
Kafka 消费组运维:一个参数没配好集群崩了
本文是消息中间件故障排除系列的第二篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
告警触发
某日早高峰,订单履约系统上线了"批量处理优化 v2",将 Kafka 消费者单次拉取的消息数从 500 提升到 5000,期望减少网络往返提升吞吐。上线不到 15 分钟,SRE 值班群连续收到三条 P0 告警——消费组 order-fulfillment 的重平衡频率飙到 1420 次/小时(阈值 50),Kafka Broker CPU 冲到 99.7%,可用内存仅剩 456MB。
告警内容显示,order-status 主题每个分区的滞后量(LAG)达到 10 万以上,且持续增长。这意味着消费者已经跟不上生产者的写入速度,消息在 Broker 上越积越多。
上机排查遇阻
张工(值班 SRE)第一时间 SSH 到 Kafka Broker 机器,top 输出触目惊心:
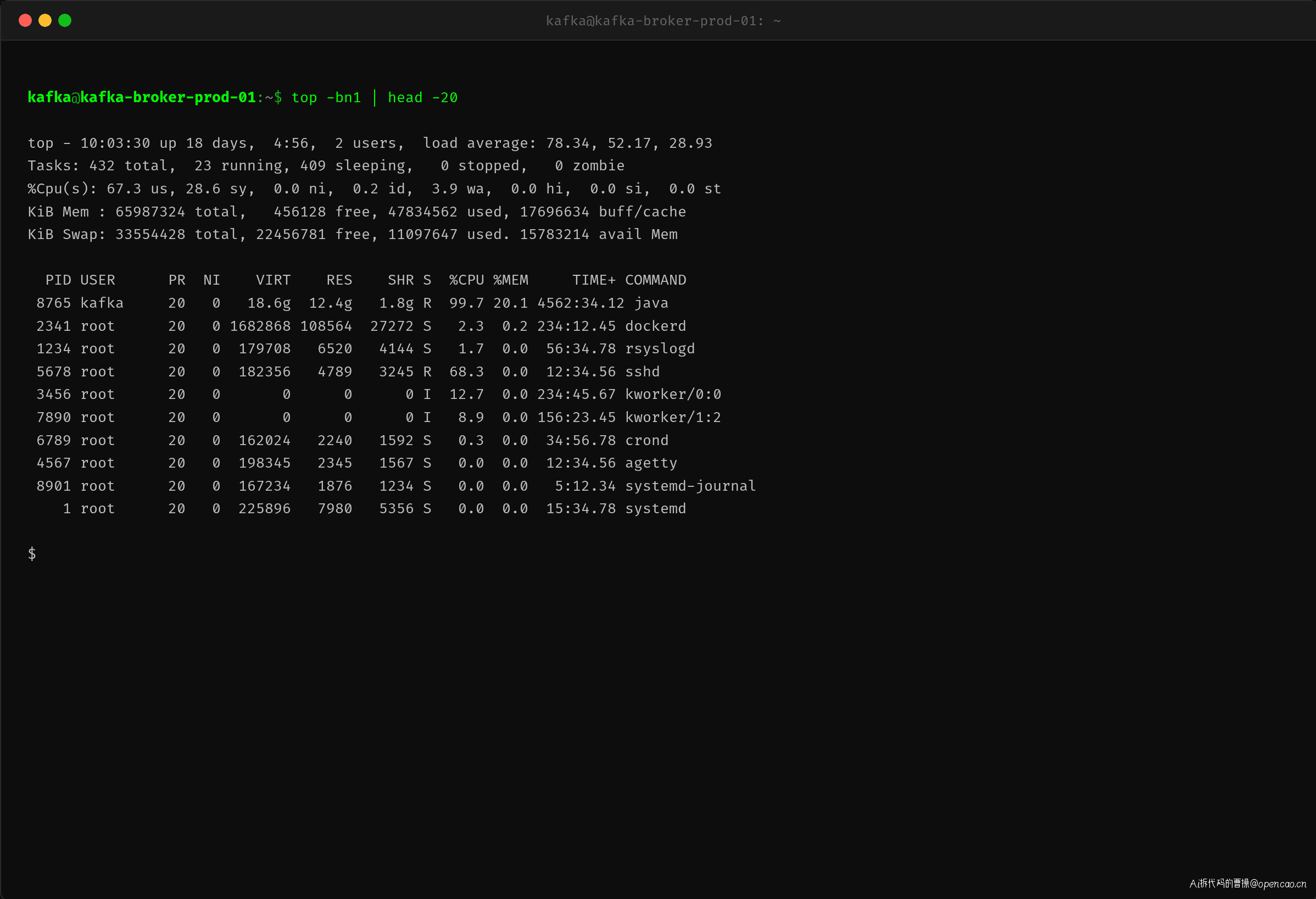
CPU 空闲率只有 0.2%,系统负载 78.34——对于一个 32 核的 Broker 来说,这是一个已经失压的数字。Kafka 进程(PID 8765)占用了 99.7% 的 CPU。但更值得注意的是 %sys 达到了 28.6%,远超正常的 5-10%,说明大量 CPU 消耗在内核态——上下文切换和中断处理。
vmstat 进一步印证了这个判断:
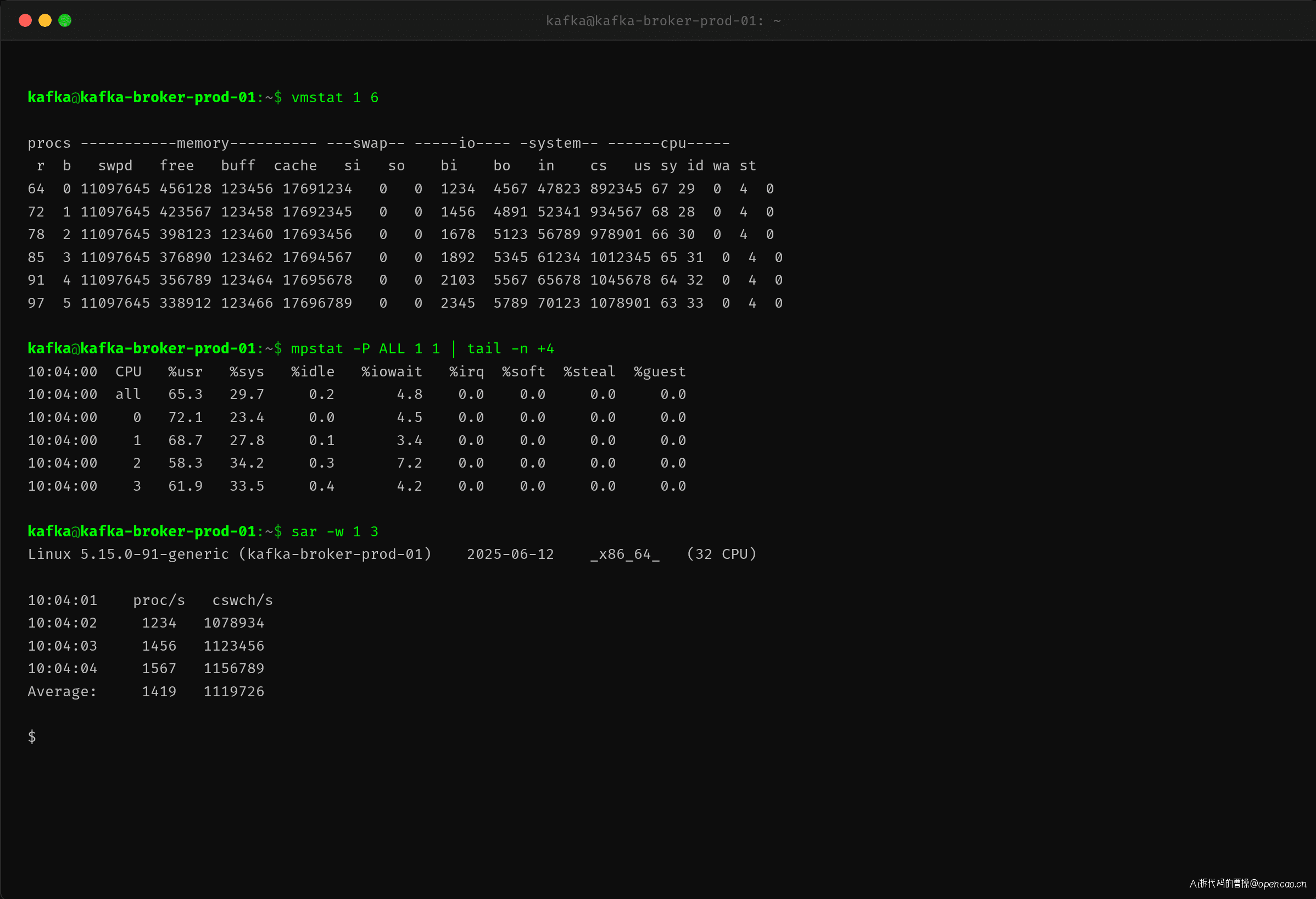
上下文切换(cs)突破了 100 万/秒,最高达到 115 万/秒。正常情况下,一个 32 核的 Kafka Broker 上下文切换在 5-10 万/秒。115 万意味着系统绝大部分时间都在切换线程而不是执行实际业务逻辑。r 列(运行队列)高达 97,说明有大量线程在竞争 CPU,但只有 32 个核可用,形成了严重的线程饥饿。
sar 的 CPU 分解也显示 %sys 占比 33%,印证了内核开销异常。
初步猜测
三个核心观察:rebalance 频率异常、CPU 系统态占比高、上下文切换百万级。这些现象指向同一个方向——消费者组的重平衡风暴。
正常情况下,消费组只有在成员加入或离开时才触发重平衡,一天几十次。1420 次/小时意味着每分钟 23 次重平衡,平均不到 3 秒一次。每个重平衡涉及 JoinGroup 请求、分区分配计算、SyncGroup 同步,对 Group Coordinator 形成持续压力。
但问题是:是什么触发了如此密集的重平衡?
排查过程
第一步:确认消费组状态
张工用 kafka-consumer-groups 命令查看 order-fulfillment 消费组的状态:
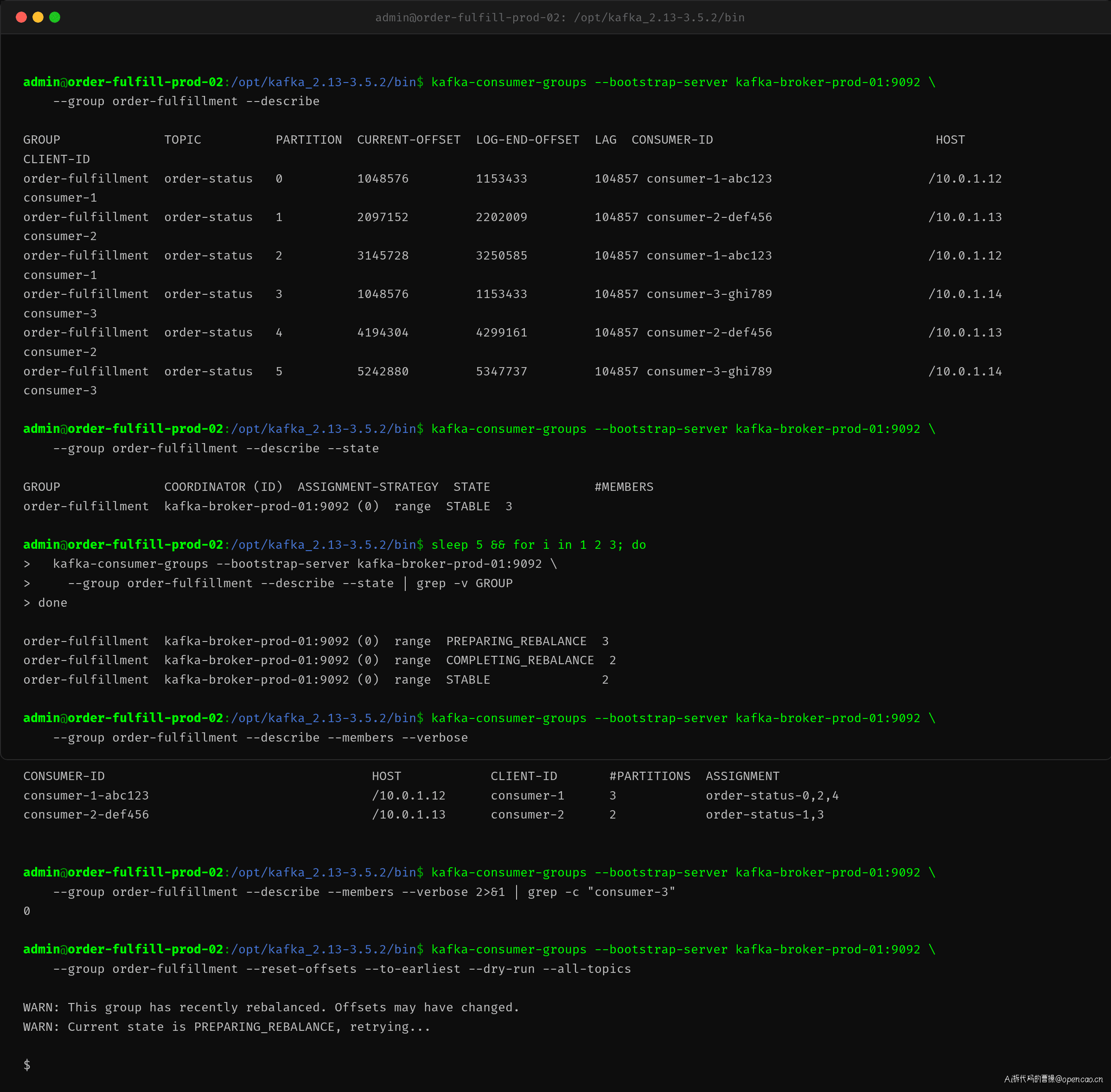
消费组在 PREPARING_REBALANCE 和 STABLE 之间反复横跳。每隔几秒查询一次,状态都不相同。成员列表显示只有 2 个消费者在线,第三个消费者(consumer-3)已经消失——被 Coordinator 踢出了群组。
第二步:查看应用日志
切换到消费者应用所在的 order-fulfill-prod-02 机器,查看应用日志:
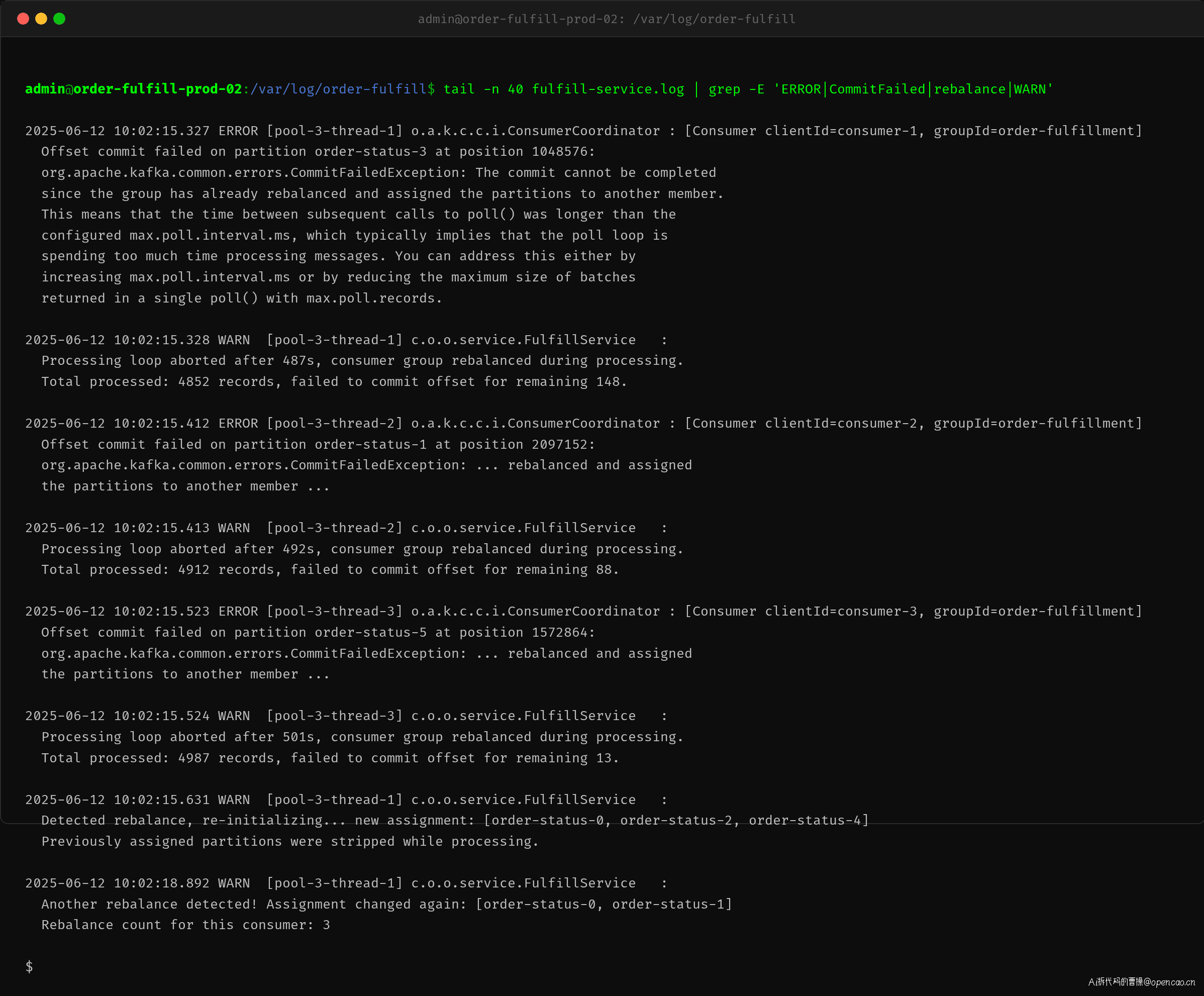
日志中有大量 CommitFailedException 报错,错误信息直接告诉了我们原因:
The commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms.
max.poll.interval.ms 的默认值是 300000ms(5 分钟)。消费者每次 poll() 后处理一批消息的时间超过了这个限制,Coordinator 判定该消费者已死,将其踢出并触发重平衡。
从日志可以看到,每个消费者每次 poll 拉取了 4852-4987 条消息,处理耗时在 487-501 秒之间,远超 300 秒的限制。
第三步:Broker 端确认 JoinGroup 风暴
回到 Broker 机器查看 Coordinator 日志:
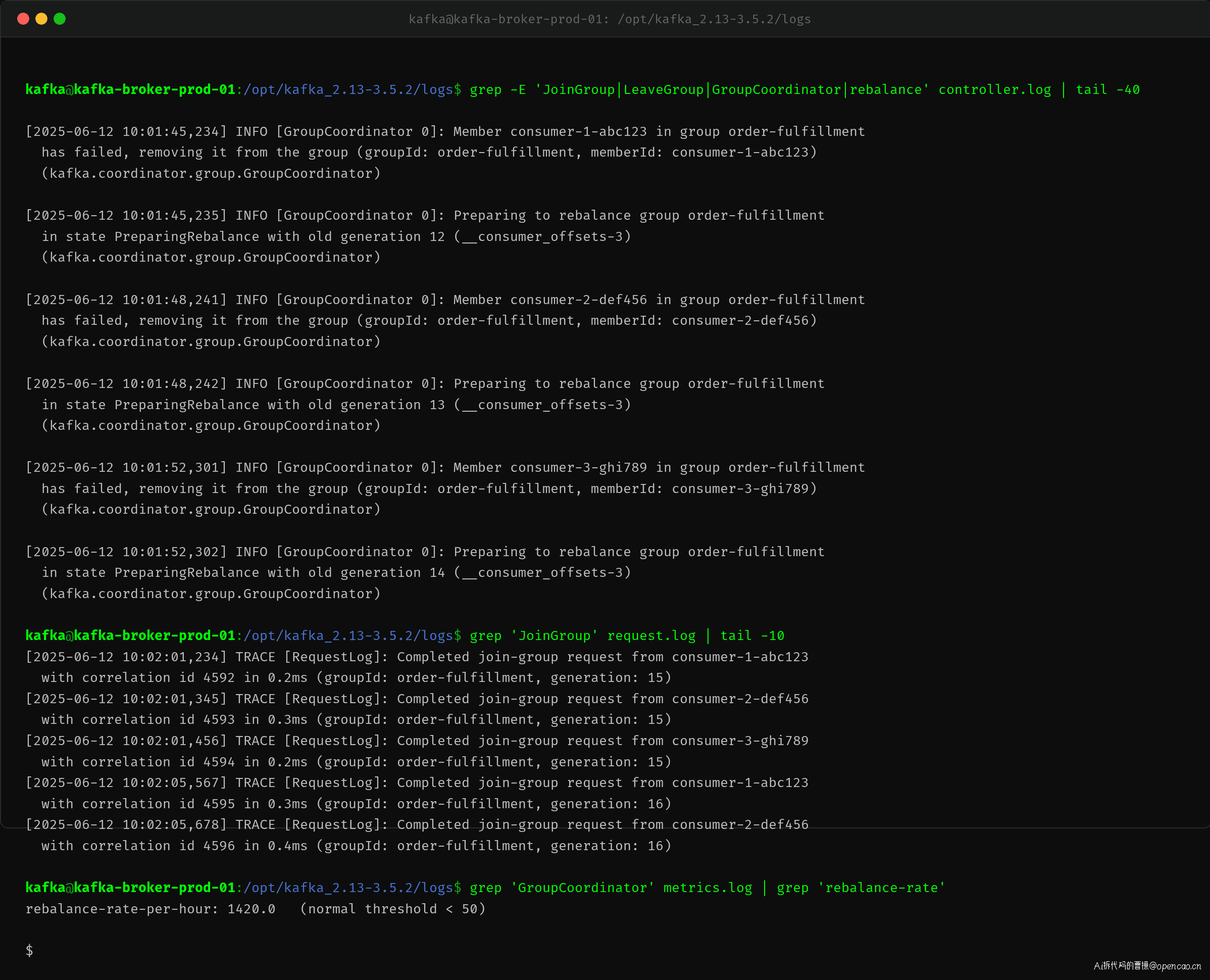
GroupCoordinator 日志清晰记录了重平衡风暴的每个关键节点:
Member consumer-1 in group order-fulfillment has failed, removing it from the group
Preparing to rebalance group order-fulfillment in state PreparingRebalance with old generation 12
Member consumer-2 in group order-fulfillment has failed, removing it from the group
Preparing to rebalance group order-fulfillment in state PreparingRebalance with old generation 13
Member consumer-3 in group order-fulfillment has failed, removing it from the group
Preparing to rebalance group order-fulfillment in state PreparingRebalance with old generation 14
generation 在短短几分钟内从 12 飙升到 16+,每次 generation 变化都意味着一次完整的重平衡流程。request.log 中 JoinGroup 请求的追踪日志也表明,每个 generation 都产生了大量的 JoinGroup/SyncGroup 往返。
更严重的是指标:rebalance-rate-per-hour: 1420.0,正常阈值是 50。
第四步:定位消费者配置
既然问题出在 max.poll.interval.ms 超限,下一步就是查看消费者端的配置:
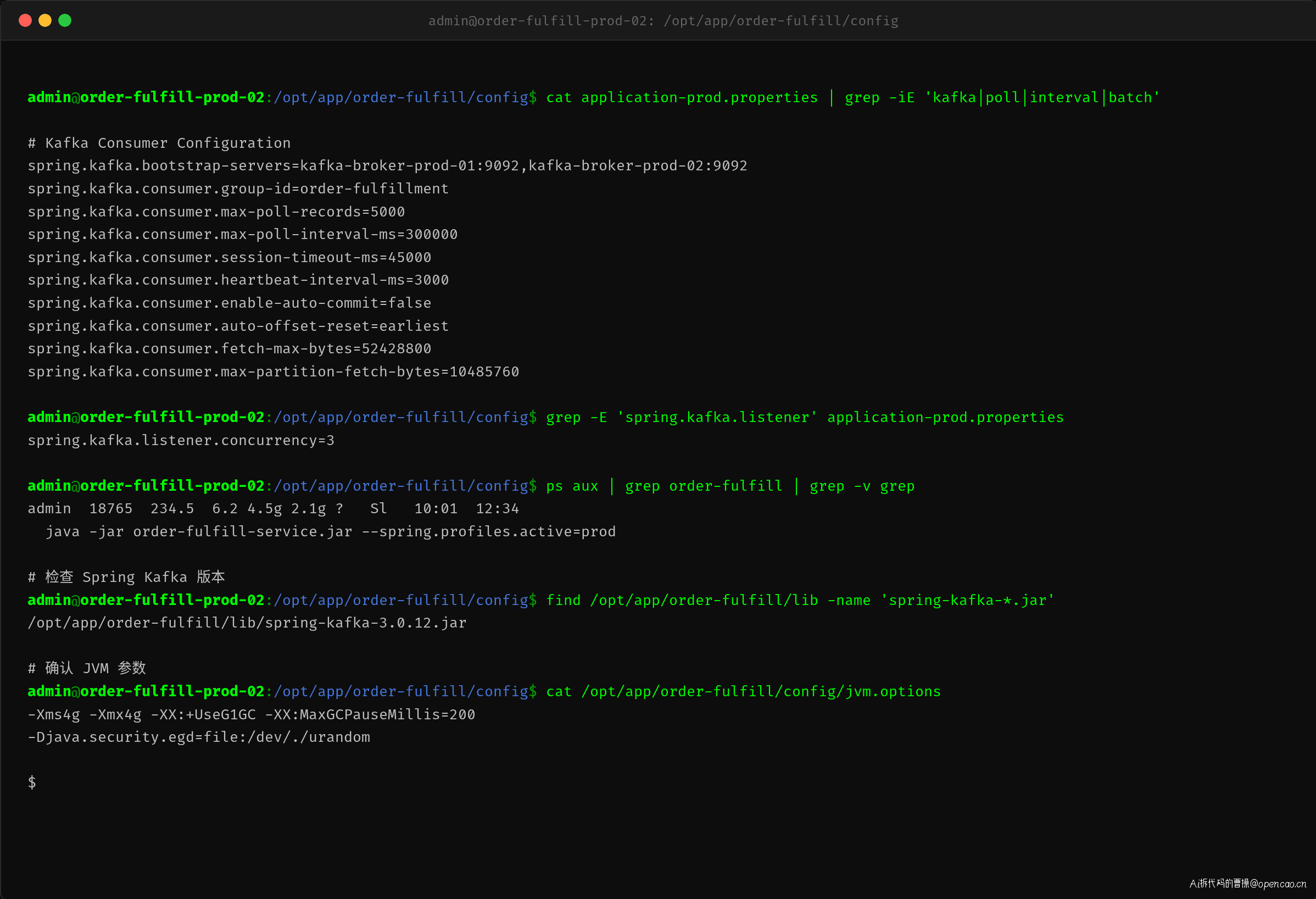
application-prod.properties 中 max.poll.records=5000 是明显的问题配置。默认值 500 被调高了 10 倍,但 max.poll.interval.ms 仍然是默认的 300000ms。
同步查看 Consumer 配置代码:
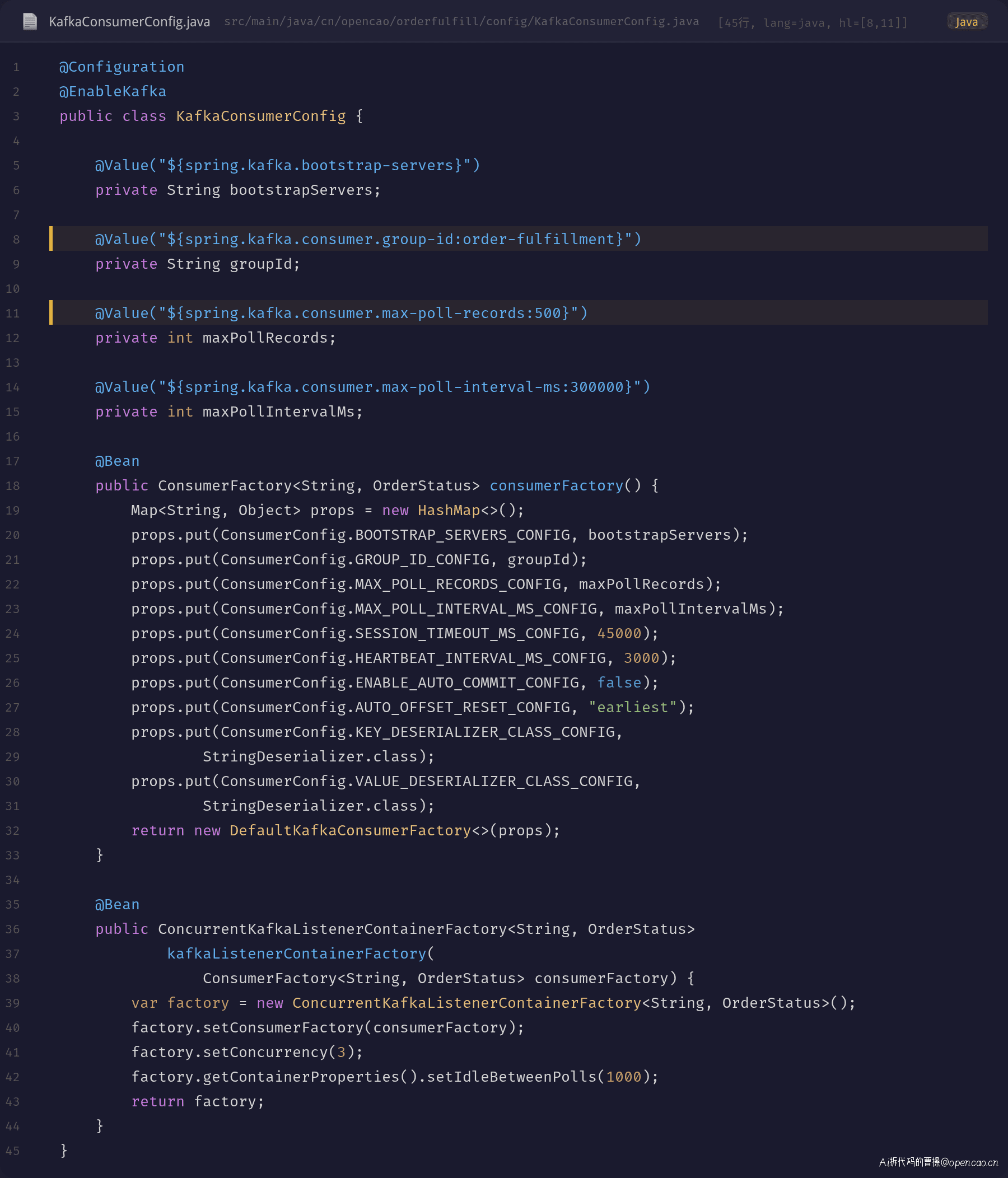
代码中的 maxPollRecords 和 maxPollIntervalMs 都是从配置读取的,说明运维层面有调整入口,但实际配置时只改了 batch size 忘了调 interval。
第五步:排查级联影响
查看其他消费组的状态,发现影响面比想象的更大:
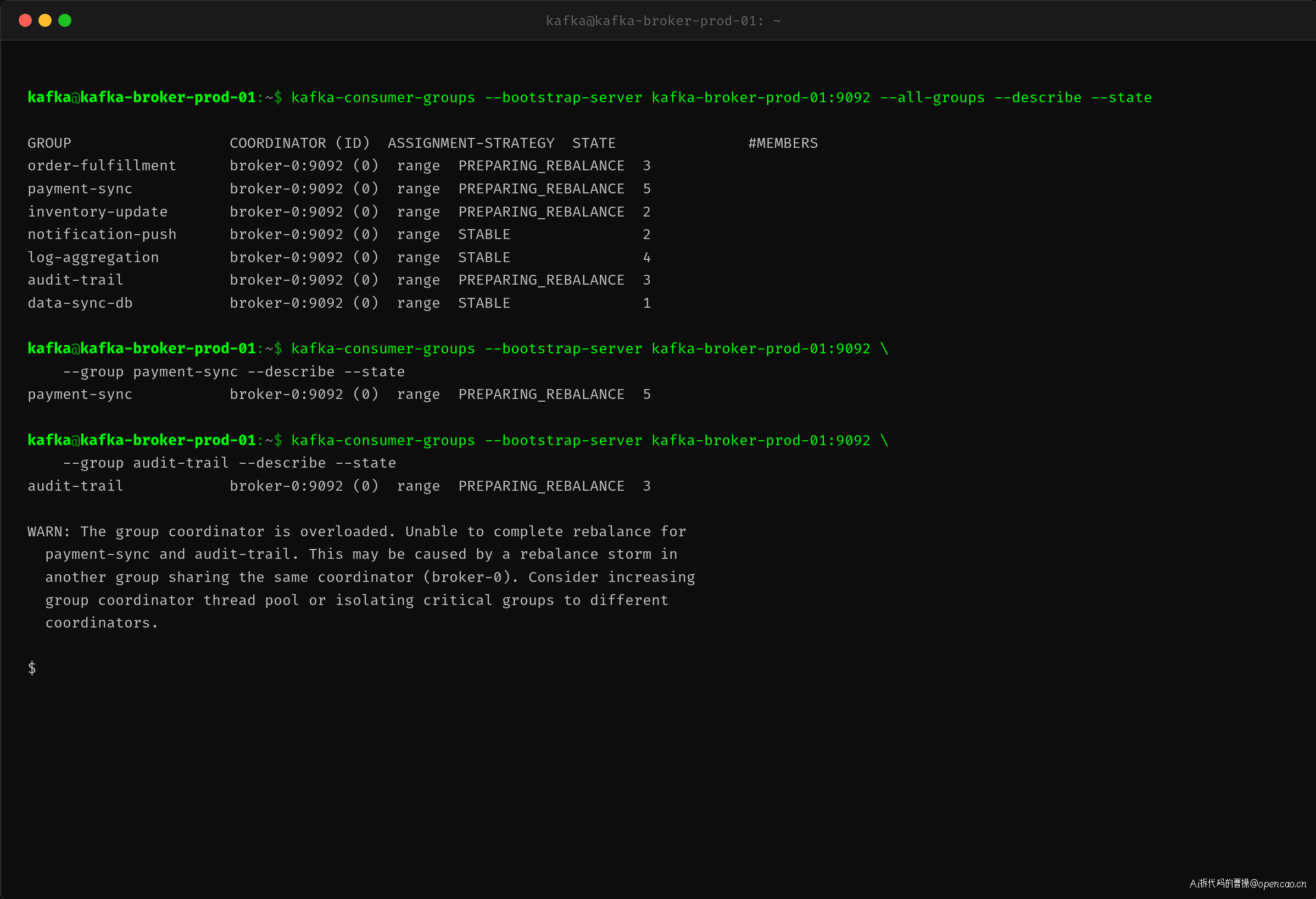
payment-sync 和 audit-trail 两个消费组也进入了 PREPARING_REBALANCE 状态。它们的 Group Coordinator 同样是 broker-0——Coordinator 线程池被 order-fulfillment 的重平衡风暴占满,导致其他组的正常心跳得不到及时处理,跟着超时。
jstack 分析进一步确认了 Coordinator 线程池过载:
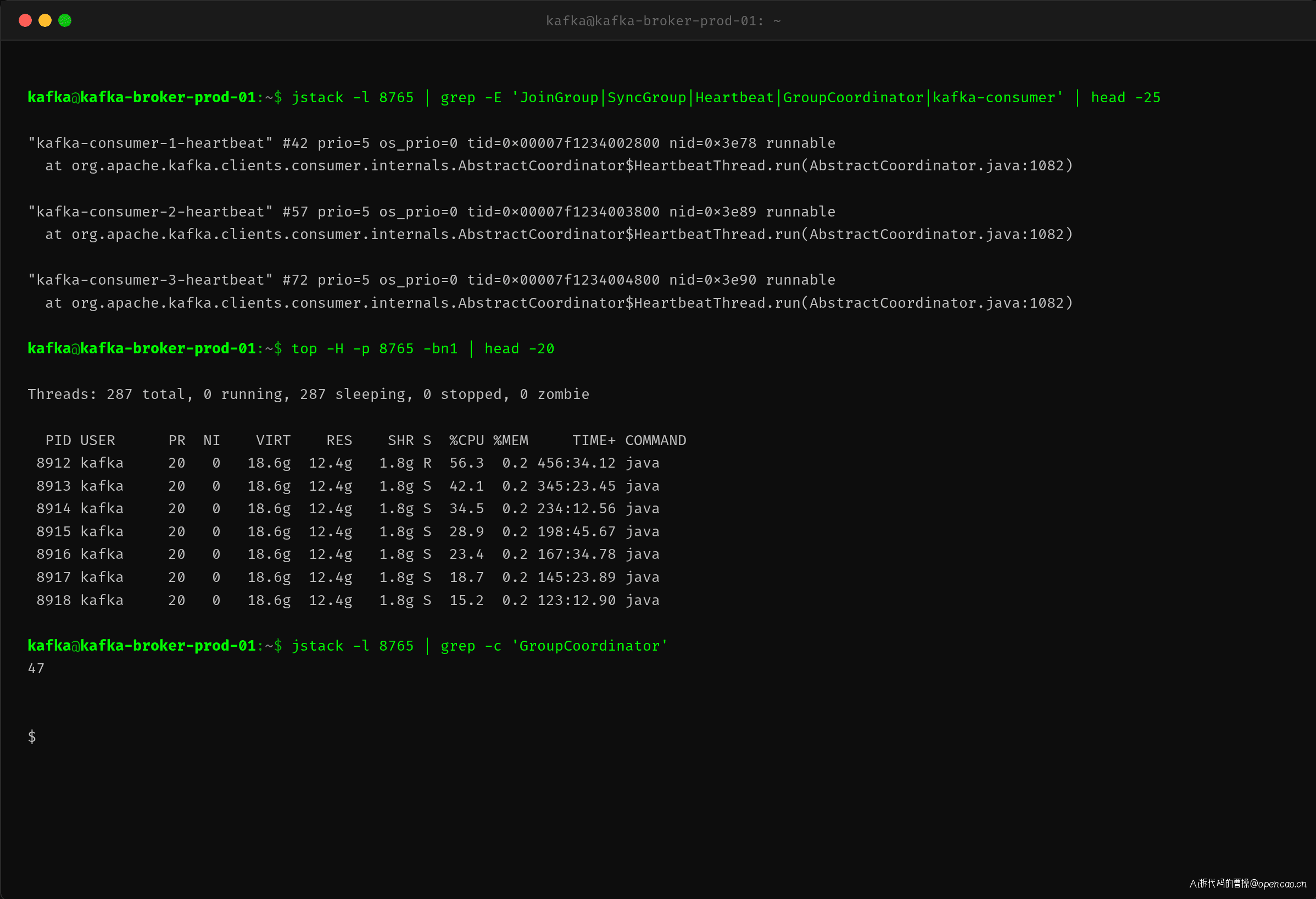
47 个线程阻塞在 GroupCoordinator 操作上,top -H 显示 Kafka 进程内部的热点线程全部集中在 Coordinator 处理上。
根因分析
原因一:max.poll.records 与 max.poll.interval.ms 失配
直接原因很明确:max.poll.records=5000 远大于默认值 500,而 max.poll.interval.ms 保持默认 300000ms(5分钟)。
我们来算一笔账:
- 单条消息处理时间:约 100ms(包括业务逻辑 + DB 写入 + 下游 RPC)
- 每批 5000 条:5000 × 100ms = 500,000ms = 500 秒 = 8.3 分钟
max.poll.interval.ms限制:300 秒 = 5 分钟- 差额:8.3 分钟 - 5 分钟 = 3.3 分钟
消费者每次 poll 后处理 5000 条需要 8.3 分钟,但在第 5 分钟时 Coordinator 已经收不到 poll 请求,将消费者标记为 Dead。消费者还在处理消息,处理完后调用 commitSync() 发现 group 已经 rebalance,抛出 CommitFailedException。
这个计算在代码变更前就应该做,但团队只关注了"单次拉取更多消息减少网络开销"这个收益,忽略了对处理耗时的影响。
原因二:Rebalance 的级联放大效应
当一个消费者被踢出后,触发重平衡,该消费者的分区被分配给剩下的成员。以 6 分区 3 消费组为例:
- 正常:每人负责 2 个分区,每批处理 5000 × 2 = 10000 条(当然实际取决于分区分配策略)
- 1 个被踢:剩下 2 人分 6 个分区,每人 3 个分区
- 每人处理的记录数变成了 3 × 5000 = 15000 条
- 处理时间从 8.3 分钟变成 12.5 分钟
- 超时更严重,继续被踢
- 只剩 1 人:6 个分区 × 5000 = 30000 条,需要 25 分钟
这就是重平衡风暴的恶性循环:一个消费者超时 → 重平衡 → 剩余消费者负荷增加 → 处理时间更长 → 更多消费者超时 → 更频繁的重平衡。
我们的案例中这轮循环在 3 个 consumer 之间反复上演,generation 从 12 跳到 16 只用了 5 分钟。
原因三:Group Coordinator 成为瓶颈
每个消费组的协调者(Group Coordinator)是 Broker 上的一个逻辑组件,负责管理消费组的成员关系、心跳检测、触发重平衡、执行分区分配。
在重平衡风暴中,Coordinator 的工作负载呈指数增长:
- 每次重平衡:接收 N 个 JoinGroup 请求 + 计算分区分配 + 发送 N 个 SyncGroup 响应
- 如果 N 个 consumer 频繁超时(每个独立),Coordinator 需要为每个 consumer 的离开/加入分别触发重平衡
- Coordinator 线程池被占满后,无法及时处理心跳请求
- 原本正常心跳的 consumer 因为心跳超时被踢出,进一步放大风暴
Broker 的 %sys CPU 占比 33% 正是这个原因——GroupCoordinator 处理的 JoinGroup/SyncGroup 请求涉及大量网络 I/O 和锁操作,这些都会消耗系统态 CPU。
原因四:Broker 端 group.max.session.timeout.ms 限制了消费者调参
Broker 端的 group.max.session.timeout.ms=300000 是另一个隐藏限制。
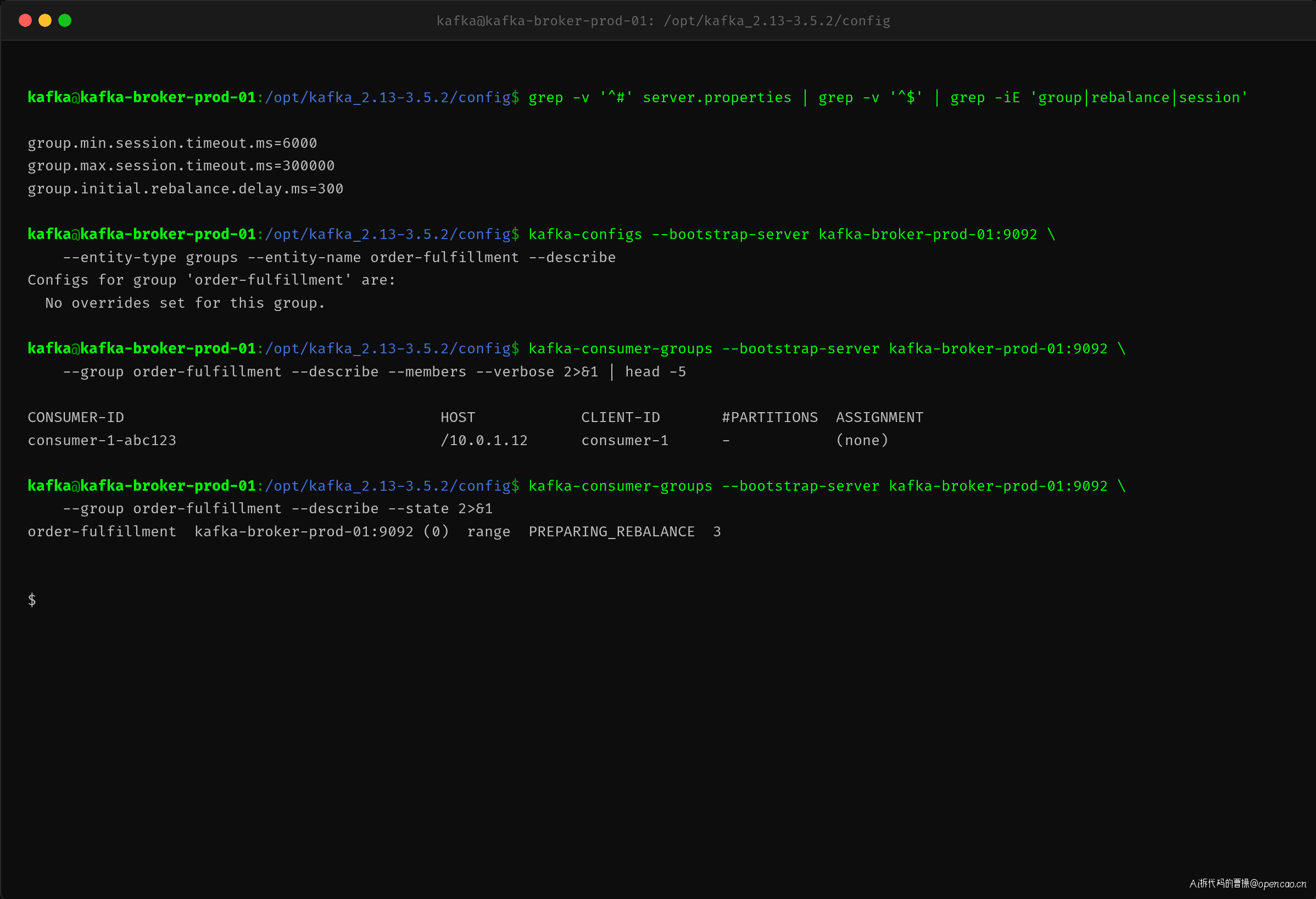
消费者端可以配置的 max.poll.interval.ms 和 session.timeout.ms 不能超过 Broker 端的 group.max.session.timeout.ms。这意味着即使运维团队想直接把 max.poll.interval.ms 设成 600000ms(10 分钟),也会被 Broker 拒绝,收到类似 Invalid session timeout 的错误。Broker 端的配置不调整,消费者端的调参空间就受限。
原因五:缺乏隔离性,单一消费组拖垮集群
最严重的问题在于 Broker 上所有消费组的 GroupCoordinator 共享同一个线程池。order-fulfillment 的重平衡风暴占满了 Coordinator 线程池,导致共享同一协作者的 payment-sync 和 audit-trail 也出现心跳超时。
这意味着一个团队的错误配置不仅影响了自己的消费组,还造成了跨业务线的事故——这正是"一个参数没配好,集群崩了"的真实含义。
修复方案
第一步:紧急止血
立即将 max.poll.records 恢复到 500,同时将 max.poll.interval.ms 调整为 600000ms(10 分钟):
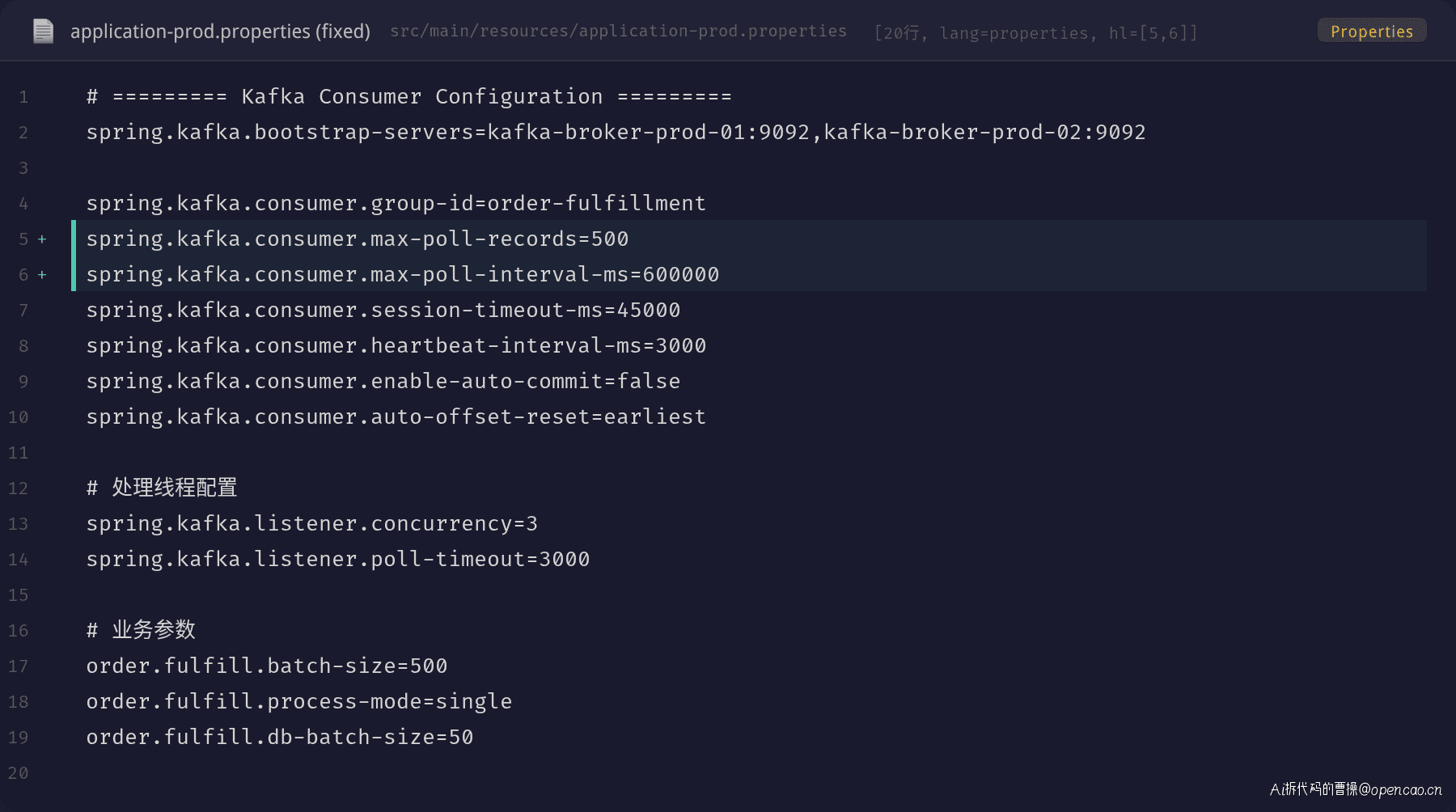
关键变更:
| 参数 | 原值 | 目标值 | 说明 |
|---|---|---|---|
| max.poll.records | 5000 | 500 | 单次拉取 500 条,处理约 50 秒 |
| max.poll.interval.ms | 300000 | 600000 | 预留 10 分钟缓冲时间,应对偶发慢处理 |
| order.fulfill.batch-size | 5000 | 500 | 业务层面的批大小同步调整 |
同时调整 Broker 端配置以允许更大的消费端 timeout:
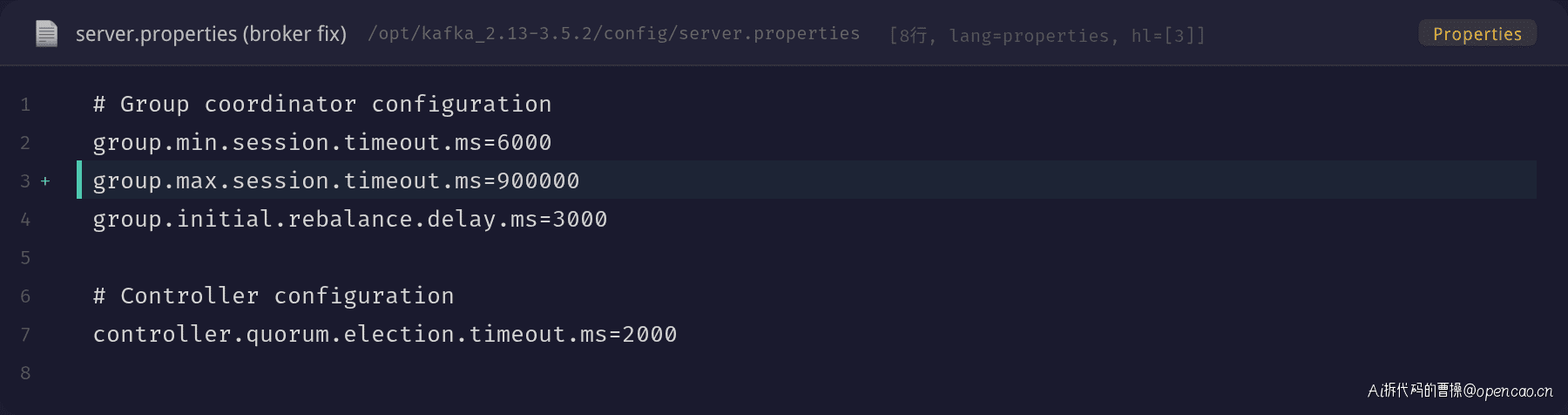
group.max.session.timeout.ms 从 300000 调整为 900000(15 分钟),给消费者留下足够的调参空间。同时 group.initial.rebalance.delay.ms 从默认的 300ms 改为 3000ms,新成员加入时等待一段时间再触发重平衡,避免滚动重启时频繁触发。
第二步:重启消费者
配置推送后,按顺序重启三个消费者实例。重启顺序很重要:consumer-3 → consumer-2 → consumer-1,确保在任何时刻至少有两个消费者在处理消息,减少 LAG 的积累。每次重启间隔 30 秒,让 Coordinator 有足够时间完成重平衡。
第三步:增加监控告警
新增以下监控指标:
rebalance-rate-per-hour:每小时重平衡次数,阈值 < 50rebalance-count-per-generation:每 generation 中的重平衡次数consumer-max-poll-interval-ratio:实际处理时间 / max.poll.interval.ms 比值,大于 0.7 告警coordinator-thread-pool-usage:GroupCoordinator 线程池使用率
特别重要的是第三个指标——它能在问题发生之前预警:当消费者的处理时间接近超时阈值时,提前介入,而不是等到消费者被踢出才告警。
第四步:上线部署
配置变更和代码更新经过 CR 后合并到主分支,遵循灰度发布策略:先在预发环境验证 30 分钟,确认消费组稳定后再推生产。生产环境按 1 台 → 50% → 100% 的节奏滚动更新。
验证结果
即时指标
配置调整和重启完成后,消费组恢复稳定:
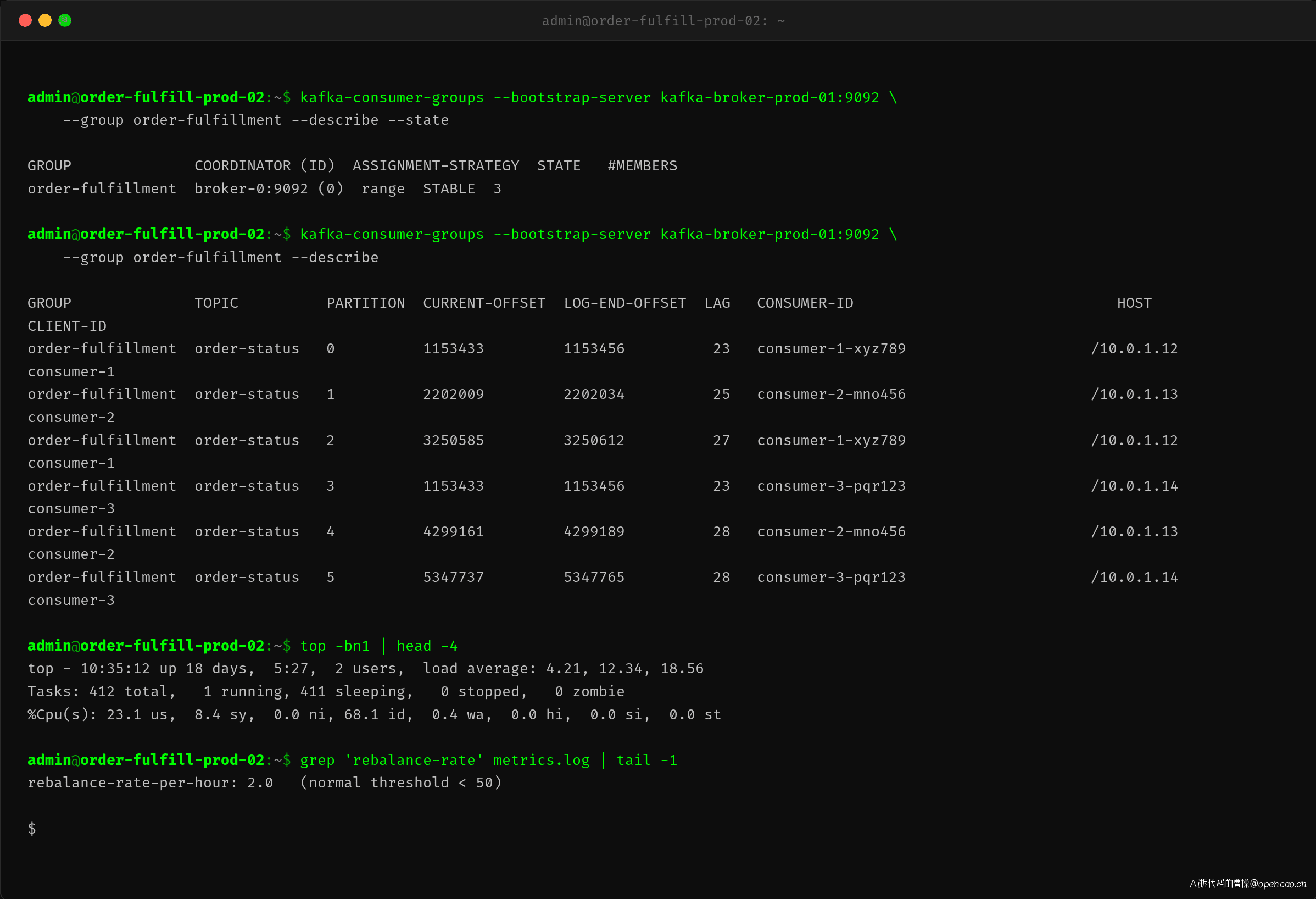
关键变化:
- 消费组状态:STABLE,不再在 PREPARING_REBALANCE 和 STABLE 之间横跳
- LAG:从 10 万以上降到 30 以内,说明消费者已经追上生产速度
- Broker CPU:从 99.7% 降到 23.1%,空闲率回到 68.1%
- 系统负载:从 78.34 降到 4.21
- rebalance-rate-per-hour:从 1420 降到 2
团队复盘
配置恢复后,团队在值班群进行了复盘讨论:
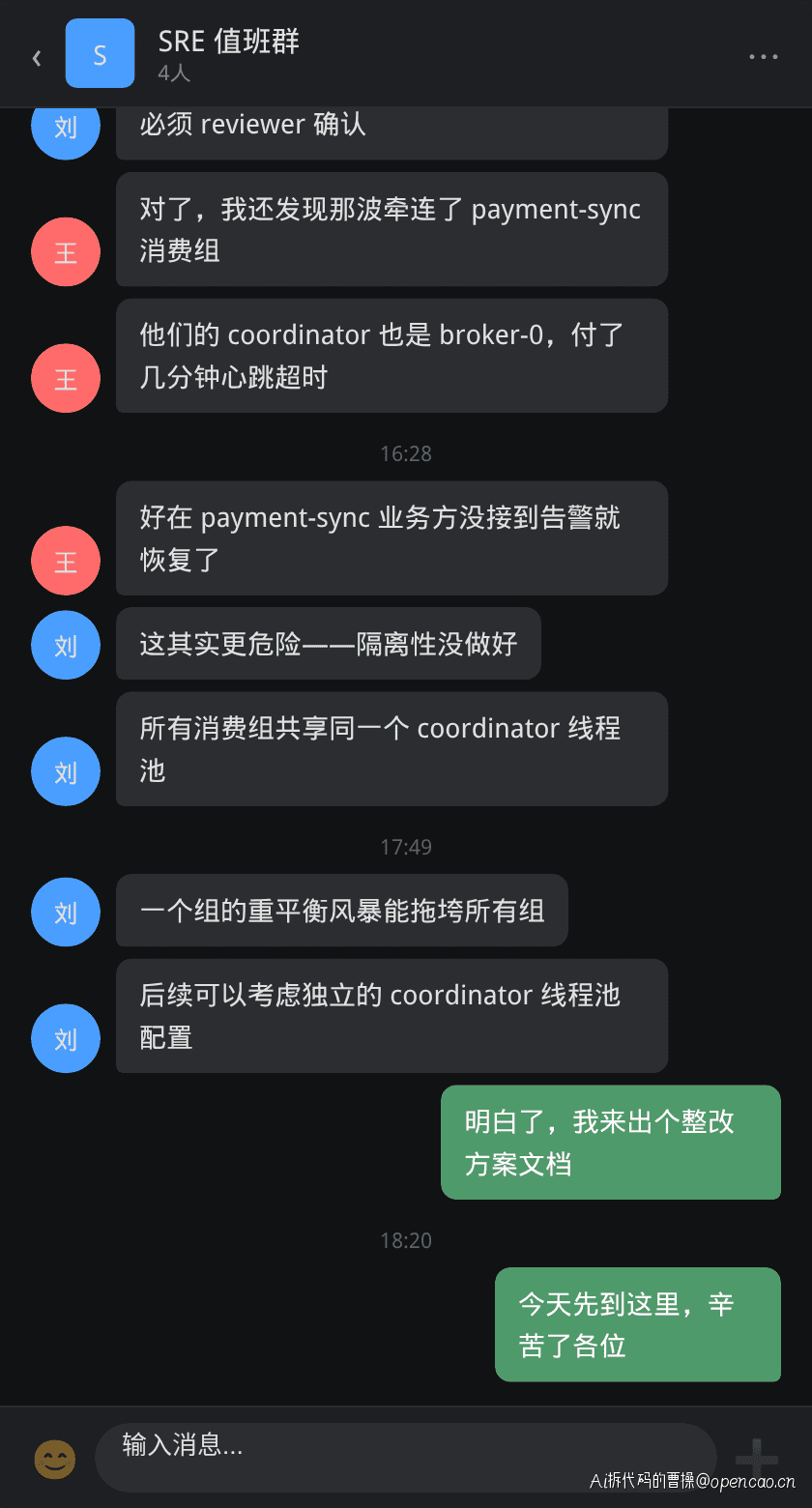
复盘确认了三层根因:
1. 直接原因:max.poll.records 与 max.poll.interval.ms 失配,处理时间远超 poll 间隔
2. 放大效应:重平衡风暴的恶性循环导致 consumer 逐一超时
3. 隔离失效:Coordinator 线程池共享,一个消费组的问题拖垮其他组
持续观察
修复后持续观察了 2 小时,指标稳定:
- CPU:23-25%,系统态占比从 33% 降到 8.4%
- 上下文切换:从 115 万/秒降到 3-4 万/秒
- 重平衡频率:2 次/小时(仅由心跳保活触发)
- 所有 6 个消费组均处于 STABLE 状态
未再出现跨组级联影响。
避坑建议
-
改 consumer 批量参数必须做处理时间估算:
max.poll.records和max.poll.interval.ms是一对耦合参数,改一个必须检查另一个。变更前用公式处理时间 = max.poll.records × 单条耗时验证是否在max.poll.interval.ms的 70% 以内。 -
Broker 端参数给消费者留余量:
group.max.session.timeout.ms不要紧贴着消费端的需求配。建议设置为预期最大值的 1.5-2 倍,给未来调参留空间。 -
消费组监控不能只看 LAG:LAG 告警通常是滞后的——等 LAG 告警触发时问题已经发生几分钟了。
rebalance-rate和 Consumer 端处理时间占比更有预警价值。 -
生产环境禁用 GroupCoordinator 默认值:Kafka 的默认参数在很多场景下是偏保守的。
max.poll.interval.ms=300000是 10 年前定的默认值,对于现在常见的批量处理场景远远不够。上线前应根据业务场景逐个 review 并显式设置。 -
Coordinator 隔离性评估:一个 Broker 上运行的所有消费组共享同一个 GroupCoordinator 线程池。关键业务消费组建议部署在独立的 Broker 上,或使用
group.coordinator.threads配置扩线程池。 -
重平衡风暴要有自动化检测和降级机制:当检测到
rebalance-rate突增(如 3 分钟内超过 50 次/小时),自动触发降级:降低该消费组的max.poll.records配置,强制 consumer 重启,防止风暴扩散。 -
Consumer 配置变更走 CR 流程并在预发验证:这类问题在预发环境中用较小流量很容易复现——启动消费者、发一批消息、观察处理时间。不要跳过预发验证直接上线。
附:完整命令清单
# 查看消费组状态
kafka-consumer-groups --bootstrap-server kafka-broker-prod-01:9092 \
--group order-fulfillment --describe --state
# 查看消费组详细成员分配
kafka-consumer-groups --bootstrap-server kafka-broker-prod-01:9092 \
--group order-fulfillment --describe --members --verbose
# 查看所有消费组的状态
kafka-consumer-groups --bootstrap-server kafka-broker-prod-01:9092 \
--all-groups --describe --state
# 系统资源排查
top -bn1 | head -20
vmstat 1 6
mpstat -P ALL 1 1
sar -w 1 3
# Kafka Broker 日志排查
grep -E 'JoinGroup|LeaveGroup|GroupCoordinator|rebalance' controller.log | tail -40
grep 'JoinGroup' request.log | tail -10
grep 'rebalance-rate' metrics.log
# 线程分析
jstack -l <pid> | grep -c 'GroupCoordinator'
top -H -p <pid> -bn1 | head -20
# 检查消费者配置
cat application-prod.properties | grep -iE 'kafka|poll|interval|batch'


