
Agent 的诞生:从 LLM 到 Autonomous Agent
本文是 AI 技术实战 系列开篇 叙事框架:
能力边界 → 演化路径 → 核心架构 → 关键模式 → 避坑思考
从聊天窗口到自主行动
2023 年初,ChatGPT 横空出世,全世界都在问同一个问题:大语言模型到底能干什么?
它能写诗,能写代码,能回答历史问题,能扮演角色。但如果你说「帮我查一下今天北京的天气」,它会回答「我的知识截止于某年某月,无法获取实时信息」。如果你说「帮我订一张明天去上海的机票」,它只能给出订票步骤,却无法真正帮你操作。
这就是 LLM 的尴尬:它像是一个被困在聊天窗口里的天才大脑——拥有惊人的知识储备和推理能力,但没有手、没有脚、无法感知外部世界、无法执行具体操作。
Autonomous Agent(自主智能体)要解决的,正是这个问题。它给大脑装上了身体,让 LLM 从「被动回答问题」进化为「主动完成任务」。
LLM 的能力边界
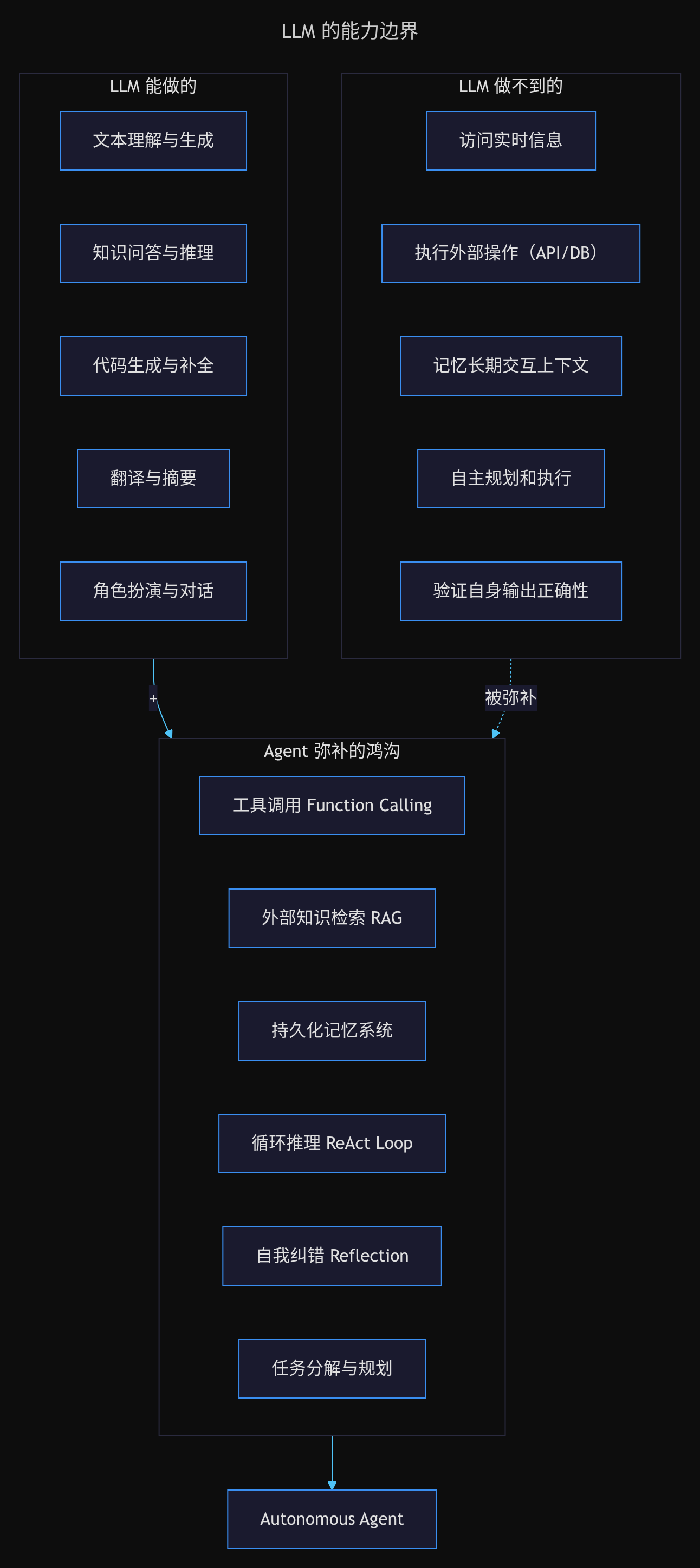
要理解 Agent 的价值,首先要看清 LLM 的能力边界。
LLM 擅长的
文本层面的任务,LLM 做得非常好:
- 文本理解与生成:读懂长文、写摘要、翻译、改写
- 知识问答与推理:基于训练数据回答事实性问题,做逻辑推理
- 代码生成与补全:从自然语言描述生成代码,或者续写已有代码
- 角色扮演与对话:保持特定 persona,进行多轮交互
这些能力的本质,是 LLM 在数万亿 token 的训练数据上学到的模式匹配与生成能力。
LLM 做不到的
但 LLM 有四个天然瓶颈,决定了它无法独立完成实际任务:
无法获取实时信息。训练数据有截止日期,LLM 不知道自己不知道什么。你问它今天的股价,它只能靠猜测。
无法执行外部操作。LLM 的输出是文本,不能直接调用 API、查询数据库、发送 HTTP 请求——不能对外部世界产生任何实质影响。
无法记忆长期上下文。Transformer 的自注意力机制受限于上下文窗口长度(从早期的 4K 到现在的 128K token),一旦超出窗口范围,信息就丢失了。
无法自主规划和纠错。LLM 每次回答都是独立生成的,没有「尝试→观察→调整」的循环机制。如果第一次回答错误,它不会自动纠正。
这些瓶颈不是模型能力的缺陷,而是架构上的根本限制——如同一个被困在房间里、只能通过文字与外界交流的天才。
从 LLM 到 Agent:五个演化阶段
从纯 LLM 到 Autonomous Agent 不是一蹴而就的,它经历了一个渐进的演化过程。理解这个过程有助于我们把握 Agent 的核心设计思想。
阶段一:纯 LLM

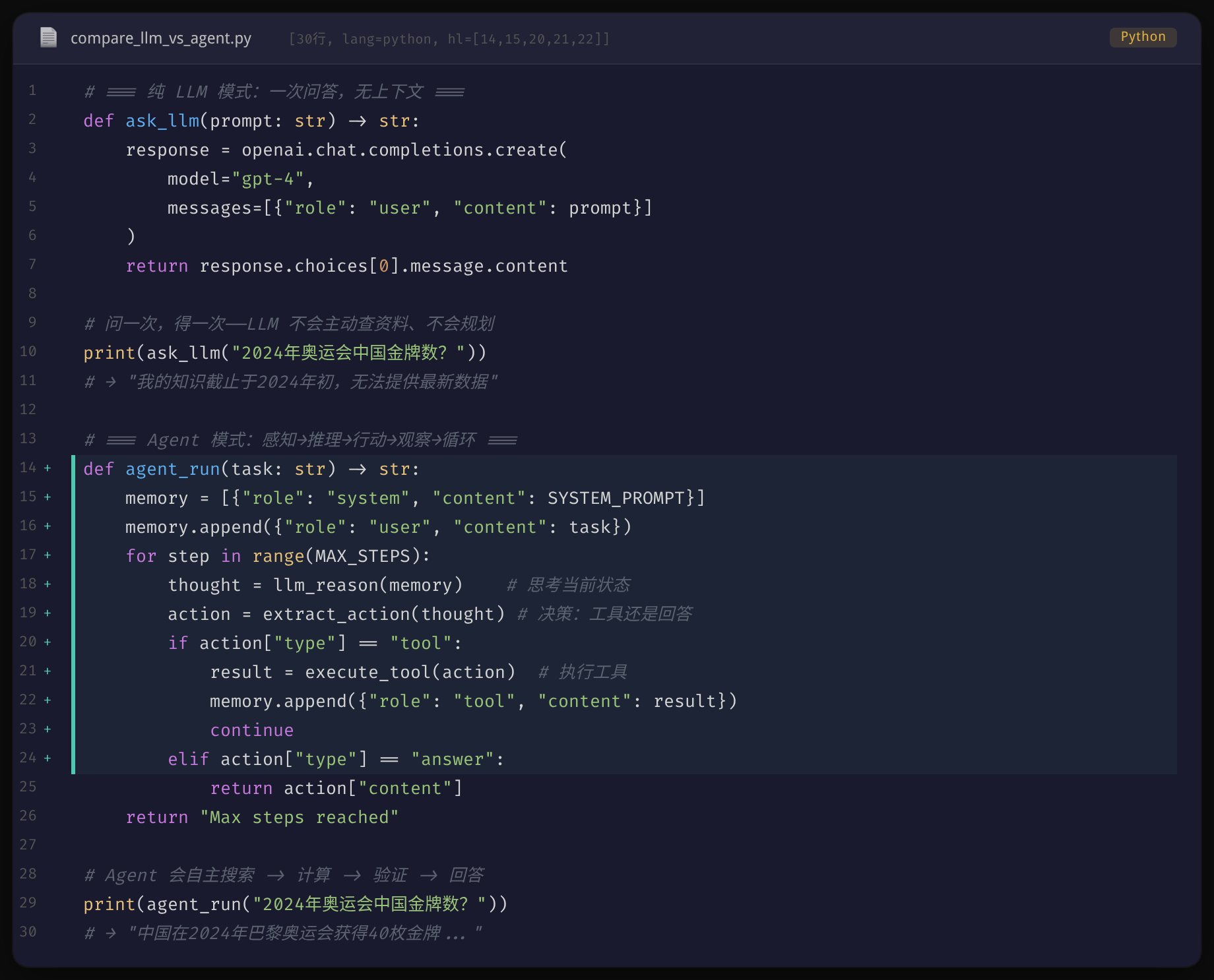
这是最原始的形态——用户输入 prompt,LLM 输出回答。没有上下文,没有工具,没有记忆。
用户:2024年奥运会中国金牌数?
LLM:我的知识截止于2024年初,无法提供最新数据。
这个阶段的能力完全取决于训练数据。LLM 是一个知识的「静态快照」。
阶段二:LLM + 上下文工程
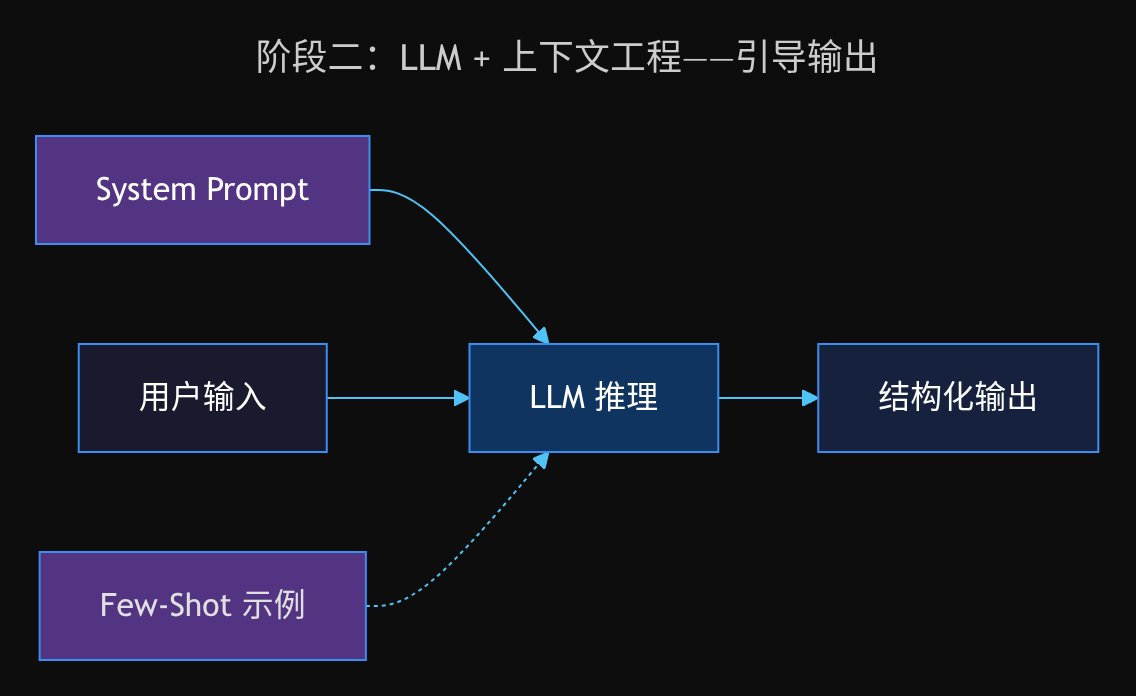
人们发现,通过精心设计的 System Prompt 和 Few-Shot 示例,可以大幅提升 LLM 的输出质量。上下文工程开始兴起:
System Prompt:
你是一个数据分析助手。当你被问到数值问题时,你要先查找信息,然后计算,最后输出。
User:
2024年奥运会中国金牌数?
这本质上没有改变 LLM 的能力边界,只是在引导 LLM 用更好的方式使用已有的能力。
阶段三:LLM + 工具调用
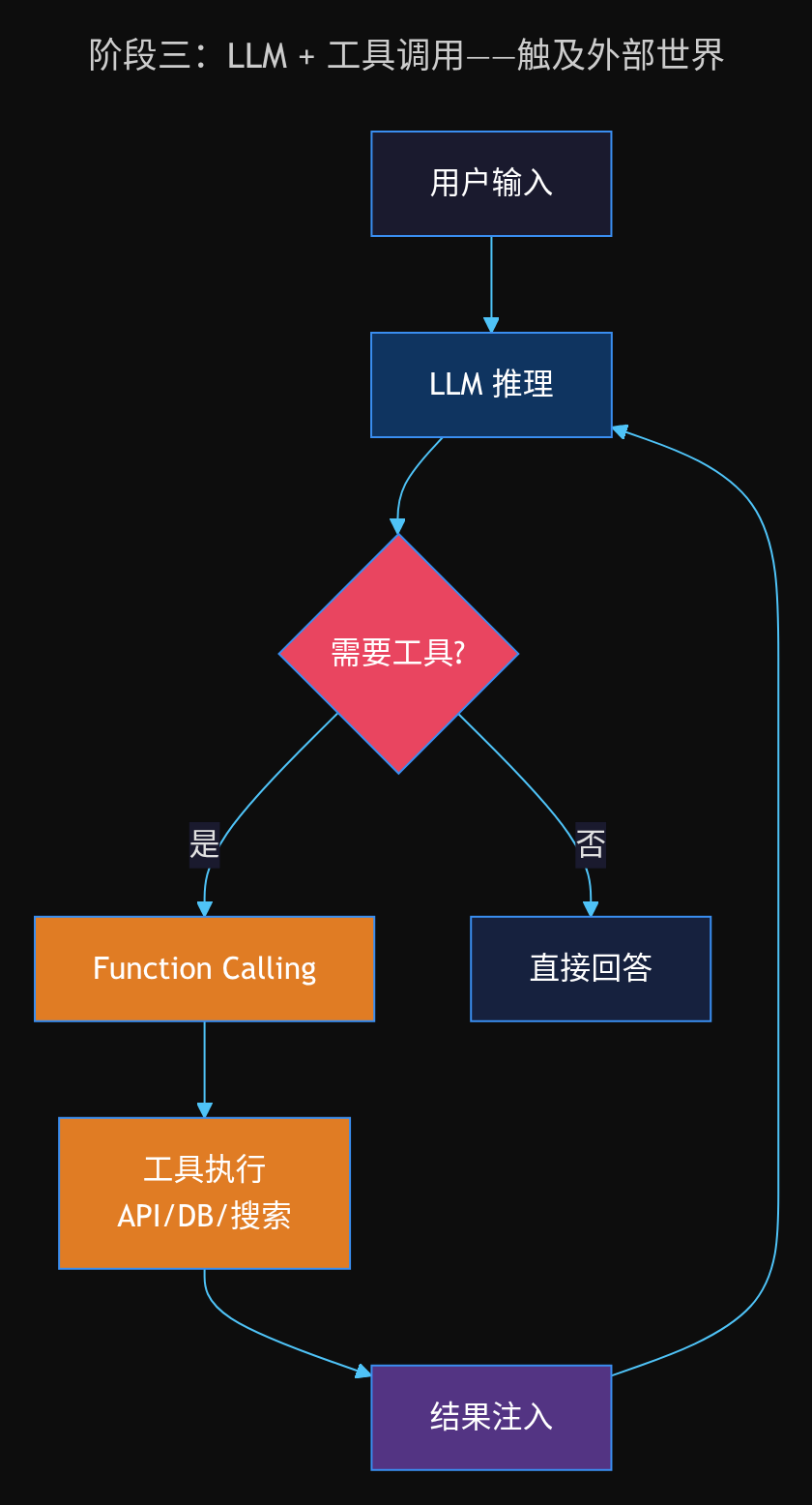
这是质的飞跃。OpenAI 在 2023 年 6 月发布的 Function Calling 能力,让 LLM 可以请求调用外部工具,而不是只输出文本。
工作流变成了:
- 用户提问
- LLM 判断需要调用什么工具(输出结构化调用请求)
- 外部系统执行工具(查询数据库、调用 API)
- 将结果注入 LLM 的上下文
- LLM 基于结果生成最终回答
这是 Agent 的雏形——LLM 第一次可以「伸手」触及外部世界。
阶段四:LLM + 循环推理
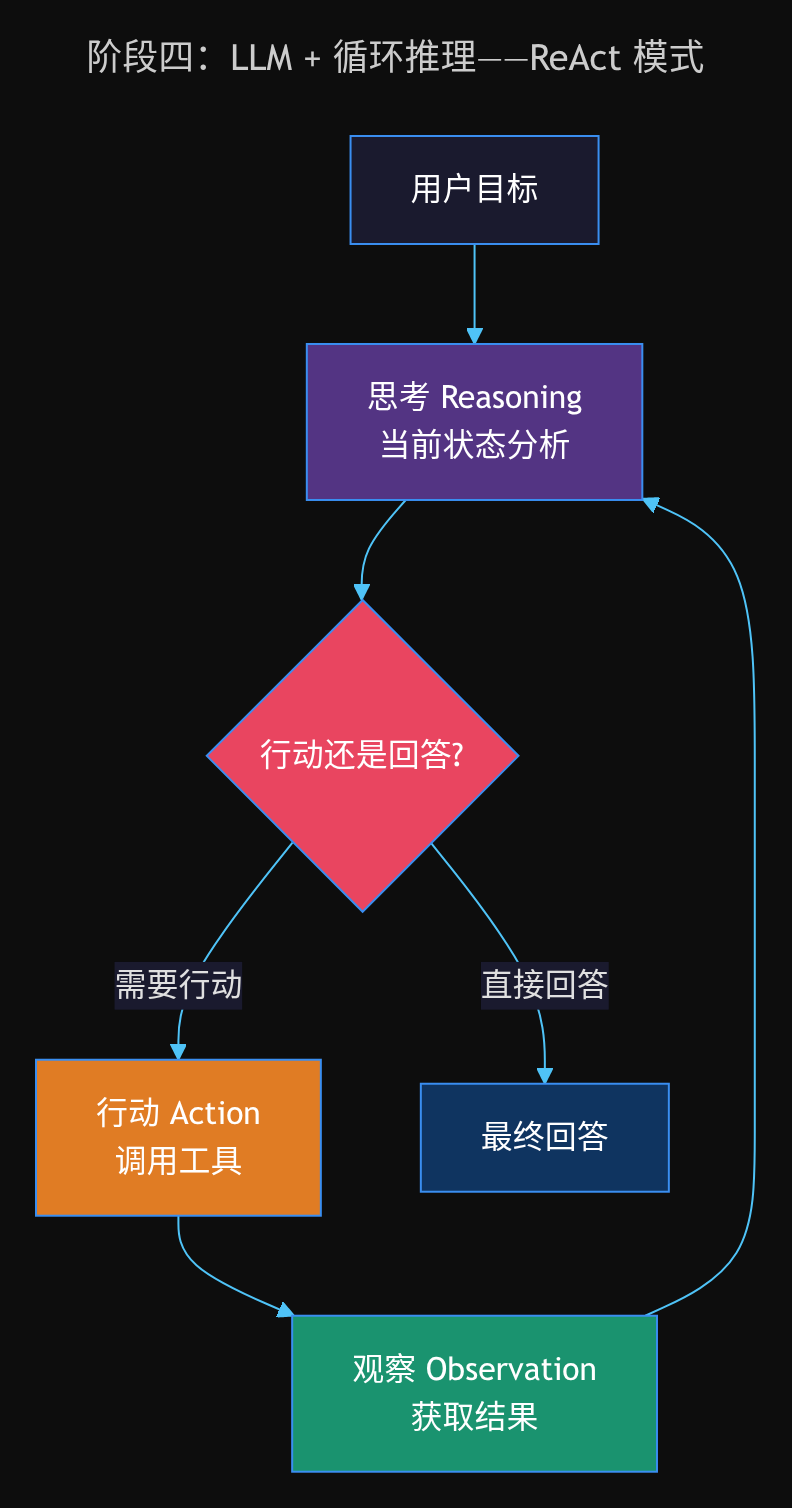
ReAct 模式(Reasoning + Acting)的出现,让 LLM 进入一个持续的推理→行动→观察循环:
每一轮,LLM 先「思考」当前状态,然后决定是采取行动还是给出最终答案。如果行动有结果,就把结果纳入下一轮思考。
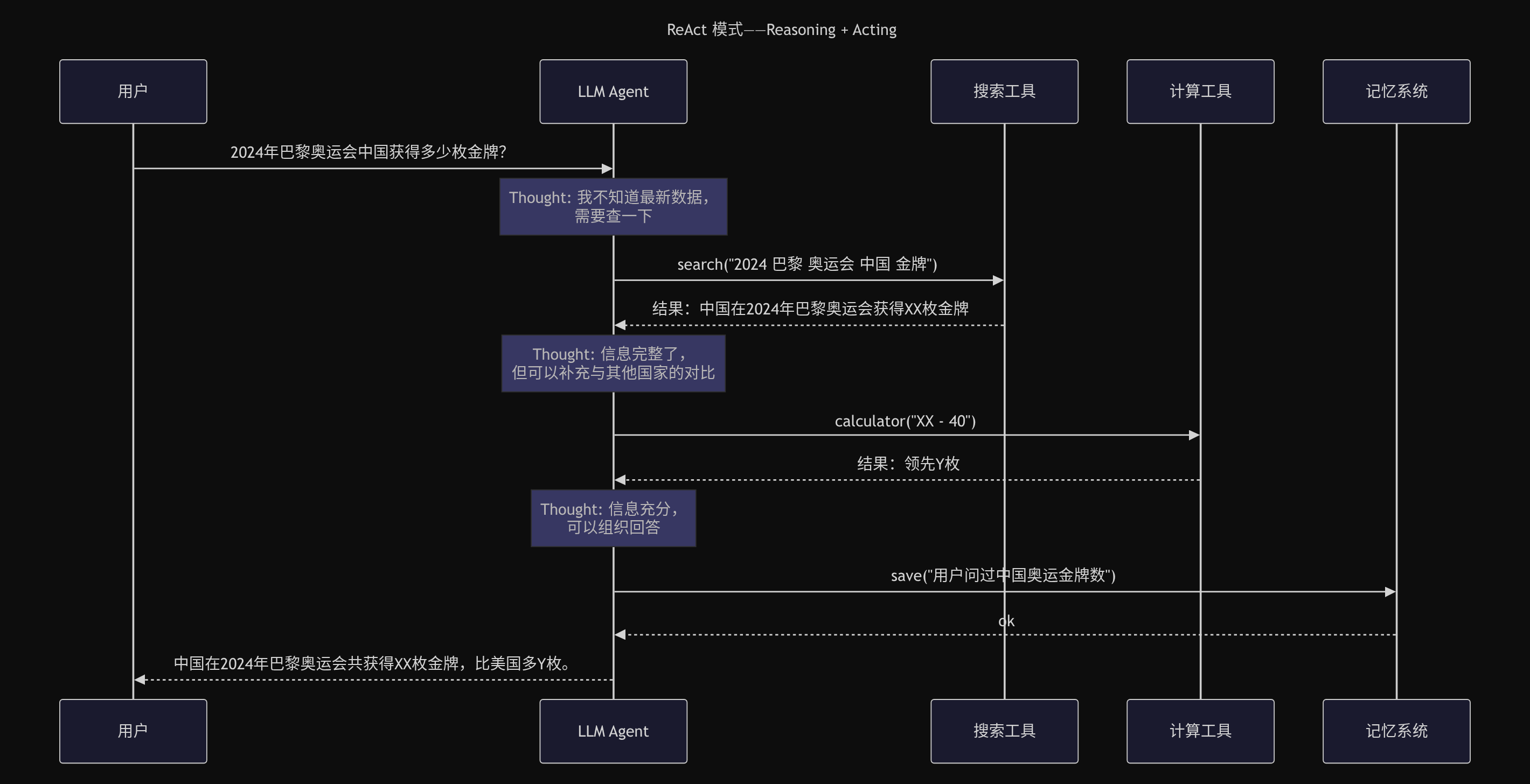
这让 LLM 能够处理多步任务,而不是一次问答就结束。
阶段五:Autonomous Agent
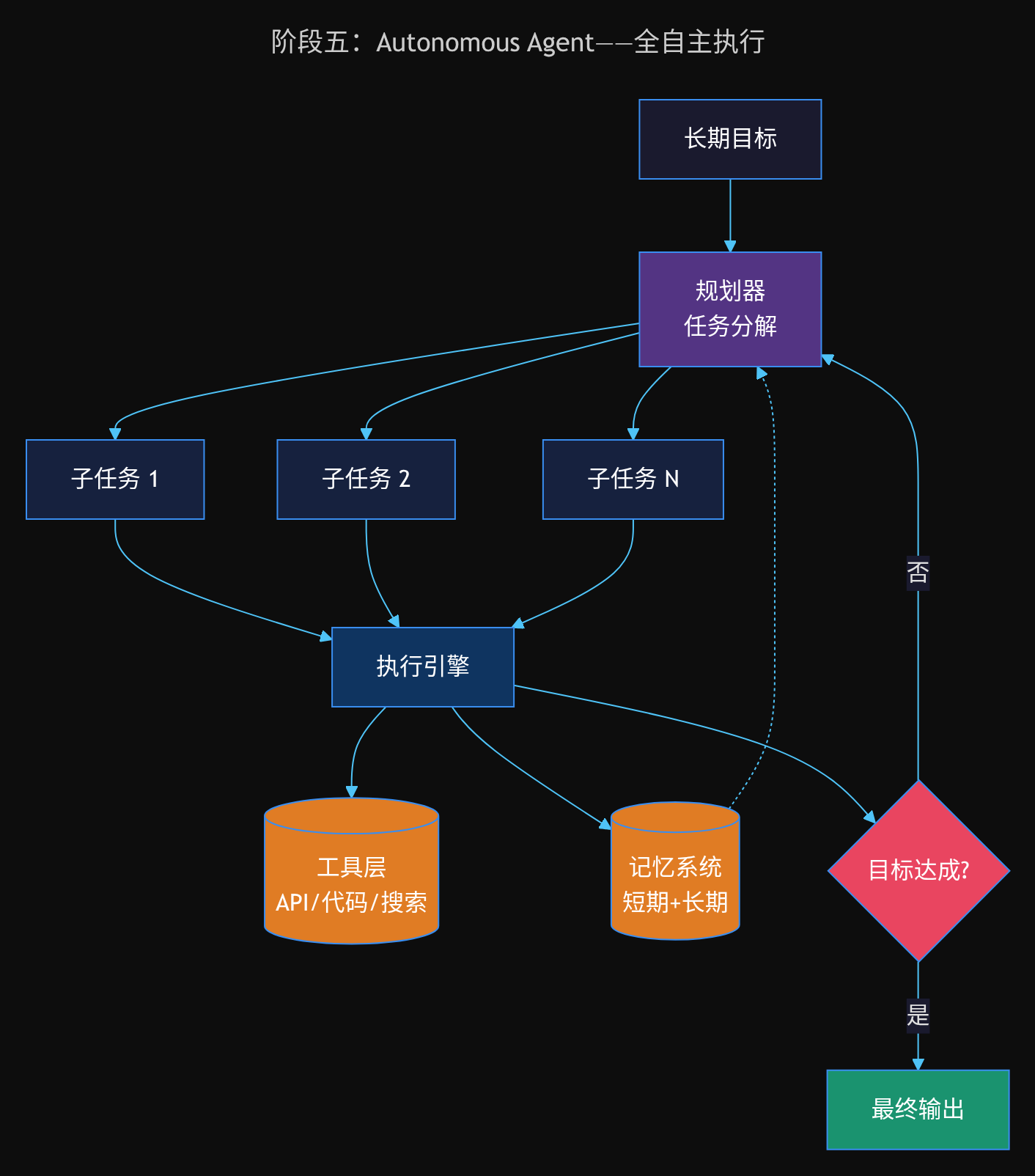
到了这个阶段,LLM 不再是被动响应者,而是主动的任务执行者:
- 接收高层目标(而非具体指令)
- 自主分解任务,制定执行计划
- 调用多种工具,按需调整策略
- 维护长期记忆,从经验中学习
- 具备自我纠错和反思能力
这是 Agent 的完整形态。它不再只是「更强的聊天机器人」,而是一个能够自主工作的数字员工。
纯 LLM 与 Agent 对比
让我们直观感受一下差异:
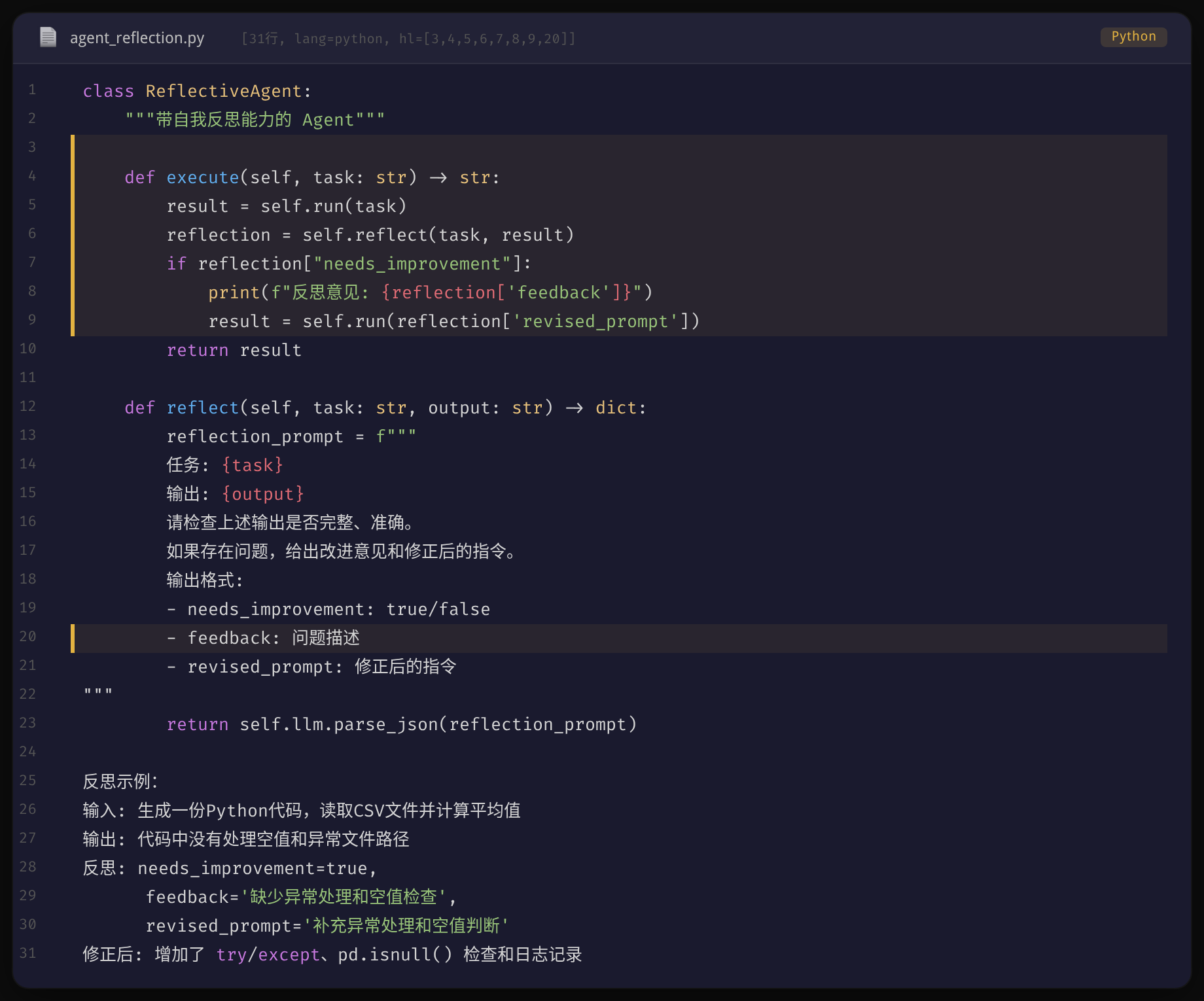
纯 LLM 模式是一次问答即结束,而 Agent 模式内置了感知→推理→行动→观察的循环。同样的任务「查询 2024 年奥运会中国金牌数」,LLM 会因知识截止而无法回答,Agent 则会自主搜索、计算、验证后给出准确结果。
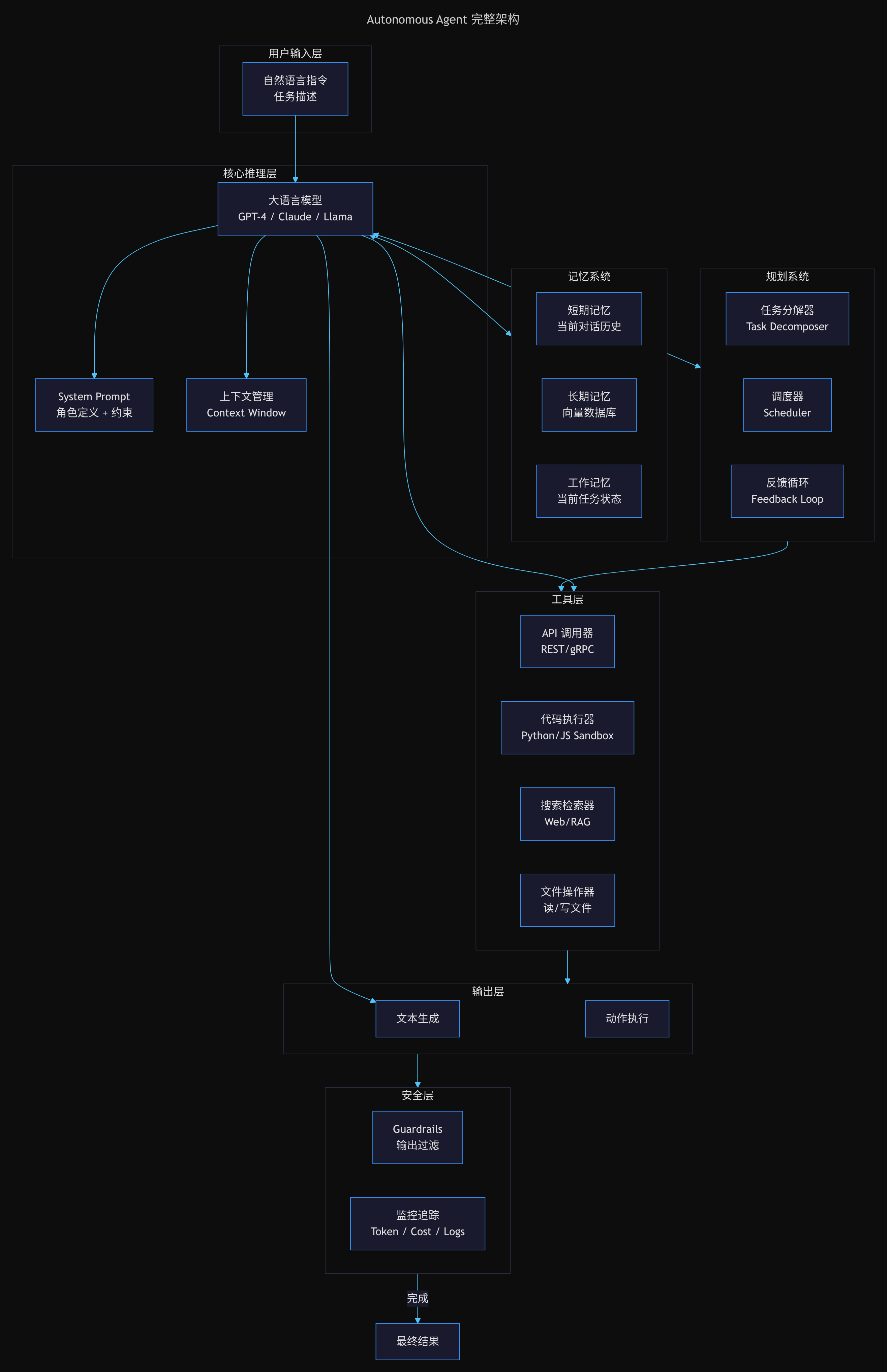
Agent 核心架构拆解
现在我们来深入 Autonomous Agent 的内部结构。
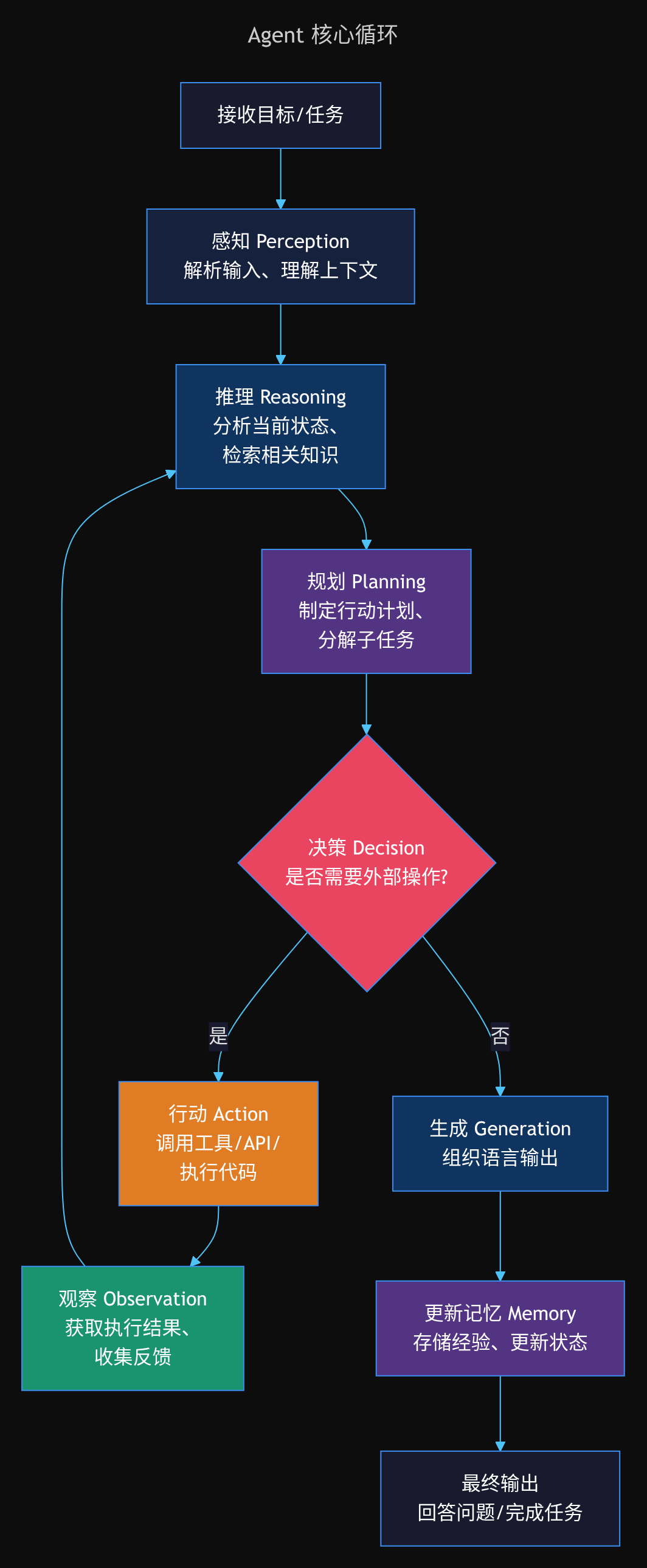
推理引擎(LLM)
Agent 的心脏。LLM 负责理解任务、生成推理链、做出决策。不是所有 LLM 都适合做 Agent 的推理引擎——它需要具备:
- 良好的指令遵循能力
- 支持 Function Calling / Tool Use
- 足够长的上下文窗口
- 可靠的输出格式
目前主流的选择是 GPT-4、Claude 3、以及开源社区训练的 Agent-tuned 模型。
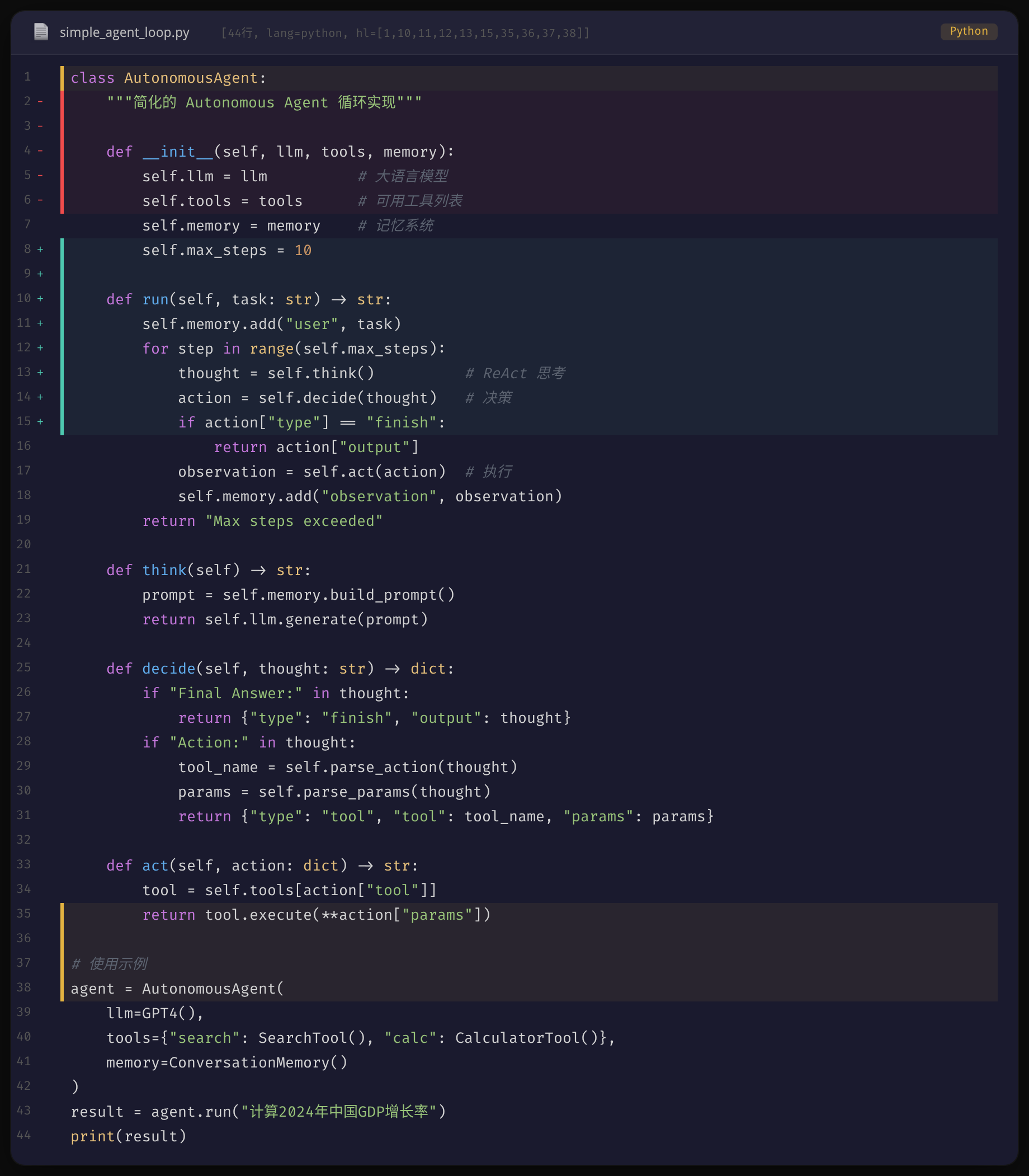
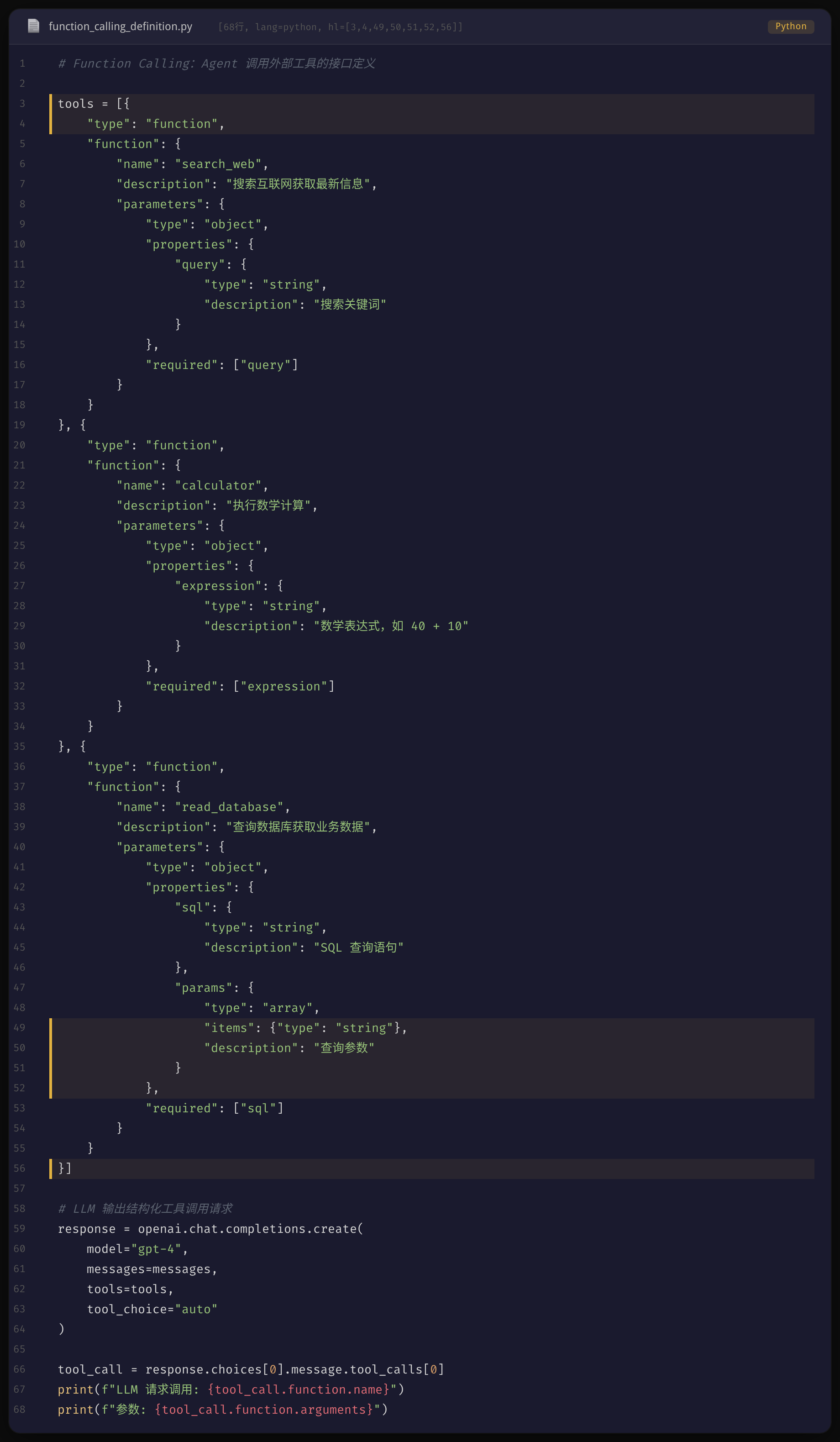
从代码层面看,推理引擎经历了从纯文本补全到 Chat 对话再到 Function Calling 的三次进化。这也是 Agent 获得「决策能力」的关键——LLM 不再只输出文字,而是能输出结构化的工具调用请求。
感知层
Agent 如何理解输入和上下文?这不仅仅是「接收一条消息」这么简单:
- 多模态感知:接收文本、图片、音频等各种输入
- 环境感知:理解当前的工作场景、可用资源、约束条件
- 状态感知:记忆当前所处的步骤、已完成和未完成的任务
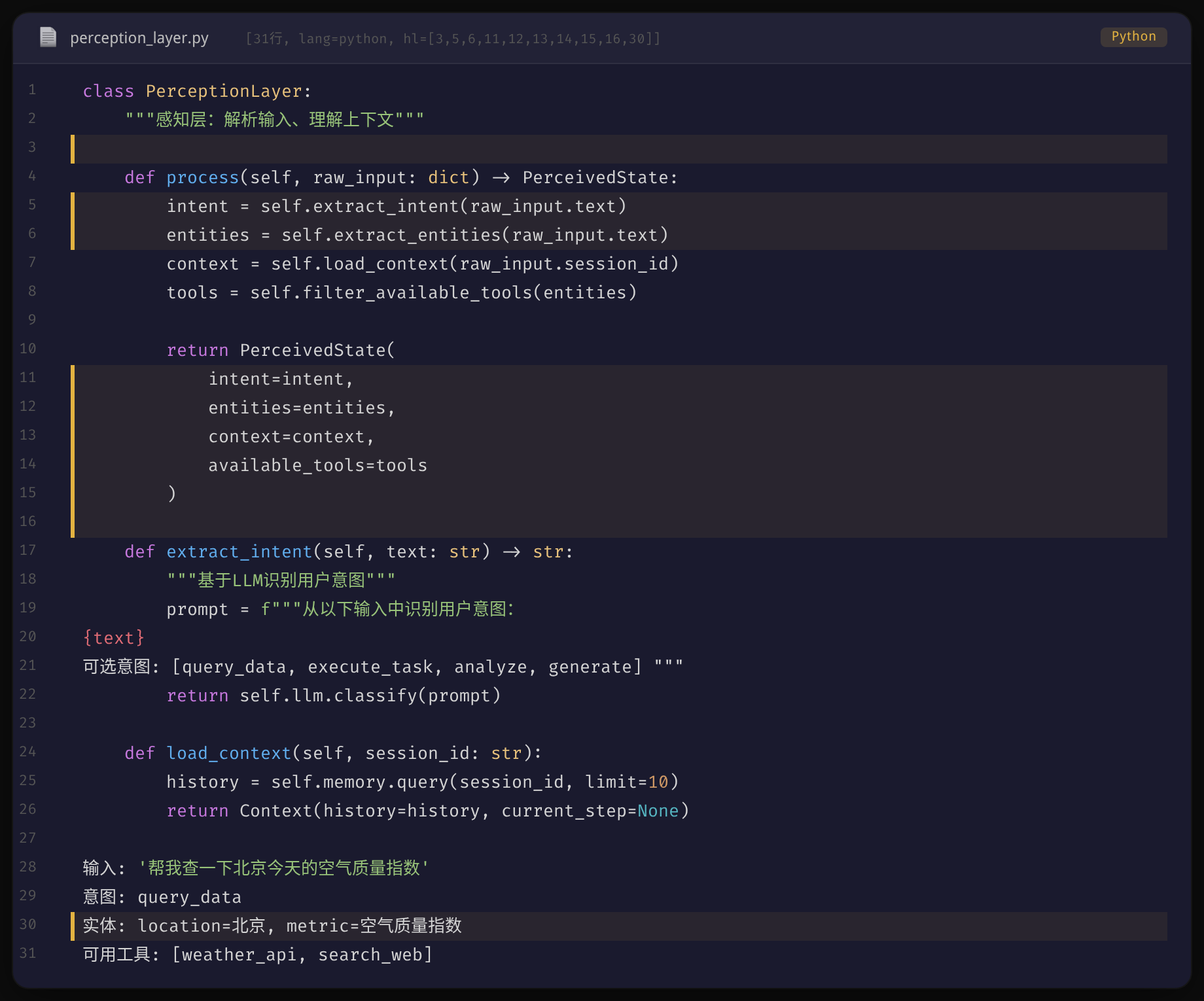
感知层的输出是一个结构化的状态对象,包含意图、实体、上下文和可用工具。后面的推理引擎基于这个结构化输入来做决策。
规划层
这是 Agent 区别于 LLM 的关键能力——将高层目标分解为可执行的步骤:
- 任务分解:将「帮我写一份市场分析报告」拆为 5-8 个具体步骤
- 依赖管理:识别步骤间的先后依赖关系
- 动态调整:当某一步执行失败时,重新规划后续步骤
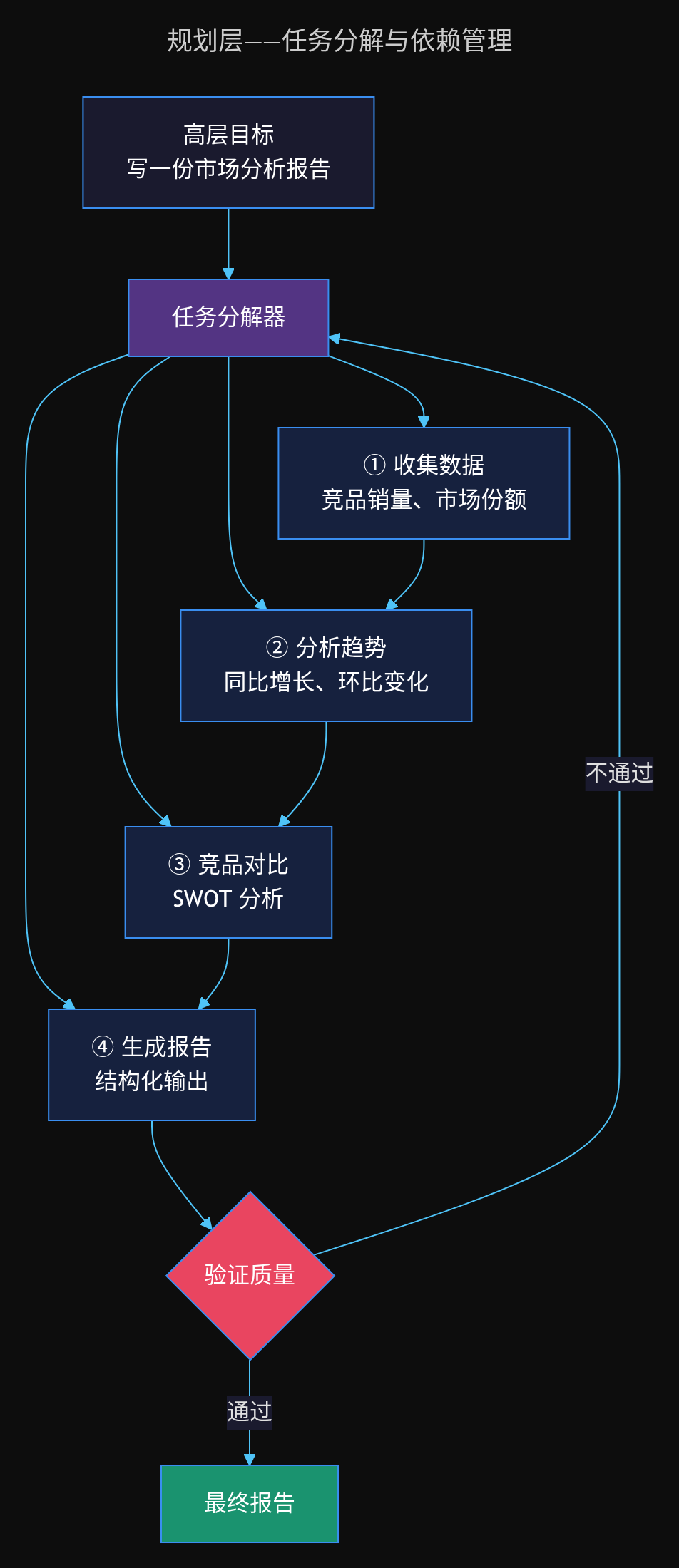
以「写一份市场分析报告」为例,规划器会自动拆解出数据收集、趋势分析、竞品对比、报告生成四个子任务,并识别出其中「数据必须在分析之前完成」的依赖关系。执行过程中如果某一步失败,规划器会动态调整后续步骤。
行动层
Agent 通过工具调用与世界交互。一个 Agent 的「工具箱」通常包含:
- API 调用器:调用 REST API、gRPC 服务
- 代码执行器:在沙箱中运行 Python/JS 代码
- 搜索检索器:Web 搜索或 RAG 知识库查询
- 文件操作器:读写文件、解析文档
- 数据库查询器:执行 SQL 查询
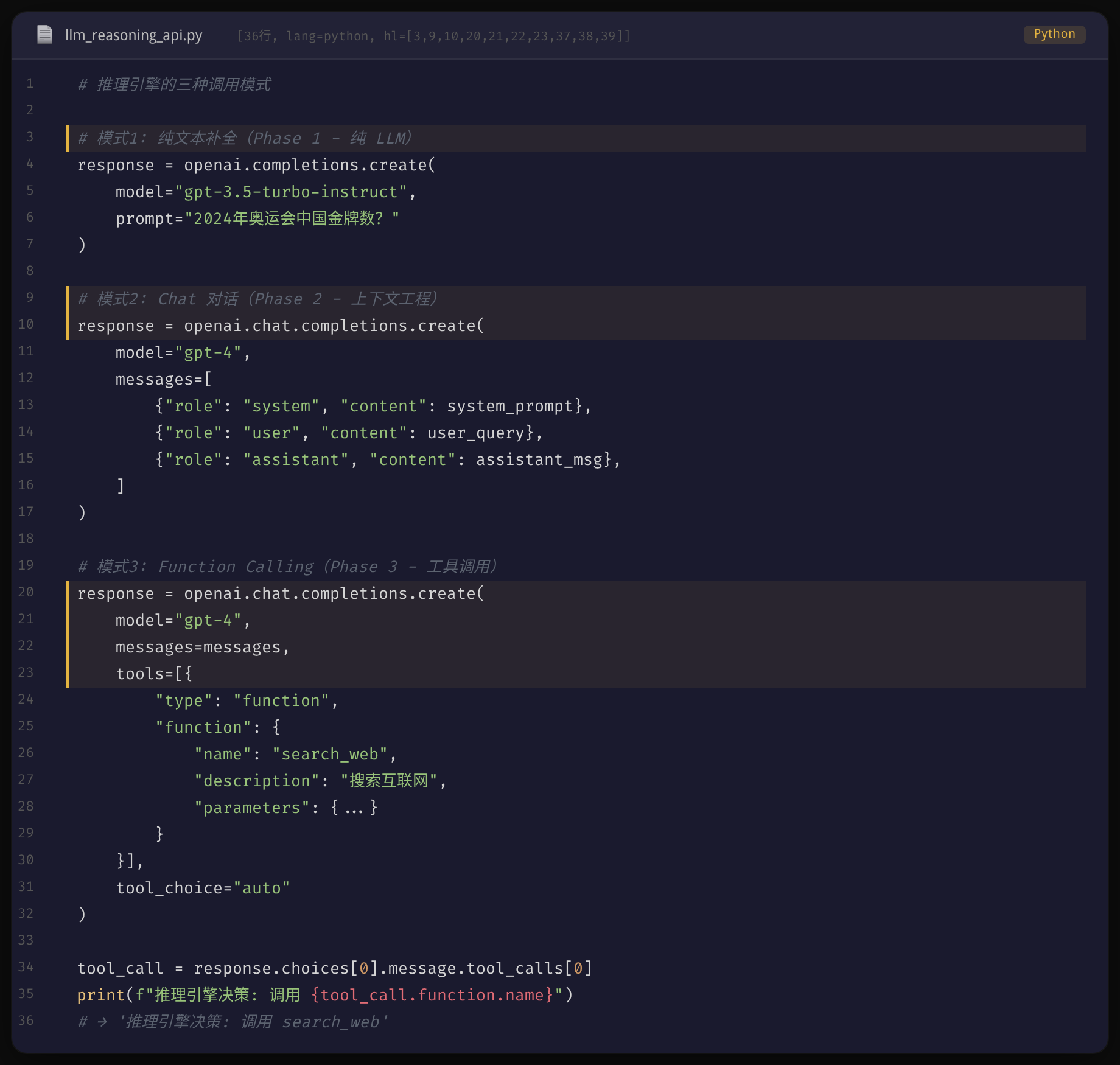
从代码层面看,Agent 的核心就是一个循环:think → decide → act → observe → repeat。
记忆系统
记忆是让 Agent 具备持续性的基础设施:
- 短期记忆:当前对话的完整历史,保持在上下文窗口中
- 工作记忆:当前任务的状态、已采取的步骤、中间结果
- 长期记忆:跨会话的经验积累,通常由向量数据库存储和检索

三层记忆之间是有流动的:短期记忆中的关键信息会在超出上下文窗口时归档到长期记忆;长期记忆中的相关经验会在需要时被检索到工作记忆;任务完成后,工作记忆中的中间结果也会归档。这种分层设计让 Agent 既能处理当前对话,又能积累跨会话的知识。
反馈循环
Agent 不会一次执行就结束。每次行动后,它会:
- 观察执行结果
- 判断是否达到预期
- 如果未达到,分析原因并调整策略
- 如果达到,继续下一步或结束
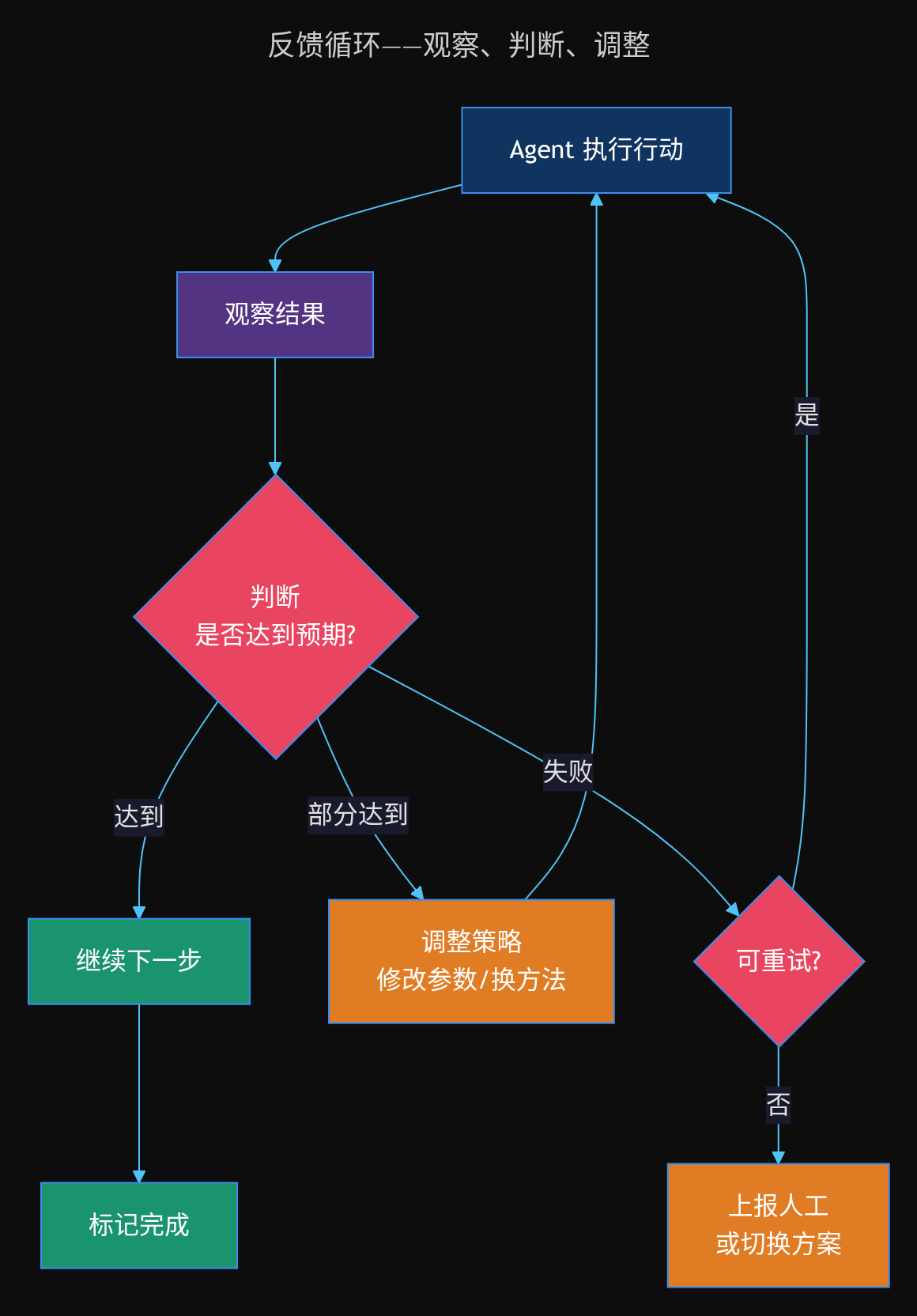
这种反馈机制让 Agent 具备鲁棒性——即使某一步出错,它也能够自我修正。
关键设计模式
ReAct(Reasoning + Acting)
ReAct 是目前最主流的 Agent 模式。它的核心思想是交替进行推理和行动,而不是一次性规划完所有步骤。
ReAct 的每一轮输出包含三个部分:
- Thought:当前状态分析,下一步应该做什么
- Action:具体要执行的操作(调用工具)
- Observation:工具返回的结果
这种「思考→行动→观察」的循环,让 Agent 能够在执行过程中不断调整策略。
Reflection(自我反思)
Reflection 是更高阶的能力——Agent 不仅执行任务,还反思自己的执行过程:
- 结果反思:输出的结果是否合理?有没有更优的方案?
- 过程反思:执行过程中是否有更高效的方法?
- 错误反思:出错的根因是什么?如何避免下次再犯?
Reflection 的本质是在 Agent 的输出基础上再加一层检查——不是让 LLM 直接回答,而是让 LLM 评估自己的回答。这种「元认知」能力让 Agent 能捕获自己的错误,并在最终输出之前完成修正。
Plan-then-Execute
与 ReAct 的「边想边做」不同,Plan-then-Execute 模式要求 Agent 先制定完整计划,再逐步执行。适合那些步骤明确、依赖关系清晰的任务。
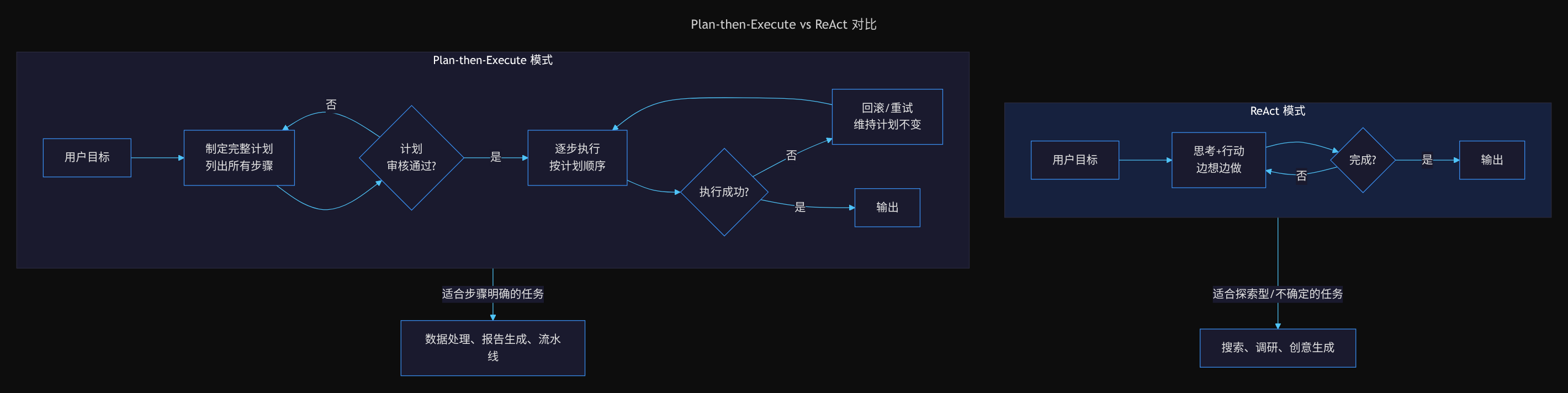
两种模式各有适用场景:ReAct 适合探索型、信息不确定的任务(如搜索、调研),Plan-then-Execute 适合步骤明确、依赖关系清晰的任务(如数据处理、报告生成)。成熟的 Agent 系统通常会根据任务类型动态选择或混合使用这两种模式。
避坑思考
1. LLM 不是万能的推理引擎
不要期待 Agent 永远给出正确的决策。LLM 有幻觉、有偏见、有时会陷入死循环。Agent 架构需要有兜底机制——重试次数限制、人工审核节点、异常处理流程。
2. 工具调用的可靠性与延迟
外部工具可能不可用、响应慢、返回错误数据。Agent 需要处理这些异常情况:超时重试、降级策略、错误上报。
3. Token 消耗的隐性成本
Agent 的推理→行动→观察循环会消耗大量 Token。一个任务可能产生几千甚至几万 Token 的中间输出。在实际部署时,必须做 Token 预算管理。
4. 上下文窗口不是越大越好
虽然现在 LLM 支持 128K+ 的上下文,但实际使用中,历史越久,噪音越多。Agent 需要有选择地保留重要信息,而不是无脑堆积上下文。
5. 安全边界必须明确
Agent 能调用工具意味着它能对系统产生实质影响。必须有严格的权限控制:Agent 能调用什么 API?能操作哪些数据?有没有操作审批流程?
6. 可观测性比功能更重要
Agent 的行为是动态的、不确定的。生产环境中必须有完善的日志和追踪系统,记录每一步的思考过程、工具调用、结果反馈。否则排障将无从下手。
7. Agent 不是替代人,而是增强人
当前 Agent 的能力还远不足以完全替代人类。最有效的使用方式是人类设定目标和边界,Agent 负责具体执行和方案生成,最终决策权留给人。
附:参考资源
- OpenAI Function Calling: https://platform.openai.com/docs/guides/function-calling
- ReAct 论文: Yao et al., "ReAct: Synergizing Reasoning and Acting in Language Models"
- LangChain Agent 文档: https://python.langchain.com/docs/modules/agents/
- AutoGPT: https://github.com/Significant-Gravitas/AutoGPT
- Anthropic Tool Use: https://docs.anthropic.com/en/docs/build-with-claude/tool-use


