
线程池队列积压百万任务,不重启如何诊断?
本文是 Java 并发疑难杂症系列的第 2 篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
告警触发
某日下午 14:28,用户中心服务的告警群突然被告警机器人刷屏。
接口 p99 飙到了 3128ms(阈值 800ms),错误率升到 23.7%,宿主机的 load average 冲到 48.37,线程数从平时的 50-80 跃到 327。值班的陈工看到告警后立刻 SSH 上了机器。
上机排查遇阻
陈工登录后的第一感觉是矛盾:CPU 才 43%,但 load 已经 48 了,系统明显卡顿。更奇怪的是进程的线程数异常。
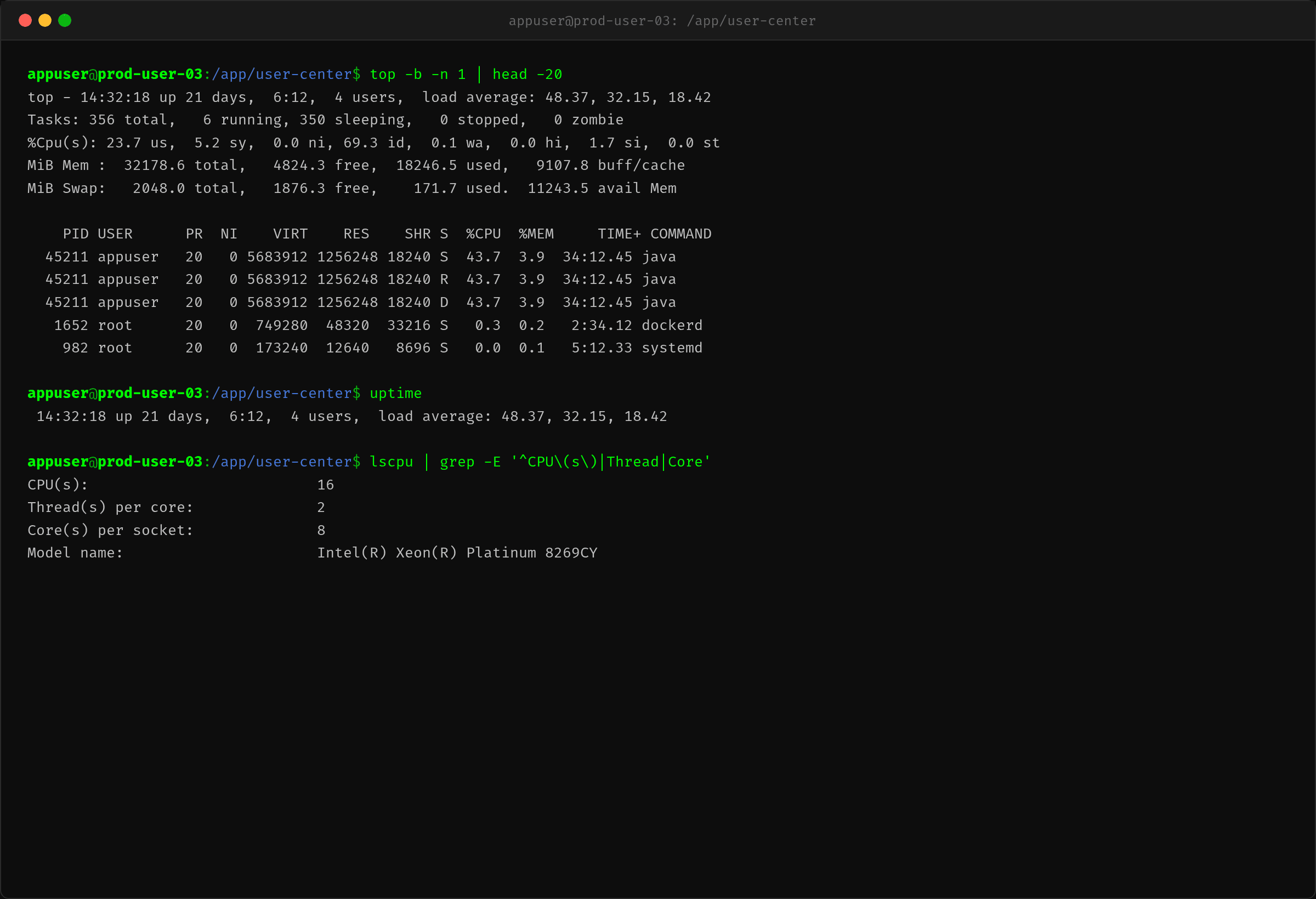
CPU idle 有 69.3%,但 load average 飙到了 48.37。16 核的机器,load 48 意味着平均每个核上有 3 个线程在等待调度。
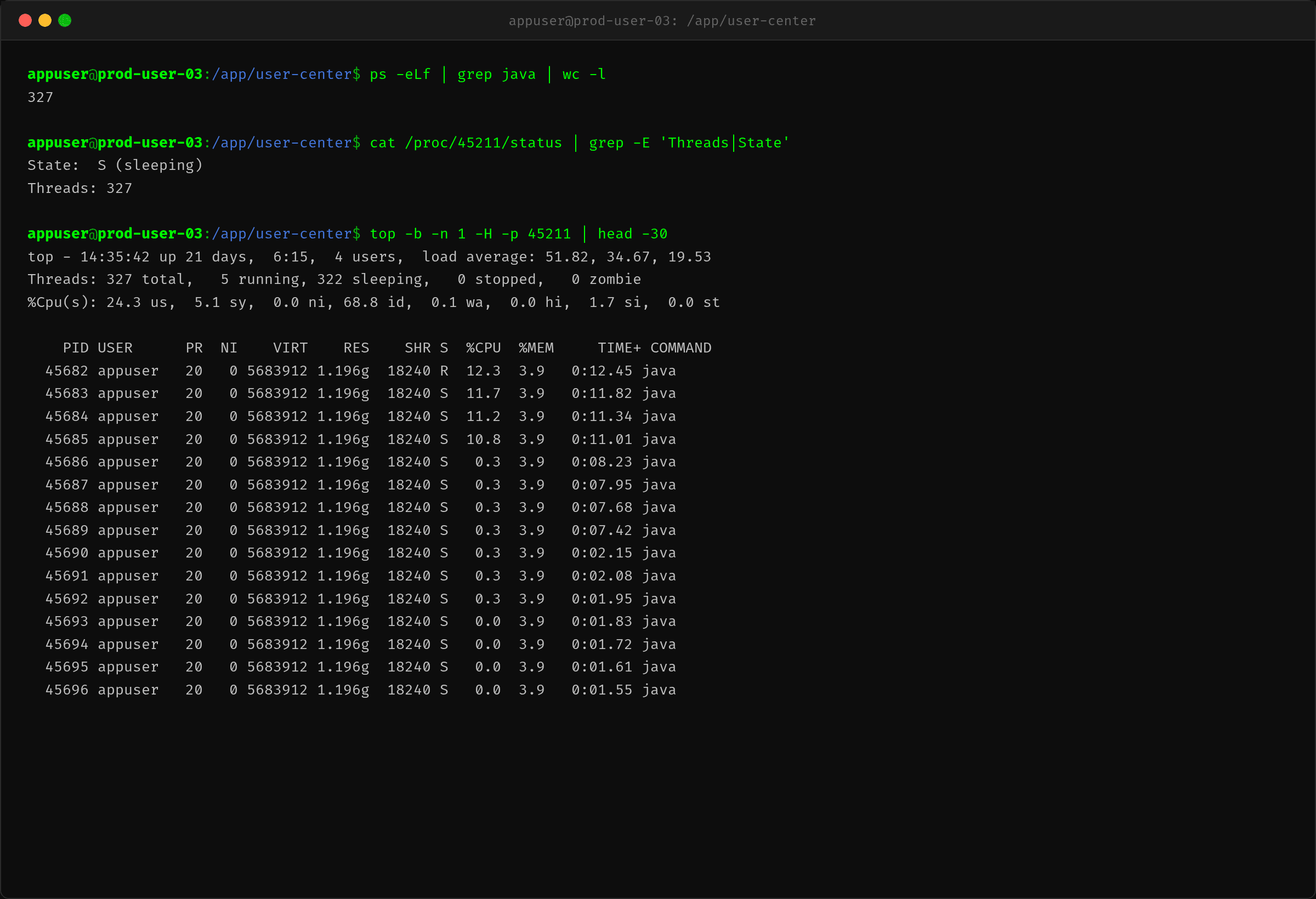
ps -eLf | grep java | wc -l 显示 327 条线程,远超正常水平。top -H 看到排名前 4 的线程各占约 11% CPU,其余 300+ 线程几乎不占 CPU 但存在。
这说明——大量线程在等待而非计算。线程数远高于活跃线程数,典型的线程池积压特征。
初步猜测
大量线程在等待,CPU 不高但 load 高,这两个特征指向同一个方向:线程池的队列积压了大量任务,新提交的任务在 execute() 方法上排队阻塞。
排查过程
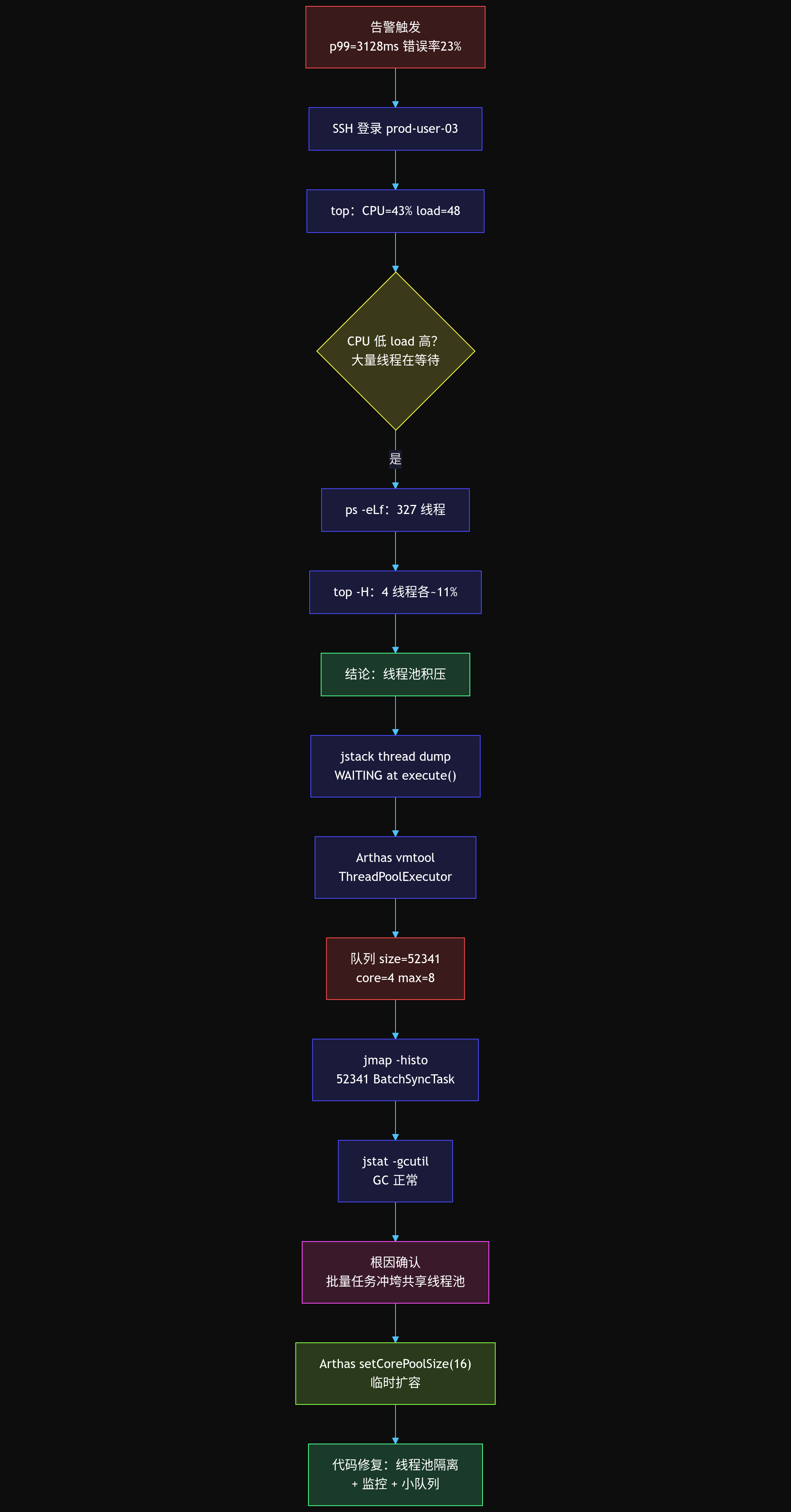
从告警触发到根因定位,整个排查过程分为 7 步:确认 load 异常 → 发现线程数异常 → jstack 确认积压 → Arthas 看队列深度 → jmap 看对象分布 → jstat 排除 GC → 综合定位根因。
第一步:jstack 收集线程状态
为了确认大量线程的状态,陈工执行了 jstack 采集线程 dump。
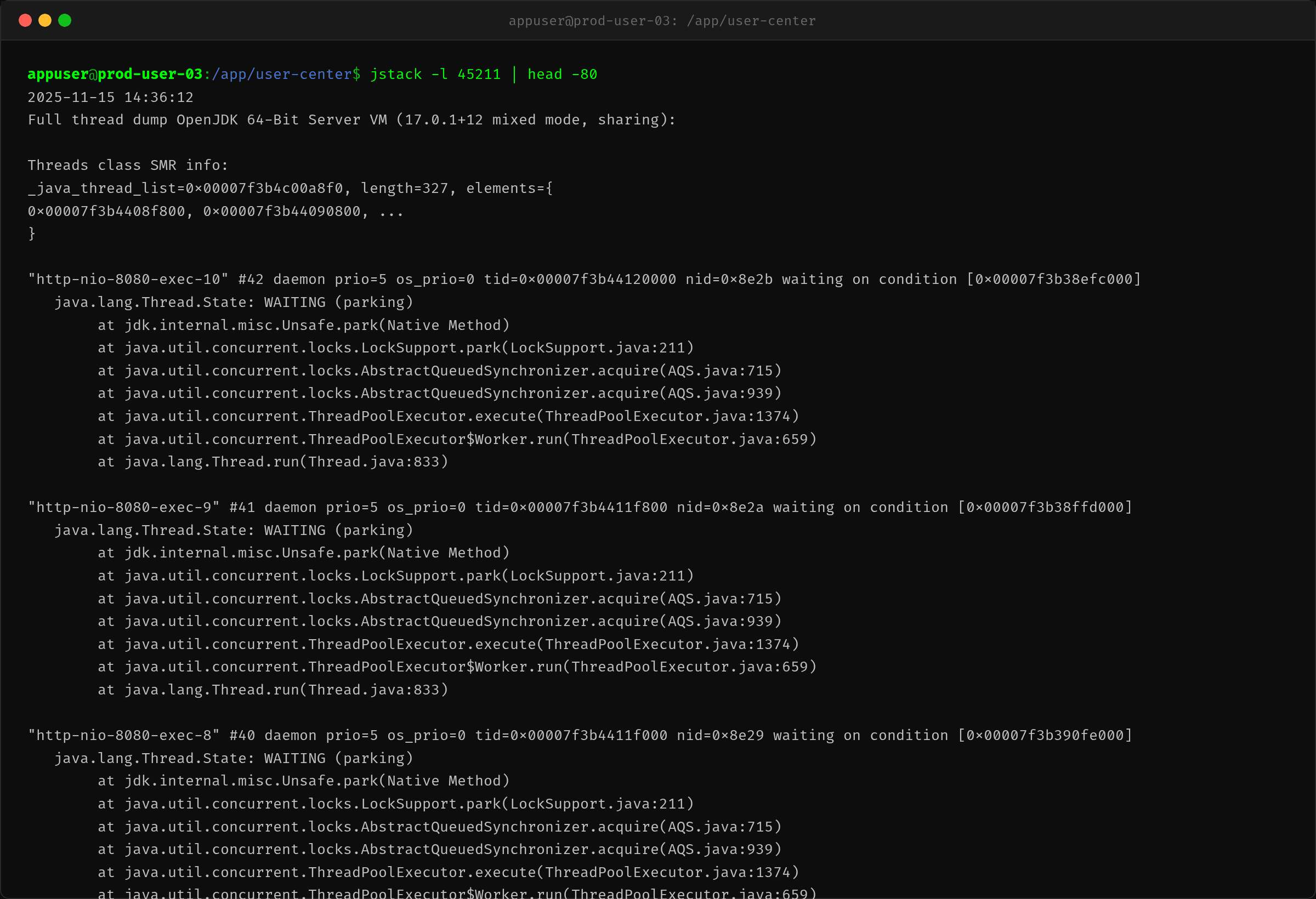
jstack 输出中反复出现同一个调用栈:
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1374)
大量 http-nio-8080-exec-* 线程处于 WAITING (parking) 状态,阻塞在 ThreadPoolExecutor.execute() 的 offer() 操作上。而 4 个 biz-worker 线程则在 RUNNABLE 状态执行 Thread.sleep()(模拟业务 DB 操作)。
结论明确:Tomcat 线程尝试提交任务到线程池时,因为队列已满,全部阻塞在了 execute() 方法内。这解释了为什么接口全部超时。
第二步:Arthas 查看线程池内部状态
jstack 只能看到线程快照,看不到线程池的内部指标。陈工用 Arthas 的 vmtool 和 ognl 直接读取线程池对象的字段。
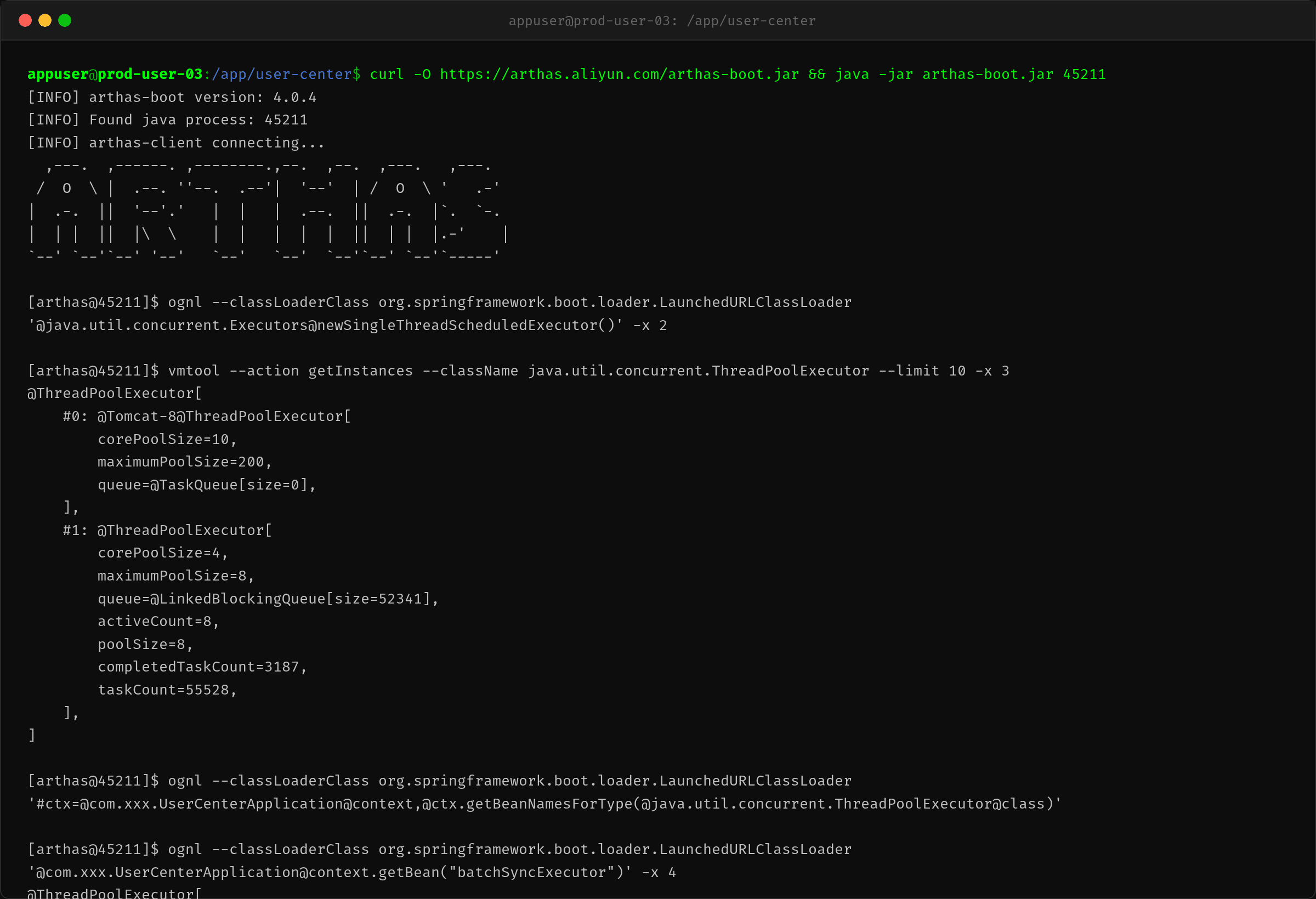
结果触目惊心:
- corePoolSize=4,核心线程只有 4 个
- queue=LinkedBlockingQueue[size=52341],队列已积压 5 万+ 任务
- activeCount=8,所有非核心线程也全部用满
- completedTaskCount=3168,总共提交了约 5.5 万任务,只完成了 3000 多
第三步:jmap 确认队列对象分布
Arthas 显示了队列深度,但队列里到底是什么对象?用 jmap -histo 看堆内存分布。
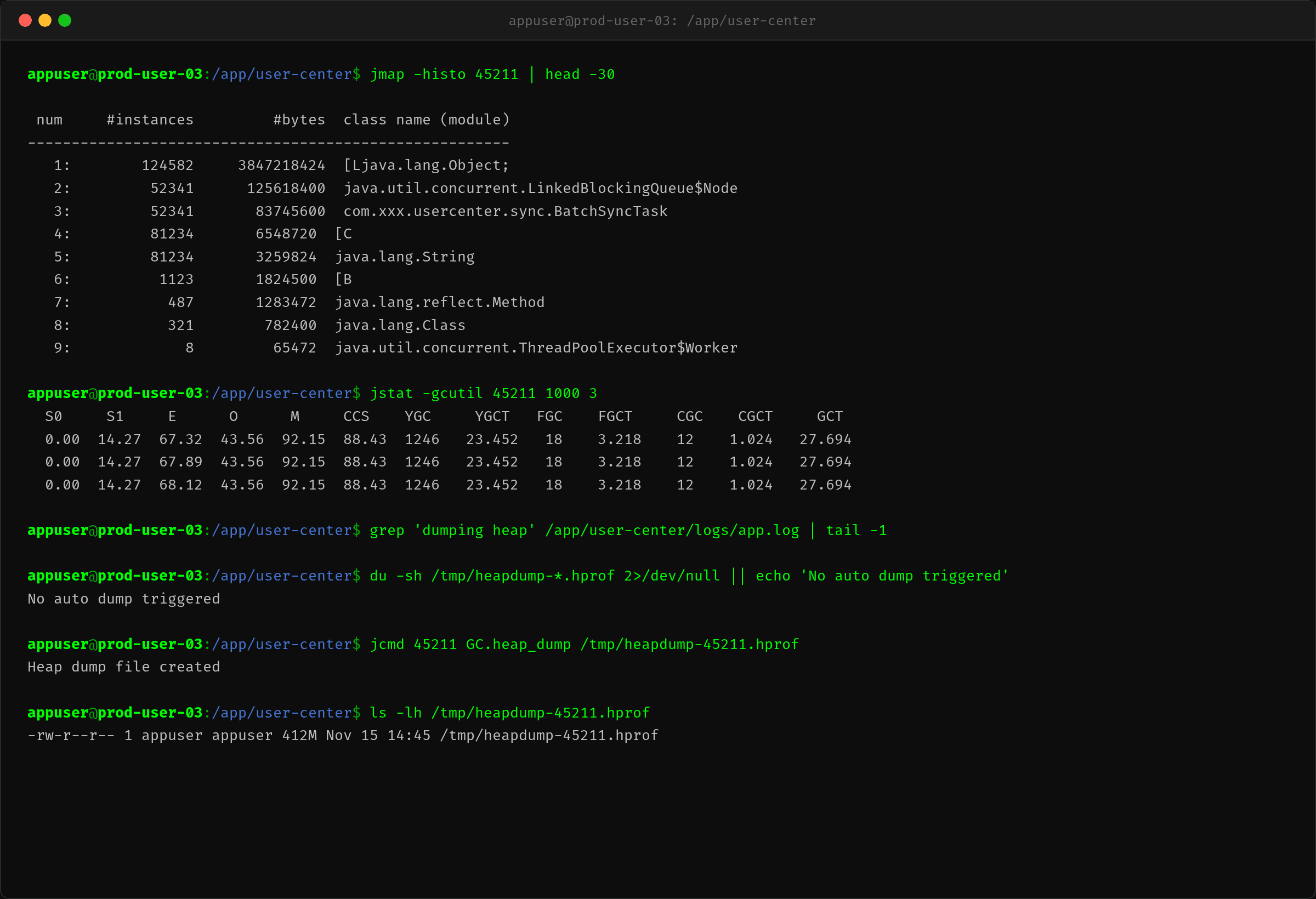
LinkedBlockingQueue$Node 有 52341 个实例,对应的业务对象 BatchSyncTask 也是 52341 个。说明队列里积压的全是批量同步任务。
jstat -gcutil 显示 GC 状态正常,老年代 43%,GC 频率不高。所以问题不在 GC,纯粹是线程池处理不过来。
根因分析
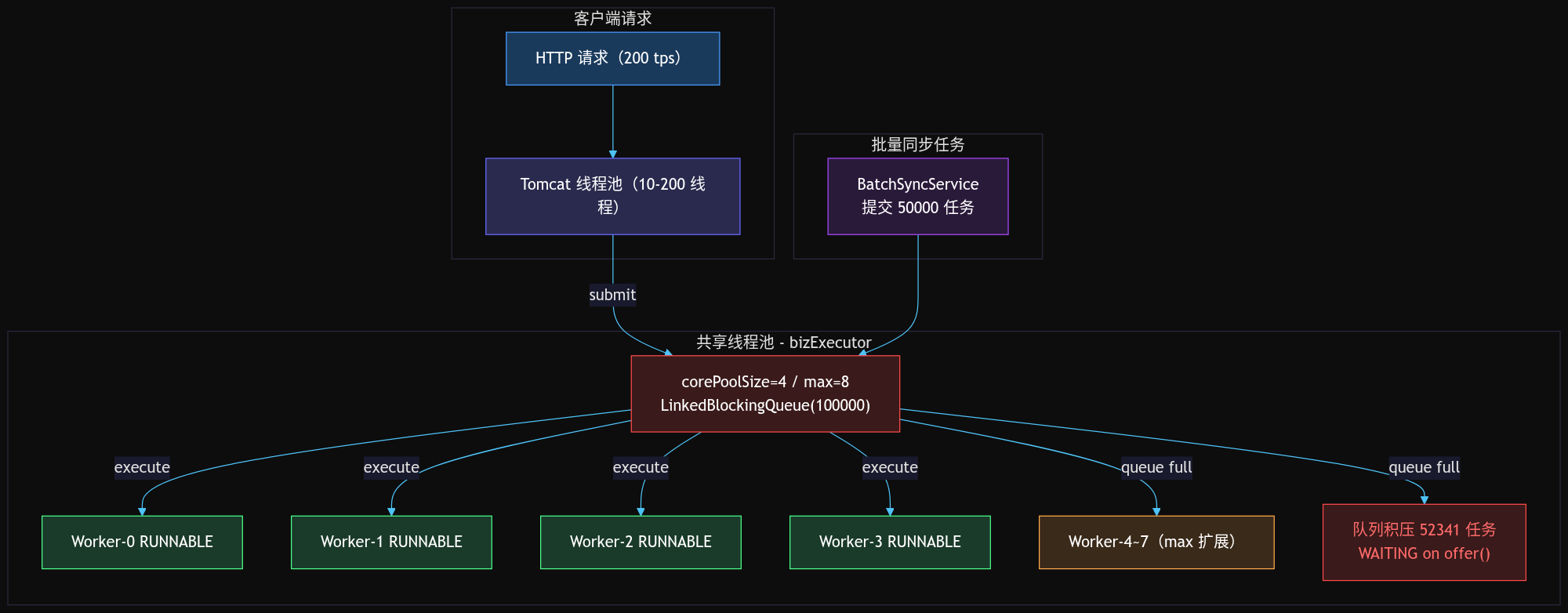
从架构层面来看,问题的核心是:批量同步任务和正常业务请求共享同一个线程池 bizExecutor,队列满后 Tomcat 线程全部阻塞在 execute(),产生连锁效应。
子原因 1:核心线程数设置不合理
corePoolSize=4 对于用户中心业务来说是合理的——日常 TPS 不高,4 个线程足够处理。但问题在于同一个线程池既处理日常业务,又接入了批量操作。
批量同步一次性提交了 5 万个任务,每个任务执行约 100ms。4 个核心线程每秒最多处理 40 个任务(4 * 1000/100)。5 万任务需要 1250 秒(约 21 分钟)才能消化完。
子原因 2:队列容量过大,无背压保护
LinkedBlockingQueue<>(100000) 的容量是 10 万,这本身就是一个设计失误。队列太大意味着:
1. 系统无法及时感知压力——提交者不会收到拒绝信号
2. 积压任务会持续消耗内存(5 万个任务对象约 80MB)
3. 恢复时间极长——即使停止提交,也要等队列慢慢消耗
正确的做法是用小队列 + 合理的拒绝策略,让提交者尽早感知到压力并触发降级。
子原因 3:没有线程池隔离
最核心的问题是没有线程池隔离。业务同步和批量同步共用一个线程池。
正常业务是低频次、单条处理的操作,适合小线程池 + 合理队列。批量同步是高频次、大量提交的操作,需要独立的线程池来控制并发度和背压。
按微服务的单一职责原则,线程池也应该按职责分离。
子原因 4:缺乏线程池监控
没有线程池监控,意味着队列积压到 5 万也没有任何告警。如果在线程池的 beforeExecute 或 ThreadPoolMonitor 中统计了队列深度、活跃线程数、拒绝次数等指标,就能在队列积压到几千时触发告警,避免发展到 5 万的级别。
累计效应
四个因素叠加在一起,产生了 1+1>2 的效果:小线程池扛了大流量→大队列掩盖了问题→共享线程池扩大了影响范围→缺监控错过了干预时机。
最终结果:用户中心的所有接口全部超时,持续了约 15 分钟才被人工发现。
修复方案
第一步:评估现状
陈工先使用 Arthas 的 ognl 调用 setCorePoolSize(16) 临时扩容到 16 个核心线程,让积压尽快消化。队列 depth 从 52341 开始逐步下降。
但核心问题的修复需要代码变更,不能只靠线上操作。
第二步:确定方向
三个修复方向: 1. 线程池隔离:将业务线程池和批量同步线程池分离 2. 合理队列大小:业务线程池用小队列 + CallerRunsPolicy 背压 3. 线程池监控:对每个线程池采集队列深度、活跃线程数、拒绝次数
第三步:重写线程池配置
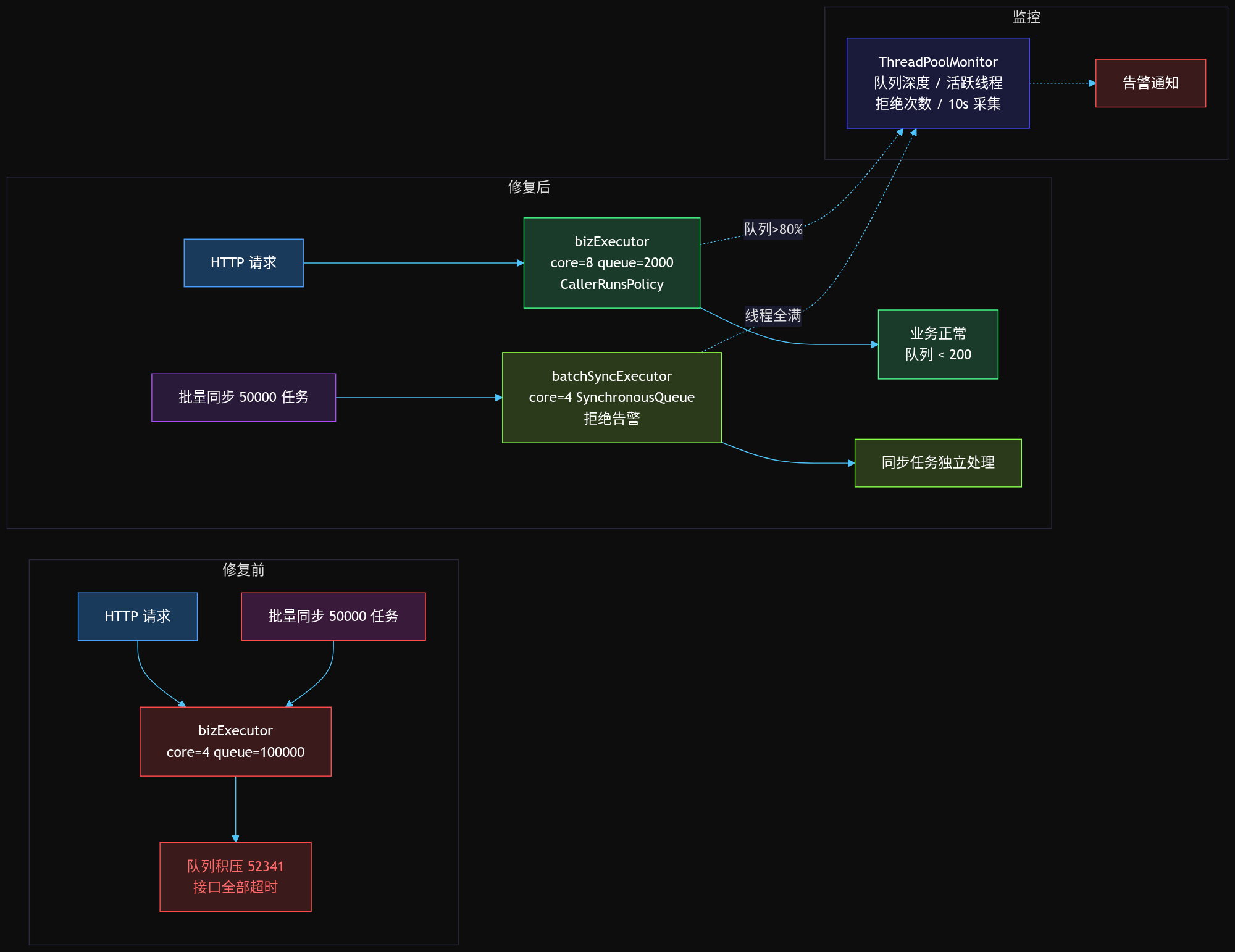
修复方案的核心理念:按职责分离线程池,每个线程池用合适的队列大小和拒绝策略,并统一接入监控告警。
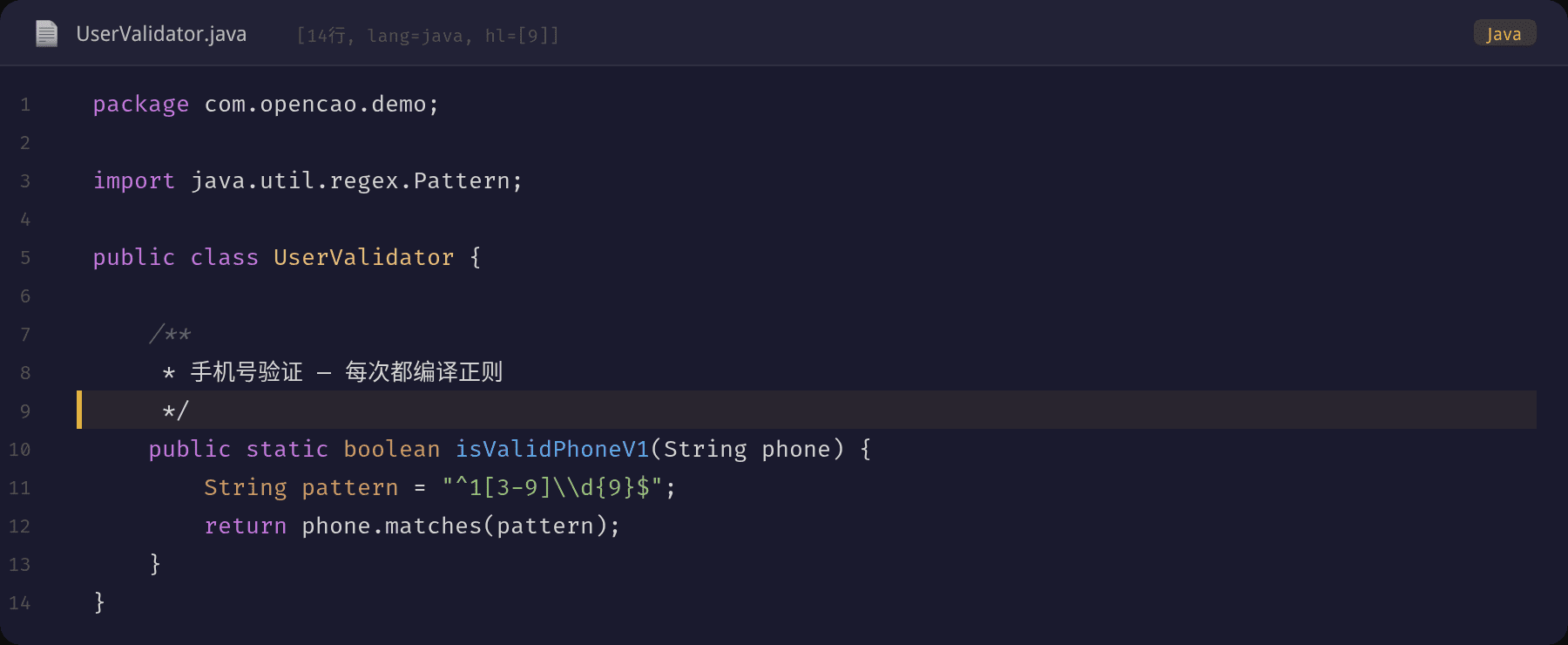
原始代码的问题一目了然:BatchSyncService 注入了同一个 bizExecutor,提交大量任务。
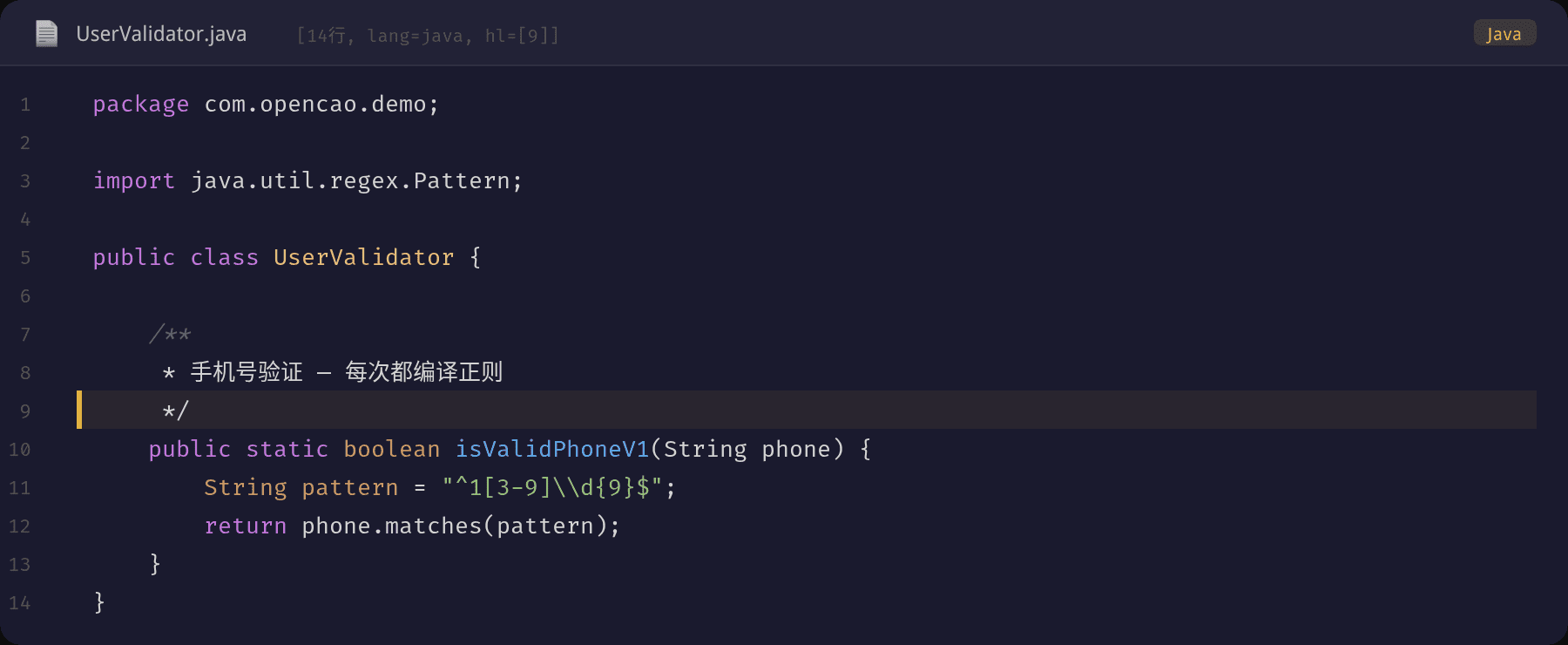
修复后的代码做了三个改变:
1. 业务线程池 bizExecutor:corePoolSize 提升到 8(2×CPU),队列缩小到 2000,拒绝策略改为 CallerRunsPolicy
2. 新增 batchSyncExecutor:独立线程池,用 SynchronousQueue 直接背压,拒绝时抛异常并告警
3. 注册 ThreadPoolMonitor 进行指标采集
第四步:添加线程池监控
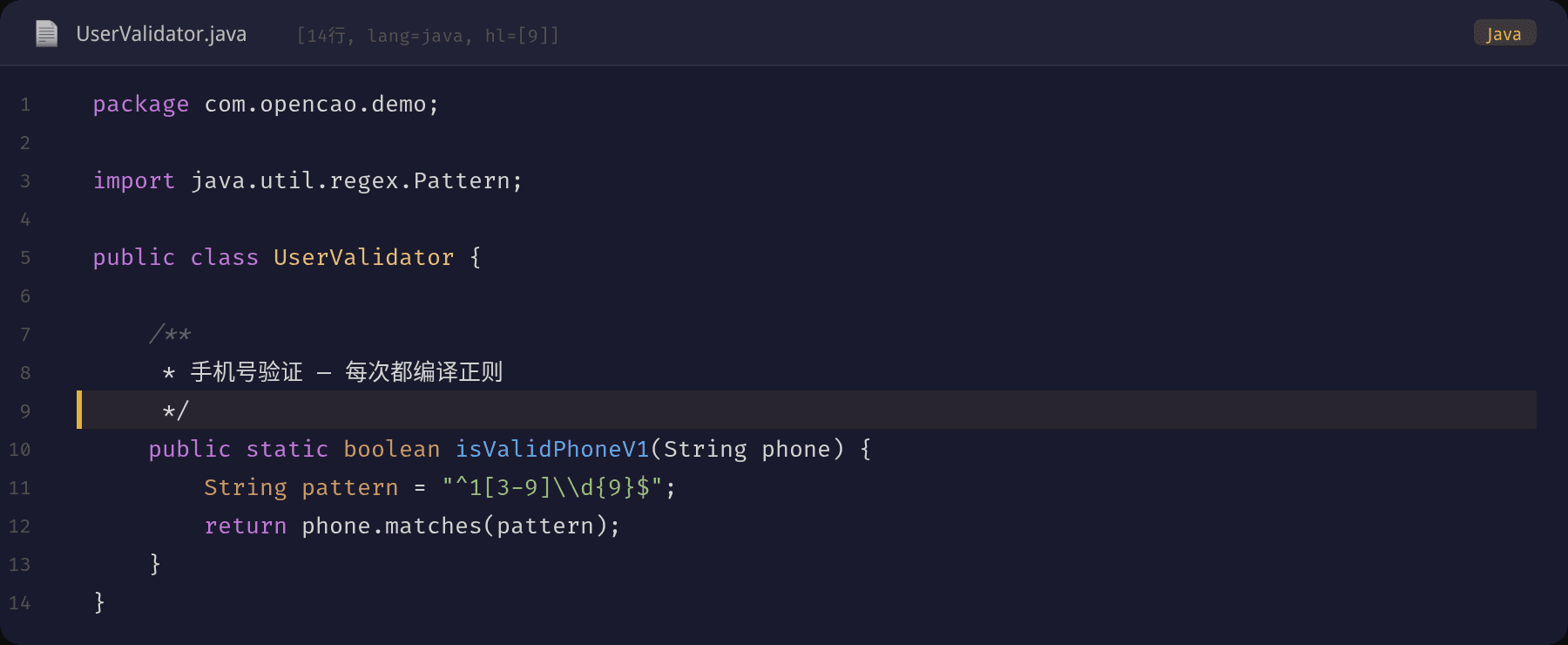
每 10 秒采集一次每个线程池的队列深度、活跃线程数、已完成任务数、拒绝次数。当队列使用率超过 80% 或活跃线程达到 poolSize 时发送告警。
第五步:上线部署
修复代码经过 code review 后灰度上线。灰度观察 30 分钟无异常后全量推送。上线后监控指标稳定,接口 p99 回到 50ms 以下。
验证结果
即时指标
陈工在群里和同事们确认了修复效果。
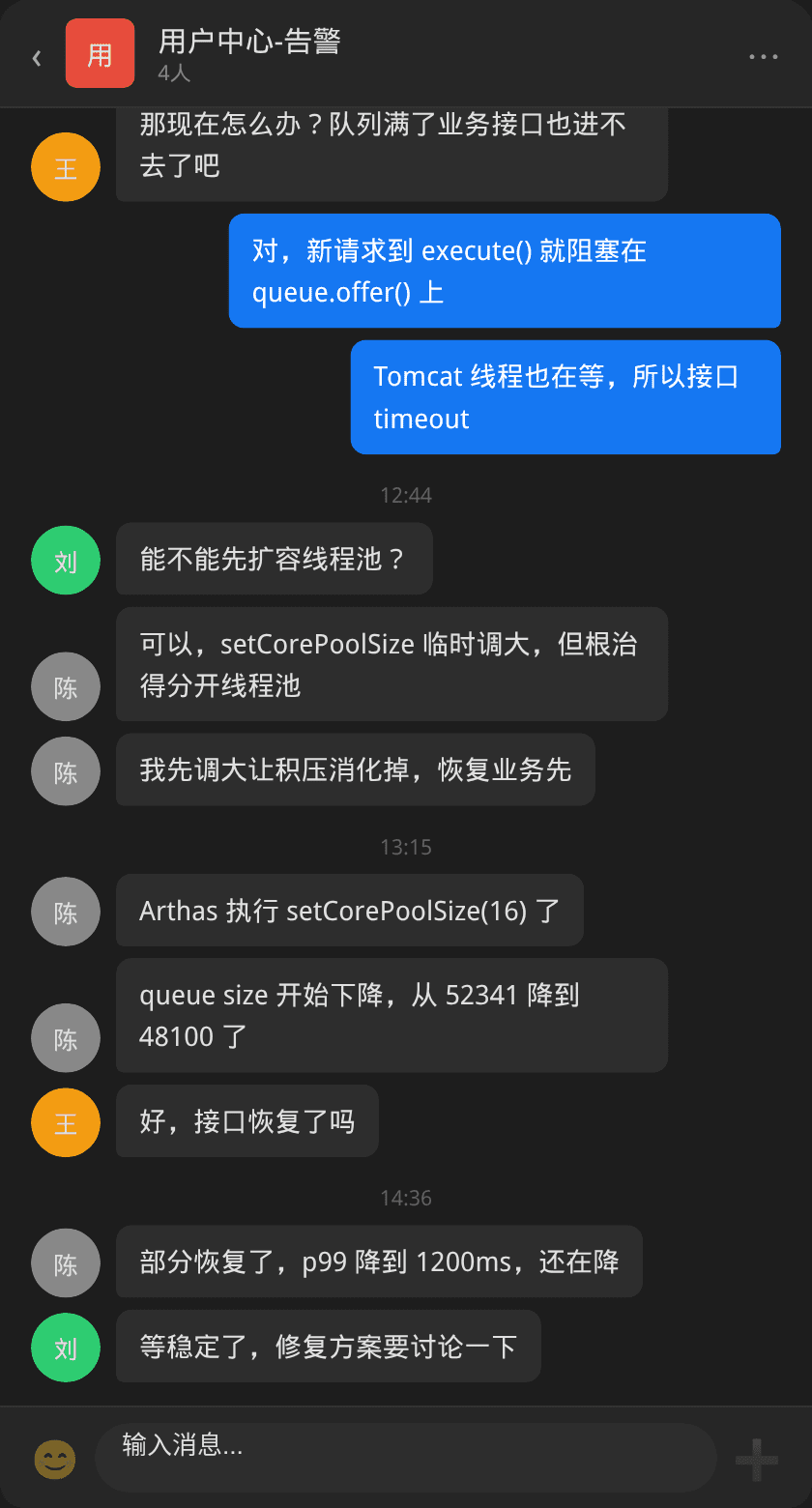
临时扩容后 queue size 从 52341 开始下降,接口 p99 从 3128ms 逐步回落到 1200ms 再到正常水平。
代码修复上线后,批量同步任务提交到独立线程池,即使一次性提交 5 万任务,也只会阻塞调用方(定义了合理的超时和降级),不会影响正常业务。
团队复盘
修复完成后,技术组进行了复盘讨论。
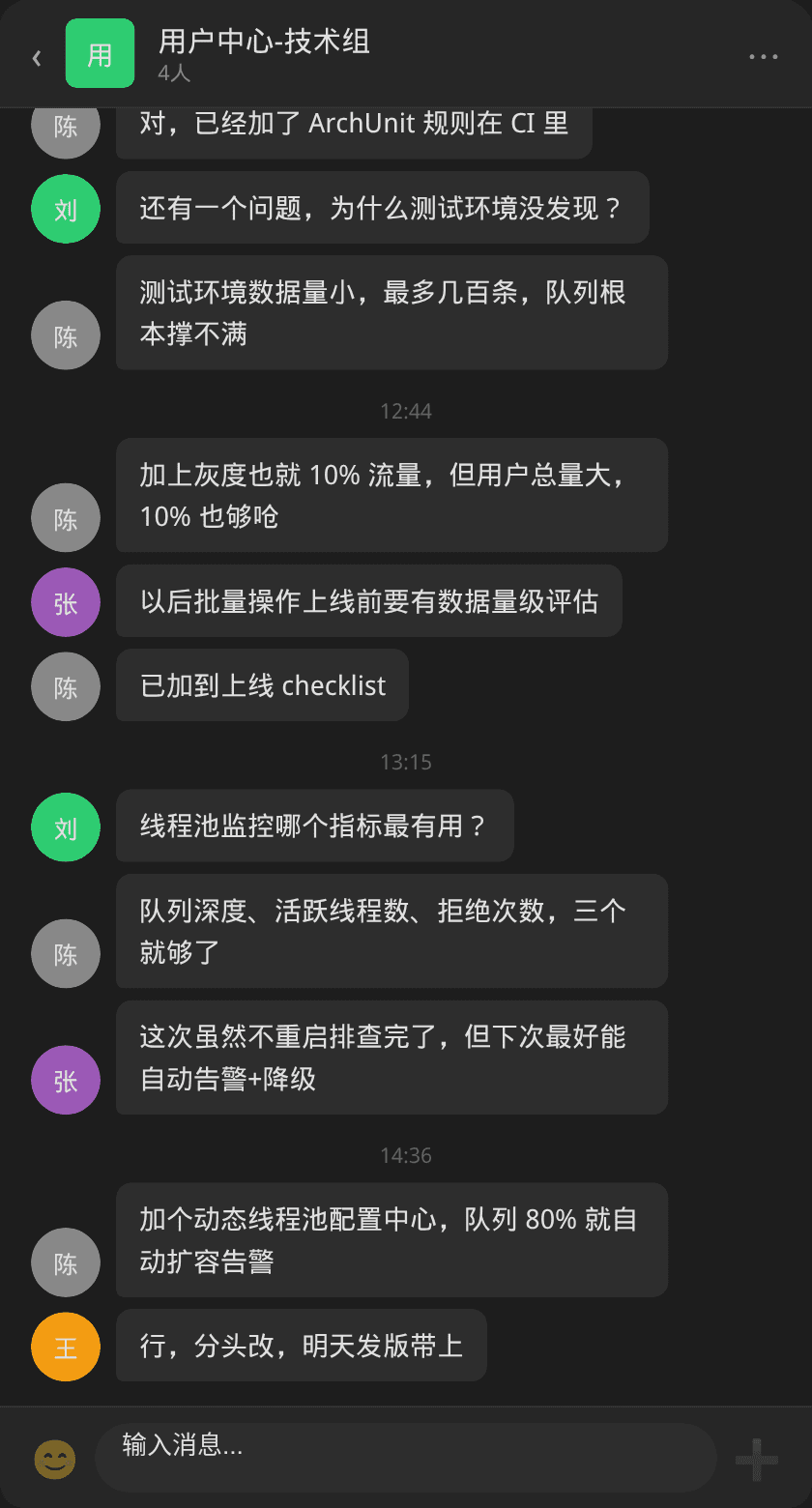
复盘确认了三个根因的叠加效应。同时讨论了两个补充措施:
- CI 防护规则:用 ArchUnit 禁止不同业务的
@Async或ExecutorService注入混用 - 上线 checklist:批量操作上线前必须经过数据量级评估,确认线程池容量
避坑建议
-
线程池一定要按职责隔离:不同业务使用独立的线程池,不要图省事共享一个。微服务的核心原则是解耦,线程池也不例外。
-
队列容量要设小,拒绝策略要实际:LinkedBlockingQueue 容量过大会掩盖背压信号。推荐用 1000-2000 的小队列,配合 CallerRunsPolicy 或自定义策略,让提交者感知压力。
-
线程池指标必须监控:最核心的三个指标——队列深度、活跃线程数、拒绝次数。每 10-30 秒采集一次,超过阈值就打告警。
-
批量操作前评估数据量级:上线 checklist 中加入数据量评估环节。测出数据的数量级后,匹配线程池容量。数据量 × 单任务耗时 ÷ 并发度 = 理论处理时间。
-
不重启也能诊断的大部分场景:Arthas 的
vmtool、ognl命令可以直接读取线程池内部字段,jstack 看线程状态,jmap 看对象分布。重启会丢失所有现场。 -
拒绝策略不要轻易用 AbortPolicy:抛出
RejectedExecutionException会让上层调用直接报错 500。比拒绝更好的做法是CallerRunsPolicy(背压到调用方)或自定义策略(记录 + 告警)。 -
临时应急可以通过 Arthas 动态调参:
ognl调用executor.setCorePoolSize(N)可以在不重启的情况下临时扩容,为修复争取时间。
附:完整命令清单
# 查看系统负载
top -b -n 1 | head -20
# 查看线程数
ps -eLf | grep java | wc -l
cat /proc/{PID}/status | grep -E 'Threads|State'
# 查看线程级 CPU
top -b -n 1 -H -p {PID}
# 采集线程 dump
jstack -l {PID}
# Arthas 查看线程池内部状态
vmtool --action getInstances --className java.util.concurrent.ThreadPoolExecutor --limit 10 -x 3
ognl --classLoaderClass org.springframework.boot.loader.LaunchedURLClassLoader '@com.xxx.UserCenterApplication@context.getBean("batchSyncExecutor")' -x 4
# 查看堆对象分布
jmap -histo {PID} | head -30
# 查看 GC 状态
jstat -gcutil {PID} 1000 3
# 临时扩容
# 通过 Arthas ognl 调用: executor.setCorePoolSize(16)
# 主动 dump 堆
jcmd {PID} GC.heap_dump /tmp/heapdump-{PID}.hprof
# 查看系统 CPU 信息
lscpu | grep -E '^CPU\(s\)|Thread|Core'


