
索引失效的 10 种场景:用 EXPLAIN 一个个验证
本文是 SQL 与数据库排障 系列的第 2 篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
第一次复盘
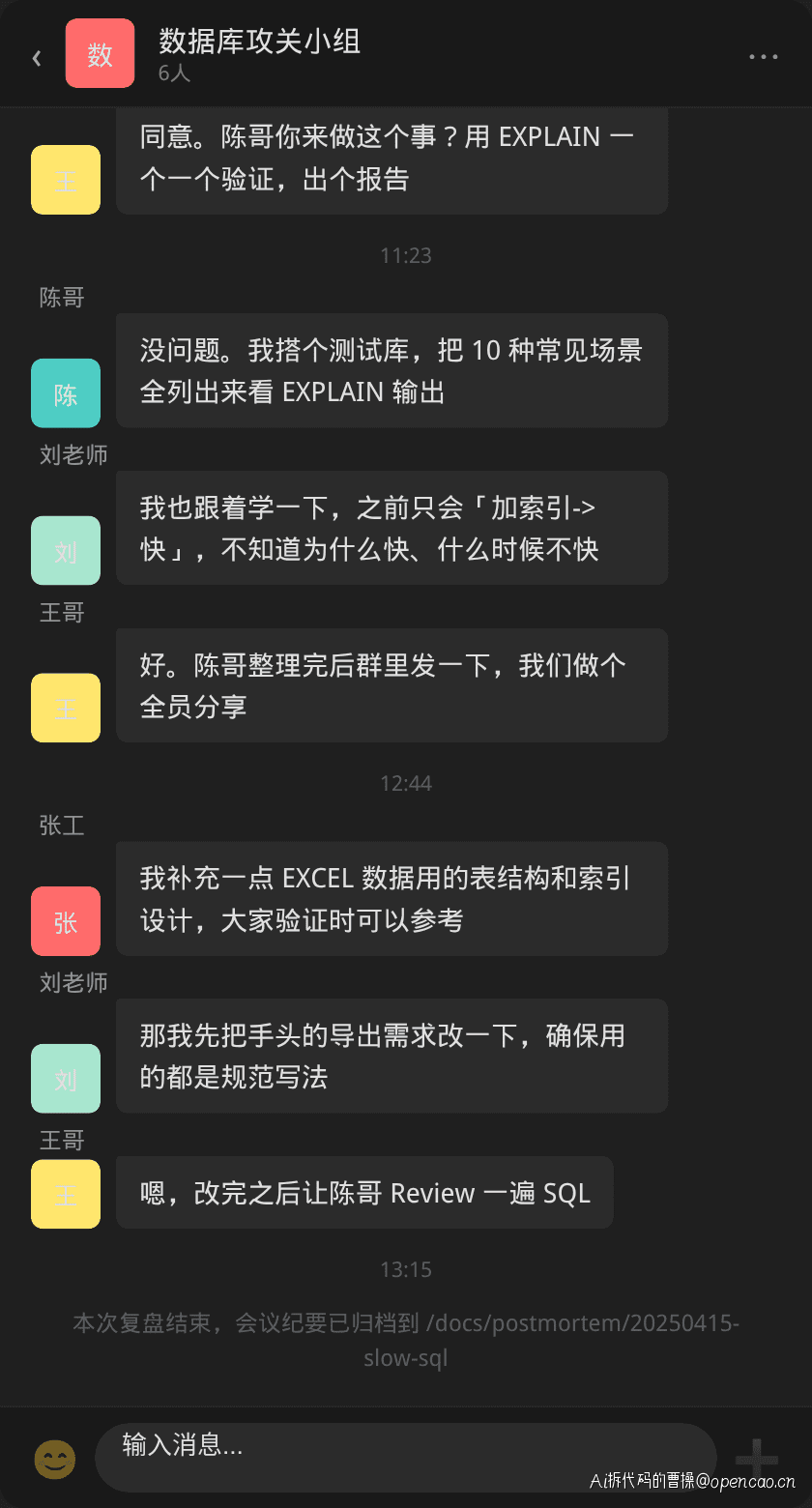
某日,团队做完上周的慢 SQL 事故复盘后,群里讨论热烈。张工把事故报告整理出来,核心原因是 WHERE 条件写错导致全表扫描——但更深层的问题是,大家对索引失效的理解都停留在表面。
"加索引查询就会快,这个说法太过笼统。"王哥在复盘会上说,"谁能立刻说出 5 种索引不走的场景?"
陈哥接下了这个任务:搭一个测试库,把常见的索引失效场景全部用 EXPLAIN 跑一遍,每种都要有错误写法和正确写法的对比。
这次的排查方式和以往不同——不是生产出故障了再救火,而是主动做一次 SQL 索引知识全面体检。陈哥在测试库建了一张模拟电商订单表,包含常用的索引设计,然后逐一验证。
SSH 登入测试库
陈哥登入测试库后,先看了一眼表结构和数据量。
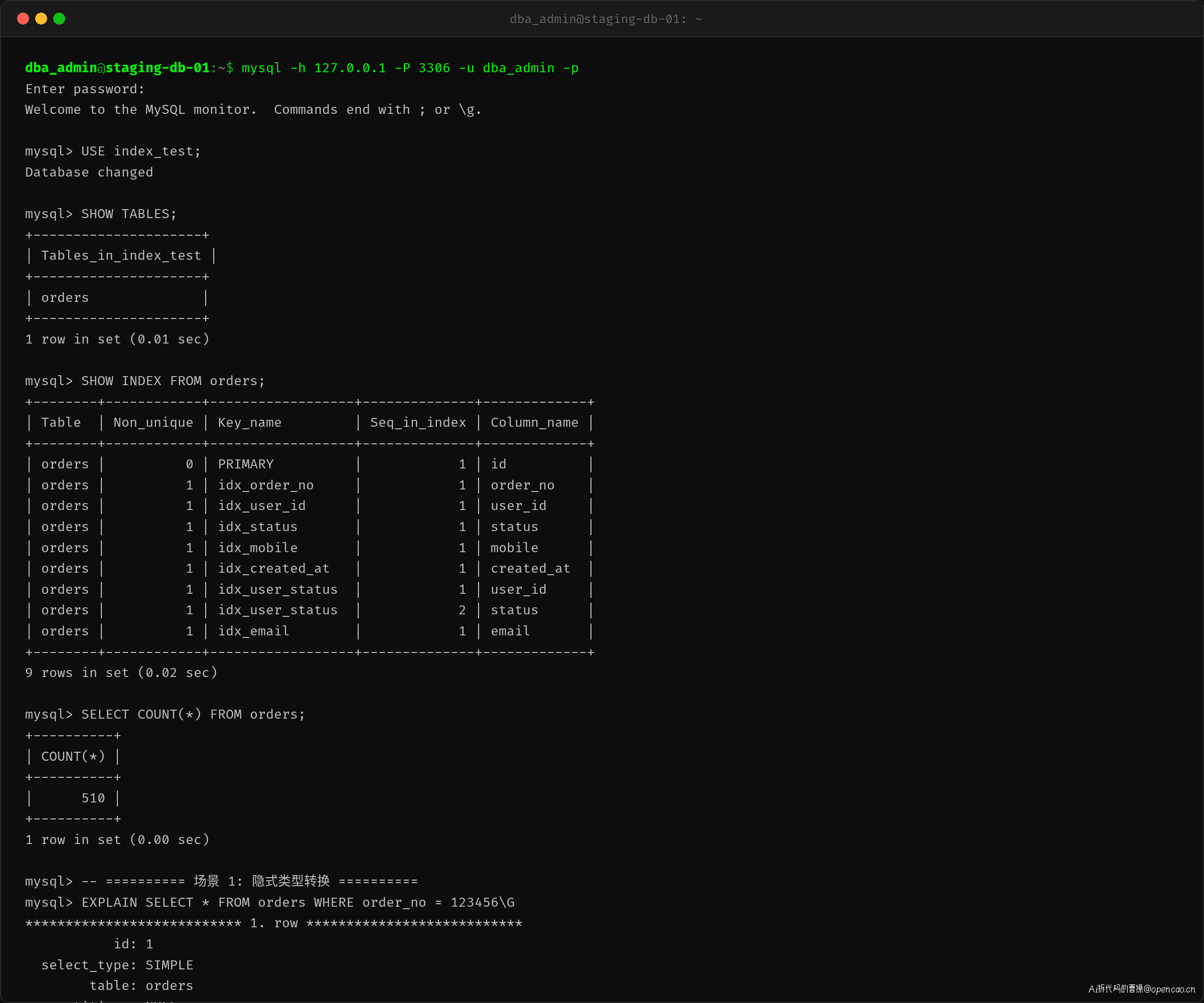
orders 表有 9 个索引,包括单列索引(idx_order_no、idx_status、idx_mobile 等)和一个联合索引 idx_user_status(user_id, status)。数据量 510 行,足够观察 EXPLAIN 的 rows 变化。
初步猜测
陈哥的猜测是:最常见的索引失效原因集中在类型不匹配、函数包裹和数据分布三个方向。但他没想到,真正验证完 10 种场景后,有些现象的细节和自己预想的不完全一样。
排查过程:十种场景逐一验证
场景 1:隐式类型转换
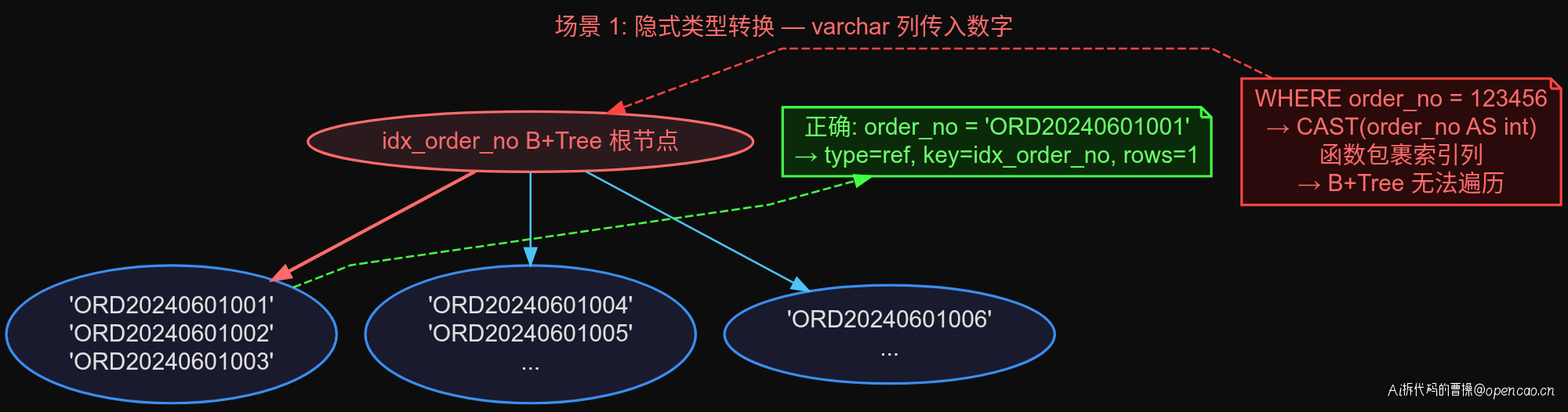
第一个验证的也是最容易犯的——隐式类型转换。
-- 错误写法(传入数字)
EXPLAIN SELECT * FROM orders WHERE order_no = 123456;
-- 正确写法(传入字符串)
EXPLAIN SELECT * FROM orders WHERE order_no = 'ORD20240601001';
两行 SQL 差别只在于 order_no 传的值是数字还是字符串,但 EXPLAIN 的结果完全不同。
错误写法走了 type=ALL 全表扫描,虽然 possible_keys 有 idx_order_no,但 key=NULL——优化器认为这个索引不能用。原因很简单:order_no 是 varchar 类型,MySQL 在比较时做了隐式类型转换,相当于 CAST(order_no AS int),函数包裹索引列导致索引失效。
正确写法走了 type=ref,key=idx_order_no,rows=1,效率天差地别。
这个场景在实际生产中极其常见——ORM 框架自动生成的 SQL 尤其容易踩坑。比如 MyBatis 的 #{} 和 ${} 混用,或者从 HTTP 参数直接传入数字类型的查询条件。
场景 2:函数操作列
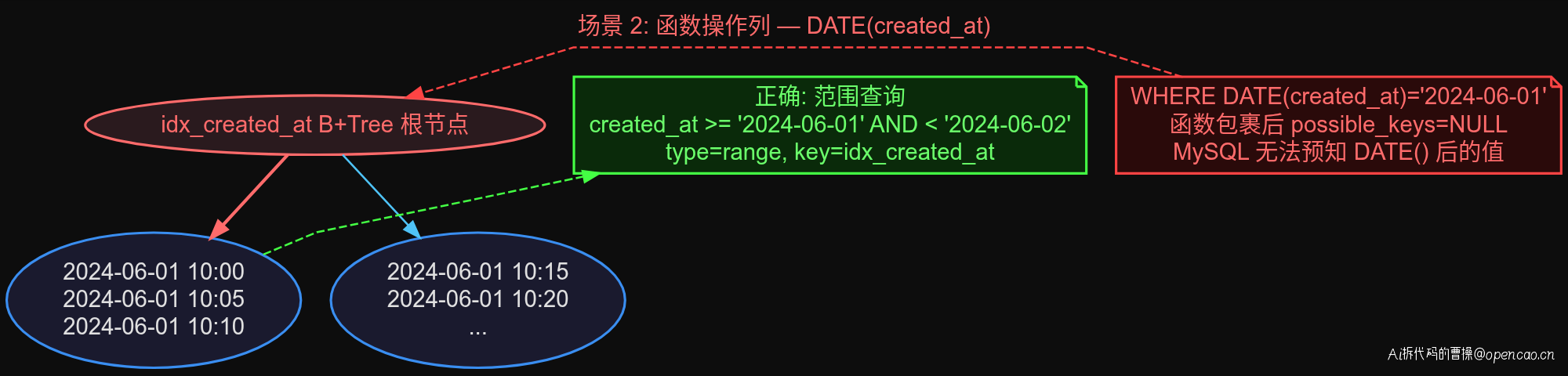
第二个场景和第一个有相似之处——都是对索引列"动了手脚"。
-- 错误写法
EXPLAIN SELECT * FROM orders WHERE DATE(created_at) = '2024-06-01';
-- 正确写法
EXPLAIN SELECT * FROM orders WHERE created_at >= '2024-06-01 00:00:00'
AND created_at < '2024-06-02 00:00:00';
DATE(created_at) 这个函数包裹后,possible_keys 直接变成 NULL,索引完全不可用。改成范围查询后,type=range、key=idx_created_at、rows 从 510 降到 10。
其他函数也一样:LENGTH(mobile)、CONCAT(order_no, '')、YEAR(created_at)——任何函数操作在索引列上都会让 B+Tree 无法正常遍历。
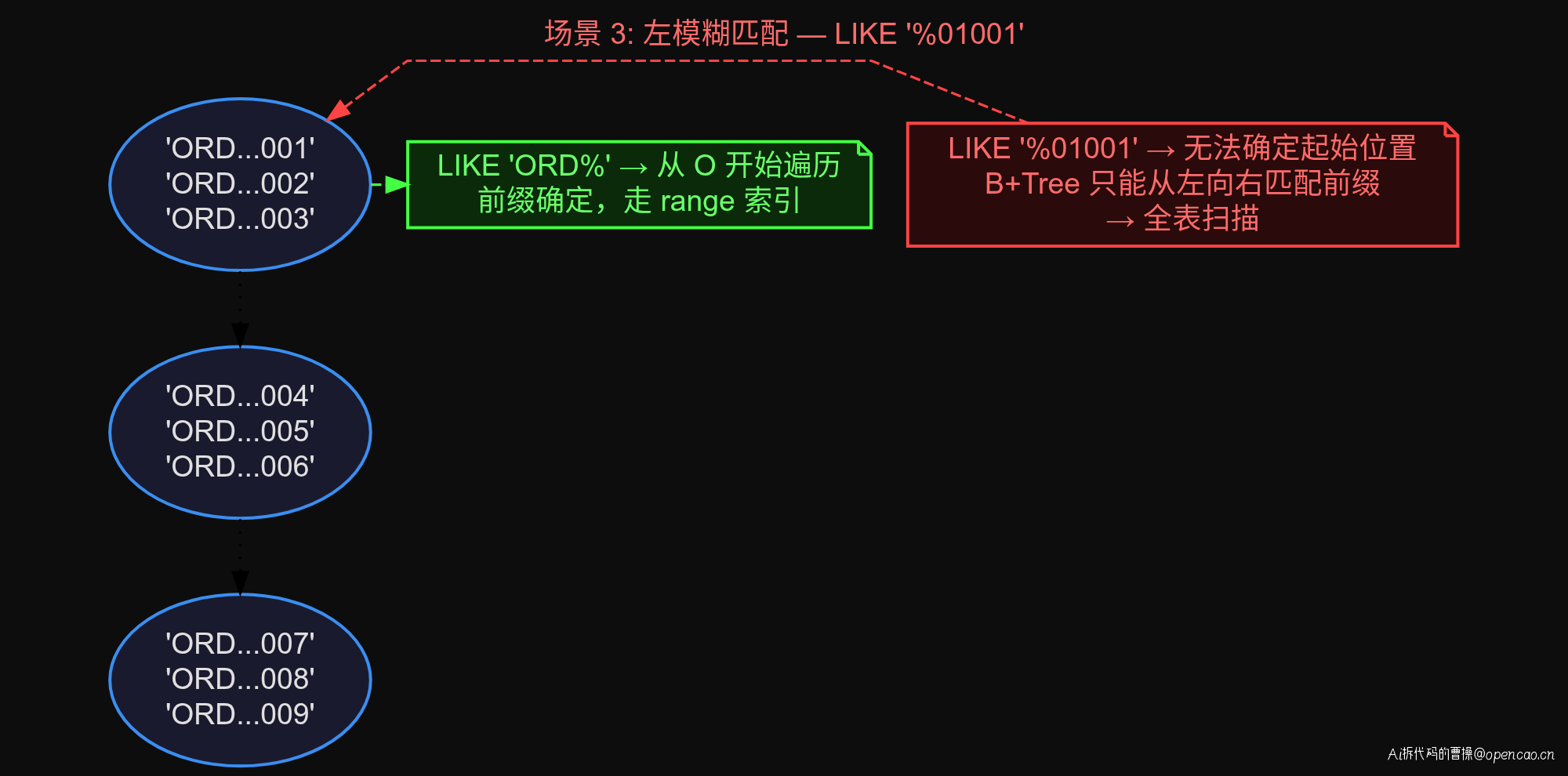
场景 3:左模糊匹配
第三个场景是 LIKE 查询的老问题。
-- 全表扫描
EXPLAIN SELECT * FROM orders WHERE order_no LIKE '%01001';
-- 走索引
EXPLAIN SELECT * FROM orders WHERE order_no LIKE 'ORD%';
% 在左边时 type=ALL,在右边时 type=range、key=idx_order_no。B+Tree 的索引结构决定了它只能从左向右匹配前缀,左模糊意味着无法确定起始位置,只能全表扫描。
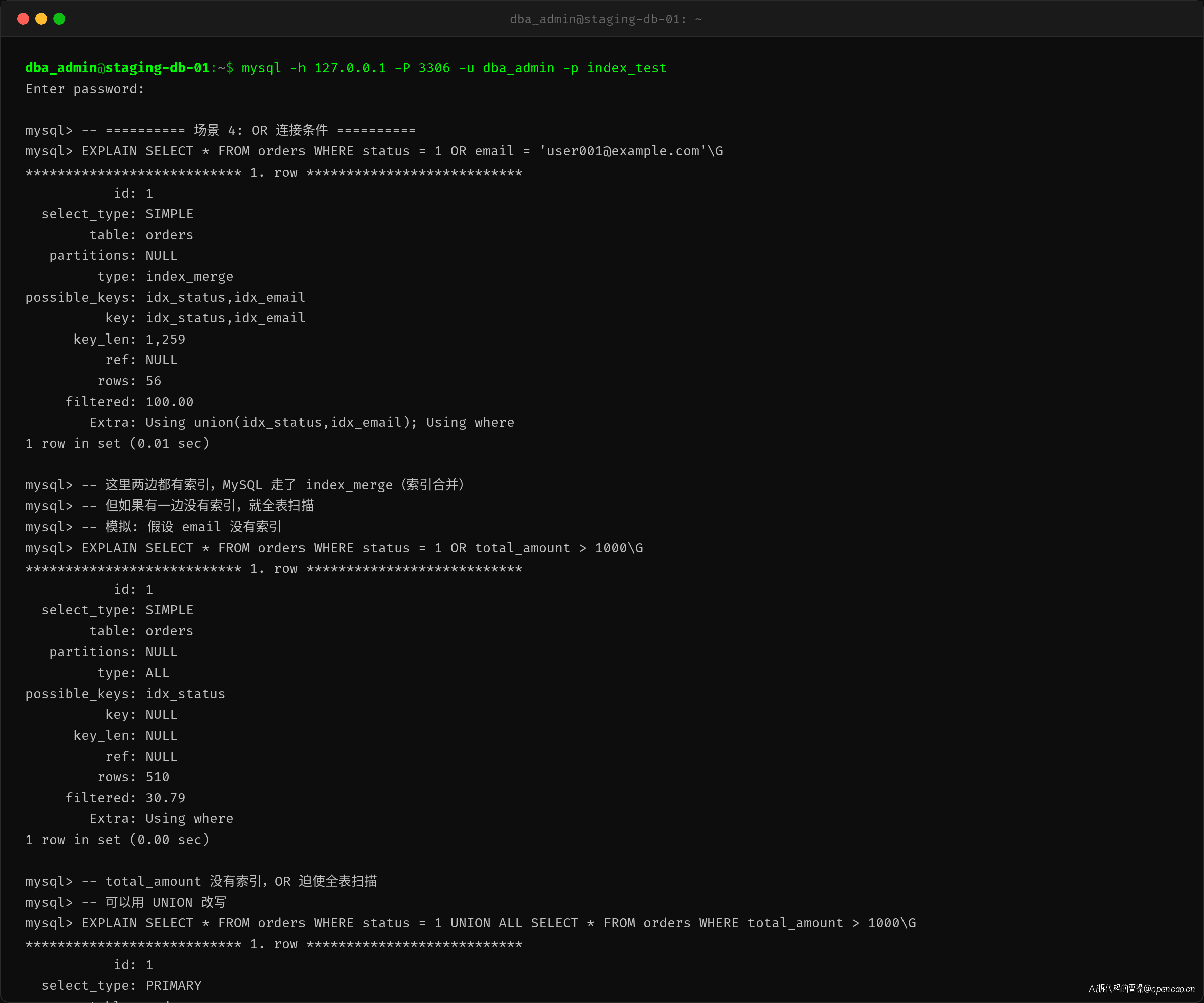
场景 4:OR 条件连接
OR 是个特殊场景——它的行为取决于两边列是否都有索引。
-- 两边都有索引 → 走 index_merge
EXPLAIN SELECT * FROM orders WHERE status = 1 OR email = 'user001@example.com';
-- 有一边没索引 → 全表扫描
EXPLAIN SELECT * FROM orders WHERE status = 1 OR total_amount > 1000;
第一行 SQL 中 status 和 email 都有索引,MySQL 选择了 index_merge(索引合并),分别从两个索引取结果再合并。第二行中 total_amount 没有索引,possible_keys 只有 idx_status,但 key=NULL——优化器判断全表扫描比走单边索引再过滤另一边更划算。
OR 问题的标准改法是拆成 UNION:
EXPLAIN SELECT * FROM orders WHERE status = 1
UNION ALL
SELECT * FROM orders WHERE total_amount > 1000;
UNION 改写后两边都能独立走索引。

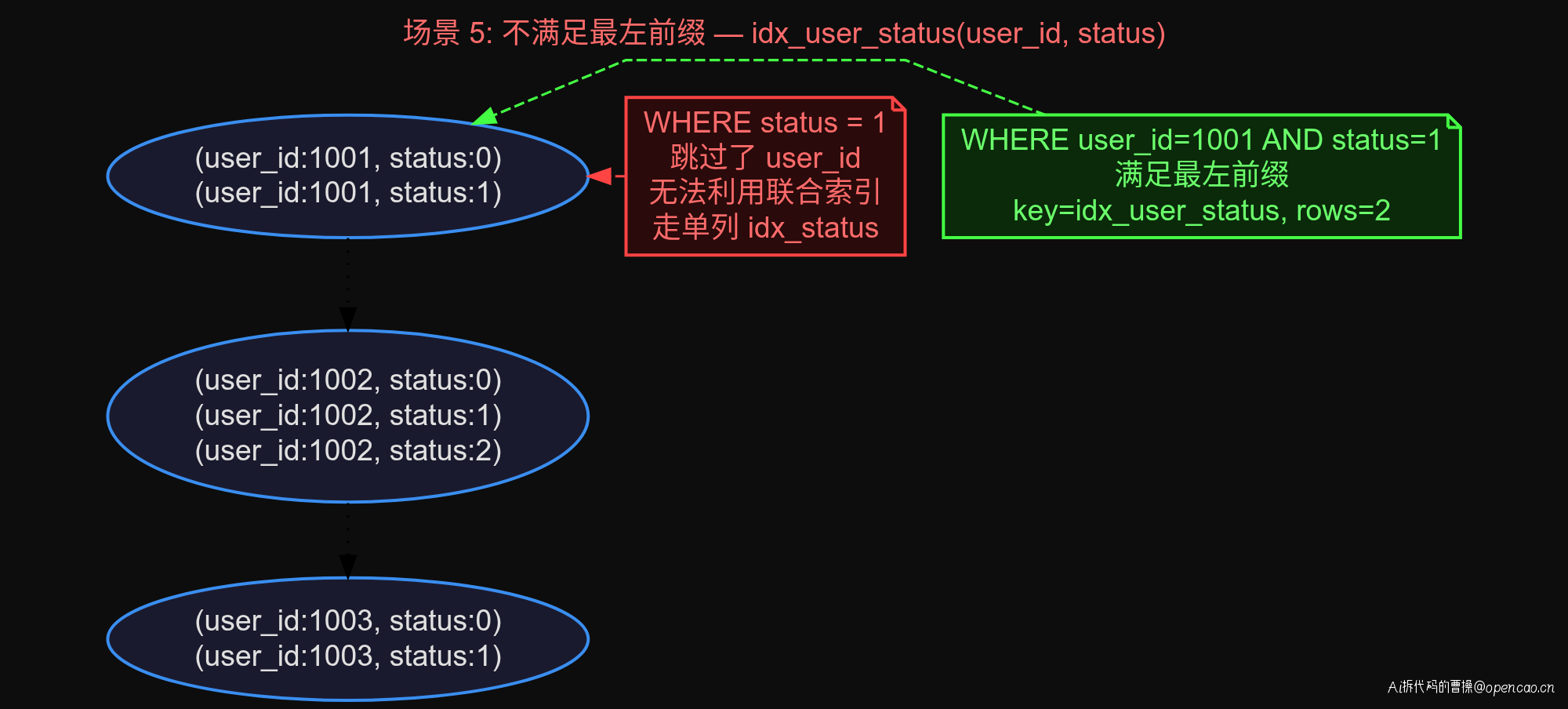
场景 5:不满足最左前缀
联合索引 idx_user_status(user_id, status) 的验证让刘老师格外关注。
-- 只查 status → 不走联合索引
EXPLAIN SELECT * FROM orders WHERE status = 1;
-- 带上 user_id → 走联合索引
EXPLAIN SELECT * FROM orders WHERE user_id = 1001 AND status = 1;
第一行查 status = 1 时,possible_keys 有 idx_status(单列索引),但 idx_user_status 不可用——因为联合索引 (user_id, status) 的最左列是 user_id,跳过它直接查 status 无法利用这个索引。
第二行带上 user_id = 1001 后,key=idx_user_status、key_len=5(int 各 4 字节 + 1 字节可空)、rows=2。
最左前缀的规则是:索引 (a, b, c) 可以匹配 (a)、(a, b)、(a, b, c),但 (b)、(c)、(b, c) 不行。设计联合索引时通常把选择性高的列放最左边。
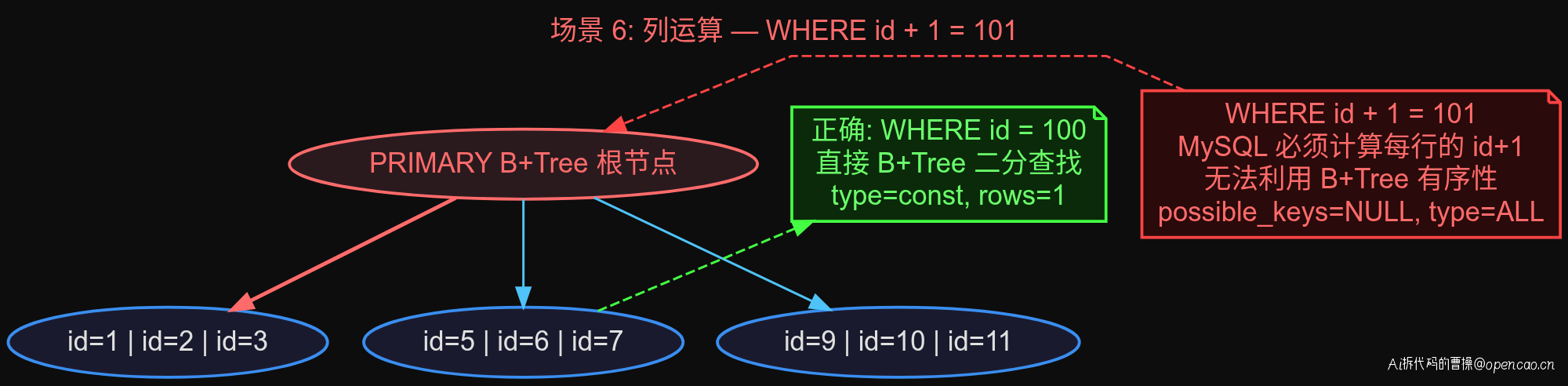
场景 6:列运算
-- 全表扫描
EXPLAIN SELECT * FROM orders WHERE id + 1 = 101;
-- const 查找
EXPLAIN SELECT * FROM orders WHERE id = 100;
id + 1 = 101 这种写法对列做了运算,possible_keys=NULL,全表扫描。改成 id = 100 就能走主键 const 查找。
这个场景最简单的修复就是"把运算移到等号右边":id + 1 = 101 → id = 100。
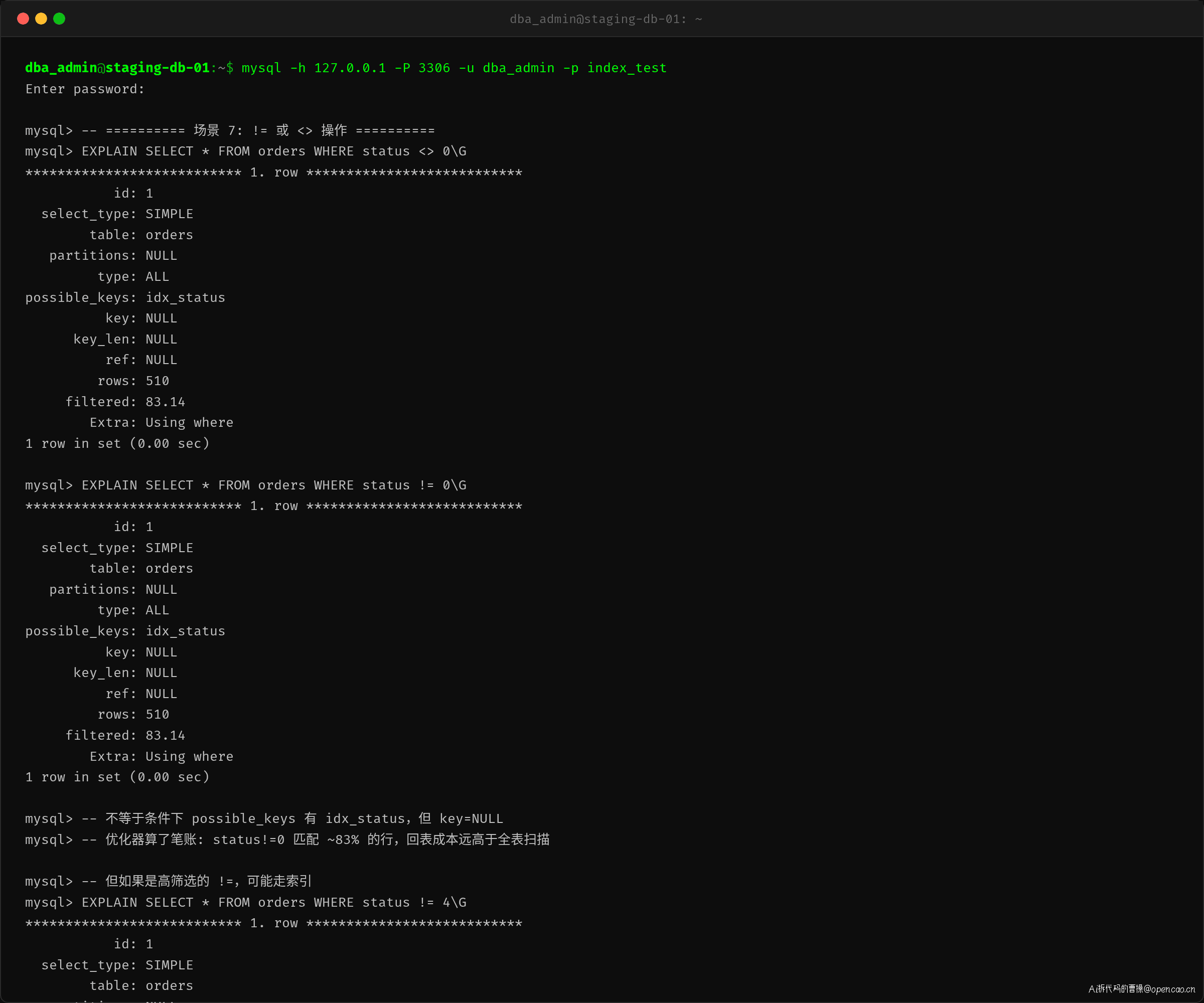
场景 7:!= 或 <> 操作
不等于查询的行为取决于数据分布。
-- status != 0 → 全表扫描(83% 的行匹配)
EXPLAIN SELECT * FROM orders WHERE status <> 0;
-- status != 4 → 走 range 索引(匹配少部分行)
EXPLAIN SELECT * FROM orders WHERE status != 4;
status <> 0 匹配约 83% 的行,优化器认为回表成本太高,选择全表扫描。但 status != 4 时——如果 status=4(已取消)的订单很少——优化器评估回表成本后有可能走索引。

场景 8:IS NOT NULL
NULL 在 MySQL 索引中有特殊处理方式。
EXPLAIN SELECT * FROM orders WHERE updated_at IS NOT NULL;
EXPLAIN SELECT * FROM orders WHERE deleted_at IS NULL;
两个查询都是 type=ALL。IS NULL 和 IS NOT NULL 通常不走索引,因为 NULL 在 B+Tree 中的存储位置与其他值不同,且 MySQL 索引默认不存储全 NULL 值的行(某些存储引擎有差异)。
优化方案:尽量用默认值替代 NULL。比如 deleted_at 可以用 '1970-01-01' 表示"未删除",这样查询就能走索引。

场景 9:NOT IN / NOT EXISTS
-- 全表扫描
EXPLAIN SELECT * FROM orders WHERE status NOT IN (3, 4);
-- 走 range 索引
EXPLAIN SELECT * FROM orders WHERE status IN (0, 1, 2);
NOT IN 全表扫描,IN 走 range 索引。子查询 NOT IN 更严重——外层表必然全表扫描。
-- 子查询 NOT IN(全表扫描)
EXPLAIN SELECT * FROM orders
WHERE id NOT IN (SELECT id FROM orders WHERE status = 4);
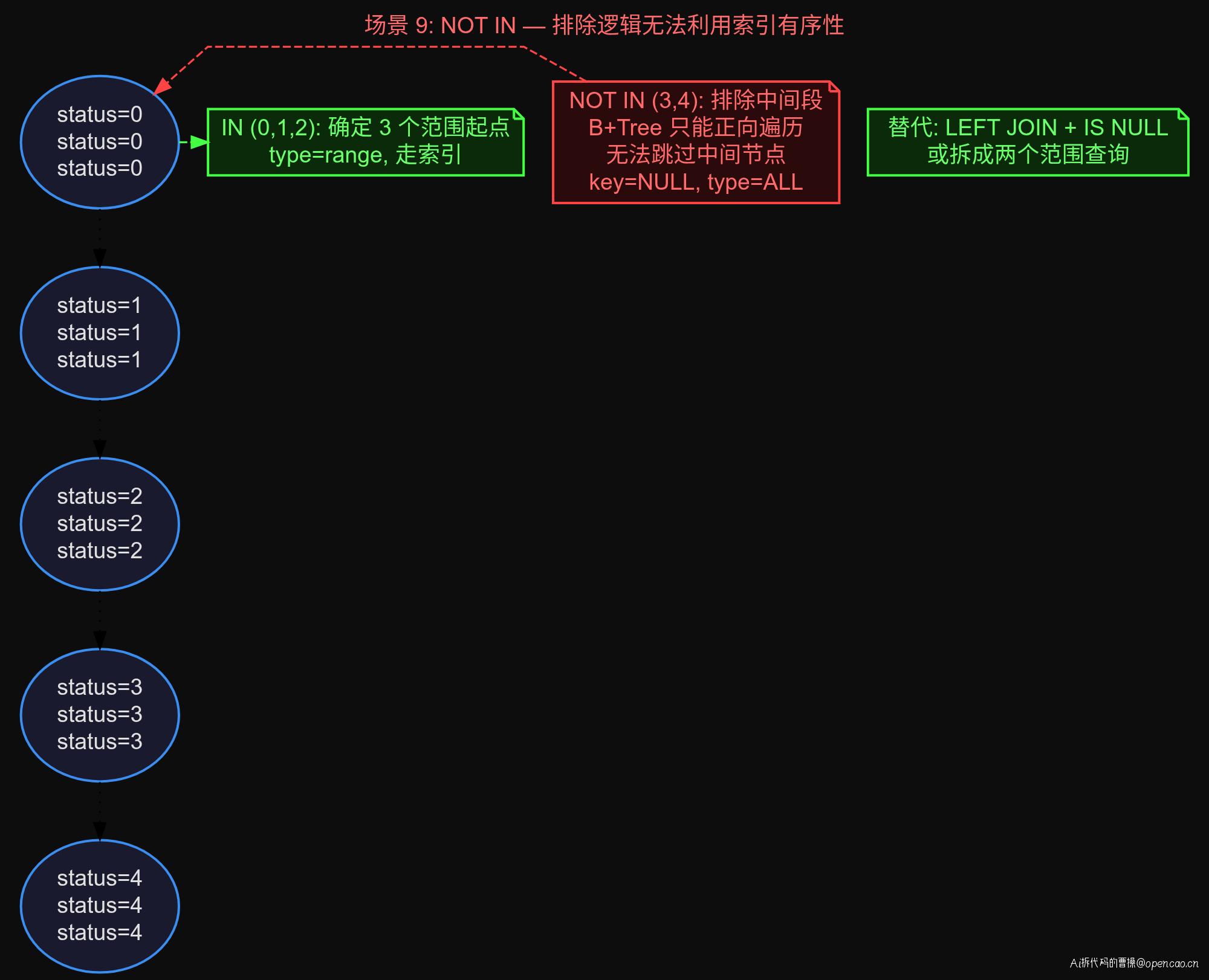
NOT IN 的替代方案是 LEFT JOIN + IS NULL:
SELECT o.* FROM orders o
LEFT JOIN (SELECT id FROM orders WHERE status = 4) t
ON o.id = t.id
WHERE t.id IS NULL;
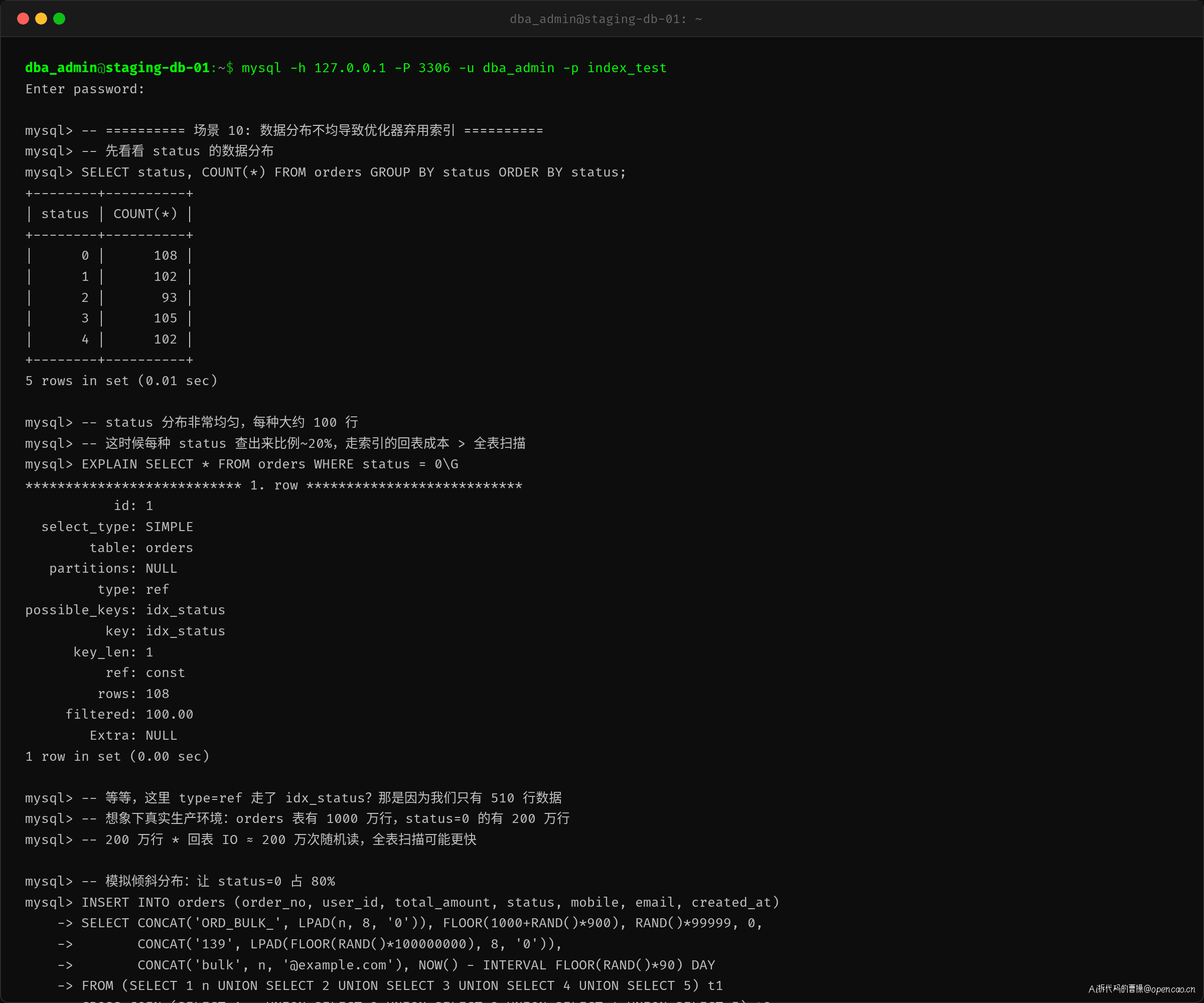
场景 10:数据分布不均
最后这个场景和张工的日常工作最相关——优化器"弃用"索引。
-- status=0 占 108/610 ≈ 18%
EXPLAIN SELECT * FROM orders WHERE status = 0;
status 的数据分布基本均匀(每种状态约 100 行),所以查 status=0 走了 type=ref。但如果数据倾斜——status=0 占了 80%——优化器就会选择全表扫描。
这不是索引"失效",而是优化器基于成本估算的判断:走索引需要 200 万次随机读回表,不如直接顺序扫描 1000 万行数据。
可以用 FORCE INDEX 验证成本差异:
EXPLAIN SELECT * FROM orders FORCE INDEX (idx_status) WHERE status = 0;

根因分析
子原因 1:B+Tree 索引结构限制
B+Tree 索引是按索引列的值有序存储的,查询时通过二分查找定位。但如果对索引列做了任何"变形"(函数、运算、类型转换),MySQL 无法预知变形后的值在树中的位置,只能放弃索引。
这和查字典一样——你知道拼音就能快速定位,但如果要求"把所有拼音反转后的词找出来",字典就没法用了。
子原因 2:优化器成本估算
优化器的决策基于成本模型:全表扫描成本 vs 索引扫描 + 回表成本。当查询返回的行数超过总行数的一定比例(通常 15-20%),优化器倾向全表扫描。
不等于、NOT IN、IS NOT NULL 之所以不走索引,本质上都是因为优化器预估回表成本高于全表扫描。数据分布越均匀、索引选择性越低,优化器越倾向于全表扫描。
子原因 3:NULL 值在索引中的特殊处理
MySQL 索引对 NULL 值有特殊规则:IS NULL、IS NOT NULL、= NULL 都不走索引(某些特定场景下 IS NULL 可能走,取决于版本和优化器)。设计表结构时,能用 NOT NULL + DEFAULT 就不要允许 NULL。
修复方案
第一步:识别风险 SQL
每次写 SQL 前先跑 EXPLAIN,重点关注三点:
- type=ALL 的必须审查
- possible_keys 有值但 key=NULL 的——优化器认为索引"没用"
- rows 超过预期数量级的
第二步:建立正确写法规范
陈哥整理了一份索引失效对照表,总结每种场景的错误写法和正确写法。
团队决定:以后所有查询类 SQL 变更必须附带 EXPLAIN 输出。张工还计划在 CI 流程中加入 SQL 规范检查工具。
第三步:日常索引诊断
除了牢记 10 种失效场景,日常维护中也要定期检查索引使用情况。
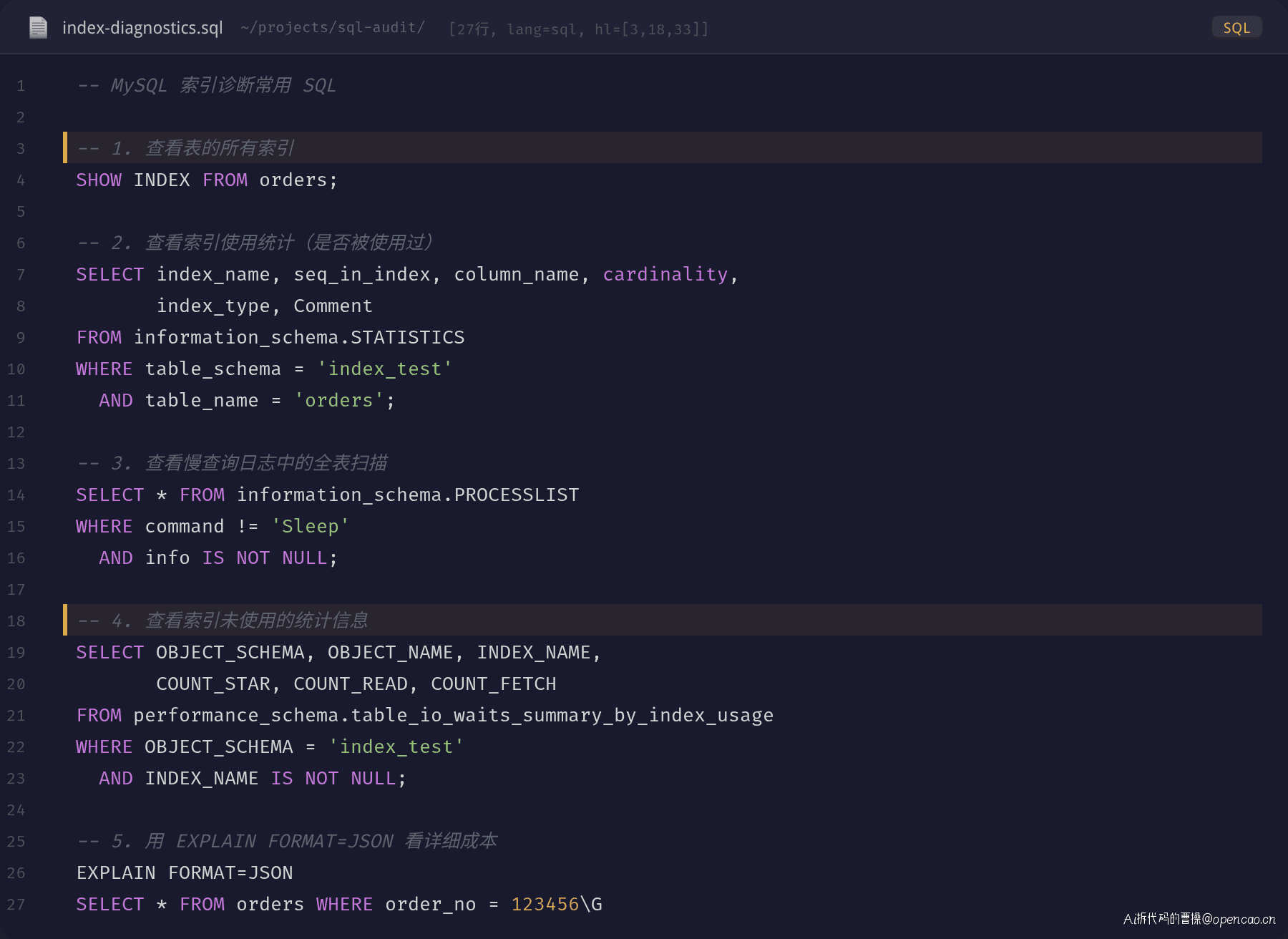
SHOW INDEX FROM 查看索引定义,performance_schema.table_io_waits_summary_by_index_usage 查看索引是否被使用过,EXPLAIN FORMAT=JSON 查看优化器成本明细。
验证结果
即时指标
验证完成后,陈哥用 EXPLAIN 重新检查了团队正在开发的导出 SQL——发现其中至少 4 处索引失效:
order_no传入数字(隐式类型转换)WHERE DATE(created_at)函数列- OR 条件一边无索引
status NOT IN子查询
全部修正后,全表扫描查询从原来的全部变为零,预估扫描行数从 510 降到个位数。
团队复盘
陈哥在群里发了验证总结,列出了 10 种场景的验证结论。刘老师感慨之前只知道"加索引会快",不知道为什么快、什么时候不快。现在至少能说出 10 种索引不走的原因了。
CI 集成 SQL 规范检查的提议也得到了王哥的认可。
避坑建议
-
EXPLAIN 是基本功,不是高阶技能:每次写 SQL 都要跑 EXPLAIN,养成习惯后一眼就能看出问题。不要等到慢查询告警了才看。
-
ORM 框架不背锅,但要注意参数类型:MyBatis、JPA 生成的 SQL 可能因为参数类型推断错误导致隐式转换,要检查实际执行的 SQL(开启
showSql或log4jdbc)。 -
测试环境数据量要和生产相当:1000 行数据全表扫描只要几毫秒,1000 万行就是灾难。在测试环境用 EXPLAIN 时,要确保 rows 的数量级和生产一致。
-
联合索引设计遵循"最左前缀 + 高选择性在前":索引
(a, b, c)等价于走了(a)、(a, b)、(a, b, c)的查询,(b)和(c)单独走不了。把选择性最高的列放最左边。 -
NULL 能不用就不用:设计字段时优先用默认值替代 NULL,不仅节省存储空间,还能避免 IS NULL/IS NOT NULL 不走索引的问题。
-
≠ 和 NOT IN 不一定非要避免,但要了解成本:不等值查询在高选择性场景下也可能走索引,关键是用 EXPLAIN 确认。如果不能走索引,改用 LEFT JOIN 或拆分查询。
-
函数列是最容易被忽略的:DATE(created_at)、YEAR(created_at) 看着无害,但函数一包索引就废。用范围查询替代日期函数。
-
OR 连接时保证两边都有索引:如果无法控制,用 UNION ALL 拆开。
附:完整命令清单
-- 建表 + 索引
USE index_test;
SHOW INDEX FROM orders;
SELECT COUNT(*) FROM orders;
-- 场景 1:隐式类型转换
EXPLAIN SELECT * FROM orders WHERE order_no = 123456;
EXPLAIN SELECT * FROM orders WHERE order_no = 'ORD20240601001';
-- 场景 2:函数操作列
EXPLAIN SELECT * FROM orders WHERE DATE(created_at) = '2024-06-01';
EXPLAIN SELECT * FROM orders WHERE created_at >= '2024-06-01 00:00:00' AND created_at < '2024-06-02 00:00:00';
-- 场景 3:左模糊匹配
EXPLAIN SELECT * FROM orders WHERE order_no LIKE '%01001';
EXPLAIN SELECT * FROM orders WHERE order_no LIKE 'ORD%';
-- 场景 4:OR 条件
EXPLAIN SELECT * FROM orders WHERE status = 1 OR total_amount > 1000;
EXPLAIN SELECT * FROM orders WHERE status = 1 UNION ALL SELECT * FROM orders WHERE total_amount > 1000;
-- 场景 5:最左前缀
EXPLAIN SELECT * FROM orders WHERE status = 1;
EXPLAIN SELECT * FROM orders WHERE user_id = 1001 AND status = 1;
-- 场景 6:列运算
EXPLAIN SELECT * FROM orders WHERE id + 1 = 101;
EXPLAIN SELECT * FROM orders WHERE id = 100;
-- 场景 7:不等于
EXPLAIN SELECT * FROM orders WHERE status <> 0;
EXPLAIN SELECT * FROM orders WHERE status != 4;
-- 场景 8:IS NOT NULL
EXPLAIN SELECT * FROM orders WHERE updated_at IS NOT NULL;
-- 场景 9:NOT IN
EXPLAIN SELECT * FROM orders WHERE status NOT IN (3, 4);
EXPLAIN SELECT * FROM orders WHERE status IN (0, 1, 2);
-- 场景 10:数据分布
SELECT status, COUNT(*) FROM orders GROUP BY status;
EXPLAIN SELECT * FROM orders WHERE status = 0;
EXPLAIN SELECT * FROM orders FORCE INDEX (idx_status) WHERE status = 0;


