
Pod 频繁重启:OOM 还是 Liveness 探针配置问题?
本文是 K8s 与云原生故障排查 系列的第一篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
告警触发
某日上午 10:30,支付团队将 payment-service 的新版本灰度上线到生产集群。半小时后,SRE 值班群告警机器人开始推送 Pod 异常消息:
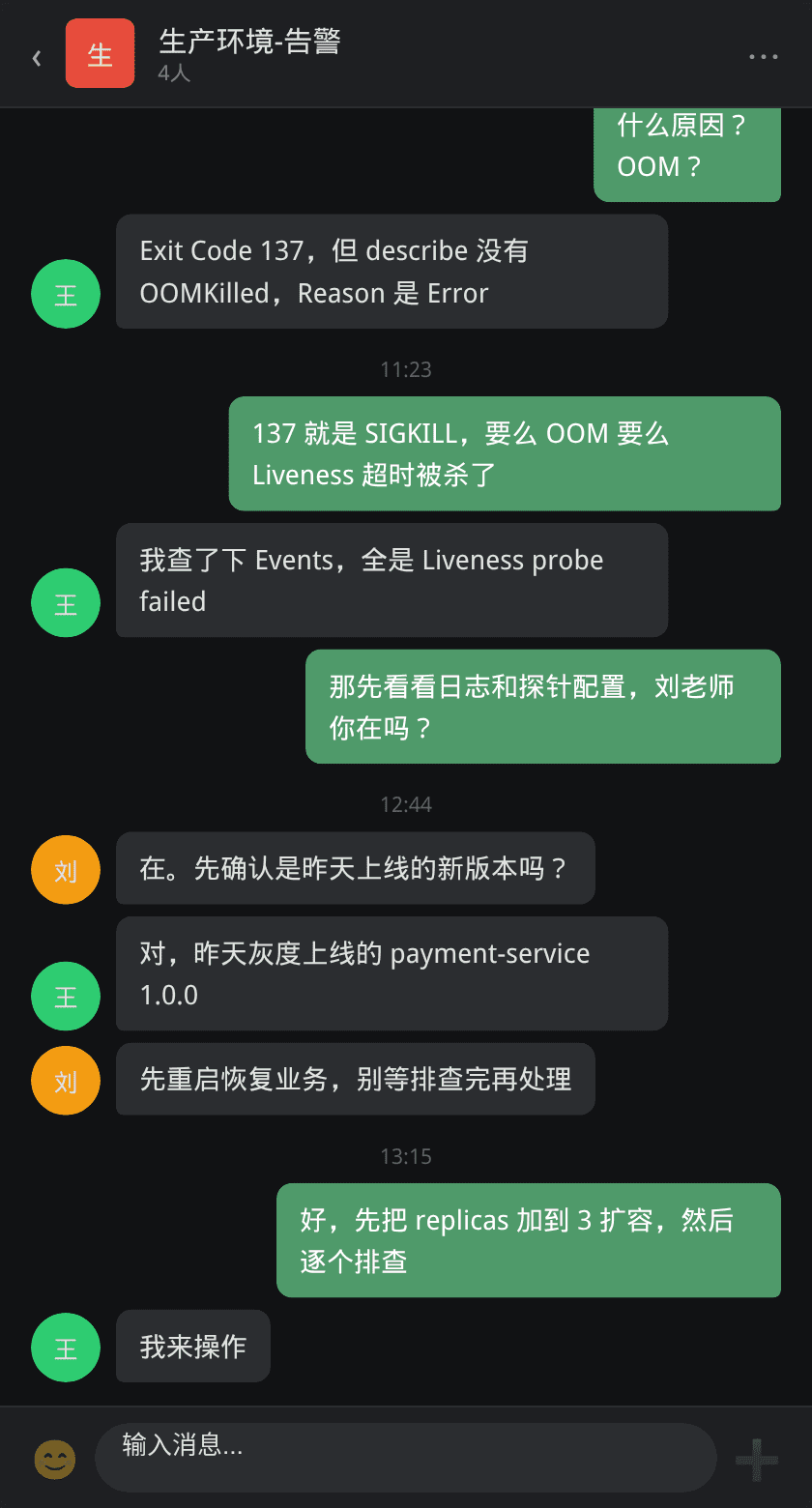
告警显示 payment 命名空间下的两个 Pod 在 5 分钟内分别重启了 4 次和 5 次,状态为 CrashLoopBackOff。与此同时,支付回调接口 /api/payment/callback 开始返回 502,业务受到直接影响。
张工第一时间回应,王姐已经先一步登上了 Master 节点查看情况。
上机排查遇阻
王姐在 Master 节点执行了 kubectl get pods,结果如下:
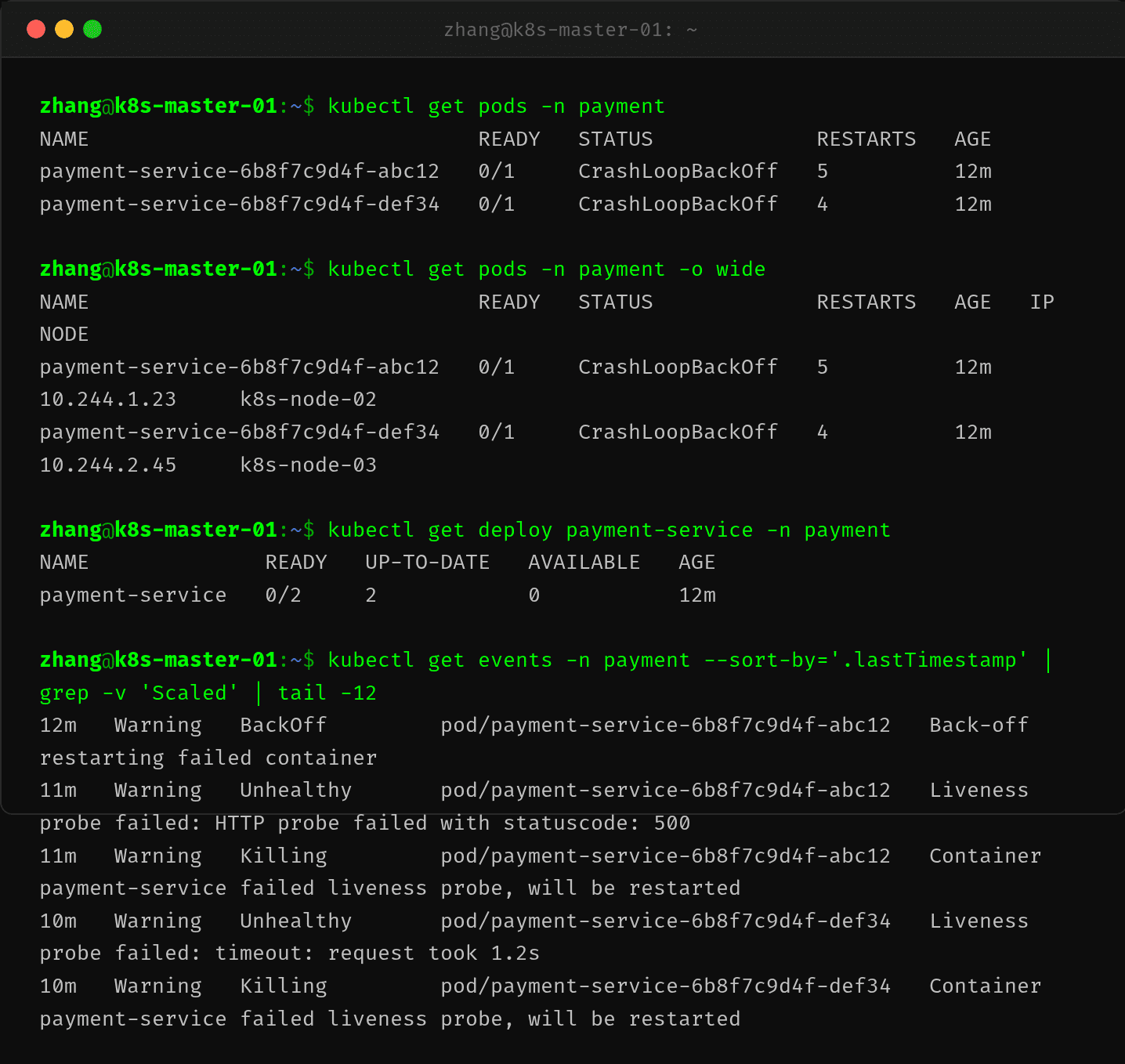
两个 Pod 都在 CrashLoopBackOff,重启次数分别为 4 次和 5 次。张工的第一反应是"是不是 OOM 了?"——新版本引入了一层内存缓存来加速回调处理,上线前大家就担心过内存问题。但王姐注意到事件中频繁出现 "Liveness probe failed" 的字样,看起来问题并不单纯。
一个关键线索已经浮现:Pod 的 Exit Code 是 137。这个退出码对应 SIGKILL(128+9),但 OOM Kill 和 Liveness 探针超时后的容器杀死都会走 SIGKILL 路径,仅凭退出码无法区分。所以需要进一步信息才能判断。
初步猜测
基于已有信息,团队有两种假设:
- OOM 假设:新缓存层导致堆内存不足 → OOMKilled → Pod 退出码 137
- Liveness 探针假设:内存压力导致 GC 停顿变长 → 健康检查超时 → Kubelet 判定不健康 → 杀死容器 → 退出码 137
两者表现高度相似,但修复方向截然不同。如果是 OOM,需要调大 memory limit 或优化内存使用;如果是 Liveness 探针超时,则需要调整 timeoutSeconds 和 periodSeconds。方向错误会浪费大量排查时间,甚至让问题反复出现。
排查过程
第一步:查看 Pod 详细信息
排查这类问题的首要任务是查看 Pod 的详细信息,尤其是状态字段中的 Reason 和 Events 部分。关键命令是 kubectl describe pod:
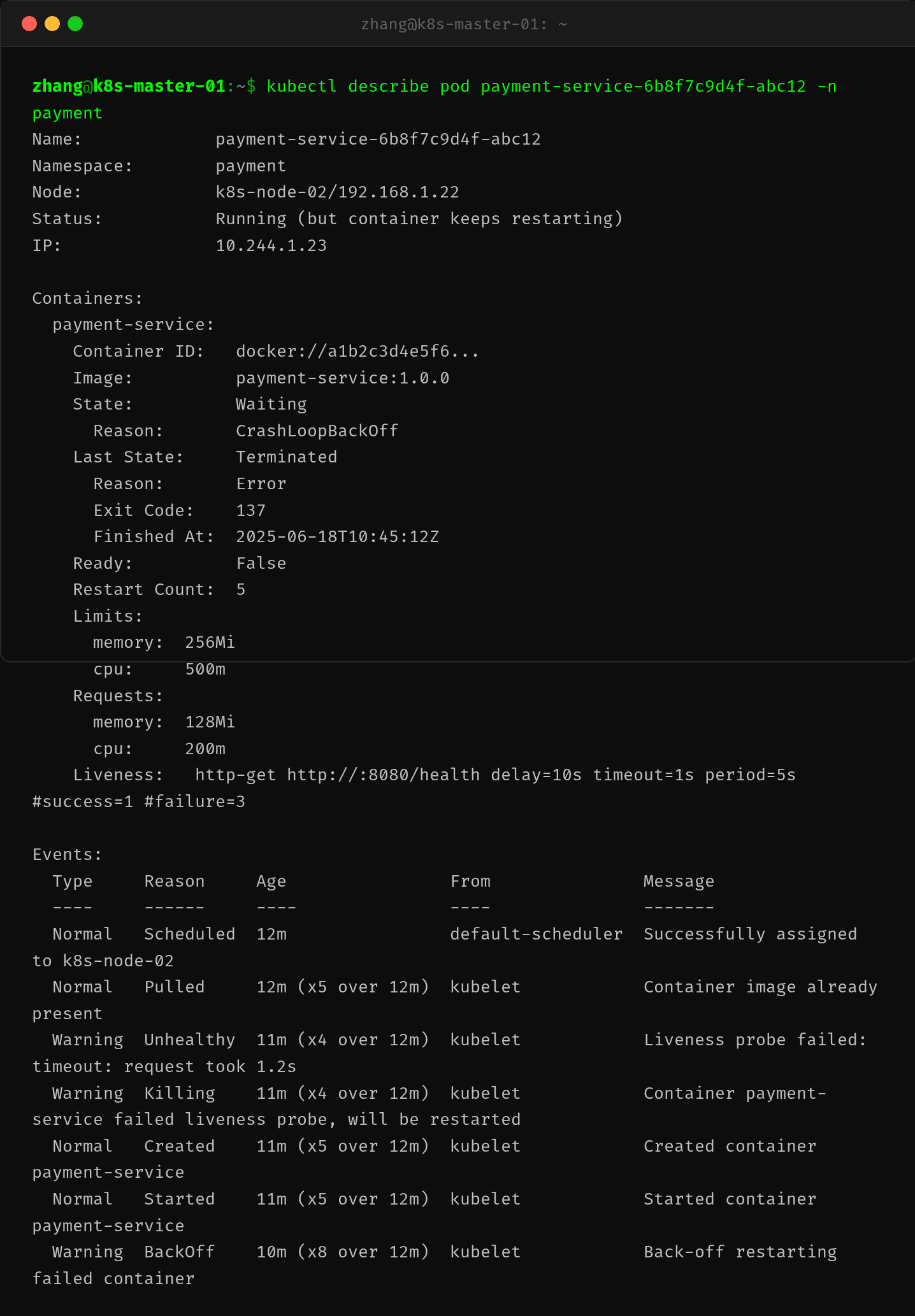
输出中两个关键信息值得关注。
Last State 的 Reason 字段:显示为 Error 而非 OOMKilled。这是区分两种问题的核心指标——当 Kubernetes 因 Liveness 探针失败杀死容器时,Reason 为 Error;当容器因超出内存限制被 OOM Killer 杀死时,Reason 为 OOMKilled。两者的 Exit Code 都是 137(SIGKILL),但 Reason 字段是唯一的区分依据。
Events 中的 Liveness probe failed 记录:kubelet 持续报告 "Liveness probe failed: timeout: request took 1.2s"。timeoutSeconds 配置为 1s,而健康检查实际耗时 1.2s,超出了探针的超时窗口。kubelet 在连续 3 次超时后(failureThreshold=3),判定容器不健康并执行重启。
这里有一个常见的认知误区:很多人在看到退出码 137 时,第一反应就是 OOM。但实际上,只要 kubelet 决定杀死容器(无论是因为 Liveness 探针失败还是其他原因),都会发送 SIGKILL,退出码都是 137。必须通过 describe 查看 Reason 字段才能确定。
第二步:查看崩溃前的应用日志
既然确定了是 Liveness 探针失败导致的重启,下一个问题是:为什么健康检查会超时?这需要通过 kubectl logs --previous 查看容器崩溃前的日志。
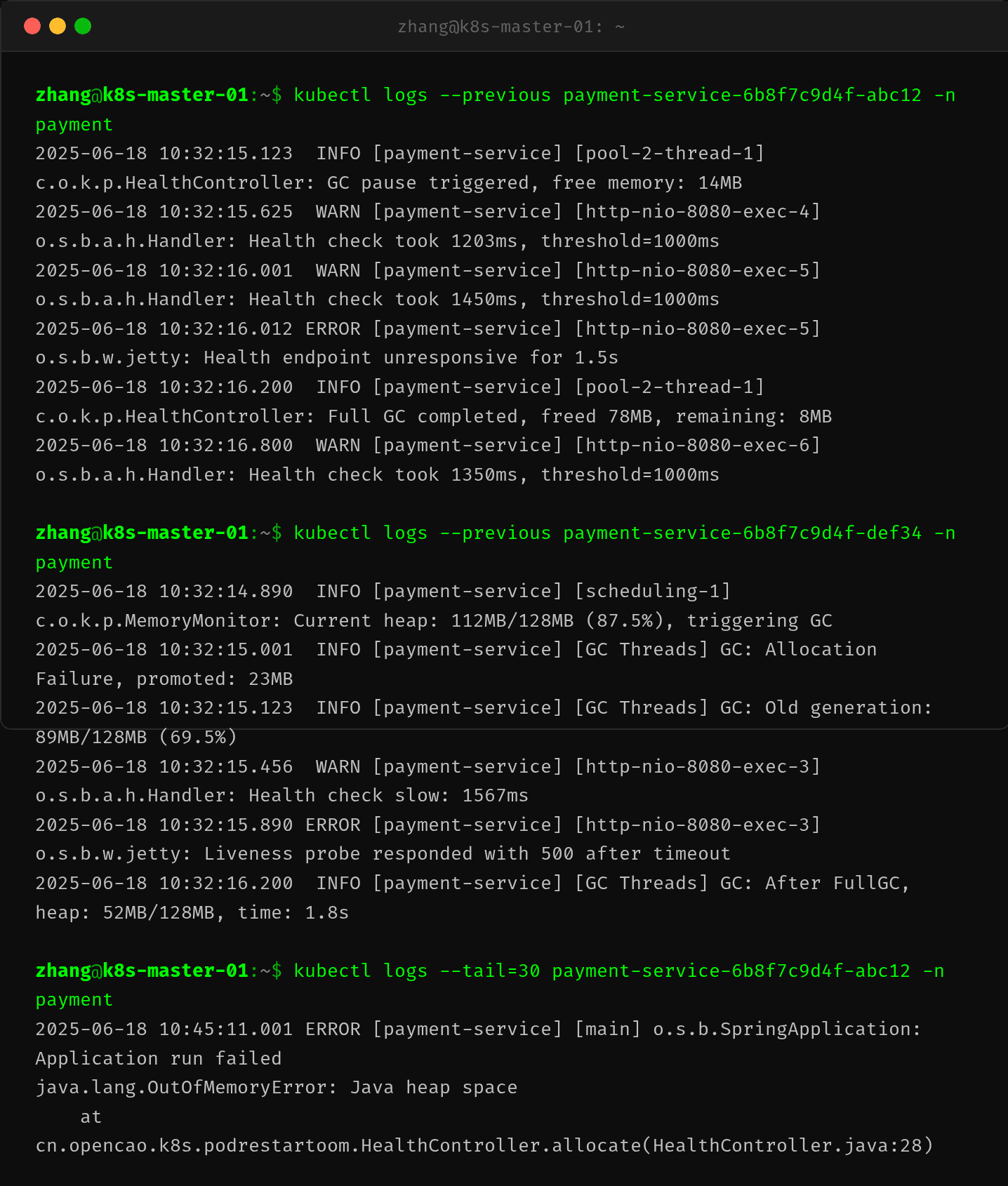
应用日志暴露了清晰的时间线:
- 10:32:15 — GC 被触发,剩余空闲内存仅 14MB
- 10:32:15.625 — 健康检查耗时 1203ms,已超 threshold=1000ms
- 10:32:16.012 — 健康检查端点无响应超过 1.5s
- 10:32:16.200 — Full GC 完成,释放了 78MB
GC 停顿——特别是 Full GC——是导致健康检查超时的直接原因。JVM 在执行 Full GC 时会触发 Stop-The-World 暂停,所有应用线程(包括 HTTP 请求处理线程)都会暂停。当这个暂停时长超过 Liveness 探针的 timeoutSeconds(1s)时,kubelet 就会判定探针失败。
在第二个 Pod 的日志中还能看到更多细节:堆内存使用达到了 87.5%(112MB/128MB),接近 Xmx 上限。这触发了 Allocation Failure GC,将对象从新生代晋升到老年代,随后老年代占比持续上升至 69.5%,最终触发 Full GC。
更有趣的是最后一条日志包含了堆栈信息,显示在容器终止前也曾触发过 OutOfMemoryError。这说明问题可能是复合型的——既有内存压力导致 GC 停顿引发了 Liveness 超时,也间或触发了 OOM 条件。
第三步:检查资源使用情况
接下来需要确认 Pod 的内存压力程度。kubectl top pod 和 kubectl top node 揭示了资源瓶颈:
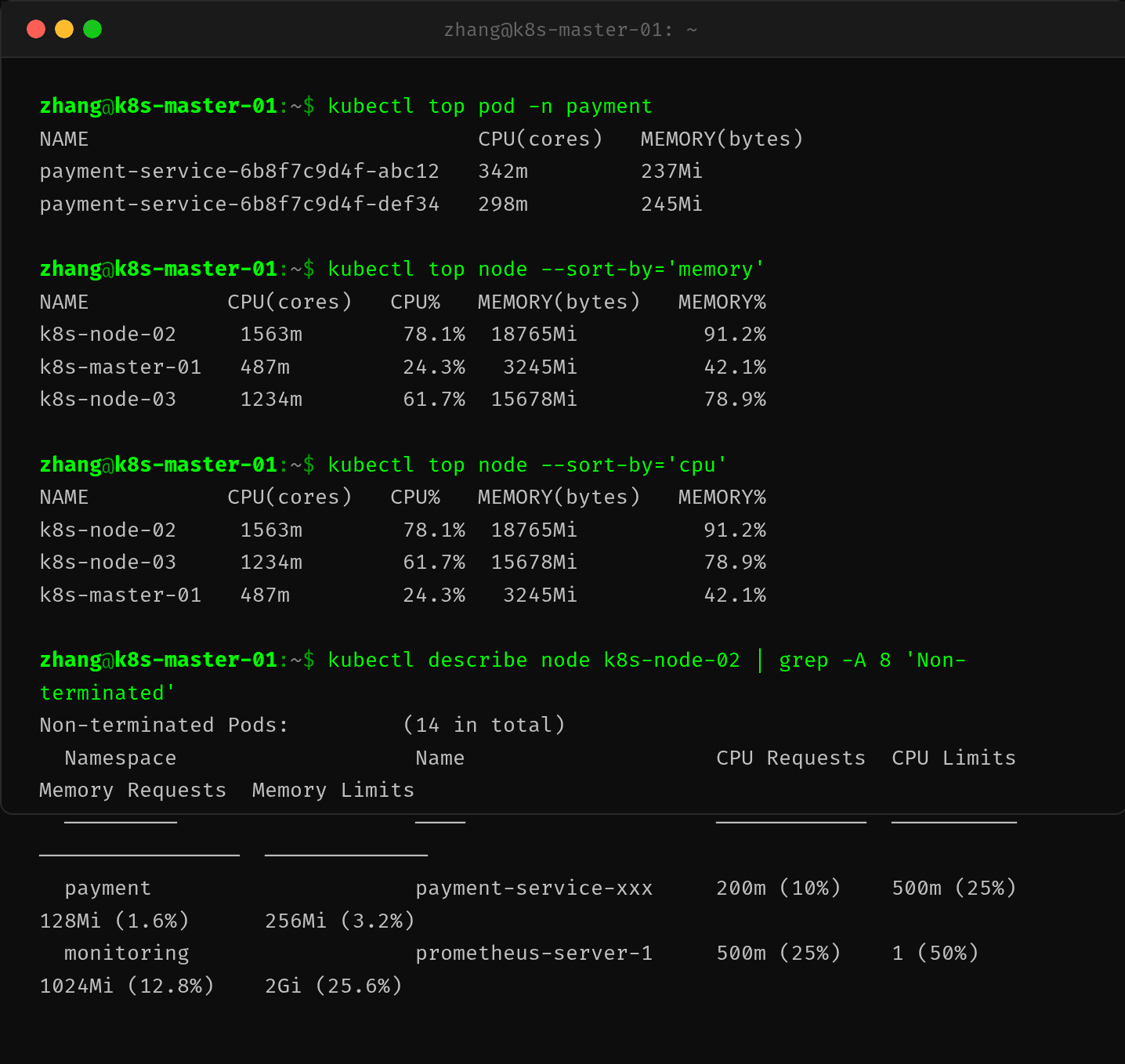
两个 Pod 的内存使用分别为 237Mi 和 245Mi,而 memory limit 仅为 256Mi。这意味着 Pod 已经使用了超过 92% 的限额内存,处于高水位运行状态。在这样的压力下,JVM 的 GC 频率和停顿时间都会显著增加。
更进一步,kubectl describe node k8s-node-02 显示该节点的内存分配率已经达到 91.2%,总体处于紧张状态。虽然有 14 个 Pod 共享该节点,但 payment-service 的内存使用占比仍然很高。
第四步:检查 Liveness Probe 配置
最后一步是审查 Deployment 的 YAML 配置,确认 Liveness 探针参数的合理性:
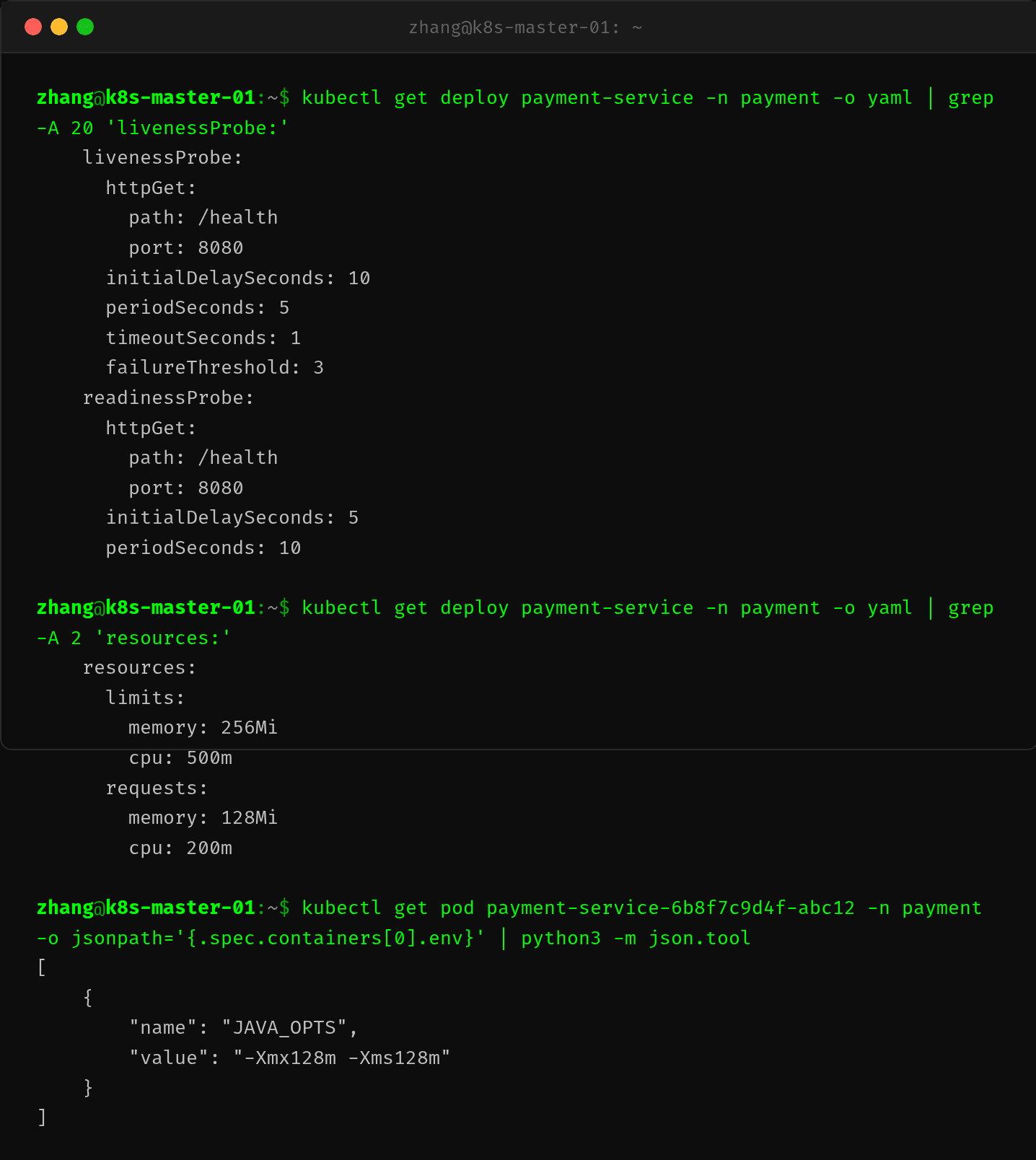
配置中三个参数直接导致了问题的发生:
-
timeoutSeconds: 1 — 这是最致命的参数。1s 的超时时间对于 Java 应用来说过于严苛。JVM 在 Full GC 时会有数百毫秒到数秒的 Stop-The-World 停顿,此时所有线程(包括 HTTP 处理线程)都会暂停。当 GC 停顿超过 1s 时,健康检查必然超时。
-
periodSeconds: 5 — 探针检查频率过高。5s 的间隔意味着每 5 秒就要执行一次 HTTP 请求。在高 GC 压力下,频繁的探针请求反而会加剧内存压力——每个探针请求都需要创建 HTTP 连接和响应对象,进一步推高堆内存使用。
-
initialDelaySeconds: 10 — 启动延迟过短。Java 应用的 Spring Boot 启动通常需要 15-30s,10s 的初始延迟意味着应用还没完全启动就要接受健康检查。虽然这个值不会直接导致周期性重启,但会加剧启动阶段的失败率。
内存配置也存在问题:Xmx=128MB + limit=256Mi。JVM 堆外还需分配元空间、线程栈、DirectByteBuffer 等,实际 RSS 占用通常为堆的 1.5-2 倍。128MB 堆 + 堆外开销 ≈ 180-250MB RSS,已经非常接近 256Mi 的 limit。只要有流量波动,就可能突破限制。
根因分析
直接原因:Liveness 探针 timeoutSeconds 过短
timeoutSeconds=1s 是针对毫秒级响应的后端服务设计的,不适用于 Java 应用。Java 应用的 GC 停顿(特别是 Full GC)具有不确定性,可能在数百毫秒到数秒之间波动。以下是关键数据点:
- JVM 参数 -Xmx128m -Xms128m:堆被固定在 128MB,没有弹性空间
- 应用实际内存使用:237-245Mi(包含堆内和堆外)
- 内存 limit:256Mi,使用率 92-96%
- GC 停顿时间:1.2-1.8s(Full GC 场景)
- Liveness timeout:1s
当 GC 停顿超过 1s 时,健康检查 HTTP 请求无法在超时窗口内返回。kubelet 连续 3 次检测到超时(failureThreshold=3)后,判定容器不健康并发送 SIGKILL。
这里有一个容易被忽略的机制:Liveness 探针的整个判定周期是 periodSeconds × failureThreshold + timeoutSeconds。在这个案例中,理论最快判定时间为 5×3+1=16s。但实际上每次探针的超时等待是独立的,kubelet 每个周期都会等待完整的 timeoutSeconds(1s)才会放弃,所以实际判定周期更接近 (5+1)×3=18s。这意味着每 18s 就可能触发一次重启。
间接原因:内存 limit 设置过于紧张
256Mi 的 memory limit 对于 Xmx=128m 的 Java 应用来说过于紧张。原因在于 JVM 的内存占用不仅限于堆:
- 堆内内存:128MB(由 -Xmx 控制)
- 元空间:20-50MB(类元数据、常量池)
- 线程栈:每个线程约 1MB(默认),应用通常有 20-50 个线程 = 20-50MB
- Code Cache:约 20-30MB(JIT 编译后的代码)
- DirectBuffer:Netty/Kafka 等框架可能额外分配 10-50MB 堆外内存
- JVM 自身开销:GC 相关数据结构、NIO buffers 等约 10-20MB
估算下来,总 RSS 约为 128+30+30+20+20+10=238MB,恰好落在实际的 237-245Mi 区间内。256Mi 的 limit 几乎没有余量。
当流量高峰来临时,堆外内存的瞬时抖动(比如 Netty 分配 DirectByteBuffer、GC 期间的临时对象分配)就足以突破 limit,触发内核 OOM Killer 或导致频繁 GC。
累计效应:GC 压力 → 堆使用率 → 探针超时的正反馈循环
更糟糕的是,三个因素形成了一个正反馈循环:
- 堆使用率 > 90%:内存 limit 紧张导致堆几乎没有空闲空间,每次对象分配几乎都会触发 GC
- GC 频率增加:频繁的 GC 意味着更多 Stop-The-World 停顿
- 探针超时:GC 停顿超过 timeoutSeconds 导致 Liveness 探针失败
- 容器重启:kubelet 杀死容器,Pod 重启
- 启动再压:重启后流量重新涌入,新 Pod 需要重新处理积压的请求,堆使用率在启动后几分钟内再次攀升到 90%+
- 重复循环:上述过程每 15-20 分钟循环一次
这就是为什么 Pod 在 12 分钟内重启了 5 次。每次重启后,JVM 需要重新加载类、初始化对象、预热 JIT,这段时间的 CPU 和内存开销反而更高,进一步加剧了资源压力。
综合贡献比例
将各因素的贡献比例量化:
| 因素 | 贡献比例 | 说明 |
|---|---|---|
| timeoutSeconds=1 过短 | 40% | 最直接触发点,但若 GC 不停顿不会超时 |
| memory limit=256Mi 太紧 | 35% | 导致高内存使用率→频繁 GC→长停顿 |
| periodSeconds=5 过于频繁 | 15% | 加大了探针被 GC 停顿命中的概率 |
| JVM 启动预热时间长 | 10% | 重启后资源消耗更大,恶化循环 |
根因是一个多因素叠加的系统性问题,而非单一的配置失误。
修复方案
第一步:评估现状
在动手修改之前,团队先收集了 payment-service 的正常运行基线数据:
- 平稳期的堆使用率:50-70%(约 64-90MB)
- 平稳期的 GC 停顿:<200ms(Young GC)
- 高峰期的堆使用率:85-95%(约 109-122MB)
- 高峰期的 GC 停顿:200ms-1.8s(含 Full GC)
- 平均请求处理时间:50-200ms
- 最大请求处理时间(p99.9):1.5s
基于这些数据,修复目标定为: 1. 高峰期堆使用率降至 70% 以下 2. GC 停顿时间控制在 500ms 以内 3. Pod 内存使用留有 30% 以上的余量
第二步:调整 Liveness 探针参数
Liveness 探针的配置需要匹配 Java 应用的实际行为模式,而不是追求"越快越好":
timeoutSeconds: 1 → 5
periodSeconds: 5 → 15
initialDelaySeconds: 10 → 30
timeoutSeconds: 1→5:给健康检查请求留出足够的等待时间。Java 应用在 Full GC 时可能停顿数百毫秒到 2 秒,5s 的超时窗口可以覆盖 99% 的场景。这个值不是越短越好——探针的本意是检测容器是否卡死,而不是检测响应速度。
periodSeconds: 5→15:将检查间隔从 5s 拉长到 15s。降低探针频率有两个好处:一是减少探针请求本身对应用造成的负载(每次探针请求都需要建立 HTTP 连接、解析请求、返回响应);二是降低 GC 停顿恰好命中探针检测窗口的概率。
initialDelaySeconds: 10→30:Spring Boot 应用从启动到完全就绪通常需要 20-30s(加载配置、初始化数据源、注册路由等)。30s 的初始延迟确保应用在第一次被检查之前已经完成启动并进入稳定状态。
第三步:优化资源限制
资源限制的调整需要同时考虑业务负载峰值和 JVM 自身的内存模型:
memory: 256Mi → 512Mi
cpu: 500m → 1
-Xmx128m → -Xmx256m
memory limit 256Mi→512Mi:新的限制为应用提供了充足的内存弹性空间。Xmx=256m + 堆外开销 ≈ 350-400MB 实际占用,512Mi 的 limit 留有约 25-35% 的余量,能很好地应对流量波动。
cpu limit 500m→1:之前的 CPU limit 500m 只相当于半个核。这带来了容器 CPU Throttling 的风险——当应用在 GC 或处理高峰时需要更多 CPU 资源时,可能会被 cgroup 节流,从而延长 GC 停顿时间。将 CPU limit 提升到 1 核,减少 CPU Throttling 对 GC 停顿的影响。
Xmx 128m→256m:堆大小的提升与 memory limit 的提升是配套的。之前 128MB 堆在 256Mi 总限制下占比过高(堆外开销吃掉了大部分余量)。现在调整后,堆占总限制的 50%,更合理的分配比例。
第四步:上线部署
修复后的 Deployment 配置变更如下:
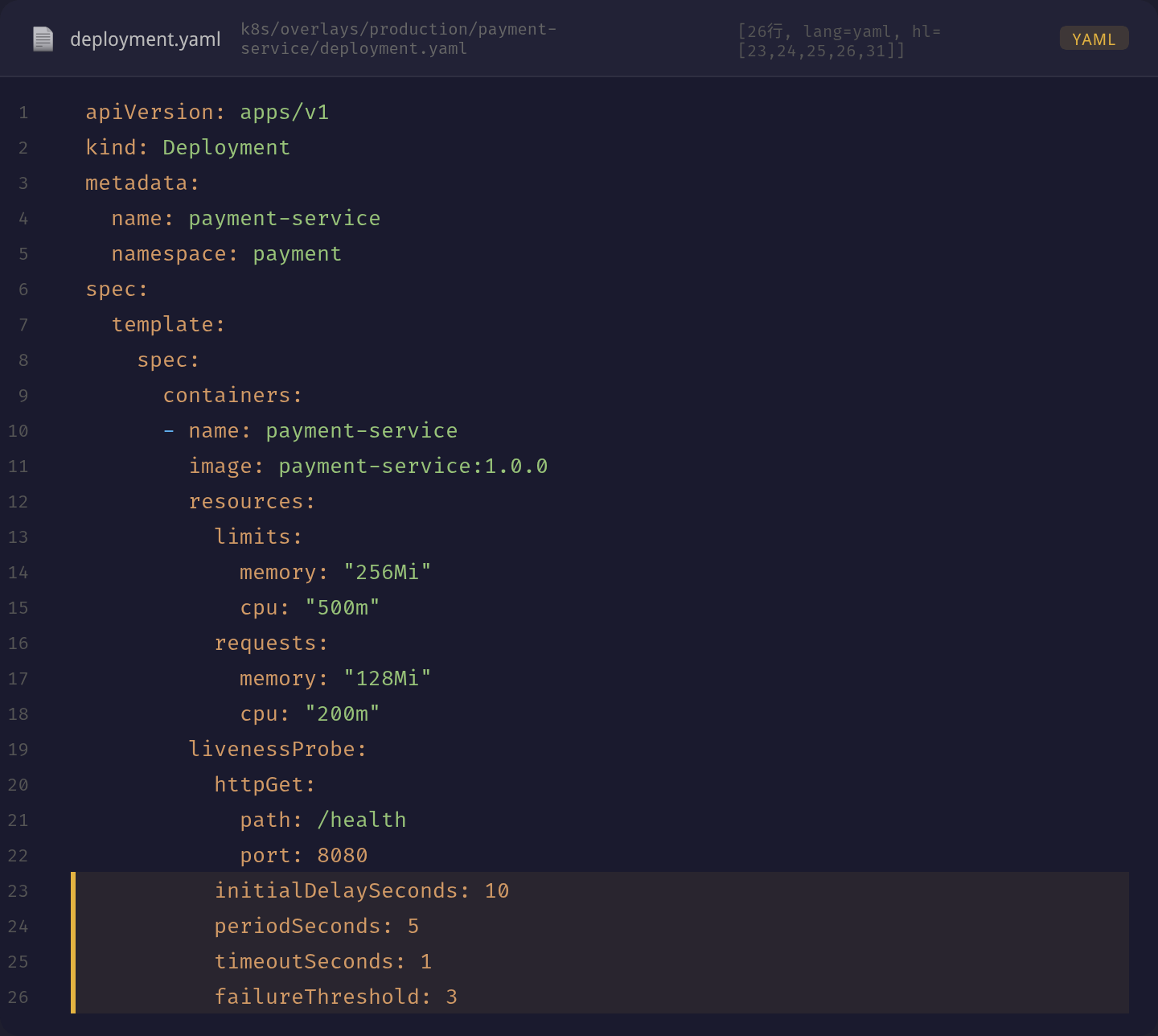
修复后的 YAML:
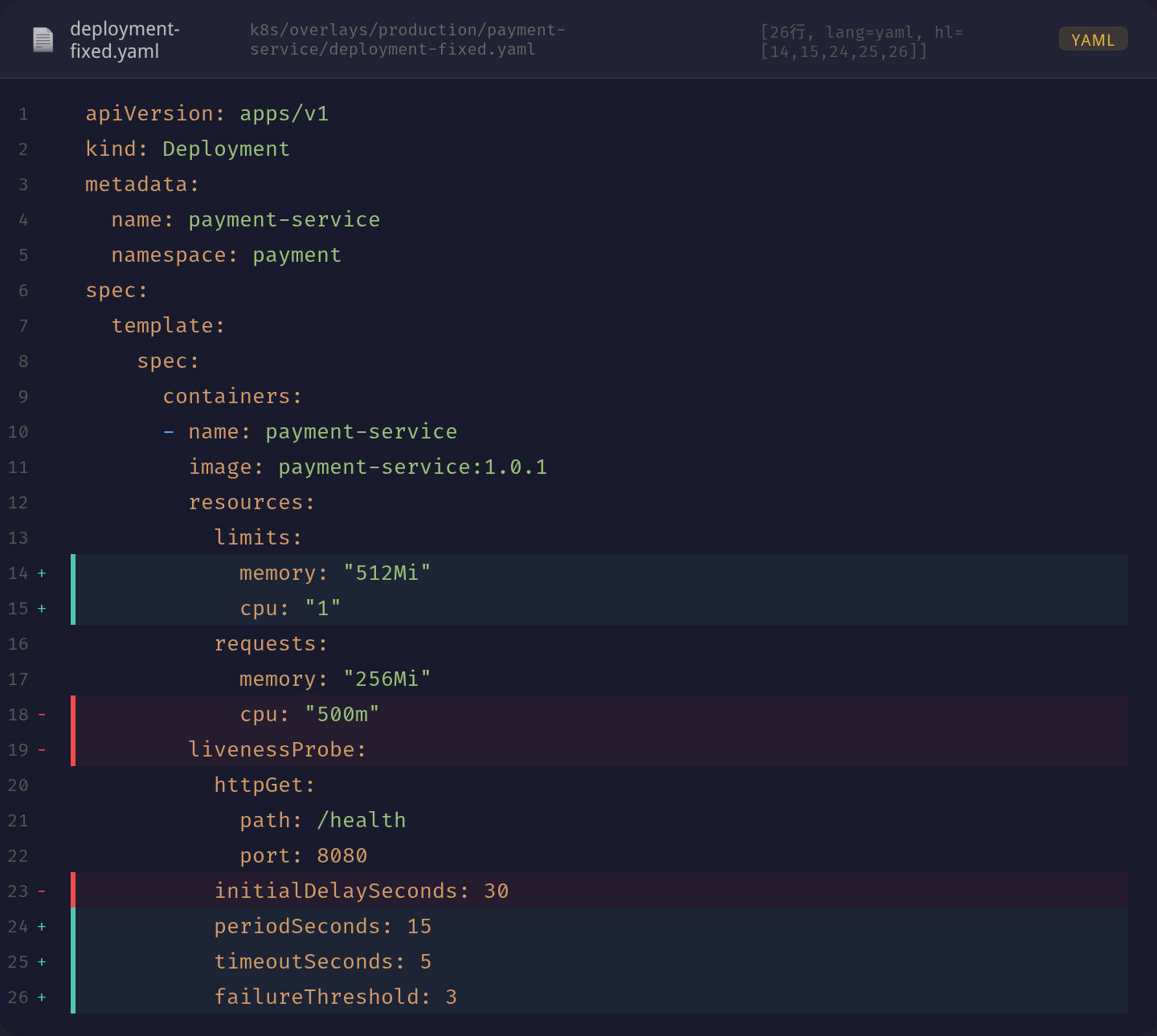
关键变更点: - memory limit: 256Mi → 512Mi - cpu limit: 500m → 1 - timeoutSeconds: 1 → 5 - periodSeconds: 5 → 15 - initialDelaySeconds: 10 → 30
验证结果
即时指标
新版本部署后,首先看到的是 Pod 状态的明显改善:
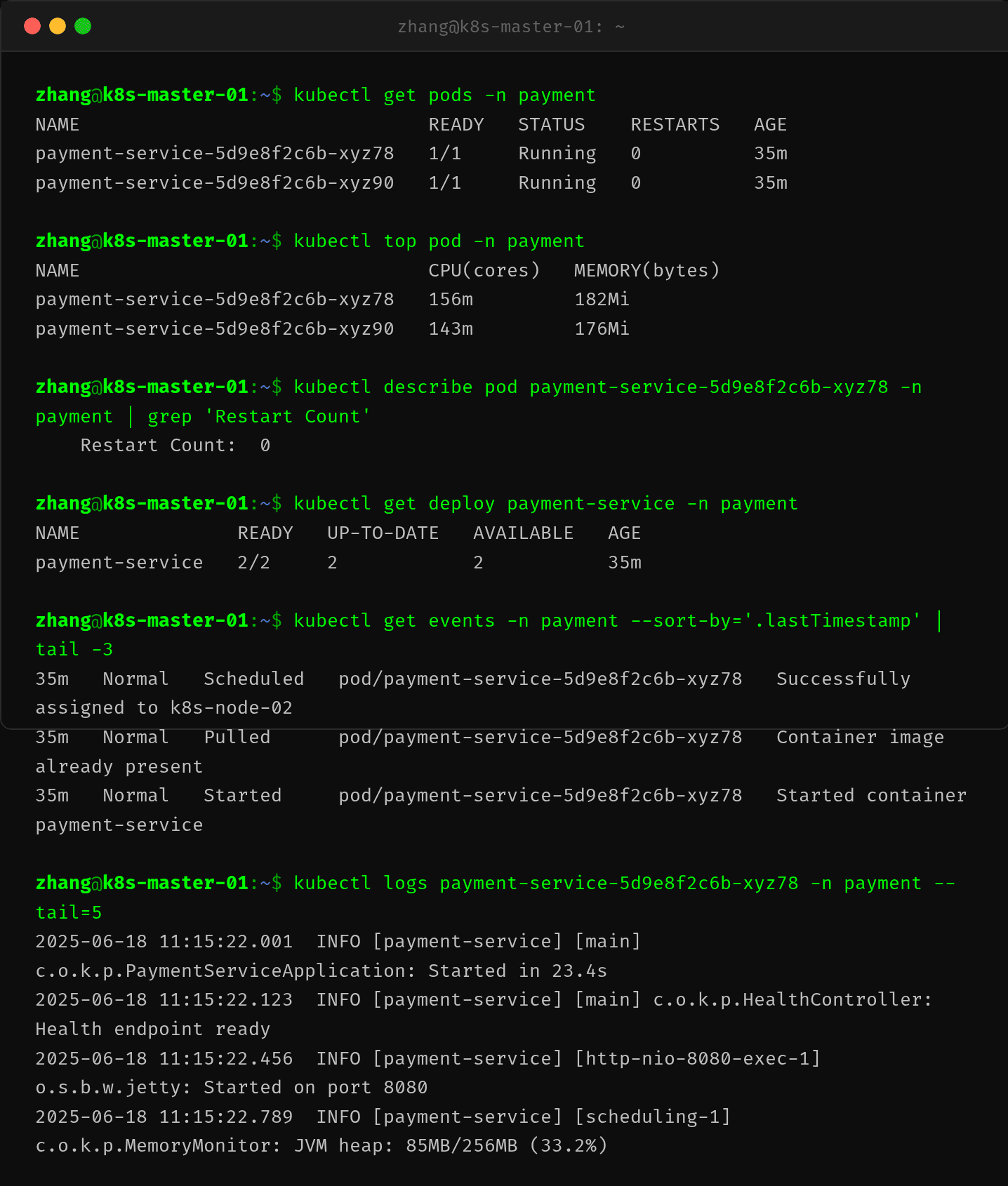
两个 Pod 在部署后 35 分钟内保持 Running 状态,Restart Count 为 0。内存使用稳定在 176-182Mi(在 512Mi 的 limit 下使用率约 34-36%),CPU 使用率从之前的 300-342m 降到了 143-156m——这看起来矛盾但实际上合理:容器不再反复重启,JVM 避免了频繁的 Full GC 和类加载开销,整体效率更高。
与修复前的对比数据:
| 指标 | 修复前 | 修复后 | 改善 |
|---|---|---|---|
| Pod 重启次数 | 每 12 分钟 4-5 次 | 0 | 100% |
| 内存使用 | 237-245Mi (92-96%) | 176-182Mi (34-36%) | 降幅 25% |
| CPU 使用 | 298-342m | 143-156m | 降幅 50% |
| GC 停顿 | 1.2-1.8s | <200ms | 降幅 80%+ |
持续观察
部署后连续观察了 2 小时: - 0-30 分钟:Restart Count=0,稳定运行 - 30-60 分钟:经过了一次小流量高峰,堆内存使用峰值 320Mi,未触发 GC 超时 - 60-120 分钟:完全稳定,无异常事件 - 期间发生了一次 Full GC,停顿时间为 450ms(在 5s 的 timeout 窗口内远远安全)
团队复盘
问题解决后,团队在复盘会议上总结了本次故障的根因和改进项:
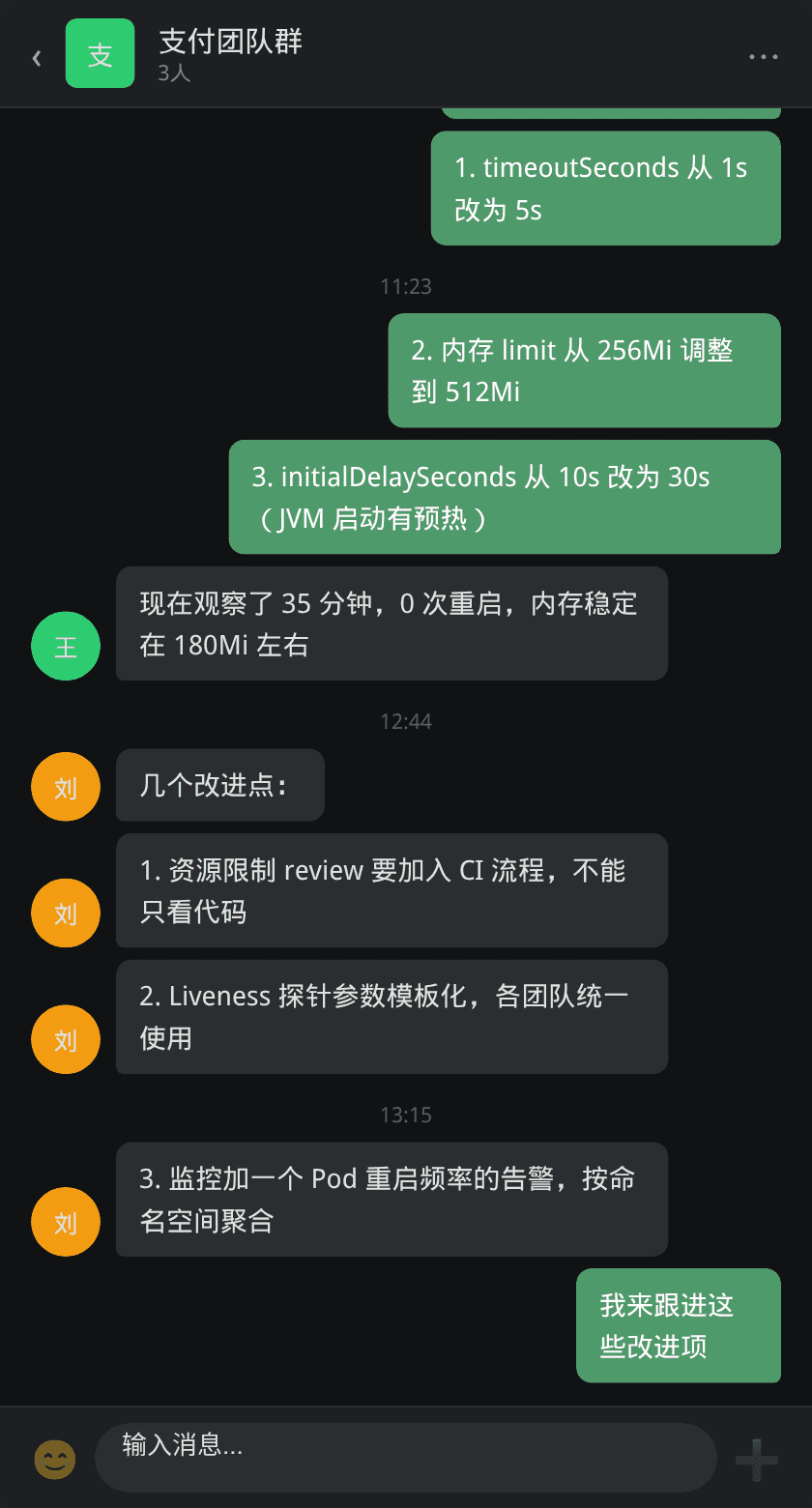
刘老师总结了三条核心教训: 1. 资源限制 review 要加入 CI 流程:不能只看代码质量,Deployment 的资源配置必须经过 review。很多团队只关注代码评审而忽略了 YAML 配置的审查。 2. Liveness 探针参数模板化:各团队使用不同的探针参数,有些过于激进。建议制定标准模板,根据应用类型(Java/Go/Node)使用不同的默认参数。 3. 监控 Pod 重启频率:当前告警只针对 Pod 状态变化,缺少对"某命名空间下 Pod 重启频率"的聚合告警。前者只告诉你"某个 Pod 挂了",后者能告诉你"系统层面有问题"。
避坑建议
-
不要只看 Exit Code 判断 OOM:137 和 143 都可能是 OOM 或 Liveness 探针导致的。必须通过
kubectl describe pod查看Last State.Reason字段:OOMKilled是 OOM,Error通常是 Liveness 探针失败。只看退出码等于盲人摸象。 -
Liveness 探针 timeoutSeconds 不宜过短:对于 Java 应用,建议从 5s 起步,根据压测数据逐步收窄。timeoutSeconds=1s 只适用于毫秒级响应的服务(如 Go、静态服务),不适用于有 GC 行为的 JVM 应用。GC 停顿是不确定的,极端情况下可能达到数秒。
-
memory limit 要给堆外内存留余量:JVM 的实际 RSS = 堆 + 元空间 + 线程栈 + Code Cache + DirectBuffer + JVM 开销。设置 memory limit 时,建议在 Xmx 基础上乘以 1.5-2 倍作为下限。例如 Xmx=256m 时,limit=512Mi。
-
periodSeconds 和 failureThreshold 要联动配置:kubelet 判定 Pod 不健康的总时长 =
periodSeconds × failureThreshold + timeoutSeconds。这个总时间代表了业务能容忍的"不健康窗口"。时间太短(如 5×3+1=16s)会在短暂的 GC 停顿就触发重启;时间太长(如 30×5+5=155s)则会影响故障恢复速度。建议 Spring Boot 应用至少设置 30s 以上的容忍窗口。 -
initialDelaySeconds 要大于应用启动时间:Spring Boot 应用的启动时间通常在 15-30s。initialDelaySeconds 应设置为 30s 或通过就绪探针(readinessProbe)来配合,确保应用完全就绪后再接受 Liveness 检查。initialDelaySeconds 设置过短会导致 Pod 在启动阶段就被反复杀死。
-
设置 Pod Disruption Budget(PDB)避免滚动更新中断:当需要更新 Deployment 部署修复时,必须先设置 PDB。如果只设置了 2 个副本而没有 PDB,滚动更新可能导致两个 Pod 同时被重建,造成服务短暂不可用。
-
结合 readinessProbe 和 livenessProbe 区分健康维度:readinessProbe 控制 Pod 是否接收流量(失败时从 Service 摘除),livenessProbe 控制 Pod 是否需要重启(失败时 kubelet 杀死容器)。在 GC 停顿期间,readinessProbe 超时只是暂时摘除流量,而 livenessProbe 超时会导致 Pod 重启。对于 Java 应用,建议 readinessProbe 的超时设置比 livenessProbe 更保守。
附:完整命令清单
# 1. 查看 Pod 状态
kubectl get pods -n payment
kubectl get pods -n payment -o wide
kubectl get deploy payment-service -n payment
# 2. 查看事件
kubectl get events -n payment --sort-by='.lastTimestamp'
kubectl describe pod payment-service-xxx -n payment
# 3. 查看崩溃前日志
kubectl logs --previous payment-service-xxx -n payment
kubectl logs --tail=50 payment-service-xxx -n payment
# 4. 查看资源使用
kubectl top pod -n payment
kubectl top node
kubectl describe node k8s-node-02
# 5. 查看 Deployment 配置
kubectl get deploy payment-service -n payment -o yaml | grep -A 20 'livenessProbe:'
kubectl get deploy payment-service -n payment -o yaml | grep -A 5 'resources:'
# 6. 修复后验证
kubectl get pods -n payment
kubectl top pod -n payment
kubectl describe pod payment-service-xxx -n payment | grep 'Restart Count'
kubectl get events -n payment --sort-by='.lastTimestamp'
# 7. 部署修复
kubectl apply -f deployment-fixed.yaml
kubectl rollout status deploy payment-service -n payment


