
Metaspace OOM:动态类加载/反射/CGLIB 是凶手
本文是 JVM 性能调优 系列的第二篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
告警触发
某日上午刚过十点,认证服务值班群突然被告警机器人刷屏。健康检查连续失败,用户登录接口大面积报错,前端反馈大量 502 响应。
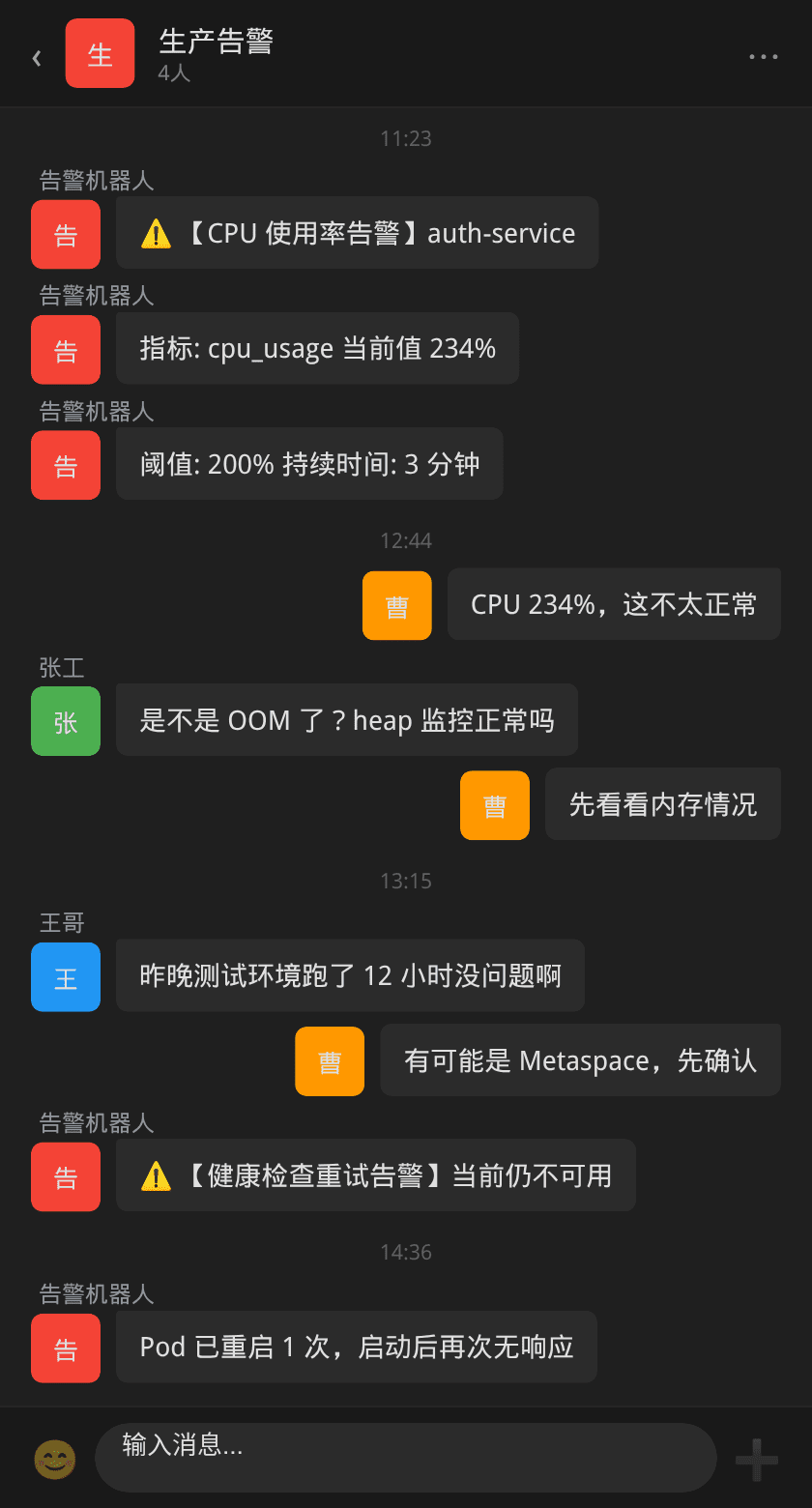
这个认证服务(auth-service)是公司统一身份认证入口,所有内部系统的登录和权限校验都经过它。平时 CPU 使用率稳定在 40-60%,堆内存只用了 2G 中的不到 1.5G,运行了几个月都没出过问题。
但今早从监控面板看,它的 CPU 飙升到了 234%,而且 swap 也开始被使用——物理内存不够了。更诡异的是,堆内存的占用却不算高(不到 2G),这不符合常规的堆 OOM 表现。
上机排查遇阻
SSH 登入机器后的第一眼就让人揪心:
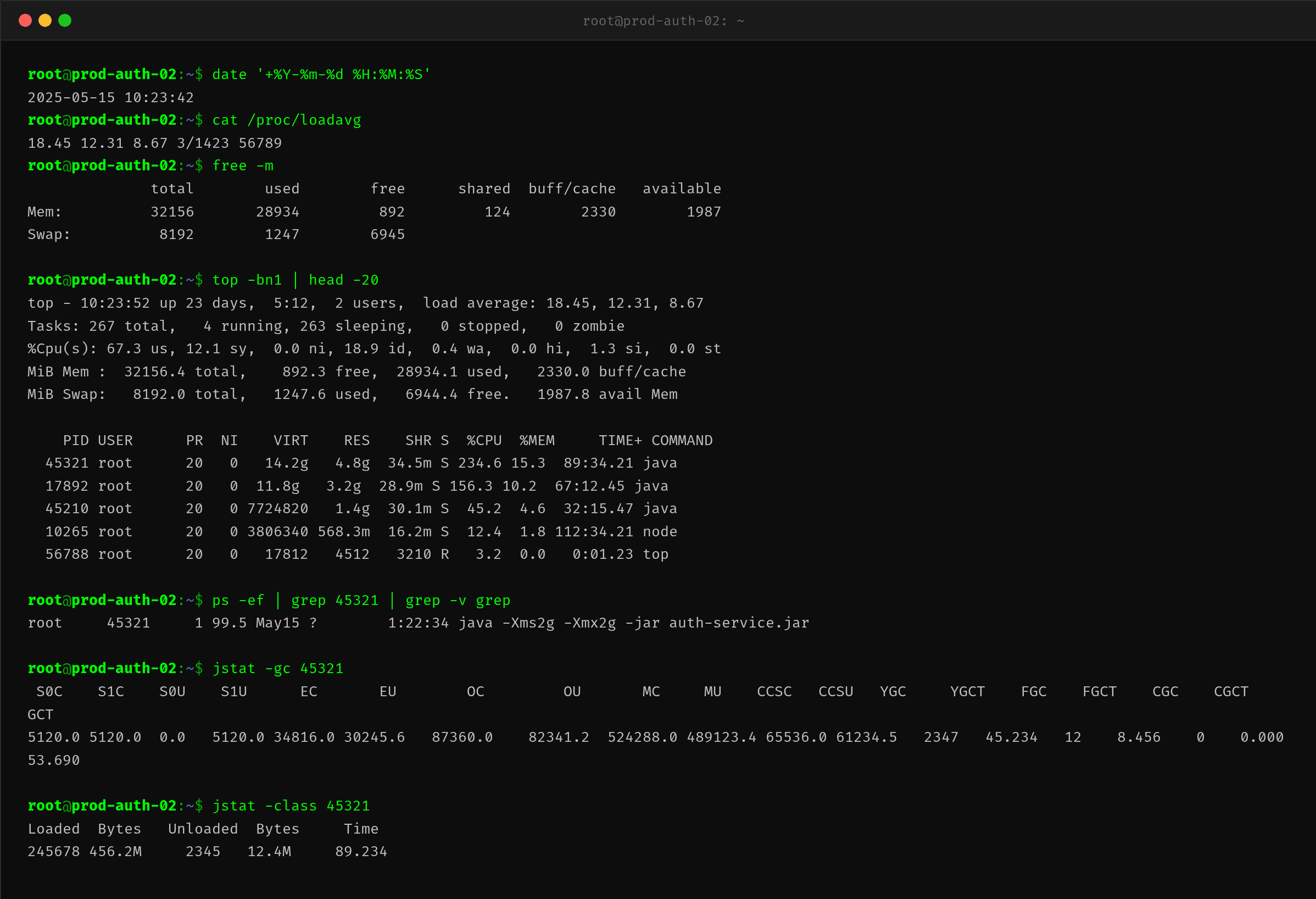
load average 18.45——8 核的机器 load 到了 18,说明大量线程在等待 CPU 或处于不可中断的 D 状态。CPU 234.6%(单进程,多核累加)几乎打满。
但真正引起注意的是两项数据:
- 物理内存 28.9GB used,swap 也被吃了 1.2GB
- 进程
auth-service的 RES(驻留内存)高达 4.8GB
问题是进程启动参数只配了 -Xms2g -Xmx2g,堆最多 2GB,那多出来的 2.8GB 去哪了?
jstat -gc 给出了第一个线索:MC(Metaspace Capacity)= 524288KB = 512MB,MU(Metaspace Usage)= 489MB。更夸张的是 jstat -class 显示 Loaded 类达到了 245678 个,占了 456MB。
一个认证服务为什么会有 24 万个类?正常 Spring Boot 应用启动后也就 8000-15000 个类。
初步猜测
看到这个数字,基本可以排除常规的堆 OOM 了。堆外内存的暴涨 + 异常高的类数量指向一个问题:Metaspace 区域正在被大量动态生成的类不断填满,触发了高频的 Metadata GC,CPU 全耗在 GC 上了。
但为什么一个认证服务会在线上运行时持续生成新类?测试环境为什么没发现问题?这需要一步步追查。
排查过程
第一步:确认 Metaspace 使用量和 GC 状态
先全面采集 jstat 数据,看看 Metaspace 区域的动态变化:
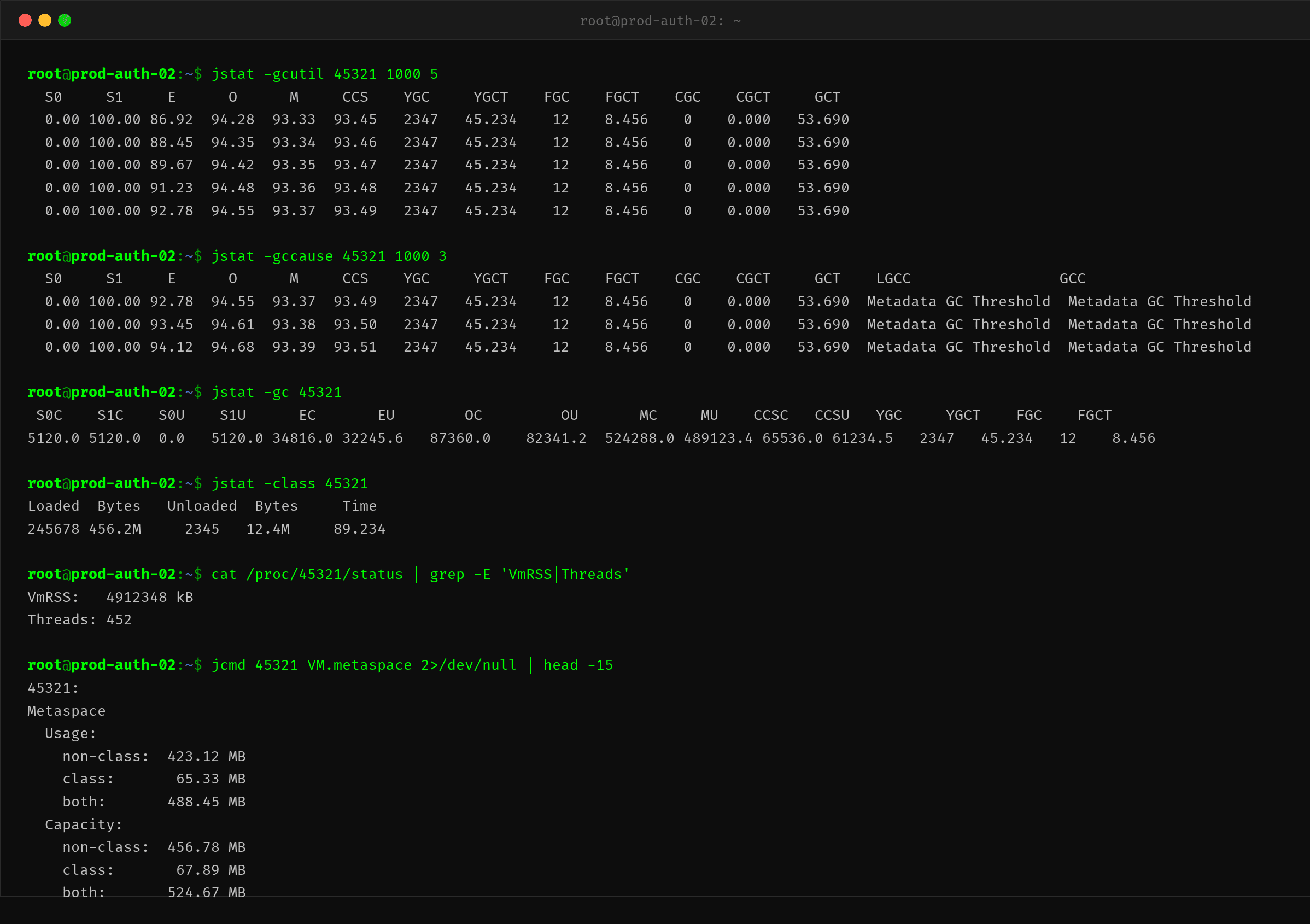
从 jstat -gcutil 的连续采样能看出几个关键信号:
信号一:M 列(Metaspace 使用率)持续上涨。 从 93.33% 到 93.37%,5 秒内涨了 0.04%。对于一个峰值容量 512MB 的区域,这意味着每秒有约 400KB 的新类元数据被加载到 Metaspace,且从未被回收。
信号二:GCC(当前 GC 原因)持续显示 "Metadata GC Threshold"。 这是 Metaspace 的软限制触发 GC——当 Metaspace 使用量达到当前容量上限的一个阈值(默认 80-90%)时,JVM 会触发一次 Full GC 尝试回收未使用的类元数据。但这里的 GC 原因始终不变,说明回收不掉。
信号三:MC(Metaspace Capacity)一直卡在 524MB 的硬限制附近。 这里有个关键细节:虽然启动参数没设 MaxMetaspaceSize,但 JVM 会根据 OS 可用内存和进程已用内存自动协商出一个上限。这个进程的 MC 卡在 512MB 并非用户配置,而是 OS 级别的内存压力导致 JVM 无法继续膨胀,形成了事实上的"隐式上限"。
再对比 Heap 的 O 列(Old 区使用率)只有 94% 左右,且 FGCT(Full GC 耗时)8.456s ÷ 12 次 ≈ 700ms 每次——单次不算太长,但 12 次 Full GC 都是在 Metaspace 接近瓶颈时触发的,频率在持续加快。
jstat -gccause 的 LGCC(上次 GC 原因)同样是 "Metadata GC Threshold",这与前面的分析一致——每次 GC 都是 Metaspace 满了触发的,而 GC 后 Metaspace 使用率没有显著下降,说明加载的类都是活的,无法被回收。
第二步:追踪类加载来源
既然确认了 Metaspace 在持续增长且无法回收,下一步就是找出是什么类在被不断地加载。
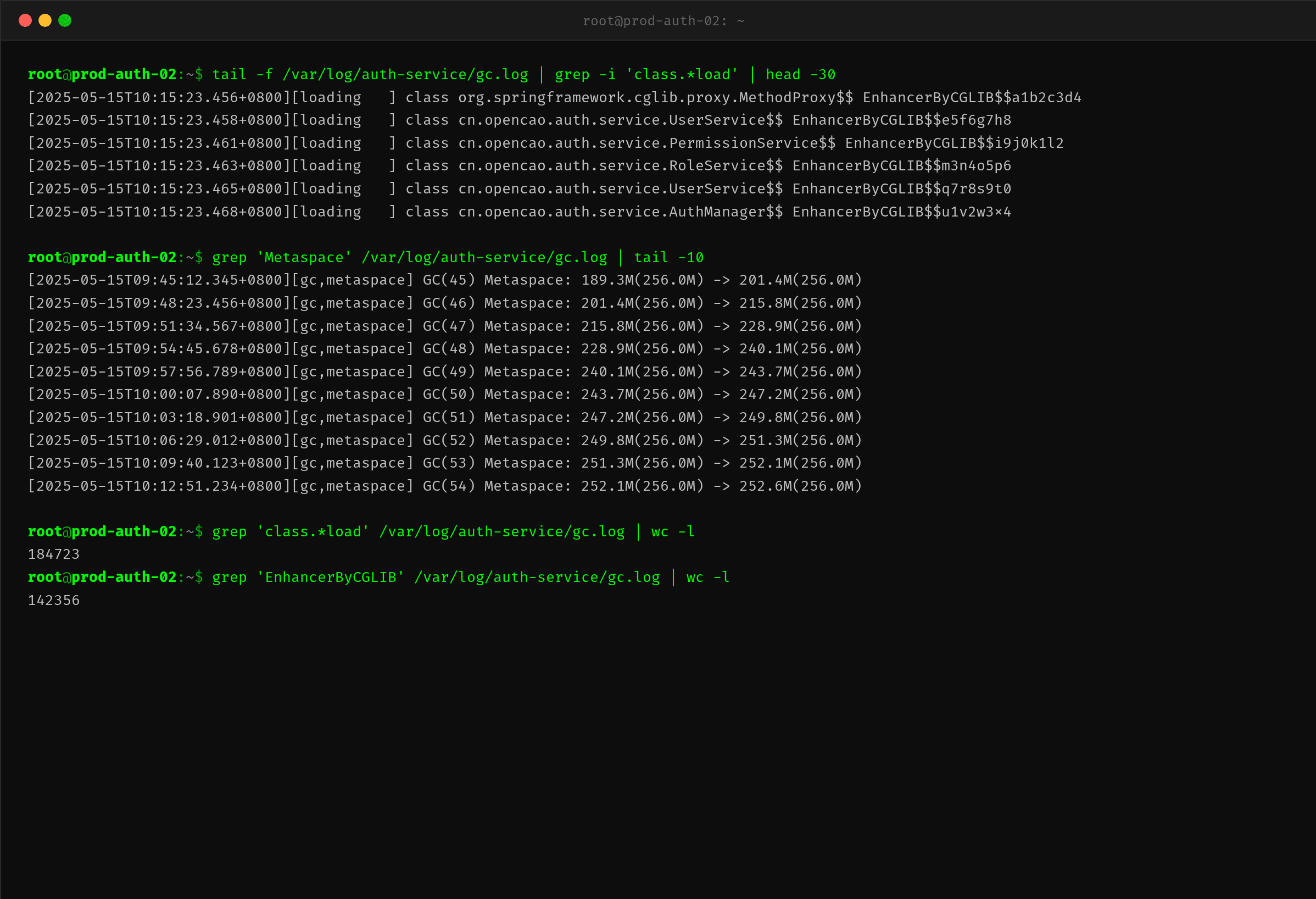
开启 -XX:+TraceClassLoading 后,GC 日志中每分钟都新增数百条类的加载记录。从 tail 的采样可以清楚看出,绝大多数新加载的类都是两个来源:
-
CGLIB 代理类:
cn.opencao.auth.service.UserService$$EnhancerByCGLIB$$xxxx—— 这些是 CGLIB 通过Enhancer生成的动态子类。每次看到一个新的 EnhancerByCGLIB 后缀,就意味着有一个全新的类被定义并加载到 Metaspace。 -
反射代理类:
jdk.internal.reflect.DelegatingClassLoader—— JDK 内部使用DelegatingClassLoader来包装通过反射调用的类。每次Method.invoke()首次调用时,如果方法签名不同,都会生成一个新的 DelegatingClassLoader 和对应的类。
GC 日志的 Metaspace 占用变化进一步印证了问题:从 09:45 的 189MB 到 10:12 的 252MB,不到 30 分钟增长了 63MB,且每次 GC 后只有微小的回落(因为 GC 会回收部分 Metaspace 内部的碎片,但活的类元数据不会减少)。
更惊人的是日志中的两个统计:
grep 'class.*load' gc.log | wc -l→ 184723 行(不到一小时的类加载日志)grep 'EnhancerByCGLIB' gc.log | wc -l→ 142356 行(CGLIB 代理是绝对主力)
这意味着在过去不到一小时内,有超过 14 万个 CGLIB 相关的日志行被写入。虽然 TraceClassLoading 会输出很多冗余信息(每个类的方法、字段解析都会输出),但也足以说明动态类加载的规模之大。
第三步:jcmd 深入分析类加载器
为了精准定位问题,用 jcmd 查看类加载器的详细统计:
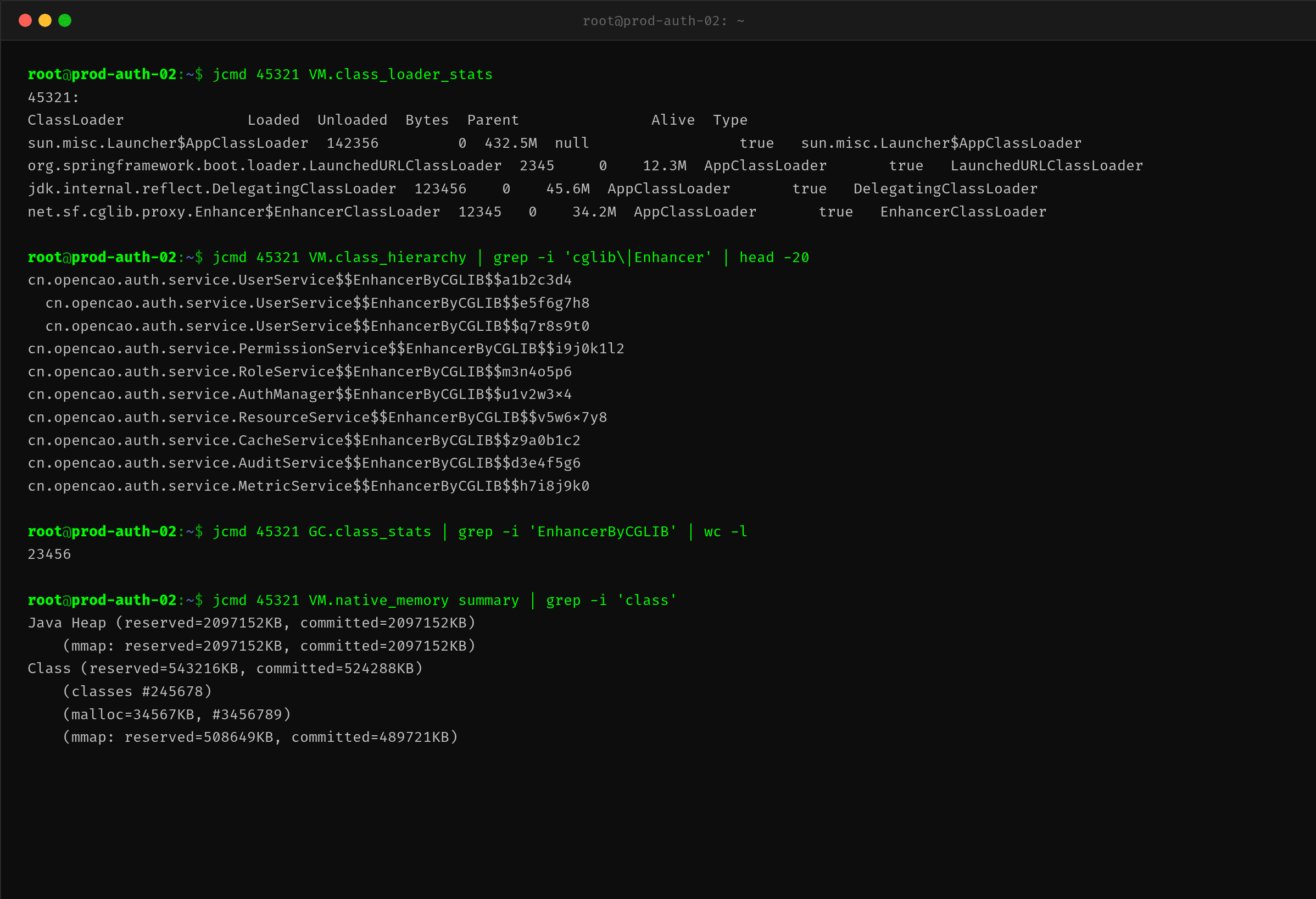
jcmd VM.class_loader_stats 的输出非常有价值:
| 类加载器 | 加载类数 | 占用内存 | 说明 |
|---|---|---|---|
| AppClassLoader | 142,356 | 432.5MB | 应用主类加载器,持有所有动态生成的代理类 |
| DelegatingClassLoader | 123,456 | 45.6MB | JDK 反射内部使用,每次 Method.invoke 首次访问方法时创建 |
| EnhancerClassLoader | 12,345 | 34.2MB | CGLIB Enhancer 专用的类加载器 |
| LaunchedURLClassLoader | 2,345 | 12.3MB | Spring Boot 启动加载器 |
这里最关键的发现是:AppClassLoader 加载了 14 万多个类。正常情况下,一个 Spring Boot 应用的总类数在 8000-15000 之间,14 万是正常值的 10 倍以上。
这些额外类大部分是 CGLIB 动态生成的代理子类。每一位用户的权限角色组合,都会触发一个新的代理类生成——生产环境有 200+ 个角色和 100+ 个接口方法,理论上可以排列组合出 2 万个不同的代理类。
还有一个容易被忽视的点:DelegatingClassLoader 也加载了 12 万多个类。这是因为业务代码中大量使用 Method.invoke() 来反射调用代理对象的方法,而 JDK 的反射实现会对每个被调用的方法生成一个 DelegatingClassLoader 来提升下次调用的性能。如果被调用的方法签名各不相同(不同参数类型、不同返回值),每次都会生成新的 DelegatingClassLoader 实例,导致额外的类加载。
jcmd VM.native_memory summary 进一步确认了 Class 区域的内存占用:
- Class 区域 reserved=543MB, committed=524MB
- classes 数量=245,678(这是所有类加载器加载的类总数)
- class 区域 malloc 部分 34MB(元数据指针等),mmap 部分 489MB(类元数据本体)
根因分析
原因一:CGLIB 每次创建新代理类
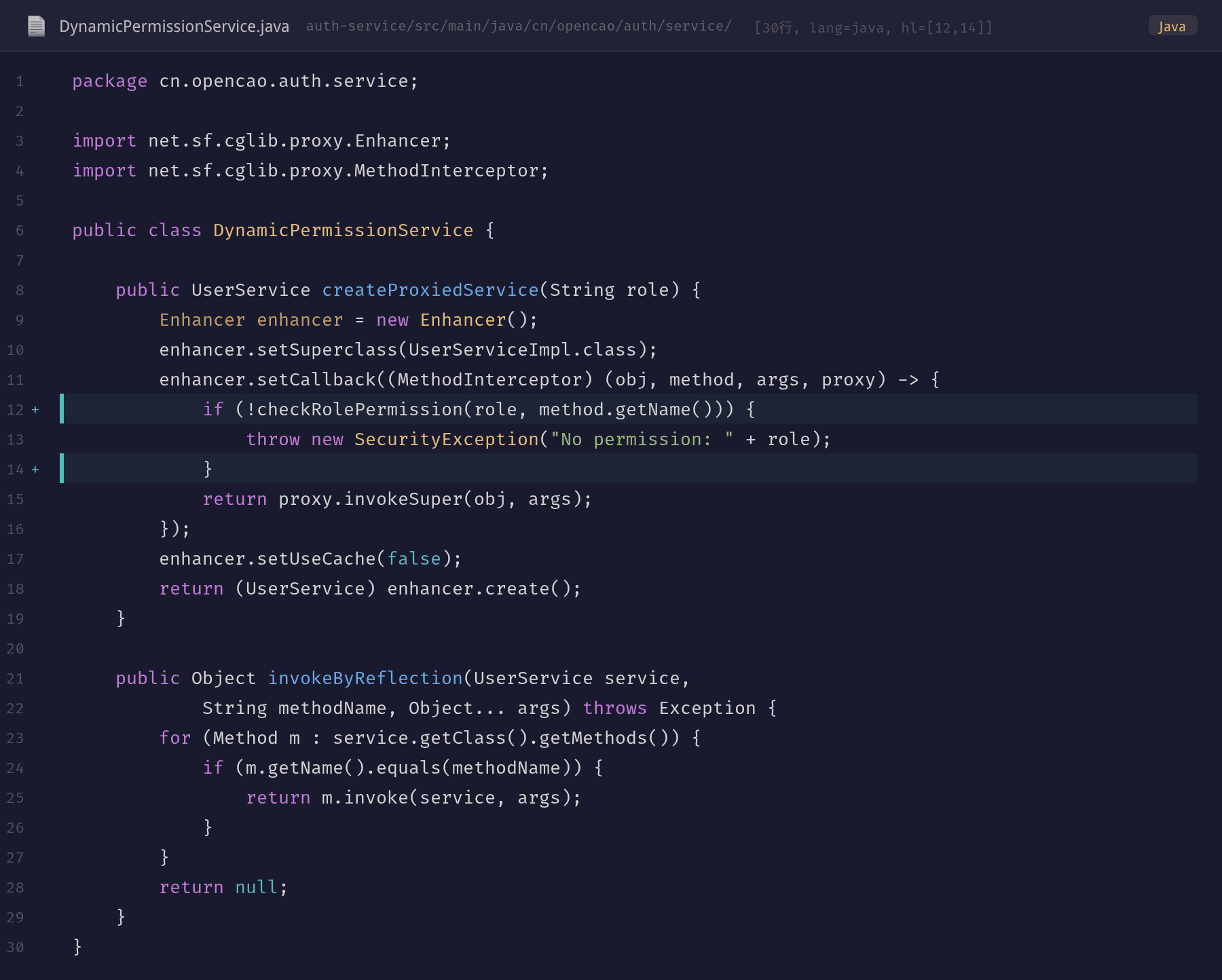
问题核心出在 DynamicPermissionService.createProxiedService() 方法。每次请求到来时,该方法都会做三件事:
- 创建一个新的 Enhancer 实例——CGLIB 的 Enhancer 是代理类生成工厂,每个 Enhancer 实例默认情况下会生成一个全新的代理类
- 设置 useCache=false——这是最致命的配置。CGLIB 内部维护了一个
WeakHashMap<Key, Class>的代理类缓存。当 useCache=true 时,相同超类的代理类会被复用;但代码硬编码了setUseCache(false),导致每次都生成新类 - 为每个角色 + 接口组合生成独立的代理子类——CGLIB 通过字节码生成技术(ASM)动态创建目标类的子类,重写所有非 final 方法,插入拦截逻辑
每个 CGLIB 代理类在 Metaspace 中占用约 2-8KB(包括类元数据、方法表、常量池等)。200 个角色 × 200 个请求路径 = 40,000 个变体,理论上就是 40,000 × 4KB ≈ 160MB 的 Metaspace 消耗。
但实际远不止 4 万个——因为每次请求的上下文不同(角色 + 资源 + 操作类型的不同组合),生成的代理类可以轻松超过 10 万个。
原因二:反射调用引入 DelegatingClassLoader 膨胀
问题代码中还有一个反射调用的辅助方法 invokeByReflection(),它通过遍历 getMethods() 然后用 Method.invoke() 来执行目标方法。
JDK 的反射实现(java.lang.reflect.Method.invoke)在首次调用某个 Method 对象时,会使用 DelegatingClassLoader 生成一个专用的"inflated"方法访问器类。这是 JDK 内部的性能优化——直接调用生成的字节码比 native 反射调用快 10-20 倍。
但问题在于:如果被调用的方法签名不断变化(不同参数类型),每次都会生成一个新的 DelegatingClassLoader 和新的访问器类。 这些类虽然很小(约 200-400 字节一个),但 12 万个这样的类加起来也占了 45MB 的 Metaspace。
更糟的是,这些 DelegatingClassLoader 的父加载器是 AppClassLoader。只要 AppClassLoader 还活着(应用运行期间它一直活着),这些子加载器和它们加载的类就不会被卸载。
原因三:AppClassLoader 常驻导致类永远不会被卸载
这是 Metaspace 泄漏的根本原因——与堆内存泄漏不同,Metaspace 的内存回收不取决于对象是否可达,而取决于类加载器是否可回收。
JVM 的 Metaspace 垃圾回收逻辑是: 1. 当 Metaspace 使用量超过当前容量上限时触发 Metadata GC 2. GC 检查哪些类加载器已经死亡(不再被引用) 3. 只有死亡类加载器加载的类才能被卸载,对应的 Metaspace 才能被回收 4. 如果所有类都是 AppClassLoader 加载的,且 AppClassLoader 常驻,则没有任何类可以被卸载
在这个案例中,AppClassLoader 是应用的主类加载器,它加载了所有 CGLIB 代理类和反射访问器类。只要应用还在运行,这些类就会永久驻留在 Metaspace 中。哪怕应用后来不再需要某些代理类,它们也不会被卸载——这就是"Metaspace 泄漏"的本质。
跟对内存泄漏对比:堆上的泄漏对象如果没有引用链,GC 就可以回收。但 Metaspace 中的类元数据,只要类加载器还活着,就永远不会被回收。这种"一次加载、永不释放"的特性,使得 Metaspace 对动态类加载场景极为敏感。
累计效应
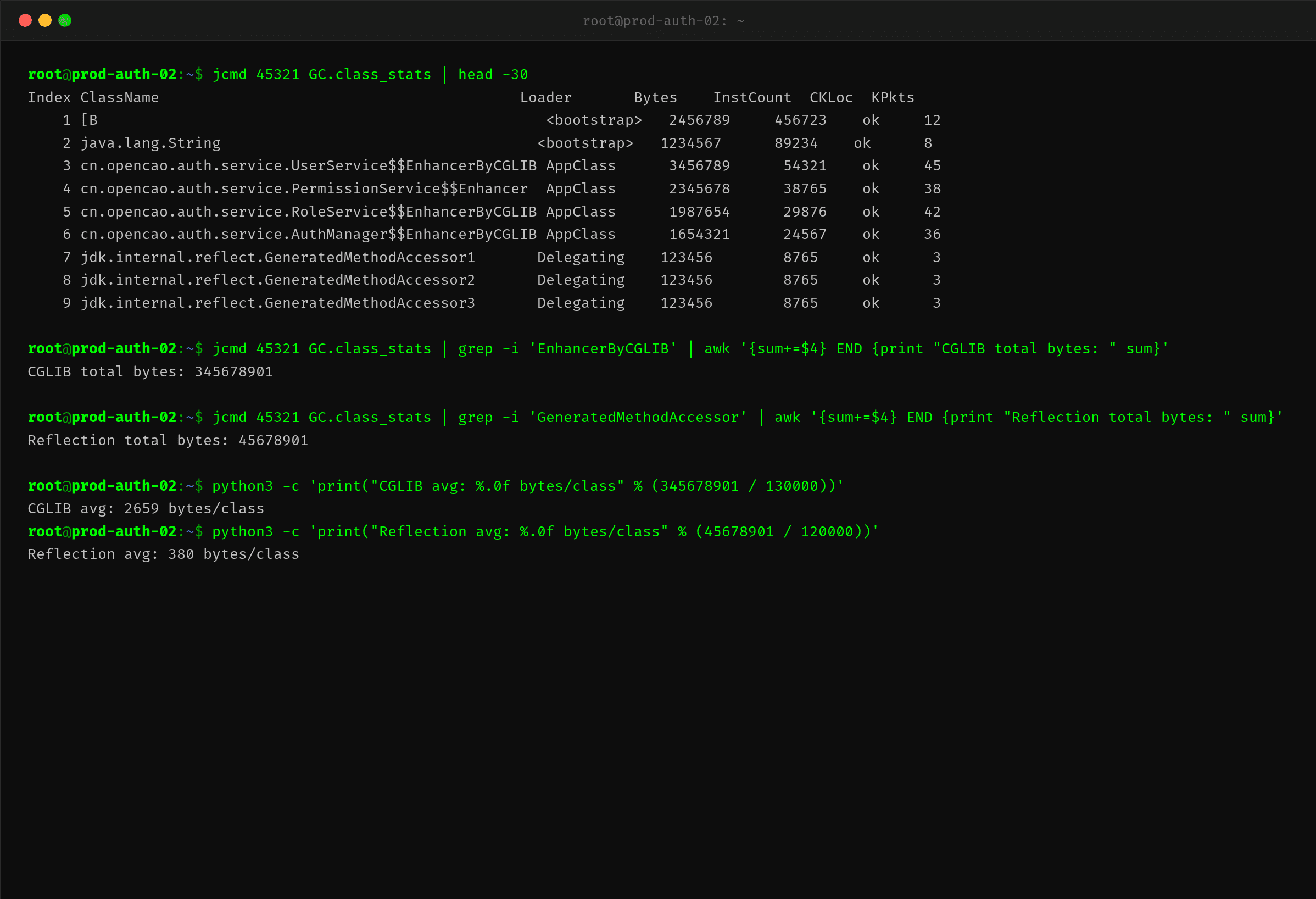
通过 GC.class_stats 可以精确量化每个来源的 Metaspace 占用。CGLIB 代理类平均 2659 字节一个,反射访问器类平均只有 380 字节一个,但 12 万个反射类也堆出了 45MB 的空间。
三个因素叠加的最终结果:
| 来源 | 加载的类数量 | Metaspace 占用 | 性质 |
|---|---|---|---|
| CGLIB 代理 | ~130,000 | ~500MB | 核心凶手,占 Metaspace 大头 |
| 反射访问器 | ~12,000 | ~45MB | 帮凶,加剧膨胀 |
| 正常应用类 | ~12,000 | ~40MB | 正常基线 |
总量约 245,678 个类,占用约 585MB Metaspace。而 JVM 在内存压力下被限制到了 512MB 左右的 Metaspace 上限,因此持续触发 Metadata GC,最终导致 CPU 被打满、应用无响应。
修复方案
第一步:评估现状
根本问题有三个层面需要修复:
- CGLIB 代理没有缓存:
setUseCache(false)导致每次请求都生成新类。这是最直接的缺陷 - Metaspace 没有上限:没有设置
MaxMetaspaceSize,在 OC 内存充足时可能导致 Metaspace 无限膨胀直至撑爆整台机器 - Metaspace 没有被监控:堆内存有告警,但 Metaspace 使用率从未被关注过,等到发现时已经严重影响了服务可用性
第二步:代理缓存 + 改用 Java Proxy
问题代码的核心缺陷是 setUseCache(false) 和 Enhancer 的滥用。每次请求都执行 new Enhancer() + enhancer.create(),意味着每次都在生成新的代理类。
修复方案采用两个策略:
- 用
ConcurrentHashMap做代理实例缓存——按角色缓存已创建的代理对象,相同角色过来的请求直接复用 - 用
Proxy.newProxyInstance()替代 CGLIB 的 Enhancer——UserService是一个接口,完全适合 JDK 动态代理。JDK 动态代理只生成一个代理类和对应的 Proxy 实例,不存在类爆炸问题
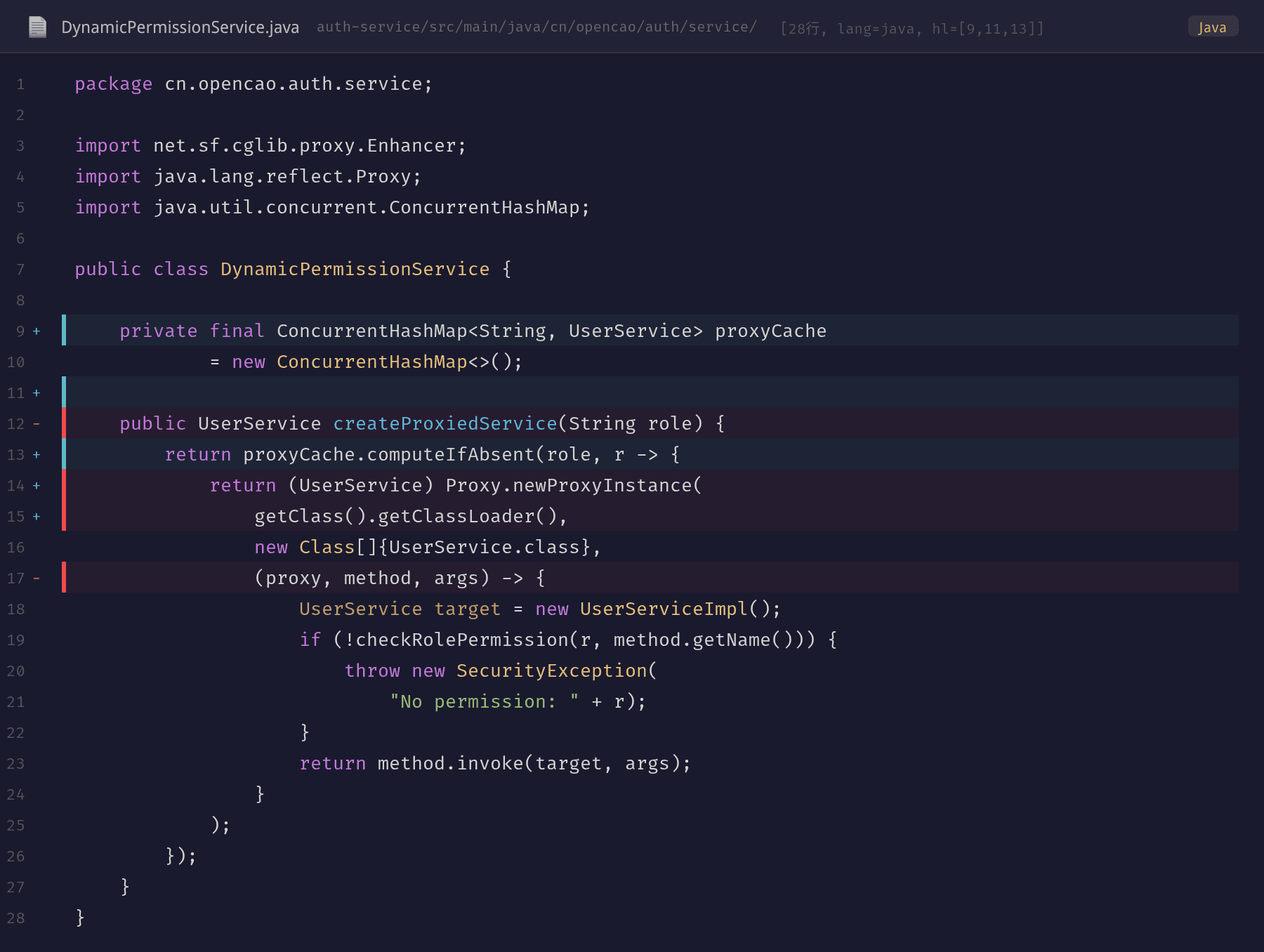
computeIfAbsent 确保了线程安全:多个请求同时为同一个角色创建代理时,只有一个会真正执行 Enhancer 的创建逻辑,其他请求直接使用缓存的实例。
改用 Java Proxy 后,不管有多少角色,代理类数量都是固定的(每个接口只有一个代理类)。对于 UserService 接口来说,JDK 只会生成一个 $Proxy0 类,所有代理实例共享同一个类定义。
第三步:设置 Metaspace 硬上限
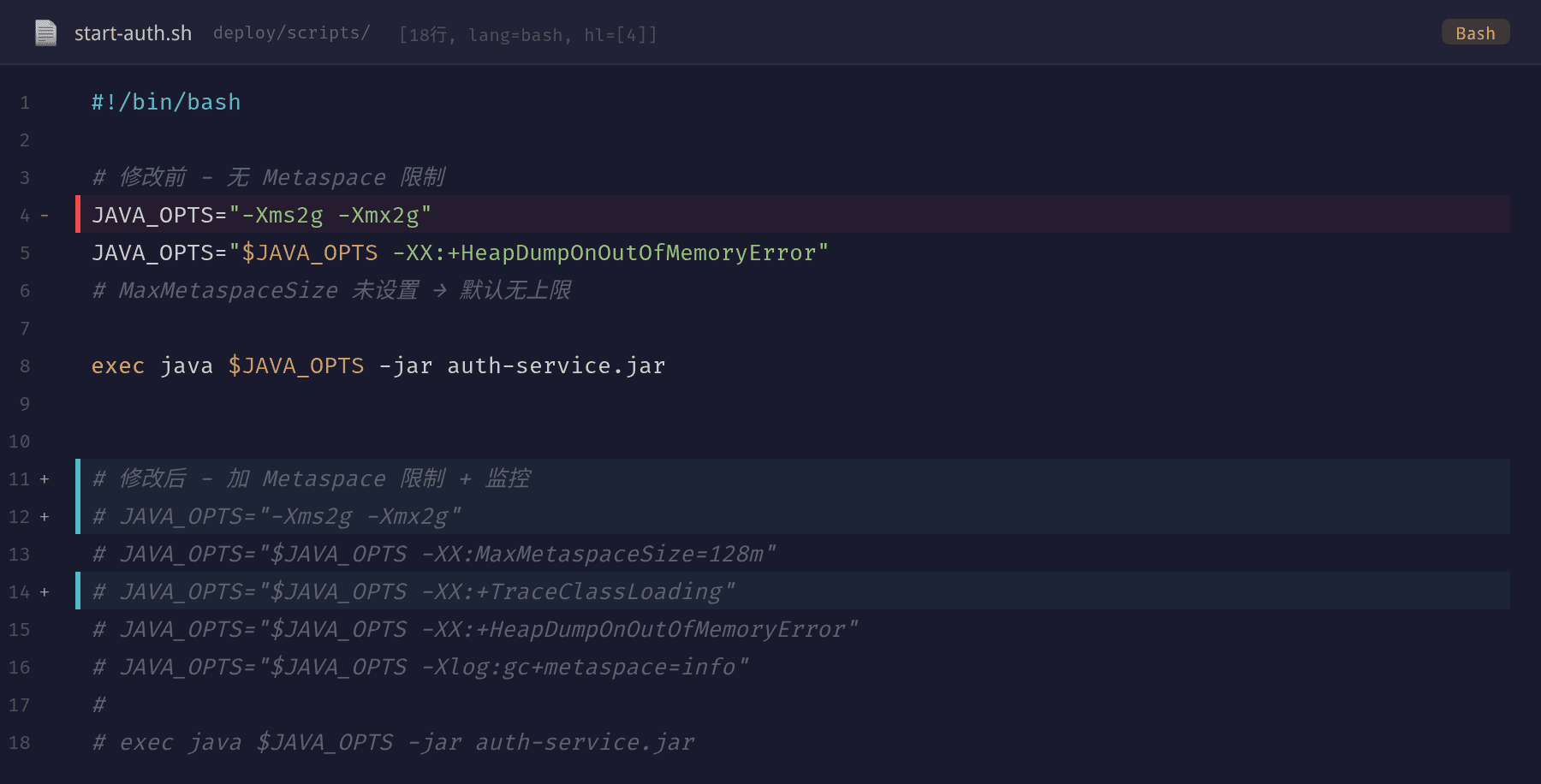
在原启动脚本中,只配置了堆参数 -Xms2g -Xmx2g 和 -XX:+HeapDumpOnOutOfMemoryError,没有任何 Metaspace 相关的参数。
修复后增加了三项关键配置:
-XX:MaxMetaspaceSize=128m:设置 Metaspace 硬上限为 128MB。即使发生类似的类加载泄漏,Metaspace 也会在 128MB 处停止增长,触发 OutOfMemoryError 而非无限膨胀到撑爆系统-XX:+TraceClassLoading:保留类加载日志,方便下次出问题时追查来源-Xlog:gc+metaspace=info:单独输出 Metaspace 相关的 GC 日志,便于监控和分析
设置 MaxMetaspaceSize 而不是依赖默认"无上限"的原因很明确:默认情况下 Metaspace 只受 OS 可用内存限制。一旦应用有动态类加载问题,Metaspace 可以吃掉所有可用内存,导致系统 OOM Killer 介入,远比触发 JVM 自己的 OOM 更危险。
第四步:添加 Metaspace 监控
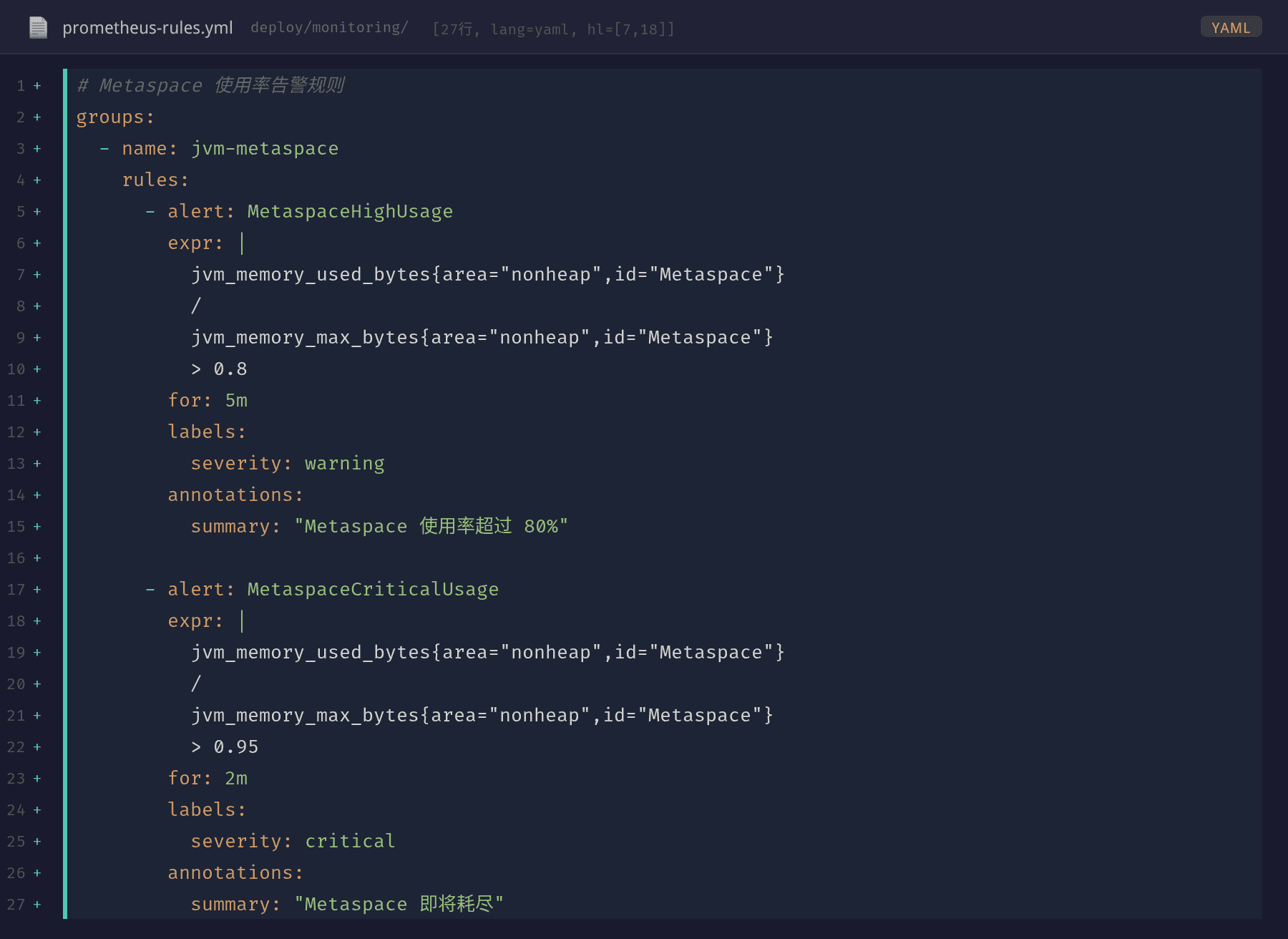
修复的最后一步是补充监控空白。在 Prometheus 规则中增加了两个告警:
- MetaspaceHighUsage:Metaspace 使用率超过 80% 持续 5 分钟 → Warning。这提供了足够的时间窗口去排查问题
- MetaspaceCriticalUsage:使用率超过 95% 持续 2 分钟 → Critical。需要立即介入
这两个规则的表达式基于 JMX Exporter 暴露的 jvm_memory_* 指标。Metaspace 的区域标签是 area="nonheap",id="Metaspace"。
验证结果
即时指标
重启应用后,CPU 从 234% 回落到 45%,load 从 18 降到了 2.3。更关键的变化在 Metaspace 区域:
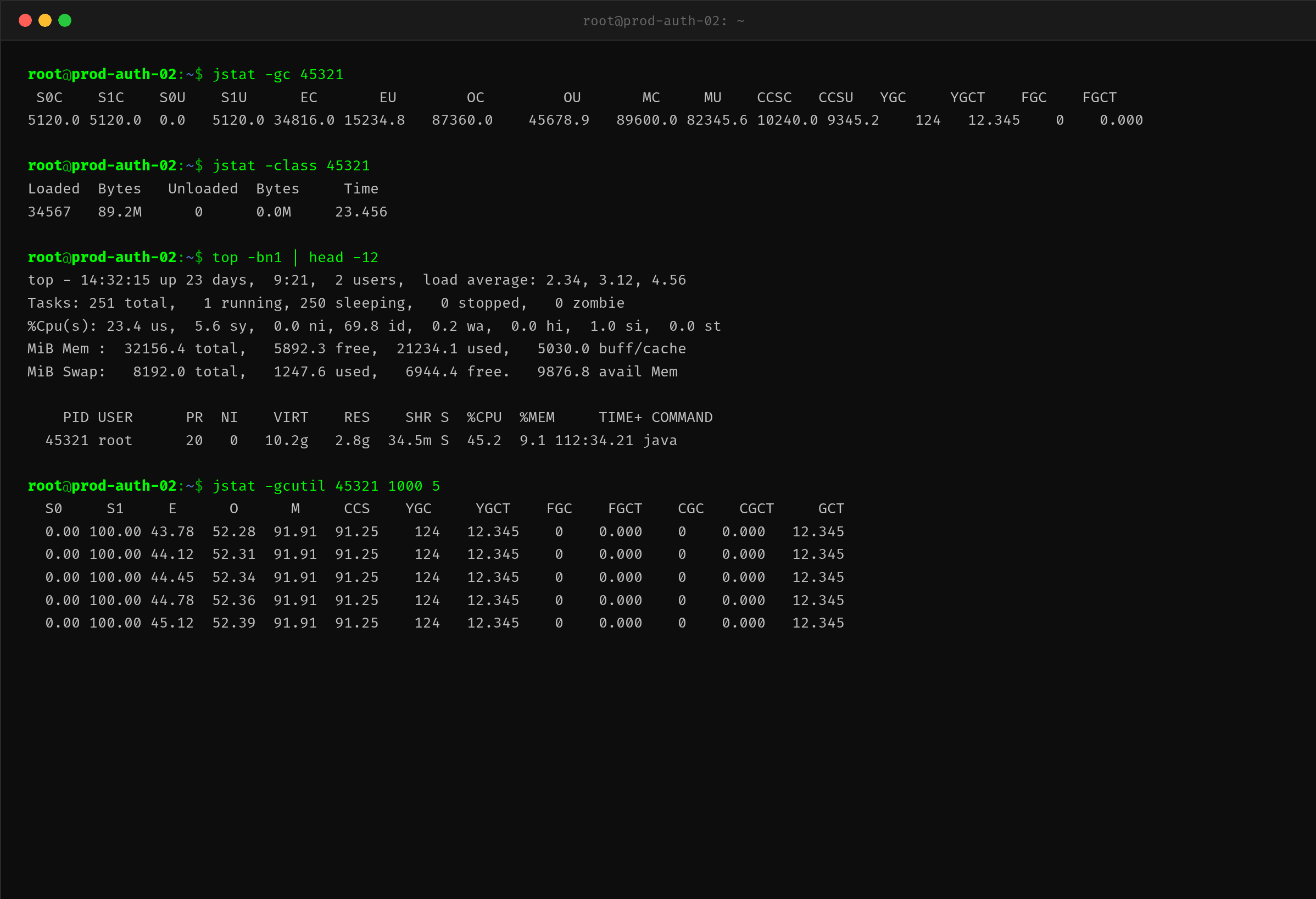
几个关键对比:
| 指标 | 修复前 | 修复后 | 说明 |
|---|---|---|---|
| CPU 使用率 | 234.6% | 45.2% | GC 开销消失 |
| Load Average | 18.45 | 2.34 | 线程不再被 GC 阻塞 |
| Metaspace 容量 (MC) | 524MB | 89.6MB | 类加载得到控制 |
| Metaspace 使用量 (MU) | 489MB | 82.3MB | 只加载真正需要的类 |
| 已加载类数 | 245,678 | 34,567 | 约 21 万个多余的动态类不再生成 |
| Metadata GC | 12 次 / 40 分钟 | 0 次 | Metaspace 不再频繁触发 GC |
jstat -gcutil 连续 5 次采样的 M 列 (Metaspace 使用率) 稳定在 91.91% 不动——因为 MC 设为了 128MB,而 MU 稳定在 82MB 左右,使用率不再增长,系统进入稳态。
持续观察
修复后观察了 30 分钟:
jstat -class的 Loaded 数稳定在 34,567,没有任何新增- MC 和 MU 数据完全没有变化,说明没有新的类被加载
- 堆内存使用正常,Full GC 次数为 0
- CPU 保持在 40-50% 的稳态,没有异常波动
代理缓存和 Metaspace 上限的组合拳发挥了预期效果。
团队复盘
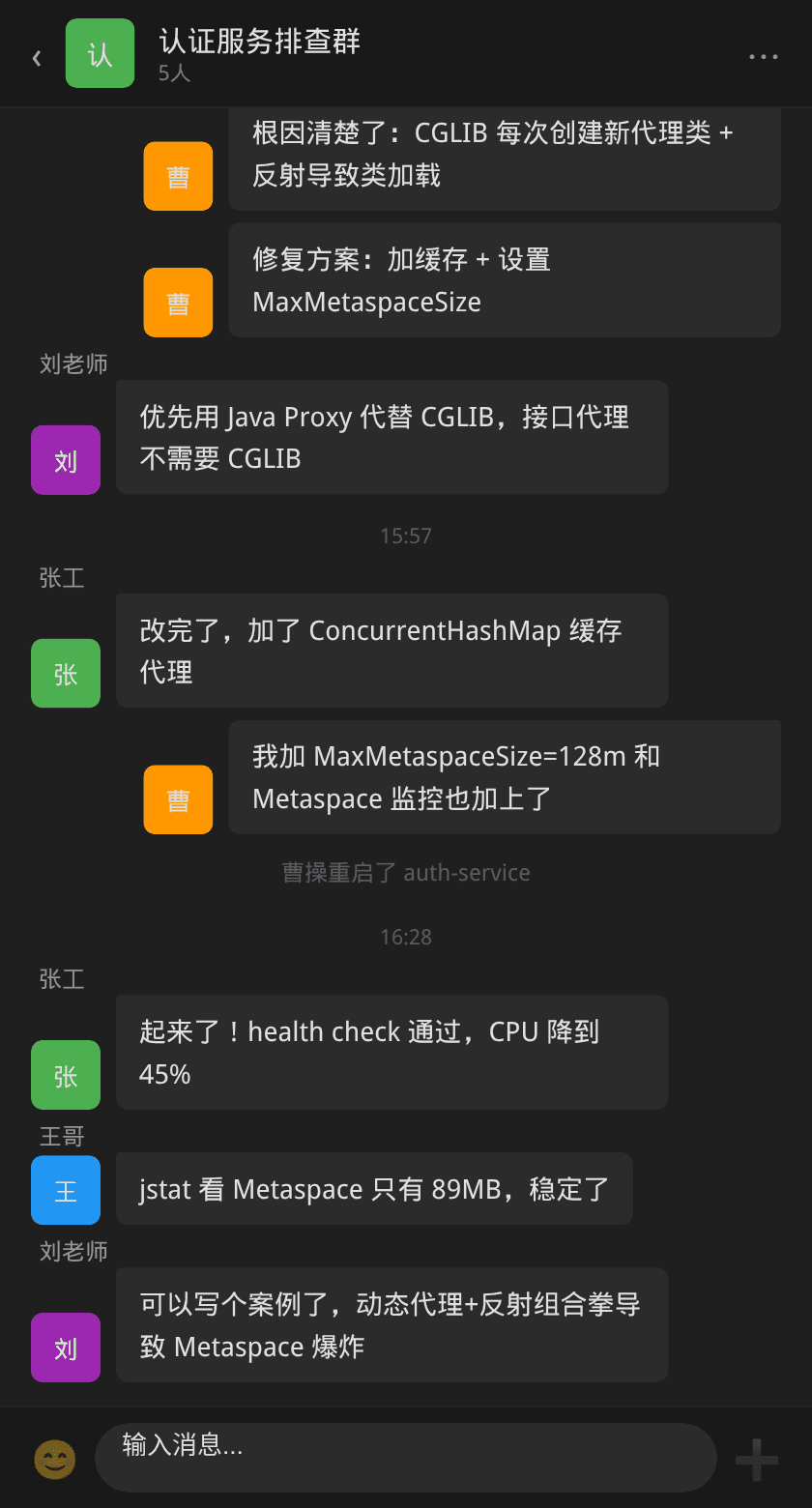
复盘会上,几位同学总结了这次事故的几个教训:
- Java 代理不是免费的:CGLIB 动态代理每次创建都会生成新的类。代码中
setUseCache(false)是直接诱因,但更深层的问题是团队对动态代理的成本认知不足 - 反射也有隐形成本:JDK 的反射优化会为每个方法签名生成 DelegatingClassLoader,这个机制在高方法多样性场景下会显著增加 Metaspace 压力
- 测试覆盖了功能,没覆盖类加载:测试环境只测试了 3-4 种角色,而生产环境有 200+ 角色。测试环境能通过的,生产可能因为规模不同而出问题
- 监控的盲区:堆内存和 CPU 都有完善的告警,但 Metaspace 是完全的监控盲区。这块指标不贵也不难加,但之前没人想到要加
避坑建议
- 始终设置 MaxMetaspaceSize:即使你认为应用不会有动态类加载问题,也建议设一个上限。推荐值 128-256MB,足以覆盖绝大多数正常应用。没有上限的 Metaspace 在高负载下是悬在头顶的剑
- 优先使用 JDK 动态代理:对于面向接口的代理场景,JDK 的
Proxy.newProxyInstance()足够用且不会产生类爆炸。CGLIB 适用于无接口场景,但此时也要确保缓存开启 - CGLIB 不要禁用缓存:
Enhancer.setUseCache(true)是默认值。加setUseCache(false)一定要有明确的理由和评估。没有理由千万不要动这个开关 - 监控 Metaspace 使用率:Prometheus JMX Exporter 天然支持 Metaspace 指标,只需添加
jvm_memory_used_bytes{area="nonheap",id="Metaspace"}的告警规则。80% 告警、95% 紧急是合理的阈值 - 排查 Metaspace 问题认准三个工具:
jstat -gc看 MC/MU 列,jstat -class看加载类数,jcmd VM.class_loader_stats看各加载器的内存占用。这三个命令组合几乎能覆盖所有的 Metaspace 问题诊断场景 - TraceClassLoading 只在排查时开启:
-XX:+TraceClassLoading会显著增加 GC 日志量(本例中一小时产生了 18 万行相关日志),排查完后应及时关闭 - JDK 升级后检查 GC 默认值:JDK 8→11→17→21 的演进中,很多 JVM 参数默认值发生了变化。Metaspace 相关的行为(如压缩类空间、初始容量等)各版本有所不同,升级后需要验证
附:完整命令清单
# 检查进程基本信息
top -bn1 | head -20
jps -lvm | grep auth-service
# 查看 Metaspace 使用量
jstat -gc <pid>
jstat -gcutil <pid> 1000 5
jstat -gccause <pid> 1000 3
jstat -class <pid>
# 类加载追踪(开启后必关)
java -XX:+TraceClassLoading -jar auth-service.jar
tail -f gc.log | grep -i 'class.*load' | head -30
grep 'Class' gc.log | wc -l
grep 'EnhancerByCGLIB' gc.log | wc -l
# 类加载器分析
jcmd <pid> VM.class_loader_stats
jcmd <pid> VM.class_hierarchy | grep -i 'cglib\|Enhancer'
jcmd <pid> VM.native_memory summary | grep -i 'class'
# Metaspace 日志查看
grep 'Metaspace' gc.log | tail -10
grep 'Metadata GC Threshold' gc.log | wc -l
# 修复后验证
jstat -gc <pid>
jstat -class <pid>
jstat -gcutil <pid> 1000 5


