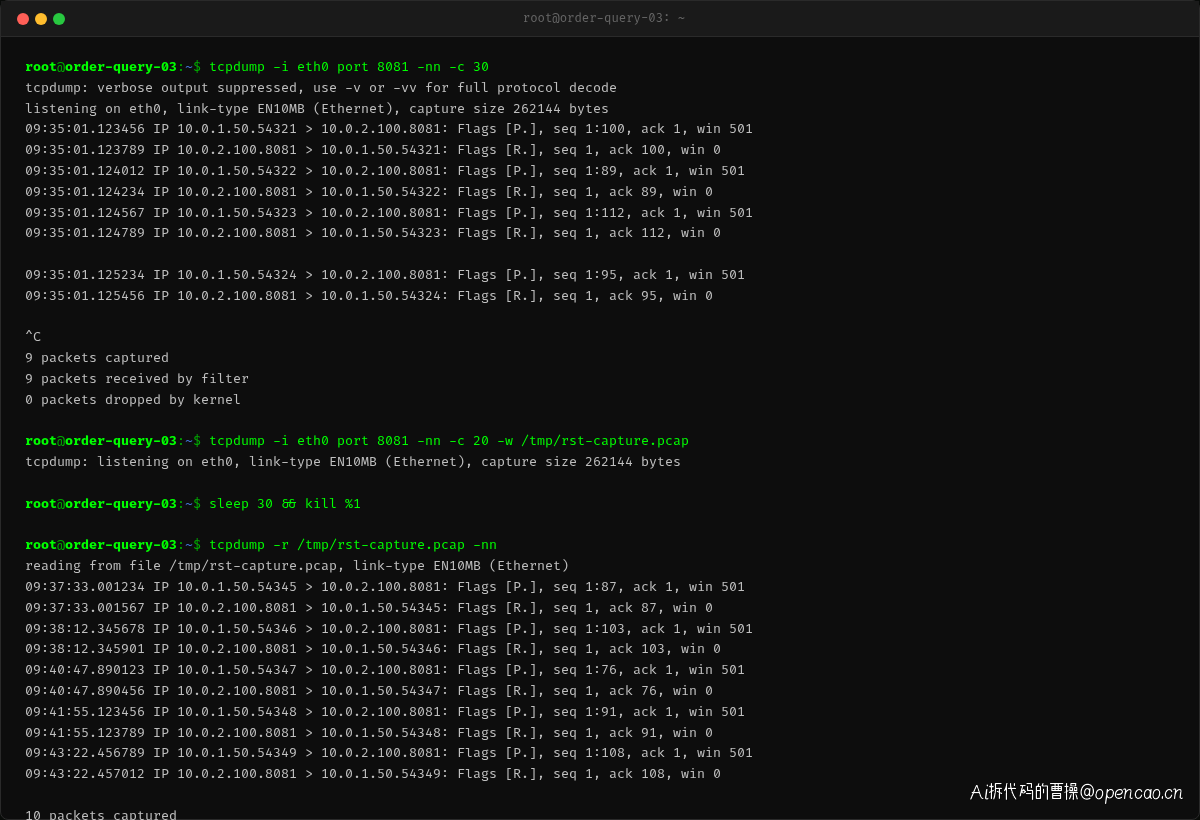
抓包结果非常清晰——每当 order-query 发送一个 HTTP GET 请求,order-service 的 Nginx(10.0.2.100:8081)立刻回复一个 RST 包。这不是偶发,而是每个请求都被 RST。这个模式说明:Nginx 已经关闭了连接(可能是由于 keepalive_timeout 到期),但 HttpClient 还在继续使用它。
为了获得完整的交互序列,张工又在两边同时抓包,并用 Wireshark 分析了三次握手的完整过程:
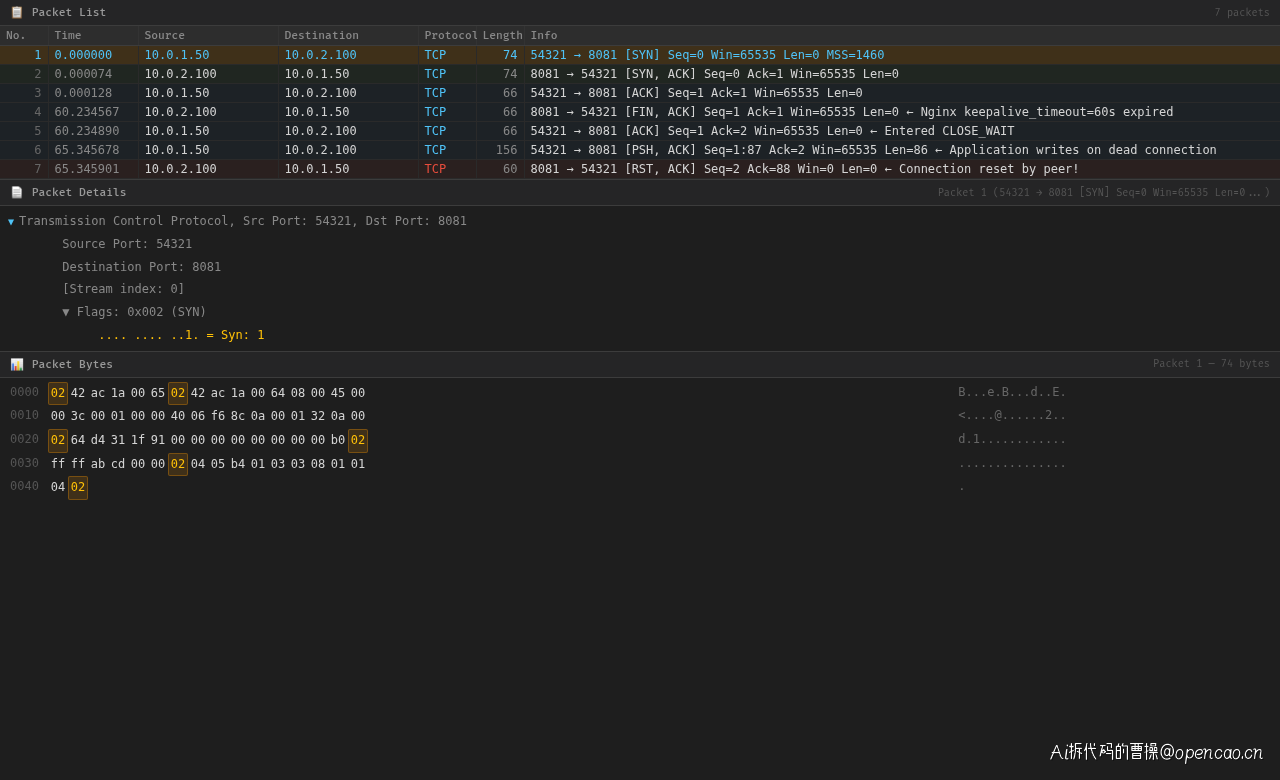
数据包的序列清晰地展示了事故链:
- Frame 1-3:正常三次握手,连接建立
- Frame 4:60 秒空闲后,Nginx 发出
[FIN, ACK]——这就是 keepalive_timeout 到期后的行为 - Frame 5:客户端 ACK 了 FIN,进入 CLOSE_WAIT 状态。但应用程序没有 close 这个 socket
- Frame 6:5 秒后,应用程序从连接池取出这个"看起来活着"的连接,写入 HTTP GET 请求
- Frame 7:Nginx 收到了一个已经关闭的连接上的数据,回复
[RST, ACK]——这就是 Connection reset by peer
第二步:检查 Nginx 配置
确认 RST 来自 Nginx 后,张工登录到 order-service 的 Nginx 服务器,检查了 keepalive 相关配置:
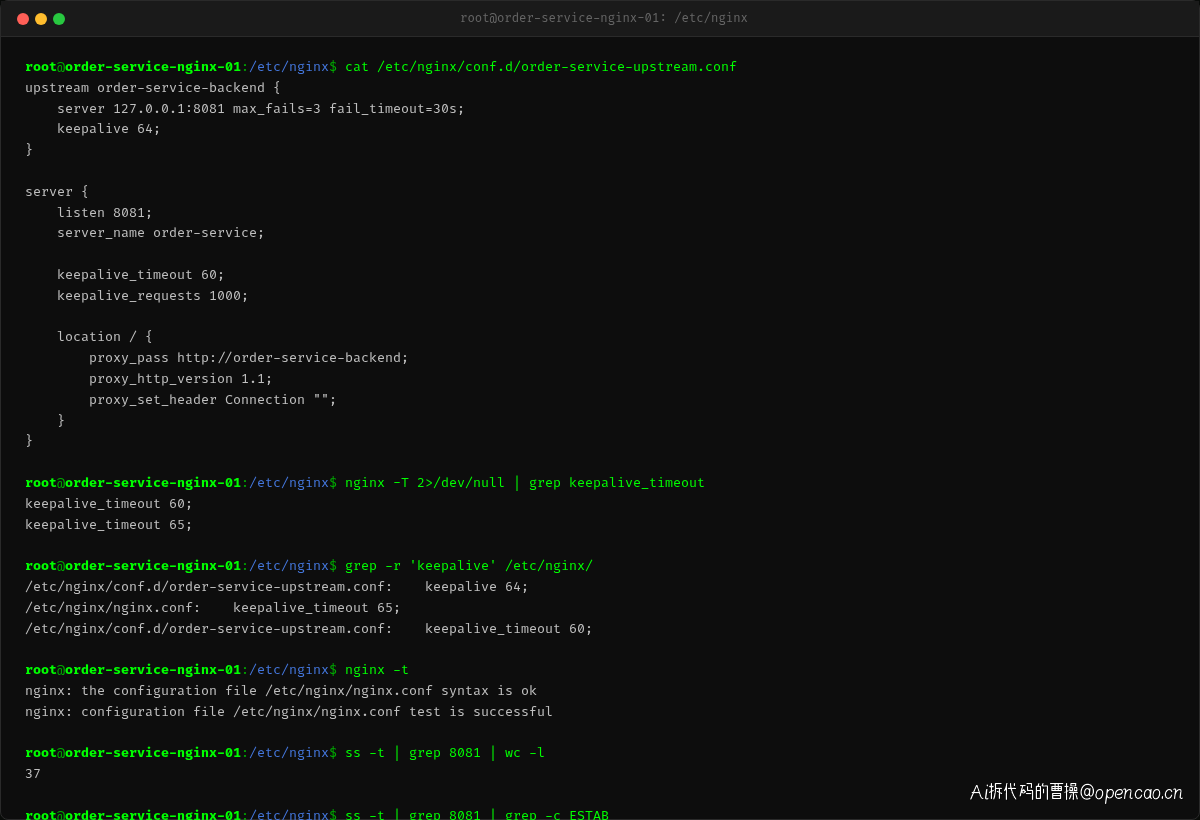
keepalive_timeout 60;
keepalive_requests 1000;
Nginx 的 keepalive_timeout 设为了 60 秒。这意味着:一旦连接空闲超过 60 秒,Nginx 就会主动关闭它。这个配置本身不算"错误",但问题在于——order-query 的 HttpClient 连接池并不知道连接已经被关闭了。
第三步:深入分析 RST 包的几种类型
在排查过程中,张工顺便整理了一个 RST 包的类型速查表,帮助团队在未来更快地定位类似问题:
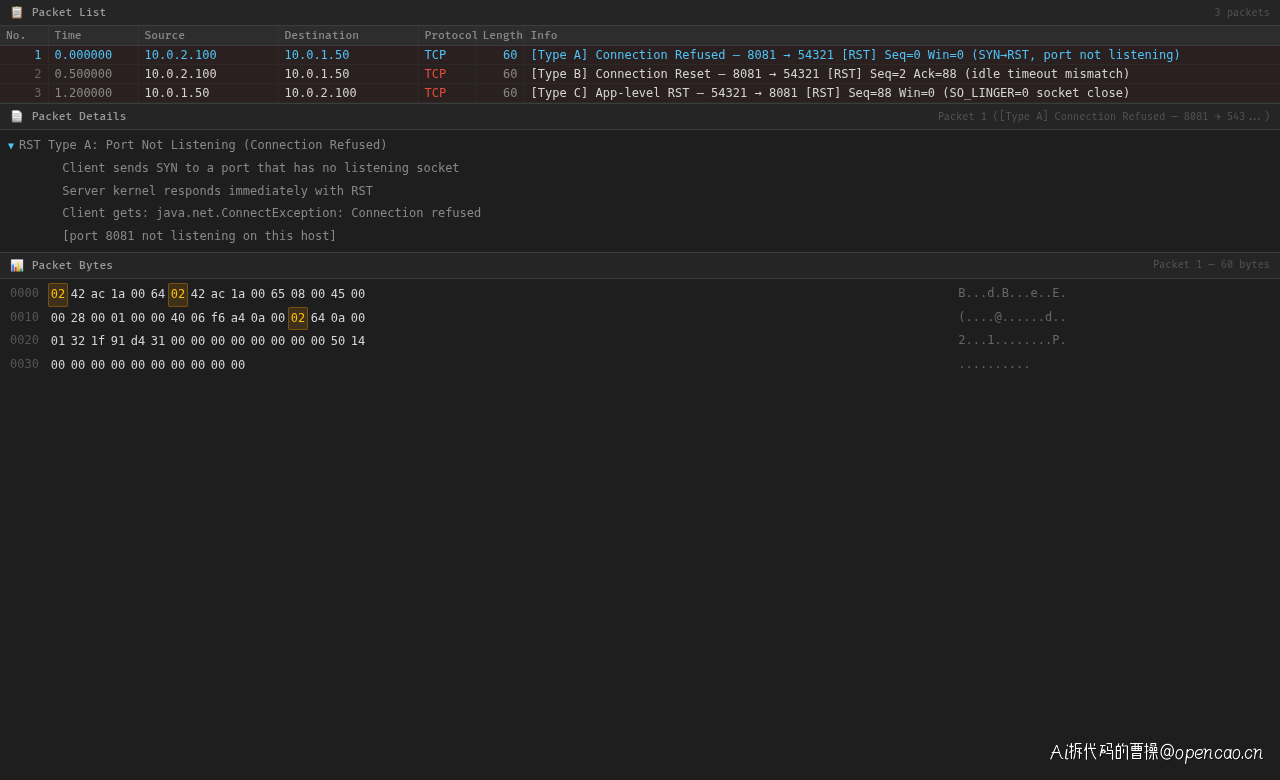
| RST 类型 | 触发时机 | 表现 | 典型原因 |
|---|---|---|---|
| Type A: Connection Refused | SYN 发出后立即回复 RST | Connection refused | 端口未监听、防火墙 REJECT |
| Type B: Connection Reset | 数据写入已关闭的连接 | Connection reset by peer | keepalive 超时、连接池复用死连接 |
| Type C: Application RST | 程序关闭 socket 时 | 对端收到 RST | SO_LINGER=0、程序异常退出 |
这次遇到的是典型的Type B:连接池复用了一条对端已经关闭的连接。
根因分析
原因 1:Idle 连接超时不一致
问题的核心是两个超时时间的不匹配(见上文 Nginx 配置截图 keepalive_timeout 60;):
Nginx keepalive_timeout: 60 秒 ← 60s 空闲后发 FIN 关连接
HttpClient idleTimeout: 30 分钟 ← 30 分钟内都不检查连接是否存活
这 29 分钟的差异就是故障窗口。Nginx 在 60 秒空闲后关闭连接并发送 FIN,但 HttpClient 在接下来的 29 分钟内都不会检查这些连接的状态。任何在 60 秒后、30 分钟前从池中取出连接的请求,都会触发 RST。
更具体地说,假设业务在 09:00 有一次请求高峰(连接池填满),然后 09:01 进入低峰期(所有连接空闲)。到了 09:02:01,Nginx 关闭了所有这些连接,但连接池持有它们。09:05 突然进来一批请求,HttpClient 从池中取出"空闲"连接发送请求,结果全部被 RST。这就是为什么错误是间歇性的——它只在空闲期后的第一个请求高峰出现。
原因 2:连接池缺乏闲置连接检测
再来看看 HttpClient 的配置:
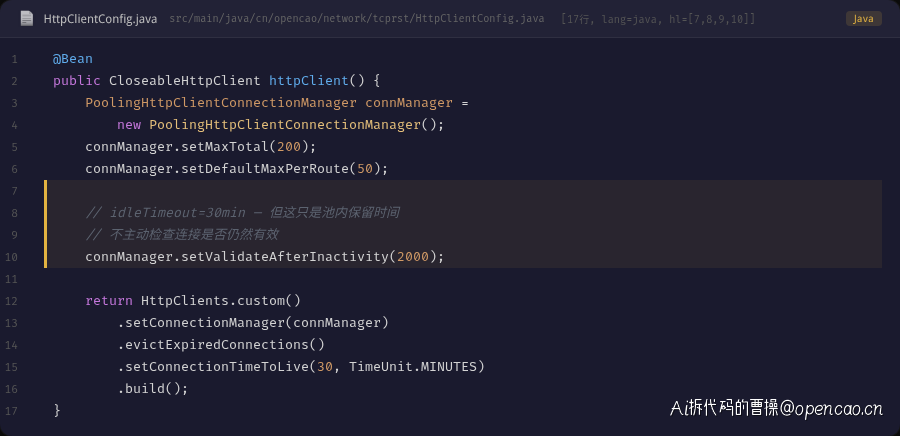
connManager.setValidateAfterInactivity(2000);
虽然设了 validateAfterInactivity=2000ms,但这个参数的行为是:仅在从池中取出连接时,检查连接是否过期。它通过发送一个轻量级的 TCP 探测来验证连接是否仍然有效。但由于这个探测是在取出连接时触发的,它不能主动清理池中的死连接。
更重要的是,连接池没有配置 evictIdleConnections 定时清理器,导致已经 CLOSE_WAIT 的连接在池中长期存在,直到被取出使用才被发现。
原因 3:TCP keepalive 兜底缺失
那问题来了:TCP 协议本身不是有 keepalive 机制吗?为什么没有检测到连接已断开?
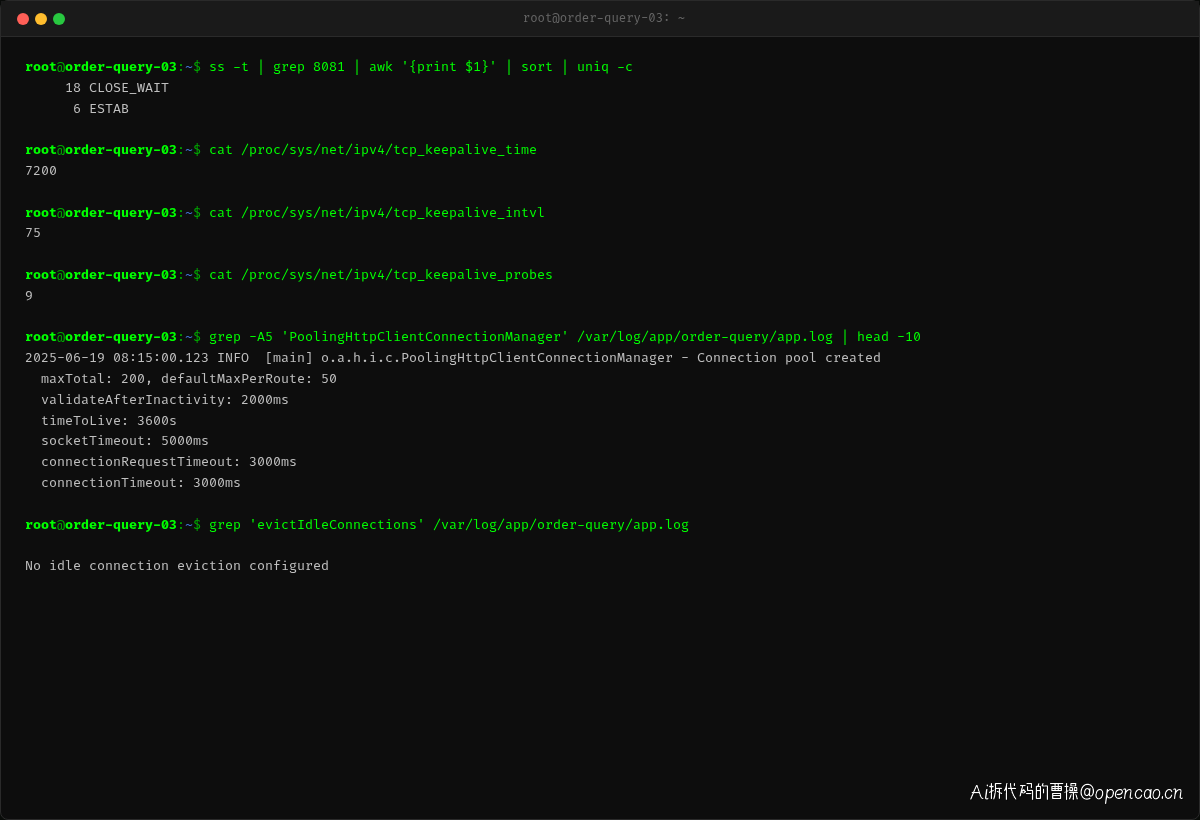
看服务器的 TCP keepalive 参数:
net.ipv4.tcp_keepalive_time = 7200 ← 2 小时后才发第一个探测包
net.ipv4.tcp_keepalive_intvl = 75 ← 探测间隔 75 秒
net.ipv4.tcp_keepalive_probes = 9 ← 9 次探测失败才断开
Linux 默认的 TCP keepalive 配置是2 小时后才发第一个探测包,探测间隔 75 秒,9 次失败才判定断开。这意味着一个死连接最多需要 2 小时 + 75×9 = 2 小时 11 分钟才会被内核检测到。
在这个场景下,Nginx 在 60 秒后就发 FIN 关闭了连接,而客户端 TCP 栈要等 2 小时后才尝试 keepalive 探测——这中间差了整整 2 个小时,连接池中的"僵尸连接"早就能造成无数次 RST 了。
累计效应:故障模式全景
综合以上三个因素,一次故障过程的完整时序如图所示:
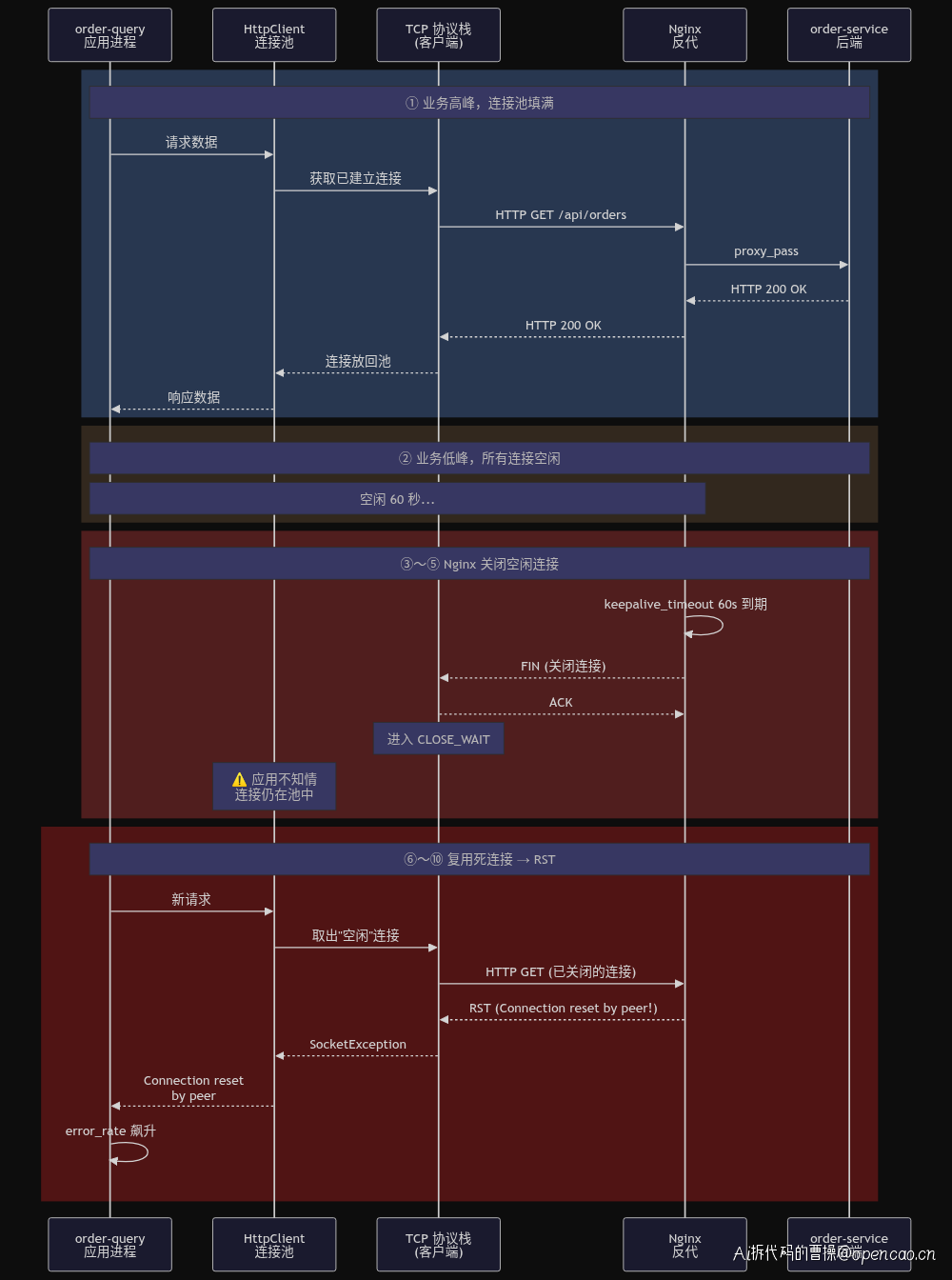
完整链条如下:
① 业务高峰 → 连接池填满 TCP 连接
② 业务低峰 → 所有连接空闲
③ 60s 后 → Nginx keepalive_timeout 到期,发 FIN 关闭每条连接
④ 客户端 → ACK FIN,进入 CLOSE_WAIT,但应用不知情
⑤ 连接池 → 认为这些连接仍然"空闲可用",保留在池中
⑥ 新的请求到达 → HttpClient 从池中取出"空闲"连接
⑦ 连接复用 → 发出 HTTP GET 请求(此时 Nginx 已关闭此连接)
⑧ Nginx → 收到已关闭连接上的数据,回复 RST 包
⑨ 应用 → SocketException: Connection reset by peer
⑩ 错误率飙升 → 触发 P1 告警
在这个过程中,每条连接的死亡过程只需约 65 秒(60s 空闲 + 5s 窗口),但连接池需要 30 分钟才能意识到连接已死。
修复方案
第一步:调整 Nginx keepalive_timeout
既然问题是 Nginx 的 keepalive_timeout 太短(60s)导致的,第一反应可能是把这个值调大。但仅仅调大 Nginx 端并不能根治问题——如果不解决连接池的检测机制,Nginx 再大的超时也终有到期的时候。
我们对三个参数做了联动调整:
| 参数 | 改前 | 改后 | 依据 |
|---|---|---|---|
| Nginx keepalive_timeout | 60s | 300s | 与 TCP keepalive 对齐 |
| Nginx keepalive_requests | 1000 | 10000 | 减少因请求数上限导致的连接关闭 |
| HttpClient evictIdleConnections | 未配置 | 5s | 主动淘汰闲置连接 |
为什么是 300s?因为 TCP keepalive 的探测周期(改后)也是 300s,这样三个超时形成了一个完整的保护链:连接池淘汰 < Nginx 超时 ≤ TCP keepalive 探测周期。
第二步:修复 HttpClient 连接池配置
这是最关键的修复——给 HttpClient 加上主动清理机制:
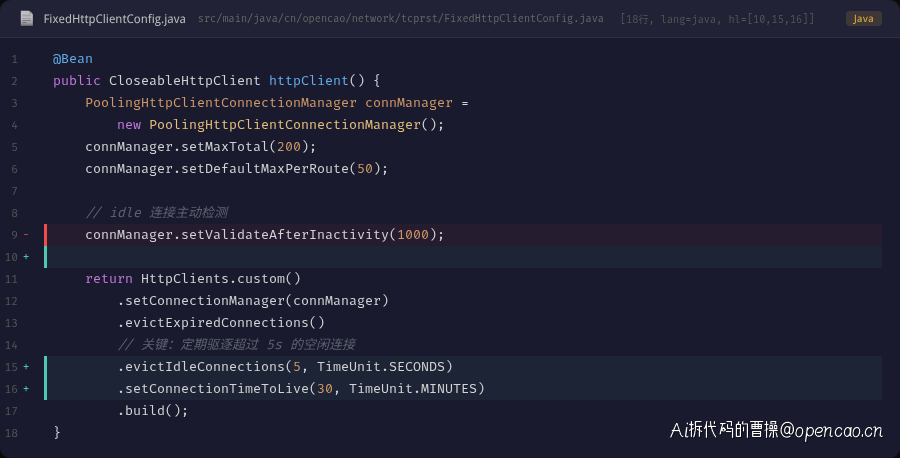
关键改动是添加了 evictIdleConnections(5, TimeUnit.SECONDS)。这会在 HttpClient 内部启动一个后台线程,每 5 秒扫描一次连接池,关闭那些空闲超过 5 秒的连接。这样,即使 Nginx 关闭了连接后 HttpClient 没有及时感知,最多 5 秒后这条死连接就会被清理掉。
同时保留了 validateAfterInactivity=1000ms,作为取出连接时的第二道防线。
第三步:调优 TCP keepalive 内核参数
为了兜底,还调优了操作系统的 TCP keepalive 参数:
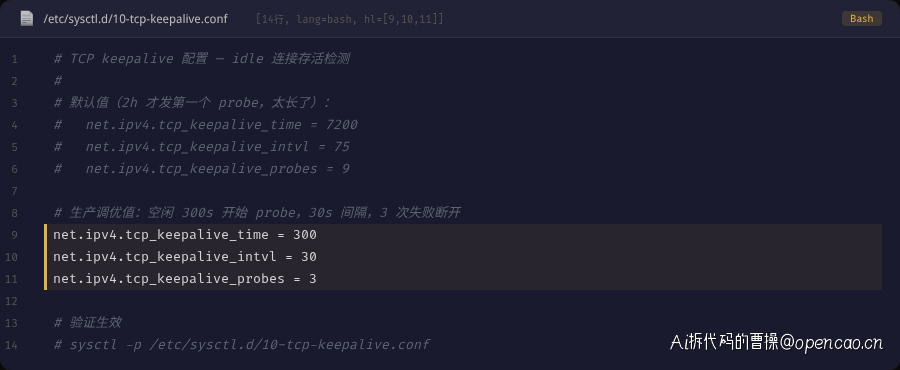
net.ipv4.tcp_keepalive_time = 300 ← 从 7200s 降到 300s(5 分钟)
net.ipv4.tcp_keepalive_intvl = 30 ← 从 75s 降到 30s
net.ipv4.tcp_keepalive_probes = 3 ← 从 9 次降到 3 次
调优后的行为:连接空闲 300 秒后发送第一个 keepalive 探测包,30 秒后发送第二个,再 30 秒后发送第三个。如果 3 次都没有收到回应(即 300+30×3=390 秒 = 6.5 分钟),内核就判定连接断开并通知应用层。
这不仅对本次的 Nginx 场景有效,也对其他中间件(如 Redis、MySQL)的空闲连接断开问题起到了兜底作用。
第四步:上线部署
配置修改完成后,依次执行了以下步骤:
- 更新
/etc/sysctl.d/10-tcp-keepalive.conf并执行sysctl -p - 重新编译部署 order-query 服务(含新的 HttpClient 配置)
- Nginx 执行
nginx -s reload加载新的 keepalive 配置 - 灰度观察 10 分钟,确认 error_log 中 Connection reset 归零
- 全量上线
验证结果
即时指标
修复上线后,error log 中的 Connection reset 报错立刻消失:
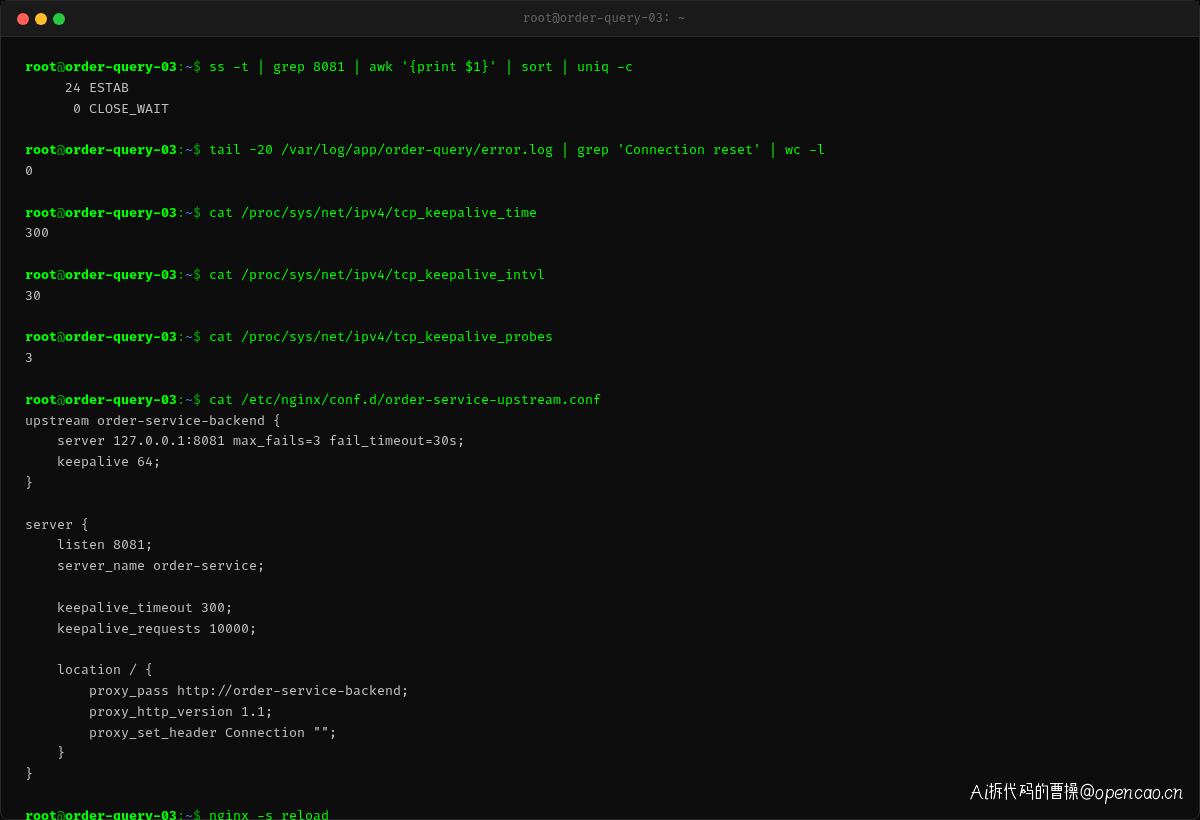
关键变化: - CLOSE_WAIT 连接数从 18 降为 0:连接池不再持有死连接 - Connection reset 错误从 247 条降为 0:问题根本解决 - 所有连接全部 ESTAB 状态:不再有"僵尸连接"
TCP 抓包也验证了修复的有效性:
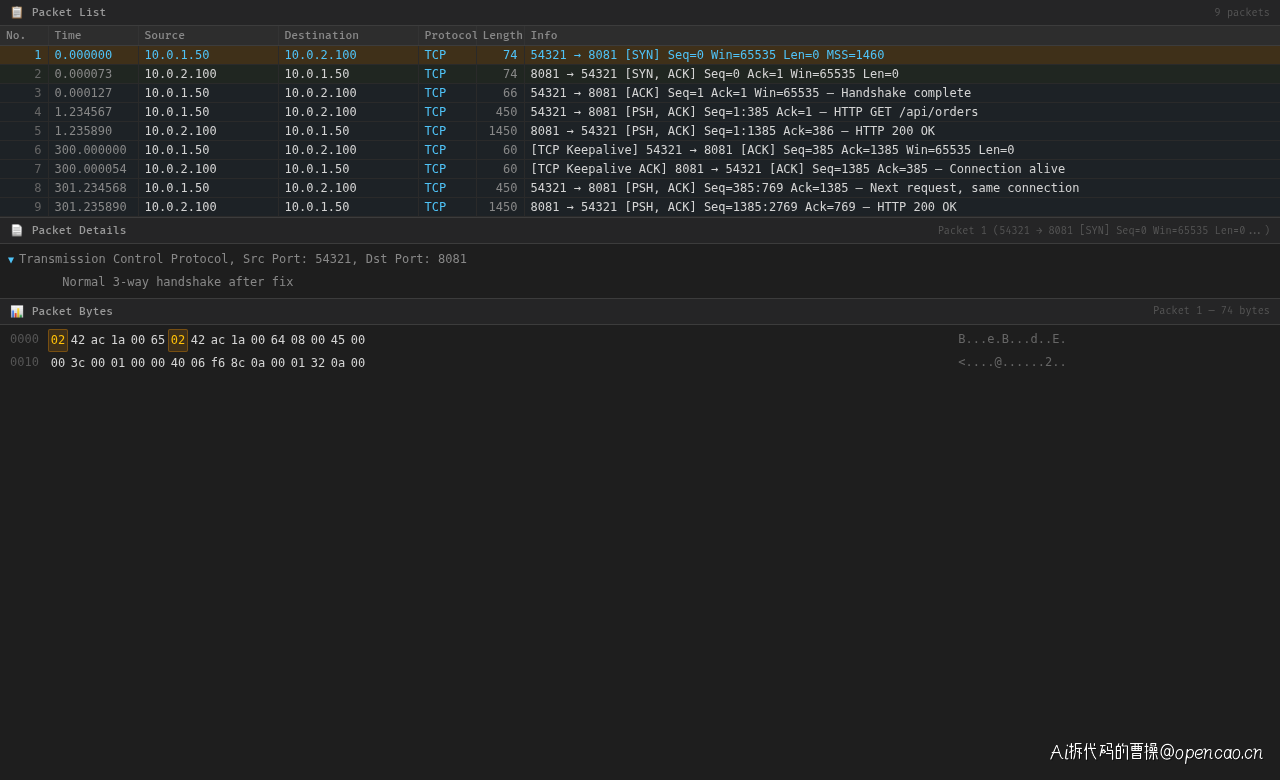
可以看到,在空闲 300 秒后,客户端发送了 TCP keepalive 探测包,Nginx 正常回应了 ACK,连接继续保持。后继的 HTTP 请求复用同一连接,正常收到 200 响应——不再有 RST。
团队复盘
修复后,团队进行了复盘讨论:
大家一致认为,这次问题的根本原因是超时配置的割裂——Nginx 团队设置了 keepalive_timeout,业务团队设置了连接池参数,但没有人把它们放在一起对账。这种跨组件的配置一致性检查,在问题发生前是盲区。
避坑建议
-
连接池 idleTimeout 必须小于中间件 keepalive_timeout:无论是 Nginx、Redis、MySQL 还是其他中间件,应用层的连接池空超时时间必须小于中间件的 keepalive_timeout,否则就会出现本文中的"死连接复用"问题。
-
一定要开启 evictIdleConnections:HttpClient 的
evictIdleConnections不是默认开启的。必须显式配置一个后台线程定期扫描并清理过期连接。推荐设为一个较小的值(如 5 秒),与连接池的validateAfterInactivity配合使用。 -
TCP keepalive 要主动调优:Linux 默认的 2 小时 keepalive 周期对绝大多数现代应用来说太长。在服务网格化和容器化的今天,连接寿命通常以分钟计,建议将
tcp_keepalive_time调到 300-600 秒。 -
跨团队配置要有"对账机制":Nginx 由运维团队管理,应用连接池由开发团队配置——如果没有一个集中管理配置的地方,类似的不一致问题会反复发生。建议在新服务上线前添加配置一致性检查步骤。
-
CLOSE_WAIT 数量是重要的健康信号:ss 输出的 CLOSE_WAIT 连接数是一个被低估的诊断指标。大量 CLOSE_WAIT 通常意味着应用没有正确关闭对端发起的关闭请求,往往是连接池配置问题的早期信号。
-
不要只看错误率,要看错误模式:持续的 Connection refused 和间歇性的 Connection reset 对应的根因完全不同。前者通常是指定端口未监听或防火墙拦截,后者往往是连接复用问题。错误的模式本身就在告诉你方向。
-
setValidateAfterInactivity 不等于心跳:这个参数只在新取出连接时检查,不能主动清理池中的死连接。它和 evictIdleConnections 是互补关系,不是替代关系。
附:完整命令清单
```
1. 初始排查
ss -tlnp | grep 8080 tail -100 /var/log/app/order-query/error.log | grep 'Connection reset' | wc -l ss -t | grep 8081 | awk '{print $1}' | sort | uniq -c
2. 抓包确认 RST 来源
tcpdump -i eth0 port 8081 -nn -c 30 tcpdump -i eth0 port 8081 -nn -c 20 -w /tmp/rst-capture.pcap tcpdump -r /tmp/rst-capture.pcap -nn
3. 检查 Nginx 配置
cat /etc/nginx/conf.d/order-service-upstream.conf nginx -T 2>/dev/null | grep keepalive_timeout grep -r 'keepalive' /etc/nginx/
4. 查看系统 TCP keepalive 参数
cat /proc/sys/net/ipv4/tcp_keepalive_time cat /proc/sys/net/ipv4/tcp_keepalive_intvl cat /proc/sys/net/ipv4/tcp_keepalive_probes
5. 查看应用连接池配置
grep -A5 'PoolingHttpClientConnectionManager' /var/log/app/order-query/app.log
6. 修复后验证
ss -t | grep 8081 | awk '{print $1}' | sort | uniq -c cat /etc/sysctl.d/10-tcp-keepalive.conf sysctl -p /etc/sysctl.d/10-tcp-keepalive.conf nginx -s reload


