
从单机到分布式:一个接口的事务一致性演进
本文是体系化知识专题的第 1 篇 叙事框架:
业务演进 → 技术挑战 → 方案对比 → 选型决策
从一条转账 SQL 说起
假设你刚接手一个转账接口,业务逻辑很简单:
① 扣减 A 账户余额
② 增加 B 账户余额
③ 写入转账流水
这三个步骤必须一起成功或一起失败——不能出现 A 扣了钱但 B 没收到的情况。单机时代,数据库的本地事务天然解决了这个问题:BEGIN → UPDATE → UPDATE → INSERT → COMMIT,要么全部生效,要么全部回滚。
但业务增长后,你拆了库、拆了服务、引了消息队列。同一个接口的三个步骤散落在不同的进程和数据库中。本地事务管不了跨库操作了。
这篇文章就沿着这个场景,看事务一致性方案如何随着架构演进而演进。
一、单机时代:本地事务的 ACID
单库单应用的架构下,事务是最"无感"的能力。你只需要写 BEGIN / COMMIT,数据库底层用一套成熟的机制保证 ACID。
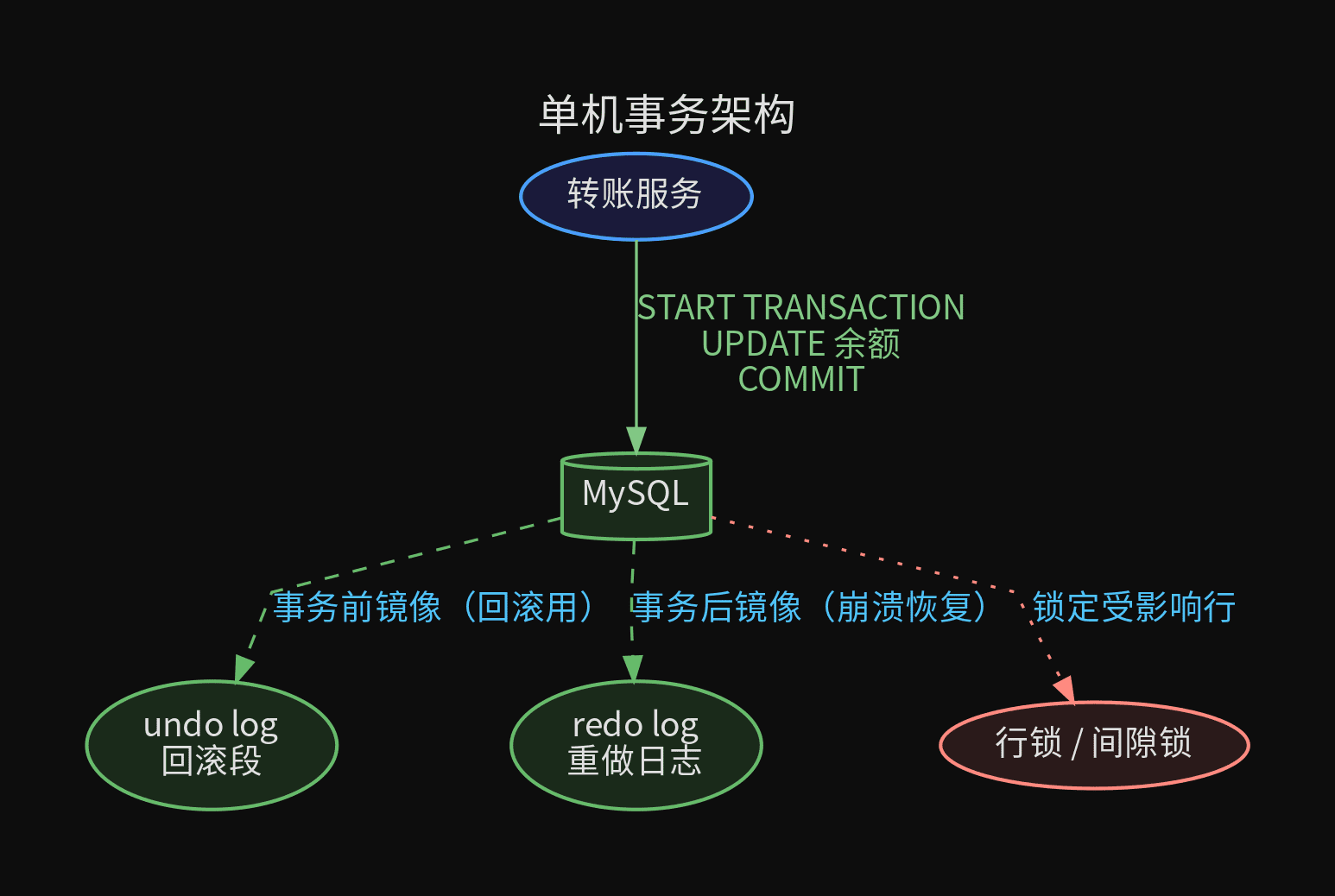
原子性(Atomicity)—— undo log
原子性的核心问题是:如何保证部分执行的事务在崩溃时能回滚。
MySQL InnoDB 用 undo log 解决。事务修改数据前,先将旧值写入 rollback segment:
UPDATE account SET balance = 100 WHERE id = 1;
↓
undo log: balance 原来是 200
事务回滚时,InnoDB 从 undo log 读取旧值写回去。崩溃恢复时,所有未 commit 的事务通过 undo log 回滚到起点。
undo log 的另一个身份是 MVCC 的快照基础——长事务读取 undo log 构建历史版本。这就是为什么长事务会导致 undo log 膨胀,最终引发 undo log 占用过大 的问题。
持久性(Durability)—— redo log
持久性的核心问题是:事务提交后、数据刷盘前,数据库宕机了怎么办。
InnoDB 用 WAL(Write-Ahead Logging)机制:每次事务提交时,只保证 redo log 刷入磁盘,不要求数据页也刷入。崩溃恢复时,扫描 redo log 重放尚未写入数据页的修改。
事务提交流程:
BEGIN → 修改数据(在 buffer pool)→ 写 redo log(刷盘)→ COMMIT
↓
redo log 刷盘成功
= 事务已持久化
数据页在后台异步刷盘,不影响事务的提交延迟。所以 COMMIT 的耗时 ≈ redo log 刷盘耗时,和修改的数据量无关——只和 fsync 延迟有关。
隔离性(Isolation)—— 锁 + MVCC
多个事务同时操作同一行时,通过行锁解决写冲突。写-写互斥,读-写不阻塞:
事务 A:UPDATE account SET balance = balance - 100
事务 B:SELECT balance FROM account
事务 A 未提交 → MVCC 提供快照读,返回旧值
MVCC 通过三个隐式字段实现:DB_TRX_ID(最后修改的事务 ID)、DB_ROLL_PTR(指向 undo log)、DB_ROW_ID。每个事务启动时拿到一个 view,查询只认 view 范围内已提交的版本。
这个阶段的局限
一个本地事务只能操作一个数据库。所有的表必须在同一个实例上。一旦你的业务拆分到多个数据库实例,本地事务就管不住了。
二、拆库之后:分布式事务的困境
业务增长,单库扛不住了。最常见的拆分路径:
- 读写分离——主库写、从库读,事务必须路由到主库
- 垂直拆分——将余额库和流水库拆分到不同实例
- 微服务拆分——账户服务和账务服务独立部署
问题来了:转账接口跨了多个数据库实例。
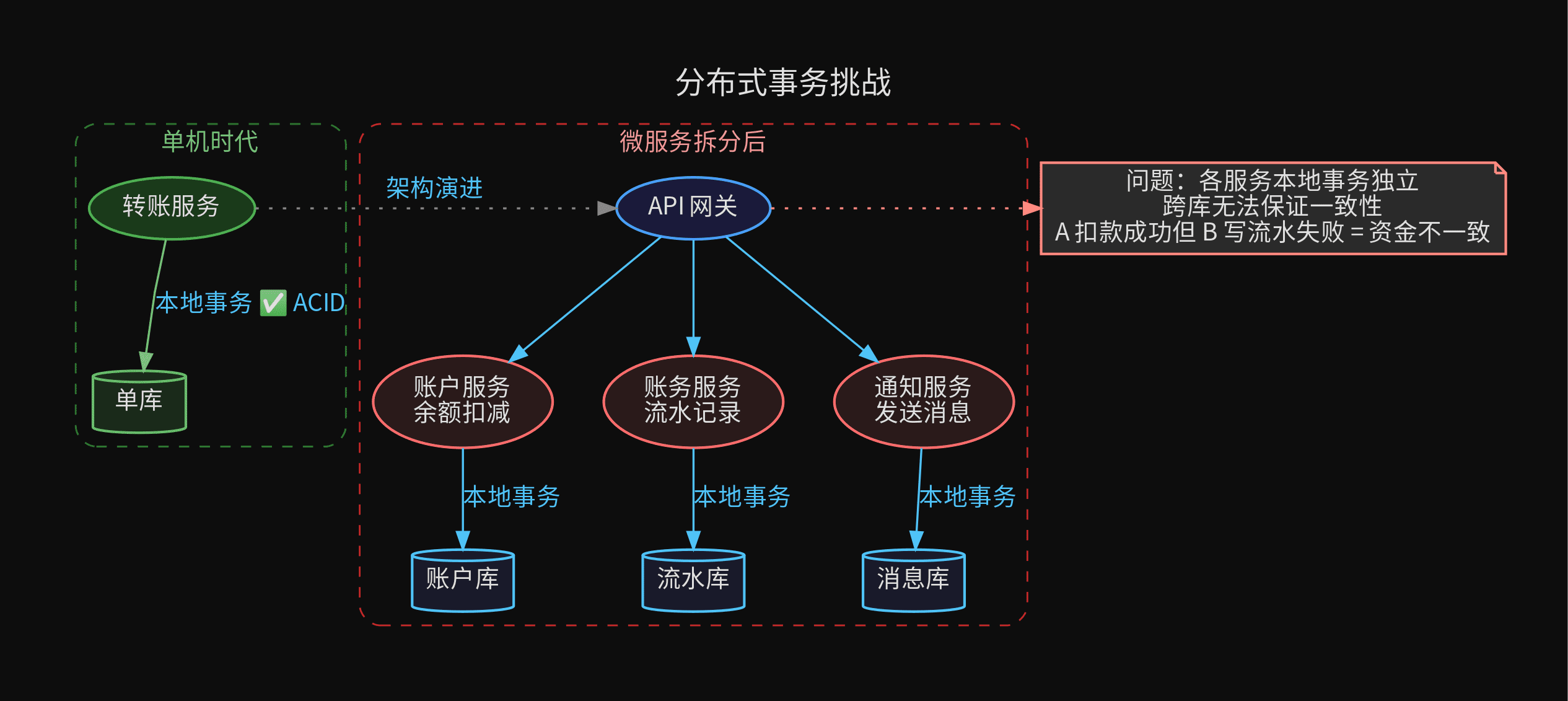
跨库事务为什么难
| 场景 | 问题 |
|---|---|
| 账户服务本地事务提交 | 余额已扣减 |
| 账务服务本地事务提交 | 流水已写入 |
| 通知服务时间点失败 | 网络超时,无法回滚前两个服务的提交 |
三个本地事务各自成功不等于全局成功。提交后无法回滚,这就是分布式事务的核心难题。
来自 CAP 的理论限制
分布式系统无法同时满足一致性(C)、可用性(A)和分区容忍性(P)。分布式事务的核心矛盾在于:
- 要实现强一致性,就必须在提交前让所有参与者达成共识——这需要锁和同步通信
- 要保证可用性,就必须容忍部分节点暂时不一致——走向最终一致性
不同的分布式事务方案,本质是在 CAP 中的不同取舍。
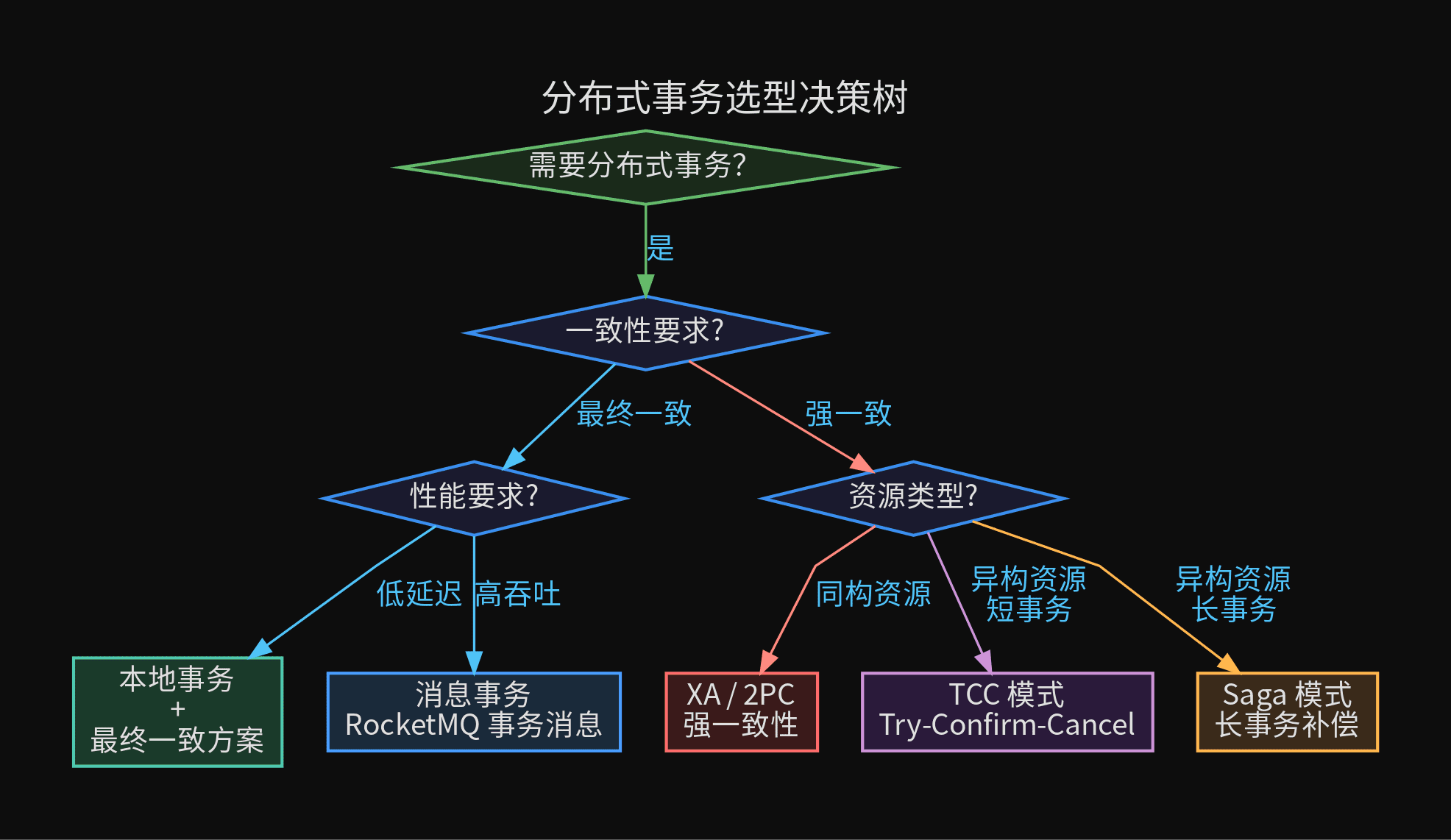
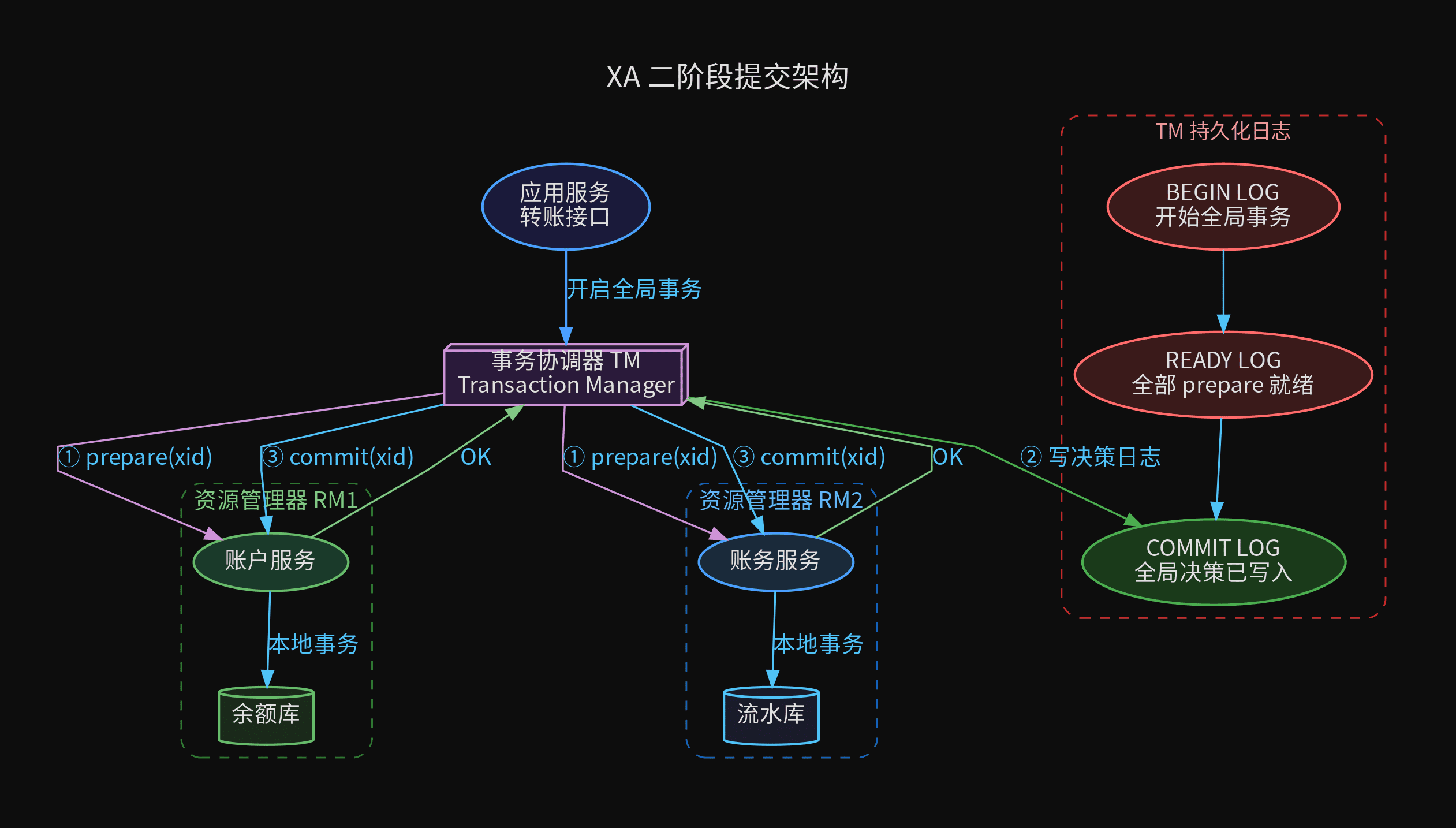
三、XA / 2PC:二阶段提交
XA(eXtended Architecture)是 X/Open 组织定义的分布式事务规范。MySQL、Oracle 等主流数据库都实现了 XA 接口。
核心思想:引入一个事务协调器(TM)来协调多个资源管理器(RM)。所有参与者执行 prepare,全部通过后才 commit。
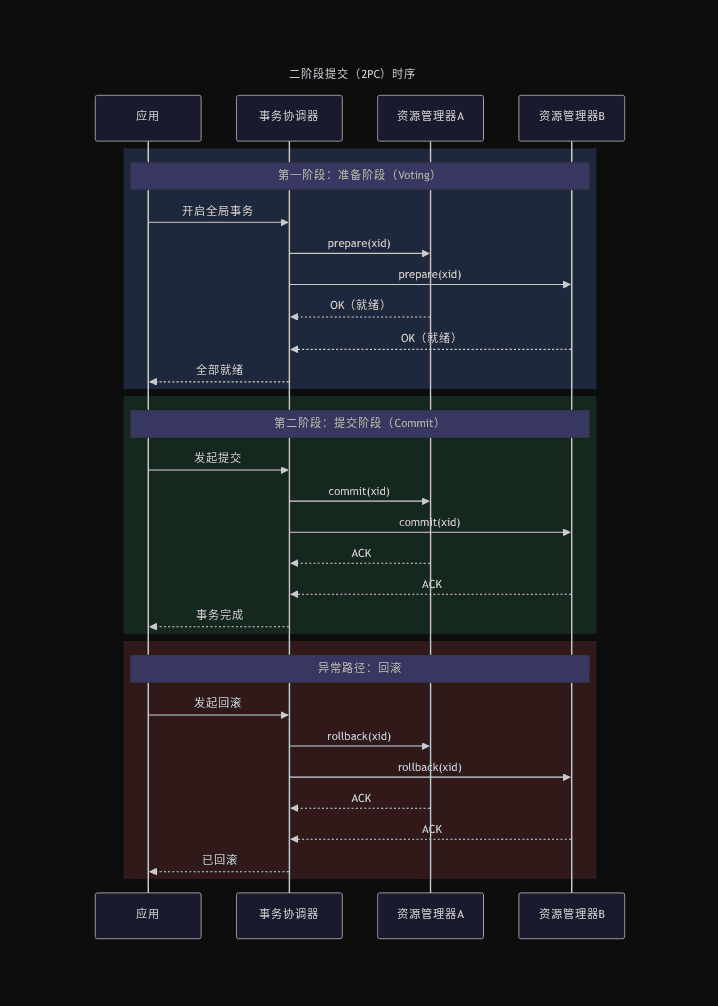
第一阶段:准备(Voting Phase)
事务协调器向所有参与者发送 prepare 请求。参与者执行但不提交:
-- 账户服务收到 prepare
XA PREPARE 'xid';
-- 数据库写入 undo/redo log,加行锁
-- 返回 OK
关键点:参与者回复 OK 后,就不能自行回滚了——它承诺等待 TM 的最终决策。
如果任何一个参与者返回 NO 或超时,TM 向所有已 prepare 的参与者发送 rollback。
第二阶段:提交(Commit Phase)
所有参与者都返回 OK 后,TM 做出全局提交决策并写入事务日志:
-- TM 写入 commit 日志(先持久化)
-- 然后广播 commit 到所有参与者
XA COMMIT 'xid';
这个决策是不可逆的——一旦 TM 决定提交,即使部分 commit 失败,也必须坚持重试或人工介入。
2PC 的核心问题
| 问题 | 说明 |
|---|---|
| 同步阻塞 | prepare 阶段持有行锁,直到全局事务结束。prepare → commit 的窗口越长,锁竞争越激烈 |
| 单点故障 | TM 宕机 → 所有参与者阻塞等待决策。需要额外的 HA 方案 |
| 不一致窗口 | Phase 2 中网络分区 → 部分参与者已 commit,部分未收到 |
| 性能差 | 2 轮 RTT + 3 次日志刷盘,RT 远高于本地事务 |
生产中的实际表现:
有一类线上故障就是 XA 事务引起的:一个跨库转账链中,DB-A prepare 很快但 DB-B 行锁等待,锁等待时间拖长了全局事务。DB-A 的行锁也一直被持有,逐渐引发连接池耗尽。
什么场景还值得用 XA
- 短事务(prepare → commit 在 200ms 内)
- 强一致要求(资金类核心链路)
- 同构数据库(全是 MySQL)
- 低并发(TPS < 1000)
在这些约束下,XA 虽然慢但正确性可靠——它保证了 ACID,没有补偿逻辑。
四、TCC:业务补偿的艺术
TCC(Try-Confirm-Cancel)是阿里提出的分布式事务方案,不依赖数据库锁,通过业务层的预留和确认保证一致性。
它将一个分布式事务拆成三个阶段,每个服务都要实现三组接口。
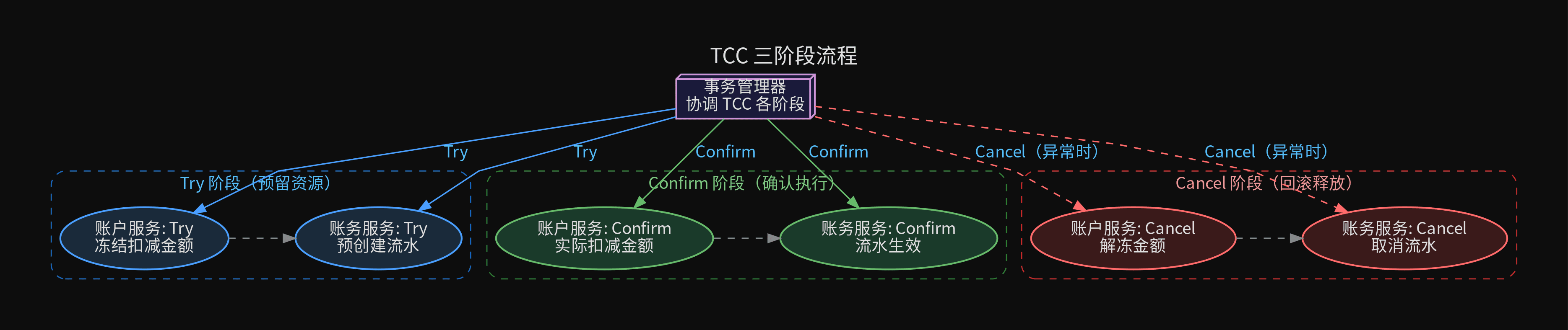
Try 阶段——资源预留
不是直接扣款,而是"冻结"。以转账为例:
// 账户服务——Try:冻结余额
public boolean tryFreeze(String accountId, long amount, String txId) {
Account account = accountMapper.selectForUpdate(accountId);
if (account.getBalance() - account.getFrozen() >= amount) {
account.setFrozen(account.getFrozen() + amount);
accountMapper.update(account);
// 记录事务日志,用于幂等和防悬挂
txLogMapper.insert(txId, "FREEZED");
return true;
}
return false; // 余额不足
}
注意这里没有减少余额,而是在冻结字段中标记。冻结的金额不能使用,但仍在余额中。
Confirm 阶段——实际执行
// 账户服务——Confirm:确认扣减
public boolean confirmDeduct(String accountId, long amount, String txId) {
// 幂等检查:已 confirm 则跳过
TxLog log = txLogMapper.select(txId);
if (log.getStatus() == "CONFIRMED") return true;
Account account = accountMapper.selectForUpdate(accountId);
account.setBalance(account.getBalance() - amount);
account.setFrozen(account.getFrozen() - amount);
accountMapper.update(account);
txLogMapper.updateStatus(txId, "CONFIRMED");
return true;
}
Confirm 方案设计上保证不会失败——因为 Try 阶段已经校验余额了。
Cancel 阶段——回滚释放
// 账户服务——Cancel:解冻
public boolean cancelFreeze(String accountId, long amount, String txId) {
// 空回滚处理:Try 未执行但 Cancel 来了
TxLog log = txLogMapper.select(txId);
if (log == null) {
txLogMapper.insert(txId, "CANCELED"); // 记录已取消,避免后续 Try 产生防悬挂
return true;
}
Account account = accountMapper.selectForUpdate(accountId);
account.setFrozen(account.getFrozen() - amount);
accountMapper.update(account);
txLogMapper.updateStatus(txId, "CANCELED");
return true;
}
三个必须处理的反向逻辑
空回滚:Try 未执行但 Cancel 到了。原因是异步网络下,TM 判定超时发送 Cancel 时,Try 请求还在路上。Cancel 中看到无事务记录→插入已取消标记→后续 Try 到达时检查到已取消→响应成功但不执行。
防悬挂:Cancel 先于 Try 到达。原因同上,但时序相反。Cancel 执行完毕、Try 才到。如果 Try 不检查事务状态,就会把冻结记录写入,但永远不会有 Confirm 或 Cancel 来清理它。解决:Try 前检查是否有 Cancel 记录,有则直接返回。
幂等控制:Confirm 和 Cancel 可能被重复调用(TM 超时重试)。用事务 ID 去重——每个接口都支持传入 txId,先检查状态再执行。
TCC 框架选型
| 框架 | 特点 |
|---|---|
| Seata | 阿里开源,支持 TCC + AT + Saga,社区活跃 |
| TCC-Transaction | 轻量级,适合快速集成 |
| Hmily | 高性能,支持异步 TCC |
Seata 是目前最流行的选择,提供了完善的空回滚、防悬挂和幂等功能。
五、方案选型:什么时候用什么
你不需要在项目初期就上 TCC。选型要看一致性要求、性能要求、资源类型和时间成本。
1. 本地事务 + 定时补偿
适用场景:低并发、能接受秒级延迟、业务可接受短暂不一致。
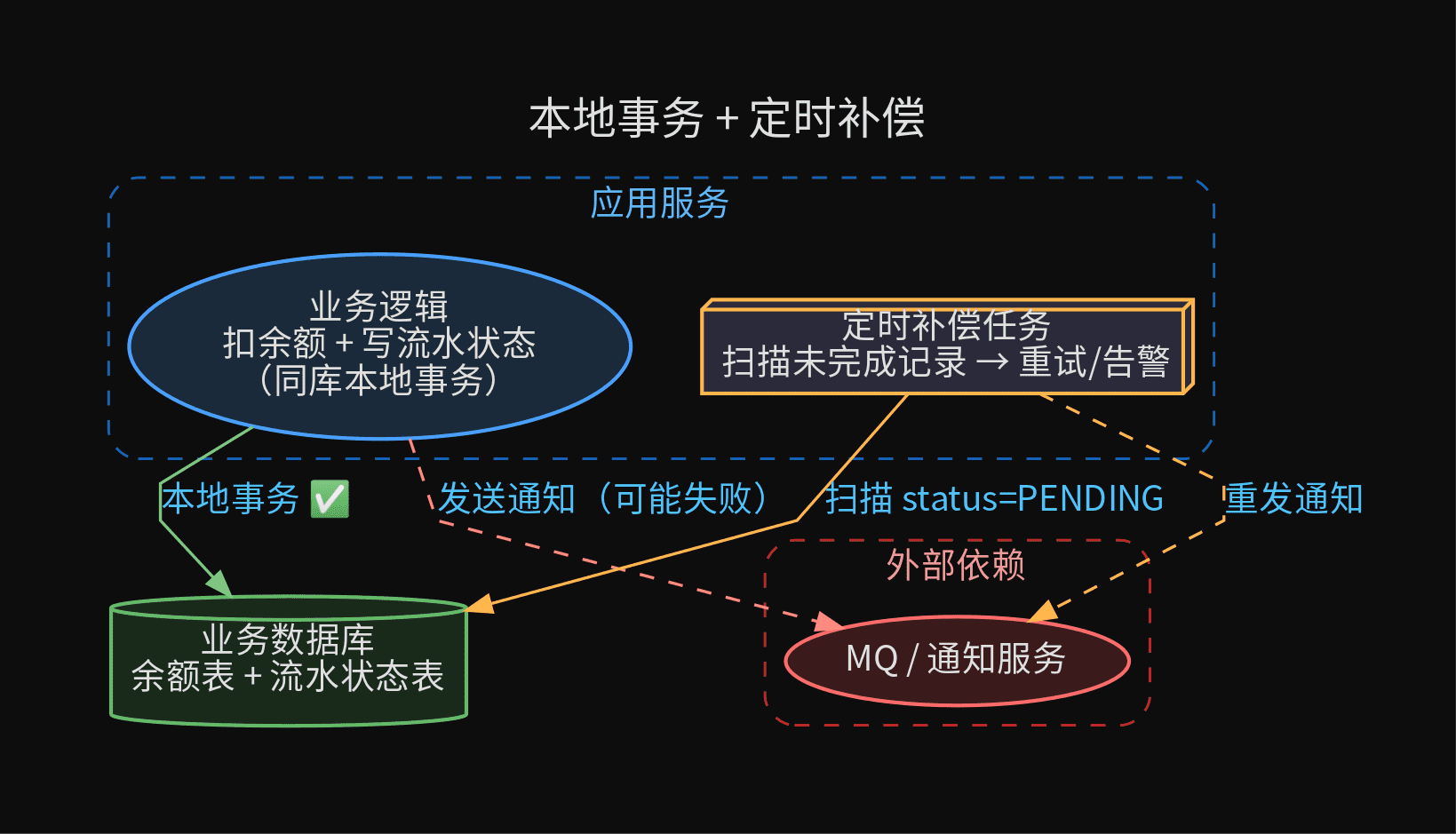
这是最简单的分布式事务方案,不需要引入任何框架。
核心设计:
业务操作(本地事务):
UPDATE 余额 SET 余额 = 余额 - 100
INSERT 流水表(状态 = PENDING)
异步通知 → 如果失败,流水表状态仍是 PENDING
定时补偿任务(每 1 分钟扫描):
SELECT * FROM 流水表 WHERE 状态 = 'PENDING'
→ 重试通知服务
→ 超过 N 次失败 → 人工告警
关键点在于业务操作和状态记录在同一个本地事务中。只要本地事务提交了,流水表的 PENDING 记录就一定存在。补偿任务只需要扫描 PENDING 状态的记录进行重试即可。
实现细节:
- 状态字段至少要包含:
status(PENDING/SUCCESS/FAILED)、retry_count、last_retry_at - 补偿任务需要幂等:重试前检查目标状态是否已变更
- 补偿任务需要退避策略:指数退避(1min → 2min → 4min → 8min → 告警)
- 补偿任务要保证只执行一次语义:用
UPDATE ... WHERE status = 'PENDING' AND retry_count = N做乐观锁
优缺点:
| 优点 | 缺点 |
|---|---|
| 零额外依赖,不需中间件 | 补偿逻辑散落在业务代码中 |
| 实现简单,开发成本低 | 数据一致窗口 = 扫描间隔(通常秒级) |
| 易于排查和对账 | 业务侵入性强(每张表都要加状态字段) |
RocketMQ 事务消息解决了补偿逻辑散落的问题,提供了更可靠的消息投递保证。
2. 消息事务(RocketMQ 事务消息)
适用场景:高吞吐、需要可靠异步通知、希望框架化管理补偿逻辑。
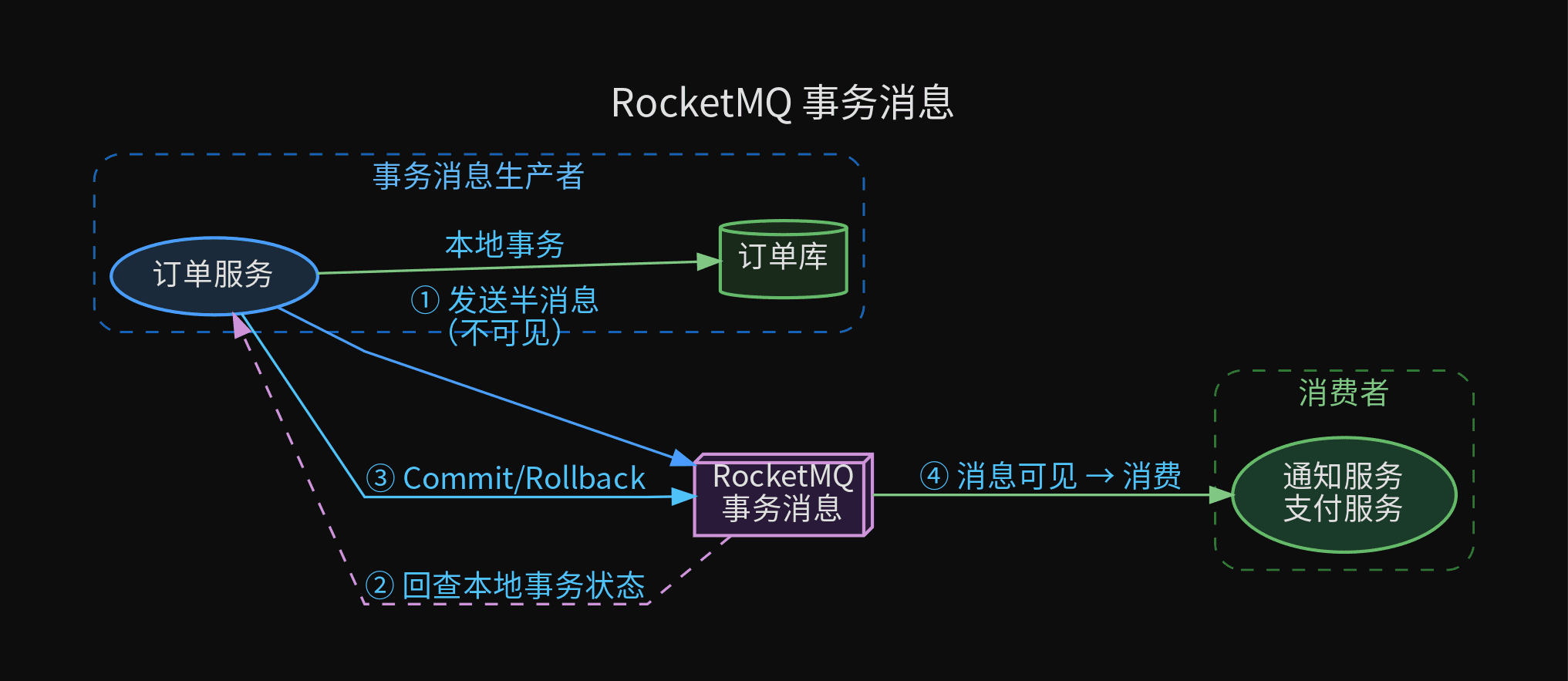
RocketMQ 事务消息的核心是半消息机制,解决"发消息"和"本地事务"的原子性问题。
流程详解:
① 生产者发送半消息(Half Message)→ 消息到达 Broker,标记为不可见
② 生产者执行本地事务(扣余额、写流水)
③ 根据本地事务结果:
- COMMIT → Broker 将消息标记为可见,消费者可以消费
- ROLLBACK → Broker 删除半消息,消费者永远不会看到
④ 如果步骤 ② 超时(生产者宕机),Broker 回调生产者的回查接口:
- 回查本地事务状态 → 返回 COMMIT / ROLLBACK / UNKNOWN
回查接口实现:
// RocketMQ 事务回查监听器
public class OrderTxListener implements TransactionListener {
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
// 步骤 ②:执行本地事务
String orderId = msg.getKeys();
return orderService.createOrder(orderId);
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
// 步骤 ④:Broker 回查事务状态
String orderId = msg.getKeys();
Order order = orderMapper.selectById(orderId);
if (order == null) return LocalTransactionState.UNKNOW;
return order.getStatus() == 1
? LocalTransactionState.COMMIT_MESSAGE
: LocalTransactionState.ROLLBACK_MESSAGE;
}
}
关键点:
- 回查接口必须幂等——可能被多次调用
- 回查接口要快——Broker 有超时阈值,超时视为 UNKNOWN
- 半消息机制只保证"发送"原子性,不保证"消费"原子性——消费失败需要消费者自行重试
与纯定时补偿的对比:
| 维度 | 定时补偿 | 消息事务 |
|---|---|---|
| 一致性窗口 | 秒级(扫描间隔) | 毫秒级(消息即到) |
| 开发量 | 维护状态表和定时任务 | 实现回查接口 |
| 运维成本 | 扫描任务监控 | RocketMQ 集群运维 |
| 适用场景 | 内部系统,允许短暂延迟 | 核心链路,要求低延迟 |
3. XA / 2PC
适用场景:短事务、强一致、同构资源、低并发(TPS < 1000)。
XA 是标准化的分布式事务协议,MySQL、Oracle、SQL Server 都原生支持。开发者只需要按 XA 规范调用接口,不需要写补偿逻辑。
XA 接口调用示例:
-- MySQL XA 事务完整流程
XA START 'xid1'; -- 第一阶段开始
UPDATE account SET balance = balance - 100 WHERE id = 1;
XA END 'xid1';
XA PREPARE 'xid1'; -- 准备:写 undo/redo log,持有行锁
XA START 'xid2';
INSERT INTO transfer_log VALUES (..., 'PENDING');
XA END 'xid2';
XA PREPARE 'xid2';
-- 如果两个都 prepare 成功
XA COMMIT 'xid1'; -- 第二阶段:提交
XA COMMIT 'xid2';
-- 如果任一 prepare 失败
XA ROLLBACK 'xid1'; -- 第二阶段:回滚
XA ROLLBACK 'xid2';
TM 的持久化日志是核心:
TM 在做出全局决策(commit/rollback)前,必须先写日志。如果 TM 在发送 commit 的过程中宕机,重启后扫描日志恢复未完成的全局事务:
事务日志条目:
[GLOBAL BEGIN] xid=tx001, rm=[rm1, rm2], time=T1
[PREPARE OK] xid=tx001, rm=rm1, time=T2
[PREPARE OK] xid=tx001, rm=rm2, time=T3
[COMMIT DECIDE] xid=tx001, time=T4 ← 先写日志再发送
[COMMIT OK] xid=tx001, rm=rm1, time=T5
[COMMIT OK] xid=tx001, rm=rm2, time=T6
崩溃恢复时,如果日志停留在 [COMMIT DECIDE] 但未收到所有 [COMMIT OK],TM 必须重试 commit 直到全部确认。这就是 XA 的"至少一次"语义——commit 可能重复执行,参与者需要幂等。
Spring 集成示例:
// 使用 Atomikos 作为 TM
@Bean(initMethod = "init", destroyMethod = "close")
public UserTransactionManager atomikosTransactionManager() {
UserTransactionManager tm = new UserTransactionManager();
tm.setForceShutdown(true);
return tm;
}
// 分布式事务调用
@Transactional
public void transfer(TransferReq req) {
accountDao.deduct(req.getFrom(), req.getAmount()); // DB1
accountDao.add(req.getTo(), req.getAmount()); // DB2
txLogDao.insert(req); // DB3
// 三个数据源在一个 @Transactional 下,底层用 XA 协调
}
XA 不适合什么场景:
- 长事务:prepare 持有锁的时间 = 整个事务耗时,长事务导致大面积锁等待
- 高并发:每轮 2 RTT + 3 次 fsync,TPS 受限于日志刷盘性能
- 异构资源:XA 规范要求资源管理器实现 XA 接口,Redis/MQ 不支持原生 XA
4. TCC
适用场景:异构资源、高并发、业务可接受三阶段设计、短事务。

TCC 是阿里提出的业务级分布式事务方案。每个服务实现三组接口,由 TCC 框架协调调用。与 XA 最大的区别:不依赖数据库锁,而是通过业务逻辑预留资源。
Seata TCC 实现示例:
// 定义 TCC 接口
@LocalTCC
public interface AccountTccService {
@TwoPhaseBusinessAction(
name = "deduct",
commitMethod = "confirm",
rollbackMethod = "cancel"
)
boolean tryDeduct(@BusinessActionContextParameter(paramName = "accountId") String accountId,
@BusinessActionContextParameter(paramName = "amount") long amount);
boolean confirm(BusinessActionContext ctx);
boolean cancel(BusinessActionContext ctx);
}
// Try:预留资源
@Override
public boolean tryDeduct(String accountId, long amount) {
// 冻结金额,不实际扣减
int rows = accountDAO.freezeBalance(accountId, amount);
return rows > 0;
}
// Confirm:实际执行
@Override
public boolean confirm(BusinessActionContext ctx) {
String accountId = (String) ctx.getActionContext("accountId");
long amount = (long) ctx.getActionContext("amount");
// 从冻结转为实际扣减
int rows = accountDAO.confirmDeduct(accountId, amount);
return rows > 0;
}
// Cancel:释放预留
@Override
public boolean cancel(BusinessActionContext ctx) {
String accountId = (String) ctx.getActionContext("accountId");
long amount = (long) ctx.getActionContext("amount");
// 解冻金额
int rows = accountDAO.cancelFreeze(accountId, amount);
return rows > 0;
}
三种异常场景的处理:
① 空回滚(Hanging Rollback)
Try 请求超时,TM 认为失败并发起 Cancel。但 Try 请求最终到达了服务端。此时 Cancel 中发现无 Try 记录——这就是空回滚。
// Cancel 中处理空回滚
public boolean cancel(BusinessActionContext ctx) {
TxLog log = txLogMapper.select(ctx.getXid());
if (log == null) {
// 空回滚:记录 Cancel 标记,防止后续 Try 执行
txLogMapper.insert(ctx.getXid(), "CANCELED");
return true;
}
// 正常回滚逻辑
}
② 防悬挂(Suspension)
空回滚的镜像问题。Cancel 先执行完(记录 CANCELED),Try 后到达。如果 Try 不检查状态直接执行,就会产生一条"悬挂"的预留记录——永远不会有 Confirm 或 Cancel 来清理它。
// Try 中处理防悬挂
public boolean tryFreeze(String accountId, long amount, String txId) {
TxLog log = txLogMapper.select(txId);
if (log != null && "CANCELED".equals(log.getStatus())) {
return true; // 已取消,不做任何事情
}
// 正常 try 逻辑
}
③ 幂等控制
Confirm 和 Cancel 可能被重复调用(TM 超时重试、网络重传):
public boolean confirm(BusinessActionContext ctx) {
TxLog log = txLogMapper.select(ctx.getXid());
if (log == null || "CONFIRMED".equals(log.getStatus())) {
return true; // 已执行过,幂等返回成功
}
// 正常 confirm 逻辑,然后更新状态
txLogMapper.updateStatus(ctx.getXid(), "CONFIRMED");
}
TCC 框架对比:
| 特性 | Seata | TCC-Transaction | Hmily |
|---|---|---|---|
| 空回滚/防悬挂 | ✅ 内置 | ⚠️ 需自行实现 | ✅ 内置 |
| 幂等控制 | ✅ 通过事务日志 | ❌ | ✅ |
| 性能 | 中等 | 高(无代理) | 高 |
| 社区活跃度 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
5. Saga
适用场景:长事务(分钟级)、异步补偿可接受、业务流程明确。
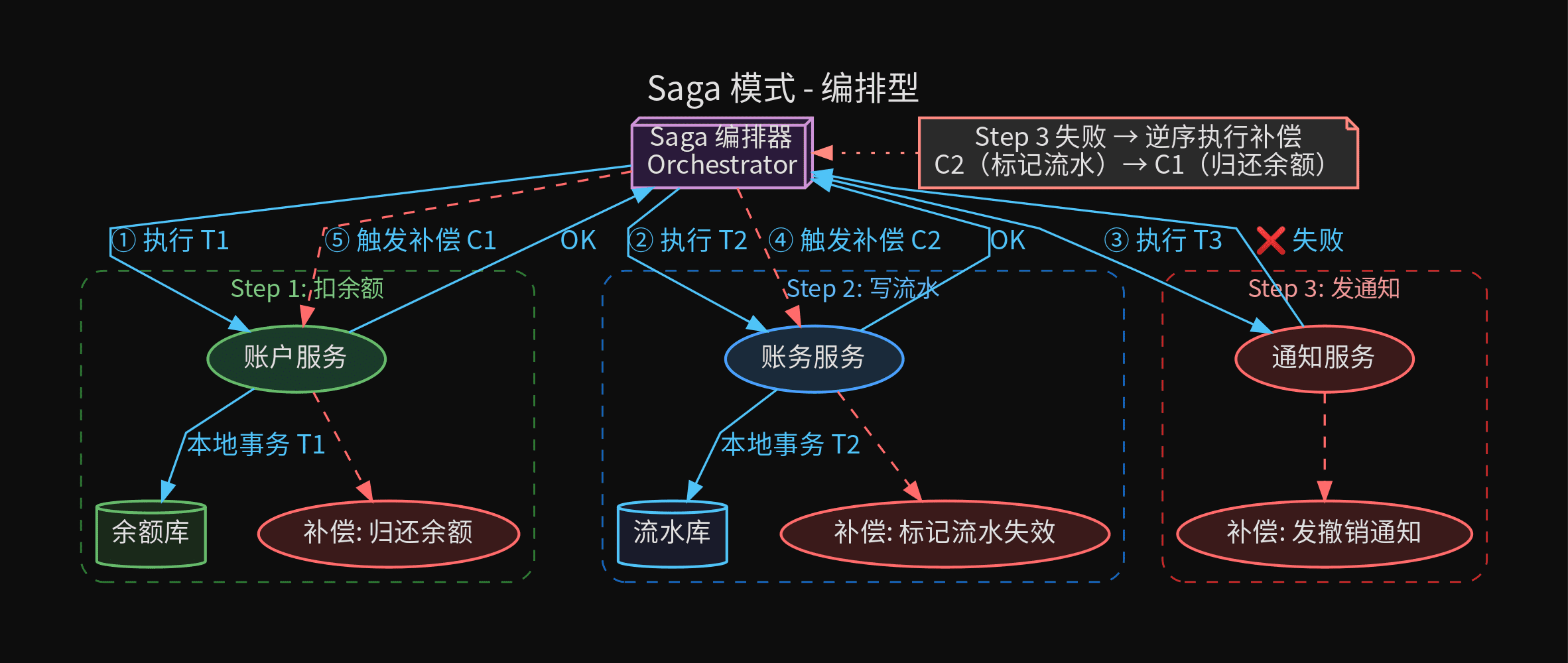
Saga 将一个长事务拆成多个本地事务,每个本地事务对应一个补偿操作。有两种实现模式:
编排型(Orchestration):
由一个 Saga 编排器负责流程控制,参与者只提供正向操作和补偿操作。编排器顺序调用正向操作,任一步失败时逆序调用补偿操作。
转账 Saga 编排流程:
编排器 → 账户服务:扣余额(正向 T1)
编排器 ← 账户服务:OK
编排器 → 账务服务:写流水(正向 T2)
编排器 ← 账务服务:OK
编排器 → 通知服务:发消息(正向 T3)
编排器 ← 通知服务:❌ 失败
编排器 → 账务服务:标记流水作废(补偿 C2)
编排器 → 账户服务:归还余额(补偿 C1)
协同型(Choreography):
没有中央编排器,每个服务执行完本地事务后通过 MQ 触发下一个服务。失败时需要反向传递消息触发补偿。
协同型 Saga 流程:
账户服务(扣余额成功)→ 发消息 → 账务服务
↓
账务服务(写流水成功)
发消息 → 通知服务
↓
通知服务(失败)
发补偿消息 → 账务服务
↓
账务服务补偿 → 账户服务补偿
两种模式对比:
| 维度 | 编排型 | 协同型 |
|---|---|---|
| 职责 | 编排器负责流程控制 | 每个服务感知上下游 |
| 复杂度 | 编排器复杂度随步骤增长 | 步骤多时消息流转复杂 |
| 耦合度 | 低(参与者不知晓全貌) | 高(服务间通过消息耦合) |
| 可观测性 | 强(编排器有完整状态) | 弱(状态分散在 MQ 中) |
| 适用场景 | 流程固定、复杂度可控 | 流程灵活、需要解耦 |
Saga 的实现难点:
- 隔离性缺失:Saga 不提供事务隔离。步骤 T2 在步骤 T1 提交后就能看到 T1 的结果,即使后续 C1 可能回滚 T1。这称为"脏读"。解决方式是用语义锁:在预留字段中标记操作进行中,读取时过滤这些标记
- 补偿幂等:补偿操作可能重复执行,需要幂等设计(同 TCC)
- 补偿正确性:补偿操作必须能将系统恢复到业务一致的状态,而不是数据一致
Saga vs TCC:
| 维度 | TCC | Saga |
|---|---|---|
| 资源占用 | Try 阶段持有资源 | 无预留,直接执行 |
| 锁持有时间 | Try → Confirm 全程 | 仅本地事务期间 |
| 适用事务时长 | 秒级 | 分钟级甚至更长 |
| 补偿设计 | 有预留,补偿简单 | 无预留,补偿要精确 |
| 隔离性 | 可提供一定隔离性 | 不保证隔离 |
一个转账接口的选型实战
回到开头的转账案例,假设当前系统的数据:
- QPS:5000(日均 4 亿笔)
- 跨 3 个服务:账户、账务、通知
- 数据源:MySQL(账户库 + 流水库)+ RocketMQ(通知)
- 一致性要求:转账链路不允许资金损失,但通知消息允许延迟
这个场景不适合 XA(跨异构资源、高并发),也不适合纯 TCC 全覆盖(开发成本高)。实际最优方案是混搭:
账户扣减 → 本地事务(余额库)
↓
写流水 → TCC Confirm(流水库)
↓
发通知 → RocketMQ 事务消息
账户和流水之间用 TCC 保证一致性(这两个不允许不一致),流水和通知之间用消息事务接受延迟。关键链路强一致,非关键链路最终一致——这是生产中最务实的做法。
演进路线总结
从一个接口的事务方案选择,可以看出一套系统的架构成熟度:
单库本地事务
→ 读写分离(本地事务不变,注意路由)
→ 分库分表(XA / 2PC)
→ 微服务拆分(TCC / Saga)
→ 最终一致 + 对账(成熟的分布式系统)
大部分系统走到"XA"或"最终一致"就够了。TCC 和 Saga 只有在跨多个异构资源、且对吞吐有明确要求时才需要引入。
从这套演进逻辑中可以看到,事务方案没有银弹。每个阶段的选择都是在一致性、性能、开发成本之间的权衡。理解权衡背后的原理,比记住某个方案的具体实现更重要。当你面对新的业务场景时,能自己判断该走到哪一步、该用什么方案,而不是盲目套用某一种分布式事务框架。
避坑建议
- 不要为了分布式事务而分布式事务——90% 的场景通过优化本地事务或异步补偿解决。引入分布式事务前先问:这个操作真的需要强一致吗?
- XA 的锁持有时间必须监控——prepare → commit 的时间超过 1 秒就要报警。锁持有时间 = 全局阻塞时间,直接决定系统吞吐上限
- TCC 的空回滚和防悬挂必须实现——不做这两个,极端情况(网络超时 + 重试)下会出现资金异常。这是线上故障最常见的原因
- 事务 ID 必须在整条链路传递——日志、数据库、MQ 都需要同一个 ID 用于回查和排障。缺少链路 ID 的分布式事务等于没有运维手段
- 先测试单机事务的正确性——分布式事务的 bug 往往根在底层事务配置(隔离级别、自动提交、代理绕过)。基础不牢,上层再好的方案也会出问题
- 最终一致性方案必须设计对账——没有对账的最终一致性等于没有一致性。对账是分布式系统的最后一道防线
- 不要混合使用不同分布式事务方案——一个链路里既有 2PC 又有 TCC,隔离性和一致性难以保证。同一链路选一种方案走到底
- XA 事务的隔离级别要设为 READ COMMITTED——不要用 REPEATABLE READ。XA + RR 的间隙锁会大幅增加死锁概率
- TCC 的 Try 接口要有防并发设计——并发下同一账户可能被多条 Try 同时冻结,需要用行锁或乐观锁保护
附:完整命令清单
-- 查看 MySQL 事务状态
SHOW ENGINE INNODB STATUS\G
-- 查看当前运行中的事务
SELECT * FROM information_schema.INNODB_TRX;
-- 查看锁等待
SELECT * FROM sys.innodb_lock_waits;
-- 本地事务测试
BEGIN;
UPDATE account SET balance = balance - 100 WHERE id = 1;
UPDATE account SET balance = balance + 100 WHERE id = 2;
COMMIT;
-- undo log 和 redo log
SHOW VARIABLES LIKE 'innodb_undo_%';
SHOW VARIABLES LIKE 'innodb_log_%';
-- XA 事务测试
XA START 'xid1';
UPDATE account SET balance = balance - 100 WHERE id = 1;
XA END 'xid1';
XA PREPARE 'xid1';
XA COMMIT 'xid1';
-- 查看 redo log 刷盘配置
SHOW VARIABLES LIKE 'innodb_flush_log_at_trx_commit';
-- 值为 1: 每次 commit 都刷盘(最安全)
-- 值为 2: 每秒刷盘(性能好但可能丢 1 秒数据)


