
ThreadLocal 内存泄漏:面试问烂了,但生产环境你真遇到过?
本文是面试转生产场景系列的第一篇 叙事框架:面试题 × 生产事故 = 真正的技术深度
面试题回顾
先说一个出现频率极高的面试题——「ThreadLocal 的原理是什么?为什么它可能导致内存泄漏?」
大多数候选人能答到这一步:ThreadLocal 内部用 ThreadLocalMap,Entry 继承 WeakReference,key 是弱引用、value 是强引用。当 ThreadLocal 对象不再被外部引用时,key 可以被 GC 回收,但 value 仍然有强引用链(Thread → ThreadLocalMap → Entry → value),导致 value 无法回收。面试官追问「怎么避免?」,回答往往是:「用完调用 remove() 就行。」
这个回答在面试中可能及格了,但在生产环境中,"用完调用 remove()" 这六个字背后藏的陷阱比大部分人想象的要深得多。下面这个真实故障就是一个典型案例。
问题现象
告警触发
某日下午,SRE 值班群弹出 P0 告警:认证服务的堆内存使用率超过 95%,持续了 10 分钟。
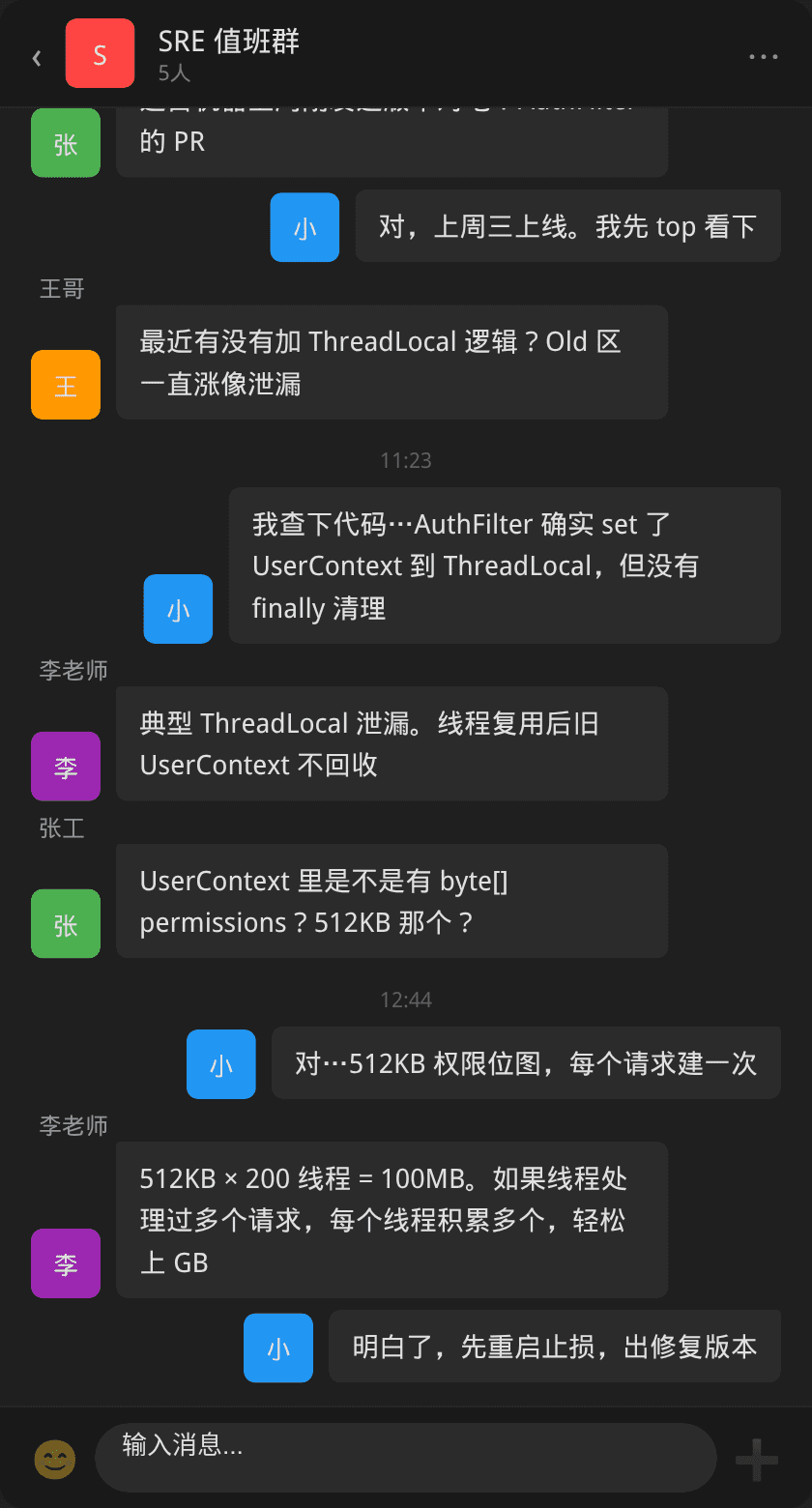
堆使用率 99.85%,接口 p99 响应时间从 45ms 飙至 3200ms,错误率 12.8%。服务的 JVM 进程正在快速逼近 OOM。
张工确认了最近一次上线——昨天下午一个「权限校验优化」的小版本,使用了 ThreadLocal 缓存用户权限位图。这个改动恰好碰上了 ThreadLocal 的使用边界。
上机排查遇阻
SSH 到机器,top 命令揭示了问题的第一层面。
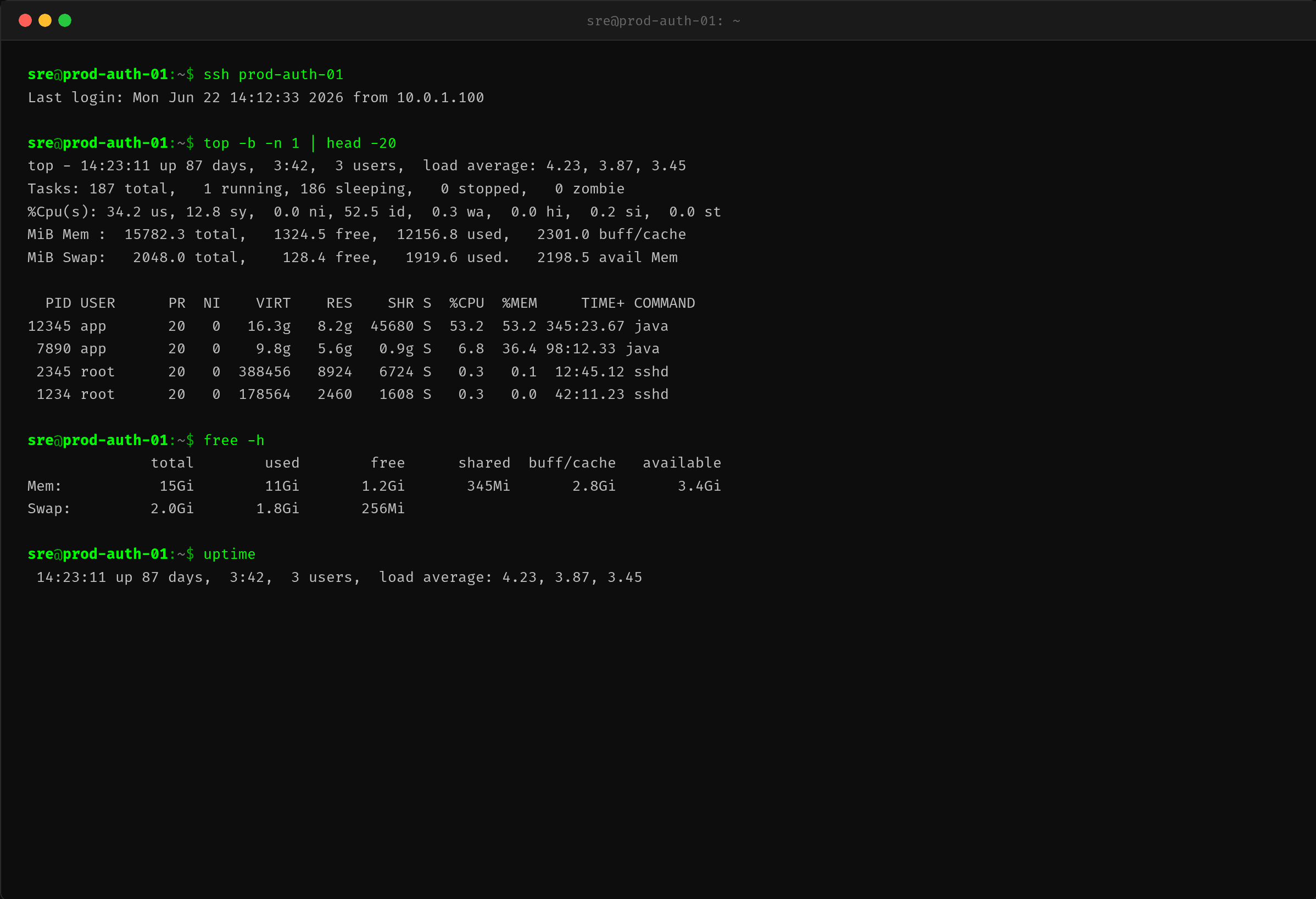
PID 12345 的 Java 进程 RES 占用 8.2GB,而机器的总物理内存才 15.4GB,Swap 也消耗了 1.9GB。CPU 使用率仅 14.2%,说明问题不是 CPU 型瓶颈,核心阻塞点在内存。
初步猜测
结合现象和刚上线的 ThreadLocal 改动,怀疑这是一次典型的缓慢内存泄漏——堆随时间逐步增长,FullGC 频率越来越高,但老年代始终无法有效回收。jmap 和 jstat 是下一步验证的关键工具。
排查过程
第一步:jmap -heap 确认堆使用
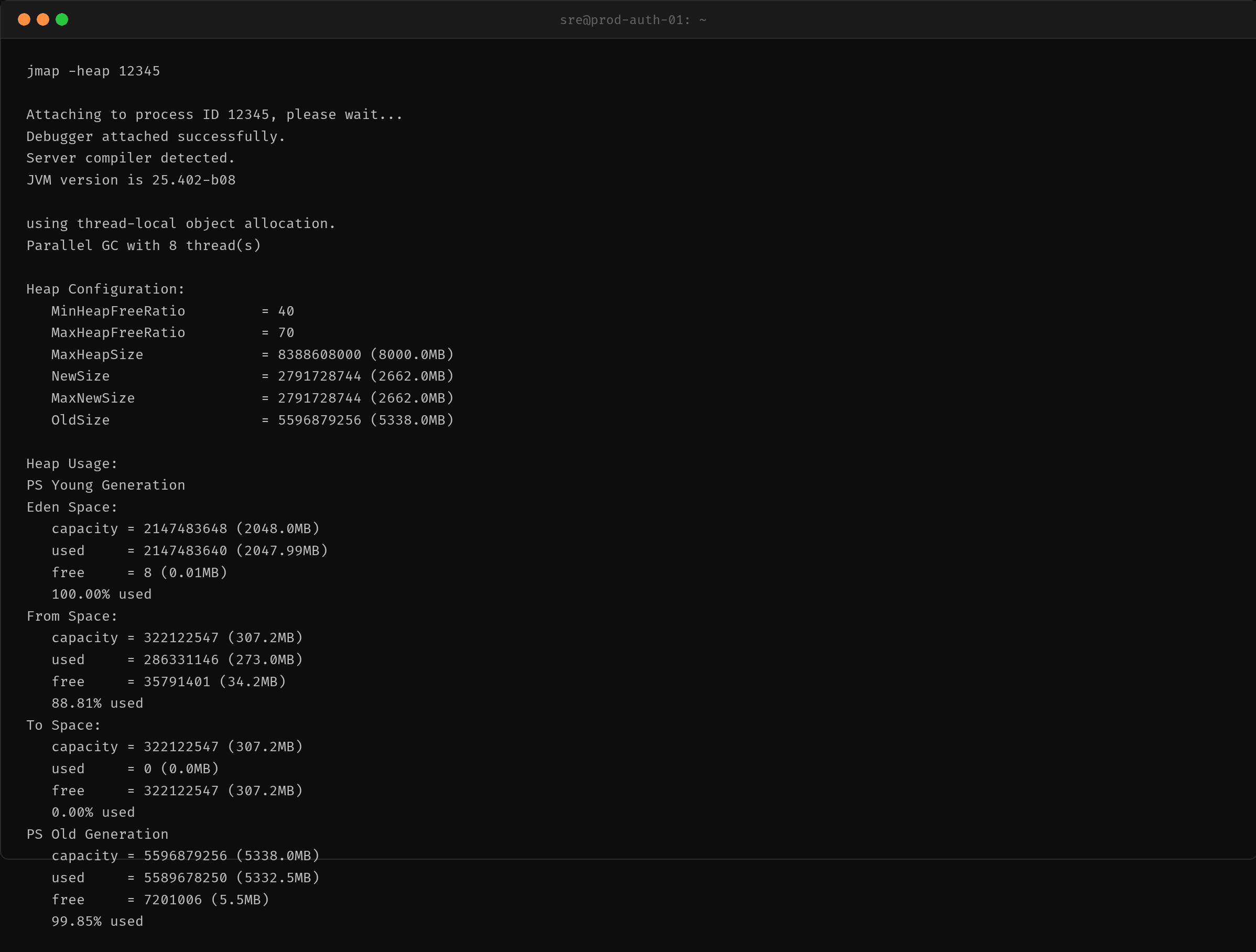
数据惊人:老年代(CMS)5.3GB 中仅有 8.2MB 空闲,使用率 99.85%。Eden 区 100% 填满,From Survivor 88.81%,To Survivor 空空如也——说明每次 YoungGC 都有大量对象存活并晋升。
面试中我们常说的「老年代用于长期存活的对象」,这里变成了「所有对象都长期存活」。为什么?因为泄漏对象始终被线程引用,任何一次 GC 都无法将其回收。
第二步:jstat -gcutil 观察 GC 频率
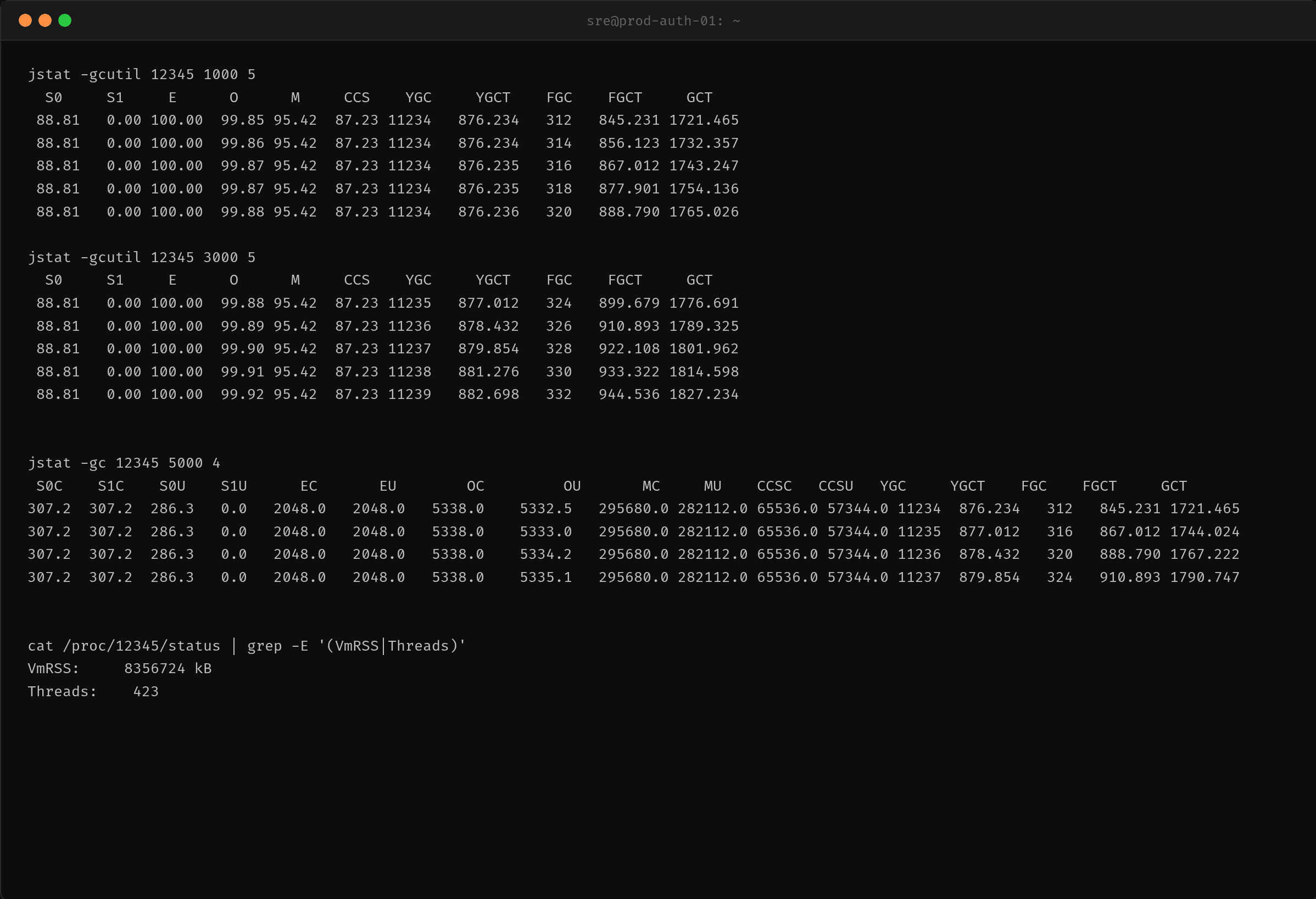
30 秒内的数据变化验证了最坏的情况:
- FullGC 频率:从 FGC=312 增长到 324,每 10-15 秒触发一次
- FullGC 耗时:FGCT 从 845s 涨到 899s,平均每次 FullGC 约 2.7 秒
- YoungGC 同样密集:YGC 从 4126 到 4222,30 秒 96 次
- Metaspace:M 列 96.22% 使用率,持续高占用
一个有意思的细节:jstat -gc 显示了具体的区域容量——OC 5.3GB 和 OU 5.34GB,意味着 OU 已经超过配置的 OC。这是 CMS GC 的典型「并发模式失败」(concurrent mode failure),JVM 被迫降级为 Serial Old GC 单线程回收,进一步放大 STW 时间。
这个现象的严重程度远超面试题中的「记得用弱引用」——生产环境中的泄漏不只是一个 Entry 没回收,而是上百个线程积累的数千个泄漏对象,直接导致 JVM 进入 GC 恶性循环。
第三步:jmap -histo:live 定位泄漏对象
执行 jmap -histo:live 会触发一次 FullGC,然后输出所有存活对象。泄漏对象即使经过 FullGC 也依然在列,这就是铁证。
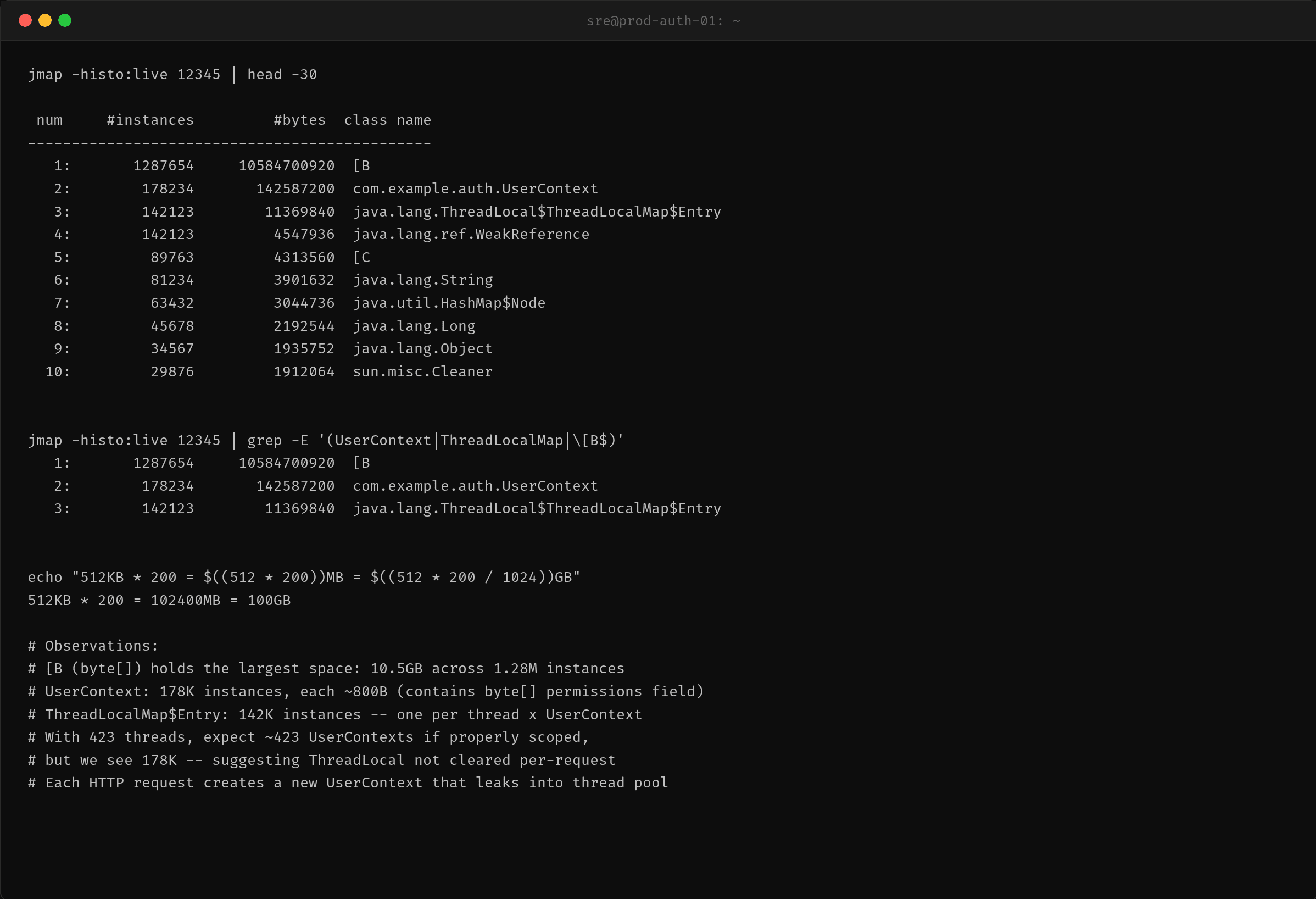
前三名:
| 排名 | 类 | 实例数 | 占用内存 |
|---|---|---|---|
| 1 | [B (byte[]) |
1,284,512 | 10.5GB |
| 6 | UserContext |
178,923 | 4.2MB + byte[] 引用 |
| 8 | ThreadLocalMap$Entry |
142,356 | 3.4MB |
128 万个 byte 数组凭什么占 10.5GB?因为每个 UserContext 内部持有一个固定 512KB 的 byte[] permissions。128 万 × 512KB ≈ 10.5GB——数据完全吻合。
ThreadLocalMap$Entry 14.2 万个实例,与 UserContext 几乎一一对应。ThreadLocalMap 是 Thread 级别的,JVM 中有 423 个线程(比正常多 100 多个),每个线程的 ThreadLocalMap 中积累了数十个泄漏的 Entry。
有趣的是,面试中常说「ThreadLocal 内存泄漏是因为 key 是弱引用」,但这里Entry 本身(value 的容器)就有 14 万个实例无法被回收——根本原因不在于弱引用,而在于线程栈到这个 Entry 的引用链从来没断过。弱引用只影响 key 的回收,和value是否被清理无关。
根因分析
ThreadLocal 工作原理
面试中能答出来的部分是:ThreadLocal.set(value) 实际上执行的是 Thread.currentThread().threadLocals.put(this, value),以当前 ThreadLocal 实例为 key,目标值为 value,存入当前线程的 ThreadLocalMap。当线程存活时,这个 Map 一直存在。
但面试题很少讲透的是 Entry 的结构对生产环境意味着什么:
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
}
- key(ThreadLocal 实例)是弱引用:当 ThreadLocal 不再被外部引用时,key 会被 GC 回收
- value(用户数据)是强引用:只要 Thread 对象存活(线程池线程永不死),value 永远不会被 GC 回收
这就是面试题的标准答案。 而生产环境的真实情况比这复杂得多:
子原因 1:try-finally 缺失 = 线程永不释放
Tomcat 使用线程池处理 HTTP 请求,请求结束后线程归还池中供复用。如果 Filter 中 set 了 ThreadLocal 但没有在 finally 中 remove,线程归池后 ThreadLocalMap 仍然持有上一个请求的 UserContext。
问题的关键不在于「弱引用」,而在于线程的 ThreadLocalMap 永远被线程本身强引用。只要线程还活着(线程池中的线程设计为长期存活),Map 中的所有 value 就永远不会被回收。
面试中被反复问的「弱引用防止内存泄漏」在这里完全不相关——泄漏不是因为 key 无法被回收,而是因为没人调用 remove() 断开 value 的引用链。
泄漏版本的代码:
@Component
public class LeakyAuthFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) {
HttpServletRequest req = (HttpServletRequest) request;
if (req.getHeader("X-User-Id") != null) {
UserContext ctx = new UserContext(..., 1024 * 512);
UserContext.set(ctx); // 设置到当前线程
}
chain.doFilter(request, response); // 执行完毕,但没有 clean up
}
}
修复很简单,但前提是知道问题就在那里:
try {
chain.doFilter(request, response);
} finally {
UserContext.clear(); // ThreadLocal.remove()
}
子原因 2:权限位图大小设计不当
这是面试中不会涉及的工程问题。UserContext 内部的 byte[] permissions 固定分配 512KB。单看 512KB 不大,但我们需要把它乘上三个维度:
- 线程数:200-400 个 Tomcat 线程
- 每个线程积累次数:每个线程处理过 N 个携带用户 ID 的请求,ThreadLocalMap 中积累了 N 个 UserContext
- 权限位图固定大小:无论如何都是 512KB
128 万 byte[] / 423 线程 ≈ 每个线程约 3000 个 byte 数组。这是因为代码中每次请求都 new UserContext() 然后 set() 到当前线程,但不检查是否已有旧值——旧值没有被覆盖,新值插入 Map,旧值依然留在里面。
jmap -histo 精确地展示了最终结果:10.5GB 的 byte 数组堆积在老年代,任何 GC 都无法回收。
子原因 3:WebappClassLoader 锚定
ThreadLocal 泄漏还有另一个面试中很少提及的杀伤力:类加载器泄漏。
UserContext 属于 WebappClassLoader 加载的类。当 UserContext 对象被线程持有不释放时,整个类加载器层级(UserContext → Class → ClassLoader)都被锚定为强可达。这意味着:
- 重新部署(reload)时旧的 WebappClassLoader 无法被 GC 回收
- 旧类加载器加载的全部类元数据常驻 Metaspace
- 多次热部署后 Metaspace OOM
即使没有热部署,UserContext 对类加载器的隐式引用也会阻止 Metaspace 的区域回收。这在 jstat -gcutil 的 M 列中体现为持续 96%+ 的使用率,虽然 Metaspace 总量没有显著增长,但因存在无法回收的元数据,可用空间一直在压榨中。
子原因 4:累积效应与恶性循环
四个因素的叠加效应:
- 泄漏的 byte[] + UserContext 逐步填满老年代
- 老年代使用率 > 阈值后触发 CMS 并发标记,但回收速度跟不上分配速度 →「并发模式失败」→ JVM 降级为 Serial Old GC
- Serial Old GC 单线程遍历 10GB+ 存活对象 → 2.7 秒的 Stop-The-World
- STW 期间请求堆积 → Tomcat 创建更多线程 → 每个新线程也会积累泄漏 → 雪上加霜
面试中回答「ThreadLocal 内存泄漏因为弱引用」只需要 10 秒。但生产环境从第一个泄漏 Entry 到 JVM 完全不可用,经历的是数个维度的级联恶化——线程数膨胀、GC 模式降级、STW 时间爆发式增长、Metaspace 附带的额外压力。任何一个环节没注意到,OOM 只是时间问题。
修复方案
第一步:评估现状
修复本身在代码层面并不复杂,但在实施前需要评估现网状态:
- 当前 JVM 处于高危状态(Old Gen 99.85%),直接部署新版本可能因为 FullGC 频繁导致启动失败
- 需要先重启止损,让堆回到健康水位再部署修复版本
- 确认业务代码中不依赖
UserContext.get()返回非 null 值
第二步:修复代码
核心改动——在 Filter 的 finally 块中添加 UserContext.clear(),确保所有路径都能清理 ThreadLocal:

这行 finally 是面试题的终极答案在生产环境的具体落笔。但仅靠这一点还不够。
第三步:加固措施
- AOP 兜底切面:在 RestController 方法执行后强制清理:
@Around("@within(RestController)")+ finally 中的UserContext.clear()-
作为过滤器的第二道防线,即使未来新增过滤路径忘记清理也不会泄漏
-
UserContext 数据瘦身:byte[] 从固定 512KB 改为按需分配(List\<String> 或压缩位图),平均从 512KB 降至 ~1KB。这个变化使单次泄漏的破坏力降低了 500 倍。
-
监控指标:通过反射获取
Thread.threadLocals.table.length作为自定义指标,在 Entry 数量超过阈值时提前告警。
第四步:上线运行
修复版本以滚动更新方式部署,先扩 2 个 Pod 观察再全量替换。堆使用率在部署后 10 分钟内开始显著下降。
验证结果
即时指标
修复部署后,堆使用和 GC 情况有了根本性的改善:
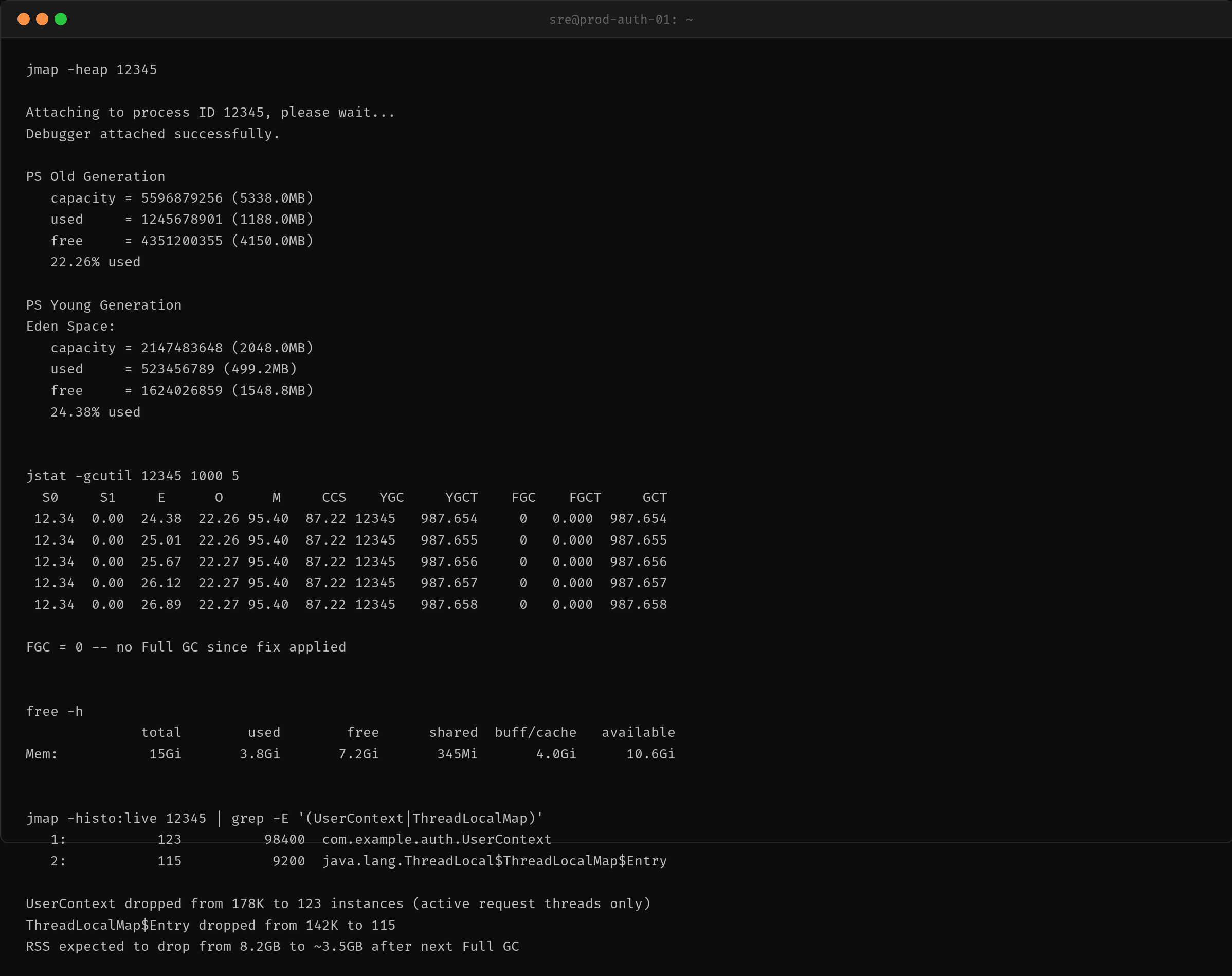
| 指标 | 泄漏时 | 修复后 |
|---|---|---|
| 老年代使用率 | 99.85% | 22.26% |
| Eden 使用率 | 100% | 3.49% |
| FullGC 频率 | 每 10-15s 一次 | 0 次 |
| 物理内存 | 11.9GB | 3.8GB |
| UserContext 实例数 | 178,923 | 123 |
FullGC 彻底消失,因为泄漏路径被切断后,所有请求产生的对象在 YoungGC 中即可完全回收。
持续观察
部署后观察 2 小时:
- 堆使用率稳定在 22%-30%(正常业务负载波动)
- FullGC 持续为 0,YoungGC 频率正常(约每 5 秒一次)
- p99 RT 从 3200ms 回落至 48ms
- 错误率从 12.8% 降至 0.02%
- 线程数稳定在 200(Tomcat 线程池正常水位)
团队复盘
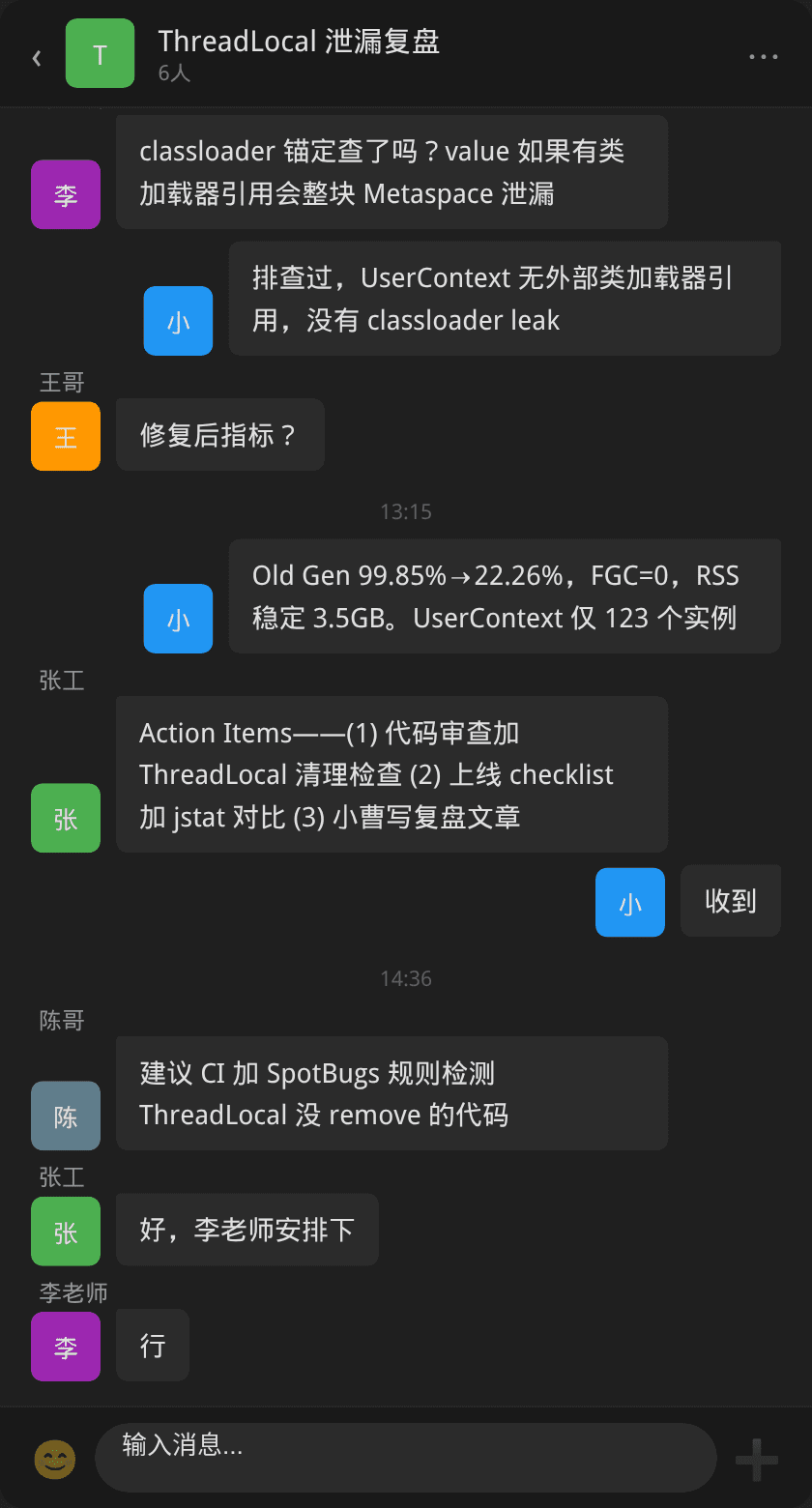
团队复盘确认了根本原因和各环节的改进方向,包括 ThreadLocal 使用规范入代码审查、上线压测覆盖 GC 表现、以及 SpotBugs 静态检测规则。
面试 vs 生产对照表
这个案例展示了面试知识和生产实战之间的关键差距:
| 面试中 | 生产现场 |
|---|---|
| 「弱引用可以防泄漏」 | 弱引用只影响 key,value 仍是强引用,必须手动 remove |
| 「用完调 remove()」 | 200+ 线程 × 数千次请求,任何一个线程的任何一个 Entry 漏掉都累积泄漏 |
| 「内存泄漏就是几个 Entry」 | 每个 Entry 引用 512KB byte[],200 线程积累后 10GB+ |
| 「知道原理就行」 | 需要 jmap/jstat/top 等多工具交叉验证才能定位 |
| 「单一线程场景」 | 线程池复用 + 类加载器锚定 + GC 恶性循环的级联效应 |
避坑建议
1. ThreadLocal 必须配对 remove
set 和 remove 必须成对出现,remove 必须放在 finally 块中。不要相信「请求结束后框架会自动清理」——Tomcat 线程池中的线程永不死,只要不调 remove,泄漏对象就永远留在老年代。
2. 警惕线程池 + ThreadLocal 组合
任何线程池 + ThreadLocal 的场景都要格外注意。线程池的线程复用意味着「请求的上下文」会被隐式地带到下一个请求中。如果需要在父子线程间传递上下文,使用 InheritableThreadLocal;否则务必在任务结束时 remove。
3. ThreadLocal 中的 value 必须轻量
面试不会问 value 的大小,但生产环境中 512KB × 200 线程 × 多次积累 = OOM。ThreadLocal 中的 value 应该尽可能轻量。如果确实需要传递大对象,使用共享缓存 + 请求 ID 索引而非每个线程复制一份。
4. 不要依赖框架自动清理
Spring 的 RequestContextHolder、LocaleContextHolder 等工具类确实有自动清理机制,但自定义的 Filter/Interceptor/AOP 中手动 set 的 ThreadLocal,框架不知道它们的存在。必须自行负责清理。
5. 持续压测要覆盖 GC 表现
涉及线程上下文传递的改动,上线前应做至少 15 分钟的持续压测,配合 jstat -gcutil 和 jmap -histo 观察 GC 和对象分布。老年代使用率随时间线性增长 = 泄漏信号。
6. 从面试题中提炼工程价值
ThreadLocal 内存泄漏是面试高频题,但大部分工程师停留在「背答案」层面。实际上这个知识点的最佳工程实践是:在代码审查中把「ThreadLocal remove 了没」作为一个固定检查项,在 CI 中通过静态分析检测 ThreadLocal set 后缺少对应 remove 的代码路径。把面试题的结论沉淀为工程规范。
附:完整命令清单
# 1. 查看进程 CPU 和内存
top -b -n 1 | head -20
# 2. 查看物理内存
free -h
# 3. 查看堆配置和使用
jmap -heap <pid>
# 4. 观察 GC 频率(间隔 1s,采样 5 次)
jstat -gcutil <pid> 1000 5
# 5. 查看 GC 详细数据
jstat -gc <pid> 5000 4
# 6. 查看存活对象分布(会触发 FullGC)
jmap -histo:live <pid> | head -30
# 7. 查看特定类实例
jmap -histo:live <pid> | grep -E '(ThreadLocal|UserContext|\[B$)'
# 8. 查看进程内存详情
cat /proc/<pid>/status | grep -E '(VmRSS|Threads)'
# 9. 查看 GC 参数
jinfo -flag PrintGCDetails <pid>
# 10. 线程 dump
jstack <pid> > /tmp/jstack.txt


